
Knowledge Acquisition and Representation for High-Performance Building Design: A Review for Defining Requirements for Developing a Design Expert System


Abstract
:1. Introduction
2. Study Objectives and Research Flow
- Step 1: The roles and functions of the knowledge base (KB) and inference engine (IE) in general expert systems were reviewed and the functions and processes of the general knowledge formulation were described (Section 3.1).
- Step 2: An overview of design expert systems and decision support systems in the AEC (Architecture, Engineering, and Construction) industry was established (Section 3.2).
- Step 3: The HPB design phase was reviewed to identify design problems that could be solved by the HPB design expert system, and the required design knowledge was summarized for each design phase (Section 4).
3. Design Expert System and Decision Support System
3.1. Expert System and Knowledge Formulation
3.2. Expert System and Decision Support System for Building Design
4. Classification of Design Problems for High Performance Building
4.1. Building Design Phases
4.1.1. Conceptual Planning Phase
4.1.2. Schematic Design Phase
4.1.3. Design Development Phase
4.1.4. Construction Document Phase
4.2. Types of HPB Design Problems
4.2.1. HPB Analysis Problems
4.2.2. HPB Synthesis Problems
5. Knowledge Acquisition
5.1. Heuristic Acquisition
5.2. Computer-Aided Acquisition
5.2.1. Web Search
5.2.2. Public Databases and Information Service Providers
5.2.3. Transactional and Operational Data
5.2.4. Simulated Data
6. Knowledge Representation
6.1. Knowledge Representation by Logic, Formula and Rules
6.1.1. First Order Logic (FOL) and Formulas
6.1.2. IF-THEN Rule

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| IF SensorPriority is High AND SensorType is Illuminance AND IlluminancePerformance is TooLow: (a) IF distanceFromGoal is Far, THEN DesiredChange is “Increase Illuminance by a Large Amount”; (b) IF distanceFromGoal is Close, THEN DesiredChange is “Increase Illuminance by a Small Amount”. |
6.1.3. Fuzzy Logic
6.2. Knowledge Representation by Semantics and Ontology
6.2.1. Semantic Model and Ontology
6.2.2. Resource Description Framework (RDF), Web Ontology Language (OWL) and Semantic Web Rule Language (SWRL)
| Column(?C) ∧ Volume(?C,?CV) ∧ hasConcrete(?C,?Con) ∧ Concrete(?Con) ∧ EmbodiedCO2e(?Con,?ECO2) ∧ swrlb:multiply(?TECO2,?CV,?ECO2)→TotalECO2e(?C,?TECO2) |
6.2.3. Building Information Modeling (BIM)
6.3. Knowledge Representation by Analysis Model and Simulation
6.3.1. Analysis Model
6.3.2. Building Performance Simulation
6.4. Knowledge Representation by Machine Learning Algorithms
6.4.1. Regressions
6.4.2. Classification
6.4.3. Neural Networks
6.4.4. Trees
6.4.5. Primary Factors
6.4.6. Clustering
6.4.7. Pattern and Association Rule Extraction
6.4.8. Optimization
6.4.9. Multi Agent Systems
6.5. Knowledge Representation by Case-Based Reasoning
6.6. Knowledge Representation by Group Decision Support
7. Summary of HPB Design Knowledge Acquisition and Representation
- Traditional methods that enable knowledge acquisition through strategies such as interviews and surveys with experts are still widely used. Passive knowledge acquisition that extracts portable knowledge by discovering and analyzing knowledge from documented facts is also considerably used. However, studies that provide detailed explanations of the methods of extracting knowledge from dialogue with experts or their opinions or from design knowledge from document-formatted facts are still scarce.
- There is a growing number of studies that extract knowledge from digital media, analyze big data, or employ computer-analyzed data as a knowledge acquisition source. However, the main actors who collect raw data, select data, and analysis methods, and conduct analysis are still domain experts or agents who should be verified by domain experts. Thus, the subjective opinions and heuristics of analyzers must be involved even in computer-aided acquisition.
- Computer-aided acquisition has the advantage of enabling the extraction of portable knowledge from a relatively objective knowledge source that has wider viewpoints. In most cases, the perspective of domain experts can be further expanded by computer-aided acquisition and, in some cases, even the bias initially possessed by domain experts can be corrected. Thus, it is more reasonable to perform computer-aided knowledge engineering directly by domain experts or to verify the (machine) extracted knowledge by domain experts.
- There were rules, frames, and a semantic network as in the conventional knowledge representation formalism of the expert system, and the knowledge representation types shown in the HPB design references were also originated from them.
- Several studies employ KR-I, because the rules and logic are the methods to represent the primary factors of knowledge the most succinctly and clearly. Although all related knowledge cannot be represented in detail, the primary knowledge such as the governing equation is relatively easy to be acquired and the representation by the rules and logic has no room for misunderstanding or misinterpretation. In addition, the rules and logic are the knowledge representation that can be easily accepted and understood by designers, as the regulations that most affect the building design are the rule formats.
- However, KR-I cannot fully represent the characteristics and state of the knowledge agent. In addition, it is difficult to systematically represent the knowledge about the activity between the knowledge agents, as well as their temporal and spatial interactions. In particular, there is an evident limitation for representing direct and indirect HPB design knowledge using KR-I for buildings, because the types of entities that are involved with the behavior of a large system and their interaction should be transient and diverse given the significant size of its system—which is the case with buildings. Thus, in recent years, studies have increasingly employed the KR-II semantic model and ontology as the framework of building design knowledge to represent detailed knowledge, such as the interaction between entities or change of state in building entities.Notably, building ontology can employ proprietary ontology specialized for a given problem or standard BIM. The former can only represent matters about a given problem efficiently, with the disadvantage of decreasing compatibility if the problem scope is expanded or changed. The latter has a drawback that the scope of the BIM may have a larger scope and more inappropriate detail than the scope and detail required by the design problem. Thus, it would be more appropriate to select the specific KR-III building performance model specifically for the corresponding performance problem.
- 4.
- KR-II and KR-III are rich models that can not only represent fine details, but also provide significant knowledge that can be used in design decision-making if the model is filled with significant input values to some extent. Ultimately, the reliability of the incomplete model’s simulation results must be considerably low if the value that is directly related to a given problem is difficult to be acquired and/or if the input value sensitivity is coincidently large when the confidence on the model input value is low. In line with this, an increasing number of studies have reported on the analysis and interpretation methods that are useful to design decision-making, which are required when using KR-II and KR-III.
- 5.
- KR-I, II, and III are relatively refined knowledge representation formalisms. However, as the proportion of knowledge acquisition from the database, digital media, and monitoring data increases daily, the ratio of research that extracts design knowledge required from raw data using machine learning algorithms has increased steadily.In particular, HPB design knowledge has been increasingly acquired from data analytics for design insights that extract latent rules, hidden patterns, trends, and meta-models from the processed data, which are prepared by collecting discrete simulations or rule results. While the traditional analysis method comprises the extraction of underlying knowledge, such as governing equation or primary factor using regressions or sensitivity analysis, attempts to implement a data model or data structure of raw data dynamics using supervised learning algorithms or to identify raw data structures and patterns using unsupervised learning algorithm have recently increased.
- 6.
- Although it is important for design problems to represent the problem space and conditions comprehensively and succinctly thereby helping designers to develop the solution efficiently, reaching the optimal solution is ultimately the designer’s responsibility, as he/she is the one who employs all the time and effort to select the solution. Thus, studies on automated optimization framework and multi-agent systems which find design solutions under the condition and constraints that designers define, and then directly suggest the solutions have increased rapidly in the past 10 years. In this case, designers select the scope of the design knowledge which is already defined by the certified knowledge provider (e.g., off-the-shelf simulation) and thus focus more on how to implement the outcome out of the selected design knowledge.
- 7.
- To acquire significant interpretation via machine learning, a considerable amount of base data must be secured. Otherwise, a realistic alternative can be selecting the final solution through case-based reasoning or group decision-making using a limited number of cases. Thus, platforms where various group decision-making processes are implemented keep being reported in the recent literature.
8. Requirements of KA, KR, and Decision Support for Developing Design Expert System
- Heuristics is still a good source of design knowledge. However, both direct and indirect knowledge regarding design decision-making should be acquired directly from domain experts or tools recommended by the experts. If experts cannot acquire knowledge by themselves, they should at least play the role of quality assurance (QA) for the acquired knowledge.
- It is difficult to completely acquire all the valid knowledge that solves the design problem solely through the experts’ heuristics. Thus, knowledge extracted through data analytics should work as a complementary tool, and the expert system should provide a platform to manage extraction, formation, synthesis, new insertion, and modification of knowledge for the both types of knowledge sources so as to achieve synergy between them.The expert knowledge particularly acquired by data analytics should be managed by open systems to be utilized in similar problems in the future after the knowledge is complete in both representation and formalization. It should also be transparent and tangible for users to easily understand, select, and apply the knowledge acquired.
- 3.
- Primary knowledge extracted from raw data should first be represented in a format as portable and compact as possible so as to be applicable to a wide range of design contexts and situations such as formula and if-then rules, although it may not be sufficiently accurate and precise to a specific configuration of the design problem.It is noteworthy that, because the knowledge base consisting of only the primary knowledge cannot reflect the unique characteristics of a specific problem context, the secondary knowledge needs to be derived by applying the primary knowledge to the context frame after configuring separately the frame that reflects the design context. Thus, the primary knowledge should be a format whose knowledge structure is simple and that can describe knowledge one-dimensionally to be easily incorporated into the context frame such as model.
- 4.
- Instead of using a proprietary context frame, a framework such as a publicly validated BIM or certified simulation model should be used even if the scope is larger than a given scope. If a framework is newly built by users, subjective opinions of the user must be involved. Thus, the knowledge implemented by the framework is likely to include potential and constant biases. Thus, it may cause a distortion to the secondary knowledge derived from the framework.
- 5.
- Recently many studies proposed the system that enables directly obtaining the design solution such as optimization and the agent-based system, because the resource and time to execute the performance evaluation and analysis of the alternatives are not sufficient even if designers are well experienced in HPB. That is, if designers do not have sufficient expertise on HPB, an expert system should be able to provide HPB design knowledge suitable to the design context as well as directly offer the design alternative like a HPB consultant.
- 6.
- However, the purpose of employing HPB consultants by designers even with the cost is to take professional expertise and receive their advice on the latest HPB trend as well as advance the design alternatives in consultation with them. That is, the final decision is made with designers and clients by comparing the advantages, disadvantages, and economic feasibility of each alternative provided by the consultants, rather than blindly accepting the proposed design.Thus, in order for the solution provided by the expert system to be reliable, the expert system should not only provide a design solution directly but also transparently disclose which frame the primary knowledge is used in to reach the solution and how the solution is derived.
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Howbuild. 2021. Available online: https://sketch.howbuild.com (accessed on 3 March 2021).
- Lutton, L. HYPEREX—A generic expert system to assist architects in the design of routine building types. Build. Environ. 1995, 30, 165–180. [Google Scholar] [CrossRef]
- Flemming, U.; Coyne, R.; Glavin, T.; Rychener, M. A Generative Expert System for the Design of Building Layouts; Springer: Berlin/Heidelberg, Germany, 1986; pp. 811–821. [Google Scholar]
- Knowledge Representation and Reasoning. Available online: https://en.wikipedia.org/wiki/Knowledge_representation_and_reasoning (accessed on 3 March 2021).
- Wagner, W.P. Trends in expert system development: A longitudinal content analysis of over thirty years of expert system case studies. Expert Syst. Appl. 2017, 76, 85–96. [Google Scholar] [CrossRef]
- Mitta, D.A. Formulation of expert system knowledge. Proc. Hum. Factors Soc. Annu. Meet. 1989, 33, 350. [Google Scholar] [CrossRef]
- Adeli, H.; Hawkins, D.W. A hierarchical expert system for design of floors in highrise buildings. Comput. Struct. 1991, 41, 773–788. [Google Scholar] [CrossRef]
- Bédard, C.; Gowri, K. Automating building design process with KBES. J. Comput. Civ. Eng. 1990, 4, 69–83. [Google Scholar] [CrossRef]
- Rosenman, M.A.; Gero, J.S. Design codes as expert systems. Comput. Aided Des. 1985, 17, 399–409. [Google Scholar] [CrossRef]
- Saouma, V.E.; Doshi, S.M.; Pace, M. Architecture of an expert-system-based code-compliance checker. Eng. Appl. Artif. Intell. 1989, 2, 49–56. [Google Scholar] [CrossRef]
- Adeli, H. Expert Systems in Construction and Structural Engineering; Chapman & Hall Ltd.: London, UK; New York, NY, USA, 1988. [Google Scholar]
- Adelman, L. Measurement issues in knowledge engineering. IEEE Trans. Syst. Man Cybern. 1989, 19, 483–488. [Google Scholar] [CrossRef]
- Hayter, S.J.; Torcellini, P.A.; Hayter, R.B. The energy design process for designing and constructing high-performance buildings. In Proceedings of the 7th REHVA World Congress and Clima, Naples, Italy, 15–18 September 2001; pp. 15–18. [Google Scholar]
- Kim, S.H.; Nam, J. Can both the economic value and energy performance of small- and mid-sized buildings be satisfied? development of a design expert system in the context of Korea. Sustainability 2020, 12, 4946. [Google Scholar] [CrossRef]
- Clancey, W.J. Heuristic classification. Artif. Intell. 1985, 27, 289–350. [Google Scholar] [CrossRef]
- Arroyo, P.; Mourgues, C.; Flager, F.; Correa, M.G. A new method for applying choosing by advantages (CBA) multicriteria decision to a large number of design alternatives. Energy Build. 2018, 167, 30–37. [Google Scholar] [CrossRef]
- Arambula, L.R.; Pernigotto, G.; Cappelletti, F.; Romagnoni, P.; Gasparella, A. Energy audit of schools by means of cluster analysis. Energy Build. 2015, 95, 160–171. [Google Scholar] [CrossRef]
- Deb, C.; Lee, S.E. Determining key variables influencing energy consumption in office buildings through cluster analysis of pre- and post-retrofit building data. Energy Build. 2018, 159, 228–245. [Google Scholar] [CrossRef]
- Papadopoulos, S.; Bonczak, B.; Kontokosta, C.E. Pattern recognition in building energy performance over time using energy benchmarking data. Appl. Energy 2018, 221, 576–586. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z.; Roth, J.; Jain, R.K. Due-B: Data-driven urban energy benchmarking of buildings using recursive partitioning and stochastic frontier analysis. Energy Build. 2018, 163, 58–69. [Google Scholar] [CrossRef]
- Wei, Y.; Zhang, X.; Shi, Y.; Xia, L.; Pan, S.; Wu, J.; Han, M.; Zhao, X. A review of data-driven approaches for prediction and classification of building energy consumption. Renew. Sustain. Energy Rev. 2018, 82, 1027–1047. [Google Scholar] [CrossRef]
- Benavente-Peces, C.; Ibadah, N. Buildings energy efficiency analysis and classification using various machine learning technique classifiers. Energies 2020, 13, 3497. [Google Scholar] [CrossRef]
- Xia, B.; Li, X.; Shi, H.; Chen, S.; Chen, J. Style classification and prediction of residential buildings based on machine learning. J. Asian Archit. Build. Eng. 2020, 19, 714–730. [Google Scholar] [CrossRef]
- Attia, S.; Gratia, E.; De Herde, A.; Hensen, J.L.M. Simulation-based decision support tool for early stages of zero-energy building design. Energy Build. 2012, 49, 2–15. [Google Scholar] [CrossRef] [Green Version]
- Østergård, T.; Jensen, R.L.; Maagaard, S.E. Early building design: Informed decision-making by exploring multidimensional design space using sensitivity analysis. Energy Build. 2017, 142, 8–22. [Google Scholar] [CrossRef]
- Pang, Z.; O’neill, Z.; Li, Y.; Niu, F. The role of sensitivity analysis in the building performance analysis: A critical review. Energy Build. 2020, 209, 109659. [Google Scholar] [CrossRef]
- Zhou, P.; El-Gohary, N. Ontology-based automated information extraction from building energy conservation codes. Autom. Constr. 2017, 74, 103–117. [Google Scholar] [CrossRef]
- Gagne, J.M.L.; Andersen, M.; Norford, L.K. An interactive expert system for daylighting design exploration. Build. Environ. 2011, 46, 2351–2364. [Google Scholar] [CrossRef]
- Schlueter, A.; Geyer, P. Linking BIM and design of experiments to balance architectural and technical design factors for energy performance. Autom. Constr. 2018, 86, 33–43. [Google Scholar] [CrossRef]
- Shen, L.; Yan, H.; Fan, H.; Wu, Y.; Zhang, Y. An integrated system of text mining technique and case-based reasoning (TM-CBR) for supporting green building design. Build. Environ. 2017, 124, 388–401. [Google Scholar] [CrossRef]
- Xiao, X.; Skitmore, M.; Hu, X. Case-based reasoning and text mining for green building decision making. Energy Procedia 2017, 111, 417–425. [Google Scholar] [CrossRef]
- Bektas Ekici, B.; Aksoy, U.T. Prediction of building energy needs in early stage of design by using ANFIS. Expert Syst. Appl. 2011, 38, 5352–5358. [Google Scholar] [CrossRef]
- Hester, J.; Gregory, J.; Kirchain, R. Sequential early-design guidance for residential single-family buildings using a probabilistic metamodel of energy consumption. Energy Build. 2017, 134, 202–211. [Google Scholar] [CrossRef]
- Pulido-Arcas, J.A.; Pérez-Fargallo, A.; Rubio-Bellido, C. Multivariable regression analysis to assess energy consumption and CO2 emissions in the early stages of offices design in Chile. Energy Build. 2016, 133, 738–753. [Google Scholar] [CrossRef]
- Amiri, S.S.; Mottahedi, M.; Asadi, S. Using multiple regression analysis to develop energy consumption indicators for commercial buildings in the U.S. Energy Build. 2015, 109, 209–216. [Google Scholar] [CrossRef]
- Deng, H.; Fannon, D.; Eckelman, M.J. Predictive modeling for US commercial building energy use: A comparison of existing statistical and machine learning algorithms using CBECS microdata. Energy Build. 2018, 163, 34–43. [Google Scholar] [CrossRef]
- Rocha, H.; Peretta, I.S.; Lima, G.F.M.; Marques, L.G.; Yamanaka, K. Exterior lighting computer-automated design based on multi-criteria parallel evolutionary algorithm: Optimized designs for illumination quality and energy efficiency. Expert Syst. Appl. 2016, 45, 208–222. [Google Scholar] [CrossRef]
- Andersen, M.; Gagne, J.M.; Kleindienst, S. Interactive expert support for early stage full-year daylighting design: A user’s perspective on Lightsolve. Autom. Constr. 2013, 35, 338–352. [Google Scholar] [CrossRef] [Green Version]
- Csík, A. An Expert System for the Cost-Optimal Refurbishment of Buildings. Adv. Mater. Res. 2014, 899, 599–604. [Google Scholar] [CrossRef]
- Min, D.A.; Hyun, K.H.; Kim, S.-J.; Lee, J.-H. A rule-based servicescape design support system from the design patterns of theme parks. Adv. Eng. Informatics 2017, 32, 77–91. [Google Scholar] [CrossRef]
- Nilashi, M.; Zakaria, R.; Ibrahim, O.; Majid, M.Z.A.; Zin, R.M.; Chugtai, M.W.; Abidin, N.I.Z.; Sahamir, S.R.; Yakubu, D.A. A knowledge-based expert system for assessing the performance level of green buildings. Knowl. Based Syst. 2015, 86, 194–209. [Google Scholar] [CrossRef]
- König, M.; Dirnbek, J.; Stankovski, V. Architecture of an open knowledge base for sustainable buildings based on Linked Data technologies. Autom. Constr. 2013, 35, 542–550. [Google Scholar] [CrossRef]
- Konis, K.; Gamas, A.; Kensek, K. Passive performance and building form: An optimization framework for early-stage design support. Sol. Energy 2016, 125, 161–179. [Google Scholar] [CrossRef]
- Arayici, Y.; Fernando, T.; Munoz, V.; Bassanino, M. Interoperability specification development for integrated BIM use in performance based design. Autom. Constr. 2018, 85, 167–181. [Google Scholar] [CrossRef]
- Liu, S.; Meng, X.; Tam, C. Building information modeling based building design optimization for sustainability. Energy Build. 2015, 105, 139–153. [Google Scholar] [CrossRef]
- Hiyama, K.; Kato, S.; Kubota, M.; Zhang, J. A new method for reusing building information models of past projects to optimize the default configuration for performance simulations. Energy Build. 2014, 73, 83–91. [Google Scholar] [CrossRef]
- Ilhan, B.; Yaman, H. Green building assessment tool (GBAT) for integrated BIM-based design decisions. Autom. Constr. 2016, 70, 26–37. [Google Scholar] [CrossRef]
- Pont, U.; Ghiassi, N.; Fenz, S.; Heurix, J.; Mahdavi, A. SEMERGY: Application of semantic web technologies in performance-guided building design optimization. J. Inf. Technol. Constr. 2015, 20, 107–120. [Google Scholar]
- Hou, S.; Li, H.; Rezgui, Y. Ontology-based approach for structural design considering low embodied energy and carbon. Energy Build. 2015, 102, 75–90. [Google Scholar] [CrossRef]
- Corry, E.; Pauwels, P.; Hu, S.; Keane, M.; O’Donnell, J. A performance assessment ontology for the environmental and energy man-agement of buildings. Autom. Constr. 2015, 57, 249–259. [Google Scholar] [CrossRef] [Green Version]
- Petersen, S.; Svendsen, S. Method and simulation program informed decisions in the early stages of building design. Energy Build. 2010, 42, 1113–1119. [Google Scholar] [CrossRef]
- Ochoa, C.E.; Capeluto, I.G. Advice tool for early design stages of intelligent facades based on energy and visual comfort approach. Energy Build. 2009, 41, 480–488. [Google Scholar] [CrossRef]
- Gerber, D.J.; Pantazis, E.; Wang, A. A multi-agent approach for performance based architecture: Design exploring geometry, user, and environmental agencies in façades. Autom. Constr. 2017, 76, 45–58. [Google Scholar] [CrossRef] [Green Version]
- Jaime, M.L.; Marilyne, A. A daylighting knowledge base for performance-driven facade design exploration. J. Illum. Eng. Soc. 2011, 8, 93–110. [Google Scholar]
- Chardon, S.; Brangeon, B.; Bozonnet, E.; Inard, C. Construction cost and energy performance of single family houses: From integrated design to automated optimization. Autom. Constr. 2016, 70, 1–13. [Google Scholar] [CrossRef]
- Oti, A.; Kurul, E.; Cheung, F.; Tah, J. A framework for the utilization of Building Management System data in building information models for building design and operation. Autom. Constr. 2016, 72, 195–210. [Google Scholar] [CrossRef] [Green Version]
- Singhaputtangkul, N.; Low, S.P.; Teo, A.L.; Hwang, B.-G. Knowledge-based Decision Support System Quality Function De-ployment (KBDSS-QFD) tool for assessment of building envelopes. Autom. Constr. 2013, 35, 314–328. [Google Scholar] [CrossRef]
- O’Donnell, J.; Corry, E.; Hasan, S.; Keane, M. Building performance optimization using cross-domain scenario modeling, linked data, and complex event processing. Build. Environ. 2013, 62, 102–111. [Google Scholar] [CrossRef] [Green Version]
- Homaei, S.; Hamdy, M. A robustness-based decision making approach for multi-target high performance buildings under uncertain scenarios. Appl. Energy 2020, 267, 114868. [Google Scholar] [CrossRef]
- Korkmaz, S.; Messner, J.I.; Riley, D.R.; Magent, C. High-Performance Green Building Design Process Modeling and Integrated Use of Visualization Tools. J. Arch. Eng. 2010, 16, 37–45. [Google Scholar] [CrossRef]
- Pieter De, W.; Godfried, A.; Marinus Van Der, V. Managing the selection of energy saving features in building design. Eng. Constr. Archit. Manag. 2002, 9, 192–208. [Google Scholar]
- Wilde, P.D.; Voorden, M.V.D. Providing computational support for the selection of energy saving building components. Energy Build. 2004, 36, 749–758. [Google Scholar] [CrossRef]
- Struck, C.; De Wilde, P.J.; Hopfe, C.J.; Hensen, J.L. An investigation of the option space in conceptual building design for advanced building simulation. Adv. Eng. Inform. 2009, 23, 386–395. [Google Scholar] [CrossRef] [Green Version]
- Kanters, J.; Horvat, M.; Dubois, M.-C. Tools and methods used by architects for solar design. Energy Build. 2014, 68, 721–731. [Google Scholar] [CrossRef]
- Ruggeri, A.G.; Calzolari, M.; Scarpa, M.; Gabrielli, L.; Davoli, P. Planning energy retrofit on historic building stocks: A score-driven decision support system. Energy Build. 2020, 224, 110066. [Google Scholar] [CrossRef]
- Zou, P.X.; Wagle, D.; Alam, M. Strategies for minimizing building energy performance gaps between the design intend and the reality. Energy Build. 2019, 191, 31–41. [Google Scholar] [CrossRef]
- Hsu, H.-C.; Chang, S.; Chen, C.-C.; Wu, I.-C. Knowledge-based system for resolving design clashes in building information models. Autom. Constr. 2020, 110, 103001. [Google Scholar] [CrossRef]
- Fan, C.; Xiao, F. Mining Gradual Patterns in Big Building Operational Data for Building Energy Efficiency Enhancement. Energy Procedia 2017, 143, 119–124. [Google Scholar] [CrossRef]
- Pickering, E.M.; Hossain, M.A.; French, R.H.; Abramson, A.R. Building electricity consumption: Data analytics of building operations with classical time series decomposition and case based subsetting. Energy Build. 2018, 177, 184–196. [Google Scholar] [CrossRef]
- Fan, C.; Xiao, F.; Li, Z.; Wang, J. Unsupervised data analytics in mining big building operational data for energy efficiency enhancement: A review. Energy Build. 2018, 159, 296–308. [Google Scholar] [CrossRef]
- Granadeiro, V.; Correia, J.R.; Leal, V.M.S.; Duarte, J.P. Envelope-related energy demand: A design indicator of energy per-formance for residential buildings in early design stages. Energy Build. 2013, 61, 215–223. [Google Scholar] [CrossRef]
- Michaels, T.; Leckey, J. Commercial Buildings Energy Consumption Survey. 2012. Available online: https://www.eia.gov/consumption/commercial/ (accessed on 3 March 2021).
- Davis, R.; Shrobe, H.; Szolovits, P. What is a knowledge representation? AI Mag. 1993, 14, 17–33. [Google Scholar]
- Chen, S.; Zhang, G.; Xia, X.; Setunge, S.; Shi, L. A review of internal and external influencing factors on energy efficiency design of buildings. Energy Build. 2020, 216, 109944. [Google Scholar] [CrossRef]
- Depecker, P.; Menezo, C.; Virgone, J.; Lepers, S. Design of buildings shape and energetic consumption. Build. Environ. 2001, 36, 627–635. [Google Scholar] [CrossRef]
- Grosan, C.; Abraham, A. Rule-Based Expert Systems. In Contactless Human Activity Analysis; Ahad, M.A.R., Mahbub, U., Rahman, T., Eds.; Springer Science and Business Media LLC: Berlin, Germany, 2011; Volume 17, pp. 149–185. [Google Scholar]
- Fuzzy Logic. Available online: https://en.wikipedia.org/wiki/Fuzzy_logic (accessed on 3 March 2021).
- Wang, C.; Cho, Y.K. Application of As-built Data in Building Retrofit Decision Making Process. Procedia Eng. 2015, 118, 902–908. [Google Scholar] [CrossRef] [Green Version]
- Geyer, P. Systems modelling for sustainable building design. Adv. Eng. Inform. 2012, 26, 656–668. [Google Scholar] [CrossRef]
- Kim, S.H. Automating building energy system modeling and analysis: An approach based on SysML and model transfor-mations. Autom. Constr. 2014, 41, 119–138. [Google Scholar] [CrossRef]
- Ślusarczyk, G.; Łachwa, A.; Palacz, W.; Strug, B.; Paszyńska, A.; Grabska, E. An extended hierarchical graph-based building model for design and engineering problems. Autom. Constr. 2017, 74, 95–102. [Google Scholar] [CrossRef]
- Solihin, W.; Eastman, C.; Lee, Y.-C.; Yang, D.-H. A simplified relational database schema for transformation of BIM data into a query-efficient and spatially enabled database. Autom. Constr. 2017, 84, 367–383. [Google Scholar] [CrossRef]
- Montali, J.; Sauchelli, M.; Jin, Q.; Overend, M. Knowledge-rich optimisation of prefabricated façades to support conceptual design. Autom. Constr. 2019, 97, 192–204. [Google Scholar] [CrossRef] [Green Version]
- Pauwels, P.; Krijnen, T.; Terkaj, W.; Beetz, J. Enhancing the ifcOWL ontology with an alternative representation for geometric data. Autom. Constr. 2017, 80, 77–94. [Google Scholar] [CrossRef] [Green Version]
- Mousavi, A.; Vyatkin, V. Energy Efficient Agent Function Block: A semantic agent approach to IEC 61499 function blocks in energy efficient building automation systems. Autom. Constr. 2015, 54, 127–142. [Google Scholar] [CrossRef]
- Pavlak, G.S.; Henze, G.P.; Hirsch, A.I.; Florita, A.R.; Dodier, R.H. Experimental verification of an energy consumption signal tool for operational decision support in an office building. Autom. Constr. 2016, 72, 75–92. [Google Scholar] [CrossRef]
- Kim, D.; Bae, Y.; Yun, S.; Braun, J.E. A methodology for generating reduced-order models for large-scale buildings using the Krylov subspace method. J. Build. Perform. Simul. 2020, 13, 419–429. [Google Scholar] [CrossRef]
- Legorburu, G.; Smith, A.D. Incorporating observed data into early design energy models for life cycle cost and carbon emissions analysis of campus buildings. Energy Build. 2020, 224, 110279. [Google Scholar] [CrossRef]
- Catalina, T.; Iordache, V.; Caracaleanu, B. Multiple regression model for fast prediction of the heating energy demand. Energy Build. 2013, 57, 302–312. [Google Scholar] [CrossRef]
- Chou, J.-S.; Bui, D.-K. Modeling heating and cooling loads by artificial intelligence for energy-efficient building design. Energy Build. 2014, 82, 437–446. [Google Scholar] [CrossRef]
- Ngo, N.-T. Early predicting cooling loads for energy-efficient design in office buildings by machine learning. Energy Build. 2019, 182, 264–273. [Google Scholar] [CrossRef]
- Jun, M.; Cheng, J.C. Selection of target LEED credits based on project information and climatic factors using data mining techniques. Adv. Eng. Inform. 2017, 32, 224–236. [Google Scholar] [CrossRef]
- Talami, R.; Jakubiec, J.A. Early-design sensitivity of radiant cooled office buildings in the tropics for building performance. Energy Build. 2020, 223, 110177. [Google Scholar] [CrossRef]
- Miller, C.; Nagy, Z.; Schlueter, A. Automated daily pattern filtering of measured building performance data. Autom. Constr. 2015, 49, 1–17. [Google Scholar] [CrossRef]
- Faia, R.; Pinto, T.; Abrishambaf, O.; Fernandes, F.; Vale, Z.; Corchado, J.M. Case based reasoning with expert system and swarm intelligence to determine energy reduction in buildings energy management. Energy Build. 2017, 155, 269–281. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Ning, C.; Deb, C.; Zhang, F.; Cheong, D.; Lee, S.E.; Sekhar, C.; Tham, K.W. k-Shape clustering algorithm for building energy usage patterns analysis and forecasting model accuracy improvement. Energy Build. 2017, 146, 27–37. [Google Scholar] [CrossRef]
- Beach, T.H.; Rezgui, Y.; Li, H.; Kasim, T. A rule-based semantic approach for automated regulatory compliance in the con-struction sector. Expert Syst. Appl. 2015, 42, 5219–5231. [Google Scholar] [CrossRef] [Green Version]
- Yarmohammadi, S.; Pourabolghasem, R.; Shirazi, A.; Ashuri, B. A Sequential Pattern Mining Approach to Extract Information from BIM Design Log Files. In Proceedings of the 33rd International Symposium on Automation and Robotics in Construction (ISARC), International Association for Automation and Robotics in Construction (IAARC), Auburn, AU, USA, 18–21 July 2016; pp. 174–181. [Google Scholar]
- Lapisa, R.; Bozonnet, E.; Salagnac, P.; Abadie, M. Optimized design of low-rise commercial buildings under various climates – Energy performance and passive cooling strategies. Build. Environ. 2018, 132, 83–95. [Google Scholar] [CrossRef]
- Statistical Classification. Available online: https://en.wikipedia.org/wiki/Statistical_classification (accessed on 3 March 2021).
- Shahi, A.; Sulaiman, N.; Mustapha, N.; Perumal, T. Naive Bayesian decision model for the interoperability of heterogeneous systems in an intelligent building environment. Autom. Constr. 2015, 54, 83–92. [Google Scholar] [CrossRef]
- Saltelli, A.; Tarantola, S.; Campolongo, F.; Ratto, M. Global Sensitivity Analysis for Importance Assessment. Sensit. Anal. Pract. 2004, 22, 31–61. [Google Scholar] [CrossRef]
- Multi-Agent System. Available online: https://en.wikipedia.org/wiki/Multi-agent_system (accessed on 3 March 2021).
- Arroyo, P.; Tommelein, I.D.; Ballard, G. Comparing AHP and CBA as Decision Methods to Resolve the Choosing Problem in Detailed Design. J. Constr. Eng. Manag. 2015, 141, 04014063. [Google Scholar] [CrossRef]
- Motawa, I.; Almarshad, A. A knowledge-based BIM system for building maintenance. Autom. Constr. 2013, 29, 173–182. [Google Scholar] [CrossRef]
- Invidiata, A.; Lavagna, M.; Ghisi, E. Selecting design strategies using multi-criteria decision making to improve the sus-tainability of buildings. Build. Environ. 2018, 139, 58–68. [Google Scholar] [CrossRef]
- Farsäter, K.; Strandberg, P.; Wahlström, Å. Building status obtained before renovating multifamily buildings in Sweden. J. Build. Eng. 2019, 24, 100723. [Google Scholar] [CrossRef]
- Serrano-Jiménez, A.; Femenías, P.; Thuvander, L.; Barrios-Padura, Á. A multi-criteria decision support method towards selecting feasible and sustainable housing renovation strategies. J. Clean. Prod. 2021, 278, 123588. [Google Scholar] [CrossRef]
- Brown, N.C. Design performance and designer preference in an interactive, data-driven conceptual building design scenario. Des. Stud. 2020, 68, 1–33. [Google Scholar] [CrossRef]












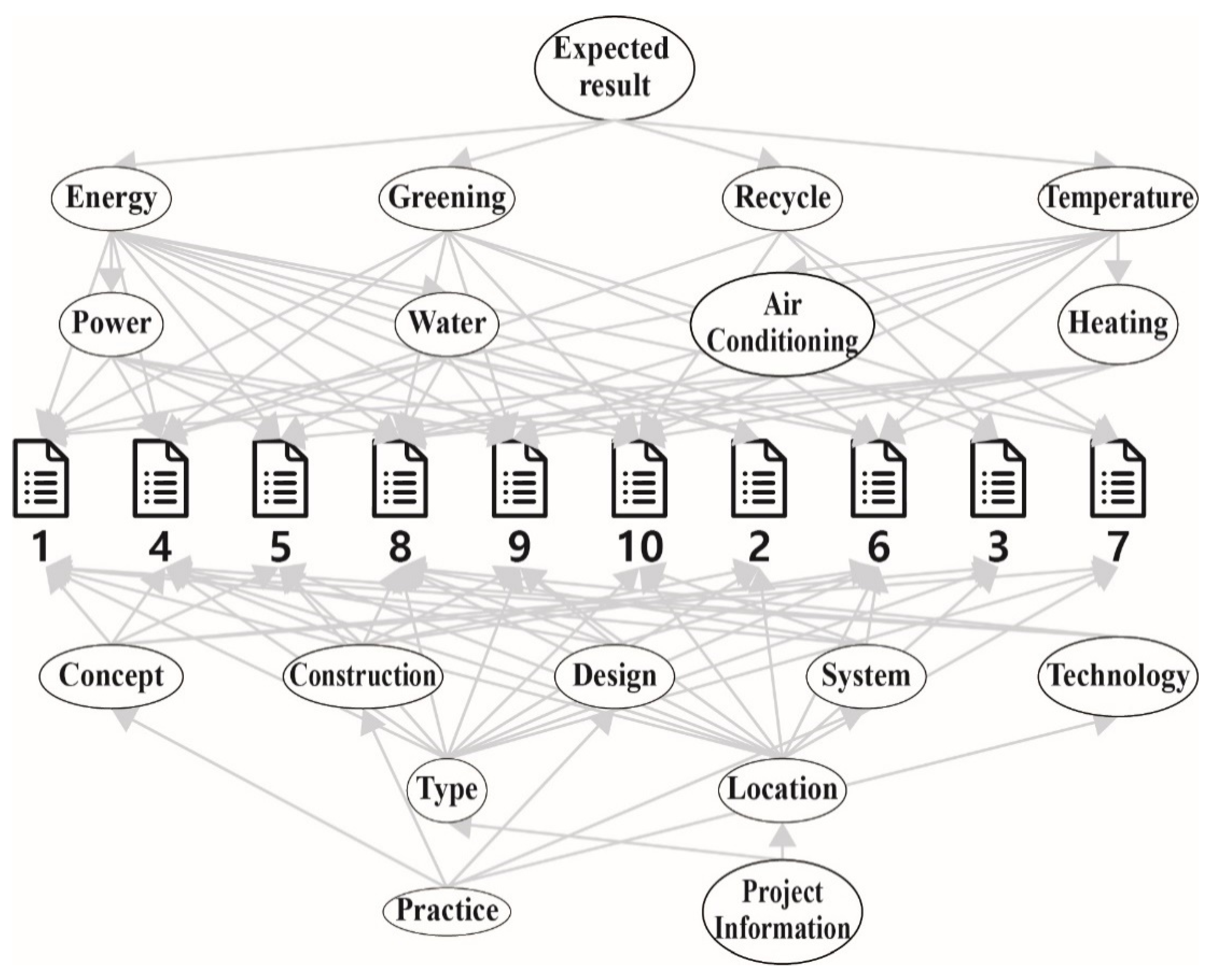

| PD-I. Analysis problems |
| PD-I-1. Understanding and comparison: identifying difference or similarity of expected outcomes PD-I-2. Classification: categorizing based on observables PD-I-3. Interpretation: inferring situation description from numeric and text data PD-I-4. Prediction: Inferring likely consequences of given situations |
| PD-II. Synthesis problems |
| PD-II-1. Configuration: configuring collections of objects under considerations in framework or platform PD-II-2. Planning and design: configuring collections of objects under considerations in relatively large search spaces PD-II-3. Process design: planning with strong temporal and/or spatial constraints |
| KA-I. Heuristic acquisition |
| KA-I-1. Unstructured interviews with experts and users KA-I-2. Structured surveys with experts and users KA-I-3. Protocol, code, guideline analysis KA-I-4. Customary practice, business convention, de-facto standards |
| KA-II. Computer-aided acquisition |
| KA-II-1. Web search KA-II-2. Databases, digital libraries, ISPs KA-II-3. Transactional and operational data (i.e., measured data) KA-II-4. Simulated data |
| KA-I-1. | Unstructured interviews | Energy saving features [61,62,63], Solar design [64] |
| KA-I-2. | Structured surveys | AHP [41,65], systemic group survey [49,57]; CBA [16]; CBR [30,31]; Energy saving features [61,62]; Usability testing [24] Building energy performance gap [66] |
| KA-I-3. | Protocol, code, guideline analysis | Energy code [27,52]; BREEAM [47] |
| KA-I-4. | Customary practice, convention, de-facto standards | Daylight knowledge base [28]; Servicescape rule extraction [40]; Façade design rule [52]; Clash database schema and feature definitions [67] |
| KA-II-1. | Web search | Semantic web [42,48,49] |
| KA-II-2. | Databases and ISPs | Manufacturers’ DB [55], Green material DB [47], GIS and climate service [48], Energy benchmark [19,20,36] |
| KA-II-3. | Transactional and operational data | Energy audit [17,18], Operation data [68,69,70] |
| KA-II-4. | Simulated data | Design of experiment [54], Simulated energy data [25,29,32,33,34,71], Optimization [37,39,43,45] |
| KR-I. Logic, equations and rules |
| KR-I-1. First order logic and formula KR-I-2. If-then rules and case statements KR-I-3. Fuzzy logic |
| KR-II. Semantics and ontology |
| KR-II-1. RDF, OWL and SWRL KR-II-2. Proprietary sematic model and ontology KR-II-3. Building information model |
| KR-III. Analysis model and simulation |
| KR-III -1. Analysis model KR-III -2. Building performance simulation |
| KR-IV. Machine learning |
| KR-IV-1. Regression KR-IV-2. Classifiers KR-IV-3. Neural networks KR-IV-4. Trees KR-IV-5. Primary factors KR-IV-6. Clusters KR-IV-7. Pattern and association rule extraction KR-IV-8. Multi agent systems KR-IV-9. Optimization |
| KR-V. Case-based reasoning |
| KR-VI. Group decision making |
| KR-I-1. | First order logic and formula | Design indicator of energy performance [71], Robustness and performance indicator [59] Building geometry indicator [74] |
| KR-I-2. | If-then rules | Design guideline [54], Servicescape design rule [40], Building design alternative rule [52] |
| KR-I-3. | Fuzzy logic | Design logic [28,38], Performance level assessment [41], Consensus scheme [57] |
| KR-II-1. | Sematic model and ontology | Performance assessment ontology, simulation Domain Model ontology, semantic Sensor Network ontology [50], SEMERGY building model [48], Information extraction ontology [27], gbXML for as-built building scanning [78], SysML for sustainable building design [79,80], Hierarchical graph-based building model [81], Relational database schema for transformation of BIM [82], Product-oriented knowledge base and optimization process model [83] |
| KR-II-2. | RDFS, OWL and SWRL | Structural design rule [49], ifcOWL [50,84], Semantic BIM [55], SEMERGY building model [48], Linked data ontology [42], Energy efficiency knowledge base [85] |
| KR-II-3. | Building information model | BIM integrated with performance based design [29,44,45,47] |
| KR-III-1. | Analysis model | Inverse gray box reduced order model [86], Reduced order model [87], VRF and air handler [88] |
| KR-III-2. | Building performance simulation | Daylight simulation [28,38], Energy simulation [24,51,52,55], IAQ [29,51] |
| KR-IV-1. | Regression | Regression [25,33,34,36], Multiple regression [89], Support vector regression [90,91] |
| KR-IV-2. | Classification | SVM [36], Random Forests, AdaBoost Decision Tree, SVM [92] |
| KR-IV-3. | Neural networks | Neuro fuzzy [32], ANN [36,90,91] |
| KR-IV-4. | Trees | Random forest [36], Classification and regression tree [20,91,92], Random Forests, AdaBoost Decision Tree [92], Conditional inference tree [14] |
| KR-IV-5. | Primary factors | Main effects [54], Factor effects [29], Sensitivity analysis [18,25,33,35,93] |
| KR-IV-6. | Clustering | k-means [16,17,18,19,94], KNN [95], k-shape clustering [96], DBSCAN [45] |
| KR-IV-7. | Pattern and association rule extraction | Text mining [30,31], Pattern matching extraction [27], Bayesian inference [86], Automated regulatory compliance check [97], Sequential pattern mining [98], Association rule learning [45] |
| KR-IV-8. | Optimization | Multi-criteria optimization [16,37,55], Passive performance optimization [43,99], BIM-based design optimization [45], Expert system for refurbishment [39] |
| KR-IV-8. | Multi agent systems | Design exploration [53] |
| KR-V. | Case-based reasoning | Case representation and retrieval [16,30,31,104], Case based reasoning with expert system [97], Knowledge-based BIM [105] |
| KR-VI. | Group decision support system | AHP [57,104], Choosing by advantage [16], Score-driven decision support [65], Multi-criteria decision making [106,107,108] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, S.Y.; Kim, S.H. Knowledge Acquisition and Representation for High-Performance Building Design: A Review for Defining Requirements for Developing a Design Expert System. Sustainability 2021, 13, 4640. https://doi.org/10.3390/su13094640
Choi SY, Kim SH. Knowledge Acquisition and Representation for High-Performance Building Design: A Review for Defining Requirements for Developing a Design Expert System. Sustainability. 2021; 13(9):4640. https://doi.org/10.3390/su13094640
Chicago/Turabian StyleChoi, Seung Yeoun, and Sean Hay Kim. 2021. "Knowledge Acquisition and Representation for High-Performance Building Design: A Review for Defining Requirements for Developing a Design Expert System" Sustainability 13, no. 9: 4640. https://doi.org/10.3390/su13094640
APA StyleChoi, S. Y., & Kim, S. H. (2021). Knowledge Acquisition and Representation for High-Performance Building Design: A Review for Defining Requirements for Developing a Design Expert System. Sustainability, 13(9), 4640. https://doi.org/10.3390/su13094640