
Internet-of-Things Traffic Analysis and Device Identification Based on Two-Stage Clustering in Smart Home Environments


Abstract
:1. Introduction
- The need to update the identification models: People often install new IoT devices and remove older devices from their home environments. To address such replacements and maintain proper management, it is essential to update identification models frequently, which requires periodic training. However, conventional methods implement IoT device identification with only one-time learning and do not consider the computational and communication loads owing to model updating.
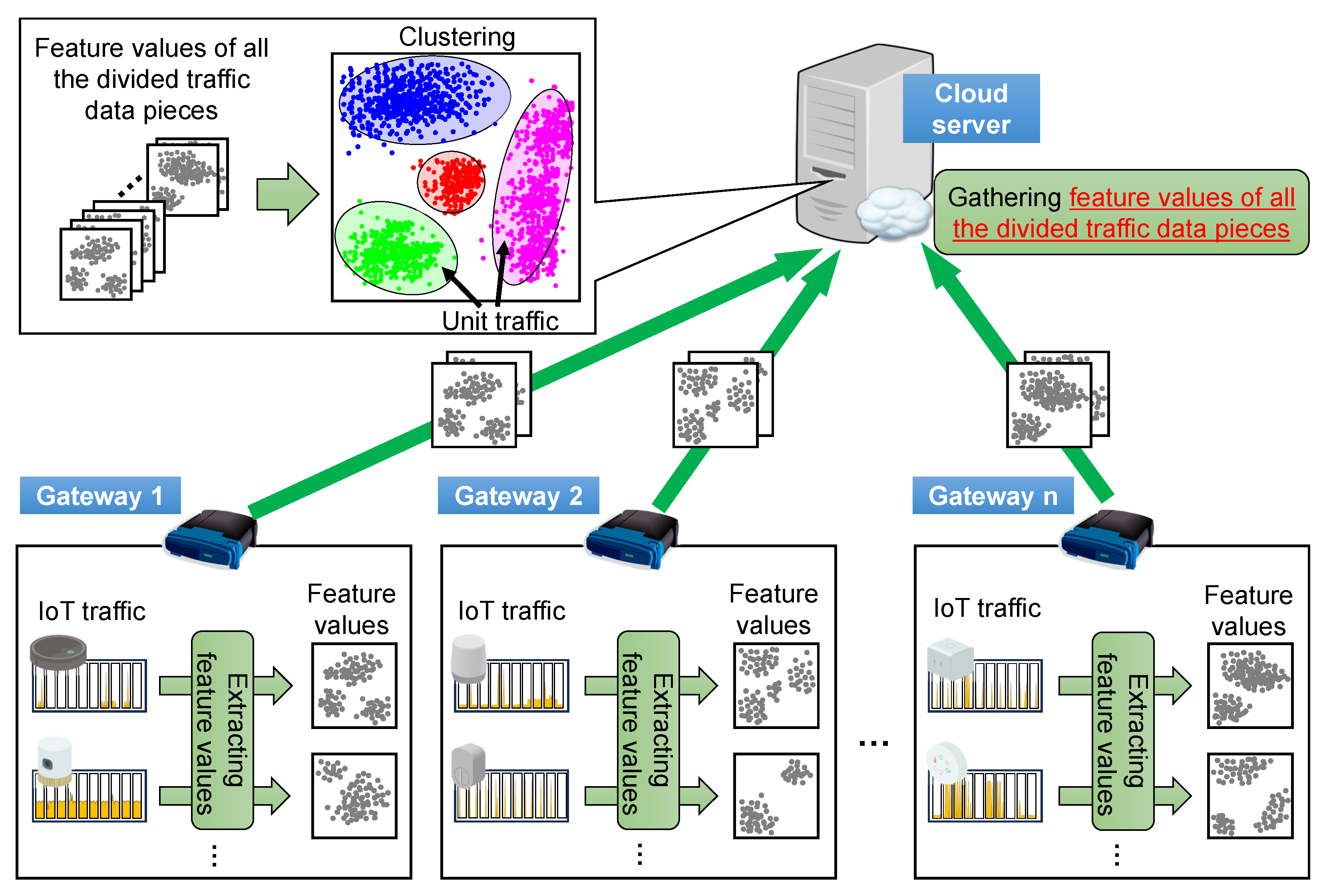
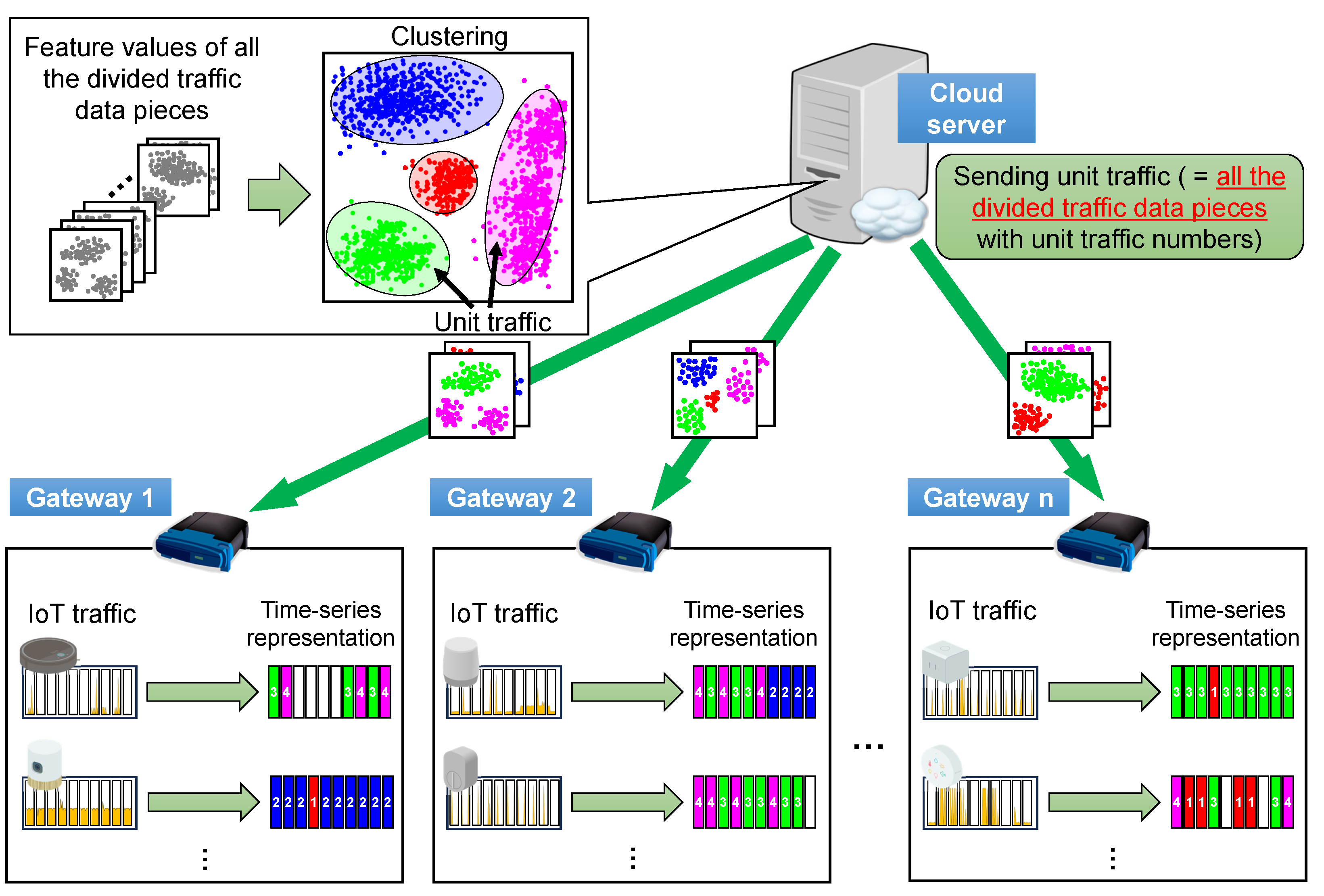
- How to process traffic data: Analyzing a significant amount of traffic data simultaneously in one place can cause a heavy load on the memory and CPU, as well as interfere with the analysis. With the growing use of IoT devices, the processing of a larger amount of collected IoT traffic is required. Although collecting and analyzing traffic data on a cloud server is one solution, this approach requires sending traffic data captured in smart homes to the cloud for analysis or learning, which is unsuitable from the perspective of communication traffic and user privacy. In addition, traffic data are biased because of variations in IoT device behaviors. The biases increase in proportion to the number of device types and the amount of collected traffic data, which could negatively impact the analytical results and appropriate classification. Therefore, it is necessary to consider how to process significant amounts of traffic data appropriately when implementing this method in smart home environments. However, conventional methods typically process traffic data simultaneously.
- The range that IoT device identification targets: Most methods utilize fixed values such as the IP and MAC addresses included in traffic data to identify specific IoT devices installed in smart homes. From the perspective of security in smart homes, however, it is important to identify and grasp not only whether the appropriate IoT devices are connected but also whether they operate properly. Some conventional methods analyze IoT traffic based on communication features, such as the number of destination IP addresses, the number of protocol types, and the total amount of data. However, they only focus on features in a fixed interval. Thus, methods that do not consider the time series characteristics of IoT traffic would overlook the behavior of IoT devices, since they cannot extract features from some IoT traffic owing to the differences in communication periods.
- We summarized the concerns regarding IoT device identification in real environments: the need to regularly update identification models, how to process traffic data, and the range of IoT device identification. Thereafter, we proposed an IoT traffic analysis and device identification method based on two-stage clustering that can be implemented in smart home environments. This study investigated whether two-stage clustering performs properly in IoT traffic analysis and device identification by comparing it with a normal centralized clustering method.
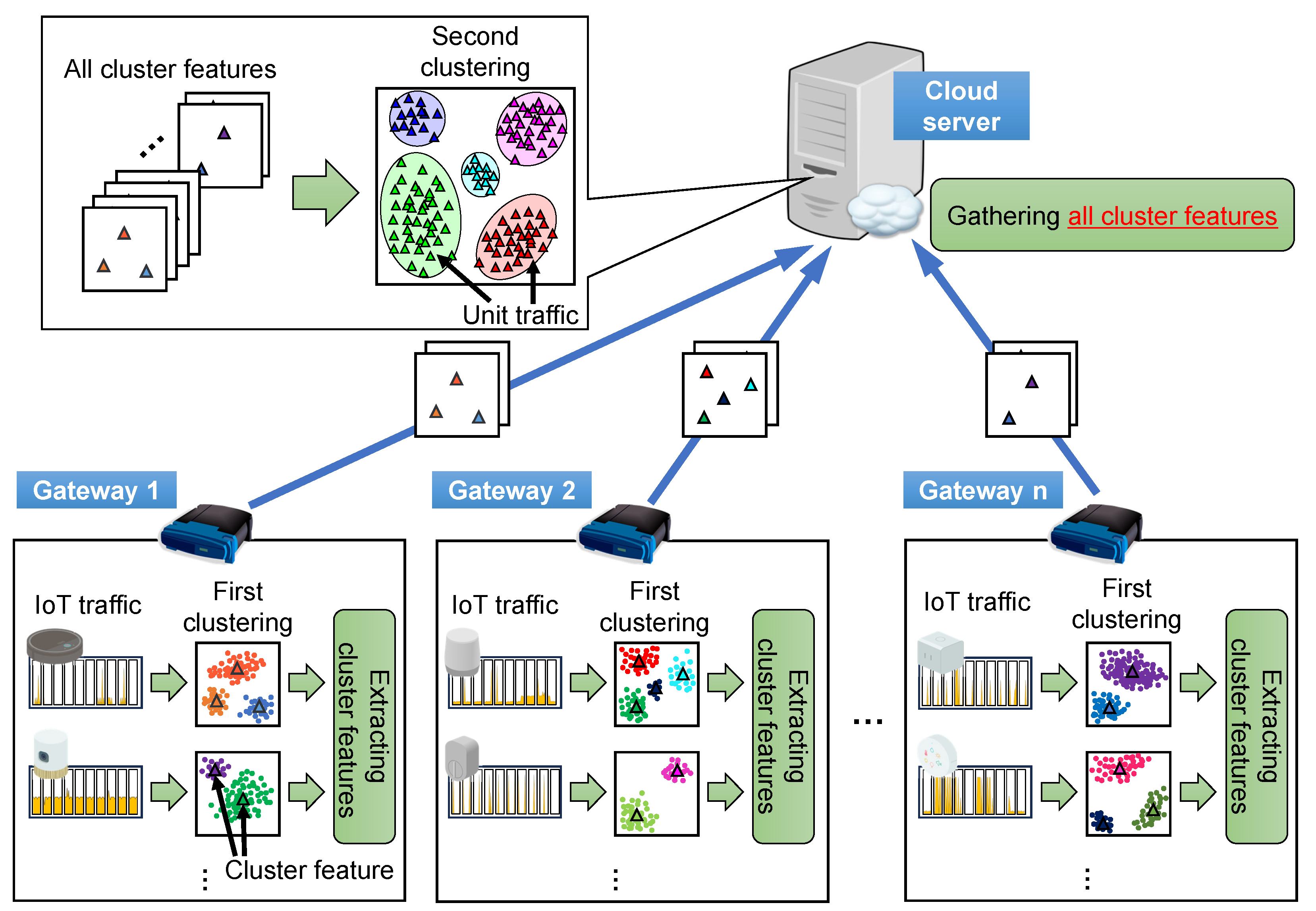
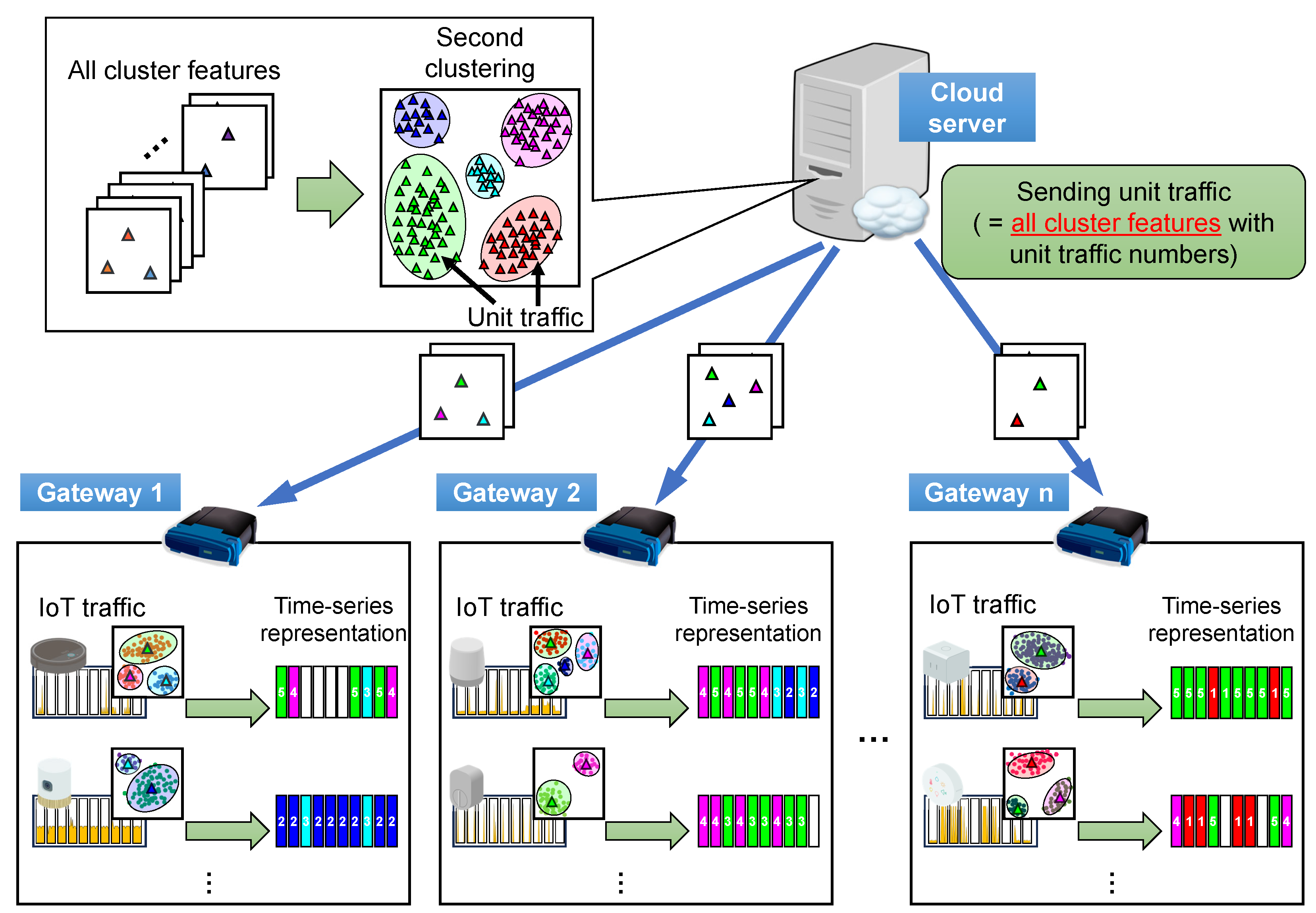
- We applied the two-stage clustering method, which has previously been proposed to grasp dynamic traffic changes specifically for peer-to-peer video streaming services (P2PTV) [15,16], to IoT traffic analysis based on the similarities between P2PTV and IoT traffic. Using two-stage clustering, we extracted traffic patterns to describe IoT traffic and transformed the IoT traffic into a time series numerical representation, which is a series of traffic patterns. Consequently, we visualized the time series characteristics of the communication of IoT devices and extracted traffic features for IoT device identification.
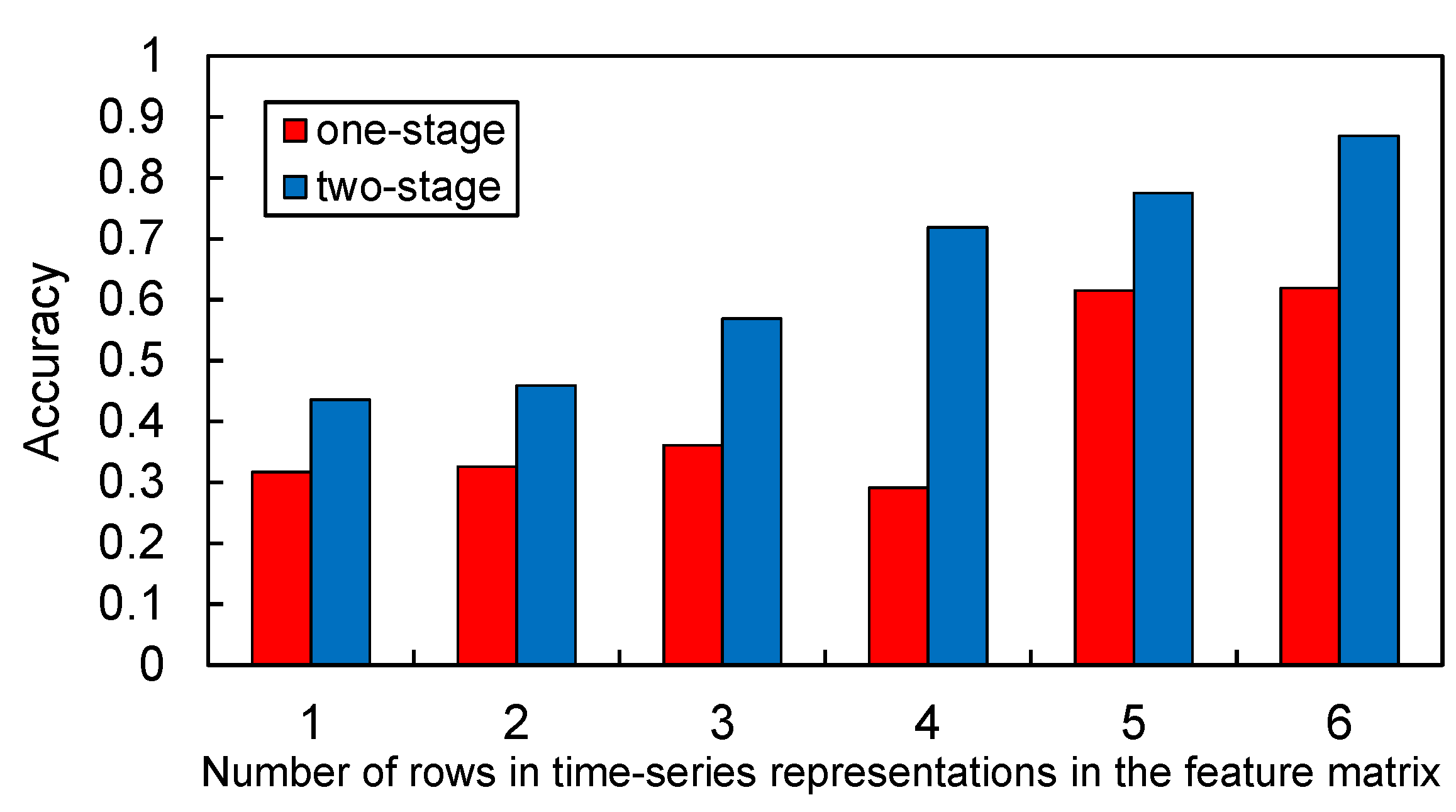
- We implemented an IoT device identification model with a long short-term memory (LSTM) network based on time series representations as the dataset. Using the proposed device identification model based on two-stage clustering, the accuracy with respect to identifying 21 IoT devices was 86.9%. The proposed method provides greater precision for both overall and for each IoT device identification than conventional single-stage centralized clustering. Moreover, by comparing the accuracies of six different time series representations as datasets, we demonstrated the effectiveness of analyzing IoT traffic over multiple time intervals.
2. Related Work
2.1. IoT Device Identification Methods
2.2. Considerations Regarding IoT Device Identification in Smart Home Environments
3. IoT Traffic Analysis with Two-Stage Clustering
3.1. Two-Stage Clustering
3.2. Procedure of the Proposed Method
3.3. Experimental Conditions
- Set k centroids of clusters randomly (initialization). The number of clusters, k, must be determined in advance.
- Traverse all data points and calculate the distances between all centroids and data points. Clusters are formed based on the minimum distance from the centroids.
- The average value of the data in each cluster is calculated as the new cluster centroid.
- The second and third steps are repeated until the centroids stop moving; that is, the centroids no longer change their positions and become static.
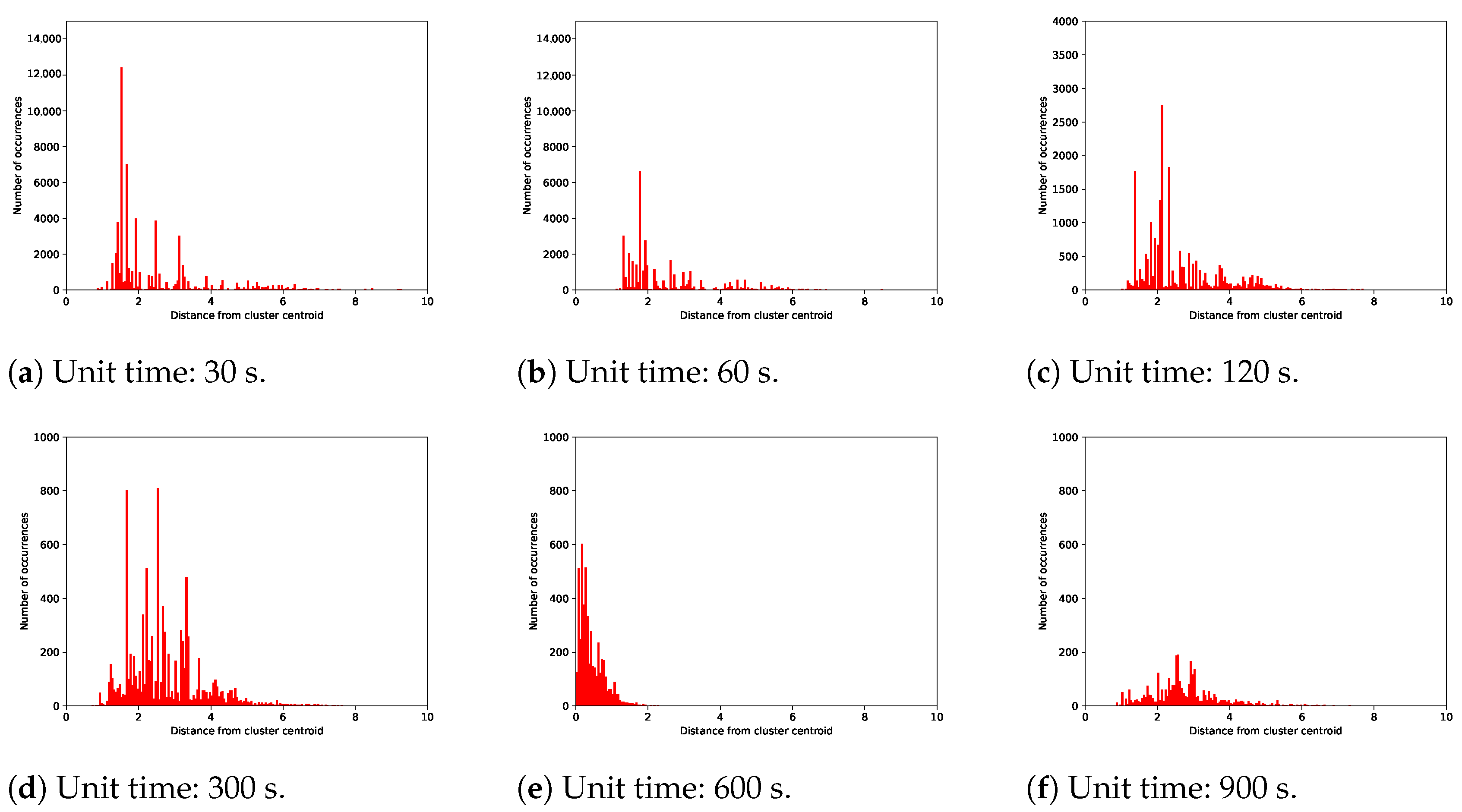
- Calculate the average distance between and the other data points within by using the following equation:
- Calculate the average distance between and all data points assigned to , which is the cluster nearest to other than , using the following equation:
- Calculate the silhouette coefficient using and through the following equation:
4. Analytical Results
4.1. One-Stage Clustering as a Comparison Target
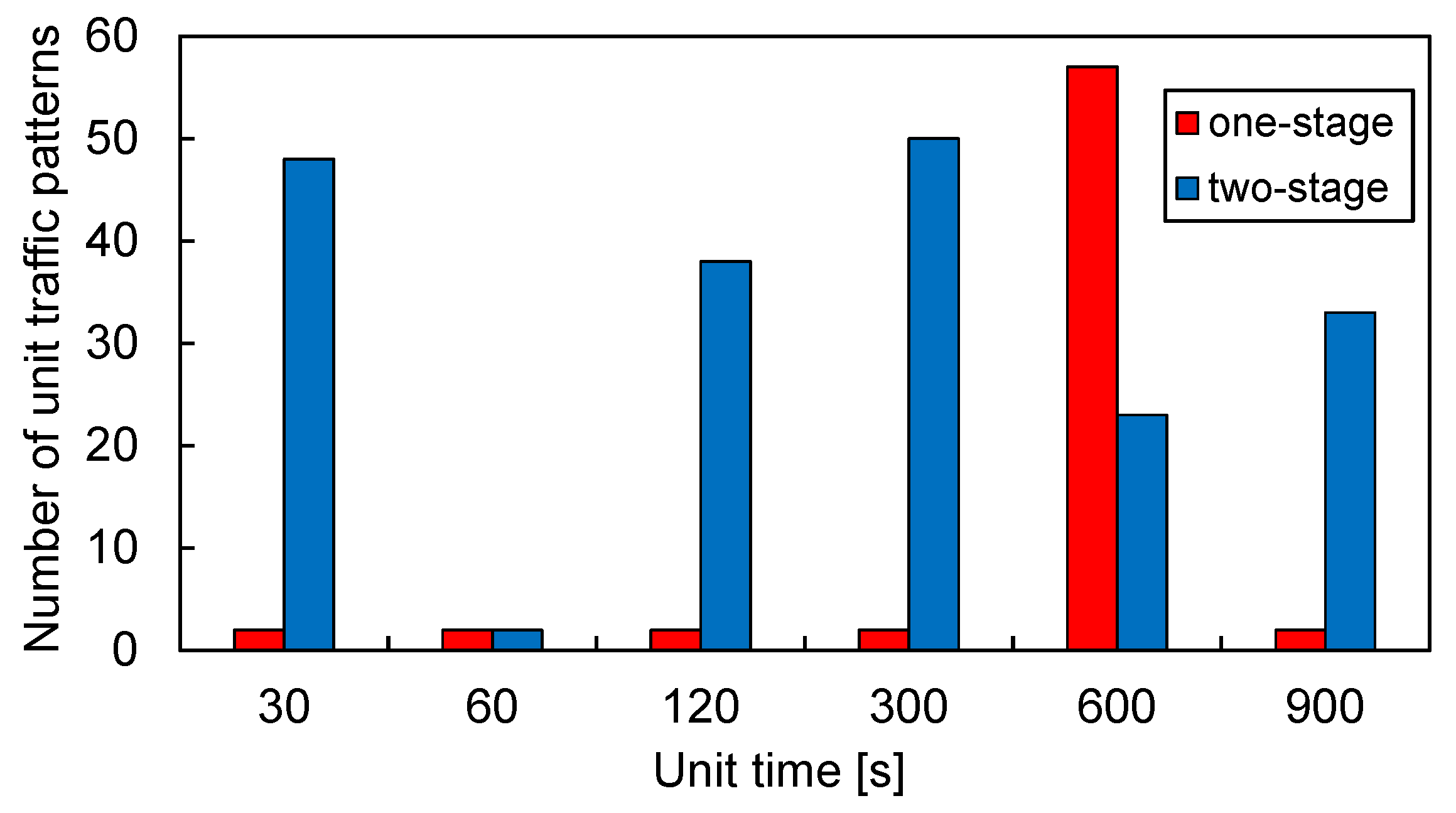
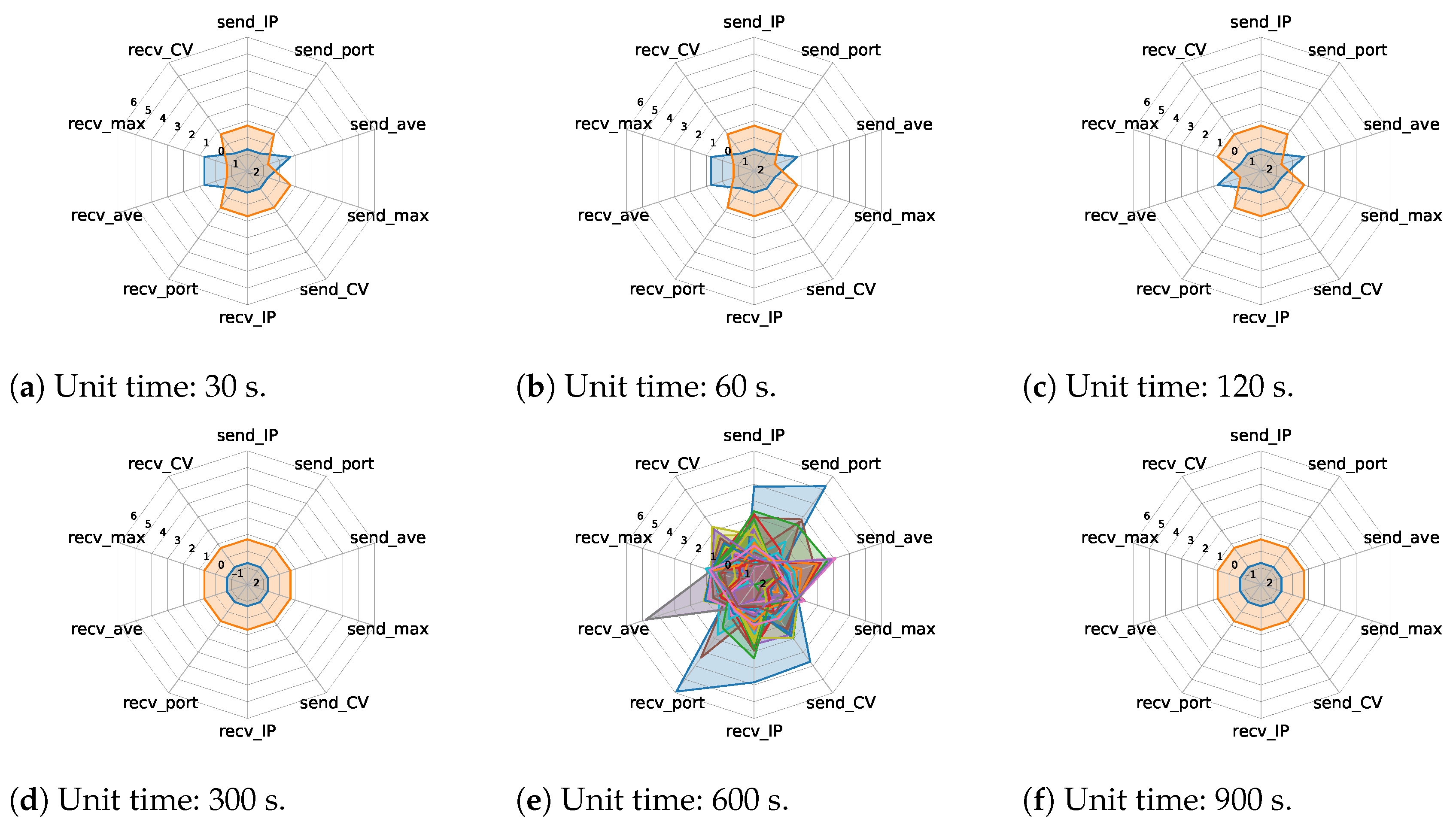
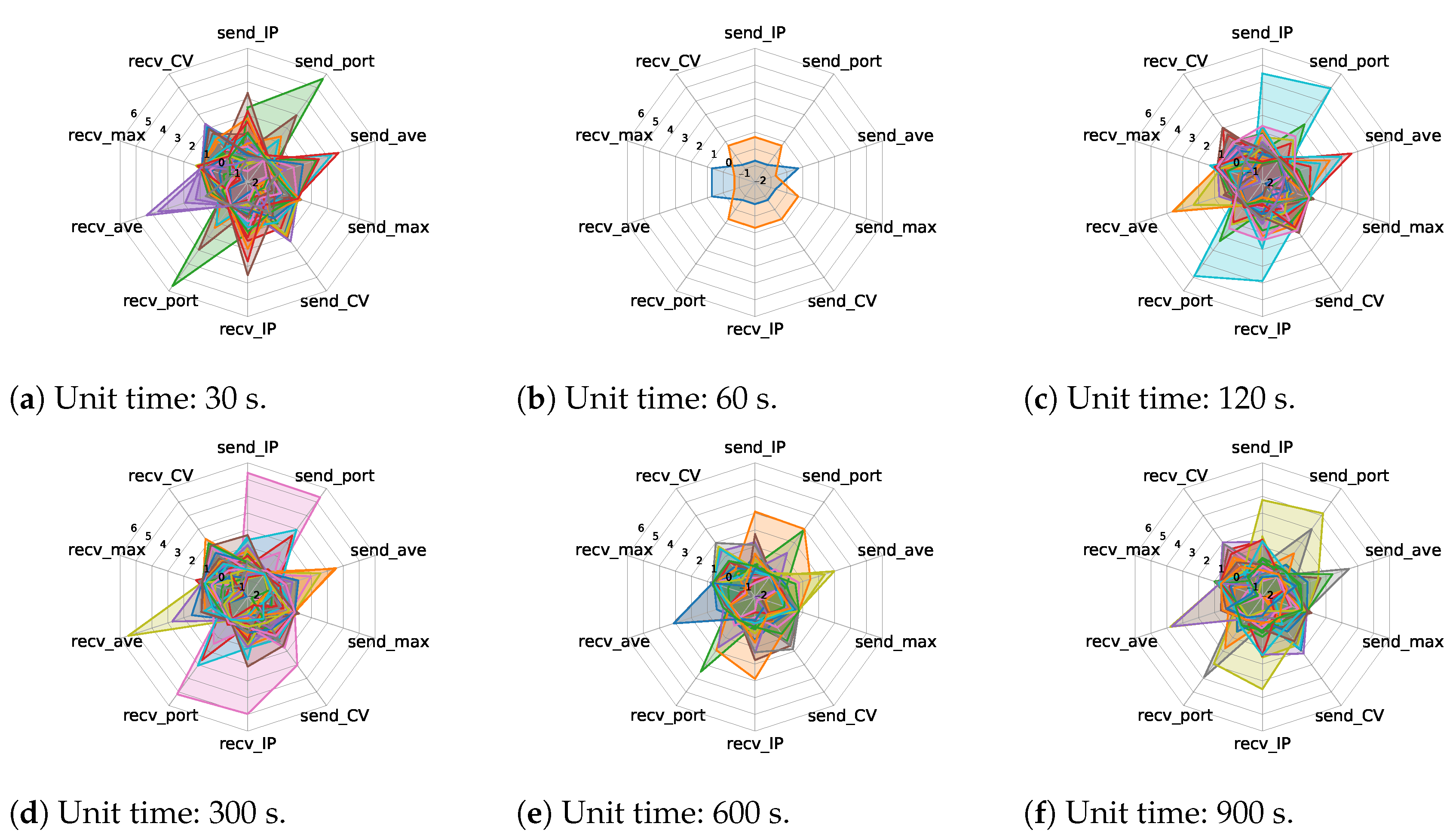
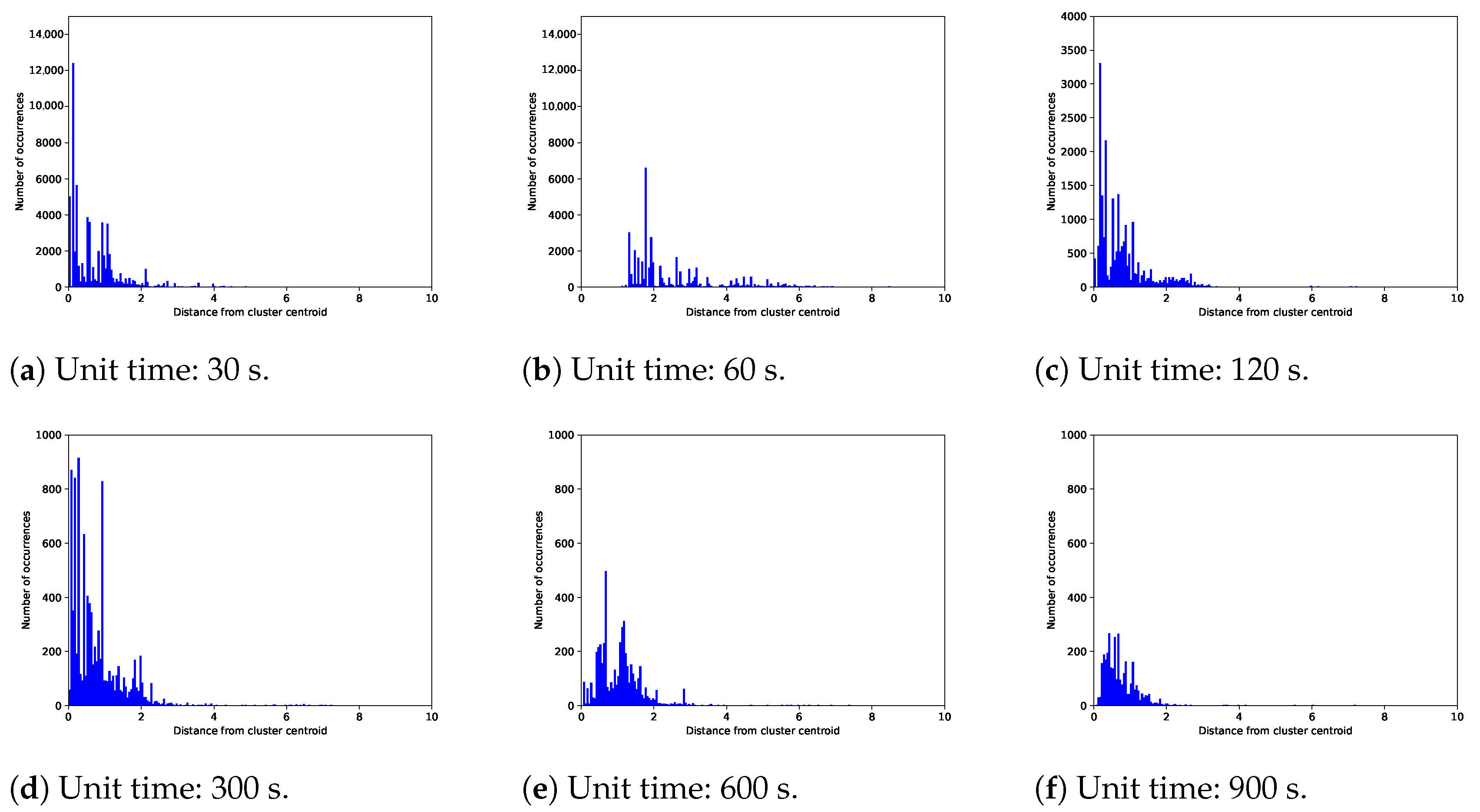
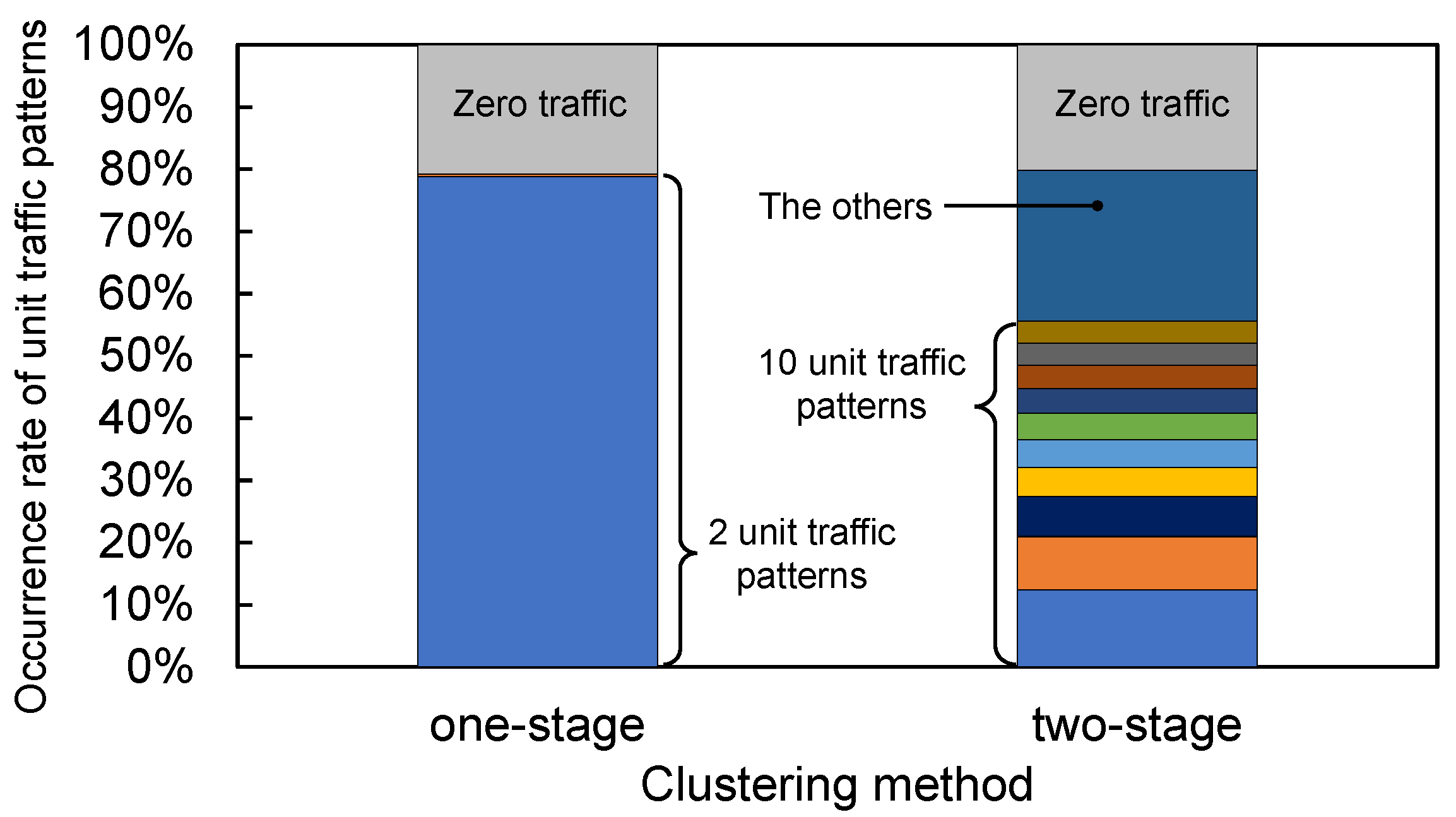
4.2. Unit Traffic Patterns Extracted by One/Two-Stage Clustering
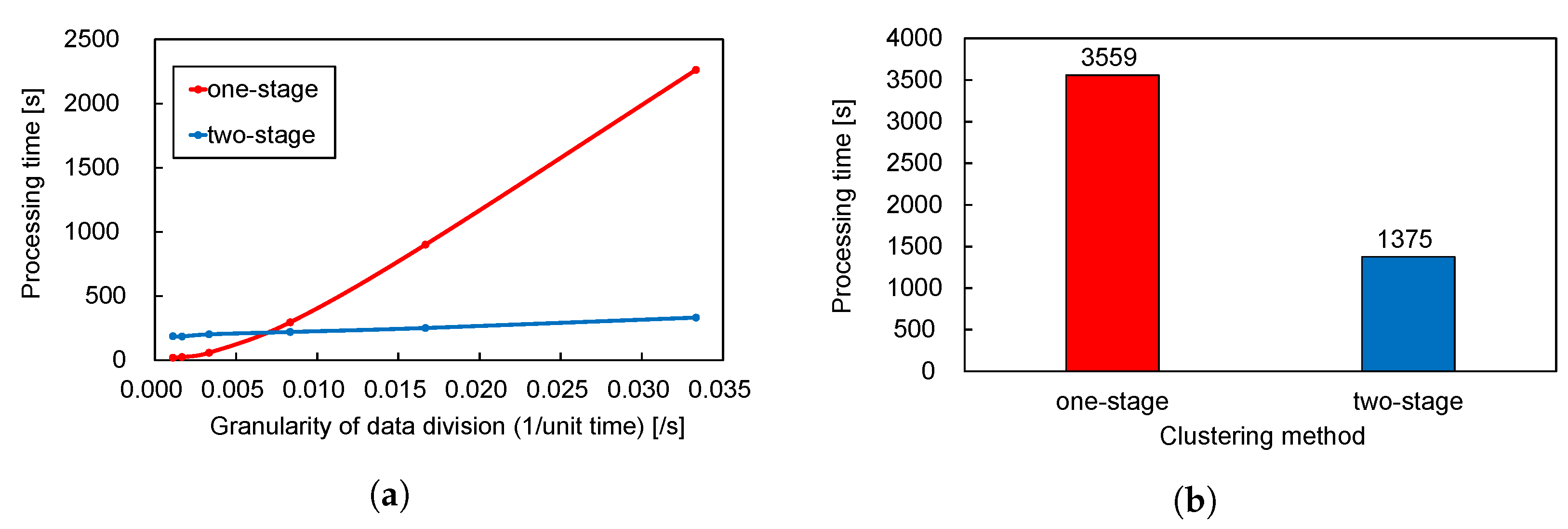
4.3. Execution Time
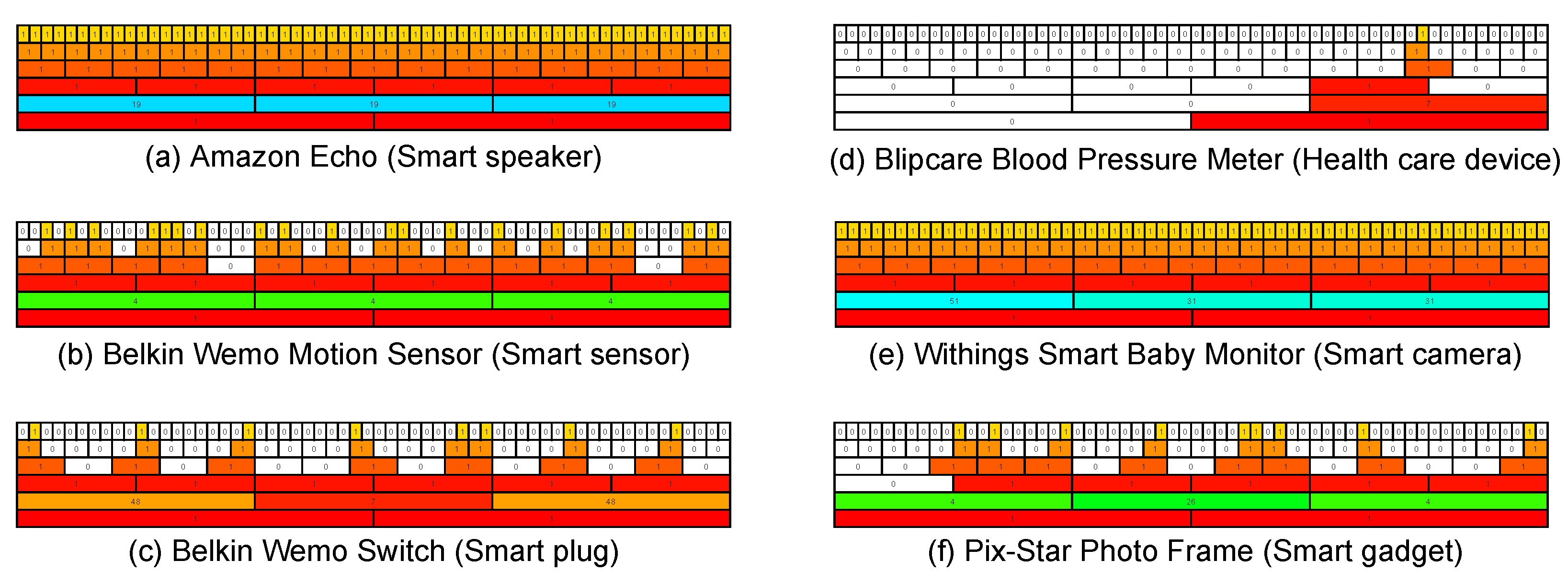
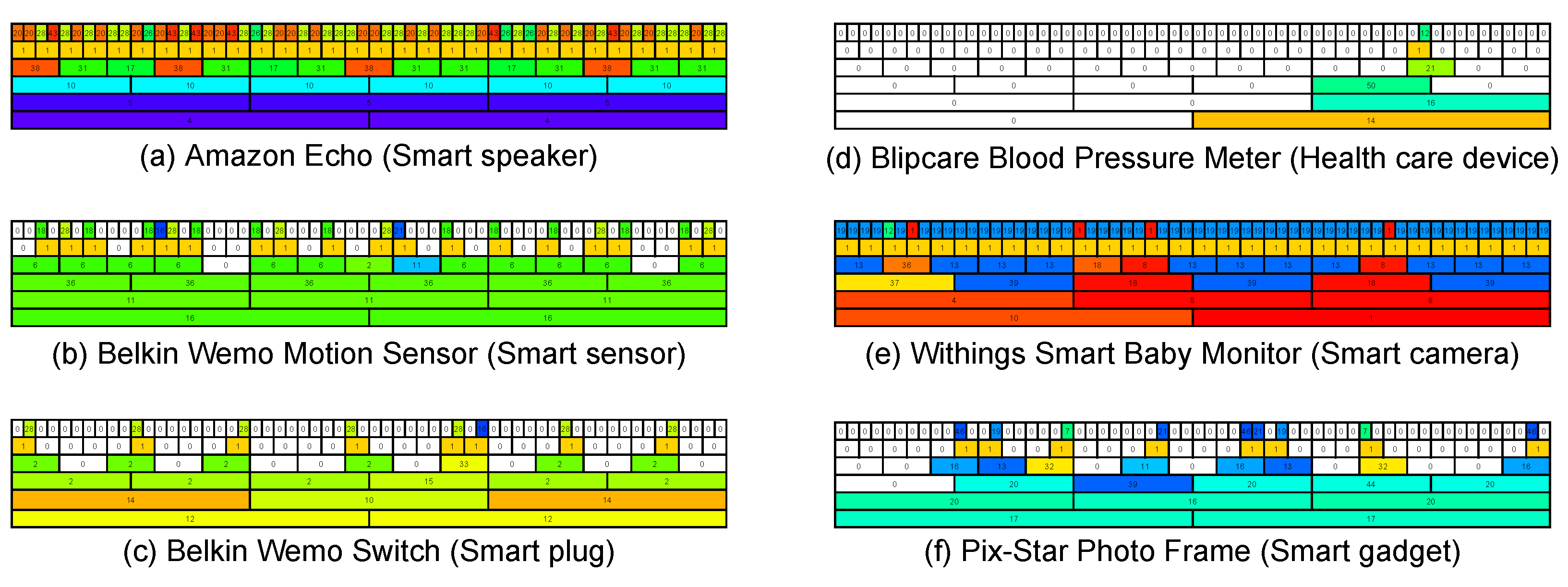
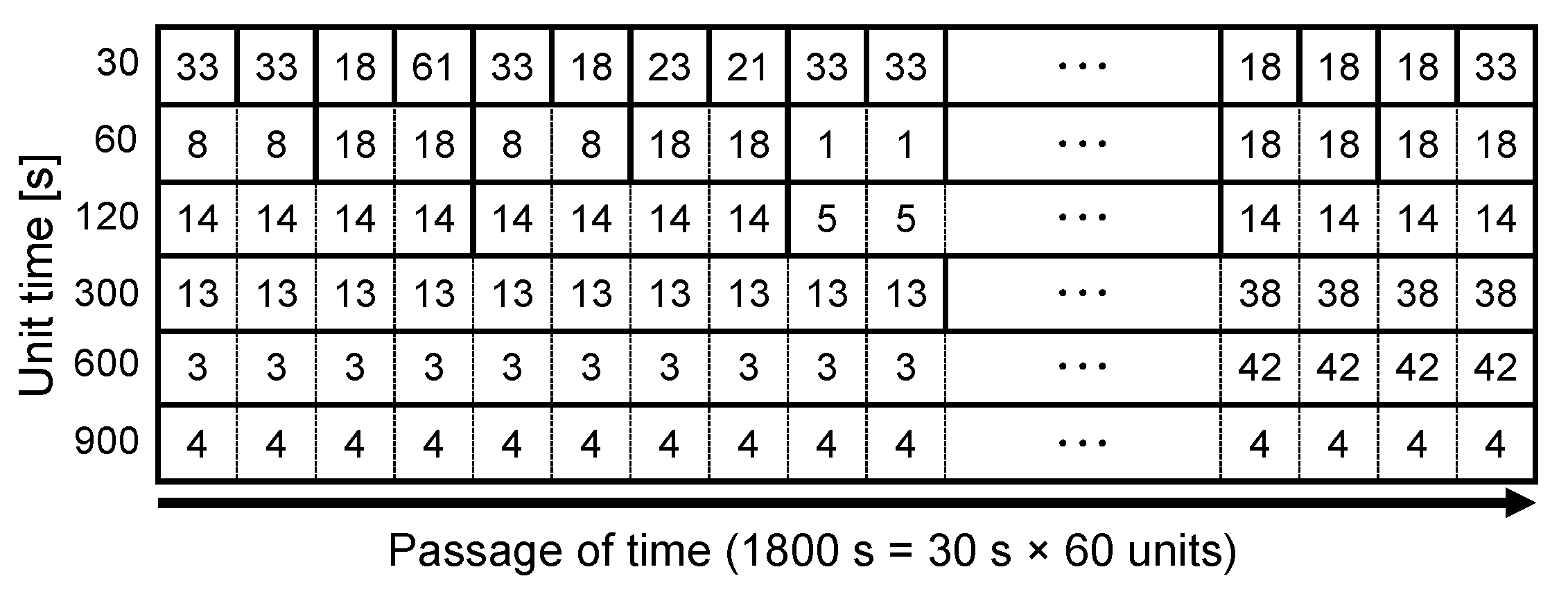
4.4. Time Series Representation
4.5. Summary
5. IoT Device Identification Based on Time Series Representations
5.1. Procedure of IoT Device Identification
5.2. Experimental Conditions
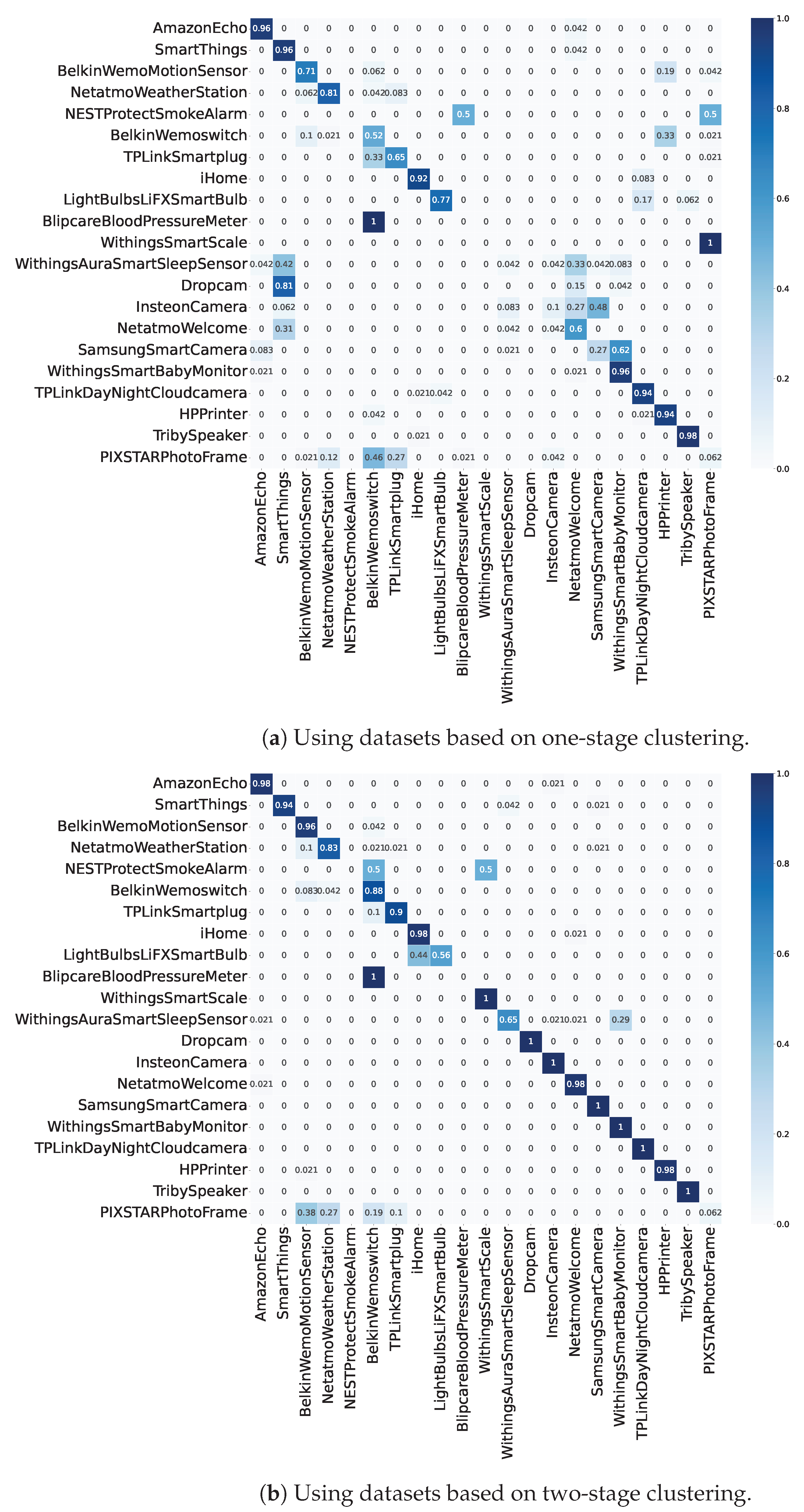
5.3. Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Shafique, K.; Khawaja, B.A.; Sabir, F.; Qazi, S.; Mustaqim, M. Internet of things (IoT) for next–generation smart systems: A review of current challenges, future trends and prospects for emerging 5G-IoT scenarios. IEEE Access 2020, 8, 23022–23040. [Google Scholar] [CrossRef]
- Fortune Business Insights. Available online: https://www.fortunebusinessinsights.com/jp/%E6%A5%AD%E7%95%8C-%E3%83%AC%E3%83%9D%E3%83%BC%E3%83%88/%E3%82%B9%E3%83%9E%E3%83%BC%E3%83%88%E3%83%9B%E3%83%BC%E3%83%A0%E5%B8%82%E5%A0%B4-101900 (accessed on 28 October 2023).
- Yu, M.; Zhuge, J.; Cao, M.; Shi, Z.; Jiang, L. A survey of security vulnerability analysis, discovery, detection, and mitigation on IoT devices. Future Internet 2020, 12, 27. [Google Scholar] [CrossRef]
- Threadpost. IoT Attacks Skyrocket, Doubling in 6 Months. Available online: https://threatpost.com/iot-attacks-doubling/169224/ (accessed on 28 October 2023).
- Sadhu, P.K.; Yanambaka, V.P.; Abdelgawad, A. Internet of things: Security and solutions survey. Sensors 2022, 22, 7433. [Google Scholar] [CrossRef] [PubMed]
- Takasaki, C.; Korikawa, T.; Hattori, K.; Ohwada, H.; Shimizu, M.; Takaya, N. IoT device identification based on two-stage traffic analysis. IEICE Tech. Rep. 2021, 121, 47–51. [Google Scholar]
- Koike, D.; Ishida, S.; Arakawa, Y. Called function identification of IoT devices by network traffic analysis. In Proceedings of the Multimedia, Distrib., Cooperative & Mobile Symp. (DICOMO2020), Virtual Event, 24–26 June 2020; pp. 933–939. [Google Scholar]
- Koike, D.; Ishida, S.; Arakawa, Y. Called function identification of IoT devices by network traffic analysis. In Proceedings of the 36th Annual ACM Symp. on Applied Comput. (SAC2021), Virtual Event, Republic of Korea, 22–26 March 2021; pp. 737–743. [Google Scholar] [CrossRef]
- Hattori, Y.; Arakawa, Y.; Inoue, S. Function estimation of multiple IoT devices by communication traffic analysis. In Proceedings of the 4th International Conference on Activity and Behavior Computing (ABC2022), London, UK, 27–29 October 2022. [Google Scholar]
- Ammar, N.; Noirie, L.; Tixeuil, S. Autonomous IoT device identification prototype. In Proceedings of the 2019 Network Traffic Measurement and Analysis Conference (TMA), Paris, France, 19–21 June 2019; pp. 195–196. [Google Scholar] [CrossRef]
- Nguyen-An, H.; Silverston, T.; Yamazaki, T.; Miyoshi, T. IoT traffic: Modeling and measurement experiments. IoT 2021, 2, 140–162. [Google Scholar] [CrossRef]
- Okui, N.; Nakahara, M.; Miyake, Y.; Kubota, A. Identification of an IoT device model in the home domain using IPFIX records. In Proceedings of the 2022 IEEE 46th Annual Computing Software, and Applications Conference (COMPSAC), Virtual Event, 27 June–1 July 2022; pp. 583–592. [Google Scholar] [CrossRef]
- Trad, F.; Hussein, A.; Chehab, A. Using siamese neural networks for efficient and accurate IoT device identification. In Proceedings of the 2022 Seventh International Conference on Fog and Mobile Edge Computing (FMEC), Paris, France, 12–15 December 2022; pp. 1–7. [Google Scholar] [CrossRef]
- Trad, F.; Hussein, A.; Chehab, A. Assessing the effectiveness of siamese neural networks to mitigate frequent retraining in IoT device identification models. In Proceedings of the 2023 International Conference on Platform Technology and Service (PlatCon), Busan, Republic of Korea, 16–18 August 2023; pp. 47–52. [Google Scholar] [CrossRef]
- Ooka, R.; Miyoshi, T.; Yamazaki, T. Unit traffic classification and analysis on P2P video delivery using machine learning. IEICE Commun. Exp. (ComEX) 2019, 8, 640–645. [Google Scholar] [CrossRef]
- Ooka, R.; Miyoshi, T.; Yamazaki, T. A two-stage clustering method for P2PTV traffic classification. IEICE Trans. Commun. 2020, 119, 51–56. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- dmlc XGBoost. XGBoost Documentation. Available online: https://xgboost.readthedocs.io/en/latest/ (accessed on 31 October 2023).
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A highly efficient gradient boosting decision tree. In Proceedings of the Advances in Neural Information Processing Systems (NIPS2017), Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30, pp. 3149–3157. [Google Scholar]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. In Proceedings of the Advances in Neural Information Processing Systems (NIPS2018), Montreal, QC, Canada, 3–8 December 2018; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; Volume 31, pp. 6639–6649. [Google Scholar]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the 5th Berkeley Symposium on Mathematical Statistics and Probability, Oakland, CA, USA, 21 June–18 July 1965; Volume 1, pp. 281–297. [Google Scholar]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. & Appl. Math. 1987, 20, 53–65. [Google Scholar]
- UNSW Sydney. IoT Security IoT Traffic Analysis. Available online: https://iotanalytics.unsw.edu.au/iottraces.html (accessed on 28 October 2023).
- Python. Time Access and Conversions. Available online: https://docs.python.org/3/library/time.html (accessed on 28 October 2023).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Device Category | IoT Device |
|---|---|
| Smart speakers | Amazon Echo |
| Smart Things | |
| Smart sensors | Belkin Wemo Motion Sensor |
| Netatmo Weather Station | |
| NEST Protect Smoke Alarm | |
| Smart plugs | Belkin Wemo Switch |
| TP-Link Smart Plug | |
| iHome | |
| Light Bulbs LiFX Smart Bulb | |
| Healthcare devices | Blipcare Blood Pressure Meter |
| Withings Smart Scale | |
| Withings Aura Smart Sleep Sensor | |
| Smart cameras | Dropcam |
| Insteon Camera | |
| Netatmo Welcome | |
| Samsung Smart Camera | |
| Withings Smart Baby Monitor | |
| TP-Link Day Night Cloud Camera | |
| Smart gadgets | HP Printer |
| Triby Speaker | |
| Pix-Star Photo Frame |
| Clustering | Distance from Cluster Feature (Unit of Time: 120 s) | Distance between Cluster Features (All Settings of Units of Time) | ||||||
|---|---|---|---|---|---|---|---|---|
| Ave | Max | Min | Var | Ave | Max | Min | Var | |
| One-stage | 2.70 | 31.9 | 0.84 | 1.76 | 2.93 | 9.99 | 0.55 | 2.41 |
| Two-stage | 0.82 | 18.5 | 0.00 | 0.81 | 3.84 | 11.4 | 0.15 | 2.09 |
| Clustering | Accuracy | Recall | Precision | F-Measure |
|---|---|---|---|---|
| One-stage | 0.619 | 0.533 | 0.499 | 0.490 |
| Two-stage | 0.869 | 0.795 | 0.793 | 0.762 |
| Method | Data Processing | Accuracy | Recall | Precision | F-Measure |
|---|---|---|---|---|---|
| Proposed | Distributed | 0.869 | 0.795 | 0.793 | 0.762 |
| Takasaki et al. [6] | Centralized | 0.837 | - | - | - |
| Koike et al. [7] | Centralized | 0.561 | - | - | - |
| Koike et al. [8] | Centralized | 0.898 | - | - | - |
| Hattori et al. [9] | Centralized | 0.910 | - | - | - |
| Ammer et al. [10] | Centralized | 0.980 | - | - | - |
| Nguyen-An et al. [11] | Centralized | 0.940 | - | - | - |
| Okui et al. [12] | Centralized | - | - | 0.985 | - |
| Trad et al. [13,14] | Centralized | - | - | - | 0.858 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Asano, M.; Miyoshi, T.; Yamazaki, T. Internet-of-Things Traffic Analysis and Device Identification Based on Two-Stage Clustering in Smart Home Environments. Future Internet 2024, 16, 17. https://doi.org/10.3390/fi16010017
Asano M, Miyoshi T, Yamazaki T. Internet-of-Things Traffic Analysis and Device Identification Based on Two-Stage Clustering in Smart Home Environments. Future Internet. 2024; 16(1):17. https://doi.org/10.3390/fi16010017
Chicago/Turabian StyleAsano, Mizuki, Takumi Miyoshi, and Taku Yamazaki. 2024. "Internet-of-Things Traffic Analysis and Device Identification Based on Two-Stage Clustering in Smart Home Environments" Future Internet 16, no. 1: 17. https://doi.org/10.3390/fi16010017
APA StyleAsano, M., Miyoshi, T., & Yamazaki, T. (2024). Internet-of-Things Traffic Analysis and Device Identification Based on Two-Stage Clustering in Smart Home Environments. Future Internet, 16(1), 17. https://doi.org/10.3390/fi16010017