Abstract
With the increasing application of web services in varying fields, the demand of effective Web service discovery approaches is becoming unprecedentedly strong. To improve the performance of service discovery, this paper proposes a collaborative Web service discovery and recommendation mechanism based on social link by extracting the latent relationships behind users and services. The presented approach can generate a set of candidate services through a complementary manner, in which service discovery and service recommendation could collaborate according to the formalized social link. The experimental results reveal that the proposed mechanism can effectively improve the efficiency and precision of Web service discovery.
1. Introduction
Web service can realize interoperable interactions between different machines via standard interfaces and communication protocols without the aid of additional third-party software or hardware. As an important innovation in service computing, more and more Web services are developed and published to the Internet. Therefore, service discovery is becoming a critical problem in service application. According to a survey [1], although there are a huge number of services advertised on the Web, about 75% of them have not been used, and only 16% of these services have been discovered or invoked. The main reasons are: most existing discovery methods only consider services as isolated functional islands with no links to related services, and they usually deal with each user and each request in isolation instead of mining and utilizing the latent social relationship among them [2].
To address these problems, in this paper, we propose a new method that differs from existing approaches in that: (1) we pay more attention to the potential social relations between users and services in the whole process of Web service discovery; (2) we redefine and formalize the social link through mining and defining typical link factors; and (3) we present a collaborative mechanism with high flexibility and satisfied performance. In this way, our proposal tackles the opportunity of exploiting social links to improve the performance of service discovery. Experimental results show that compared with similar methods, the proposed method has higher efficiency and precision.
The rest of this paper is organized as follows. Section 2 discusses the application and significance of social information in service discovery. Section 3 details our definitions about link factors and the formalization of social link. A collaborative discovery and recommendation mechanism based on social link is described in Section 4 before conducting the experimental evaluations in Section 5. The conclusion is given in Section 6.
2. Related Work
From recent research, leveraging latent user social information in the process of Web service discovery to improve the performance of discovery result is a feasible and effective method. In [3], the concept of community and the metaphor of social networking were discussed to build a framework to managing Web services, in which a community was proposed to gather Web services that offer similar functionalities together, and a social networking was designed to capture all interactions that occur between services located in the same or separate communities. Z. Maamar et al. discussed the intertwining of social networks of users and social networks in [4]. They used the former to help users select the necessary services, and adopted the latter to permit extending these services with new services or maintaining the operation continuity in case of failure. To maximize the utilization of limited network resources, a hybrid service-demand discovery architecture for mobile social networks was introduced in [5], in which users can discover their relationships with others based on the historical data of movement. In order to address the problems of the isolation of services and the lack of social relationships in Web service discovery, Chen et al. presented a global social service network connecting the isolated service islands to enhance the services’ sociability on a global scale in [6]. The network can be constructed following linked social service-specific principles based on complex network theories. In [7], Kalai et al. proposed a web service discovery process based on users’ queries and their social profiles that can be extracted from their egocentric network. The process employs the best social friendships of the current user and the past invocation histories with satisfactory web services of his friends to generate satisfactory results. To limit the disadvantages of distributed approaches, a novel distributed reputation model was presented in [8], which treats multi-agent systems as social networks and leverages social relations among these agents.
Some typical social factors such as trust and clustering are also widely discussed in service discovery. A novel evaluation model for Web Service discovery by leveraging trust as an approach was introduced in [9]. The authors incorporated a trust management module into the standard Service Oriented Architecture and transformed a Web Service network to a small-world network based on the trust relationships of service entities. Then they proposed a trust evaluation model with an amendatory subjective logic. In [10], a trusted service discovery method based on trust and recommendation relationships was presented. In this method, two types of trust relationships and an open service network were both defined, and a dynamic service discovery algorithm was also proposed. Based on the intuition that a user’s web service QoS usage experiences can be predicted by both the user’s own characteristics and the past usage experiences of other similar users, Z. Zheng et al. proposed a neighborhood-integrated matrix factorization approach for making personalized prediction in service discovery and service selecting [11], which could systematically fuse the neighborhood-based and model based collaborative filtering approaches to achieve higher prediction accuracy. A new service discovery method based on referral network and ant-colony algorithm was proposed in [12]. The approach can make use of recommendation and ant colony algorithm to improve the success and recall rate of service discovery. Based on friend relationships and interaction behaviors, a new recommender approach was introduced in [13]. The approach adopted a trust computing method and depended on an authentic social network to obtain more authentic neighbors to improve the accuracy of recommendations. In order to acquire satisfactory performance-based service discovery/selection, Q. Duan suggested that it is important for both service providers and service consumers to obtain thorough understanding of performance of service provisioning [14]. To tackle the challenge, a new model for characterizing the service provisioning capabilities of converged systems was presented, and the analysis techniques for evaluating performance were also developed.
All the above studies show that it is a non-trivial task to leverage social information to improve the performance of service discovery. However, as mentioned above, most of the tasks are still troubled by low precision and low efficiency. Therefore, in this paper, we are motivated to investigate how social link could benefit Web services discovery by reducing the retrieval time and improving the accuracy of results.
3. Social Link
Different from the general definition in social network, in this paper, we define social link in another way and exploit it to capture the interaction relationships that influence the performance of Web service discovery, which are similar to those found in people’s daily life such as reputation, clustering, preference and trust. More specifically, we decompose the social link in Web service discovery into four factors: reputation degree, clustering link, preference link and trust link, which can be defined as follows.
3.1. Link Factors
3.1.1. Reputation Degree
Ontology is essentially a conceptual framework that gives a set of terms to identify a set of concepts. In addition, domain ontology is a professional ontology that describes the concepts and the relationship between concepts in a particular field. In our previous study [2], we have proposed a user personalization model based on ontology technology. Therefore, for a specific user, by analyzing and refining his/her historical operation records, we can mine their interesting points which performance as local nodes of domain ontology. In other words, each personalization model is a sub-tree of an ontology tree.
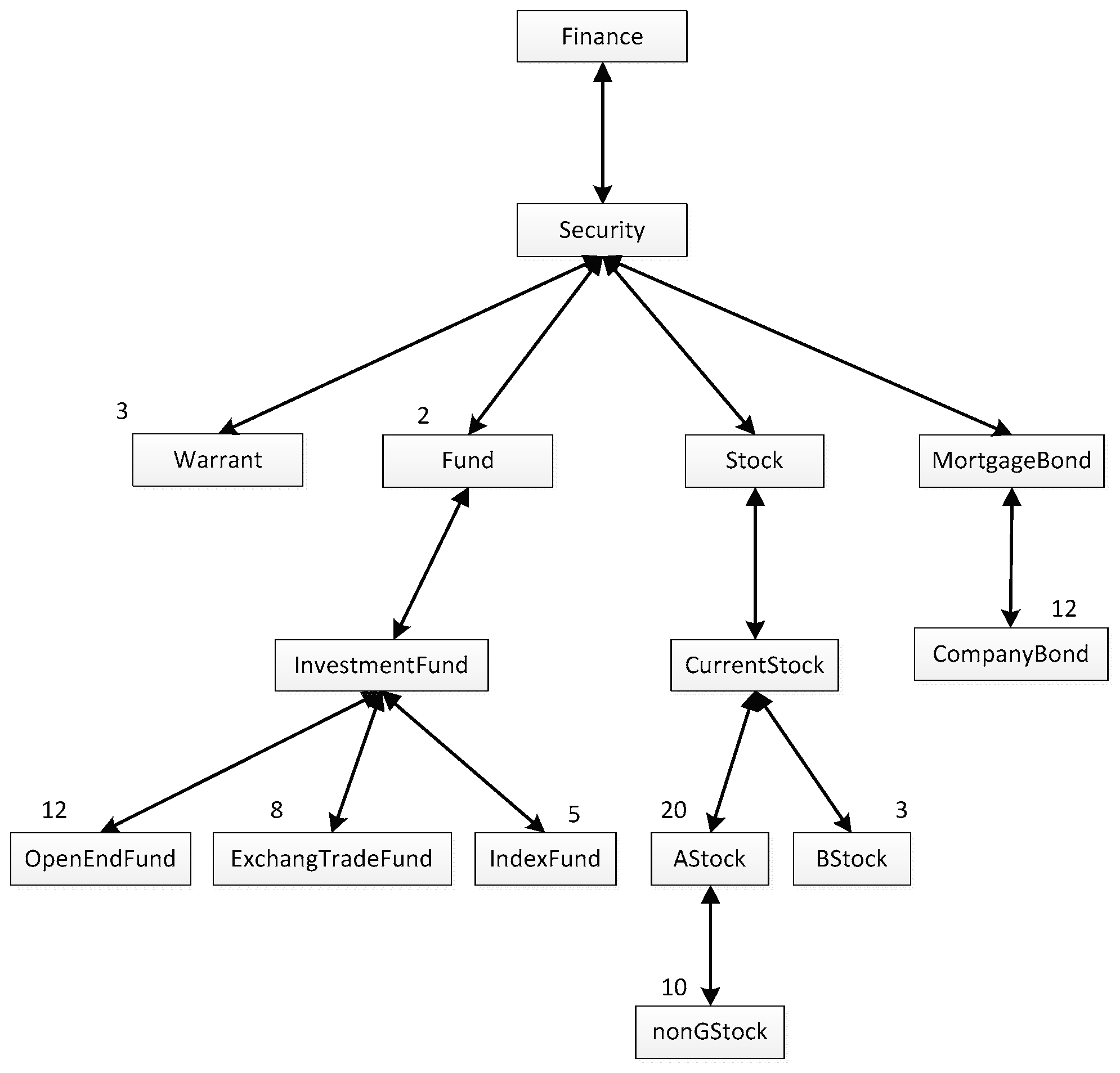
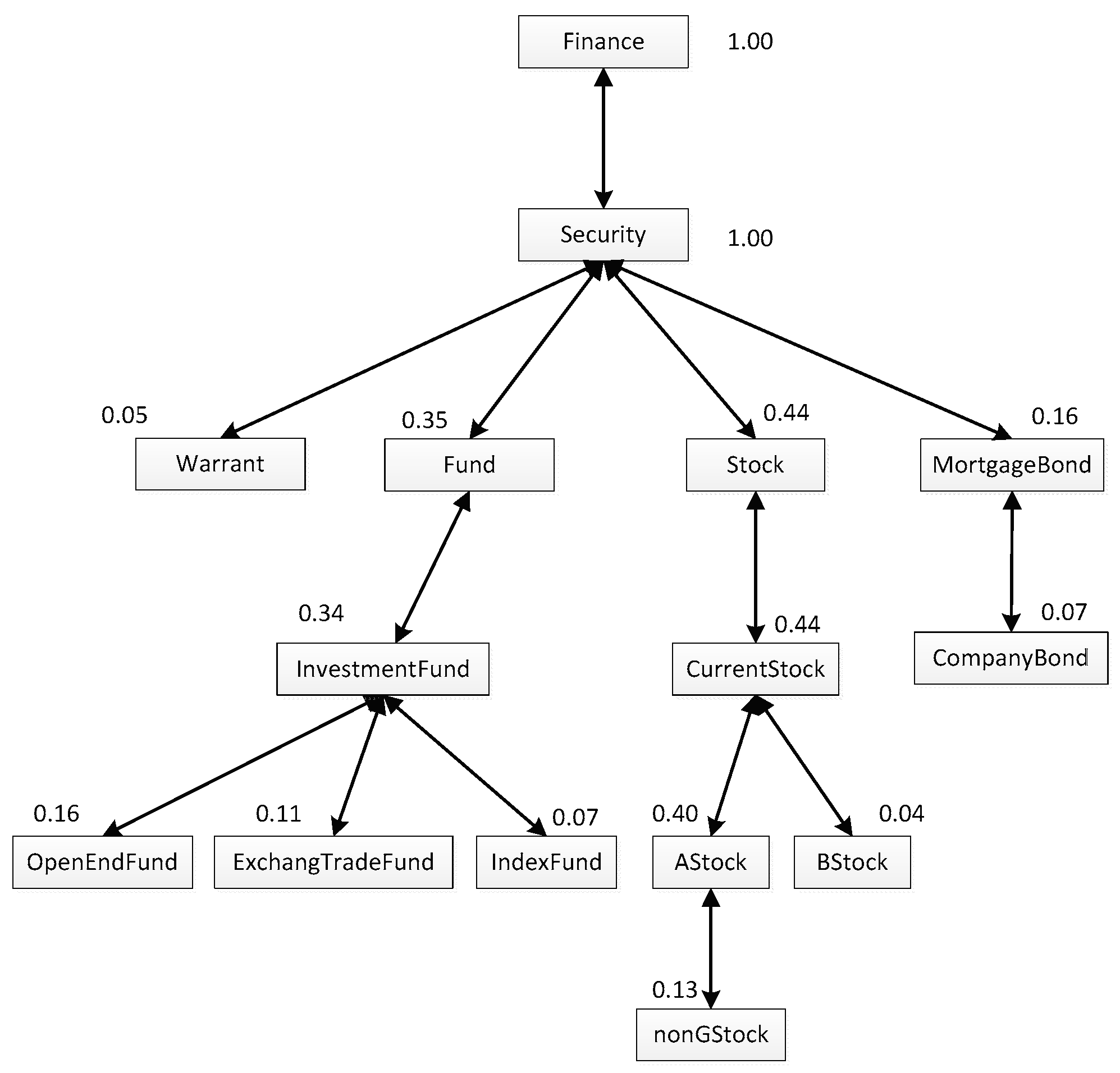
For instance, if the numbers of ontology concepts called by the user ua can be gained based on his/her operation history and the distribution of the numbers can be shown as Figure 1, in which the number above each box represents the number of calls to the concept in the box, it can be concluded that the total number of ontology concepts called by ua is 75, then, ua’s interestingness in each concept can be calculated, for example, the interestingness in concept “CompanyBond” is 12/75, which is 0.16. It is worth noting that although the number of concept “InvestmentFund” called is zero, since it is the parent concept of concept “OpenEndFund”, concept “ExchangeTradeFund” and concept “IndexFund”, the interestingness in it is actually 0.34.
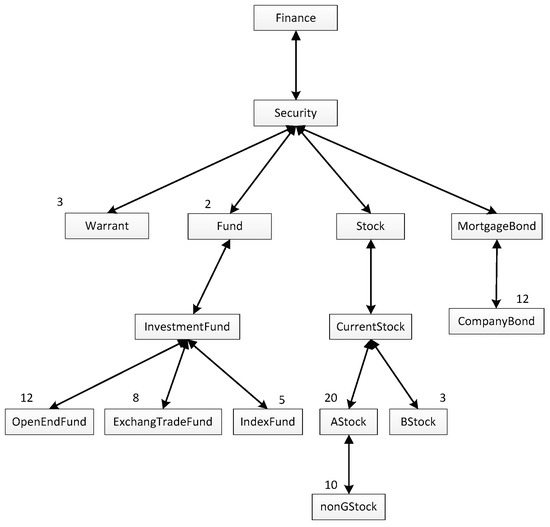
Figure 1.
The distribution of the numbers of ontology concepts called by ua.
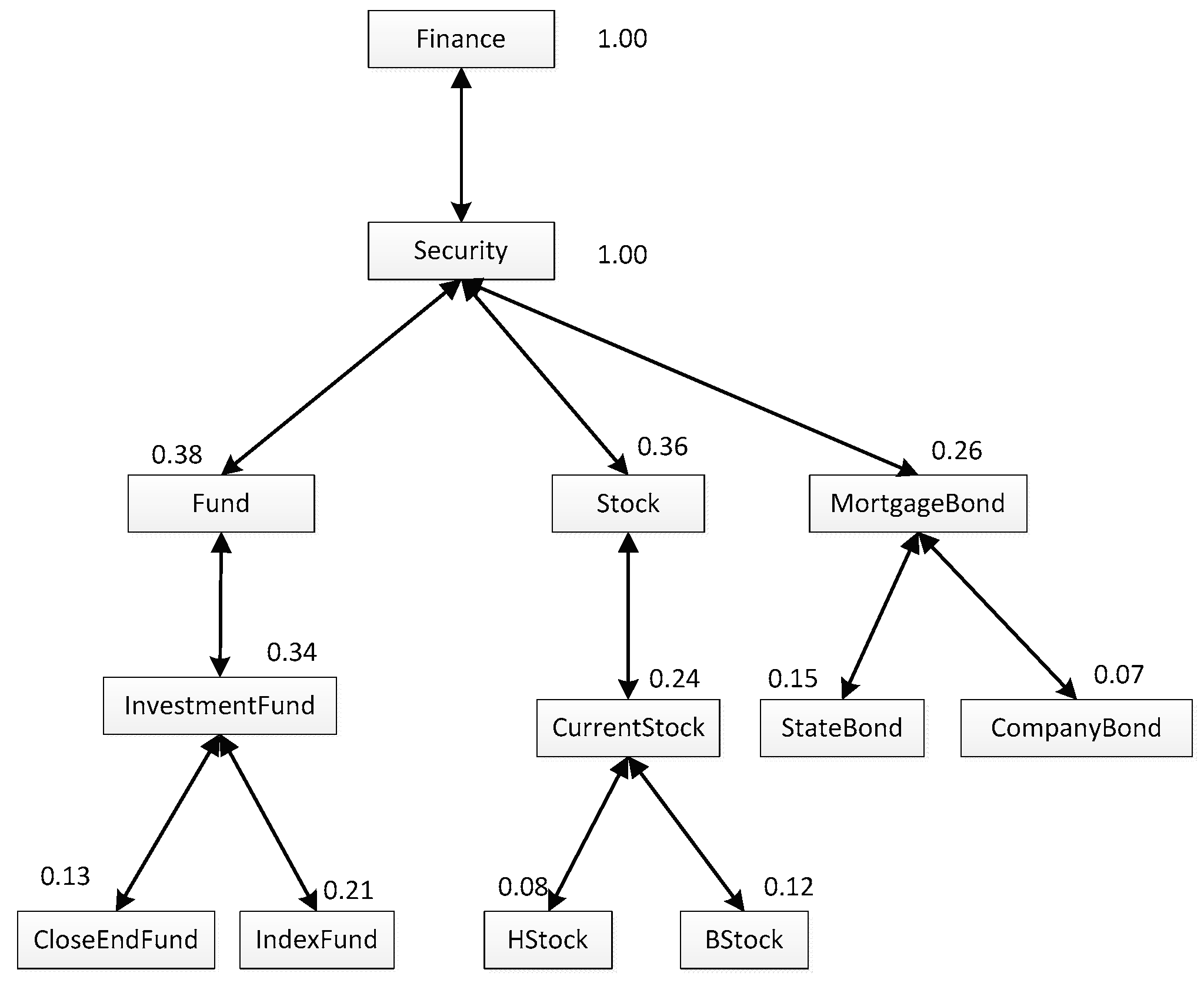
Replacing the numbers of concept called in Figure 1 with the calculated interestingness, the user personalization model of ua can be obtained, which is shown as Figure 2. Compared with Figure 1, it has the same tree structure, and the main difference is that there is a value above each concept box.
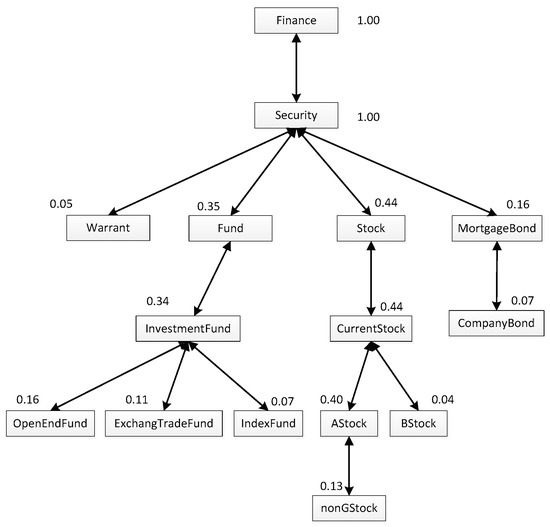
Figure 2.
The user personalization model of ua.
Based on the proposed user personalization model, we define a user’s Reputation Degree (RD) is the proportion of the quantity of the concepts in his/her personalization model to the quantity of the whole concepts in the corresponding ontology.
where, RDm is the Reputation Degree of user um; Nm means the quantity of the concepts in the personalization model of um; No is the quantity of the whole concepts in the corresponding ontology. For example, if the personalization model of user ua is shown as Figure 1, and the quantity of the whole concepts in the Finance Ontology is 100, that is, Na = 15, and N0 = 100, then RDa = 0.15.
3.1.2. Clustering Link
Clustering Link (CL) contains two sub-classes: Service Clustering Link (SCL) and User Clustering Link (UCL), the former is the set of services and their similarities, which is described as Equation (2).
where, SCLi denotes the Service Clustering Link of Web service wsi; SSimij is the service similarity between wsi and wsj, and SSim0 is the threshold of it.
A representation of a service specification was introduced in [15], which can be shown as following:
- A service profile P = ⟨sn; ʘ⟩ consists of a service name sn and a set ʘ of operations.
- An operation O∈ʘ has a name O:n and a set O:IN and O:OUT of inputs and outputs: O = <n; IN; OUT>. For example, P:sn is the service name, and P:ʘi:INj is the j-th input of the i-th operation.
Based on the representation, we can calculate the similarity SSimij by Equation (3).
where, wsi.sn and wsi.o are respectively the name and the set of function properties of wsi; NSim(·) and FSim(·) are the similarity functions proposed in [2]; additionally, 0 < ω1, ω2 < 1 and ω1 + ω2 = 1.
Similarly, User Clustering Link can be defined as the set of users and their similarities, which is described as Equation (4).
In this equation, UCLm denotes the User Clustering Link of user um; USimmn is the user similarity between um and un, and USim0 is the threshold of it.
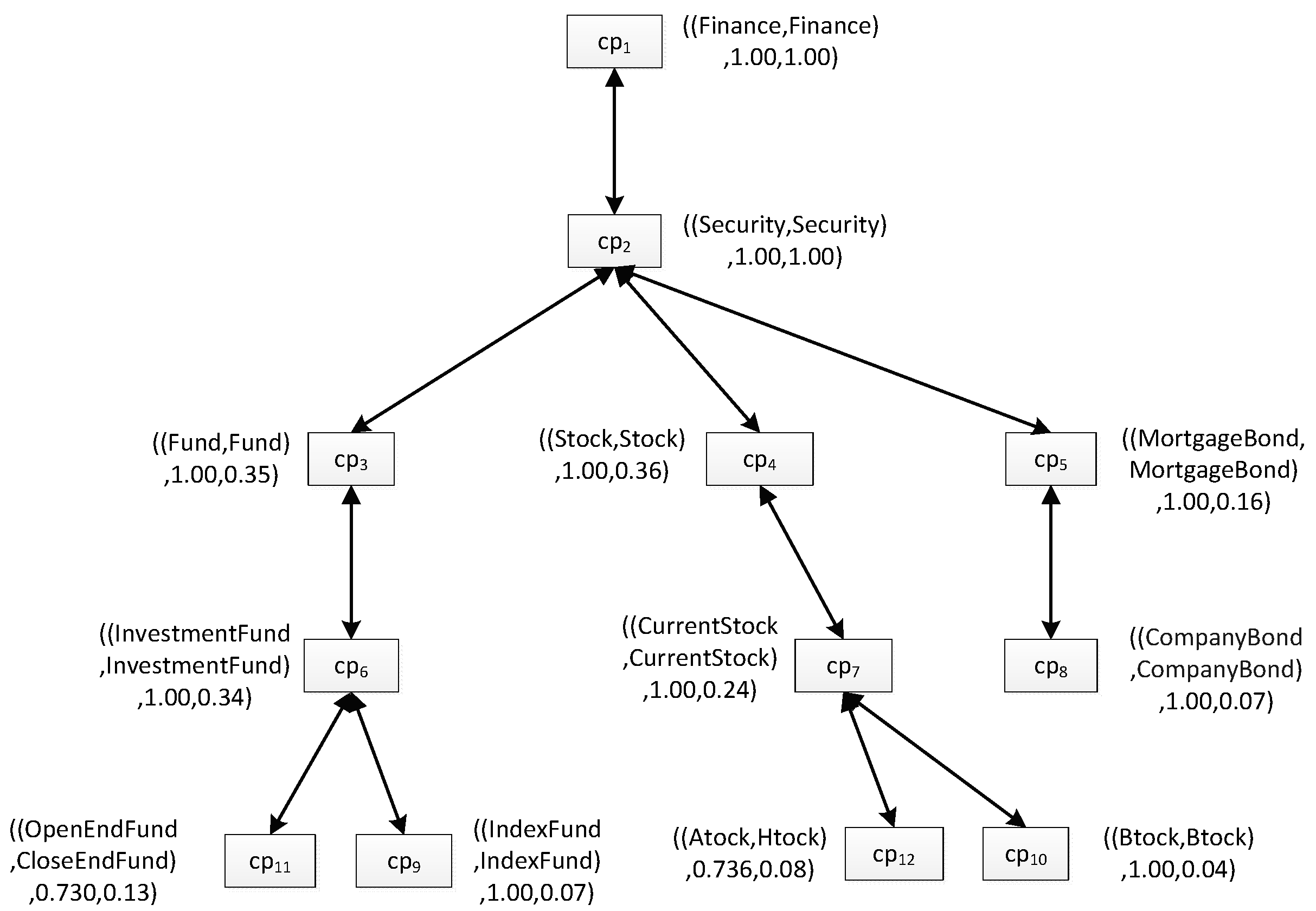
In our view, we can get the value of a user similarity between two users by comparing their personalization models. For example, if there is another personalization model of ub which is shown as Figure 2, then, based on the pruning strategy proposed in [2], we can construct a matching tree between Figure 2 and Figure 3, which is shown as Figure 4. Different from the personalization model, each box in the match tree has a concept pair instead of a single concept, and near to the box is a description of the concept pair. The description is always a triple such as “((AStock, HStock), 0.736, 0.08)”, specifically, the first element describes the two concrete concepts in the concept pair; the second one is the similarity between the two concepts; and the last one is the minimum interestingness in them.
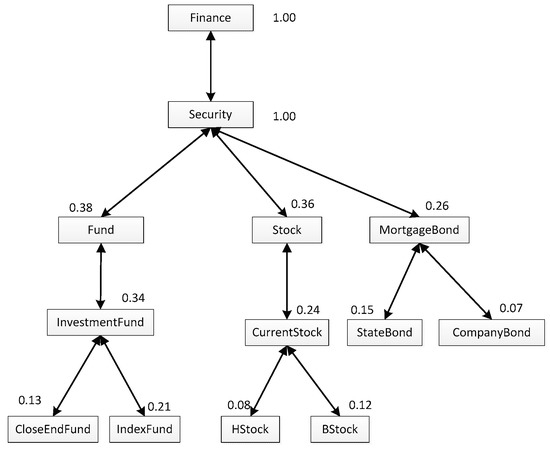
Figure 3.
The user personalization model of ub.
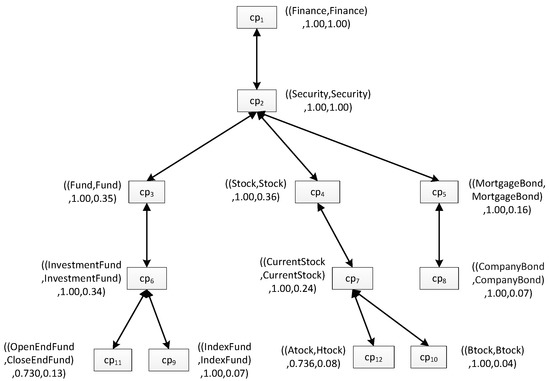
Figure 4.
The matching tree between the user preference models of ua and ub.
Based on the match tree, we can calculate the value of the user similarity between users according Equations (5) and (6), for ua and ub, the user similarity USimab = 0.68.
where, MT represents the matching tree between user preference models; S(cpk) is the distance between concept ci and concept cj; par(cpk) is the parent node of cpk; Intr(ci) means the interestingness in concept ci; D(cpk) is the depth of cpk; DOa signifies the depth of user personalization model Pa; N(ck) denotes the density of concept ck; FDOab is the floor depth between user personalization model Pa and user personalization model Pb, and RDOab is the roof depth between them. Their definitions and calculations are shown in [2].
3.1.3. Preference Link
A user’s Preference Link (PL) is described as Equation (7), it is defined as the set of services invoked by him/her and corresponding experience.
where, PLm means the Preference Link of user um; eim is the experience of um on service wsi, it is essentially the rating value of wsi by um, specifically, to formalize the experience, we normalize eim with integers in the range from 1 to 5, eim = 5 means the best experience and eim = 1 denotes the poorest experience, and e0 is the threshold of it.
3.1.4. Trust Link
A user’s Trust Link (TL) is designed to formalize the relation between him/her and his/her trusted friends, it is the set of users that ever recommended service to him/her and corresponding trust degree, which is described as Equation (8).
For the user um, TLm is his/her Trust Link; TDgrmn is the trust degree to user un, and TDgr0 is the threshold of it. TDgrmn can be calculated by Equation (9).
where, SR is the set of services that un has recommended to um, and |SR| is the number of services in it; emax is the maximum value in the normalization range. Normally, |SR| ≠ 0, otherwise, the link between the two uses will be released.
3.2. Formalization of Social Link
Based on the above factors, we formalize the Social Link (SL) in Web service discovery as a tetrad shown as Equation (10).
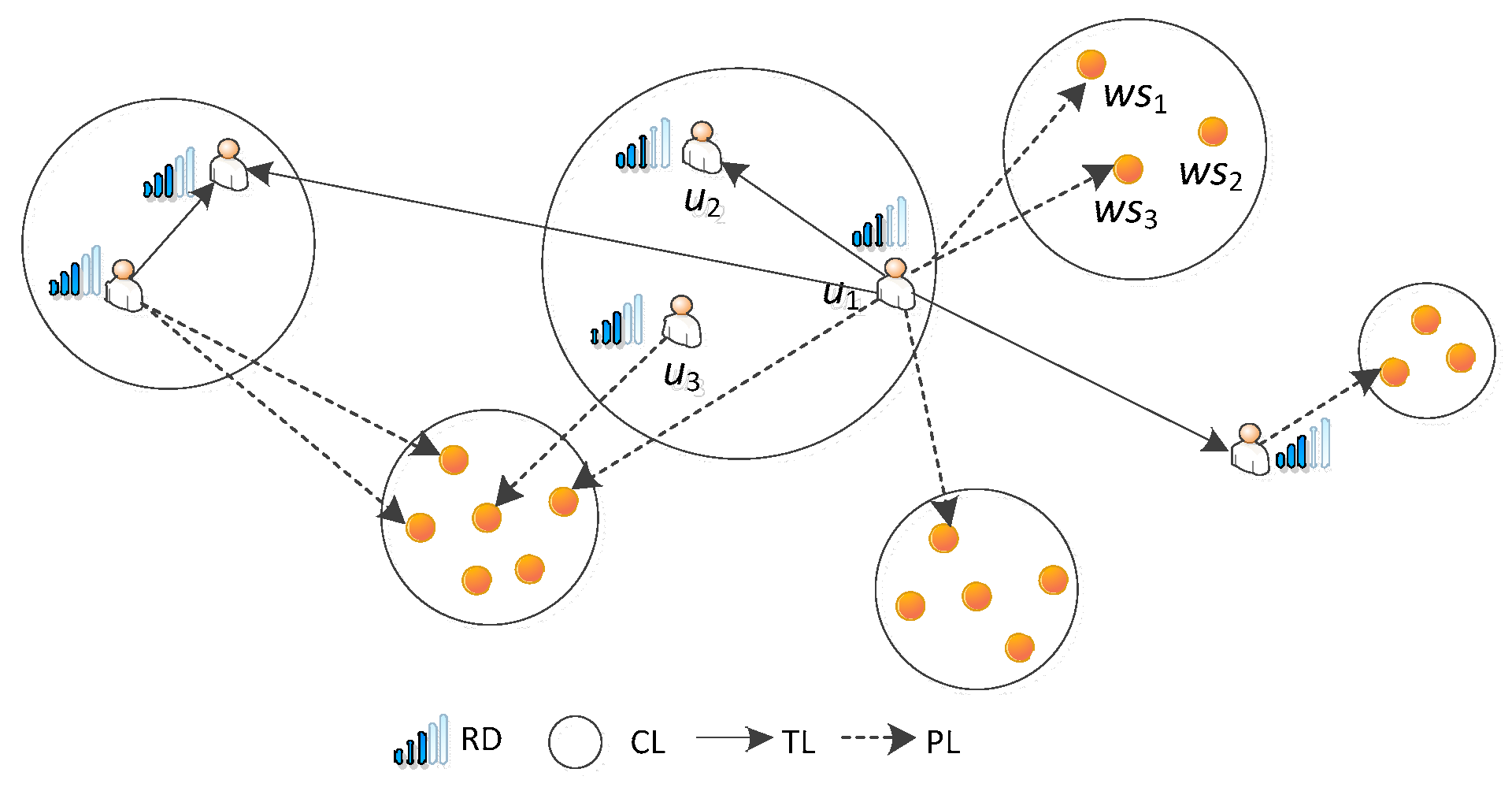
Figure 5 shows an instance of Social Link. In this instance, there are two users: u2 and u3, in the User Clustering Link of u1, and his/her Preference Link contains four services and, moreover, they belong to three different Service Clustering Links.
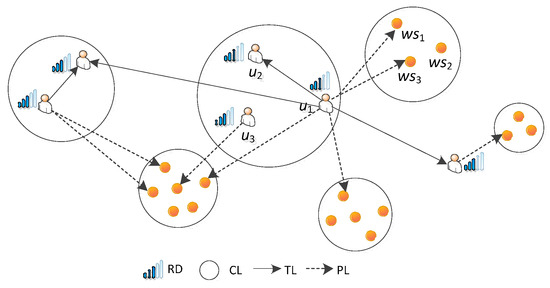
Figure 5.
Instance of a formalized social link.
4. Discovery and Recommendation Mechanism Based on Social Link
In this section, we propose a Collaborative Web Service Discovery and Recommendation Mechanism (CSDRM) to further select or recommend a subset of services over SL. First we introduce the basic algorithm of service discovery based on Clustering Link and Preference Link (DCLPL). Then we present an auxiliary algorithm of service recommendation based on Reputation Degree and Trust Link (RRDTL).
4.1. DCLPL
Given a user request, DCLPL performs search starting from the user’s Preference Link to his/her Clustering Link, to narrow the search scope gradually, while matching the latent candidates preferentially.
| Algorithm DCLPL. |
| Input: user um’s request r |
| Output: candidate service list L1 |
| 1. initialize um’s Social Link SLm; |
| 2. set L0 = and L1 = ; |
| 3. for each wsi∈PLm do // query the service collection in the preference link |
| 4. calculate the similarity RSimi between wsi and r; // calculate and compare the matching degree |
| 5. if RSimi > RSim0 do |
| 6. add wsi to L1 // add the service into the candidate list |
| 7. else |
| 8. add wsi and each wsl∈SCLi to L0 // add the service and its service collection in the clustering |
| link into the unfit list |
| 9. end if |
| 10. for each wsj∈SCLi∧wsj∉L0 do // query other services in the clustering link of current |
| service and not into the unfit list |
| 11. repeat from step 4 to step 9 |
| 12. end for |
| 13. end for |
| 14. for each un∈UCLm do // query the user collection in the current user’s clustering link |
| 15. for each wsk∈PLn∧wsk∉L0 do |
| 16. repeat from step 4 to step 12 |
| 17. end for |
| 18. end for |
| 19. for each remained wsp∉L0 do // query remained services |
| 20. repeat from step 4 to step 6 |
| 21. end for |
| 22. return L1 |
In the above algorithm, we calculate RSimi by Equation (11):
Similar to Equation (3), r.sn is the user’s demand for service name, and r.o is the user’s demand for service functions. Additionally, the value setting of ω1 and ω2 is same with Equation (3).
4.2. RRDTL
If the user’s request conditions are too restrictive or the request statements are vague, L1 will be empty, then, CSDRM will recommend a candidate service set by performing RRDTL algorithm.
| Algorithm RRDTL |
| Input: um’s Social Link SLm, user um’s request r |
| Output: candidate service list L1 |
| 1. if L1 = do |
| 2. for each un∈TLm do // query the user collection in the current user’s trust link |
| 3. for each wsi∈PLn do // query the service collection in each user’s preference link |
| 4. calculate Ri = RSimi* (1 + RDi); // calculate the reliability of each service |
| 5. end for |
| 6. add wsi which has the maximum Ri to L1; // select the most reliable service |
| 7. end for |
| 8. rank services in L1 by Ri and remain Top-k services |
| 9. return L1 |
| 10. end if |
5. Experiment and Analysis
To evaluate the performances of CSDRM, we conducted following experiments, in which we considered three comparison partners: Ant-Algorithm-Based Service Discovery Algorithm (ABSDA) [12], Trustworthy Service Discovery based on Trust and Recommendation relationships (TRTSD) [10] and Random Ergodic Matching (REM) [16]. ABSDA adopts recommendation mechanism in service discovery, TRTSD can reduce the searching path and search trusted services by exploiting trust and recommendation relationships, and they are partly similar to CSDRM on the principles of algorithms. REM is actually a flooding algorithm, and we select it to highlight the comparison effect.
5.1. Experimental Setup
We constructed the same experiment environment with [16], namely, we created 10 different requests, and performed the experiments with service number being [300, 400, 500, 600, 700, 800, 900, 1000] respectively. Eventually, we adopted the average efficiency (ACT) and the average precision (AP) that were defined in [16] as the metrics to compare the four methods. The average completion time refers to the time from matching the service according to the parsed request to returning the list of results, and the average precision can be described as Equation (12):
where, nT is the number of services that meet user’s requirements in the returned results, and nF is the number of services that cannot fully meet the user’s requirements.
5.2. Parameters Evaluation
From the above analysis, it can be found that the specific values of some parameters will affect the performance of our proposed algorithm. Furthermore, since ω1 is the weight of service name and ω2 is the weight of service operation, in our previous study [2], we have drawn a conclusion that ω1 = 0.3 and ω2 = 0.7 is reasonable. Thus, in order to evaluate the influence and decide the suitable value of these parameters, we compared the average efficiency and the average precision of CSDRM with different values of the key parameters in it. Here, we set RSim0 = 0.4 and k = 5.
Table 1 provides the results of the average efficiency and the average precision of CSDRM with different values of the key parameters. We can observe that the greater the values of parameter SSim0 and parameter USim0, the lower the efficiency and the higher the precision of the algorithm, and in the case of invariant parameter SSim0 and parameter USim0, the higher the value of parameter TDgr0, the higher the efficiency and the less change in precision. On the whole, when SSim0 = 0.5, USim0 = 0.5 and TDgr0 = 0.2, the algorithm can achieve a better balance between efficiency and precision.

Table 1.
Comparison with different values of the key parameters in CSDRM.
5.3. Top-k Analysis
To analyze the effect of parameter k on the performance of the algorithms, we define a new precision metric:
where, k is the concrete value of Top-k, and nk is the number of services that meet the user’s requirements in the Top-k services.
In this experiment, we set SSim0 = 0.5, USim0 = 0.5, TDgr0 = 0.2 and RSim0 = 0.4, use the same requests and candidate services, and compare the average precision of the four approaches in the conditions of k = 5, 8 and 10.
Table 2 shows the results of the average precision of the four approaches with different values of k. It can be seen that our proposed method achieves the best precision results among these four approaches from beginning to end. For the synthetic precision, CSDRM achieves 5.05~71.39% improvements. It is also clear that the methods work best when k = 5.
Table 2.
Precision comparison of Top-k effect.
5.4. Efficiency and Precision Comparison
We conducted this experiment to compare the efficiency and precision of these four methods, and based on the above analysis, we set ω1 = 0.3, ω2 = 0.7, SSim0 = USim0 = 0.5, e0 = 3, TDgr0 = 0.2, RSim0 = 0.4 and k = 5.
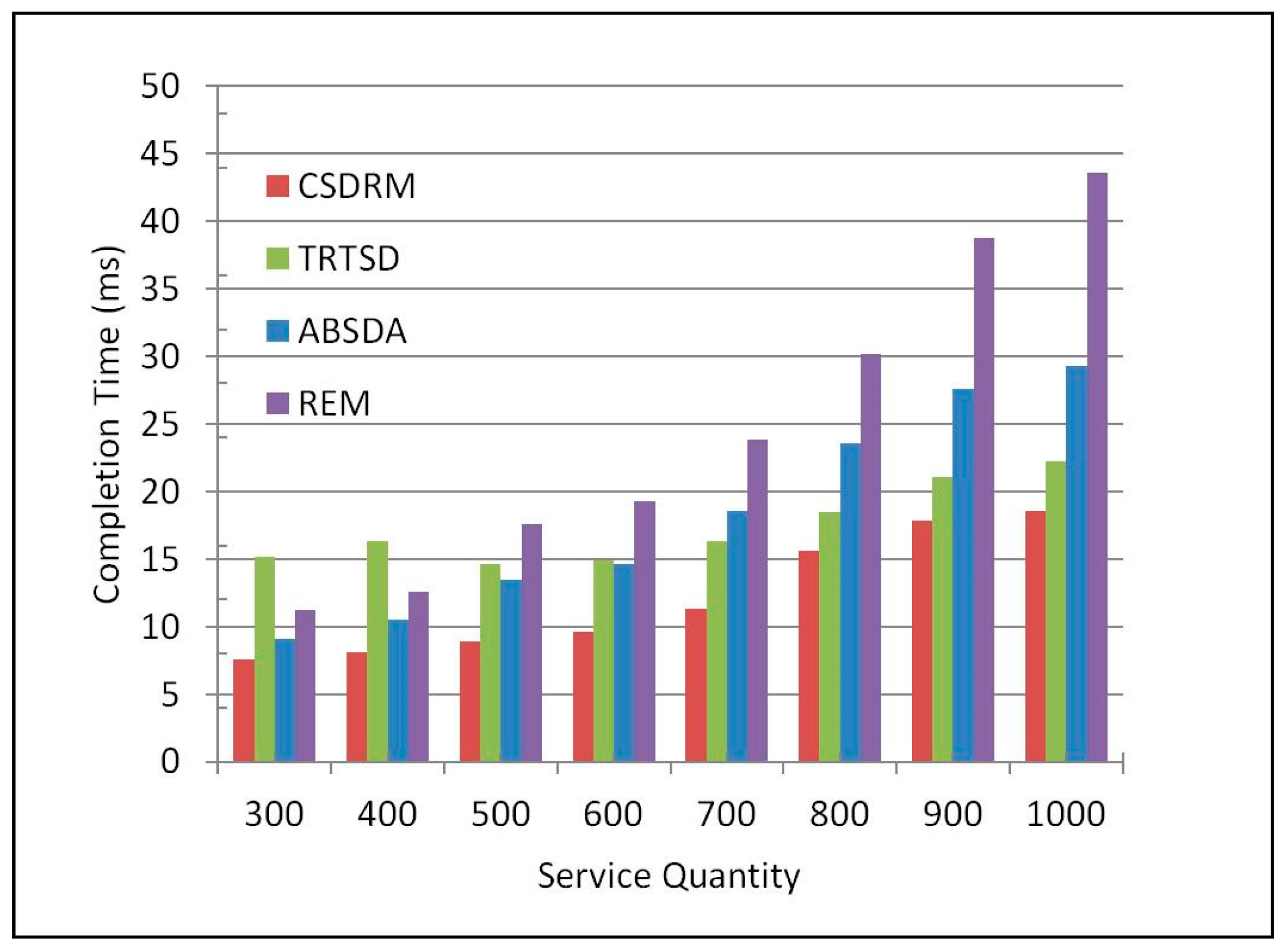
Figure 6 shows the average efficiency. It is obvious that the completion time is getting longer as the number of services increases. Among these four methods, CSDRM costs the shortest completion time from beginning to end. Specifically, compared with the flooding algorithm REM, the completion time of CSDRM is improved by 50.53% on average; compared with the Ant-Algorithm-Based algorithm ABSDA, the completion time is increased by 33.58% on average; and compared with the trust and recommendation based algorithm TRTSD, and the completion time is increased by 29.91% on average. This is because CSDRM can rapidly narrow the scope of matching based on SL, discard irrelevant services. Comparing with the others, it has the minimum number of services required to be matched. The results indicate that CSDRM can improve the efficiency of Web service discovery effectively.
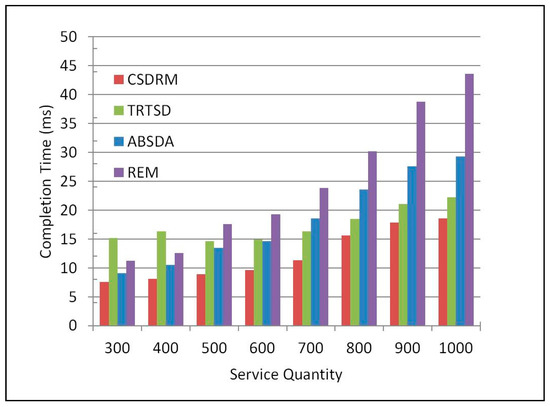
Figure 6.
Comparison of efficiency.
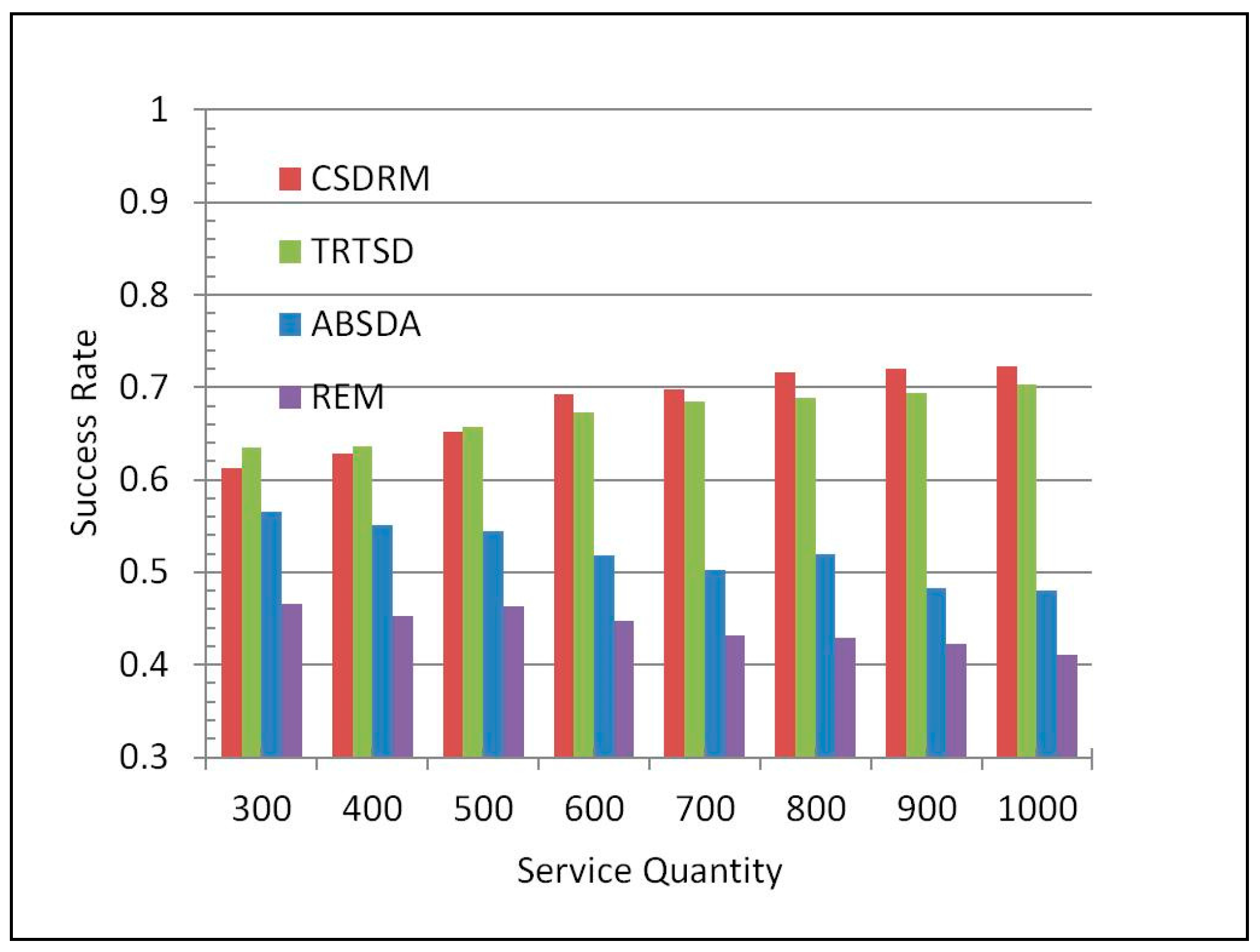
Figure 7 describes the result of comparing the average precision of the four approaches. In the best case, CSDRM can achieve the precision of 72.23%. Meanwhile, the best Success Rates of TRTSD and ABSDA are 70.32% and 56.52% respectively, and the highest precision in REM is only 46.52%. Furthermore, when the service quantity is over 500, CSDRM is always the best one in the precision performing. On average, CSDRM improves the percentage of Success Rate by nearly 22% compared to REM. The results reveal that SL can also benefit the precision in Web service discovery.
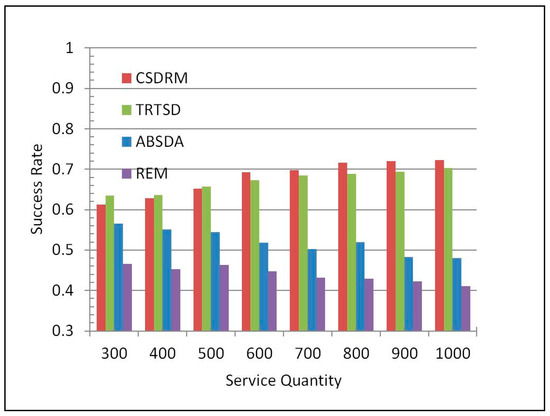
Figure 7.
Comparison of precision.
6. Conclusions
In this paper, we present a collaborative web service discovery and recommendation mechanism grounded on the latent social relationships behind users and services. By defining four link factors, we formalize the social link. Based on it, we further propose two algorithms, which can collaborate to select or recommend a subset of services to meet the requirements of users. The experiment results have demonstrated that our proposed approach is capable of improving the efficiency and precision of Web service discovery. In the future, we plan to extend SL by taking into consideration more specific link factors, so as to make the mechanism more flexible and effective.
Acknowledgments
This work is supported by the Science Research Key Project of the Department of Education in Hubei Province, China under Grant No. D20162202.
Author Contributions
Lijun Duan and Hao Tian conceived and designed the experiments; Lijun Duan performed the experiments; Hao Tian analyzed the data; Lijun Duan contributed analysis tools; Hao Tian wrote the paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Jiang, W.; Lee, D.; Hu, S. Large-scale longitudinal analysis of soap-based and restful web services. In Proceedings of the 2012 IEEE 19th International Conference On Web Services (ICWS), Honolulu, HI, USA, 24–29 June 2012; pp. 218–225. [Google Scholar]
- Tian, H. Research on User-Centered Web Service Discovery and Its Application in Financial Services; Wuhan University: Wuhan, China, 2014. [Google Scholar]
- Yahyaoui, H.; Maamar, Z.; Lim, E.; Thiran, P. Towards a community-based, social network-driven framework for Web services management. Future Gener. Comput. Syst. 2013, 29, 1363–1377. [Google Scholar] [CrossRef]
- Maamar, Z.; Faci, N.; Sheng, Q.; Yao, L. Towards a user-centric social approach to Web services composition, execution, and monitoring. In Proceedings of the 13th International Conference on Web Information Systems Engineering, Paphos, Cyprus, 28–30 November 2012; pp. 72–86. [Google Scholar]
- Wu, D.; Yan, J.; Wang, H.; Wang, R.Y. Service demand discovery mechanism for mobile social networks. Sensors 2016, 16, 1982. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.; Paik, I.; Hung, P.C. Constructing a global social service network for better quality of Web service discovery. IEEE Trans. Serv. Comput. 2015, 8, 284–298. [Google Scholar] [CrossRef]
- Kalai, A.; Zayani, C.A.; Amous, I. User’s social profile-based web services discovery. In Proceedings of the IEEE 8th International Conference on Service-Oriented Computing and Applications, Rome, Italy, 19–21 October 2015; pp. 2–9. [Google Scholar]
- Kravari, K.; Bassiliades, N. DISARM: A social distributed agent reputation model based on defeasible logic. J. Syst. Softw. 2016, 117, 130–152. [Google Scholar] [CrossRef]
- Liu, F.; Wang, L.; Gao, L.; Li, H.; Zhao, H.; Men, S. A Web service trust evaluation model based on small-world networks. Knowl.-Based Syst. 2014, 57, 161–167. [Google Scholar] [CrossRef]
- Liu, Y.; Zheng, X.; Chen, D. Trustworthy services discovery based on trust and recommendation relationships. Syst. Eng. Theory Pract. 2012, 32, 2789–2795. [Google Scholar]
- Zheng, Z.; Ma, H.; Lyu, M.; King, I. Collaborative Web service QoS prediction via neighborhood integrated matrix factorization. IEEE Trans. Serv. Comput. 2013, 6, 289–299. [Google Scholar] [CrossRef]
- Xie, X.; Song, C.; Zhang, Z. A service discovery method based on referral network and ant-colony algorithm. Chin. J. Comput. 2010, 33, 2093–2103. [Google Scholar] [CrossRef]
- Zhu, Q.; Sun, Y.Q. Collaborative filtering recommender method based on trust. J. Tsinghua Univ. (Sci. Technol.) 2014, 54, 360–365. [Google Scholar]
- Duan, Q. Modeling and delay analysis for converged network-cloud service provisioning systems. In Proceedings of the 2013 International Conference on Computing, Networking, and Communications, San Diego, CA, USA, 28–31 January 2013; pp. 66–70. [Google Scholar]
- Pirro, G.; Talia, D.; Trunfio, P. A DHT-based semantic overlay network for service discovery. Future Gener. Comput. Syst. 2012, 28, 689–707. [Google Scholar] [CrossRef]
- Tian, H.; Fan, H.; Du, W. Research on Web service discovery based on user community relations. J. Commun. 2015, 36, 28–36. [Google Scholar]
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).