
A Density-Based Random Forest for Imbalanced Data Classification


Abstract
:
1. Introduction
- (1)
- We used a method to identify the boundary minority samples and remove noise minority samples. The method determines whether a minority sample is a boundary minority sample or a noise sample based on the number of majority samples in its nearest neighbor samples;
- (2)
- We applied a density-based method to identify the boundary samples by boundary minority samples. The density-based method identifies the class boundary samples by taking into account the density of objects in space, as is done when solving the clustering problem with the DBSCAN algorithm;
- (3)
- A density-based random forest (DBRF) is proposed to deal with the imbalanced data problem. There are two types of classifiers in DBRF. One is built from the original dataset, and the other is constructed with boundary class samples identified by the density method, including minority class samples;
- (4)
- The performance of DBRF was evaluated based on the public binary-class-imbalanced datasets. We also compared DBRF with other common algorithms.
2. Related Work
2.1. Data-Level Imbalanced Data Processing
2.2. Algorithm-Level Methods for Imbalanced Data
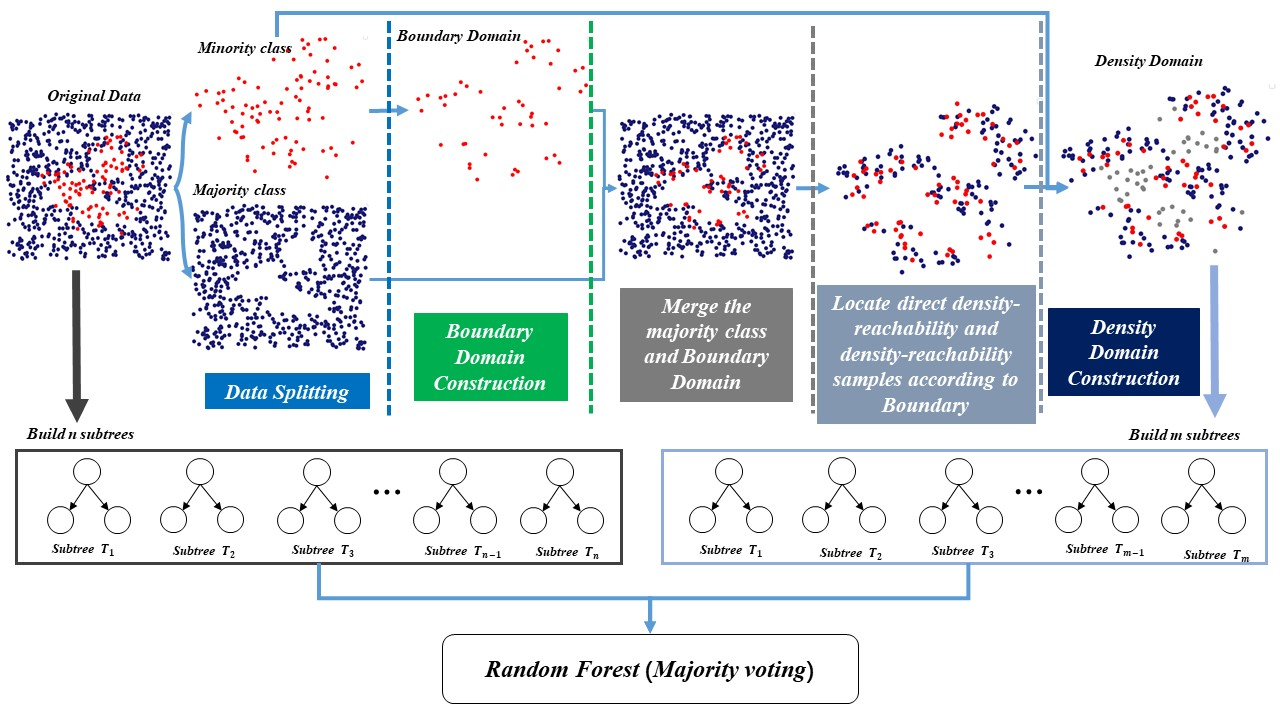
3. Methods
3.1. Definition
3.1.1. Boundary Domain
3.1.2. Direct Density-Reachability and Density-Reachability
- -
- Direct density-reachability: If , and , then sample is directly-reachable by the density of , where , . Here, represents the set of majority class samples, represents the distance between samples and , represents the maximum distance that can reach, represents a set of majority samples whose distance from sample is less than or equal to , and represents the total number of sets. represents the minimum number of sets whose distances between the samples in the set and sample are less than or equal to ;
- -
- Density-reachability: For samples and , if there are sample sequences where , , and is directly density-reachable by , then it is said that is density-reachable by .
3.1.3. Density Domain
3.2. DBRF Algorithm
| Algorithm 1Density-based random forest (DBRF). |
|
| Algorithm 2Data splitting. |
|
| Algorithm 3Boundary domain construction. |
|
| Algorithm 4Density domain construction. |
|
4. Experimental Setup and Results’ Analysis
4.1. Experimental Dataset
4.2. Algorithm Evaluation Indicators
4.3. Experimental Results and Analysis
4.3.1. Parameter Setting on and p
4.3.2. Performance on Public Imbalanced Datasets
5. Discussion
- (1)
- Parameter setting problem. DBRF has two parameters, and p. Figure 4, Figure 5 and Figure 6 show that different parameters need to be set for different datasets. If is too large, the density domain will have all samples in the dataset. This results in the failure of DBRF to classify the minority class. Choosing which parameters to use to train the model requires some tuning experience;
- (2)
- Questions about datasets. For this question, there are two main problems: (a) Time-consuming problem. DBRF can effectively train large datasets, but it takes much time in the training process. Metal glass is a dataset with 98 features and 5936 samples. It is the largest of the 34 datasets. According to the experimental results in Table 2, DBRF took more time to train on it than other algorithms. Therefore, for large datasets with high-dimensional features, the training time of DBRF will obviously become long; (b) The number of minority class samples problem. DBRF will be ineffective if the dataset has few minority class samples. Owing to the excessively scattered distribution of minority class samples, they will be deleted as noise samples when DBRF constructs the boundary domain. This will lead to an inability to build the density domain. Our proposed method will not work;
- (3)
- The problem of unclear decision boundaries between minority classes. DBRF cannot solve this problem. DBRF can just deal with the problem of the unclear decision boundary between majority samples and minority samples. This is because DBRF takes one class from the minority class group separately as the only minority class for density domain construction.
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, J.; Cao, P.; Gross, D.P.; Zaiane, O.R. On the application of multi-class classification in physical therapy recommendation. Health Sci. Syst. 2013, 1, 15. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Zhang, H.; Zhang, X.; Qi, D. Deep learning intrusion detection model based on optimized imbalanced network data. In Proceedings of the 2018 IEEE 18th International Conference on Communication Technology (ICCT), Chongqing, China, 8–11 October 2018. [Google Scholar]
- Bian, Y.; Cheng, M.; Yang, C.; Yuan, Y.; Li, Q.; Zhao, J.L.; Liang, L. Financial fraud detection: A new ensemble learning approach for imbalanced data. In Proceedings of the 20th Pacific Asia Conference on Information Systems (PACIS 2016), Chiayi, Taiwan, 27 June–1 July 2016; p. 315. [Google Scholar]
- Plant, C.; Böhm, C.; Tilg, B.; Baumgartner, C. Enhancing instance-based classification with local density: A new algorithm for classifying unbalanced biomedical data. Bioinformatics 2006, 22, 981–988. [Google Scholar] [CrossRef] [Green Version]
- Yap, B.W.; Rani, K.A.; Rahman, H.A.A.; Fong, S.; Khairudin, Z.; Abdullah, N.N. An application of oversampling, undersampling, bagging and boosting in handling imbalanced datasets. In Proceedings of the First International Conference on Advanced Data and Information Engineering (DaEng-2013), Kuala Lumpur, Malaysia, 16–18 December 2013; Springer: Berlin/Heidelberg, Germany, 2014; pp. 13–22. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. Smote: Synthetic minority over-sampling technique. J. Artif. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Bunkhumpornpat, C.; Sinapiromsaran, K.; Lursinsap, C. Dbsmote: Density-based synthetic minority over-sampling technique. Appl. Intell. 2012, 36, 664–684. [Google Scholar] [CrossRef]
- Ma, L.; Fan, S. Cure-smote algorithm and hybrid algorithm for feature selection and parameter optimization based on random forests. BMC Bioinform. 2017, 18, 169. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gao, M.; Aiqiang, X.U.; Qing, X.U. Fault detection method of electronic equipment based on sl-smote and cs-rvm. Comput. Eng. Appl. 2019, 55, 185–192. [Google Scholar]
- Han, H.; Wang, W.-Y.; Mao, B.-H. Borderline-smote: A new over-sampling method in imbalanced datasets learning. In Proceedings of the International Conference on Intelligent Computing, Hefei, China, 23–26 August 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 878–887. [Google Scholar]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. Adasyn: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, 1–8 June 2008; pp. 322–1328. [Google Scholar]
- Batista, G.E.; Prati, R.C.; Monard, M.C. A study of the behavior of several methods for balancing machine learning training data. ACM Sigkdd Explor. Newsl. 2004, 6, 20–29. [Google Scholar] [CrossRef]
- Tomek, I. Two modifications of cnn. IEEE Trans. Syst. Man Cybern. 1976, SMC-6, 769–772. [Google Scholar]
- Kubat, M.; Matwin, S. Addressing the curse of imbalanced training sets: One-sided selection. Icml 1997, 97, 179–186. [Google Scholar]
- Wilson, D.L. Asymptotic properties of nearest neighbor rules using edited data. IEEE Trans. Syst. Man Cybern. 1972, SMC-2, 408–421. [Google Scholar] [CrossRef] [Green Version]
- Laurikkala, J. Improving identification of difficult small classes by balancing class distribution. In Proceedings of the Conference on Artificial Intelligence in Medicine in Europe, Cascais, Portugal, 1–4 July 2001; Springer: Berlin/Heidelberg, Germany, 2001; pp. 63–66. [Google Scholar]
- Zhou, Z.-H.; Liu, X.-Y. Training cost-sensitive neural networks with methods addressing the class imbalance problem. IEEE Trans. Knowl. Data Eng. 2005, 18, 63–77. [Google Scholar] [CrossRef]
- Zhou, Z.-H. Ensemble Learning: Foundations and Algorithms; Electronic Industry Press: Beijing, China, 2020. [Google Scholar]
- Raskutti, B.; Kowalczyk, A. Extreme re-balancing for svms: A case study. ACM Sigkdd Explor. Newsl. 2004, 6, 60–69. [Google Scholar] [CrossRef]
- Chawla, N.V.; Lazarevic, A.; Hall, L.O.; Bowyer, K.W. Smoteboost: Improving prediction of the minority class in boosting. In Proceedings of the European Conference on Principles of Data Mining and Knowledge Discovery, Antwerp, Belgium, 15–19 September 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 107–119. [Google Scholar]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Ournal Comput. And Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Chen, Z.; Duan, J.; Kang, L.; Qiu, G.-Q. A hybrid data-level ensemble to enable learning from highly imbalanced dataset. Inf. Sci. 2021, 554, 157–176. [Google Scholar] [CrossRef]
- Fan, W.; Stolfo, S.J.; Zhang, J.; Chan, P.K. Adacost: Misclassification cost-sensitive boosting. Icml 1999, 99, 97–105. [Google Scholar]
- Schapire, R.E.; Freund, Y. Boosting: Foundations and algorithms. Kybernetes 2013, 42, 164–166. [Google Scholar] [CrossRef]
- Chen, C.; Breiman, L. Using Random Forest to Learn Imbalanced Data; University of California: Berkeley, CA, USA, 2004. [Google Scholar]
- Choudhary, R.; Shukla, S. A clustering based ensemble of weighted kernelized extreme learning machine for class imbalance learning. Expert Syst. Appl. 2021, 164, 114041. [Google Scholar] [CrossRef]
- Bader-El-Den, M.; Teitei, E.; Perry, T. Biased random forest for dealing with the class imbalance problem. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 2163–2172. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.-S.; Chi, H.; Shao, X.-Y.; Qi, M.-L.; Xu, B.-G. A novel random forest approach for imbalance problem in crime linkage. Knowl.-Based Syst. 2020, 195, 105738. [Google Scholar] [CrossRef]
- Oyewola, D.O.; Dada, E.G.; Misra, S.; Damaeviius, R. Detecting cassava mosaic disease using a deep residual convolutional neural network with distinct block processing. PeerJ Comput. Sci. 2021, 7, E352. [Google Scholar] [CrossRef]
- Hemalatha, J.; Roseline, S.A.; Geetha, S.; Kadry, S.; Damaeviius, R. An Efficient DenseNet-Based Deep Learning Model for Malware Detection. Entropy 2021, 23, 344. [Google Scholar] [CrossRef] [PubMed]
- Alli, O.O.A.; Damaeviius, R.; Misra, S.; Rytis, M.; Alli, A.A. Malignant skin melanoma detection using image augmentation by oversampling in nonlinear lower-dimensional embedding manifold. Turk. J. Electr. Eng. Comput. Sci. 2021, 2021, 2600–2614. [Google Scholar] [CrossRef]
- Nasir, I.M.; Khan, M.A.; Yasmin, M.; Shah, J.H.; Damasevicius, R. Pearson Correlation-Based Feature Selection for Document Classification Using Balanced Training. Sensors 2020, 20, 6793. [Google Scholar] [CrossRef] [PubMed]
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. Kdd 1996, 96, 226–231. [Google Scholar]
- Zhang, L.; Huang, H. Micro machining of bulk metallic glasses: A review. Int. J. Adv. Manuf. Technol. 2018, 100, 637–661. [Google Scholar] [CrossRef]
- Dua, D.; Graff, C. UCI Machine Learning Repository. 2017. Available online: http://archive.ics.uci.edu/ml (accessed on 8 May 2012).
- Alcalá-Fdez, J.; Fernandez, A.; Luengo, J.; Derrac, J.; García, S.; Sánchez, L.; Herrera, F. Keel data-mining software tool: Data set repository, integration of algorithms and experimental analysis framework. Crit. Rev. Solid State Mater. Sci. 2011, 17, 255–287. [Google Scholar]
- Mehdi, J.Z.; Gideon, P.K.; Paulo, B.; Mohsen, S.; John, L.; Cui, F. A critical review on metallic glasses as structural materials for cardiovascular stent applications. J. Funct. Biomater. 2018, 9, 19. [Google Scholar]
- Khan, M.M.; Nemati, A.; Rahman, Z.U.; Shah, U.H.; Asgar, H.; Haider, W. Recent advancements in bulk metallic glasses and their applications: A review. Crit. Rev. Solid State Mater. Sci. 2018, 43, 233–268. [Google Scholar] [CrossRef]
- Nair, B.; Priyadarshini, B.G. Process, structure, property and applications of metallic glasses. AIMS Mater. Sci. 2016, 3, 1022–1053. [Google Scholar] [CrossRef]
- Zhou, Z.-H. Machine Learning; Tsinghua University Press: Beijing, China, 2016. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Name | Sample Size | Feature Number | Majority Class Number | Minority Class Number | Imbalance Ratio | |
|---|---|---|---|---|---|---|
| A | Metal glass | 5936 | 98 | 3708 | 675 | 5.493 |
| Vehicle evaluation | 1728 | 6 | 1210 | 518 | 2.3359 | |
| Haberman survival | 306 | 4 | 225 | 81 | 2.7778 | |
| B | glasses0 | 214 | 9 | 144 | 70 | 2.06 |
| glasses1 | 214 | 9 | 138 | 76 | 1.82 | |
| glasses5 | 214 | 9 | 205 | 9 | 22.81 | |
| Ecoli1 | 336 | 7 | 259 | 77 | 3.36 | |
| Ecoli2 | 336 | 7 | 284 | 52 | 5.46 | |
| Ecoli3 | 336 | 7 | 301 | 35 | 8.19 | |
| Ecoli0-1 | 244 | 7 | 220 | 24 | 9.17 | |
| car-good | 1728 | 6 | 1659 | 69 | 24 | |
| car-vgood | 1728 | 6 | 1663 | 65 | 25.58 | |
| cleveland | 173 | 13 | 160 | 13 | 12,62 | |
| dermatology | 358 | 34 | 338 | 20 | 16.9 | |
| page-blocks0 | 5472 | 10 | 4913 | 559 | 8.77 | |
| Vehicle0 | 846 | 18 | 647 | 199 | 3.23 | |
| Vehicle1 | 846 | 18 | 629 | 217 | 2.52 | |
| Vehicle2 | 846 | 18 | 628 | 218 | 2.52 | |
| Vehicle3 | 846 | 18 | 634 | 212 | 2.52 | |
| Wisconsin | 683 | 9 | 444 | 239 | 1.86 | |
| Yeast1 | 1484 | 8 | 1055 | 429 | 2.46 | |
| Connectionist Bench | 990 | 13 | 900 | 90 | 10 | |
| C | Clover0 | 800 | 2 | 700 | 100 | 7 |
| Clover30 | 800 | 2 | 700 | 100 | 7 | |
| Clover50 | 800 | 2 | 700 | 100 | 7 | |
| Clover70 | 800 | 2 | 700 | 100 | 7 | |
| Subclus0 | 800 | 2 | 700 | 100 | 7 | |
| Subclus30 | 800 | 2 | 700 | 100 | 7 | |
| Subclus50 | 800 | 2 | 700 | 100 | 7 | |
| Subclus70 | 800 | 2 | 700 | 100 | 7 | |
| Paw0 | 800 | 2 | 700 | 100 | 7 | |
| Paw30 | 800 | 2 | 700 | 100 | 7 | |
| Paw50 | 800 | 2 | 700 | 100 | 7 | |
| Paw70 | 800 | 2 | 700 | 100 | 7 |
| Predict | |||
|---|---|---|---|
| Minority Class | Majority Class | ||
| Actual | Minority class | TP | FN |
| Majority class | FP | TN | |
| Dataset | RF | DBRF | SMOTE + RF | b-SMOTE + RF | ADASYN + RF | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | GM | F1 | GM | F1 | GM | F1 | GM | F1 | GM | ||
| A | metal glass | 0.889 ± 0.01 | 0.871 ± 0.02 | 0.894 ± 0.01 | 0.892 ± 0.02 | 0.858 ± 0.01 | 0.879 ± 0.01 | 0.857 ± 0.02 | 0.877 ± 0.01 | 0.838 ± 0.01 | 0.879 ± 0.02 |
| vehicle evaluation | 0.824 ± 0.03 | 0.826 ± 0.03 | 0.875 ± 0.02 | 0.910 ± 0.02 | 0.862 ± 0.03 | 0.887 ± 0.03 | 0.865 ± 0.03 | 0.890 ± 0.03 | 0.865 ± 0.02 | 0.895 ± 0.02 | |
| Haberman’s survival | 0.541 ± 0.08 | 0.435 ± 0.17 | 0.603 ± 0.08 | 0.615 ± 0.07 | 0.533 ± 0.07 | 0.526 ± 0.08 | 0.524 ± 0.07 | 0.512 ± 0.1 | 0.551 ± 0.09 | 0.558 ± 0.11 | |
| B | glasses0 | 0.830 ± 0.11 | 0.812 ± 0.14 | 0.858 ± 0.1 | 0.854 ± 0.11 | 0.835 ± 0.1 | 0.838 ± 0.11 | 0.823 ± 0.1 | 0.833 ± 0.1 | 0.831 ± 0.1 | 0.850 ± 0.09 |
| glasses1 | 0.839 ± 0.08 | 0.825 ± 0.09 | 0.818 ± 0.09 | 0.819 ± 0.09 | 0.821 ± 0.06 | 0.819 ± 0.07 | 0.848 ± 0.07 | 0.845 ± 0.08 | 0.845 ± 0.08 | 0.850 ± 0.08 | |
| glasses5 | 0.651 ± 0.22 | 0.340 ± 0.45 | 0.737 ± 0.26 | 0.497 ± 0.52 | 0.693 ± 0.22 | 0.421 ± 0.46 | 0.692 ± 0.22 | 0.421 ± 0.46 | 0.693 ± 0.22 | 0.426 ± 0.47 | |
| Ecoli1 | 0.843 ± 0.07 | 0.844 ± 0.10 | 0.870 ± 0.05 | 0.910 ± 0.05 | 0.862 ± 0.07 | 0.889 ± 0.06 | 0.869 ± 0.06 | 0.901 ± 0.06 | 0.849 ± 0.06 | 0.853 ± 0.08 | |
| Ecoli2 | 0.874 ± 0.08 | 0.826 ± 0.12 | 0.891 ± 0.09 | 0.891 ± 0.12 | 0.878 ± 0.09 | 0.863 ± 0.12 | 0.868 ± 0.09 | 0.833 ± 0.11 | 0.839 ± 0.08 | 0.844 ± 0.12 | |
| Ecoli3 | 0.745 ± 0.17 | 0.593 ± 0.34 | 0.805 ± 0.14 | 0.808 ± 0.28 | 0.803 ± 0.14 | 0.801 ± 0.28 | 0.765 ± 0.17 | 0.623 ± 0.34 | 0.763 ± 0.12 | 0.793 ± 0.29 | |
| Ecoli0-1 | 0.816 ± 0.13 | 0.775 ± 0.28 | 0.853 ± 0.15 | 0.783 ± 0.29 | 0.837 ± 0.14 | 0.824 ± 0.29 | 0.827 ± 0.14 | 0.809 ± 0.29 | 0.829 ± 0.14 | 0.822 ± 0.29 | |
| car-good | 0.921 ± 0.06 | 0.861 ± 0.09 | 0.946 ± 0.04 | 0.903 ± 0.07 | 0.910 ± 0.04 | 0.991 ± 0 | 0.927 ± 0.04 | 0.993 ± 0 | 0.917 ± 0.03 | 0.992 ± 0 | |
| car-vgood | 0.966 ± 0.04 | 0.94 ± 0.07 | 0.974 ± 0.03 | 0.970 ± 0.04 | 0.949 ± 0.05 | 0.996 ± 0.01 | 0.948 ± 0.06 | 0.996 ± 0.01 | 0.963 ± 0.05 | 0.997 ± 0 | |
| cleveland | 0.565 ± 0.18 | 0.171 ± 0.35 | 0.749 ± 0.22 | 0.523 ± 0.44 | 0.697 ± 0.21 | 0.423 ± 0.43 | 0.697 ± 0.21 | 0.423 ± 0.43 | 0.628 ± 0.18 | 0.299 ± 0.38 | |
| dermatology | 0.550 ± 0.14 | 0.141 ± 0.3 | 0.724 ± 0.18 | 0.608 ± 0.43 | 0.749 ± 0.23 | 0.523 ± 0.46 | 0.731 ± 0.22 | 0.520 ± 0.46 | 0.739 ± 0.23 | 0.521 ± 0.46 | |
| page-blocks0 | 0.936 ± 0.02 | 0.930 ± 0.02 | 0.932 ± 0.02 | 0.939 ± 0.02 | 0.927 ± 0.02 | 0.956 ± 0.02 | 0.925 ± 0.02 | 0.957 ± 0.02 | 0.910 ± 0.02 | 0.960 ± 0.01 | |
| Vehicle0 | 0.965 ± 0.02 | 0.966 ± 0.02 | 0.961 ± 0.02 | 0.960 ± 0.02 | 0.945 ± 0.03 | 0.962 ± 0.03 | 0.950 ± 0.02 | 0.965 ± 0.03 | 0.950 ± 0.02 | 0.969 ± 0.02 | |
| Vehicle1 | 0.704 ± 0.05 | 0.661 ± 0.06 | 0.721 ± 0.03 | 0.736 ± 0.04 | 0.743 ± 0.03 | 0.773 ± 0.04 | 0.743 ± 0.03 | 0.775 ± 0.04 | 0.760 ± 0.03 | 0.796 ± 0.03 | |
| Vehicle2 | 0.982 ± 0.02 | 0.977 ± 0.03 | 0.980 ± 0.02 | 0.976 ± 0.03 | 0.982 ± 0.01 | 0.984 ± 0.02 | 0.983 ± 0.01 | 0.985 ± 0.01 | 0.983 ± 0.01 | 0.984 ± 0.02 | |
| Vehicle3 | 0.684 ± 0.08 | 0.609 ± 0.11 | 0.723 ± 0.05 | 0.749 ± 0.07 | 0.672 ± 0.06 | 0.621 ± 0.09 | 0.716 ± 0.05 | 0.737 ± 0.06 | 0.719 ± 0.05 | 0.749 ± 0.07 | |
| Wisconsin | 0.971 ± 0.02 | 0.973 ± 0.02 | 0.972 ± 0.02 | 0.978 ± 0.02 | 0.966 ± 0.02 | 0.970 ± 0.02 | 0.963 ± 0.02 | 0.969 ± 0.02 | 0.966 ± 0.02 | 0.972 ± 0.02 | |
| Yeast1 | 0.709 ± 0.05 | 0.664 ± 0.07 | 0.718 ± 0.04 | 0.727 ± 0.05 | 0.717 ± 0.05 | 0.727 ± 0.06 | 0.717 ± 0.04 | 0.689 ± 0.05 | 0.706 ± 0.03 | 0.721 ± 0.04 | |
| Connectionist Bench | 0.982 ± 0.03 | 0.971 ± 0.05 | 0.990 ± 0.02 | 0.993 ± 0.02 | 0.987 ± 0.02 | 0.987 ± 0.02 | 0.965 ± 0.03 | 0.989 ± 0.02 | 0.989 ± 0.02 | 0.987 ± 0.03 | |
| C | 03subcl0 | 0.907 ± 0.04 | 0.901 ± 0.06 | 0.824 ± 0.07 | 0.941 ± 0.02 | 0.824 ± 0.06 | 0.930 ± 0.04 | 0.824 ± 0.06 | 0.930 ± 0.04 | 0.822 ± 0.06 | 0.924 ± 0.04 |
| 03subcl30 | 0.747 ± 0.14 | 0.645 ± 0.27 | 0.683 ± 0.06 | 0.828 ± 0.04 | 0.700 ± 0.07 | 0.822 ± 0.07 | 0.701 ± 0.06 | 0.823 ± 0.07 | 0.675 ± 0.07 | 0.812 ± 0.06 | |
| 03subcl50 | 0.682 ± 0.12 | 0.551 ± 0.25 | 0.701 ± 0.06 | 0.751 ± 0.09 | 0.650 ± 0.06 | 0.796 ± 0.05 | 0.648 ± 0.07 | 0.791 ± 0.06 | 0.643 ± 0.05 | 0.799 ± 0.04 | |
| 03subcl70 | 0.592 ± 0.09 | 0.408 ± 0.25 | 0.641 ± 0.06 | 0.648 ± 0.14 | 0.627 ± 0.06 | 0.791 ± 0.04 | 0.628 ± 0.06 | 0.791 ± 0.05 | 0.628 ± 0.06 | 0.794 ± 0.05 | |
| 04clover0 | 0.878 ± 0.05 | 0.859 ± 0.1 | 0.741 ± 0.04 | 0.886 ± 0.04 | 0.710 ± 0.06 | 0.863 ± 0.06 | 0.712 ± 0.07 | 0.864 ± 0.06 | 0.706 ± 0.05 | 0.862 ± 0.06 | |
| 04clover30 | 0.758 ± 0.08 | 0.687 ± 0.13 | 0.687 ± 0.07 | 0.832 ± 0.08 | 0.672 ± 0.05 | 0.815 ± 0.08 | 0.674 ± 0.06 | 0.815 ± 0.08 | 0.642 ± 0.04 | 0.805 ± 0.06 | |
| 04clover50 | 0.628 ± 0.09 | 0.480 ± 0.15 | 0.679 ± 0.06 | 0.806 ± 0.06 | 0.638 ± 0.06 | 0.800 ± 0.07 | 0.642 ± 0.06 | 0.804 ± 0.07 | 0.640 ± 0.06 | 0.805 ± 0.07 | |
| 04clover70 | 0.594 ± 0.08 | 0.421 ± 0.11 | 0.656 ± 0.06 | 0.761 ± 0.09 | 0.646 ± 0.06 | 0.799 ± 0.06 | 0.632 ± 0.06 | 0.781 ± 0.07 | 0.615 ± 0.07 | 0.776 ± 0.09 | |
| paw0 | 0.939 ± 0.04 | 0.932 ± 0.04 | 0.889 ± 0.08 | 0.956 ± 0.03 | 0.778 ± 0.07 | 0.907 ± 0.04 | 0.778 ± 0.07 | 0.907 ± 0.04 | 0.781 ± 0.06 | 0.916 ± 0.03 | |
| paw30 | 0.830 ± 0.06 | 0.793 ± 0.1 | 0.817 ± 0.04 | 0.836 ± 0.07 | 0.705 ± 0.06 | 0.830 ± 0.06 | 0.708 ± 0.05 | 0.835 ± 0.05 | 0.665 ± 0.05 | 0.822 ± 0.04 | |
| paw50 | 0.757 ± 0.09 | 0.693 ± 0.16 | 0.743 ± 0.04 | 0.832 ± 0.06 | 0.669 ± 0.07 | 0.814 ± 0.05 | 0.673 ± 0.07 | 0.817 ± 0.07 | 0.652 ± 0.06 | 0.820 ± 0.04 | |
| paw70 | 0.668 ± 0.05 | 0.599 ± 0.12 | 0.666 ± 0.09 | 0.818 ± 0.07 | 0.654 ± 0.07 | 0.814 ± 0.05 | 0.656 ± 0.07 | 0.816 ± 0.05 | 0.645 ± 0.08 | 0.809 ± 0.06 | |
| Average | 0.787 | 0.704 | 0.804 | 0.820 | 0.779 | 0.811 | 0.779 | 0.808 | 0.772 | 0.812 | |
| RF | DBRF | SMOTE + RF | b-SMOTE + RF | ADASYN + RF | ||
|---|---|---|---|---|---|---|
| A | metal glass | 3.038 | 8.190 | 4.672 | 4.572 | 4.630 |
| vehicle evaluation | 0.140 | 0.374 | 0.159 | 0.162 | 0.222 | |
| Haberman’s survival | 0.120 | 0.379 | 0.127 | 0.126 | 0.165 | |
| B | glasses0 | 0.120 | 0.380 | 0.131 | 0.131 | 0.153 |
| glasses1 | 0.123 | 0.409 | 0.131 | 0.130 | 0.148 | |
| glasses5 | 0.114 | 0.381 | 0.126 | 0.125 | 0.143 | |
| Ecoli1 | 0.121 | 0.386 | 0.132 | 0.131 | 0.192 | |
| Ecoli2 | 0.119 | 0.379 | 0.134 | 0.134 | 0.198 | |
| Ecoli3 | 0.118 | 0.381 | 0.140 | 0.138 | 0.202 | |
| Ecoli0-1 | 0.115 | 0.368 | 0.126 | 0.125 | 0.164 | |
| car-good | 0.134 | 0.359 | 0.165 | 0.164 | 0.195 | |
| car-vgood | 0.128 | 0.370 | 0.157 | 0.160 | 0.160 | |
| cleveland | 0.113 | 0.355 | 0.125 | 0.124 | 0.183 | |
| dermatology | 0.117 | 0.357 | 0.128 | 0.126 | 0.146 | |
| page-blocks0 | 0.734 | 1.584 | 0.899 | 0.907 | 0.948 | |
| Vehicle0 | 0.149 | 0.478 | 0.181 | 0.226 | 0.187 | |
| Vehicle1 | 0.176 | 0.505 | 0.206 | 0.248 | 0.210 | |
| Vehicle2 | 0.176 | 0.505 | 0.206 | 0.248 | 0.210 | |
| Vehicle3 | 0.176 | 0.540 | 0.205 | 0.255 | 0.211 | |
| Wisconsin | 0.125 | 0.438 | 0.134 | 0.136 | 0.164 | |
| Yeast1 | 0.185 | 0.544 | 0.214 | 0.280 | 0.225 | |
| Connectionist Bench | 0.165 | 0.531 | 0.215 | 0.235 | 0.219 | |
| C | 03subcl0 | 0.163 | 0.353 | 0.145 | 0.145 | 0.147 |
| 03subcl30 | 0.166 | 0.368 | 0.151 | 0.147 | 0.150 | |
| 03subcl50 | 0.162 | 0.368 | 0.149 | 0.148 | 0.148 | |
| 03subcl70 | 0.166 | 0.371 | 0.148 | 0.147 | 0.149 | |
| 04clover0 | 0.164 | 0.360 | 0.147 | 0.147 | 0.148 | |
| 04clover30 | 0.167 | 0.365 | 0.148 | 0.147 | 0.149 | |
| 04clover50 | 0.166 | 0.366 | 0.151 | 0.150 | 0.150 | |
| 04clover70 | 0.168 | 0.369 | 0.151 | 0.149 | 0.150 | |
| paw0 | 0.151 | 0.349 | 0.145 | 0.146 | 0.146 | |
| paw30 | 0.165 | 0.364 | 0.149 | 0.147 | 0.148 | |
| paw50 | 0.167 | 0.370 | 0.149 | 0.148 | 0.149 | |
| paw70 | 0.168 | 0.369 | 0.149 | 0.149 | 0.151 |
| Comparison | W+ | W− | p-Value | Hypothesis (0.05) | |
|---|---|---|---|---|---|
| F1 | DBRF vs. RF | 370 | 191 | Rejected | |
| DBRF vs. SMOTE + RF | 492 | 69 | Rejected | ||
| DBRF vs. b-SMOTE+ RF | 498 | 63 | Rejected | ||
| DBRF vs. ADASYN + RF | 507 | 54 | Rejected | ||
| GM | DBRF vs. RF | 553 | 8 | Rejected | |
| DBRF vs. SMOTE + RF | 351 | 210 | Rejected | ||
| DBRF vs. b-SMOTE+ RF | 343 | 218 | Rejected | ||
| DBRF vs. ADASYN + RF | 331 | 230 | Rejected |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, J.; Qian, Q. A Density-Based Random Forest for Imbalanced Data Classification. Future Internet 2022, 14, 90. https://doi.org/10.3390/fi14030090
Dong J, Qian Q. A Density-Based Random Forest for Imbalanced Data Classification. Future Internet. 2022; 14(3):90. https://doi.org/10.3390/fi14030090
Chicago/Turabian StyleDong, Jia, and Quan Qian. 2022. "A Density-Based Random Forest for Imbalanced Data Classification" Future Internet 14, no. 3: 90. https://doi.org/10.3390/fi14030090
APA StyleDong, J., & Qian, Q. (2022). A Density-Based Random Forest for Imbalanced Data Classification. Future Internet, 14(3), 90. https://doi.org/10.3390/fi14030090