
Leveraging Internet News-Based Data for Rockfall Hazard Susceptibility Assessment on Highways




Abstract
1. Introduction
2. Materials and Methods
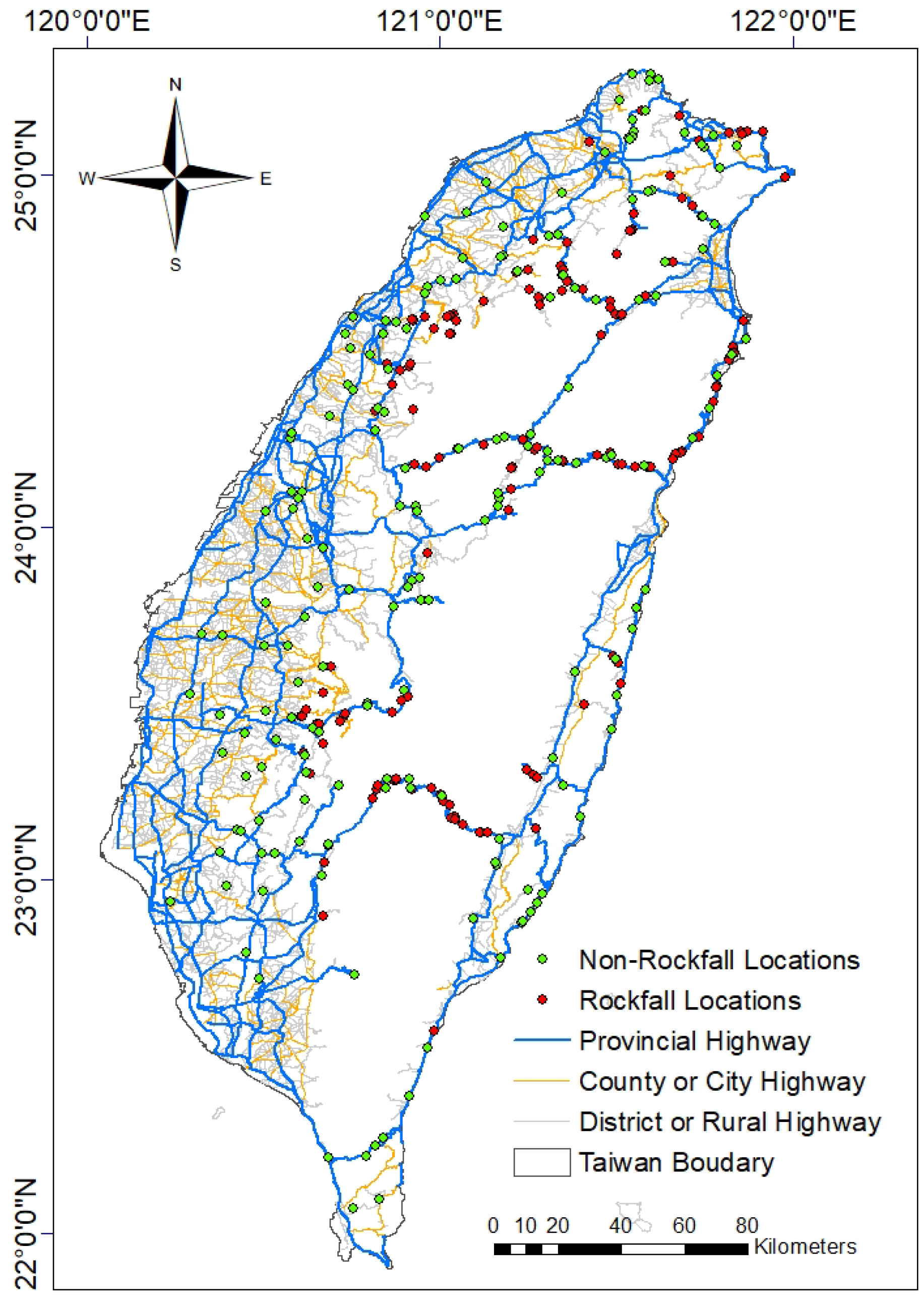
2.1. Rockfall Data Collection
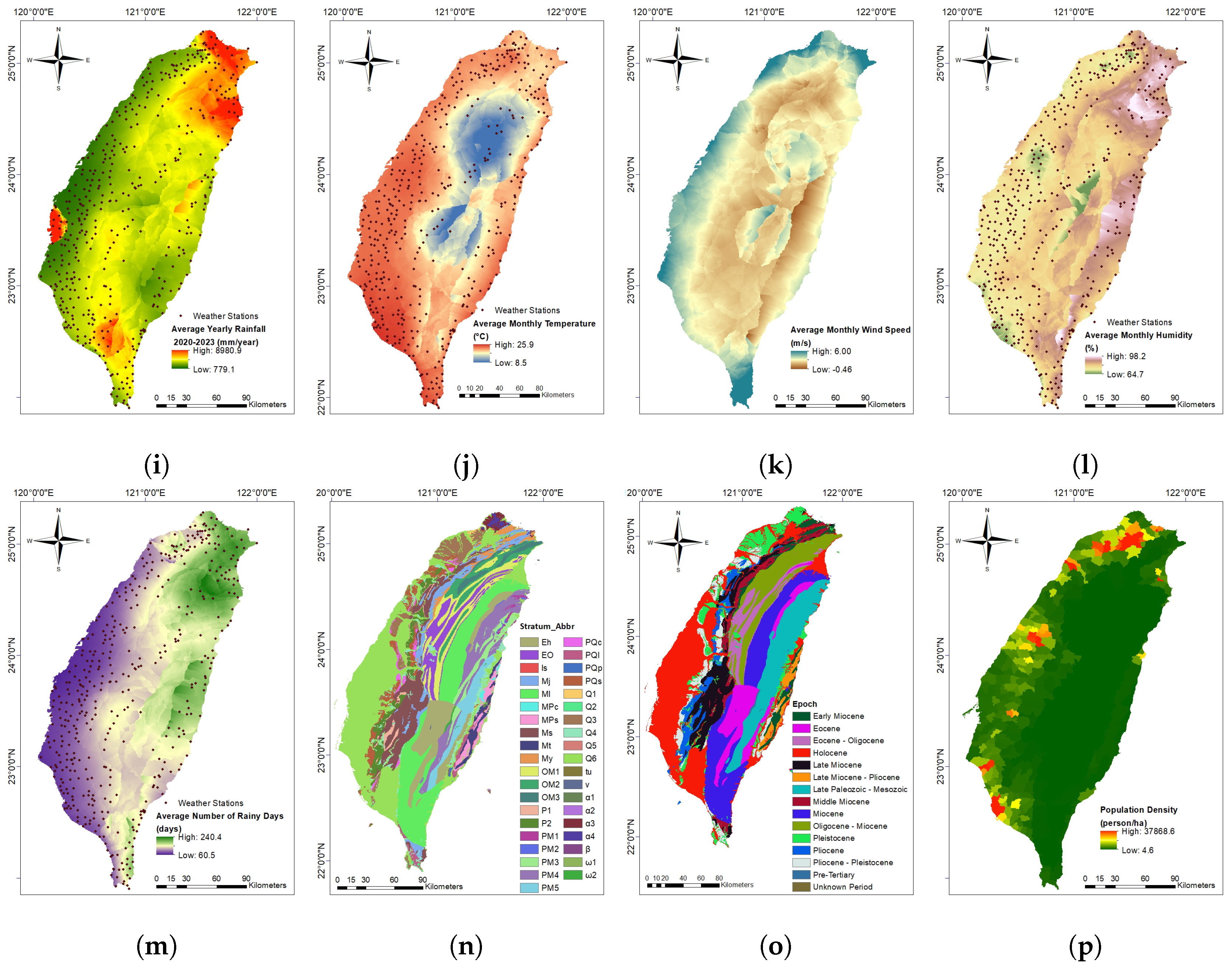
2.2. Independent Variables for Rockfall Analysis
2.3. Machine Learning and Accuracy Indices
3. Results
3.1. Random Forest Model Performance in Rockfall Prediction
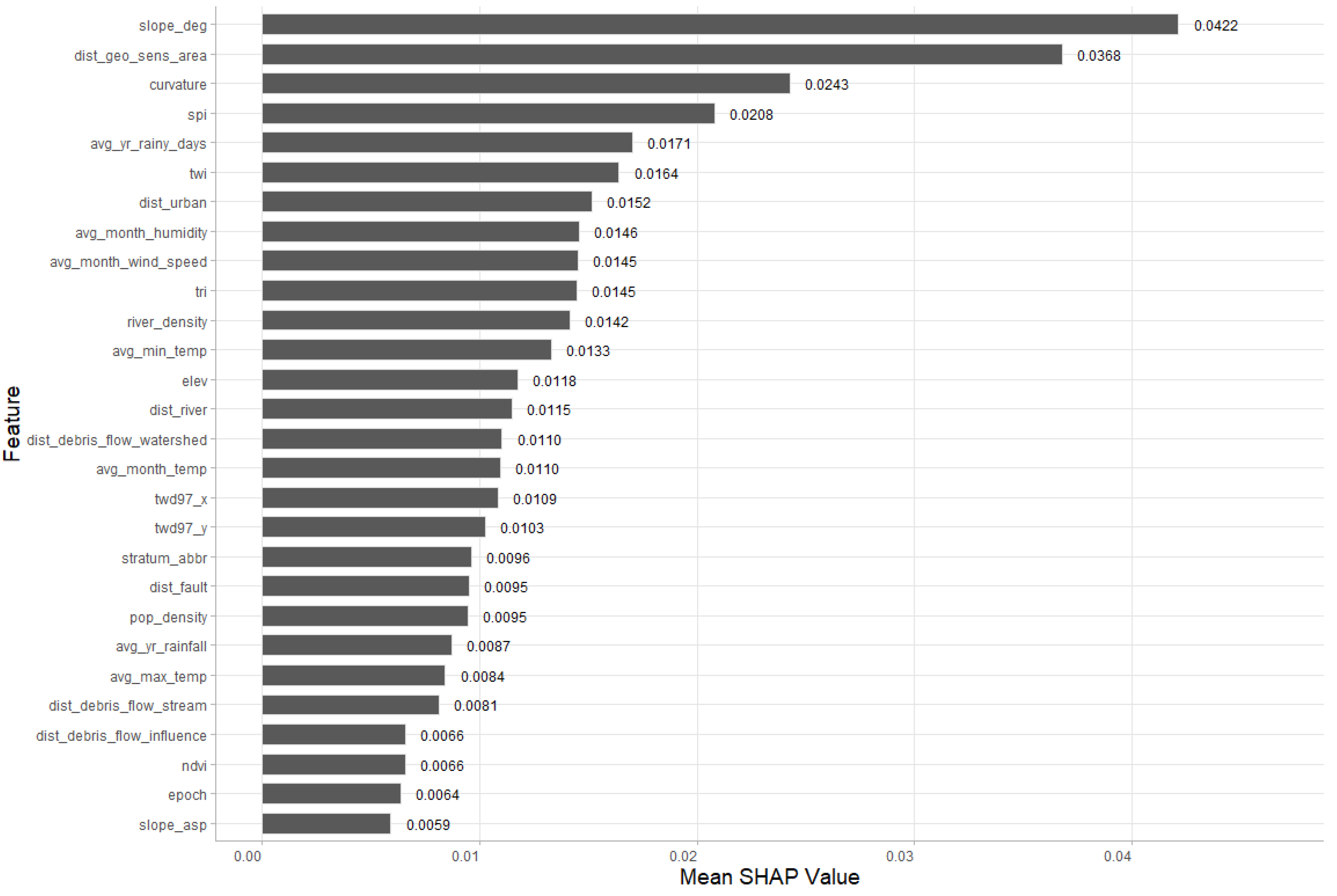
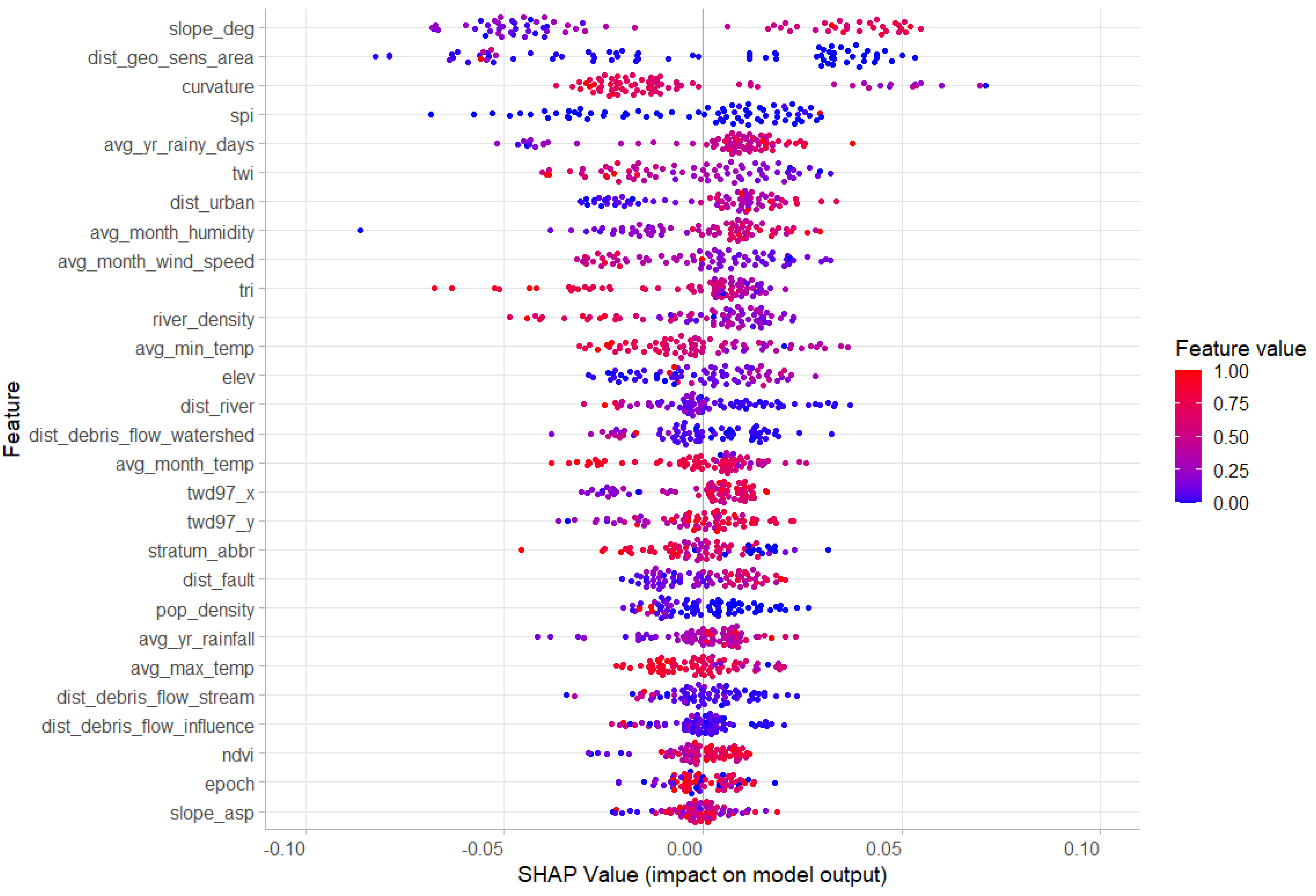
3.2. Feature Importance Visualization
4. Discussion
4.1. The Usefulness of Internet-Based Data Collection for Rockfall Hazards
4.2. Machine Learning Applications in Rockfall Hazard Prediction
4.3. Insights from SHAP Value Analysis
4.4. Practical Implications for Model Accuracy and Reliability
4.5. Limitations of the Study
4.5.1. Bias in Data Collection via Google Alerts
4.5.2. Omission of Severity of Rockfalls
4.5.3. Effects of Seasonal Vegetation and Precipitation Patterns
4.5.4. Effect of Climate Change on Model Prediction
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Varnes, D.J. Slope movement types and processes. Spec. Rep. 1978, 176, 11–33. [Google Scholar]
- Li, Z.H.; Huang, H.W.; Xue, Y.D.; Yin, J. Risk assessment of rockfall hazards on highways. Georisk 2009, 3, 147–154. [Google Scholar]
- Guzzetti, F.; Reichenbach, P.; Ghigi, S. Rockfall hazard and risk assessment along a transportation corridor in the Nera Valley, Central Italy. Environ. Manag. 2004, 34, 191–208. [Google Scholar]
- Michoud, C.; Derron, M.-H.; Horton, P.; Jaboyedoff, M.; Baillifard, F.-J.; Loye, A.; Nicolet, P.; Pedrazzini, A.; Queyrel, A. Rockfall hazard and risk assessments along roads at a regional scale: Example in Swiss Alps. Nat. Hazards Earth Syst. Sci. 2012, 12, 615–629. [Google Scholar]
- Singh, P.K.; Kainthola, A.; Panthee, S.; Singh, T.N. Rockfall analysis along transportation corridors in high hill slopes. Environ. Earth Sci. 2016, 75, 1–11. [Google Scholar]
- Cignetti, M.; Godone, D.; Bertolo, D.; Paganone, M.; Thuegaz, P.; Giordan, D. Rockfall susceptibility along the regional road network of Aosta Valley Region (northwestern Italy). J. Maps 2021, 17, 54–64. [Google Scholar]
- Shirzadi, A.; Chapi, K.; Shahabi, H.; Solaimani, K.; Kavian, A.; Ahmad, B.B. Rock fall susceptibility assessment along a mountainous road: An evaluation of bivariate statistic, analytical hierarchy process and frequency ratio. Environ. Earth Sci. 2017, 76, 1–17. [Google Scholar]
- Nanehkaran, Y.A.; Zhu, L.; Chen, J.; Azarafza, M.; Mao, Y. Application of artificial neural networks and geographic information system to provide hazard susceptibility maps for rockfall failures. Environ. Earth Sci. 2022, 81, 475. [Google Scholar]
- Wen, H.; Hu, J.; Zhang, J.; Xiang, X.; Liao, M. Rockfall susceptibility mapping using XGBoost model by hybrid optimized factor screening and hyperparameter. Geocarto Int. 2022, 37, 16872–16899. [Google Scholar]
- Kulsoom, I.; Hua, W.; Hussain, S.; Chen, Q.; Khan, G.; Shihao, D. SBAS-InSAR based validated landslide susceptibility mapping along the Karakoram Highway: A case study of Gilgit-Baltistan, Pakistan. Sci. Rep. 2023, 13, 3344. [Google Scholar]
- Dilley, M. Natural Disaster Hotspots: A Global Risk Analysis; World Bank Publications: Washington, DC, USA, 2005. [Google Scholar]
- Su, Y.-F.; Wu, C.-H.; Lee, T.-F. Public health emergency response in Taiwan. Health Secur. 2017, 15, 137–143. [Google Scholar] [PubMed]
- Tso, Y.-E.; McEntire, D.A. Emergency management in Taiwan: Learning from past and current experiences. In Comparative Emergency Management: Understanding Disaster Policies, Organizations, and Initiatives from around the World; Federal Emergency Management Agency: Emmitsburg, MD, USA, 2011. [Google Scholar]
- Executive Yuan. Overview of National Conditions: Land Transport. 2024. Available online: https://www.ey.gov.tw/state/A44E5E33CDA7E738/738c0735-9a67-4bb8-a7da-5a9b0e956461 (accessed on 26 June 2024).
- Nguyen, K.A.; Chen, W. DEM-and GIS-based analysis of soil erosion depth using machine learning. ISPRS Int. J. -Geo-Inf. 2021, 10, 452. [Google Scholar]
- Tsai, F.; Lai, J.-S.; Nguyen, K.A.; Chen, W. Determining cover management factor with remote sensing and spatial analysis for improving long-term soil loss estimation in watersheds. ISPRS Int. J. Geo-Inf. 2021, 10, 19. [Google Scholar] [CrossRef]
- Nguyen, K.A.; Seeboonruang, U.; Chen, W. Projected Climate Change Effects on Global Vegetation Growth: A Machine Learning Approach. Environments 2023, 10, 204. [Google Scholar] [CrossRef]
- Li, X.; Gong, P.; Zhou, Y.; Wang, J.; Bai, Y.; Chen, B.; Hu, T.; Xiao, Y.; Xu, B.; Yang, J.; et al. Mapping global urban boundaries from the global artificial impervious area (GAIA) data. Environ. Res. Lett. 2020, 15, 094044. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar]
- Šegina, E.; Jemec Auflič, M.; Mikoš, M.; Bezak, N. A preliminary investigation of the small rockfall triggering conditions along a road network in Slovenia. Landslides 2024, 1–13. [Google Scholar] [CrossRef]
- Usta, Z.; Akıncı, H.; Akın, A.T. Comparison of tree-based ensemble learning algorithms for landslide susceptibility mapping in Murgul (Artvin), Turkey. Earth Sci. Inform. 2024, 17, 1459–1481. [Google Scholar]
- Qi, L.; Zhou, Y.; Van Oost, K.; Ma, J.; van Wesemael, B.; Shi, P. High-resolution soil erosion mapping in croplands via Sentinel-2 bare soil imaging and a two-step classification approach. Geoderma 2024, 446, 116905. [Google Scholar]
- Jevšenak, J.; Klisz, M.; Mašek, J.; Čada, V.; Janda, P.; Svoboda, M.; Vostarek, O.; Treml, V.; van der Maaten, E.; Popa, A.; et al. Incorporating high-resolution climate, remote sensing and topographic data to map annual forest growth in central and eastern Europe. Sci. Total Environ. 2024, 913, 169692. [Google Scholar]
- Sharma, R.; Levi, M.R.; Ricker, M.C.; Thompson, A.; King, E.G.; Robertson, K. Scaling of soil organic carbon in space and time in the Southern Coastal Plain, USA. Sci. Total Environ. 2024, 933, 173060. [Google Scholar] [PubMed]
- Singha, C.; Swain, K.C.; Pradhan, B.; Rusia, D.K.; Moghimi, A.; Ranjgar, B. Mapping groundwater potential zone in the Subarnarekha basin, India, using a novel hybrid multi-criteria approach in Google Earth Engine. Heliyon 2024, 10, 1–25. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 30, 1–10. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Highway Type | Num. | Total Length (km) | Num. of Rockfall | Rockfall Roads | % Rockfall Roads | Rockfall/km |
|---|---|---|---|---|---|---|
| National Expressway | 10 | 1061.8 | 0 | 0 | 0.0% | 0.0000 |
| Provincial Highway | 97 | 5323.2 | 126 | 24 | 24.7% | 0.0237 |
| City/County Highway | 158 | 3684.1 | 19 | 13 | 8.2% | 0.0052 |
| District/Rural Highway | 2250 | 11362.7 | 37 | 16 | 0.7% | 0.0033 |
| Exclusive Highway | 35 | 407.8 | 0 | 0 | 0.0% | 0.0000 |
| No. | Variable | Description |
|---|---|---|
| Geographical Variables | ||
| 1 | twd97_y | The northing coordinate in the TWD97 coordinate system (also known as the 1997 Taiwan Datum), which is used for mapping and surveying in Taiwan. |
| 2 | twd97_x | The easting coordinate in the TWD97 coordinate system. |
| 3 | dist_river | Distance to the nearest river (meters). |
| 4 | dist_fault | Distance to the nearest fault line (meters). |
| 5 | dist_urban | Distance to the urban boundary (meters). |
| 6 | dist_geo_sens_area | Distance to the geologically sensitive area boundary (meters). |
| 7 | dist_debris_flow_stream | Distance to the potential debris flow stream (meters). |
| 8 | dist_debris_flow_watershed | Distance to the potential debris flow stream watershed boundary (meters). |
| 9 | dist_debris_flow_influence | Distance to the potential debris flow stream influence area boundary (meters). |
| Topographical Variables | ||
| 10 | elev | Elevation from 20 m resolution DEM (meters). |
| 11 | slope_deg | Slope measured in degrees. |
| 12 | slope_asp | Slope aspect. |
| 13 | curvature | Slope curvature. |
| 14 | twi | Topographic Wetness Index. |
| 15 | spi | Stream Power Index. |
| 16 | tri | Terrain Ruggedness Index. |
| 17 | river_density | River density (km/km2). |
| Environmental Variables | ||
| 18 | avg_yr_rainfall | Average yearly rainfall from 2020 to 2023 (mm/year). |
| 19 | avg_yr_rainy_days | Average number of rainy days per year from 2020 to 2023 (days). |
| 20 | avg_month_temp | Average monthly temperature from 2020 to 2023 (℃). |
| 21 | avg_min_temp | Average minimum temperature per year from 2020 to 2023 (℃). |
| 22 | avg_max_temp | Average maximum temperature per year from 2020 to 2023 (℃). |
| 23 | avg_month_wind_speed | Average monthly wind speed from 2020 to 2023 (m/s). |
| 24 | avg_month_humidity | Average monthly humidity from 2020 to 2023 (%). |
| 25 | ndvi | Normalized Difference Vegetation Index (NDVI). |
| Geological Variables | ||
| 26 | epoch | Geological time period. |
| 27 | stratum_abbr | Stratum abbreviation. |
| Socioeconomic Variables | ||
| 28 | pop_density | Population density (persons/ha). |
| 5-Fold Cross-Validation | ||||||||
|---|---|---|---|---|---|---|---|---|
| mtry | ntree | Accuracy | Kappa | Sensitivity | Specificity | Precision | F1 | |
| 1 | 1 | 100 | 0.8069 | 0.6138 | 0.8759 | 0.7379 | 0.7721 | 0.8170 |
| 2 | 1 | 500 | 0.7897 | 0.5793 | 0.8552 | 0.7241 | 0.7592 | 0.8008 |
| 3 | 1 | 1000 | 0.8000 | 0.6000 | 0.8690 | 0.7310 | 0.7654 | 0.8108 |
| 4 | 3 | 100 | 0.7931 | 0.5862 | 0.8552 | 0.7310 | 0.7669 | 0.8041 |
| 5 | 3 | 500 | 0.7862 | 0.5724 | 0.8276 | 0.7448 | 0.7688 | 0.7929 |
| 6 | 3 | 1000 | 0.7793 | 0.5586 | 0.8276 | 0.7310 | 0.7589 | 0.7879 |
| 7 | 5 | 100 | 0.7862 | 0.5724 | 0.8345 | 0.7379 | 0.7642 | 0.7946 |
| 8 | 5 | 500 | 0.7828 | 0.5655 | 0.8345 | 0.7310 | 0.7623 | 0.7924 |
| 9 | 5 | 1000 | 0.7862 | 0.5724 | 0.8276 | 0.7448 | 0.7688 | 0.7928 |
| 10 | 7 | 100 | 0.7897 | 0.5793 | 0.8414 | 0.7379 | 0.7658 | 0.7998 |
| 11 | 7 | 500 | 0.7828 | 0.5655 | 0.8276 | 0.7379 | 0.7670 | 0.7914 |
| 12 | 7 | 1000 | 0.7793 | 0.5586 | 0.8345 | 0.7241 | 0.7568 | 0.7904 |
| 13 | 9 | 100 | 0.7862 | 0.5724 | 0.8414 | 0.7310 | 0.7603 | 0.7967 |
| 14 | 9 | 500 | 0.7793 | 0.5586 | 0.8207 | 0.7379 | 0.7620 | 0.7865 |
| 15 | 9 | 1000 | 0.7931 | 0.5862 | 0.8483 | 0.7379 | 0.7702 | 0.8040 |
| 16 | 11 | 100 | 0.7690 | 0.5379 | 0.8276 | 0.7103 | 0.7473 | 0.7808 |
| 17 | 11 | 500 | 0.7931 | 0.5862 | 0.8483 | 0.7379 | 0.7679 | 0.8035 |
| 18 | 11 | 1000 | 0.7793 | 0.5586 | 0.8414 | 0.7172 | 0.7529 | 0.7914 |
| Test Dataset | ||||||||
| Accuracy | Kappa | Sensitivity | Specificity | Precision | F1 | |||
| 0.8514 | 0.7027 | 0.8378 | 0.8649 | 0.8611 | 0.8493 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, K.A.; Jiang, Y.-J.; Huang, C.-S.; Kuo, M.-H.; Chen, W. Leveraging Internet News-Based Data for Rockfall Hazard Susceptibility Assessment on Highways. Future Internet 2024, 16, 299. https://doi.org/10.3390/fi16080299
Nguyen KA, Jiang Y-J, Huang C-S, Kuo M-H, Chen W. Leveraging Internet News-Based Data for Rockfall Hazard Susceptibility Assessment on Highways. Future Internet. 2024; 16(8):299. https://doi.org/10.3390/fi16080299
Chicago/Turabian StyleNguyen, Kieu Anh, Yi-Jia Jiang, Chiao-Shin Huang, Meng-Hsun Kuo, and Walter Chen. 2024. "Leveraging Internet News-Based Data for Rockfall Hazard Susceptibility Assessment on Highways" Future Internet 16, no. 8: 299. https://doi.org/10.3390/fi16080299
APA StyleNguyen, K. A., Jiang, Y.-J., Huang, C.-S., Kuo, M.-H., & Chen, W. (2024). Leveraging Internet News-Based Data for Rockfall Hazard Susceptibility Assessment on Highways. Future Internet, 16(8), 299. https://doi.org/10.3390/fi16080299