
An Outlier Detection Study of Ozone in Kolkata India by the Classical Statistics, Statistical Process Control and Functional Data Analysis

Abstract
:1. Introduction
2. Methods
2.1. Air Quality Monitoring Station, Kolkata, India
2.2. Analysis Methodology
2.3. Imputation
2.4. Classical Analysis
2.5. Statistical Process Control
2.6. Functional Data Analysis
- Extract the substitution of the original with a new sample.
- Via the statistics of this new sample, estimate the research parameter.
- Repeat the steps overhead a significant number of times. The Monte-Carlo simulation is often referred to as this repetition. It uses duplication to extract evidence from the data.
- Determine the empirical statistical distribution.
3. Results and Discussion
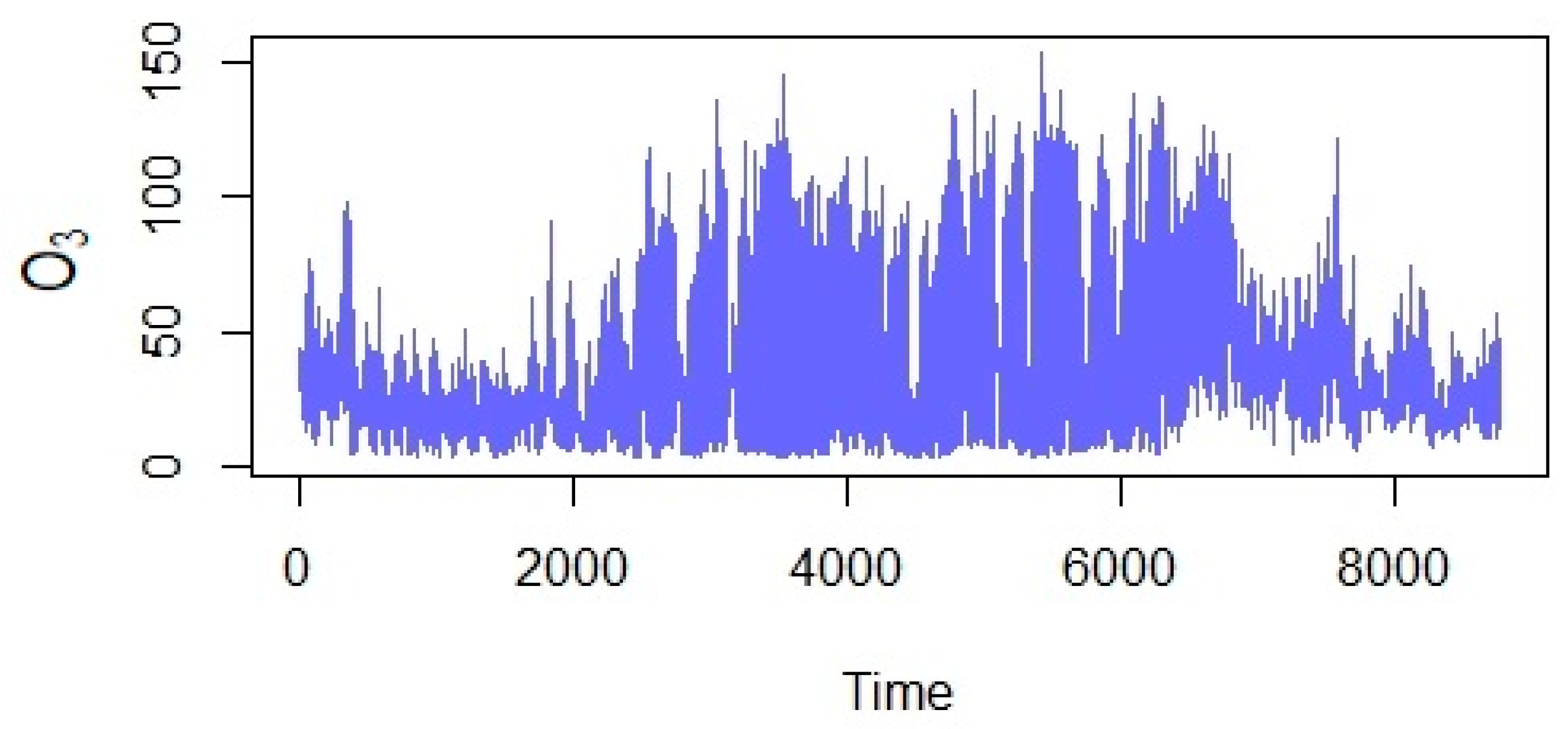
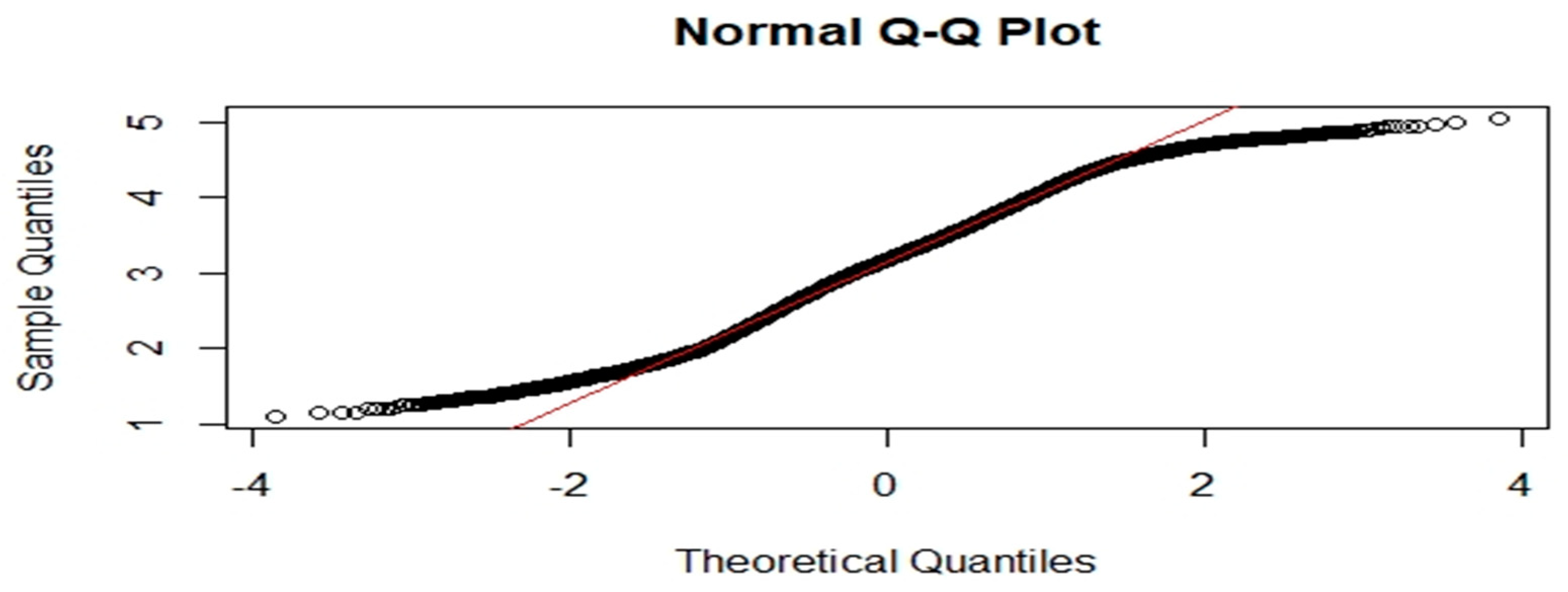
3.1. Classical Statistical Analysis
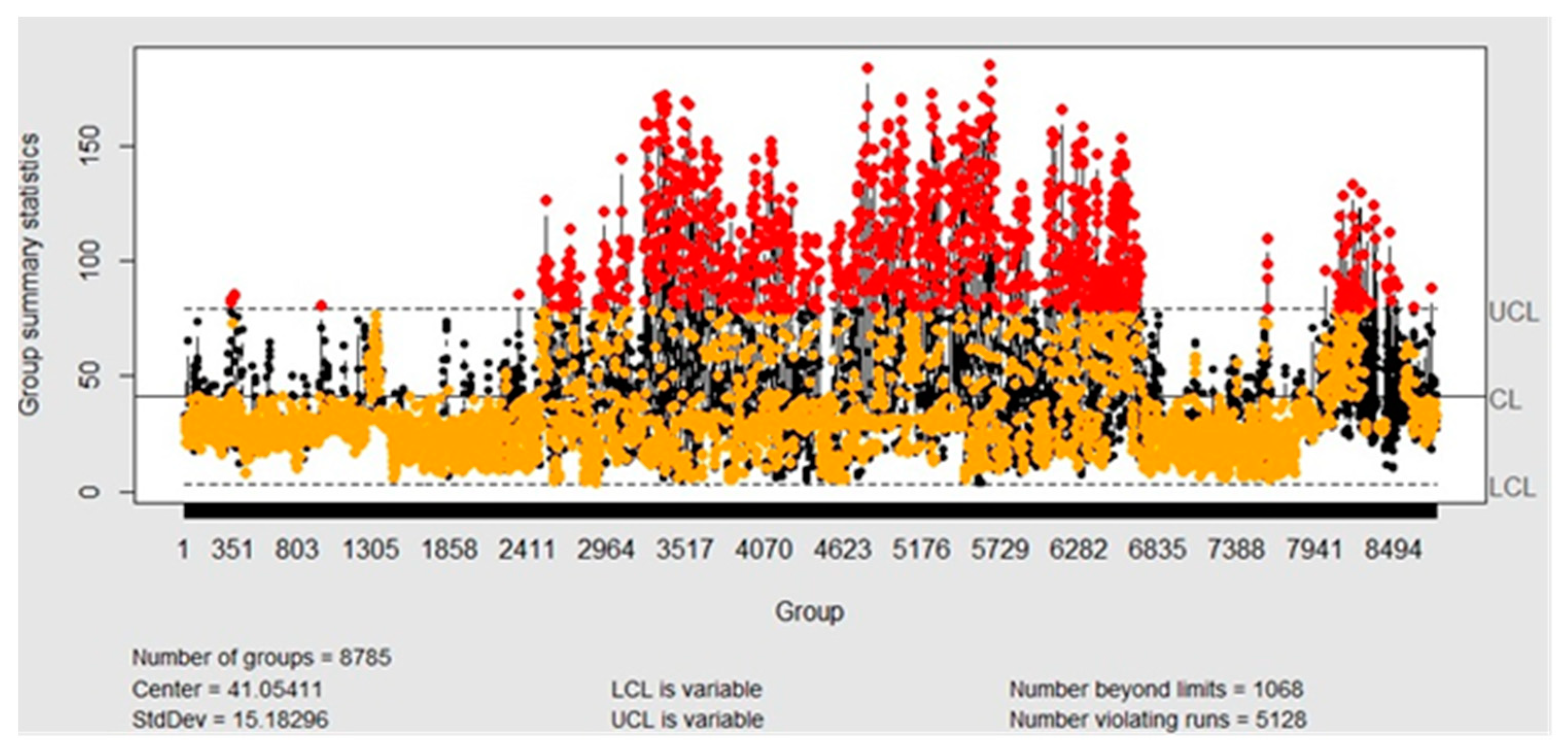
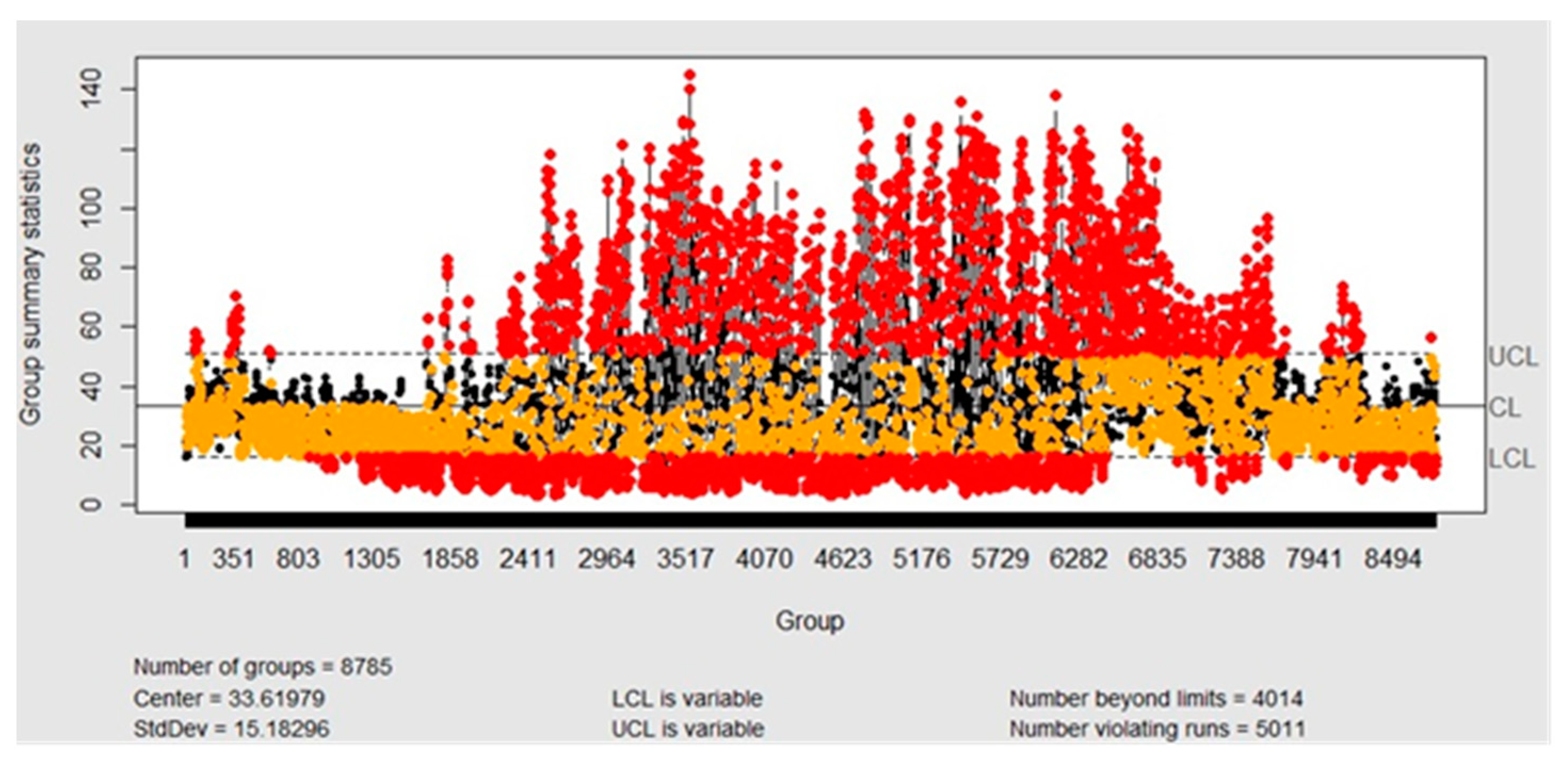
3.2. Statistical Process Control
- (I)
- Control I-MR Chart with Individual Mean
- (II)
- Control Chart with Hourly Rational Subgroups
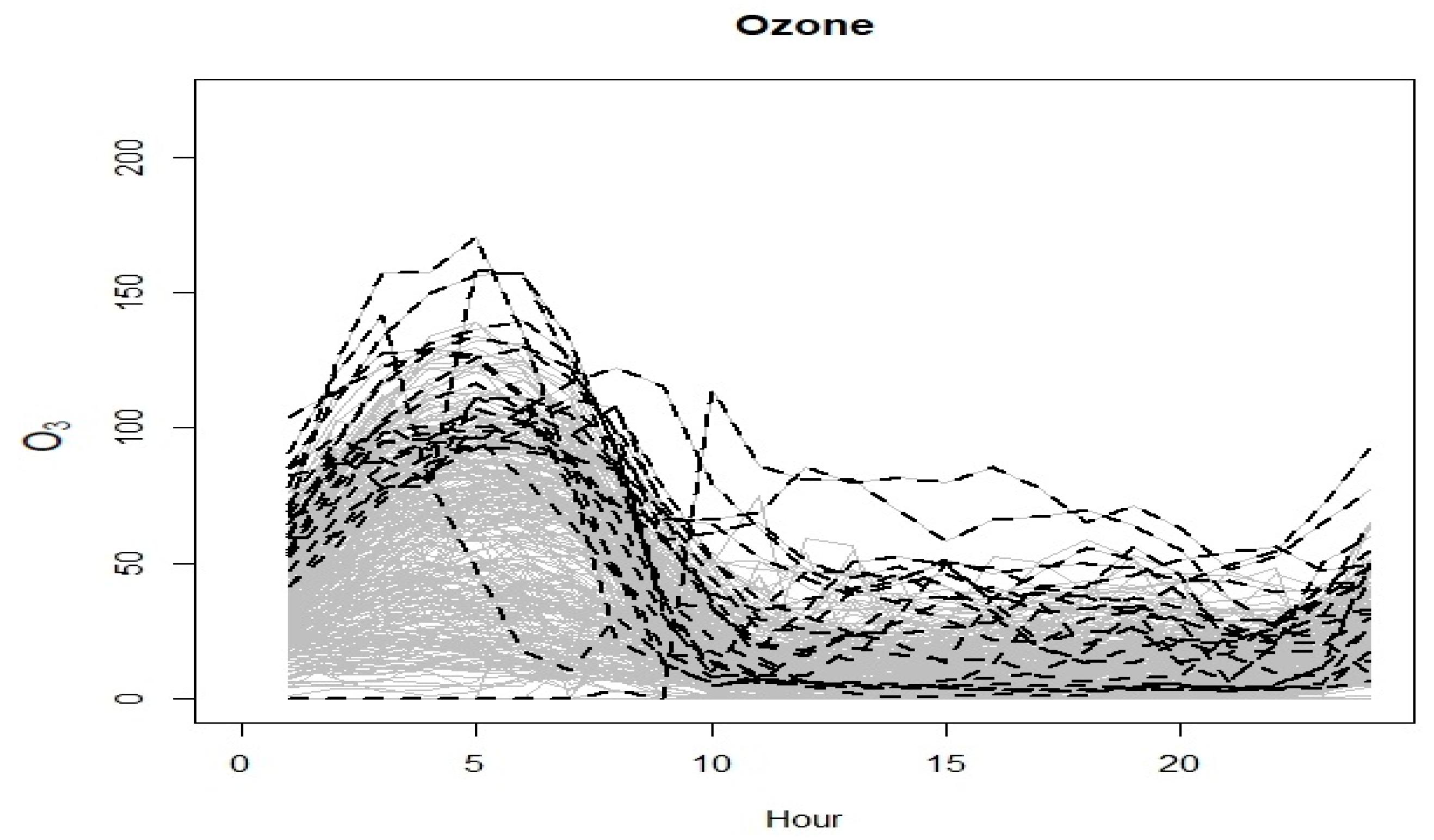
3.3. Functional Data Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chatterjee, A.; Sarkar, C.; Adak, A.; Mukherjee, U.; Ghosh, S.K.; Raha, S. Ambient air quality during Diwali Festival over Kolkata-a mega-city in India. Aerosol Air Qual. Res. 2013, 13, 1133–1144. [Google Scholar] [CrossRef]
- Haque, M.S.; Singh, R.B. Air pollution and human health in Kolkata, India: A case study. Climate 2017, 5, 77. [Google Scholar] [CrossRef]
- Kumar, K.; Pande, B.P. Air pollution prediction with machine learning: A case study of Indian cities. Int. J. Environ. Sci. Technol. 2023, 20, 5333–5348. [Google Scholar] [CrossRef] [PubMed]
- Majumdar, D.; Purohit, P.; Bhanarkar, A.D.; Rao, P.S.; Rafaj, P.; Amann, M.; Sander, R.; Pakrashi, A.; Srivastava, A. Managing future air quality in megacities: Emission inventory and scenario analysis for the Kolkata Metropolitan City, India. Atmos. Environ. 2020, 222, 117135. [Google Scholar] [CrossRef]
- Aldegunde, J.A.; Bolaños, E.Q.; Fernández-Sánchez, A.; Saba, M.; Caraballo, L. Environmental and Health Benefits Assessment of Reducing PM2.5 Concentrations in Urban Areas in Developing Countries: Case Study Cartagena de Indias. Environments 2023, 10, 42. [Google Scholar] [CrossRef]
- Aldegunde, J.A.; Sánchez, A.F.; Saba, M.; Bolaños, E.Q.; Palenque, J.Ú. Analysis of PM2.5 and meteorological variables using enhanced geospatial techniques in developing countries: A case study of Cartagena de Indias City (Colombia). Atmosphere 2022, 13, 506. [Google Scholar] [CrossRef]
- Karaca, F.; Alagha, O.; Ertürk, F. Statistical characterization of atmospheric PM10 and PM2.5 concentrations at a non-impacted suburban site of Istanbul, Turkey. Chemosphere 2005, 59, 1183–1190. [Google Scholar] [CrossRef]
- Datta, A.; Hassan, K.L.; Kundu, K. Rule-Based Investigation on Positive Change in Air Quality at Kolkata during Lockdown Period Due to COVID-19 Pandemic. In Proceedings of the Doctoral Symposium on Human Centered Computing, West Bengal, India, 23 February 2023; Springer Nature: Singapore, 2023; pp. 212–222. [Google Scholar]
- Chinnasamy, P.; Shah, Z.; Shahid, S. Impact of lockdown on air quality during COVID-19 pandemic: A case study of India. J. Indian Soc. Remote Sens. 2023, 51, 103–120. [Google Scholar] [CrossRef]
- Persis, J.; Amar, A.B. Predictive modeling and analysis of air quality–Visualizing before and during COVID-19 scenarios. J. Environ. Manag. 2023, 327, 116911. [Google Scholar] [CrossRef]
- Rubin, D.B. An overview of multiple imputation. In Proceedings of the Survey Research Methods Section of the American Statistical Association, New Orleans, LA, USA, 22–25 August 1988; Volume 79, p. 84. [Google Scholar]
- Lin, W.C.; Tsai, C.F.; Zhong, J.R. Deep learning for missing value imputation of continuous data and the effect of data discretization. Knowl.-Based Syst. 2022, 239, 108079. [Google Scholar] [CrossRef]
- Boursalie, O.; Samavi, R.; Doyle, T.E. Evaluation methodology for deep learning imputation models. Exp. Biol. Med. 2022, 247, 1972–1987. [Google Scholar] [CrossRef] [PubMed]
- Sosa Donoso, J.R.; Flores, M.; Naya, S.; Tarrío-Saavedra, J. Local Correlation Integral Approach for Anomaly Detection Using Functional Data. Mathematics 2023, 11, 815. [Google Scholar] [CrossRef]
- Sancho, J.; Pastor, J.J.; Martínez, J.; García, M.A. Evaluation of harmonic variability in electrical power systems through statistical control of quality and functional data analysis. Procedia Eng. 2013, 63, 295–302. [Google Scholar] [CrossRef]
- Sancho, J.; Martínez, J.; Pastor, J.J.; Taboada, J.; Piñeiro, J.I.; García-Nieto, P.J. New methodology to determine air quality in urban areas based on runs rules for functional data. Atmos. Environ. 2014, 83, 185–192. [Google Scholar] [CrossRef]
- Sancho, J.; Iglesias, C.; Piñeiro, J.; Martínez, J.; Pastor, J.J.; Araújo, M.; Taboada, J. Study of water quality in a spanish river based on statistical process control and functional data analysis. Math. Geosci. 2016, 48, 163–186. [Google Scholar] [CrossRef]
- Martínez, J.; Saavedra, Á.; García-Nieto, P.J.; Piñeiro, J.I.; Iglesias, C.; Taboada, J.; Sancho, J.; Pastor, J. Air quality parameters outliers detection using functional data analysis in the Langreo urban area (Northern Spain). Appl. Math. Comput. 2014, 241, 1–10. [Google Scholar] [CrossRef]
- Martínez Torres, J.; Pastor Pérez, J.; Sancho Val, J.; McNabola, A.; Martínez Comesaña, M.; Gallagher, J. A functional data analysis approach for the detection of air pollution episodes and outliers: A case study in Dublin, Ireland. Mathematics 2020, 8, 225. [Google Scholar] [CrossRef]
- Beevers, S.D.; Carslaw, D.C.; Dajnak, D.; Stewart, G.B.; Williams, M.L.; Fussell, J.C.; Kelly, F.J. Traffic management strategies for emissions reduction: Recent experience in London. Energy Emiss. Control Technol. 2016, 28, 27–39. [Google Scholar] [CrossRef]
- Dombeck, D.A.; Graziano, M.S.; Tank, D.W. Functional clustering of neurons in motor cortex determined by cellular resolution imaging in awake behaving mice. J. Neurosci. 2009, 29, 13751–13760. [Google Scholar] [CrossRef]
- Ordòñez, C.; Martìnez, J.; Saavedra, À.; Mourelle, A. Intercomparison exercise for gases emitted by a cement industry in Spain: A functional data approach. J. Air Waste Manag. Assoc. 2011, 61, 135–141. [Google Scholar] [CrossRef]
- Torres, J.M.; Nieto, P.G.; Alejano, L.; Reyes, A.N. Detection of outliers in gas emissions from urban areas using functional data analysis. J. Hazard. Mater. 2011, 186, 144–149. [Google Scholar] [CrossRef] [PubMed]
- Di Blasi, J.P.; Torres, J.M.; Nieto, P.G.; Fernández, J.A.; Muñiz, C.D.; Taboada, J. Analysis and detection of outliers in water quality parameters from different automated monitoring stations in the Miño river basin (NW Spain). Ecol. Eng. 2013, 60, 60–66. [Google Scholar] [CrossRef]
- Matías, J.M.; Ordóñez, C.; Taboada, J.; Rivas, T. Functional support vector machines and generalized linear models for glacier geomorphology analysis. Int. J. Comput. Math. 2009, 86, 275–285. [Google Scholar] [CrossRef]
- Martinez, W.G.; Weese, M.L.; Jones-Farmer, L.A. A one-class peeling method for multivariate outlier detection with applications in phase I SPC. Qual. Reliab. Eng. Int. 2020, 36, 1272–1295. [Google Scholar] [CrossRef]
- García-Nieto, P.J. Parametric study of selective removal of atmospheric aerosol by coagulation, condensation and gravitational settling. Int. J. Environ. Health Res. 2001, 11, 149–160. [Google Scholar] [CrossRef] [PubMed]
- Donders, A.R.; Van Der Heijden, G.J.; Stijnen, T.; Moons, K.G. A gentle introduction to imputation of missing values. J. Clin. Epidemiol. 2006, 59, 1087–1091. [Google Scholar] [CrossRef]
- Carslaw, D.C.; Ropkins, K. Openair—An R package for air quality data analysis. Environ. Model. Softw. 2012, 27, 52–61. [Google Scholar] [CrossRef]
- Piateski, G.; Frawley, W. Knowledge Discovery in Databases; MIT Press: Cambridge, MA, USA, 1991. [Google Scholar]
- Narasimhan, D.; Vanitha, M. Machine Learning Approach-based Big Data Imputation Methods for Outdoor Air Quality Forecasting. J. Sci. Ind. Res. 2023, 82, 338–347. [Google Scholar]
- Montgomery, D.C. Design and Analysis of Experiments; John Wiley & Sons: Hoboken, NJ, USA, 2017. [Google Scholar]
- Shewhart, W.A. Economic Control of Quality of Manufactured Product; Macmillan and Co Ltd.: London, UK, 1931. [Google Scholar]
- Chen, Y.K. An evolutionary economic-statistical design for VSI X control charts under non-normality. Int. J. Adv. Manuf. Technol. 2003, 22, 602–610. [Google Scholar] [CrossRef]
- Box, G.E.; Cox, D.R. An analysis of transformations. J. R. Stat. Soc. Ser. B Stat. Methodol. 1964, 26, 211–243. [Google Scholar] [CrossRef]
- Grant, E.; Leavenworth, R. Statistical Quality Control; McGraw-Hill: New York, NY, USA, 1998. [Google Scholar]
- Champ, C.W.; Woodall, W.H. Exact results for Shewhart control charts with supplementary runs rules. Technometrics 1987, 29, 393–399. [Google Scholar] [CrossRef]
- Zhang, M.H.; Lin, W.Y.; Klein, S.A.; Bacmeister, J.T.; Bony, S.; Cederwall, R.T.; Del Genio, A.D.; Hack, J.J.; Loeb, N.G.; Lohmann, U.; et al. Comparing clouds and their seasonal variations in 10 atmospheric general circulation models with satellite measurements. J. Geophys. Res. Atmos. 2005, 110, D15S02. [Google Scholar] [CrossRef]
- Western Electric Company. Statistical Quality Control Handbook; Western Electric Company: Roseville, GA, USA, 1956. [Google Scholar]
- Ramsay, J.O.; Silverman, B.W. Functional Data Analysis; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2014. [Google Scholar]
- Central Pollution Control Board Air Quality (2018) India. Available online: https://cpcb.nic.in/ (accessed on 20 March 2021).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Min | Q1 |
| 3.03 μg/ | 12.46 μg/ |
| Max | Q2 |
| 153.32 μg/3 | 23.91 |
| Mean | Q3 |
| 32.98 | 43.84 |
| Std Dev | Var |
| 27.75 | 770.06 |
| N | IQR |
| 8785 | 31.38 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahmad, M.; Cheng, W.; Zhao, X. An Outlier Detection Study of Ozone in Kolkata India by the Classical Statistics, Statistical Process Control and Functional Data Analysis. Sustainability 2023, 15, 12790. https://doi.org/10.3390/su151712790
Ahmad M, Cheng W, Zhao X. An Outlier Detection Study of Ozone in Kolkata India by the Classical Statistics, Statistical Process Control and Functional Data Analysis. Sustainability. 2023; 15(17):12790. https://doi.org/10.3390/su151712790
Chicago/Turabian StyleAhmad, Mohammad, Weihu Cheng, and Xu Zhao. 2023. "An Outlier Detection Study of Ozone in Kolkata India by the Classical Statistics, Statistical Process Control and Functional Data Analysis" Sustainability 15, no. 17: 12790. https://doi.org/10.3390/su151712790