An Improved Method for Obtaining Solar Irradiation Data at Temporal High-Resolution





Abstract
1. Introduction
2. Materials and Methods
2.1. Methods for Predicting Solar Irradiation
- Independent characteristics of solar irradiation time, such as means (both monthly and annual), variances, or standard deviations, etc.
- Time-dependent or sequential characteristics of solar irradiation: mainly partial and total autocorrelation functions.
2.2. Database of Solar Irradiation in Jaén
2.3. Characterization of Solar Irradiation in Jaén
2.4. Calculation of the Typical Meteorological Year (TMY) for Jaén
- Criterion I: Criterion of the monthly average values of daily irradiation.Based on finding a month whose average daily irradiation value is as close as possible to the average irradiation value of the same month of all years.
- Criterion II: Criteria for the monthly distribution of values of the clarity index.
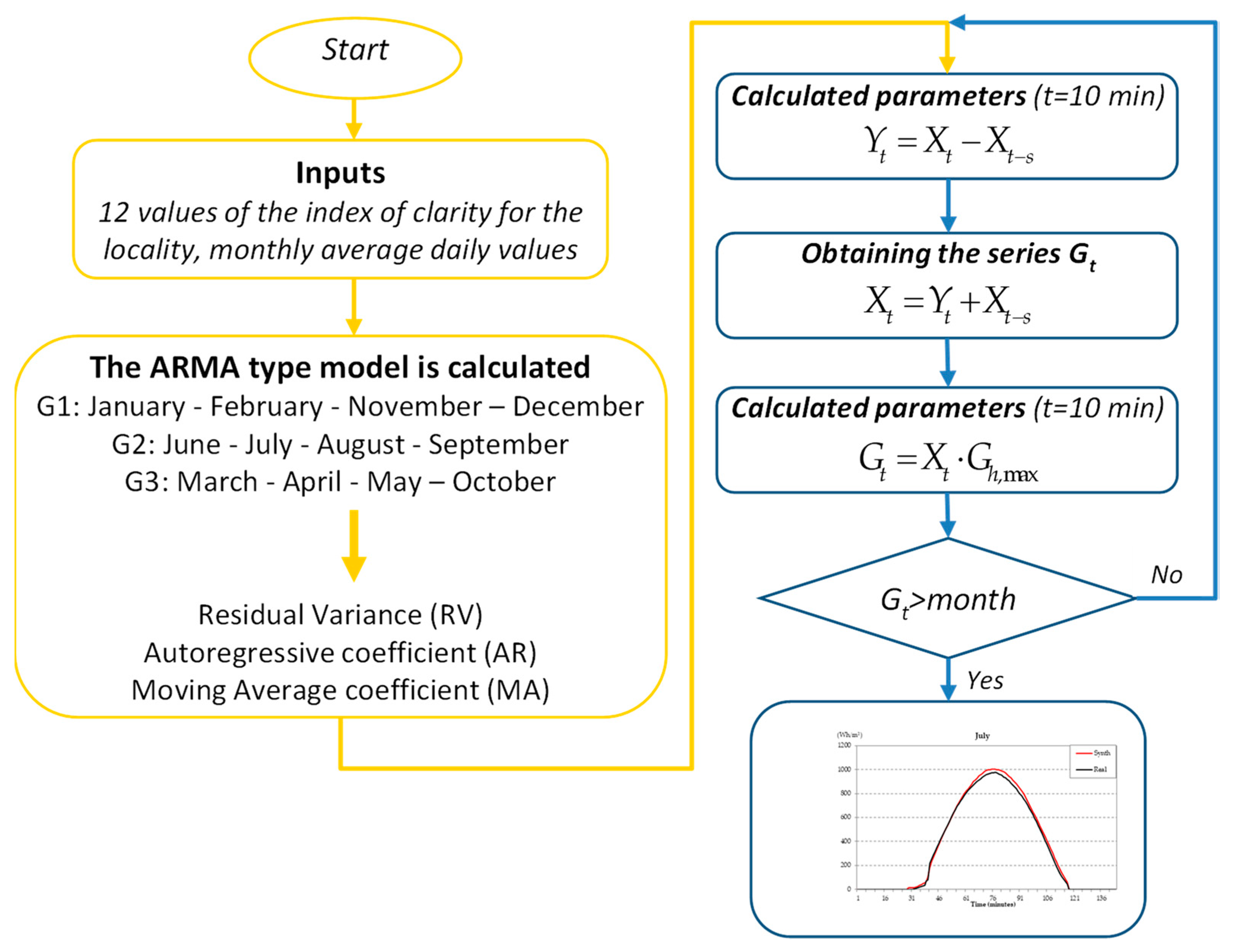
2.5. Proposed Method to Generate Data of Solar Irradiation at Minor Time Scale of an Hour
- Step 1: One should start from knowing 12 values of the index of clarity for the locality, in particular of the twelve monthly average daily values of said index.The expression for this first variable is given by:where:: monthly average daily clarity index: monthly average global solar irradiation per month: monthly average extraterrestrial solar irradiationTable 2 shows the values of from the typical meteorological year of Jaén.
- Step 2: Determination of the ARMA type model.
- G1: January–February–November–December
- G2: June–July–August–September
- G3: March–April–May–October
- Step 3: Generation of the series .The variable is defined as:The value t indicates a fixed hour, and s is some time before.For obtaining the ARMA model is applied in this way:where and are Gaussian white noise.
- Step 4: Obtaining the series .In this step, the series is obtained from the previous equation in this way:
- Step 5: Obtaining the series .is calculated as follows:with and is the solar altitude.
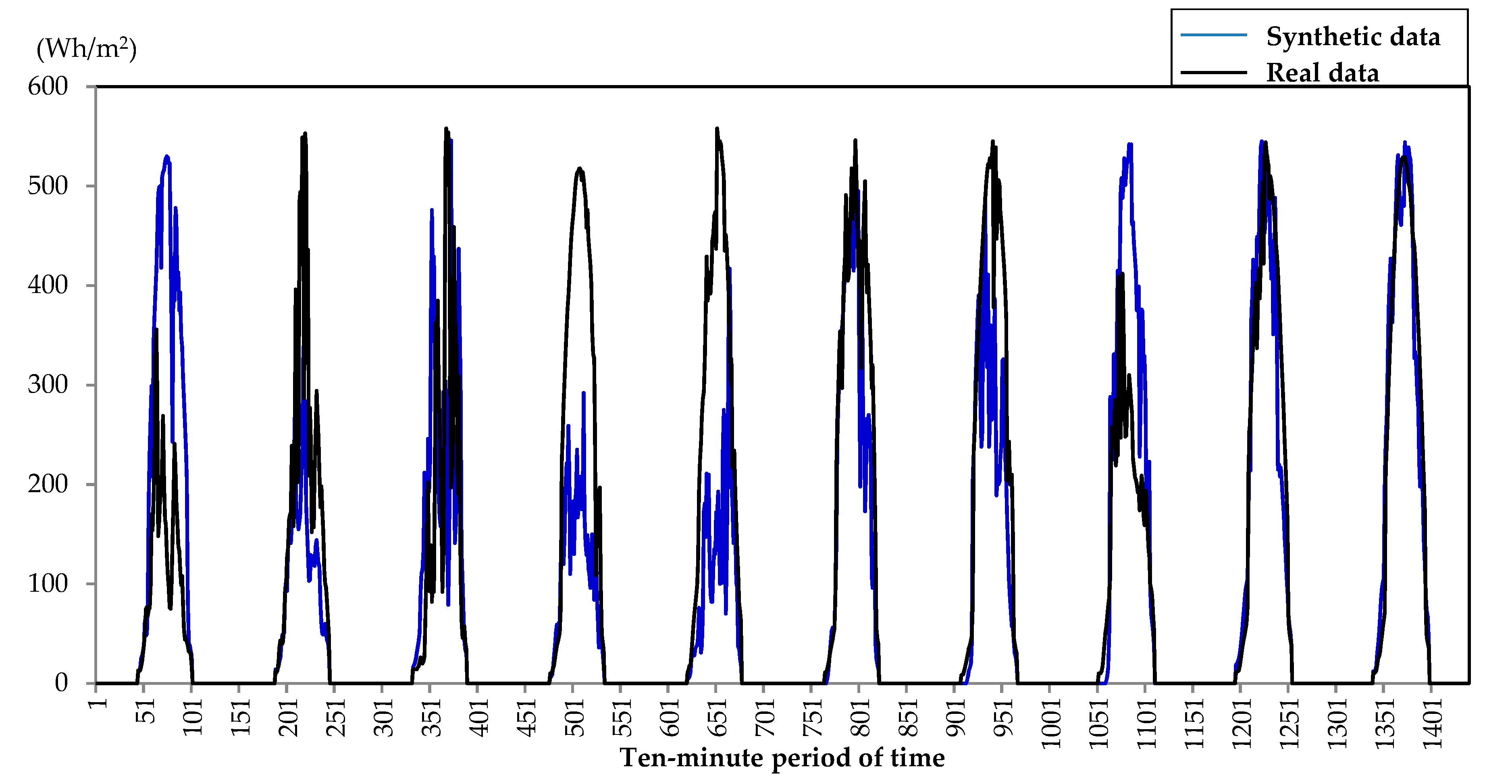
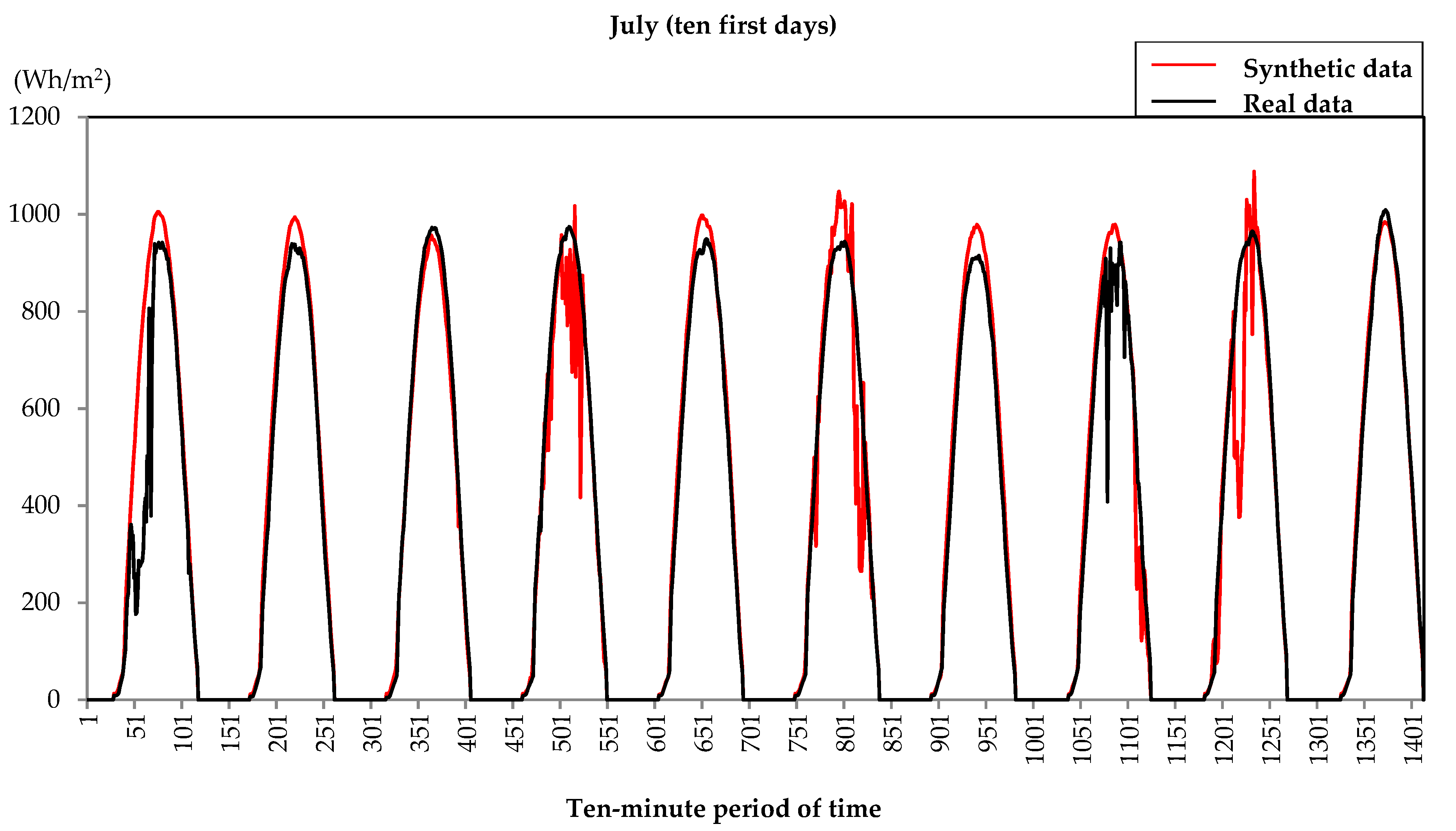
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Jiménez-Torres, M.; Rus-Casas, C.; Lemus-Zúñiga, L.G.; Hontoria, L. The importance of accurate solar data for designing solar photovoltaic systems—Case studies in Spain. Sustainability 2017, 9, 247. [Google Scholar] [CrossRef]
- Rus-Casas, C.; Hontoria, L.; Fernández-Carrasco, J.I.; Jiménez-Castillo, G.; Muñoz-Rodríguez, F. Development of a utility model for the measurement of global irradiation in photovoltaic applications in the internet of things (IoT). Electronics 2019, 8, 30. [Google Scholar] [CrossRef]
- López-Lapeña, O.; Pallas-Areny, R. Solar energy irradiation measurement with a low–power solar energy harvester. Comput. Electron. Agric. 2018, 151, 150–155. [Google Scholar] [CrossRef]
- Rus-Casas, C.; Aguilar, J.D.; Rodrigo, P.; Almonacid, F.; Pérez-Higueras, P.J. Classification of methods for annual energy harvesting calculations of photovoltaic generators. Energy Convers. Manag. 2014, 78, 527–536. [Google Scholar] [CrossRef]
- Gueymard, C.A.; Wilcox, S.M. Assessment of spatial and temporal variability in the US solar resource from radiometric measurements and predictions from models using ground-based or satellite data. Sol. Energy 2011, 85, 1068–1084. [Google Scholar] [CrossRef]
- Hontoria, L.; Aguilera, J.; Zufíria, P. Generation of hourly irirradiation synthetic series using the neural network multilayer perceptron. Sol. Energy 2002, 72, 441–446. [Google Scholar] [CrossRef]
- Amrouche, B.; Le Pivert, X. Artificial neural network based daily local forecasting for global solar irradiation. Appl. Energy 2014, 130, 333–341. [Google Scholar] [CrossRef]
- Elma, O.; Tascıkaraglu, A.; Ince, A.T.; Selamogulları, U.S. Implementation of a dynamic energy management system using real time pricing and local renewable energy generation forecasts. Energy 2017, 134, 206–220. [Google Scholar] [CrossRef]
- Hosseinnia, H.; Tousi, B. Optimal operation of DG-based micro grid (MG) by considering demand response program (DRP). Electr. Power Syst. Res. 2019, 167, 252–260. [Google Scholar] [CrossRef]
- Oprea, S.V.; Bara, A.; Ileana Uță, A.; Pirjan, A.; Căruțașu, G. Analyses of distributed generation and storage effect on the electricity consumption curve in the smart grid context. Sustainability 2018, 10, 2264. [Google Scholar] [CrossRef]
- Morales-Velazquez, L.; Romero-Troncoso, R.J.; Herrera-Ruiz, G.; Morinigo-Sotelo, D.; Osornio-Rios, R.A. Smart sensor network for power quality monitoring in electrical installations. Measurement 2017, 103, 133–142. [Google Scholar] [CrossRef]
- Angrisani, L.; Bonavolonta, F.; Liccardo, A.; Schiano Lo Moriello, R.; Serino, F. Smart power meters in augmented reality environment for electricity consumption awareness. Energies 2018, 11, 2303. [Google Scholar] [CrossRef]
- Viciana, E.; Alcayde, A.; Montoya, F.G.; Baños, R.; Arrabal-Campos, F.M.; Zapata-Sierra, A.; Manzano-Agugliaro, F. OpenZmeter: An efficient low-cost energy smart meter and power quality analyser. Sustainability 2018, 10, 4038. [Google Scholar] [CrossRef]
- Sanchez-Sutil, F.; Cano-Ortega, A.; Hernandez, J.C.; Rus-Casas, C. Development and calibration of an open source, low-cost power smart meter prototype for PV household-prosumers. Electronics 2019, 8, 878. [Google Scholar] [CrossRef]
- Robles Algarín, C.; Sevilla Hernández, D.; Restrepo Leal, D. A low-cost maximum power point tracking system based on neural network inverse model controller. Electronics 2018, 7, 4. [Google Scholar] [CrossRef]
- Hernández, J.C.; Sanchez-Sutil, F.; Muñoz-Rodríguez, F.J. Design criteria for the optimal sizing of a hybrid energy storage system in PV household-prosumers to maximize self-consumption and self-sufficiency. Energy 2019, 186. [Google Scholar] [CrossRef]
- Abate, F.; Carratu, M.; Liguori, C.; Paciello, V. A low cost smart power meter for IoT. Measurement 2019, 136, 59–66. [Google Scholar] [CrossRef]
- Schlund, J.; German, R. A control algorithm for a heterogeneous virtual battery storage providing FCR power. In Proceedings of the 2017 IEEE International Conference on Smart Grid and Smart Cities, Singapore, 23–26 July 2017; pp. 61–66. [Google Scholar] [CrossRef]
- Megel, O.; Mathieu, J.; Andersson, G. Scheduling distributed energy storage units to provide multiple services. In Proceedings of the IEEE Power Systems Computation Conference, Wroclaw, Poland, 18–22 August 2014; pp. 1–7. [Google Scholar] [CrossRef]
- Steber, D.; Bazan, P.; German, R. SWARM—Strategies for providing frequency containment reserve power with a distributed battery storage system. In Proceedings of the IEEE International Energy Conference, Leuven, Belgium, 4–8 April 2016; pp. 1–7. [Google Scholar] [CrossRef]
- Hernandez, J.C.; Sanchez-Sutil, F.; Vidal, P.G.; Rus-Casas, C. Primary frequency control and dynamic grid support for vehicle-to-grid in transmission systems. Int. J. Electr. Power Energy Syst. 2018, 100, 152–166. [Google Scholar] [CrossRef]
- Hernandez, J.C.; Bueno, P.G.; Sanchez-Sutil, F. Enhanced utility-scale photovoltaic units with frequency support functions and dynamic grid support for transmission systems. IET Renew. Power Gener. 2017, 11, 361–372. [Google Scholar] [CrossRef]
- Litjens, G.B.M.A.; Worrell, E.; Van Sark, W.G.J.H.M. Economic benefits of combining selfconsumption enhancement with frequency restoration reserves provision by photovoltaic-battery systems. Appl. Energy 2018, 223, 172–187. [Google Scholar] [CrossRef]
- Braun, M.; Büdenbender, K.; Magnor, D.; Jossen, A. Photovoltaic self-consumption in Germany: Using lithium-ion storage to increase self-consumed photovoltaic energy. In Proceedings of the 24th European Photovoltaic Solar Energy Conference, Hamburg, Germany, 21–24 September 2009; pp. 1–7. [Google Scholar]
- Bruch, M.; Müller, M. Calculation of the cost-effectiveness of a PV battery system. Energy Procedia 2014, 46, 262–270. [Google Scholar] [CrossRef]
- Schreiber, M.; Hochloff, P. Capacity-dependent tariffs and residential energy management for PV storage systems. In Proceedings of the IEEE Power and Energy Society General Meeting, Vancouver, BC, Canada, 21–25 July 2013; pp. 1–5. [Google Scholar] [CrossRef]
- Linssen, J.; Stenzel, P.; Fleer, J. Techno-economic analysis of photovoltaic battery systems and the influence of different consumer load profiles. Appl. Energy 2017, 185, 2019–2025. [Google Scholar] [CrossRef]
- Luthander, R.; Widen, J.; Nilsson, D.; Palm, J. Photovoltaic self-consumption in buildings: A review. Appl. Energy 2015, 142, 80–94. [Google Scholar] [CrossRef]
- Fridgen, G.; Kahlen, M.; Ketter, W.; Riegera, A.; Thimmel, M. One rate does not fit all: An empirical analysis of electricity tariffs for residential microgrids. Appl. Energy 2018, 210, 800–814. [Google Scholar] [CrossRef]
- Murray, D.; Stankovic, L.; Stankovic, V. An electrical load measurements dataset of United Kingdom households from a two-year longitudinal study. Sci. Data 2017, 4, 1–12. [Google Scholar] [CrossRef]
- Barker, S.; Mishra, A.; Irwin, D.; Cecchet, E.; Shenoy, P. Smart: An open data set and tools for enabling research in sustainable homes. In Proceedings of the 2nd KDD Workshop on Data Mining Applications in Sustainability, Beijing, China, 12 August 2012; pp. 1–6. [Google Scholar]
- Klein, S.A.; Beckman, W.A. TRNSYS- A transient simulation program. ASHRAE Trans. 1976, 82, 623. [Google Scholar]
- Brinkworth, B.J. Autocorrelation and stochastic modelling of insolation sequences. Sol. Energy 1977, 19, 343–347. [Google Scholar] [CrossRef]
- Van Paasen, A.H.C. Indoor Climate, Outdoor Climate and Energy Consumption. Ph.D. Thesis, Delft University of Technology, Delft, The Netherlands, 1981. [Google Scholar]
- Exell, R.H.B. A mathematical model for solar irradiation in Southeast Asia (Thailand). Sol. Energy 1981, 26, 161–168. [Google Scholar] [CrossRef]
- Vergara-Domínguez, L.; Garcia-Gomez, R.; Figueiras-Vidal, A.R.; Casar-Corredera, J.; Casajus-Quiros, F.J. Automatic modelling simulation of daily global solar irradiation series. Sol. Energy 1985, 35, 483–489. [Google Scholar] [CrossRef]
- Amato, U.; Andretta, A.; Bartoli, B.; Coluzzi, B.; Cuomo, V.; Fontana, F.; Serio, C. Markov processes and Fourier analysis as a tool to describe and simulate daily solar irradiance. Sol. Energy 1986, 37, 179–194. [Google Scholar] [CrossRef]
- Liu, B.; Jordan, R. The interrelationship and characteristics distribution of direct, diffuse and total solar irradiation. Sol. Energy 1960, 4, 1–19. [Google Scholar] [CrossRef]
- Dagelman, L.O. A Weather Simulation Model for Building Energy Analysis; ASHRAE Trans. Symposium on Weather Data: Seattle, WA, USA, 1976; pp. 435–447. [Google Scholar]
- Bolieau, E. Use of simple statistical models in solar meteorology. Sol. Energy 1983, 30, 333–339. [Google Scholar] [CrossRef]
- Bartoli, B.; Coluzzi, B.; Cuomo, V.; Francesca, M.; Serio, C. Autocorrelation of daily global solar irradiation. Il Nuovo Cimento 1983, 40, 113–122. [Google Scholar]
- Graham, V.A.; Hollands, K.G.T.; Unny, T.E. A time series model for Kt with application to global synthetic weather generation. Sol. Energy 1988, 40, 269–279. [Google Scholar] [CrossRef]
- Aguiar, R.; Collares-Pereira, M.; Conde, J.P. Simple procedure for generating sequences of daily irradiation values using a library of Markov transition matrices. Sol. Energy 1988, 40, 269–279. [Google Scholar] [CrossRef]
- Goh, T.; Tan, K. Stochastic modelling and forecasting of solar irradiation data. Sol. Energy 1977, 19, 755–757. [Google Scholar] [CrossRef]
- Mustacchi, C.; Cena, V.; Rocchi, M. Stochastic simulation of hourly global irradiation sequences. Sol. Energy 1979, 23, 47–51. [Google Scholar] [CrossRef]
- Balouktsis, A.; Tsalides, P. Stochastic simulation model of hourly total solar irradiation. Sol. Energy 1986, 37, 119–126. [Google Scholar] [CrossRef]
- Mora, L.L.; Sidrach-de-Cardona, M. Multiplicative ARMA models to generate hourly series of global irirradiation. Sol. Energy 1998, 63, 283–291. [Google Scholar] [CrossRef]
- Palomo, E. Hourly solar irradiation time series as first-order Markov chains. In Proceedings of the ISES Solar World Congress, Kobe, Japan, 4–8 September 1989; pp. 1–6. [Google Scholar]
- Graham, V.A.; Hollands, K.G.T. A method to generate synthetic hourly solar irradiation globally. Sol. Energy 1990, 44, 333–341. [Google Scholar] [CrossRef]
- Aguiar, R.; Collares-Pereira, M. TAG: A time-dependent, autorregressive, gaussian model for generating synthetic hourly irradiation. Sol. Energy 1992, 49, 167–174. [Google Scholar] [CrossRef]
- Reikard, G. Predicting solar irradiation at high resolutions: A comparison of time series forecasts. Sol. Energy 2009, 83, 342–349. [Google Scholar] [CrossRef]
- Barbieri, F.; Rajakaruna, S.; Ghosh, A. Very short-term photovoltaic power forecasting with cloud modeling: A review. Renew. Sustain. Energy Rev. 2017, 75, 242–263. [Google Scholar] [CrossRef]
- Rahmann, C.; Mayol, C.; Haas, J. Dynamic control strategy for large-scale photovoltaic power plants operating under partial shaded conditions: A way to reduce negative effects on frequency regulation. in press.
- Marion, W.; Urban, K. User’s Manual for TMY2s (Typical Meteorological Years); NREL: Golden, CO, USA, 1995. [Google Scholar] [CrossRef]
- Hassani, H.; Silva, E.S. A Kolmogorov-Smirnov Based test for comparing the predictive accuracy of two sets of forecasts. Econometrics 2015, 3, 590–609. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Period | Total Days | Days with Errors | Percentage of Days with Errors |
|---|---|---|---|
| 1996–2011 | 5476 | 250 | 4.56% |
| Month | |
|---|---|
| January | 0.481 |
| February | 0.562 |
| March | 0.567 |
| April | 0.575 |
| May | 0.577 |
| June | 0.661 |
| July | 0.676 |
| August | 0.657 |
| September | 0.581 |
| October | 0.577 |
| November | 0.519 |
| December | 0.474 |
| Model | G1 (group1)January–February–November–December | G2 (group2)June–July–August–September | G3 (group3)March–April–May–October |
|---|---|---|---|
| Type 1 | 0.583 | 0.633 | 0.637 |
| Type 2 | 0.564 | 0.614 | 0.618 |
| Type 3 | 0.545 | 0.594 | 0.598 |
| Type 4 | 0.514 | 0.563 | 0.567 |
| Type 5 | 0.480 | 0.530 | 0.534 |
| Model | RV | AR | MA |
|---|---|---|---|
| Type 1 | 0.008 | 0.720 | 0.845 |
| Type 2 | 0.012 | 0.745 | 0.845 |
| Type 3 | 0.018 | 0.745 | 0.845 |
| Type 4 | 0.025 | 0.762 | 0.845 |
| Type 5 | 0.036 | 0.728 | 0.862 |
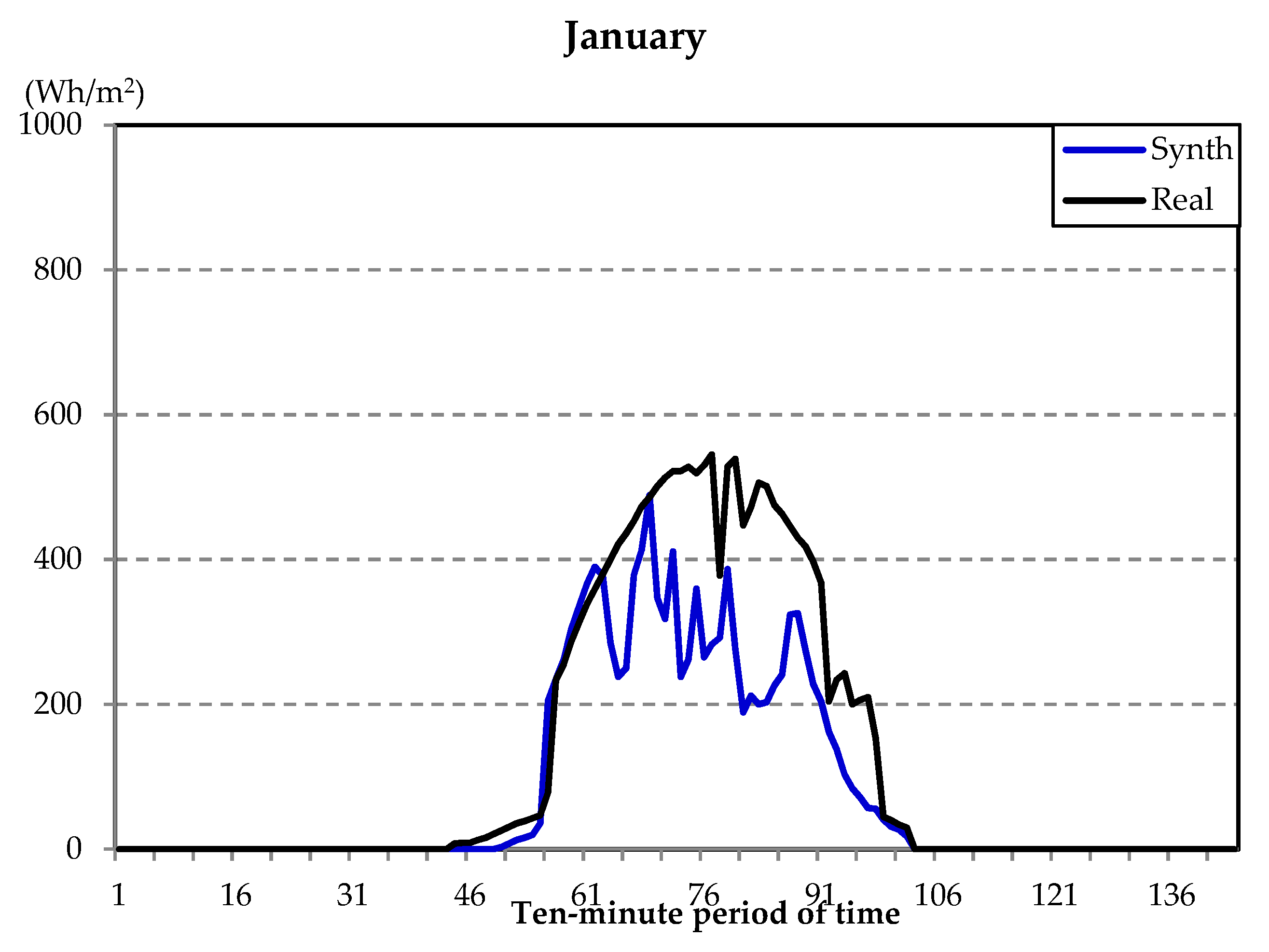
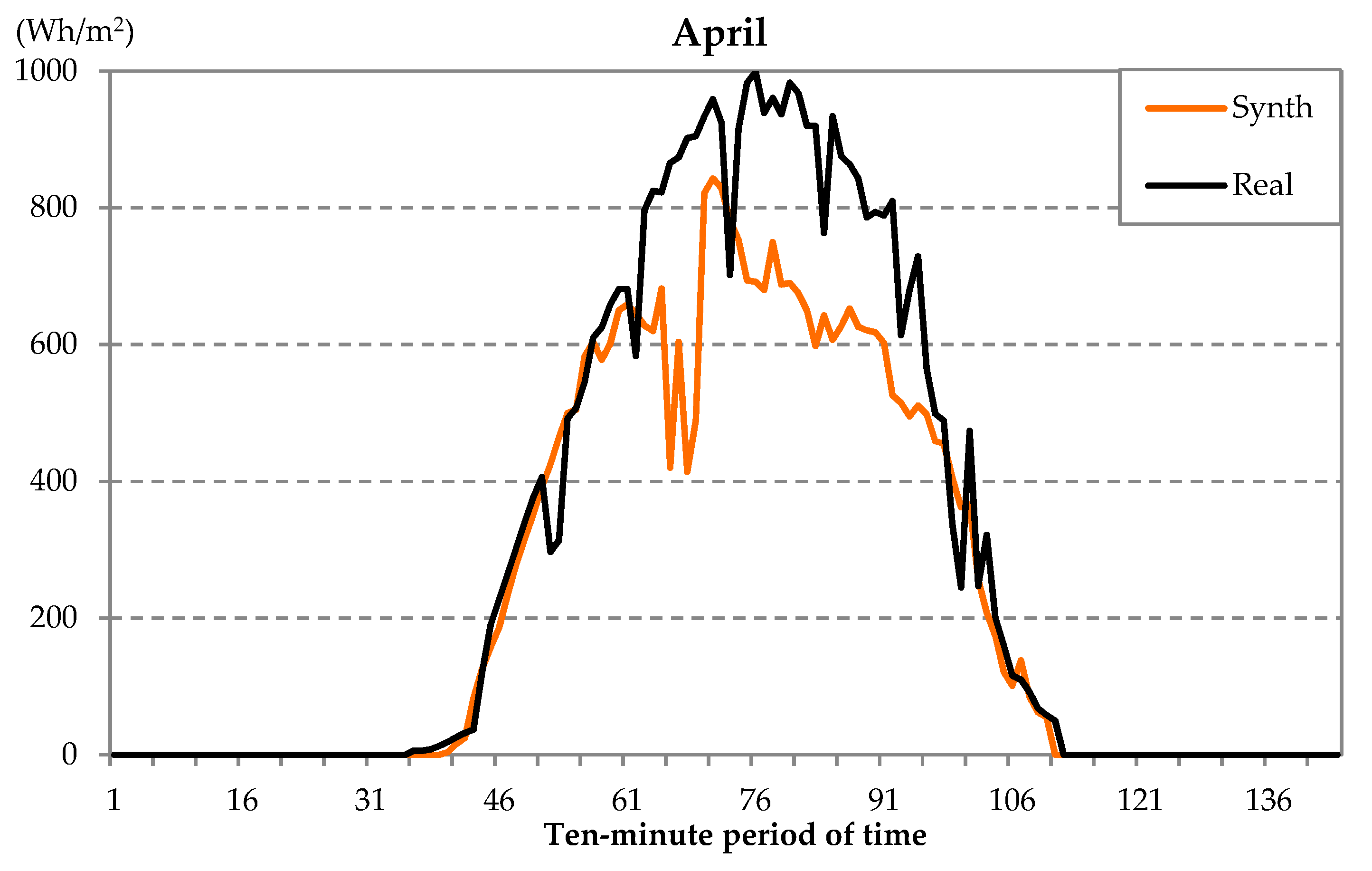
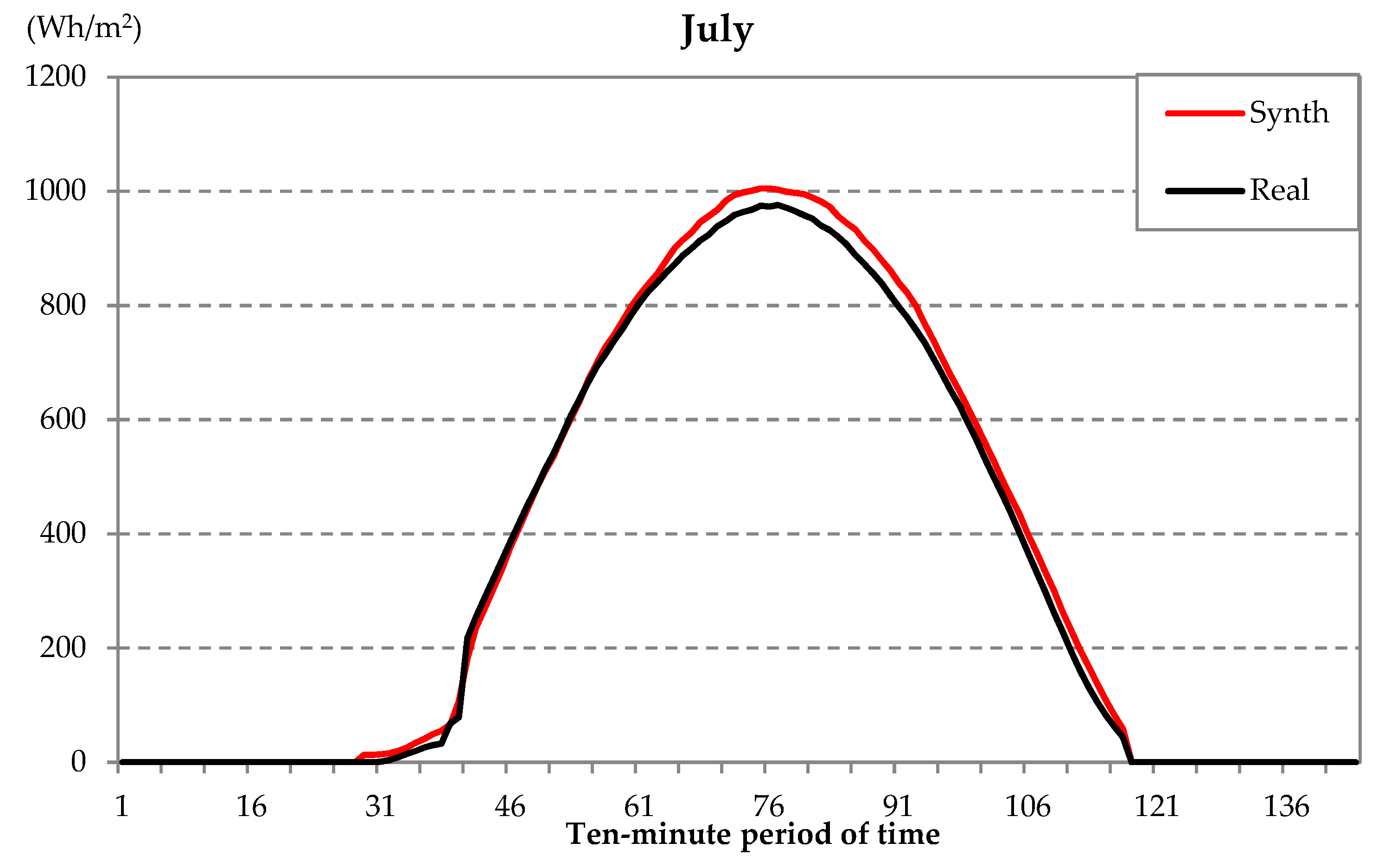
| Example Day | RMV (%) |
|---|---|
| January | 1.79 |
| April | 0.61 |
| July | 0.07 |
| Example Day | RMV (%) |
|---|---|
| January (G1) | 2.37 |
| April (G3) | 1.13 |
| July (G2) | 0.16 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hontoria, L.; Rus-Casas, C.; Aguilar, J.D.; Hernandez, J.C. An Improved Method for Obtaining Solar Irradiation Data at Temporal High-Resolution. Sustainability 2019, 11, 5233. https://doi.org/10.3390/su11195233
Hontoria L, Rus-Casas C, Aguilar JD, Hernandez JC. An Improved Method for Obtaining Solar Irradiation Data at Temporal High-Resolution. Sustainability. 2019; 11(19):5233. https://doi.org/10.3390/su11195233
Chicago/Turabian StyleHontoria, Leocadio, Catalina Rus-Casas, Juan Domingo Aguilar, and Jesús C. Hernandez. 2019. "An Improved Method for Obtaining Solar Irradiation Data at Temporal High-Resolution" Sustainability 11, no. 19: 5233. https://doi.org/10.3390/su11195233
APA StyleHontoria, L., Rus-Casas, C., Aguilar, J. D., & Hernandez, J. C. (2019). An Improved Method for Obtaining Solar Irradiation Data at Temporal High-Resolution. Sustainability, 11(19), 5233. https://doi.org/10.3390/su11195233