
Selecting Workers Wisely for Crowdsourcing When Copiers and Domain Experts Co-exist


Abstract
:1. Introduction
- The methods that adopt a redundancy-based strategy [3,5]: Majority voting chooses the answer given by the majority of workers as the estimated truth. Gold-injected methods [6] use a small number of tasks with basic facts to evaluate the credibility of workers. The expectation–maximization-based method [7] evaluates worker credibility and forecasts the truth at the same time;
- The methods [8] that improve accuracy by eliminating bad workers: These methods believe that aggregating answers from a small amount of high-credibility workers may achieve better accuracy than blindly pursuing more workers. A typical method [9] is to use qualification tests to distinguish bad workers and stop assigning tasks to them.
- 1.
- To the best of our knowledge, we are the first to propose a crowdsourcing system that comprehensively considers the worker domain expertise and copier detection;
- 2.
- We used a greedy strategy to select experts in task assignment and updated worker domain expertise vectors in truth discovery for more precise quantification. Copier removal was then conducted to facilitate task assignment;
- 3.
- We conducted extensive experiments to demonstrate the effectiveness of our approach via comparison with baseline methods on two real-world datasets and one synthetic dataset.
2. Related Work
2.1. Task Assignment in Crowdsourcing
2.2. Truth Discovery in Crowdsourcing
3. Problem Definition
- A set of domains, D.. This contains all the possible domains involved in the tasks in the system. All domain IDs are named from 1 to ;
- A set of tasks, T. Each is a numerical selection task. indicates the number of options for the task . For example, if the task is to give Obama’s age, then the is 130. In addition, we use to represent the domain set involved in task ;
- A set of workers, W. Each applies to complete tasks in the crowdsourcing system;
- A set of labels, L. Each label is the information voluntarily provided by the worker at the time of registration, indicating some characteristics of the worker, such as age, occupation, etc. These labels are used to better initialize the domain expertise of workers in the initialization algorithm;
- M. The upper limit of the number of tasks each worker can complete. We set M as a constant;
- K. The number of workers required for each task. We set K to another constant.
- Worker domain expertise vector. Each is modeled as a vector , where each indicates the expertise of worker in answering tasks in domain . A higher value means that worker is better at domain k. The system updates it after completes tasks;
- Fine-grained worker credibility,. This reflects the capability of worker providing true value to task . It is calculated based on the worker domain expertise vector;
- Selected workers set,. This collects the workers selected to complete task . (Section 4.2);
- . This depicts the number of tasks that has already been assigned to worker . should never exceed M;
- A set of answers provided by workers after task assignment, A. Each depicts the answer provided by worker on task ;
- Historical task completion records, H. This collection contains all tasks that have been previously completed by workers. Each is modeled as a vector , where is the estimated truth of task . We denote by the observation of H.
- Estimated truth, . This is obtained by integrating the answers of all workers on task .
- Independent copying: The dependence of any pair of workers is independent of the dependence of any other pair of workers;
- No loop dependence: The dependence relationship between workers is non-transitive;
- Uniform false value distribution: For each task, there are multiple false values, and an independent worker has the same probability of providing each of them.
4. Task Assignment
| Algorithm 1 Task assignment. |
|
4.1. Fine-Grained Worker Credibility Calculation
4.2. Worker Selection
| Algorithm 2 Worker selection. |
|
4.3. Copier Detection and Removal
| Algorithm 3 Copier disposal. |
|
5. Truth Discovery
| Algorithm 4 Truth discovery. |
|
6. Worker Domain Expertise Renewal and Initialization
6.1. Worker Domain Expertise Renewal
6.2. Worker Domain Expertise Initialization
7. Experiments
7.1. Experimental Settings
- MovieLens [63]: This dataset contains 1,000,209 anonymous ratings of approximately 3900 movies made by 6040 MovieLens users. All ratings are in the following format: UserID-MovieID-Rating. UserIDs range between 1 and 6040. MovieIDs range between 1 and 3952. Ratings are made on a 5-star scale. Another file contains the domain to which each movie belongs. Each user has at least 20 ratings;
- Anime (https://www.kaggle.com/CooperUnion/anime-recommendations-database (accessed on 19 December 2021)): This dataset contains information on user preference data from 73,516 users on 12,294 anime works. Each user is able to add anime works to his/her completed list and give it a rating. This dataset is a compilation of those ratings. All data are displayed in the following format: userid-animid-rating (ratings range from 0 to 10). The domain information of anime works is in the description document of the anime works;
- Synthetic dataset: This dataset was synthesized on the basis of MovieLens dataset by manually adding copiers. We added different proportions of copiers, in which each copier randomly copies a worker in the MovieLens dataset. Due to randomness, we generated 100 synthetic datasets for each proportion, and the experimental results of each method were averaged. We discuss the performance of various algorithms via tuning the proportion of copiers.
- RandomMV: This method uses a random strategy for task assignment and aggregates workers’ answers to generate truth by using majority voting;
- D&S [7]: This method also uses the random strategy for task assignment. For truth discovery, it uses the EM algorithm, which calculates worker accuracy and truth;
- ASKIT! [17]: This method uses an entropy-like method to define the uncertainty of each task and infers the truth by majority voting. The task with the highest uncertainty is the next one to be assigned to the worker;
- CDAS [6]: It provides an estimated accuracy for each result from workers based on the workers’ historical performances. Each task we are already confident in is terminated and no longer assigned to workers. At each step, CDAS selects at random a non-terminated task to assign to the incoming worker;
- ARE [14]: This method selects one expert for each task based on the professional domain and proficiency of workers’ knowledge. In this model, experts accept tasks equal to or lower than their proficiency;
- MDC [15]: This method considers the domain factors of tasks and workers to aggregate better results in the truth discovery stage. Calculate the truth, and update the worker’s domain credibility by the proportion of the task in each domain, the worker’s answer, and domain credibility;
- SWWC-NoCopier: This is a variant of our method SWWC, but it assumes all workers are independent.
- MAE: This quantifies the average error between the estimated truth and the ground truth. The lower the MAE, the better the estimated truth. The formula is as follows:
- RMSE: This can well measure the deviation between the estimated value and the ground truth. The lower the RMSE, the better the estimated truth. The formula is as follows:
7.2. Comparative Study on Two Real-World Datasets
7.3. Comparative Study on One Synthetic Dataset
7.4. Validation of Worker Domain Expertise and Initialization Algorithm
7.4.1. Diverse Accuracies across Domains
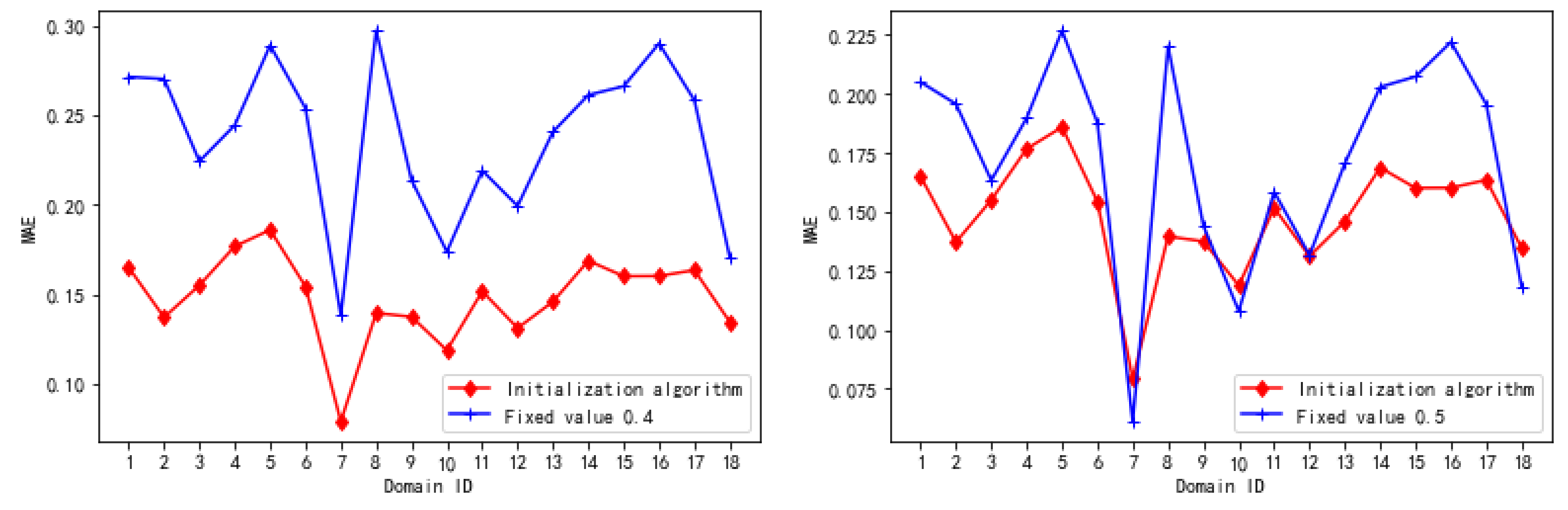
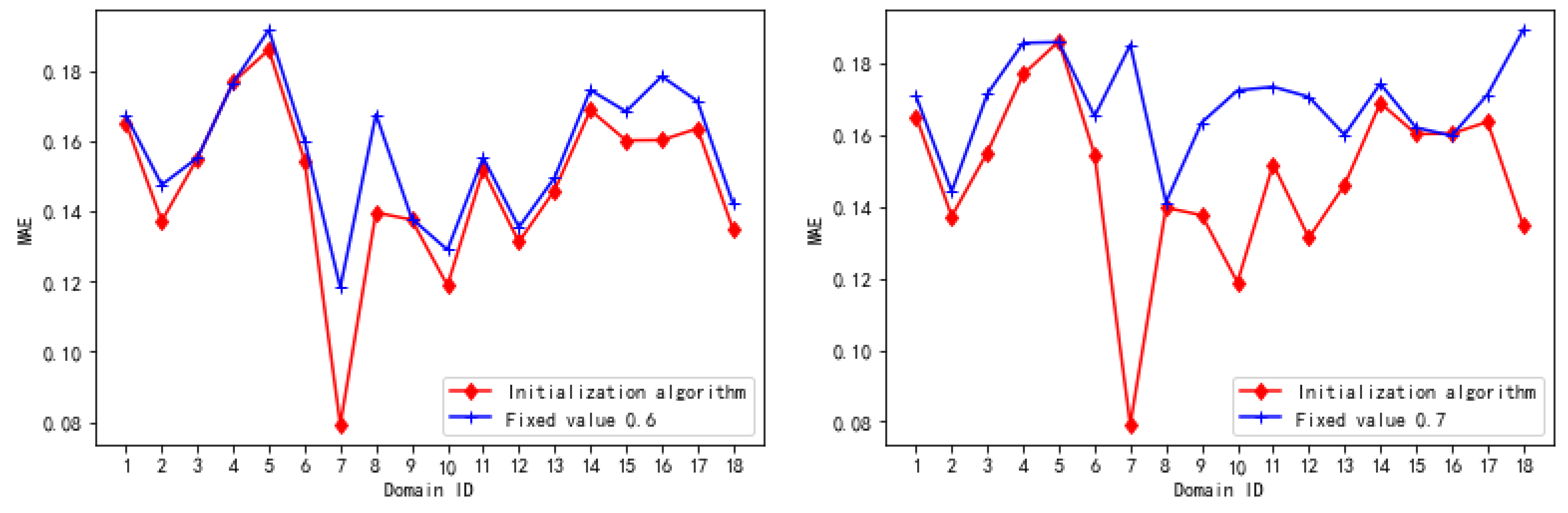
7.4.2. Initialization Algorithm
8. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Eickhoff, C. Cognitive Biases in Crowdsourcing. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Los Angeles, CA, USA, 5–9 February 2018; pp. 162–170. [Google Scholar]
- Saito, S.; Kobayashi, T.; Nakano, T. Towards a Framework for Collaborative Video Surveillance System Using Crowdsourcing. In Proceedings of the 19th ACM Conference on Computer Supported Cooperative Work and Social Computing Companion, San Francisco, CA, USA, 27 February–2 March 2016; pp. 393–396. [Google Scholar]
- Fan, J.; Lu, M.; Ooi, B.C.; Tan, W.; Zhang, M. A hybrid machine-crowdsourcing system for matching web tables. In Proceedings of the 2014 IEEE 30th International Conference on Data Engineering, Chicago, IL, USA, 31 March–4 April 2014; pp. 976–987. [Google Scholar]
- Tan, J.T.C.; Hagiwara, Y.; Inamura, T. Learning from Human Collaborative Experience: Robot Learning via Crowdsourcing of Human-Robot Interaction. In Proceedings of the Companion of the 2017 ACM/IEEE International Conference on Human-Robot Interaction, Vienna, Austria, 6–9 March 2017; pp. 297–298. [Google Scholar]
- Wang, J.; Kraska, T.; Franklin, M.J.; Feng, J. CrowdER: Crowdsourcing Entity Resolution. Proc. VLDB Endow. 2012, 5, 1483–1494. [Google Scholar] [CrossRef]
- Liu, X.; Lu, M.; Ooi, B.C.; Shen, Y.; Wu, S.; Zhang, M. CDAS: A Crowdsourcing Data Analytics System. Proc. VLDB Endow. 2012, 5, 1040–1051. [Google Scholar] [CrossRef]
- Dawid, A.P.; Skene, A.M. Maximum likelihood estimation of observer error-rates using the em algorithm. Appl. Stat. 1979, 28, 20–28. [Google Scholar] [CrossRef]
- Xu, L.; Hao, X.; Lane, N.D.; Liu, X.; Moscibroda, T. More with Less: Lowering User Burden in Mobile Crowdsourcing through Compressive Sensing. In Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Osaka, Japan, 7–11 September 2015; pp. 659–670. [Google Scholar]
- Kae-Nune, N.; Pesseguier, S. Qualification and Testing Process to Implement Anti-Counterfeiting Technologies into IC Packages. In Proceedings of the 2013 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 18–22 March 2013; pp. 1131–1136. [Google Scholar]
- Demartini, G.; Difallah, D.E.; Cudré-Mauroux, P. ZenCrowd: Leveraging probabilistic reasoning and crowdsourcing techniques for large-scale entity linking. In Proceedings of the 21st International Conference on World Wide Web, Lyon, France, 16–20 April 2012; pp. 469–478. [Google Scholar]
- Franklin, M.J.; Kossmann, D.; Kraska, T.; Ramesh, S.; Xin, R. CrowdDB: Answering queries with crowdsourcing. In Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data, Athens, Greece, 12–16 June 2011; pp. 61–72. [Google Scholar]
- Zheng, Y.; Cheng, R.; Maniu, S.; Mo, L. On Optimality of Jury Selection in Crowdsourcing. In Proceedings of the 18th International Conference on Extending Database Technology, Brussels, Belgium, 23–27 March 2015; pp. 193–204. [Google Scholar]
- Zheng, Y.; Wang, J.; Li, G.; Cheng, R.; Feng, J. QASCA: A Quality-Aware Task Assignment System for Crowdsourcing Applications. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, Victoria, Australia, 31 May–4 June 2015; pp. 1031–1046. [Google Scholar]
- Han, F.; Tan, S.; Sun, H.; Srivatsa, M.; Cai, D.; Yan, X. Distributed Representations of Expertise. In Proceedings of the 2016 SIAM International Conference on Data Mining. Society for Industrial and Applied Mathematics, Miami, FL, USA, 5–7 May 2016; pp. 531–539. [Google Scholar]
- Liu, X.; He, H.; Baras, J.S. Crowdsourcing with multi-dimensional trust. In Proceedings of the 2015 18th International Conference on Information Fusion, Washington, DC, USA, 6–9 July 2015; pp. 574–581. [Google Scholar]
- Dong, X.L.; Berti-Équille, L.; Srivastava, D. Truth Discovery and Copying Detection in a Dynamic World. Proc. VLDB Endow. 2009, 2, 562–573. [Google Scholar] [CrossRef]
- Boim, R.; Greenshpan, O.; Milo, T.; Novgorodov, S.; Polyzotis, N.; Tan, W.C. Asking the Right Questions in Crowd Data Sourcing. In Proceedings of the 2012 IEEE 28th International Conference on Data Engineering, Arlington, VA, USA, 1–5 April 2012; pp. 1261–1264. [Google Scholar]
- Chen, X.; Lin, Q.; Zhou, D. Optimistic Knowledge Gradient Policy for Optimal Budget Allocation in Crowdsourcing. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; Volume 28, pp. 64–72. [Google Scholar]
- Khan, A.R.; Garcia-Molina, H. CrowdDQS: Dynamic Question Selection in Crowdsourcing Systems. In Proceedings of the 2017 ACM International Conference on Management of Data, Chicago, CA, USA, 14–19 May 2017; pp. 1447–1462. [Google Scholar]
- Parameswaran, A.G.; Garcia-Molina, H.; Park, H.; Polyzotis, N.; Ramesh, A.; Widom, J. CrowdScreen: Algorithms for filtering data with humans. In Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data, Scottsdale, AZ, USA, 20–24 May 2012; pp. 361–372. [Google Scholar]
- Gao, J.; Liu, X.; Ooi, B.C.; Wang, H.; Chen, G. An online cost sensitive decision-making method in crowdsourcing systems. In Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data, Indianapolis, IN, USA, 6–10 June 2013; pp. 217–228. [Google Scholar]
- Mo, L.; Cheng, R.; Kao, B.; Yang, X.S.; Ren, C.; Lei, S.; Cheung, D.W.; Lo, E. Optimizing plurality for human intelligence tasks. In Proceedings of the 22nd ACM International Conference on Information & Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013; pp. 1929–1938. [Google Scholar]
- Sheng, V.S.; Provost, F.J.; Ipeirotis, P.G. Get another label? Improving data quality and data mining using multiple, noisy labelers. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NA, USA, 24–27 August 2008; pp. 614–622. [Google Scholar]
- Mo, K.; Zhong, E.; Yang, Q. Cross-task crowdsourcing. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, CA, USA, 11–14 August 2013; pp. 677–685. [Google Scholar]
- Qiu, C.; Squicciarini, A.C.; Carminati, B.; Caverlee, J.; Khare, D.R. CrowdSelect: Increasing Accuracy of Crowdsourcing Tasks through Behavior Prediction and User Selection. In Proceedings of the 25th ACM International on Conference on Information and Knowledge Management, Indianapolis, IN, USA, 24–28 October 2016; pp. 539–548. [Google Scholar]
- Dai, P.; Lin, C.H.; Mausam; Weld, D.S. POMDP-based control of workflows for crowdsourcing. Artif. Intell. 2013, 202, 52–85. [Google Scholar] [CrossRef]
- Karger, D.R.; Oh, S.; Shah, D. Iterative Learning for Reliable Crowdsourcing Systems. In Proceedings of the Neural Information Processing Systems, Granada, Spain, 12–15 December 2011; pp. 1953–1961. [Google Scholar]
- Qiu, S.; Gadiraju, U.; Bozzon, A. Improving Worker Engagement Through Conversational Microtask Crowdsourcing. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; pp. 1–12. [Google Scholar]
- Qiu, S.; Gadiraju, U.; Bozzon, A. Just the Right Mood for HIT!—Analyzing the Role of Worker Moods in Conversational Microtask Crowdsourcing; Springer: Berlin/Heidelberg, Germany, 2020; pp. 381–396. [Google Scholar]
- Zhuang, M.; Gadiraju, U. In What Mood Are You Today?: An Analysis of Crowd Workers’ Mood, Performance and Engagement. In Proceedings of the 10th ACM Conference on Web Science, Boston, MA, USA, 30 June–3 July 2019; pp. 373–382. [Google Scholar]
- Mavridis, P.; Huang, O.; Qiu, S.; Gadiraju, U.; Bozzon, A. Chatterbox: Conversational Interfaces for Microtask Crowdsourcing. In Proceedings of the 27th ACM Conference on User Modeling, Adaptation and Personalization, Larnaca, Cyprus, 9–12 June 2019; pp. 243–251. [Google Scholar]
- Qiu, S.; Gadiraju, U.; Bozzon, A. TickTalkTurk: Conversational Crowdsourcing Made Easy. In Proceedings of the Conference Companion Publication of the 2020 on Computer Supported Cooperative Work and Social Computing, Virtual Event, 17–21 October 2020; pp. 53–57. [Google Scholar]
- Shin, S.; Choi, H.; Yi, Y.; Ok, J. Power of Bonus in Pricing for Crowdsourcing. Proc. ACM Meas. Anal. Comput. Syst. 2021, 5, 36:1–36:25. [Google Scholar] [CrossRef]
- Miao, X.; Kang, Y.; Ma, Q.; Liu, K.; Chen, L. Quality-aware Online Task Assignment in Mobile Crowdsourcing. ACM Trans. Sens. Netw. 2020, 16, 30:1–30:21. [Google Scholar] [CrossRef]
- Fang, Y.; Si, L.; Mathur, A.P. Discriminative models of integrating document evidence and document-candidate associations for expert search. In Proceedings of the 33rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Geneva, Switzerland, 19–23 July 2010; pp. 683–690. [Google Scholar]
- Deng, H.; King, I.; Lyu, M.R. Formal Models for Expert Finding on DBLP Bibliography Data. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 163–172. [Google Scholar]
- Serdyukov, P.; Rode, H.; Hiemstra, D. Modeling multi-step relevance propagation for expert finding. In Proceedings of the 17th ACM Conference on Information and Knowledge Management, Napa Valley, CA, USA, 26–30 October 2008; pp. 1133–1142. [Google Scholar]
- Guan, Z.; Yang, S.; Sun, H.; Srivatsa, M.; Yan, X. Fine-Grained Knowledge Sharing in Collaborative Environments. IEEE Trans. Knowl. Data Eng. 2015, 27, 2163–2174. [Google Scholar] [CrossRef]
- Davenport, T.H.; Prusak, L. Working knowledge: How organizations manage what they know. Ubiquity 2000, 2000, 6. [Google Scholar] [CrossRef]
- Mimno, D.M.; McCallum, A. Expertise modeling for matching papers with reviewers. In Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, London, UK, 19–23 August 2007; pp. 500–509. [Google Scholar]
- Rosen-Zvi, M.; Chemudugunta, C.; Griffiths, T.L.; Smyth, P.; Steyvers, M. Learning author-topic models from text corpora. ACM Trans. Inf. Syst. 2010, 28, 4:1–4:38. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Zhao, W.X.; Jiang, J.; Weng, J.; He, J.; Lim, E.; Yan, H.; Li, X. Comparing Twitter and Traditional Media Using Topic Models. In Proceedings of the European Conference on Information Retrieval, Dublin, Ireland, 18–21 April 2011; pp. 338–349. [Google Scholar]
- Zheng, Y.; Li, G.; Cheng, R. DOCS: A Domain-Aware Crowdsourcing System Using Knowledge Bases. Proc. VLDB Endow. 2016, 10, 361–372. [Google Scholar] [CrossRef]
- Goel, G.; Nikzad, A.; Singla, A. Allocating tasks to workers with matching constraints: Truthful mechanisms for crowdsourcing markets. In Proceedings of the 23rd International Conference on World Wide Web, Seoul, Korea, 7–11 April 2014; pp. 279–280. [Google Scholar]
- Han, L.; Maddalena, E.; Checco, A.; Sarasua, C.; Gadiraju, U.; Roitero, K.; Demartini, G. Crowd Worker Strategies in Relevance Judgment Tasks. In Proceedings of the 13th International Conference on Web Search and Data Mining, Houston, TX, USA, 3–7 February 2020; pp. 241–249. [Google Scholar]
- Yin, X.; Han, J.; Yu, P.S. Truth Discovery with Multiple Conflicting Information Providers on the Web. IEEE Trans. Knowl. Data Eng. 2008, 20, 796–808. [Google Scholar]
- Zhao, B.; Rubinstein, B.I.P.; Gemmell, J.; Han, J. A Bayesian Approach to Discovering Truth from Conflicting Sources for Data Integration. Proc. VLDB Endow. 2012, 5, 550–561. [Google Scholar] [CrossRef] [Green Version]
- Pochampally, R.; Sarma, A.D.; Dong, X.L.; Meliou, A.; Srivastava, D. Fusing data with correlations. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data, Snowbird, UT, USA, 22–27 June 2014; pp. 433–444. [Google Scholar]
- Zheng, Y.; Li, G.; Li, Y.; Shan, C.; Cheng, R. Truth Inference in Crowdsourcing: Is the Problem Solved? Proc. VLDB Endow. 2017, 10, 541–552. [Google Scholar] [CrossRef] [Green Version]
- Ma, F.; Li, Y.; Li, Q.; Qiu, M.; Gao, J.; Zhi, S.; Su, L.; Zhao, B.; Ji, H.; Han, J. FaitCrowd: Fine Grained Truth Discovery for Crowdsourced Data Aggregation. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 745–754. [Google Scholar]
- Galland, A.; Abiteboul, S.; Marian, A.; Senellart, P. Corroborating information from disagreeing views. In Proceedings of the Third ACM International Conference on Web Search and Data Mining, New York, NY, USA, 3–6 February 2010; pp. 131–140. [Google Scholar]
- Lin, X.; Chen, L. Domain-Aware Multi-Truth Discovery from Conflicting Sources. Proc. VLDB Endow. 2018, 11, 635–647. [Google Scholar] [CrossRef]
- Miao, C.; Jiang, W.; Su, L.; Li, Y.; Guo, S.; Qin, Z.; Xiao, H.; Gao, J.; Ren, K. Cloud-Enabled Privacy-Preserving Truth Discovery in Crowd Sensing Systems. In Proceedings of the 13th ACM Conference on Embedded Networked Sensor Systems, Seoul, Korea, 1–4 November 2015; pp. 183–196. [Google Scholar]
- Tang, X.; Wang, C.; Yuan, X.; Wang, Q. Non-Interactive Privacy-Preserving Truth Discovery in Crowd Sensing Applications. In Proceedings of the IEEE INFOCOM 2018-IEEE Conference on Computer Communications, Honolulu, HI, USA, 15–19 April 2018; pp. 1988–1996. [Google Scholar]
- Yang, S.; Wu, F.; Tang, S.; Gao, X.; Yang, B.; Chen, G. On Designing Data Quality-Aware Truth Estimation and Surplus Sharing Method for Mobile Crowdsensing. IEEE J. Sel. Areas Commun. 2017, 35, 832–847. [Google Scholar] [CrossRef]
- Xiao, M.; Wu, J.; Zhang, S.; Yu, J. Secret-sharing-based secure user recruitment protocol for mobile crowdsensing. In Proceedings of the INFOCOM 2017-IEEE Conference on Computer Communications, Atlanta, GA, USA, 1–4 May 2017; pp. 1–9. [Google Scholar]
- Jin, H.; Su, L.; Nahrstedt, K. CENTURION: Incentivizing multi-requester mobile crowd sensing. In Proceedings of the IEEE INFOCOM 2017-IEEE Conference on Computer Communications, Atlanta, GA, USA, 1–4 May 2017. [Google Scholar]
- Wang, X.; Sheng, Q.Z.; Fang, X.S.; Yao, L.; Xu, X.; Li, X. An Integrated Bayesian Approach for Effective Multi-Truth Discovery. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, Australia, 19–23 October 2015; pp. 493–502. [Google Scholar]
- Jiang, L.; Niu, X.; Xu, J.; Yang, D.; Xu, L. Incentivizing the Workers for Truth Discovery in Crowdsourcing with Copiers. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems, Dallas, TX, USA, 7–9 July 2019; pp. 1286–1295. [Google Scholar]
- Ho, C.; Vaughan, J.W. Online Task Assignment in Crowdsourcing Markets. In Proceedings of the AAAI Conference on Artificial Intelligence, Toronto, ON, Canada, 22–26 July 2012; pp. 45–51. [Google Scholar]
- Tran-Thanh, L.; Stein, S.; Rogers, A.; Jennings, N.R. Efficient crowdsourcing of unknown experts using bounded multi-armed bandits. Artif. Intell. 2014, 214, 89–111. [Google Scholar] [CrossRef]
- Harper, F.M.; Konstan, J.A. The MovieLens Datasets: History and Context. ACM Trans. Interact. Intell. Syst. 2016, 5, 19:1–19:19. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MovieLens | |||
|---|---|---|---|
| MAE | RMSE | Time (s) | |
| SWWC | 0.3677 | 0.7583 | 1855.29 |
| SWWC-NoCopier | 0.3606 | 0.7222 | 14.07 |
| RandomMV | 0.6914 | 1.0969 | 56.31 |
| D&S | 0.4364 | 0.7942 | 54.74 |
| ASKIT! | 0.7348 | 1.1110 | 1561.88 |
| CDAS | 0.4134 | 0.7801 | 59.66 |
| ARE | 0.8792 | 1.2247 | 69.53 |
| MDC | 0.3851 | 0.7243 | 69.60 |
| Anime (Domain 1) | Anime (Domain 2) | |||||
|---|---|---|---|---|---|---|
| MAE | RMSE | Time (s) | MAE | RMSE | Time (s) | |
| SWWC | 0.3043 | 1.1036 | 3614.597 | 0.3243 | 1.0234 | 3524.965 |
| SWWC-NoCopier | 0.2875 | 1.0368 | 5.611 | 0.3075 | 0.9521 | 5.483 |
| RandomMV | 0.8882 | 1.1077 | 48.123 | 0.6779 | 0.8865 | 52.328 |
| D&S | 0.4850 | 0.6799 | 46.375 | 0.4971 | 0.6459 | 50.762 |
| ASKIT! | 0.7605 | 0.9749 | 1507.95 | 0.7605 | 0.9749 | 1507.95 |
| CDAS | 0.3097 | 1.0935 | 39.32 | 0.3097 | 1.0935 | 39.32 |
| ARE | 1.2089 | 1.6919 | 519.29 | 1.2757 | 1.6080 | 502.35 |
| MDC | 0.3663 | 0.4879 | 489.131 | 0.3662 | 1.1027 | 482.58 |
| 10% Copiers | 20% Copiers | 30% Copiers | ||||
|---|---|---|---|---|---|---|
| MAE | RMSE | MAE | RMSE | MAE | RMSE | |
| SWWC | 0.3677 | 0.7583 | 0.3685 | 0.7583 | 0.3702 | 0.7583 |
| SWWC-NoCopier | 0.5278 | 0.6272 | 1.0189 | 1.0951 | 1.4917 | 1.5435 |
| RandomMV | 0.6611 | 1.0908 | 0.7469 | 1.1896 | 1.6419 | 2.1663 |
| D&S | 0.8970 | 1.0769 | 1.0974 | 1.2058 | 1.1716 | 1.2551 |
| ASKIT | 1.6580 | 2.2113 | 1.5712 | 2.1211 | 1.7439 | 2.2494 |
| CDAS | 0.4631 | 0.7967 | 0.7013 | 0.9290 | 0.9266 | 1.0898 |
| ARE | 1.2088 | 1.6919 | 1.5936 | 2.0176 | 1.9235 | 2.3544 |
| MDC | 0.65 | 0.7598 | 1.1594 | 1.2300 | 1.6219 | 1.6697 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fang, X.; Si, S.; Sun, G.; Sheng, Q.Z.; Wu, W.; Wang, K.; Lv, H. Selecting Workers Wisely for Crowdsourcing When Copiers and Domain Experts Co-exist. Future Internet 2022, 14, 37. https://doi.org/10.3390/fi14020037
Fang X, Si S, Sun G, Sheng QZ, Wu W, Wang K, Lv H. Selecting Workers Wisely for Crowdsourcing When Copiers and Domain Experts Co-exist. Future Internet. 2022; 14(2):37. https://doi.org/10.3390/fi14020037
Chicago/Turabian StyleFang, Xiu, Suxin Si, Guohao Sun, Quan Z. Sheng, Wenjun Wu, Kang Wang, and Hang Lv. 2022. "Selecting Workers Wisely for Crowdsourcing When Copiers and Domain Experts Co-exist" Future Internet 14, no. 2: 37. https://doi.org/10.3390/fi14020037
APA StyleFang, X., Si, S., Sun, G., Sheng, Q. Z., Wu, W., Wang, K., & Lv, H. (2022). Selecting Workers Wisely for Crowdsourcing When Copiers and Domain Experts Co-exist. Future Internet, 14(2), 37. https://doi.org/10.3390/fi14020037