
Investigation of Using CAPTCHA Keystroke Dynamics to Enhance the Prevention of Phishing Attacks



Abstract
:1. Introduction
- −
- Designed and implemented an effective and secure approach to investigate the effectiveness of using CAPTCHA keystroke dynamics in enhancing the prevention of phishing attacks.
- −
- Analysed the existing schemes to design effective CAPTCHA, which helps to take advantage of keystroke dynamics to prevent phishing attacks.
- −
- Significant time features were selected, representing users’ typing behaviour, and measured according to the existing literature. To the best of our knowledge, these features have not been used before in preventing phishing attacks.
- −
- Appropriate similarity threshold was determined to produce excellent results.
- −
- Collected a large number of participants compared with previous works.
- −
- A controlled laboratory experiment was conducted in order to practically evaluate the approach applied.
2. Related Work and Background
3. Proposed Work
4. Methodology
4.1. Definition of Features
- Keystroke duration or hold time: the interval between a key being pressed and released, which may be computed according to the following formula:
- Keystroke latencies (also called press-press or DD time): time taken by the user to press two consecutive keys, which can be calculated with the following formula:
- Di-graph duration: time difference between releasing one key and pressing another, computed with the following formula:
4.2. Extraction of Timing Vectors
4.3. Finding the Distance and Classification Methods
| Algorithm 1: Euclidean distance (ED) |
| 1: begin 2: Compute the different values between two timing vectors. 3: Calculate Square value 4: Sum the values of step 3 5: Take the square root 6: end |
| Algorithm 2: Standard Deviation (SD) |
| 1: begin 2: Compute the mean values for each feature 3: Calculate Square value 4: Sum the value of step 3 5: Divide by 2 6: Take the square root 7: end |
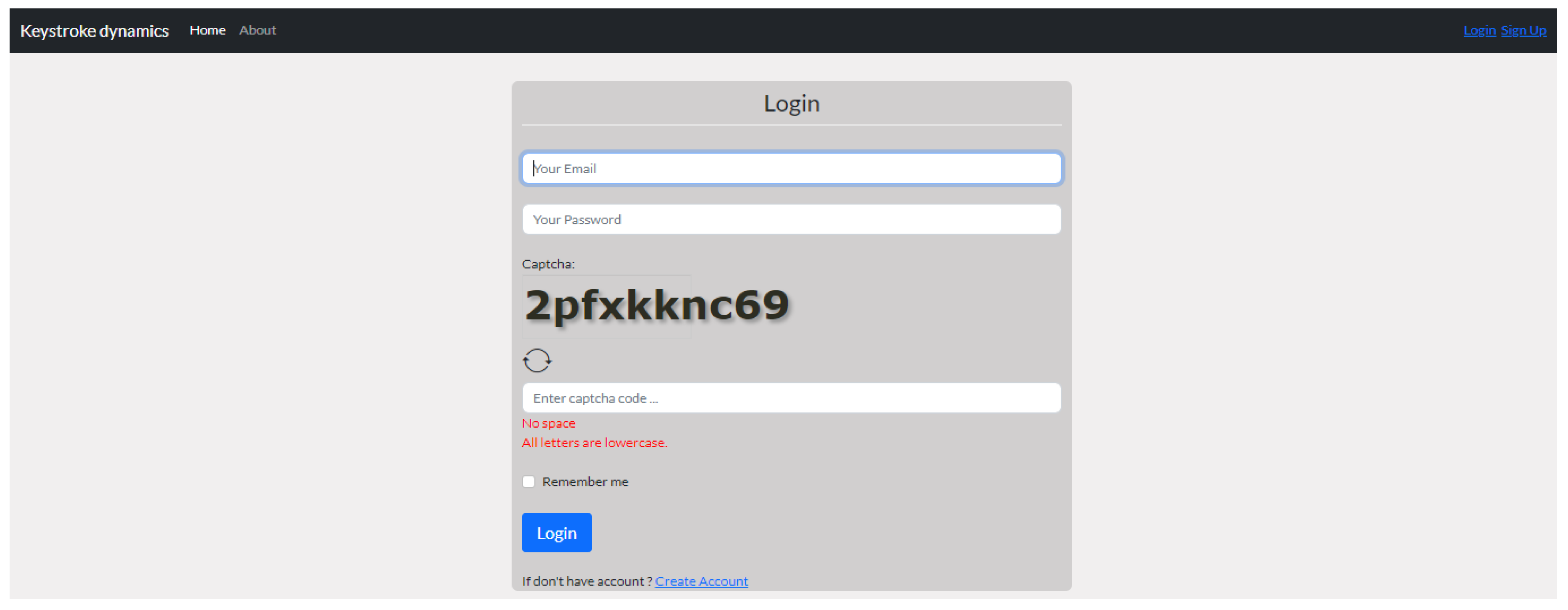
4.4. Typing Text
- Typed Text in the Sign-up (Enrolment) Phase
- Text in the Log-in (Verification) Phase
5. Experimental Evaluation of the Proposed System
5.1. Pilot Experiment
5.2. Main Experiment
5.2.1. Experimental Setup
5.2.2. The Experimental Procedure
6. Evaluation Metrics
7. Results and Discussion
7.1. Time Taken for Each Genuine User to Register in the System
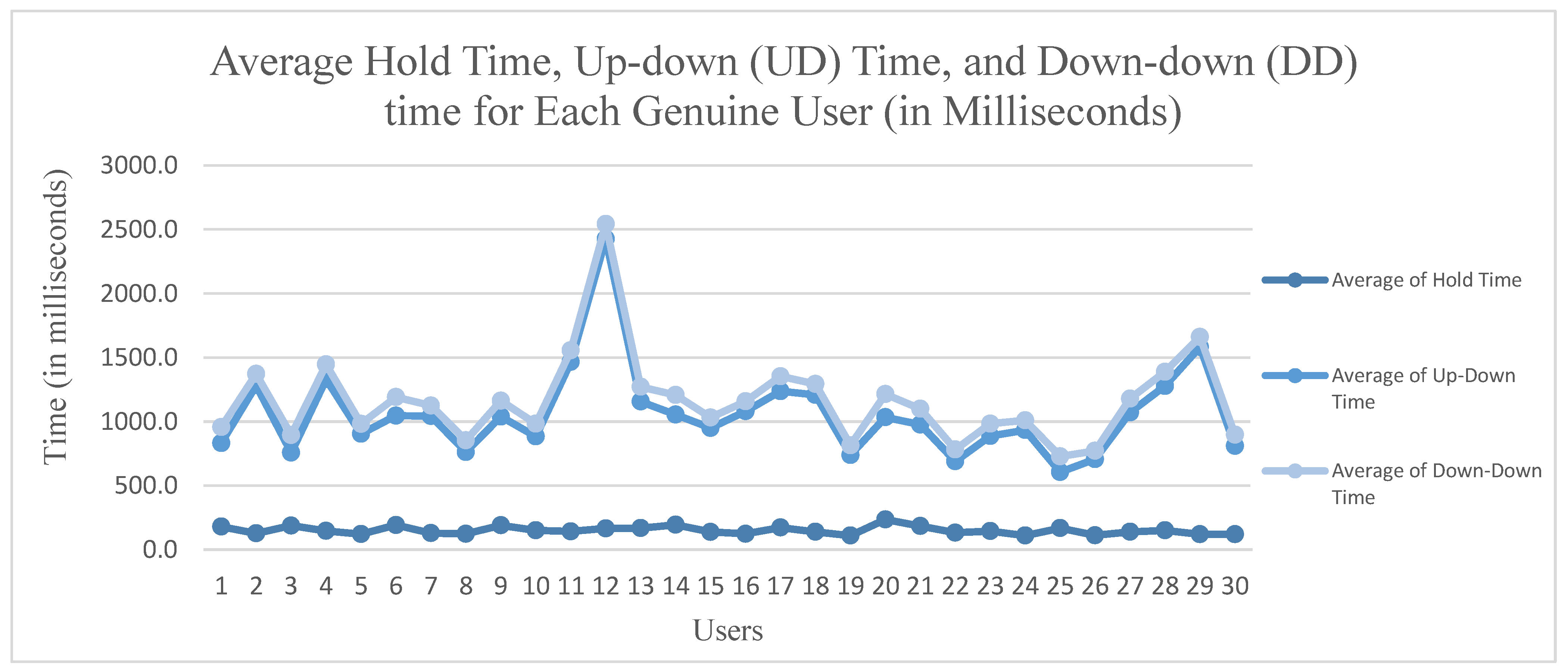
7.2. Results for Average Hold Time, Up-Down (UD) Time, and Down-Down (DD) Time for Each Genuine User
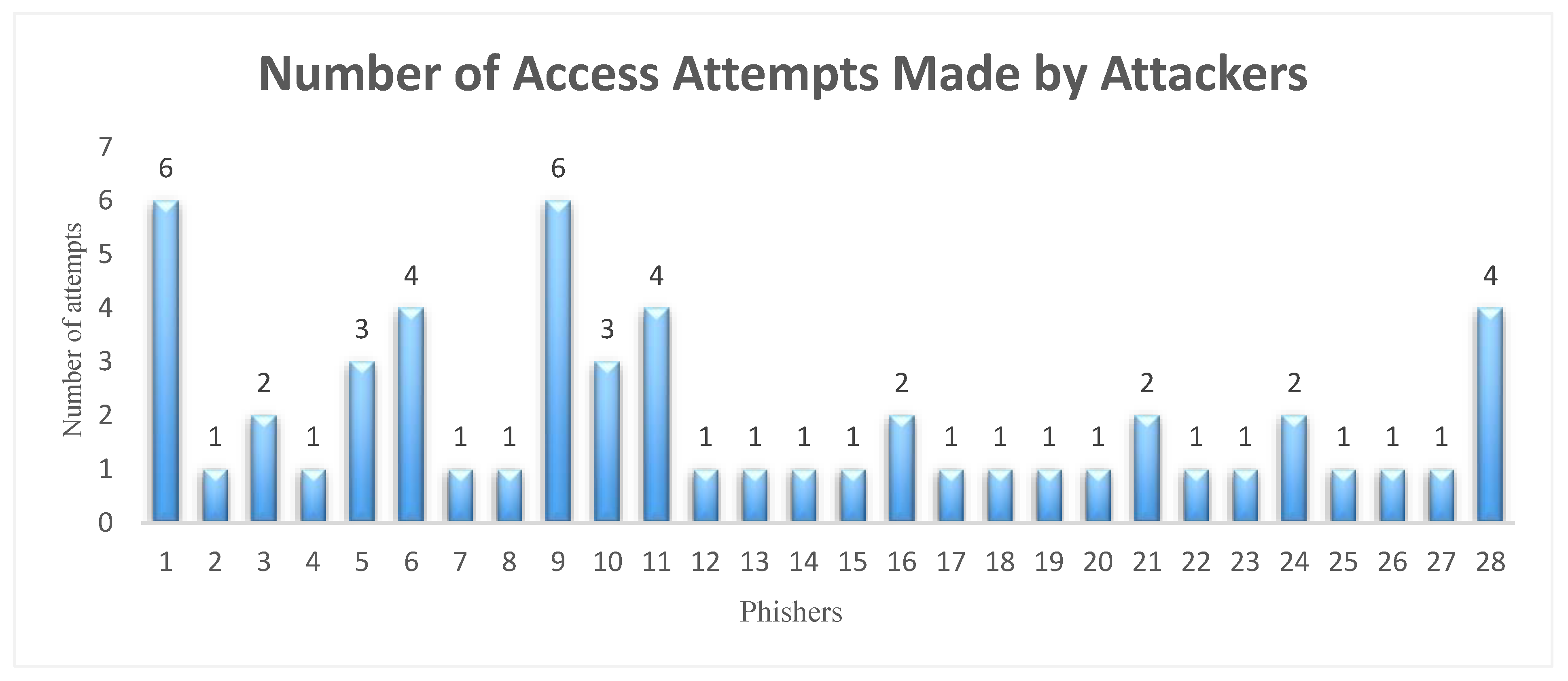
7.3. Number of Attempts Made by Attackers to Gain Unauthorised Access to the System
7.4. Results of Average Hold Time, Up-Down (UD) Time, and Down-Down (DD) Time for Each Phisher
- ▪
- Ease of use is a basic concept referring to the facility of the authentication method adopted in terms of the level of user acceptance and system availability.
- ▪
- Cost-effectiveness refers to an authentication method that provides excellent results without requiring high expenditure.
- ▪
- Observed popularity indicates the percentage popularity of the method used as compared to other types of authentication.
- ▪
- General security refers to an evaluation of the safety provided by the authentication method used.
- ▪
- Brute force: the attackers attempt to try all possible combinations of characters in the hopes to find the username and password.
- −
- If the attacker finds the username and password, they must know the typing rhythm of the user when solving the CAPTCHA.
- ▪
- Shoulder surfing: the attacker observes the typing pattern of the victim when solving the CAPTCHA to try mimicking typing rhythms.
- −
- Although it is possible to mimic a user’s typing pattern in fixed-text systems, it is more difficult in free-text systems because it requires the attacker to observe the victim’s behaviour for the duration of their logged-in session. Therefore, it is quite rare for an attacker to be able to replicate all typing rhythms of users.
- ▪
- Guessing: the attacker tries to guess the correct password by using the most common words that they expect all the users used.
- −
- The attacker needs to obtain the typing pattern of the user to pass the CAPTCHA test.
- ▪
- Dictionary attacks: the attacker attempts to defeat the authentication mechanism by determining the correct password from a large number of possibilities.
- −
- If the attacker finds the correct password, they must know the typing rhythm of the user when solving the CAPTCHA
8. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Basit, A.; Zafar, M.; Liu, X.; Javed, A.R.; Jalil, Z.; Kifayat, K. A comprehensive survey of AI-enabled phishing attacks detection techniques. Telecommun. Syst. 2021, 76, 139–154. [Google Scholar] [CrossRef] [PubMed]
- Uma, M.; Padmavathi, G. A survey on various cyber attacks and their classification. Int. J. Netw. Secur. 2013, 15, 390–396. [Google Scholar]
- Lastdrager, E.E.H. Achieving a consensual definition of phishing based on a systematic review of the literature. Crime Sci. 2014, 3, 1–10. [Google Scholar] [CrossRef]
- Jakobsson, M.; Myers, S. Phishing and Countermeasures: Understanding the Increasing Problem of Electronic Identity Thef; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- APWG. Phishing Activity Trends Report: 3rd Quarter 2021. 2021. Available online: https://docs.apwg.org/reports/apwg_trends_report_q3_2021.pdf?_ga=2.147528119.149518382.1644108193-680326765.1644108193&_gl=1*cr9iea*_ga*NjgwMzI2NzY1LjE2NDQxMDgxOTM.*_ga_55RF0RHXSR*MTY0NDEwODE5My4xLjAuMTY0NDEwODE5My4w (accessed on 23 February 2022).
- Hewage, C. Coronavirus pandemic has unleashed a wave of cyber attacks-here’s how to protect yourself. Conversation 2020, 31. Available online: https://theconversation.com/coronavirus-pandemic-has-unleashed-a-wave-of-cyber-attacks-heres-how-to-protect-yourself-135057 (accessed on 23 February 2022).
- Federal Bureau of Investigation-Internet Crime Complaint Center (IC3). 2020 Internet Crime Report. 2021. Available online: https://www.ic3.gov/Media/PDF/AnnualReport/2020_IC3Report.pdf (accessed on 23 February 2022).
- Kulikova, T.; Shcherbakova, T.; Sidorina, T. Spam and phishing in Q1 2021. Available online: https://securelist.com/spam-and-phishing-in-q1-2021/102018/ (accessed on 23 February 2022).
- Kulikova, T.; Shcherbakova, T.; Sidorina, T. Spam and phishing in 2020. Secur. Kapersky 2021. Available online: https://securelist.com/spam-and-phishing-in-2020/100512/ (accessed on 23 February 2022).
- Ponemon, L. The 2021 Cost of Phishing Study. 2021. Available online: https://www.proofpoint.com/us/resources/analyst-reports/ponemon-cost-of-phishing-study (accessed on 23 February 2022).
- Stanford University IT. University IT Launches Phishing Awareness Service. 2016. Available online: https://uit.stanford.edu/news/university-it-launches-phishing-awareness-service (accessed on 23 February 2022).
- Buza, K. Person identification based on keystroke dynamics: Demo and open challenge. CEUR Workshop Proc. 2016, 1612, 161–168. [Google Scholar]
- Brodić, D.; Amelio, A. The CAPTCHA—Perspectives and Challenges Perspectives and Challenges; Springer Nature: Cham, Switzerland, 2020. [Google Scholar]
- Ahn, L.V.; Blum, M.; Hopper, N.J.; Langford, J. CAPTCHA: Using Hard AI Problems for Security; Lecture Notes in Computer Science; Springer Nature: Berlin/Heidelberg, Germany, 2003; Volume 2656, pp. 294–311. [Google Scholar] [CrossRef] [Green Version]
- Varshney, G.; Misra, M.; Atrey, P.K. A survey and classification of web phishing detection schemes. Secur. Commun. Networks 2016, 9, 6266–6284. [Google Scholar] [CrossRef]
- Masri, R.; Aldwairi, M. Automated Malicious Advertisement Detection using VirusTotal, URLVoid, and TrendMicro. In Proceedings of the 2017 8th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 4–6 April 2017; pp. 336–341. [Google Scholar]
- Jain, A.K.; Gupta, B.B. A novel approach to protect against phishing attacks at client side using auto-updated white-list. EURASIP J. Inf. Secur. 2016, 2016, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Kumar, A.; Gupta, J.B.B. Towards detection of phishing websites on client-side using machine learning based approach. Telecommun. Syst. 2017, 68, 687–700. [Google Scholar] [CrossRef]
- Mao, J.; Li, P.; Li, K.; Wei, T.; Liang, Z. BaitAlarm: Detecting phishing sites using similarity in fundamental visual features. In Proceedings of the 2013 5th International Conference on Intelligent Networking and Collaborative Systems, Xi’an, China, 9–11 September 2013; pp. 790–795. [Google Scholar] [CrossRef]
- Tirfe, D.; Anand, V.K. A survey on trends of two-factor authentication. In Contemporary Issues in Communication, Cloud and Big Data Analytics; Springer: Singapore, 2022; pp. 285–296. [Google Scholar] [CrossRef]
- Khan, A.A. Preventing Phishing Attacks using One Time Password and User Machine Identification. Int. J. Comput. Appl. 2013, 68, 7–11. [Google Scholar]
- Lee, Y.S.; Kim, N.H.; Lim, H.; Jo, H.K.; Lee, H.J. Online Banking Authentication system using Mobile-OTP with QR-code. In Proceedings of the 5th International Conference on Computer Sciences and Convergence Information Technology ICCIT 2010, Seoul, Korea, 30 November–2 December 2010; pp. 644–648. [Google Scholar] [CrossRef]
- Patel, Y.; Diana, M.S.C. Fingerprint authentication technique to prevent phishing using pattern matrix. Int. J. Eng. Res. Dev. 2013, 6, 88–92. [Google Scholar]
- Jepkemboi, C.L. Enhancing Security of Mpesa Transactions by Use of Voice Biometrics. Ph.D. Thesis, United States International University-Africa, Nairobi, Kenya, May 2018. [Google Scholar]
- Hassan, M.A.; Shukur, Z. A secure multi factor user authentication framework for electronic payment system. In Proceedings of the 2021 3rd International Cyber Resilience Conference (CRC) 2021, Langkawi Island, Malaysia, 29–31 January 2021. [Google Scholar] [CrossRef]
- James, D.; Philip, M. A novel anti phishing framework based on visual cryptography. In Proceedings of the 2012 International Conference on Power, Signals, Controls and Computation, Thrissur, India, 3–6 January 2012; pp. 207–218. [Google Scholar]
- Krishnamoorthy, S.K.; Thankappan, S. A novel method to authenticate in website using CAPTCHA-based validation. Secur. Commun. Netw. 2016, 9, 5934–5942. [Google Scholar] [CrossRef]
- Nanglae, N.; Bhattarakosol, P. A study of human bio-detection function under text-based CAPTCHA system. In Proceedings of the 11th IEEE/ACIS International Conference on Computer and Information Science, Shanghai, China, 30 May–1 June 2012; pp. 139–144. [Google Scholar] [CrossRef]
- Costigan, N. The growing pain of phishing: Is biometrics the cure? Biom. Technol. Today 2016, 2016, 8–11. [Google Scholar] [CrossRef]
- Karnan, M.; Akila, M.; Krishnaraj, N. Biometric personal authentication using keystroke dynamics: A review. Appl. Soft Comput. J. 2011, 11, 1565–1573. [Google Scholar] [CrossRef]
- Alsultan, A.; Warwick, K. User-friendly free-text keystroke dynamics authentication for practical applications. In Proceedings of the 2013 IEEE International Conference on Systems, Man, and Cybernetics, SMC 2013, Washington, DC, USA, 13–16 October 2013; pp. 4658–4663. [Google Scholar] [CrossRef]
- Alsultan, A.; Warwick, K.; Wei, H. Free-text keystroke dynamics authentication for Arabic language. IET Biom. 2016, 5, 164–169. [Google Scholar] [CrossRef] [Green Version]
- Alsuhibany, S.A.; Almushyti, M.; Alghasham, N.; Alkhudier, F. Analysis of free-Text keystroke dynamics for Arabic language using Euclidean distance. In Proceedings of the 2016 12th International Conference on Innovations in Information Technology, IIT 2016, Al-Ain, United Arab Emirates, 28–30 November 2016; pp. 185–190. [Google Scholar] [CrossRef]
- Garrett, P.B. Linear algebra I: Dimension. In Number Theory, Trace Formulas and Discrete Groups; Academic Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Rouaud, M. Probability, Statistics and Estimation: Propagation of Uncertainties, p.191. 865 Creative Commons. 2013. Available online: http://www.incertitudes.fr/book.pdf (accessed on 23 February 2022).
- Alsuhibany, S.A. Optimising CAPTCHA generation. In Proceedings of the 2011 Sixth International Conference on Availability, Reliability and Security, Washingot, DC, USA, 22–26 August 2011. [Google Scholar] [CrossRef]
- Bursztein, E.; Moscicki, A.; Fabry, C.; Bethard, S.; Mitchell, J.C.; Jurafsky, D. Easy does it: More usable CAPTCHAs. In Proceedings of the Conference on Human Factors in Computing Systems-Proceedings, Toronto, CA, USA, 26 April–1 May 2014; pp. 2637–2646. [Google Scholar] [CrossRef]
- Alsultan, A.; Warwick, K. Keystroke Dynamics Authentication: A Survey of Free-text Methods. Int. J. Comput. Sci. 2013, 10, 1–10. Available online: http://citeseerx.ist.psu.edu/viewdoc/download;jsessionid=6B582DD715E9CD8F474394CED80C2A56?doi=10.1.1.412.2833&rep=rep1&type=pdf%5Cnhttp://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.412.2833 (accessed on 23 February 2022).
- Killourhy, K.S.; Maxion, R.A. Comparing anomaly-detection algorithms for keystroke dynamics. In Proceedings of the International Conference on Dependable Systems and Networks (DSN), Lisbon, Portugal, 29 June 2009; pp. 125–134. [Google Scholar] [CrossRef] [Green Version]
- Alsuhibany, S.A.; Alreshoodi, L.A. Detecting human attacks on text-based CAPTCHAs using the keystroke dynamic approach. IET Inf. Secur. 2021, 15, 191–204. [Google Scholar] [CrossRef]
- Alsultan, A.; Warwick, K.; Wei, H. Improving the performance of free-text keystroke dynamics authentication by fusion. In Proceedings of the 2009 IEEE/IFIP International Conference on Dependable Systems & Networks, Lisbon, Portugal, 29 June–2 July 2009; pp. 1024–1033. [Google Scholar]
- Idrus, S.Z.S.; Cherrier, E.; Rosenberger, C.; Schwartzmann, J.J. A Review on Authentication Methods. Aust. J. Basic Appl. Sci. 2013, 7, 95–107. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Contribution | Results |
|---|---|---|
| [24] | Proposed a multi-factor authentication scheme using voice traits as behavioural biometrics to protect a mobile banking system (Mpesa) in Kenya. | The results demonstrated that voice biometrics have numerous potential advantages and benefits in terms of reducing risk for mobile financial systems. |
| [33] | Introduced a new approach involving free-text keystroke dynamics authentication to provide a high degree of usability and security. Arabic and English language typing text was used to compare the performance of Arabic input with another input. Keystroke duration, di-graph duration, and latency were combined as a feature to distinguish between samples of authenticated users and impostors. | The results showed that the proposed approach achieved excellent results with FAR = 0.2 and FRR = 0.0. |
| Current work | Investigate the effectiveness of using CAPTCHA keystroke dynamics in enhancing the prevention of phishing attacks. | The results are promising in terms of providing a practical and cost-effective solution to prevent phishing attacks. |
| Components | Description |
|---|---|
| Participants | 75 |
| Genuine group | 30 |
| Phishing group | 45 |
| Gender | Female |
| User’s profession | Students at Qassim University |
| Age range | Between 19 and 27 years |
| Language | Python |
| Recording of typing rhythms | JavaScript |
| Timing function | Date.getTime() |
| Keyboard | QWERTY (laptop) |
| Acquisition platform | Windows |
| Controlled environment | Yes |
| Typing text | English language free text |
| Training sample | 7 samples |
| Testing sample | One-time sample |
| IP Address | Successful Attempts | Failed Attempts | Number of Similar Profiles | Time Consumed (In Minutes) |
|---|---|---|---|---|
| 192.168.0.1 | 0 | 6 | 4 | Most users did not exceed two minutes |
| 192.168.0.2 | 2 | |||
| 192.168.0.3 | 0 | |||
| 192.168.0.4 | 0 | |||
| 192.168.0.5 | 1 |
| ID | IP Address |
|---|---|
| 1 | 192.168.0.1 |
| 2 | 192.168.0.2 |
| 3 | 192.168.0.3 |
| 4 | 192.168.0.4 |
| 5 | 192.168.0.5 |
| 6 | 192.168.0.6 |
| 9 | 192.168.0.9 |
| 11 | 192.168.0.11 |
| 12 | 192.168.0.12 |
| 15 | 192.168.0.15 |
| 18 | 192.168.0.18 |
| 32 | 192.168.0.32 |
| 34 | 192.168.0.34 |
| 35 | 192.168.0.35 |
| 38 | 192.168.0.38 |
| 40 | 192.168.0.40 |
| 41 | 192.168.0.41 |
| Approach | TPR | TNR | FPR | FNR | Accuracy |
|---|---|---|---|---|---|
| The proposed approach | 82.2% | 100% | 0% | 17.8% | 85% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alamri, E.K.; Alnajim, A.M.; Alsuhibany, S.A. Investigation of Using CAPTCHA Keystroke Dynamics to Enhance the Prevention of Phishing Attacks. Future Internet 2022, 14, 82. https://doi.org/10.3390/fi14030082
Alamri EK, Alnajim AM, Alsuhibany SA. Investigation of Using CAPTCHA Keystroke Dynamics to Enhance the Prevention of Phishing Attacks. Future Internet. 2022; 14(3):82. https://doi.org/10.3390/fi14030082
Chicago/Turabian StyleAlamri, Emtethal K., Abdullah M. Alnajim, and Suliman A. Alsuhibany. 2022. "Investigation of Using CAPTCHA Keystroke Dynamics to Enhance the Prevention of Phishing Attacks" Future Internet 14, no. 3: 82. https://doi.org/10.3390/fi14030082
APA StyleAlamri, E. K., Alnajim, A. M., & Alsuhibany, S. A. (2022). Investigation of Using CAPTCHA Keystroke Dynamics to Enhance the Prevention of Phishing Attacks. Future Internet, 14(3), 82. https://doi.org/10.3390/fi14030082