


Applying Self-Optimised Feedback to a Learning Management System for Facilitating Personalised Learning Activities on Massive Open Online Courses


Abstract
:1. Introduction
- Aim1:
- To comprehensively understand the generic feedback process through extensive research, including the design, pipeline, structure, and content of feedback messages, among other aspects.
- Aim2:
- To extract pertinent information from website resources based on learners’ demands and individual backgrounds, facilitating the design of modules and a planner system to optimise the learning process accordingly.
- Aim3:
- To design a system capable of recording platform communications, including interaction logs and quiz attempts, thereby enhancing the system’s capacity for automated feedback in future iterations.
2. Background
2.1. Preliminary Knowledge
2.1.1. Learning Analytics
2.1.2. Effect of Gamification
2.2. Categorisation and Frameworks
2.2.1. Learning Process
2.2.2. Learning Analytics Visualisation
2.2.3. Learning Feedback
2.2.4. Learning Result Analysis
2.3. Gaps of Existing Research
2.4. Motivation
2.5. Main Research Topics
2.5.1. Impact of Learning Analytics-Based(LAB) Process Feedback in a Large Course
2.5.2. Metacognitive Control
2.5.3. Multimodal Learning Analytics
2.6. Hypothesis
2.7. Research Objectives
2.7.1. Personalised Feedback
- Instructors:
- Track students’ course completion patterns to evaluate students’ engagement with the online course.
- Discern the concepts/topics that are most confusing for students by analysing forums.
- Evaluate the quality and difficulty of quizzes/assignments by examining results.
- Evaluate the study patterns by checking clicks per student for pre-reading materials.
- Analyse surveys for queries regarding course instructions.
- Learning researchers:
- Observe the relation between students’ course completion patterns and their results.
- Analyse keystroke rhythm recognition for each student to maintain the integrity of online submissions.
2.7.2. Design of Feedback
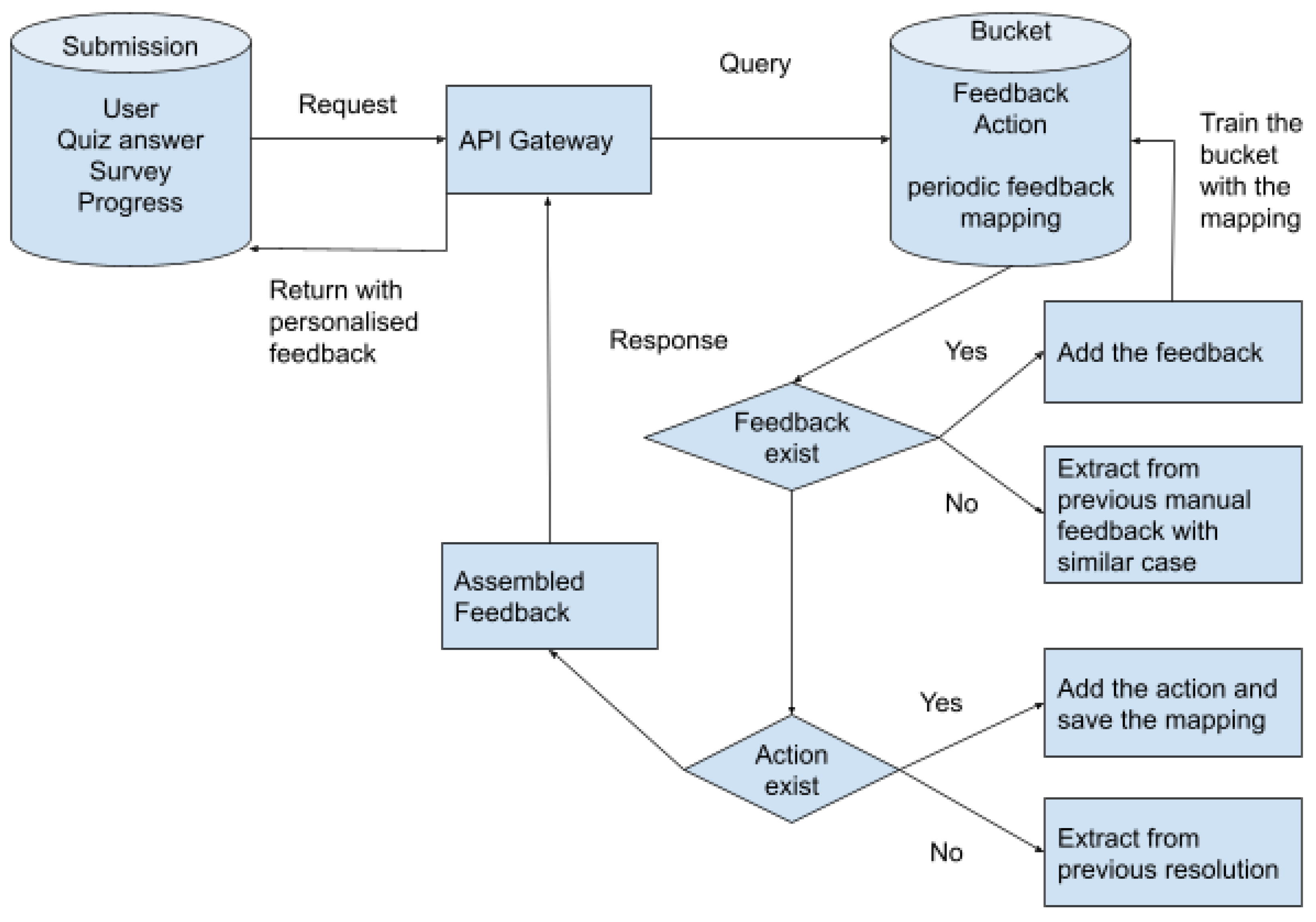
2.7.3. The Pipeline of Feedback Data
2.7.4. Structure and Content of Feedback Message
2.8. Research Methods
2.8.1. Learning Data
<Analyzing_Result> <Sender=‘‘Activity_Agent‘‘/> <Destination=‘‘Modeling_Agent‘‘/> <TimeStamp=‘‘15/9/25/08/2021‘‘/> <LearnerName=‘‘Tony‘‘/> <LearnerID=‘‘990013‘‘/> <CourseID=‘‘FB2500‘‘/> <Stage=‘‘Afterpretest‘‘/> <Individual_Summary Subject=‘‘Pretest‘‘/> <Range=‘‘Course‘‘/> <TimeSpent=‘‘20m\‘‘/> <HitCounts=‘‘13\‘‘/> <Percentage_of_cor />
- Slides completion analysis;
- Slides time taken analysis;
- Quiz time taken analysis;
- Quiz answer analysis;
- Learning interval;
- Visited page tracking;
- Submitted quiz answers;
- Questionnaires.
2.8.2. Classification, Regression, and Clustering
2.8.3. Natural Language Processing
3. Research Design
3.1. Experiment Hypothesis
3.2. Experiment Setup
3.2.1. Experiment Conditions
3.2.2. Evaluation
4. Results
4.1. Data Collection Process
4.2. Data Import
import pandas as pd
import seaborn as sns
import numpy as np
data = pd.read_csv('~/Downloads/PersonalisedLearning.csv')
data.head()
4.3. Data Prepossessing
data = pd.get_dummies(data) data = data.fillna(0)
from sklearn.preprocessing import StandardScaler data = StandardScaler().fit_transform(data)
4.4. Data Clustering and Shaping
kmeans = KMeans(n_clusters=3) clusters = kmeans.fit_predict(data) from sklearn.cluster import KMeans
from sklearn.cluster import KMeans kmeans = KMeans(n_clusters=3) clusters = kmeans.fit_predict(data)
4.5. Provide Personalised Feedback to Each Student Based on Cluster
feedback = {
0: 'You may benefit from setting specific goals for studying and breaking tasks into manageable parts.',
1: 'Keep up the great work!',
2: 'You may benefit from establishing specific study schedules and creating a distraction-free study environment.'
}
for i in range(len(data)): cluster_num = clusters[i]
print('Student {}: {}'.format(i, feedback[cluster_num]))
4.6. Data Analysis
4.6.1. t-Test for Hypothesis 1
import pandas as pd import seaborn as sns import numpy as np import scipy.stats as stats
q1_feedback_scores = [3, 5, 5, 4, 4, 3, 5, 5] q3_feedback_scores = [4, 5, 5, 4, 4, 4, 5, 5]
t_statistic, p_value = stats.ttest_ind(q1_feedback_scores, q3_feedback_scores) print(‘‘T-Statistic: '', t_statistic) print(‘‘P-Value: '', p_value)
-
T-Statistic: −0.6831300510639732 p-Value: 0.5056732339622882
4.6.2. ANOVA for Hypothesis 2
n1_scores = [2, 3, 3] n2_scores = [4, 4, 5] pf1_scores = [4, 5, 4] pf2_scores = [4, 4, 5]
f_value, p_value = stats.f_oneway(pf1_scores, pf2_scores, n1_scores, n2_scores) print(‘‘F-value:'', f_value) print(‘‘p-value:'', p_value)
if p_value < 0.05:
print(‘‘There is a significant difference in test scores between the 2 groups.'')
else:
print(‘‘There is not a significant difference in test scores between the 2 groups.'')
5. Conclusions and Future Work
5.1. Conclusions
5.2. Future Work
5.2.1. Feedback of Feedback
5.2.2. Tukey’s HSD Post-Hoc Test
5.2.3. Bridge the Required but Missing Information to Evaluate Each Individual’s Portfolio Matrix and Learning Progress
5.2.4. Investigate the Various Forms of Participant Support Offered in These Digital Learning Environments
5.2.5. The Design and Development of an Innovative Online Virtual Simulation Course Platform
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pandey, A. What is Personalized Learning? 2017. Available online: https://medium.com/%20personalizing-the-learning-experience-insights/what-is-personalized-learning-bc874799b6f (accessed on 1 June 2023).
- Henderson, M.; Boud, D.; Molloy, E.; Ajjawi, R. The Impact of Feedback in Higher Education; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Lim, L.A.; Dawson, S.; Gašević, D.; Joksimović, S.; Pardo, A.; Fudge, A.; Gentili, S. Students’ perceptions of, and emotional responses to, personalised learning analytics-based feedback: An exploratory study of four courses. Assess. Eval. High. Educ. 2021, 46, 339–359. [Google Scholar] [CrossRef]
- Fischer, H.; Heinz, M. Onboarding by Gamification. Design and Evaluation of an Online Service to Support First Year Students. In EdMedia+ Innovate Learning; Association for the Advancement of Computing in Education: Chesapeake, VA, USA, 2020. [Google Scholar]
- Reich, J.; Ruipérez-Valiente, J.A. The MOOC Pivot. Science 2019, 363, 130–131. [Google Scholar] [CrossRef] [PubMed]
- Han-Huei Tsay, C.; Kofinas, A.; Luo, J. Enhancing student learning experience with technology-mediated gamification: An empirical study. Comput. Educ. 2018, 121, 1–17. [Google Scholar] [CrossRef]
- Leftheriotis, I.; Giannakos, M.N.; Jaccher, L. Gamifying informal learning activities using interactive displays: An empirical investigation of students’ learning and engagement. Smart Learn. Environ. 2017, 4, 2. [Google Scholar] [CrossRef]
- Antonaci, A.; Klemke, R.; Stracke, C.M.; Specht, M. Gamification in MOOCs to enhance users’ goal achievement. In Proceedings of the 2017 IEEE Global Engineering Education Conference (EDUCON), Athens, Greece, 25–28 April 2017. [Google Scholar]
- Henderikx, M.A.; Kreijns, K.; Kalz, M. Refining success and dropout in massive open online courses based on the intention–behavior gap. Distance Educ. 2017, 38, 353–368. [Google Scholar] [CrossRef]
- Antonaci, A.; Klemke, R.; Specht, M. The Effects of Gamification in Online Learning Environments: A Systematic Literature Review. Informatics 2019, 6, 32. [Google Scholar] [CrossRef]
- Halli, S.; Lavoué, E.; Serna, A. To Tailor or Not to Tailor Gamification? An Analysis of the Impact of Tailored Game Elements on Learners’ Behaviours and Motivation. In International Conference on Artificial Intelligence in Education; Springer International Publishing: Cham, Switzerland, 2020. [Google Scholar]
- Faust, A. The Effects of Gamification on Motivation and Performance; Springer Gabler: Berlin, Germany, 2021. [Google Scholar]
- Riiid Answer Correctness Prediction. 2020. Available online: https://www.kaggle.com/c/riiid-test-answer-prediction/overview/description (accessed on 1 June 2023).
- Iandoli, L.; Quinto, I.; De Liddo, A.; Buckingham Shum, S. Socially-augmented argumentation tools: Rationale, design and evaluation of a debate dashboard. Int. J.-Hum.-Comput. Stud. 2014, 72, 298–319. [Google Scholar] [CrossRef]
- Brusilovsky, P. KnowledgeTree: A distributed architecture for adaptive e-learning. In Proceedings of the 13th international World Wide Web conference on Alternate track Papers & Poster, New York, NY, USA, 19–24 May 2004. [Google Scholar]
- Kitto, K. Using Data to Help Students Get on TRACK to Success. 2020. Available online: https://lx.uts.edu.au/blog/2020/02/24/using-data-to-help-students-get-on-track-to-success/ (accessed on 1 June 2023).
- Xua, D.; Wang, H. Intelligent agent supported personalization for virtual learning environments. Decis. Support Syst. 2005, 42, 825–843. [Google Scholar] [CrossRef]
- Antonaci, A.; Klemke, R.; Dirk, K.; Specht, M. May the Plan be with you! A Usability Study of the Stimulated Planning Game Element Embedded in a MOOC Platform. Int. J. Serious Games 2019, 6, 49–70. [Google Scholar] [CrossRef]
- Pardo, A. OnTask has piloted courses at USYD, UTS, UniSA, UNSW and UTA. 2020. Available online: https://www.ontasklearning.org/ (accessed on 1 June 2023).
- Pardo, A.; Liu, D.; Vigentini, L.; Blumenstein, M. Scaling Personalised Student Communication Current Initiatives and Future Directions. In Australian Learning Analytics Summer Institute “Promoting Cross-Disciplinary Collaborations, Linking Data, and Building Scale”; 2019; Available online: https://www.ontasklearning.org/wp-content/uploads/ALASI_Scale_personalised_communication_2019.pdf (accessed on 1 June 2023).
- Lim, L.A.; Gentili, S.; Pardo, A.; Kovanović, V.; Whitelock-Wainwright, A.; Gašević, D.; Dawsona, S. What changes, and for whom? A study of the impact of learning analytics-based process feedback in a large course. Learn. Instr. 2019, 72, 101202. [Google Scholar] [CrossRef]
- Piloting Personalised Feedback at Scale with OnTask. 2019. Available online: https://cic.uts.edu.au/piloting-personalised-feedback-at-scale-with-ontask/ (accessed on 1 June 2023).
- Roosta, F.; Taghiyareh, F.; Mosharraf, M. Personalization of gamification-elements in an e-learning environment based on learners’ motivation. In Proceedings of the 2016 8th International Symposium on Telecommunications (IST), Tehran, Iran, 27–28 September 2016. [Google Scholar]
- de Marcos, L.; Domínguez, A.; de Navarrete, J.S.; Pagés, C. An empirical study comparing gamification and social networking on e-learning. Comput. Educ. 2014, 75, 82–91. [Google Scholar] [CrossRef]
- Hallifax, S.; Serna, A. Adaptive Gamification in Education: A Literature Review of Current Trends and Developments. In Transforming Learning with Meaningful Technologies: Proceedings of the 14th European Conference on Technology Enhanced Learning, EC-TEL 2019, Delft, The Netherlands, 16–19 September 2019; Springer International Publishing: Delft, The Netherlands, 2019. [Google Scholar]
- Lyons, K.E.; Zelazo, P. Monitoring, metacognition, and executive function: Elucidating the role of self-reflection in the development of self-regulation. Adv. Child Dev. Behav. 2011, 40, 379–412. [Google Scholar] [PubMed]
- Lang, C.; Siemens, G.; Wise, A.; Gasevic, D. (Eds.) Handbook of Learning Analytics; Society for Learning Analytics and Research: New York, NY, USA, 2019. [Google Scholar]
- Broadbent, J.; Panadero, E.; Boud, D. Implementing summative assessment with a formative flavour: A case study in a large class. Assess. Eval. High. Educ. 2018, 43, 307–322. [Google Scholar] [CrossRef]
- Krulwich, B.; Burkey, C. Learning user information interests through extraction of semantically significant phrases. In Proceedings of the AAAI Spring Symposium on Machine Learning in Information Access, Palo Alto, CA, USA, 25–27 March 1996. [Google Scholar]
- Alomari, M.M.; El-Kanj, H.; Alshdaifat, N.I.; Topal, A. A Framework for the Impact of Human Factors on the Effectiveness of Learning Management Systems. IEEE Access 2020, 8, 23542–23558. [Google Scholar] [CrossRef]
- Kreutzer, J.; Riezler, S. Self-Regulated Interactive Sequence-to-Sequence Learning. arXiv 2019, arXiv:1907.05190. [Google Scholar]
- Siddhant, A.; Lipton, Z.C. Deep Bayesian Active Learning for Natural Language Processing: Results of a Large-Scale Empirical Study. arXiv 2018, arXiv:1808.05697. [Google Scholar]
- Azevedo, R. MetaTutor: An Intelligent Multi-Agent Tutoring System Designed to Detect, Track, Model, and Foster Self-Regulated Learning. In Proceedings of the Fourth Workshop on Self-Regulated Learning in Educational Technologies; 2012. Available online: https://www.researchgate.net/profile/Francois_Bouchet2/publication/234163751_MetaTutor_An_Intelligent_MultiAgent_Tutoring_System_Designed_to_Detect_Track_Model_and_Foster_SelfRegulated_Learning/links/09e41512f0b6e88370000000/MetaTutor-An-Intelligent-Multi-Agent-Tutoring-System-Designed-to-Detect-Track-Model-and-Foster-Self-Regulated-Learning.pdf (accessed on 1 June 2023).
- Palmer, M. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Copenhagen, Denmark, 7–11 September 2017; Available online: https://www.aclweb.org/anthology/D17-1.pdf (accessed on 1 June 2023).
- Fang, M.; Li, Y.; Cohn, T. Learning how to Active Learn: A Deep Reinforcement Learning Approach. arXiv 2017, arXiv:1708.02383. [Google Scholar]


{kind=link}
{kind=link}
| Course Features | Feedback Message Details | |||||
|---|---|---|---|---|---|---|
| C/se | Dis. (No.) | CD | SA | No. of Feedback Emails | Metrics Used | Additional Message Content |
| A | HS (242) | Blended | 2 quizzes (20%), Practicals (25%), Final exam (55%) | 2 | Logins to course site; E-book assignment completion; Tutorial & workshop attendance; Quiz marks (pass/fail) | Tips for boosting learning skills; Offer of assistance from instructor |
| B | Arch (83) | Blended | Assignments (50%), Final project (50%) | 3 | Access to assessment-related links; Access to course resources; Quiz marks (pass/fail) | Motivational messages; Reminders; Offer of assistance from instructor |
| C | FS (215) | Blended | Quiz (15%), Progressive assessments (20% + 20% + 35%) Participation (10%) | 13 | Logins to course site; Access to assessment-related links; Access to course resources; Tutorial attendance; Assessment 1 & 2 marks | Motivational messages; Reminders; Tips for boosting learning skills; Offer of assistance from instructor |
| D | CE (601) | Flipped | Midterm exam (20%), Weekly online prep (20%), Project (20%), Final exam (20%) | 8 | Completion of weekly online prep; Outcome of weekly video quiz; Midterm grades | Recommended strategy to improve outcome |
| Condition | Feedback Message |
|---|---|
| 1 (no attempt) | The Accounting A Team have noticed that you are yet to attempt the learning quizzes from last week on
the topic of ‘Recording Accounting Transactions’.
|
| 2 (low performance: less than 50%) | The Accounting A Team and Iwould like to commended on your efforts to complete last weeks’ quizzes on ’Recording Accounting Transactions’, but would like to encourage you to continue practising this topic.
|
| 3 (average performance: 50–74%) | >Congratulations on making the effort to complete the learning quiz last week on the topic of ’Recording Accounting Transactions’. To improve your understanding:
|
| 4 (high performance: 75%+) | On behalf of the Accounting A Team, I’d like to congratulate you on completing the learning quiz from last week and receiving such a wonderful mark! |
| Detailed Feedback | ||
|---|---|---|
| Task Related | High (H) | Low (L) |
| High (H) | HH | LH |
| Low (L) | HL | LL |
| Detailed Feedback | General Feedback | |
|---|---|---|
| Non Task Related | The way you crafted these algorithms to fit together to take the machine learning tasks through the Nomral Language Process is very good. | good job |
| Task Related | Your goal was to write about all of the things you did (the events) in order. Yes, you have written the first thing first, but after that it becomes muddled. Your next step is to go back to your plan and check your numbering of the order of the events as they happened. Then you can use your plan to rewrite them in that order. | Provides information on which steps were done or not |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qi, X.; Sun, G.; Yue, L. Applying Self-Optimised Feedback to a Learning Management System for Facilitating Personalised Learning Activities on Massive Open Online Courses. Sustainability 2023, 15, 12562. https://doi.org/10.3390/su151612562
Qi X, Sun G, Yue L. Applying Self-Optimised Feedback to a Learning Management System for Facilitating Personalised Learning Activities on Massive Open Online Courses. Sustainability. 2023; 15(16):12562. https://doi.org/10.3390/su151612562
Chicago/Turabian StyleQi, Xin, Geng Sun, and Lin Yue. 2023. "Applying Self-Optimised Feedback to a Learning Management System for Facilitating Personalised Learning Activities on Massive Open Online Courses" Sustainability 15, no. 16: 12562. https://doi.org/10.3390/su151612562
APA StyleQi, X., Sun, G., & Yue, L. (2023). Applying Self-Optimised Feedback to a Learning Management System for Facilitating Personalised Learning Activities on Massive Open Online Courses. Sustainability, 15(16), 12562. https://doi.org/10.3390/su151612562