
Optimization of the System of Allocation of Overdue Loans in a Sub-Saharan Africa Microfinance Institution †




Abstract
:1. Introduction
- Definition of a prioritization scale to call the users with overdue loans;
- Definition of the list of contacts of the officers based on the prioritization scale.
2. Background
2.1. Importance of Microfinance
- Nonperforming loans
- Capital inadequacy
- Non-transparency
2.2. Process of an Application to Loan
- (1)
- The user must download the app and log in;
- (2)
- The user fills in the profile and loan details;
- (3)
- The loans are evaluated based on the probability of default by processing all the details gathered from the device;
- (4)
- If the loan is accepted, the money is paid out to the bank account from the user directly;
- (5)
- The user repays via bank transfer or online transaction using a debit card, within an interval of 30 days after the loans get accepted.
2.3. Related Works
3. Materials and Methods
3.1. Pratical Method
3.2. Tools
- Pandas: it provides a structure for the data allowing to manipulate it by columns ([11]);
- Matplotlib: it is the most used library to plot graphs and other 2D data visualization ([11]);
- Seaborn: it is a library that provides data visualization, but with more plot styles and color options ([12]);
- Scikit-learn: it has the majority of the machine learning algorithms from techniques such as classification, regression, or clustering; but it also has some important tools such as the principal component analysis or the metrics used to evaluate the models ([13]);
- Kneed: to make it possible to identify easily the number of clusters in a dataset, this library has the KneeLocator, making it automatic ([14]).
3.3. Algorithm Selection
3.4. Feature Encoding
- Standard Scaler: Divides the value by a normalization constant. This does not change the shape of each feature distribution but normalizes the values to be understood by the model ([20]);
- Dummy Codding: This is one of the methods to encode categorical variables (qualitative variables). It transforms labels into a new feature with 0 or 1 and it guarantees an advantage when compared to the one-hot encoder (another method to encode categorical variables)—it removes one degree of freedom and it uses one less feature in the representation ([20]);
- Label Encoder: It is also used to encode categorical variables, with multiple labels. It associates with these labels one different and progressive integer number ([21]).
3.5. Confusion Matrix
- True Positive (TP): when the model predicts correctly the positive value, in this case the variable paid is 1;
- True Negative (TN): when the model predicts correctly the negative value, in this case the variable paid is 0;
- False Positive (FP): when the model predicts wrongly the positive value, in this case the model returns variable paid as 0 but in reality it is 1;
- False Negative (FN): when the model predicts wrongly the negative value, in this case the model returns variable paid as 1 but in reality it is 0.
3.6. Classification Report
- Precision: is 1 when the model does not label a positive value as negative. So, this represents the percentage of positive values that were positive (positive prediction). It is calculated as:
- Recall: is 1 when the model recognizes all the positive instances. This represents a fraction of positive values that were well identified. It is calculated as:
- F1 Score: is the balance between Precision and Recall. It is calculated as:
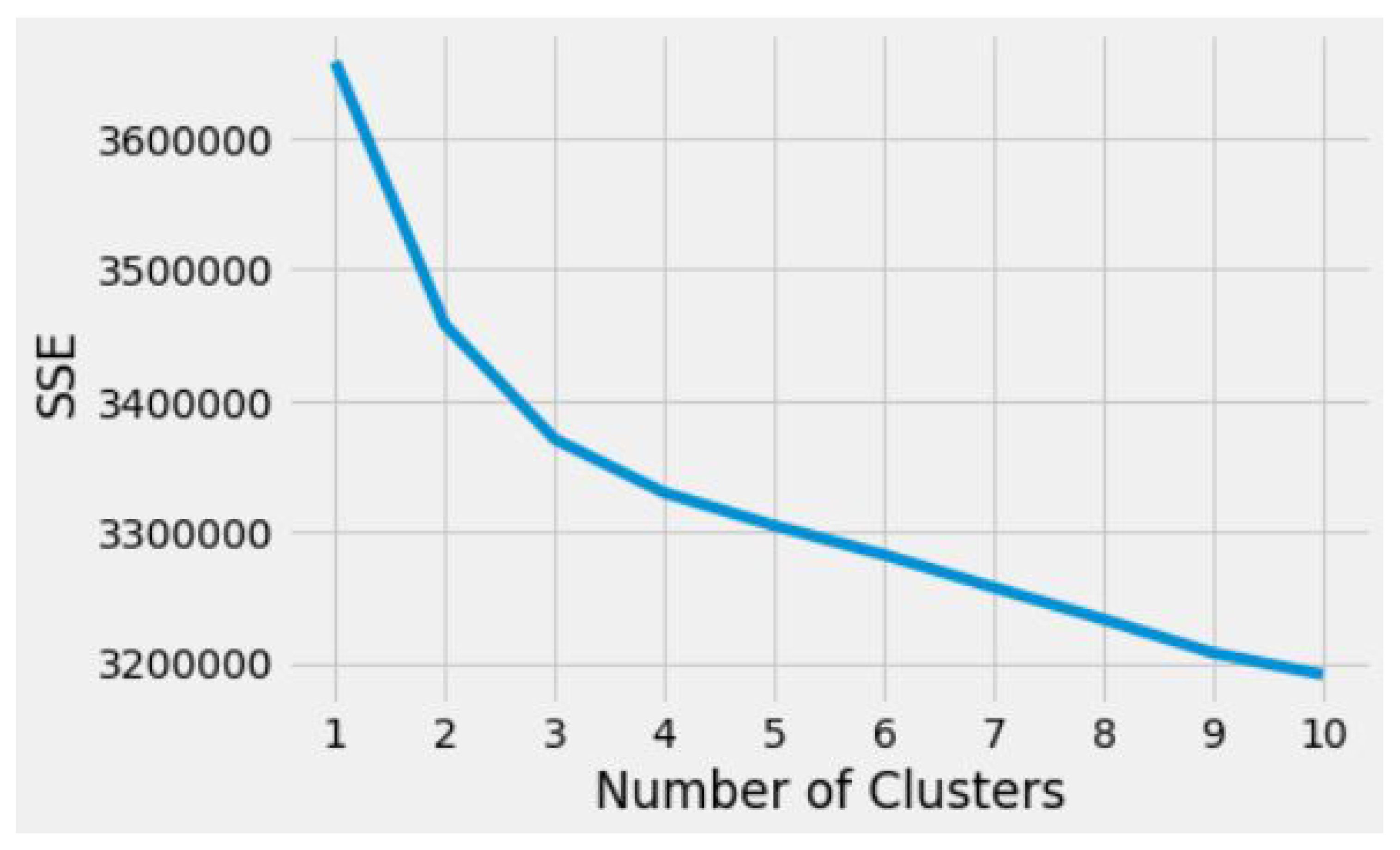
3.7. Elbow Method
3.8. Principal Component Analysis
4. Case Study
4.1. Data Structure
4.2. Data Description
4.3. Modeling
4.3.1. First Experiment
- Demographic of the users: would be allocated to the demographic variables of the officers;
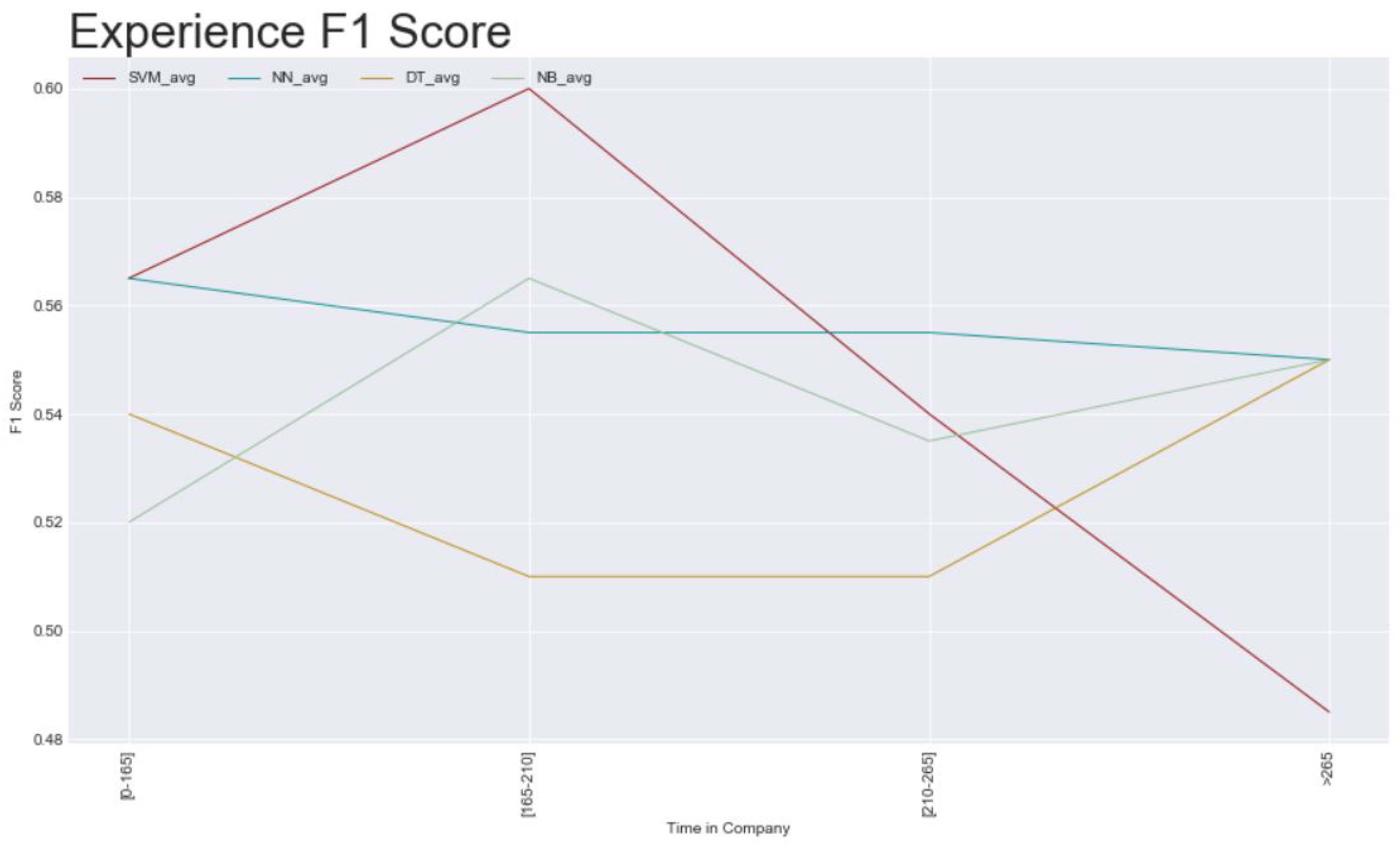
- Experience of the officers: the time_in_company variable should be based on what stage the user is in if it is their first loan with this company, what type of loan it is, and the behavior of the users, here analyzed as SMS and app features;
- Field of studies: which should be related to with the academic background of the users and a mix of characteristics from the loan such as the amount, reason, or the bank entity where the loan was deposited.
4.3.2. Second Experiment
4.3.3. Third Experiment
5. Results and Discussion
5.1. First Experiment
5.2. Second Experiment
5.3. Third Experiment
- (1)
- Percentage of loans recovered per cluster: To check where the amount of paid loans is the highest, and consequently with more probability of a return;
- (2)
- Amount of defaulting money per cluster: To show where the biggest amount of money can be lost is. This results from the sum of the variable principal;
- (3)
- Average from a particular SMS feature: This criterion will not be described in detail to protect the business side of this MFI.
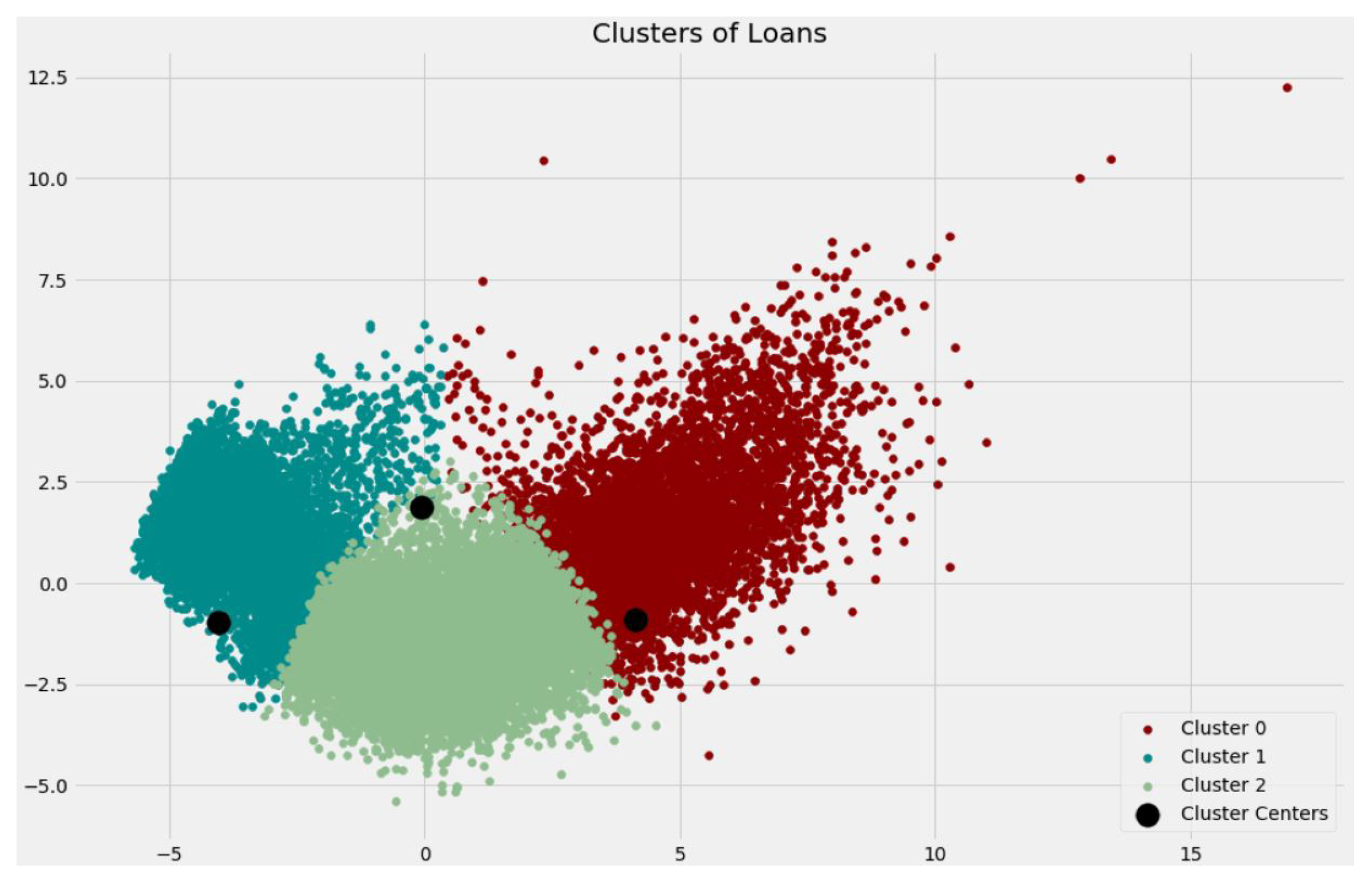
- (1)
- Cluster 2
- (2)
- Cluster 0
- (3)
- Cluster 1
5.4. Allocation Model
6. Conclusions
6.1. Final Considerations
- Demographics: only three subsets could achieve an average of 0.55 as the maximum;
- Academic background: the difference between subsets has not that much variance; however, the best value is an average of 0.58;
- Experience: this was the one having the highest value—0.60, the worst of it is that the model that represents this, is the same that has the low value of all in another subset, which deconstructs the credibility on it.
6.2. Next Steps
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Variables from Dataset A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Type | Description |
|---|---|---|
| loan_id | Nominal | Loan ID |
| cardinal | Scale | Number of loans accepted in this MFI |
| product_id | Scale | Different modes to apply |
| principal | Scale | Total amount applied |
| reason | Nominal | Reason to ask for credit |
| user_age | Scale | Age of the user |
| user_state | Nominal | City where user lives |
| address_info_complete | Binary | All the address information filled? |
| user_gender | Binary | Gender of the user |
| user_employment_status | Scale | User is unemployed or employed or other |
| employment_info_complete | Binary | All the employment information filled? |
| user_marital_status | Scale | If the user is married, single, for example |
| user_number_children | Scale | How many children an user has |
| owns_car | Binary | If the user has or not a car |
| user_education_status | Scale | What education degree the user has |
| entity_short_name | Nominal | Bank entity of the user |
| sms_feature_01 | Scale | Feature related to SMS of the user |
| sms_feature_02 | Scale | Feature related to SMS of the user |
| sms_feature_03 | Scale | Feature related to SMS of the user |
| sms_feature_04 | Scale | Feature related to SMS of the user |
| sms_feature_05 | Scale | Feature related to SMS of the user |
| sms_feature_06 | Scale | Feature related to SMS of the user |
| sms_feature_07 | Scale | Feature related to SMS of the user |
| sms_feature_08 | Scale | Feature related to SMS of the user |
| sms_feature_09 | Scale | Feature related to SMS of the user |
| sms_feature_10 | Scale | Feature related to SMS of the user |
| loan_installed | Binary | Was APP related to Loan installed? |
| competitor_installed | Binary | Was APP of a Competitor installed? |
| bank_installed | Binary | Was APP of a registered Bank installed? |
| otherbank_installed | Binary | Was APP of other Banks installed? |
| cryptocurrency_installed | Binary | Was APP about Cryptocurrency installed? |
| invet_trade_installed | Binary | Was APP about Invest/Trading installed? |
| money_installed | Binary | Was APP about making money installed? |
| officer_id | Nominal | Officer ID |
| officer_age | Scale | Age of the officer (years) |
| officer_gender | Binary | Gender of the officer |
| officer_demographic_01 | Nominal | Variable related to demographics of the officer |
| officer_demographic_02 | Nominal | Variable related to demographics of the officer |
| officer_language | Nominal | Which languages they know |
| officer_education_status | Scale | Education degree of the officer |
| officer_studies | Nominal | Field of studies |
| time_company | Scale | Number of days working on the company |
| paid | Binary | 0 if not paid; 1 if paid |
Appendix B. Variables from Dataset B
| Variable | Type | Description |
|---|---|---|
| loan_id | Nominal | Loan ID |
| cardinal | Scale | Number of loans accepted in this MFI |
| product_id | Scale | Different modes to apply |
| principal | Scale | Total amount applied |
| reason | Nominal | Reason to ask for credit |
| user_age | Scale | Age of the user |
| user_state | Nominal | City where user lives |
| address_info_complete | Binary | All the address information filled? |
| user_gender | Binary | Gender of the user |
| user_employment_status | Scale | User is unemployed or employed or other |
| employment_info_complete | Binary | All the employment information filled? |
| user_marital_status | Scale | If the user is married, single, for example |
| user_number_children | Scale | How many children an user has |
| owns_car | Binary | If the user has or not a car |
| user_education_status | Scale | What education degree the user has |
| entity_short_name | Nominal | Bank entity of the user |
| sms_feature_01 | Scale | Feature related to SMS of the user |
| sms_feature_02 | Scale | Feature related to SMS of the user |
| sms_feature_03 | Scale | Feature related to SMS of the user |
| sms_feature_04 | Scale | Feature related to SMS of the user |
| sms_feature_05 | Scale | Feature related to SMS of the user |
| sms_feature_06 | Scale | Feature related to SMS of the user |
| sms_feature_07 | Scale | Feature related to SMS of the user |
| sms_feature_08 | Scale | Feature related to SMS of the user |
| sms_feature_09 | Scale | Feature related to SMS of the user |
| sms_feature_10 | Scale | Feature related to SMS of the user |
| sms_feature_11 | Scale | Feature related to SMS of the user |
| sms_feature_12 | Scale | Feature related to SMS of the user |
| sms_feature_13 | Scale | Feature related to SMS of the user |
| sms_feature_14 | Scale | Feature related to SMS of the user |
| sms_feature_15 | Scale | Feature related to SMS of the user |
| sms_feature_16 | Scale | Feature related to SMS of the user |
| sms_feature_17 | Scale | Feature related to SMS of the user |
| sms_feature_18 | Scale | Feature related to SMS of the user |
| sms_feature_19 | Scale | Feature related to SMS of the user |
| sms_feature_20 | Scale | Feature related to SMS of the user |
| sms_feature_21 | Scale | Feature related to SMS of the user |
| sms_feature_22 | Scale | Feature related to SMS of the user |
| sms_feature_23 | Scale | Feature related to SMS of the user |
| sms_feature_24 | Scale | Feature related to SMS of the user |
| sms_feature_25 | Scale | Feature related to SMS of the user |
| sms_feature_26 | Scale | Feature related to SMS of the user |
| sms_feature_27 | Scale | Feature related to SMS of the user |
| sms_feature_28 | Scale | Feature related to SMS of the user |
| sms_feature_29 | Scale | Feature related to SMS of the user |
| sms_feature_30 | Scale | Feature related to SMS of the user |
| sms_feature_31 | Scale | Feature related to SMS of the user |
| sms_feature_32 | Scale | Feature related to SMS of the user |
| loan_installed | Binary | Was APP related to Loan installed? |
| competitor_installed | Binary | Was APP of a Competitor installed? |
| bank_installed | Binary | Was APP of a registered Bank installed? |
| otherbank_installed | Binary | Was APP of other Banks installed? |
| cryptocurrency_installed | Binary | Was APP about Crypto installed? |
| invet_trade_installed | Binary | Was APP about Invest/Trading installed? |
| money_installed | Binary | Was APP about making money installed? |
| paid | Binary | 0 if not paid; 1 if paid |
References
- Araújo, A.; Portela, F.; Alvelos, F.; Ruiz, S. Allocation of overdue loans in a Sub-Saharan Africa micronance institution. In Lecture Notes in Computer Science (LNCS)—Computational Science and Its Applications—MIKE 2021; Springer LNCS: Hammamet, Tunisia, 2021. [Google Scholar]
- Adeyemi, B. Bank failure in Nigeria: A consequence of capital inadequacy, lack of transparency and nonperforming loans. Banks Bank Syst. 2011, 6, 99–109. [Google Scholar]
- Reinhart, C.M.; Rogoff, K.S. From financial crash to debt crisis. Am. Econ. Rev. 2011, 101, 1676–1706. [Google Scholar] [CrossRef] [Green Version]
- Mpofu, T.R.; Nikolaidou, E. Determinants of credit risk in the banking system in sub-saharan africa. Rev. Dev. Financ. 2018, 8, 141–153. [Google Scholar] [CrossRef]
- Yang, L.; Wang, Z.; Ding, Y.; Hahn, J. The role of online peer-to-peer lending in crisis response: Evidence from kiva. ICIS 2016 Proc. 2016, 17. [Google Scholar]
- McIntosh, C. Monitoring repayment in online peer-to-peer lending. In The Credibility of Transnational NGOs: When Virtue is Not Enough; Cambridge University Press: Cambridge, UK, 2011; pp. 165–190. [Google Scholar]
- Flannery, M. Kiva and the birth of person-to-person microfinance. Innov. Technol. Governance Globalization 2007, 2, 31–56. [Google Scholar] [CrossRef]
- Huang, C.L.; Chen, M.C.; Wang, C.J. Credit scoring with a data mining approach based on support vector machines. Expert Syst. Appl. 2007, 33, 847–856. [Google Scholar] [CrossRef]
- West, D. Neural network credit scoring models. Comput. Oper. Res. 2000, 27, 1131–1152. [Google Scholar] [CrossRef]
- Olson, D.L.; Delen, D. Advanced Data Mining Techniques; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- McKinney, W. Python for Data Analysis: Data Wrangling with Pandas, NumPy, and IPython; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2012. [Google Scholar]
- VanderPlas, J. Python Data Science Handbook: Essential Tools for Working with Data; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2016. [Google Scholar]
- Grus, J. Data Science from Scratch: First Principles with Python; O’Reilly Media: Sebastopol, CA, USA, 2019. [Google Scholar]
- Mousavi, M.R.; Sgall, J. Topics in Theoretical Computer Science. In Proceedings of the Second IFIP WG 1.8 International Conference, TTCS 2017, Tehran, Iran, 12–14 September 2017. [Google Scholar]
- Byanjankar, A.; Heikkilä, M.; Mezei, J. Predicting credit risk in peer-to-peer lending: A neural network approach. In Proceedings of the 2015 IEEE Symposium Series on Computational Intelligence, Cape Town, South Africa, 7–10 December 2015; pp. 719–725. [Google Scholar]
- Paleologo, G.; Elisseeff, A.; Antonini, G. Subagging for credit scoring models. Eur. J. Oper. Res. 2010, 201, 490–499. [Google Scholar] [CrossRef]
- Ngai, E.W.; Xiu, L.; Chau, D.C. Application of data mining techniques in customer relationship management: A literature review and classification. Expert Syst. Appl. 2009, 36, 2592–2602. [Google Scholar] [CrossRef]
- Baesens, B.; Verstraeten, G.; Van den Poel, D.; Egmont-Petersen, M.; Van Kenhove, P.; Vanthienen, J. Bayesian network classifiers for identifying the slope of the customer lifecycle of long-life customers. Eur. J. Oper. Res. 2004, 156, 508–523. [Google Scholar] [CrossRef] [Green Version]
- Cheng, C.H.; Chen, Y.S. Classifying the segmentation of customer value via RFM model and RS theory. Expert Syst. Appl. 2009, 36, 4176–4184. [Google Scholar] [CrossRef]
- Zheng, A.; Casari, A. Feature Engineering for Machine Learning: Principles and Techniques for Data Scientists; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2018. [Google Scholar]
- Bonaccorso, G. Machine Learning Algorithms; Packt Publishing: Birmingham, UK, 2017. [Google Scholar]
- Caruso, G.; Battista, T.; Gattone, S. A Micro-level Analysis of Regional Economic Activity Through a PCA Approach. In Decision Economics: Complexity of Decisions and Decisions for Complexity; Springer: Ávila, Spain, 2020; pp. 227–234. [Google Scholar]
- Björkegren, D.; Grissen, D. Behavior revealed in mobile phone usage predicts loan repayment. arXiv 2018, arXiv:1712.05840. [Google Scholar] [CrossRef] [Green Version]








| Dataset A | Dataset B | |
|---|---|---|
| Number of rows | 46,132 | 26,825 |
| Period | Not defined | 1 January 2019 to 1 November 2019 |
| Percentage Paid | 54.46% | 55.50% |
| Percentage Defaulting | 45.54% | 44.50% |
| Total number of variables | 43 | 56 |
| Features related to officers | 9 | 0 |
| Features related to SMS | 10 | 32 |
| Dataset A | ||||||
|---|---|---|---|---|---|---|
| user_ age | marital_ status | nr_ children | employ_ status | educ_ status | officer_ age | |
| Mean | 34.53 | 0.61 | 1.52 | 0.54 | 1.80 | 26.19 |
| Std dev | 14.03 | 0.56 | 1.87 | 0.64 | 0.41 | 3.28 |
| Min | 18.00 | 0.00 | 0.00 | 0.00 | 0.00 | 21.00 |
| 1st Q | 29.00 | 0.00 | 0.00 | 0.00 | 2.00 | 25.00 |
| 2nd Q | 34.00 | 1.00 | 1.00 | 0.00 | 2.00 | 26.00 |
| 3rd Q | 39.00 | 1.00 | 2.00 | 1.00 | 2.00 | 27.00 |
| Max | 1822.00 | 3.00 | 100.00 | 4.00 | 2.00 | 35.00 |
| Dataset B | |||||
|---|---|---|---|---|---|
| user_ age | marital_ status | nr_ children | employ_ status | education_ status | |
| Mean | 35.01 | 0.62 | 1.55 | 0.79 | 1.81 |
| Std dev | 11.81 | 0.56 | 1.84 | 1.16 | 0.40 |
| Min | 18.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 1st Q | 30.00 | 0.00 | 0.00 | 0.00 | 2.00 |
| 2nd Q | 34.00 | 1.00 | 1.00 | 1.00 | 2.00 |
| 3rd Q | 40.00 | 1.00 | 2.00 | 1.00 | 2.00 |
| Max | 1024.00 | 3.00 | 100.00 | 7.00 | 2.00 |
| Y | |||
|---|---|---|---|
| dem1Xdem2 | field_of_studies | time_in_company | |
| X | user_age | employment_status | cardinal |
| user_state | principal | product_id | |
| user_gender | education_status | sms_features (all) | |
| marital_status | reason | app_features (all) | |
| nr_children | entity_short_name | ||
| owns_car | |||
| Cluster | Percentage of Loans Recovered | Amount of Defaulting | Average of an SMS Feature |
|---|---|---|---|
| 0 | 51.77% | 124,178,220.00 | 59,024,711.00 |
| 1 | 50.50% | 66,444,430.00 | 70,482.00 |
| 2 | 67.77% | 89,303,870.00 | 94,007,441.00 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Araújo, A.; Portela, F.; Alvelos, F.; Ruiz, S. Optimization of the System of Allocation of Overdue Loans in a Sub-Saharan Africa Microfinance Institution. Future Internet 2022, 14, 163. https://doi.org/10.3390/fi14060163
Araújo A, Portela F, Alvelos F, Ruiz S. Optimization of the System of Allocation of Overdue Loans in a Sub-Saharan Africa Microfinance Institution. Future Internet. 2022; 14(6):163. https://doi.org/10.3390/fi14060163
Chicago/Turabian StyleAraújo, Andreia, Filipe Portela, Filipe Alvelos, and Saulo Ruiz. 2022. "Optimization of the System of Allocation of Overdue Loans in a Sub-Saharan Africa Microfinance Institution" Future Internet 14, no. 6: 163. https://doi.org/10.3390/fi14060163
APA StyleAraújo, A., Portela, F., Alvelos, F., & Ruiz, S. (2022). Optimization of the System of Allocation of Overdue Loans in a Sub-Saharan Africa Microfinance Institution. Future Internet, 14(6), 163. https://doi.org/10.3390/fi14060163