

Enhancing Data Management Strategies with a Hybrid Layering Framework in Assessing Data Validation and High Availability Sustainability


Abstract
:1. Introduction
- -
- What are the challenges of developing a comprehensive framework that integrates data validation and high availability techniques within a data migration practice, ensuring data integrity and continuous accessibility?
- -
- How can a comprehensive framework be evaluated for the sustainability of data validation techniques that can detect and address data quality issues, ensuring data accuracy throughout the data migration?
- -
- How can the effectiveness of sustainable criteria metrics and methodologies be defined and established for evaluating the efficiency and effectiveness of different data migration techniques, thereby providing decision-makers with clear guidelines for evaluating migration options?
- The framework combines hybrid data migration approaches, layered approaches, data validation, and high availability strategies. The collaborative approach to stakeholder collaboration and communication within the framework of data mapping and transitions is essential for successful data migration and promotes effective communication between team members and stakeholders. Implementing the recommended data migration techniques ensures business continuity during migration, reduces data and service corruption risks, and improves productivity, efficiency, and availability.
- Further, the study defines recommendations for evaluating and validating the accuracy and completeness of migrated data. This guidance is crucial for organizations to ensure data reliability and correctness during migration.
- This research offers practical insights into the effectiveness of the data migration framework by providing a real-world case study of converting proprietary databases to open-source ones. This empirical demonstration lends credibility to the framework for hybrid layering.
- The study assists organizations in adapting to new database system technologies when streamlining technological change and business expansion, emphasizing the significance of understanding and implementing data migration techniques to safeguard data migration strategies and sustain technological agility.
2. Theoretical Background
2.1. Comparison of Existing Data Migration Techniques and Hybrid Framework
2.2. Novel Criteria Metrics of Effectiveness Evaluation in Data Migration Sustainability
3. Research Model and Methodology
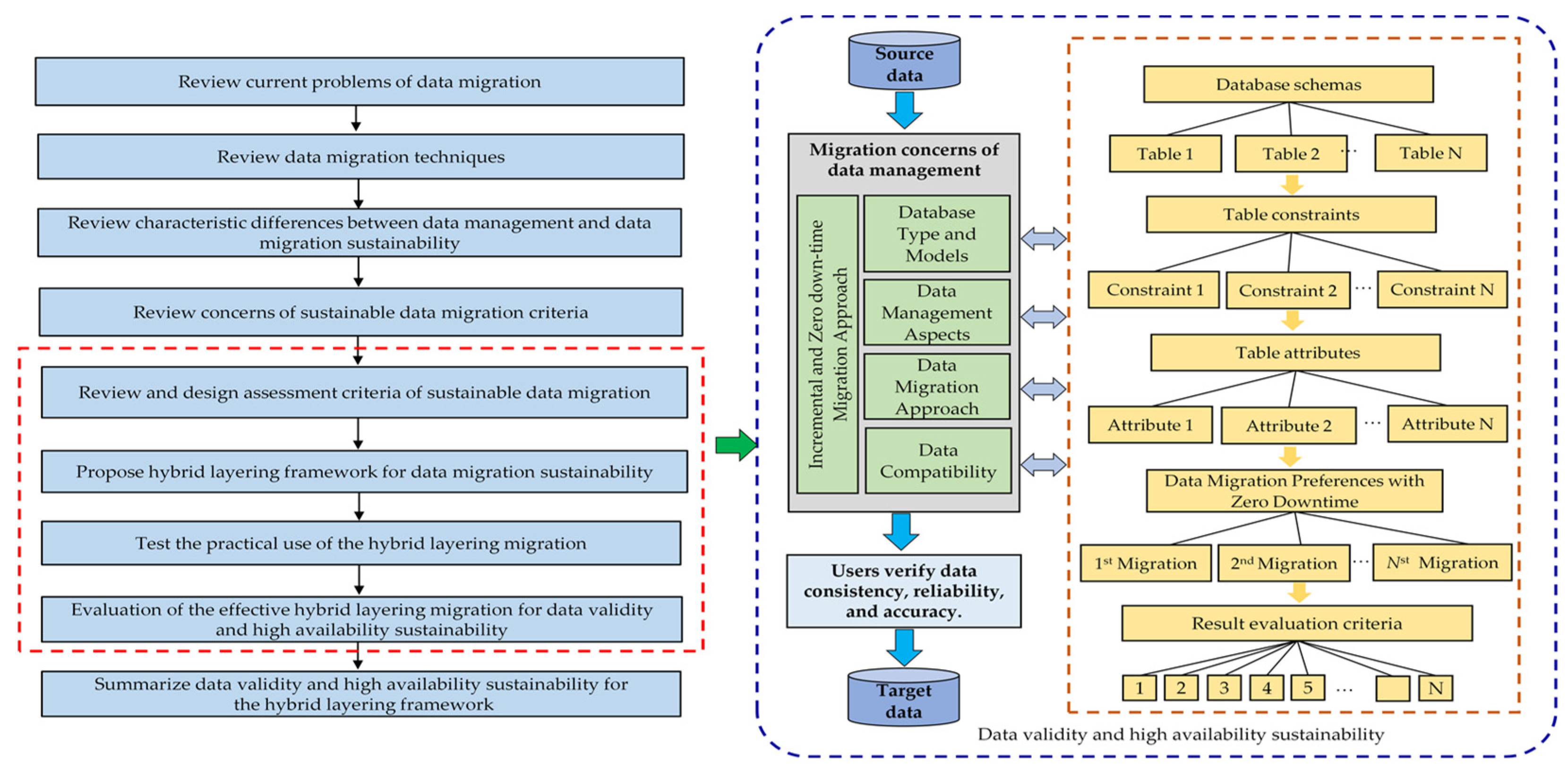
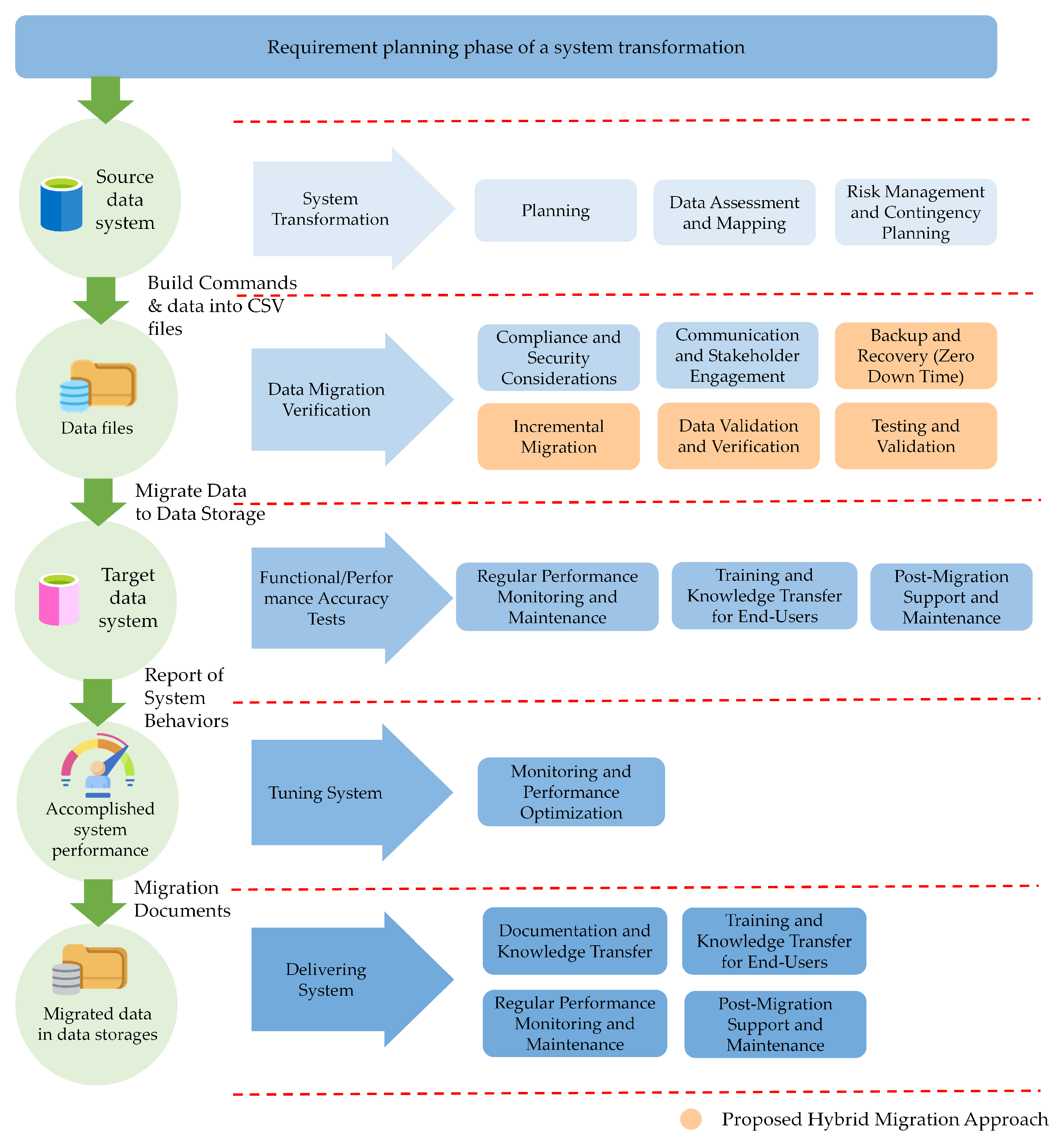
3.1. Methodological Development of Hybrid-Layering Migration Framework

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Framework Phase | Efficient Practice Activity | Description |
|---|---|---|
| System Transformation | Thorough Planning | Develop a comprehensive migration plan, including analysis, objectives, timelines, and milestones. |
| Data Assessment and Mapping | Assess the source data, map it to the target data, and ensure compatibility and integrity. | |
| Expertise and Collaboration | Engage experienced professionals and collaborate closely with the migration team for comprehensive understanding. | |
| Risk Management and Contingency Planning | Identify potential risks and develop contingency plans to mitigate them during the migration process. | |
| System Transformation Data Migration Verification Functional/Performance Accuracy Tests | Compliance and Security Considerations | Ensure compliance with relevant data regulations and implement appropriate security measures in the new data. |
| System Transformation Functional/Performance Accuracy Tests Delivering System | Communication and Stakeholder Engagement | Maintain open communication with stakeholders and involve them throughout the migration process. |
| Data Migration Verification Functional/Performance Accuracy Tests | Testing and Validation | To ensure accuracy, completeness, and integrity, perform extensive testing and validation of the migrated data. |
| System Transformation Data Migration Verification Functional/Performance Accuracy Tests | Back-up and Recovery | Implement robust back-up and recovery mechanisms to safeguard the data during the migration process. |
| Data Migration Verification Functional/Performance Accuracy Tests | Incremental Migration | Consider migrating data into smaller batches or modules to facilitate monitoring, validation, and troubleshooting. |
| Data Validation and Verification | Validate the migrated data’s accuracy, completeness, and integrity through various verification techniques. | |
| Tuning System | Monitoring and Performance Optimization | Continuously monitor the migration process and optimize the performance of the target data. |
| Delivering System | Documentation and Knowledge Transfer | Maintain thorough documentation to aid future reference and knowledge transfer to other team members. |
| Post-Migration Support and Maintenance | Provide support and maintenance after migration to address any post-migration issues or performance optimization. | |
| Training and Knowledge Transfer for End-Users | Conduct training sessions and knowledge transfer activities to ensure end-users are familiar with the new data. | |
| Regular Performance Monitoring and Maintenance Reviews | Regularly monitor the performance of the target data and conduct maintenance reviews to optimize functionality. |
3.2. Evaluation Criteria Metrics and Formula of Data Validation Sustainability
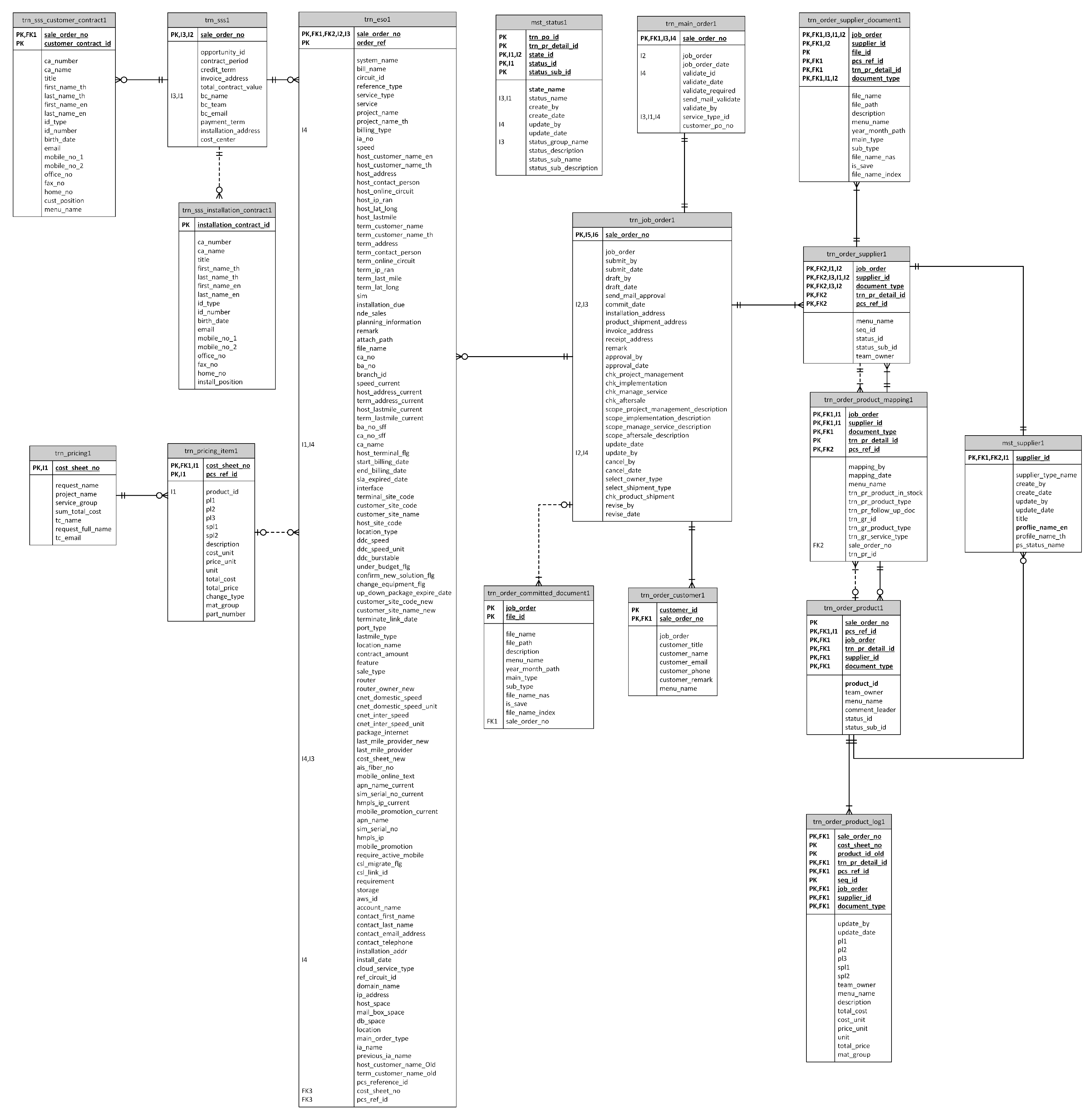
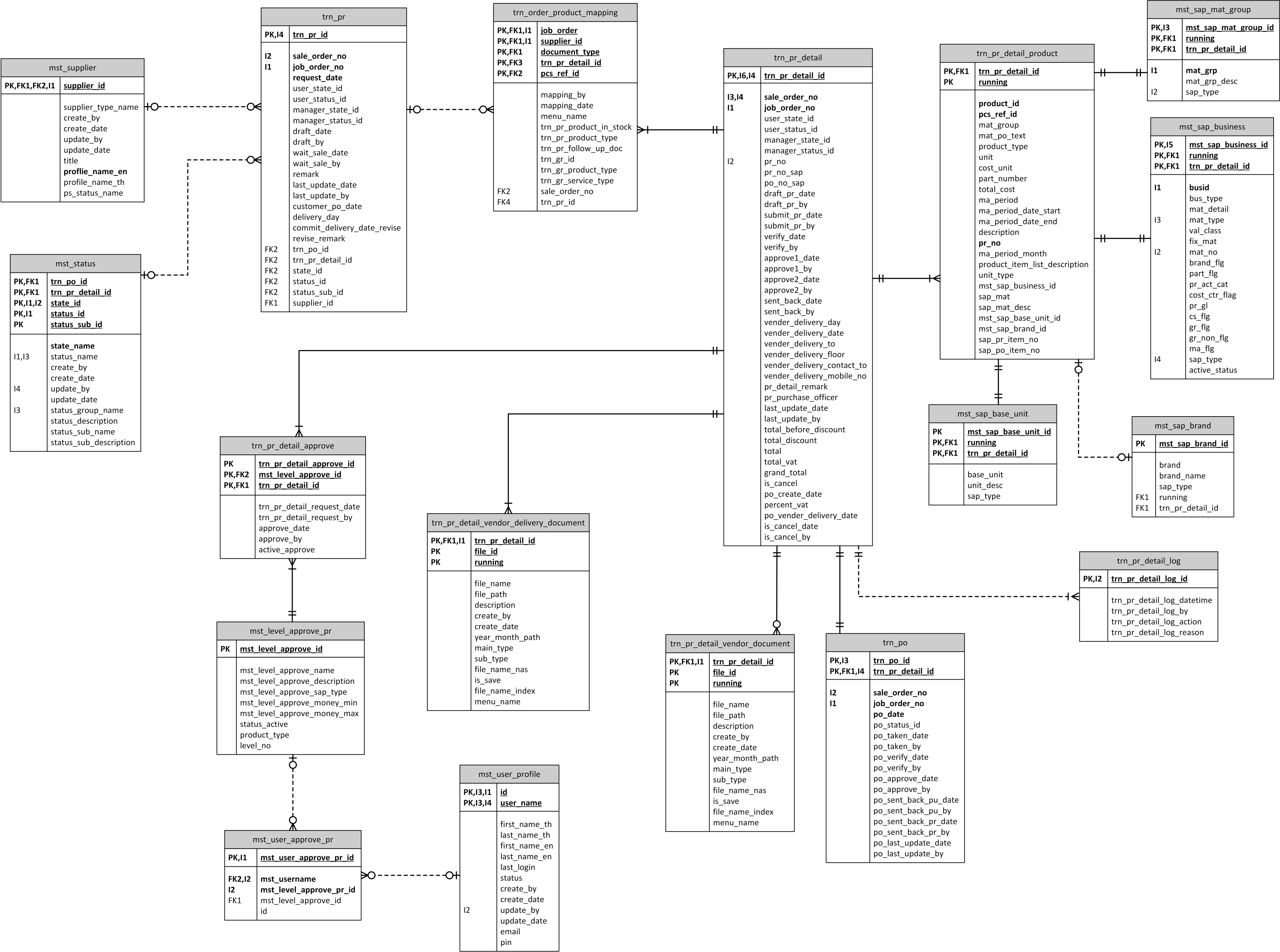
3.3. A Real-World Case Study to Evaluate the Hybrid Layering Framework
3.4. A Practice Implementation for the Sustainability of the Hybrid Layering Framework
3.5. Data Collection
3.6. Data Analysis and Results
4. Discussion
4.1. Data Migration’s Impact on Efficient Business and Technology
4.2. Hybrid Layering Data Migration’s Efficient Techniques
4.3. Successful Data Migration of Data Validity and High Availability Sustainability
4.4. The Hybrid Layering Framework Applying in the Case of Non-Relational Data
5. Conclusions
5.1. Theoretical Contributions
5.2. Practical Implications
5.3. Limitations and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wongvilaisakul, W.; Netinant, P.; Rukhiran, M. Dynamic multi-criteria decision making of graduate admission recommender system: AHP and fuzzy AHP approaches. Sustainability 2023, 15, 9758. [Google Scholar] [CrossRef]
- Sánchez-García, E.; Marco-Lajara, B.; Seva-Larrosa, P.; Martínez Falcó, J. Driving innovation by managing entrepreneurial orientation, cooperation and learning for the sustainability of companies in the energy sector. Sustainability 2022, 14, 16978. [Google Scholar] [CrossRef]
- Rukhiran, M.; Netinant, P. A practical model from multidimensional layering: Personal finance information framework using mobile software interface operations. J. Inf. Commun. Technol. 2020, 19, 321–349. [Google Scholar] [CrossRef]
- Xiong, F.; Xie, M.; Zhao, L.; Li, C.; Fan, X. Recognition and evaluation of data as intangible assets. SAGE Open 2022, 12, 21582440221094600. [Google Scholar] [CrossRef]
- Fleckenstein, M.; Fellows, L. Overview of data management frameworks. In Modern Data Strategy; Springer International Publishing: Cham, Switzerland, 2018; pp. 55–59. [Google Scholar] [CrossRef]
- Yang, Z. Replacing Oracle DBMS: A Feasibility Study. Master’s Thesis, Tampere University, Tampere, Finland, November 2020. [Google Scholar]
- Antanasijević, D.; Lolić, T.; Stefanović, D.; Ristić, S. The challenge of an extraction-transformation-loading tool selection. In Proceedings of the XIV International SAUM Conference on Systems, Automatic Control and Measurements, Niš, Serbia, 14–16 November 2018. [Google Scholar]
- Madhikerrni, M.; Främling., K. Data discovery method for extract-transform-load. In Proceedings of the 10th International Conference on Mechanical and Intelligent Manufacturing Technologies, Cape Town, South Africa, 15–17 February 2019. [Google Scholar] [CrossRef]
- Opara-Martins, J.; Sahandi, R.; Tian, F. Critical analysis of vendor lock-in and its impact on cloud computing migration: A business perspective. J. Cloud Comput. 2016, 5, 4. [Google Scholar] [CrossRef]
- Cao, R.; Iansiti, M. Digital transformation, data architecture, and legacy systems. J. Digit. Econ. 2022, 1, 1–19. [Google Scholar] [CrossRef]
- Cavalcanti, D.R.; Oliveira, T.; Santini, F.O. Drivers of digital transformation adoption: A weight and meta-analysis. Heliyon 2022, 8, e08911. [Google Scholar] [CrossRef] [PubMed]
- Banimfreg, B.H. A comprehensive review and conceptual framework for cloud computing adoption in bioinformatics. Healthc. Anal. 2023, 3, 100190. [Google Scholar] [CrossRef]
- Chawla, N.; Kumar, D.; Sharma, D. Improving cost for data migration in cloud computing using genetic algorithm. Int. J. Softw. Innov. 2020, 8, 69–81. [Google Scholar] [CrossRef]
- Ansar, M.; Ashraf, M.W.; Fatima, M. Data migration in cloud: A systematic review. Am. Sci. Res. J. Eng. Technol. Sci. 2018, 48, 73–89. [Google Scholar]
- Azeroual, O.; Jha, M. Without data quality, there is no data migration. Big Data Cogn. Comput. 2021, 5, 24. [Google Scholar] [CrossRef]
- Jaumard, B.; Pouya, H. Migration plan with minimum overall migration time or cost. J. Opt. Commun. Netw. 2018, 10, 1–13. [Google Scholar] [CrossRef]
- Yang, Y.; Mao, B.; Jiang, H.; Yang, Y.; Luo, H.; Wu, S. SnapMig: Accelerating VM live storage migration by leveraging the existing VM snapshots in the cloud. IEEE Trans. Parallel Distrib. Syst. 2018, 29, 1416–1427. [Google Scholar] [CrossRef]
- Tošić, A.; Vičič, J.; Burnard, M.; Mrissa, M. A blockchain protocol for real-time application migration on the edge. Sensors 2023, 23, 4448. [Google Scholar] [CrossRef] [PubMed]
- Bouhamed, M.M.; Chaoui, A.; Nouara, R.; Diaz, G.; Dembri, A. Reducing the number of migrated instances during business process change: A graph rewriting approach. J. King Saud Univ. Comput. Inf. 2022, 34, 7720–7734. [Google Scholar] [CrossRef]
- Eyada, M.M.; Saber, W.; Genidy, M.M.; Amer, F. Performance evaluation of IoT data management using MongoDB versus MySQL databases in different cloud environments. IEEE Access 2020, 8, 110656–110668. [Google Scholar] [CrossRef]
- Ellison, M.; Calinescu, R.; Paige, R.F. Evaluating cloud database migration options using workload models. J. Cloud Comput. 2018, 7, 6. [Google Scholar] [CrossRef]
- Luca, M.; Barlacchi, G.; Oliver, N.; Lepri, B. Leveraging mobile phone data for migration flows. In Data Science for Migration and Mobility Studies, 1st ed.; Korkmaz, E.E., Salah, A.A., Eds.; Oxford University Press: Oxford, UK, 2021; pp. 1–14. [Google Scholar] [CrossRef]
- Sibgatullina, A.I.; Yakupov, A.S. Development a data validation module to satisfy the retention policy metric. Russ. Digit. Libr. J. 2022, 25, 159–178. [Google Scholar] [CrossRef]
- Prasanna, C.; Subha, R.; Sreemathy, J.; Aravindh Ramanathan, P.; Jainaveen, M. Data validation and migration-a theoretical perspective. In Proceedings of the 7th International Conference on Advanced Computing and Communication Systems, Coimbatore, India, 19–20 March 2021. [Google Scholar] [CrossRef]
- Yang, C.; Zhao, F.; Tao, X.; Wang, Y. Publicly verifiable outsourced data migration scheme supporting efficient integrity checking. J. Netw. Comput. Appl. 2021, 192, 103184. [Google Scholar] [CrossRef]
- Latha, M.; Kumar, P. Analysis on data migration strategies in heterogeneous databases. Int. J. Adv. Res. Sci. Commun. Technol. 2021, 6, 210–214. [Google Scholar] [CrossRef]
- McGill, M.M.; Sexton, S.; Peterfreund, A.; Praetzellis, M. Efficient, effective, and ethical education research data management and sustainability. In Proceedings of the 52nd ACM Technical Symposium on Computer Science Education, Virtual Event, USA, 13–20 March 2021. [Google Scholar] [CrossRef]
- Bento, P.; Neto, M.; Corte-Real, N. How data governance frameworks can leverage data-driven decision making: A sustainable approach for data governance in organizations. In Proceedings of the 2022 17th Iberian Conference on Information Systems and Technologies, Madrid, Spain, 22–25 June 2022. [Google Scholar] [CrossRef]
- Dehury, C.K.; Srirama, S.N.; Chhetri, T.R. CCoDaMiC: A framework for coherent coordination of data migration and computation platforms. Future Gener. Comput. Syst. 2020, 109, 1–16. [Google Scholar] [CrossRef]
- Transition from Legacy Databases to a Modern Data Architecture. Available online: https://www.devprojournal.com/technology-trends/open-source/transition-from-legacy-databases-to-a-modern-data-architecture (accessed on 13 July 2023).
- Hussein, A.A. Data migration need, strategy, challenges, methodology, categories, risks, uses with cloud computing, and improvements in its using with cloud using suggested proposed model (DMig 1). J. Inf. Secur. 2021, 12, 17–103. [Google Scholar] [CrossRef]
- Mackita, M.; Shin, S.; Choe, T. ERMOCTAVE: A risk management framework for IT systems which adopt cloud computing. Future Internet 2019, 11, 195. [Google Scholar] [CrossRef]
- Trisnawaty, N.W.; Hidayanto, A.N.; Ruldeviyani, Y. Database and application migration in the financial services industry sector in the acquisition environment and environmental science. In Proceedings of the 9th Engineering International Conference, Semarang, Indonesia, 24 September 2020. [Google Scholar] [CrossRef]
- Barrios, P.; Loison, F.; Danjou, C.; Eynard, B. PLM Migration in the era of big data and IoT: Analysis of information system and data topology. In Proceedings of the 17th IFIP International Conference on Product Lifecycle Management, Rapperswil, Switzerland, 5–8 July 2020. [Google Scholar] [CrossRef]
- Nyeint, K.A.; Soe, K.M. Database migration based on Trickle migrations approach. Natl. J. Parallel Soft Comput. 2019, 1, 81–86. [Google Scholar]
- Mateus, B.G.; Martinez, M.; Kolski, C. Learning migration models for supporting incremental language migrations of software applications. Inf. Softw. Technol. 2023, 153, 107082. [Google Scholar] [CrossRef]
- Types of Data Migration. Available online: https://www.codemotion.com/magazine/devops/cloud/migrating-data-to-the-cloud-a-practical-guide (accessed on 29 July 2023).
- Gundall, M.; Stegmann, J.; Reichardt, M.; Schotten, H.D. Downtime Optimized Live Migration of Industrial Real-Time Control Services. In Proceedings of the IEEE 31st International Symposium on Industrial Electronics (ISIE), Anchorage, AK, USA, 1–3 June 2022. [Google Scholar] [CrossRef]
- Fernandex, J.B. Database Schema Migration in Highly Available Services. Master’s Thesis, KTH Royal Institute of Technology, Stockholm, Sweden, 20 January 2021. [Google Scholar]
- Rukhiran, M.; Buaroong, S.; Netinant, P. Software development for educational information services using multilayering semantics adaptation. Int. J. Serv. Sci. Manag. Eng. Technol. 2022, 13, 1–27. [Google Scholar] [CrossRef]
- Romhányi, Á.; Vámossy, Z. Benefits of Layered Software Architecture in Machine Learning Applications. In Proceedings of the International Conference on Image Processing and Vision Engineering, Online, 28–30 April 2021; SCITEPRESS—Science and Technology Publications: Setubal, Portugal, 2021. [Google Scholar] [CrossRef]
- Zhuxian, W.; Xingmin, G.; Peng, F. The application of layering technology in computer software development. In Proceedings of the 2017 International Conference on Robots & Intelligent System, Huaian, China, 15–16 October 2017. [Google Scholar] [CrossRef]
- Li, X. Application effect of layering technology in computer software development. J. Comput. Sci. Res. 2018, 1, 1. [Google Scholar] [CrossRef]
- Ramli, S.; Redzuan, I.; Mamood, I.H.; Mohd Zainudin, N.; Hasbullah, N.A.; Wook, M. National sport institute case: Automated data migration using Talend open studio with ‘Trickle approach’. In Advances in Visual Informatics; IVIC 2021, Lecture Notes in Computer Science; Zaman, H.B., Smeaton, A.F., Shih, T.K., Velastin, S., Terutoshi, T., Jørgensen, B.N., Aris, H., Ibrahim, N., Eds.; Springer: Cham, Switzerland, 2021; Volume 13051, pp. 214–223. [Google Scholar] [CrossRef]
- Singh, A. Data Migration from Relational Database to MongoDB Using XAMPP and NoSQL. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3372802 (accessed on 13 July 2023).
- Ceresnak, R.; Matiasko, K.; Dudas, A. Influencing migration processes by real-time data. In Proceedings of the 28th Conference of Open Innovations Association, Moscow, Russia, 27–29 January 2021. [Google Scholar] [CrossRef]
- Blagaić, S.; Babac, M.B. Application for data migration with complete data integrity. Int. J. Syst. Syst. Eng. 2022, 12, 405–432. [Google Scholar] [CrossRef]
- Yang, C.; Tao, X.; Wang, S.; Zhao, F. Data integrity checking supporting reliable data migration in cloud storage. In Proceedings of the 15th International Conference on Wireless Algorithms, Systems, and Applications, Qingdao, China, 13–15 September 2020. [Google Scholar] [CrossRef]
- Rinken, S.; Ortega, J.L. Leveraging the web for migration studies: Data sources and data extraction. In Migration Research in a Digitized World, IMISCOE Research Series; Pötzschke, S., Rinken, S., Eds.; Springer: Cham, Switzerland, 2022; pp. 129–148. [Google Scholar] [CrossRef]
- Petrasch, R.J.; Petrasch, R.P. Data integration and interoperability: Towards a model-driven and pattern-oriented approach. Modelling 2022, 3, 105–126. [Google Scholar] [CrossRef]
- Ramzan, S.; Bajwa, I.S.; Ramzan, B.; Anwar, W. Intelligent data engineering for migration to NoSQL based secure environments. IEEE Access 2019, 7, 69042–69057. [Google Scholar] [CrossRef]
- Wang, X. Design and implementation strategy of data migration system based on Hadoop platform. J. Phys. 2021, 2010, 012082. [Google Scholar] [CrossRef]
- Poudel, M.; Sarode, R.P.; Watanobe, Y.; Mozgovoy, M.; Bhalla, S. Processing analytical queries over Polystore system for a large astronomy data repository. Appl. Sci. 2022, 12, 2663. [Google Scholar] [CrossRef]
- Rukhiran, M.; Wong-In, S.; Netinant, P. IoT-Based biometric recognition systems in education for identity verification services: Quality assessment approach. IEEE Access 2023, 11, 22767–22787. [Google Scholar] [CrossRef]
- Cheng, Z.; Wang, L.; Cheng, Y.; Chen, G. Automated and intelligent data migration strategy in high energy physical storage systems. J. Phys. 2020, 1525, 012042. [Google Scholar] [CrossRef]
- Martinho, N.; Almeida, J.-P.d.; Simões, N.E.; Sá-Marques, A. UrbanWater: Integrating EPANET 2 in a PostgreSQL/PostGIS-based geospatial database management system. ISPRS Int. J. Geo-Inf. 2020, 9, 613. [Google Scholar] [CrossRef]
- Chang, Q.; Nazir, S.; Li, X. Decision-making and computational modeling of big data for sustaining influential usage. Sci. Program. 2022, 2022, 2099710. [Google Scholar] [CrossRef]
- Ibrahim, M.; Imran, M.; Jamil, F.; Lee, Y.; Kim, D. EAMA: Efficient adaptive migration algorithm for cloud data centers (CDCs). Symmetry 2021, 13, 690. [Google Scholar] [CrossRef]
- Kaur, A.; Kumar, S.; Gupta, D.; Hamid, Y.; Hamdi, M.; Ksibi, A.; Elmannai, H.; Saini, S. Algorithmic approach to virtual machine migration in cloud computing with updated SESA algorithm. Sensors 2023, 23, 6117. [Google Scholar] [CrossRef] [PubMed]
- Deshmukh, O. Data Migration Techniques across DBMS by Using Metadata. Int. J. Res. Appl. Sci. Eng. Technol. 2022, 10, 457–463. [Google Scholar] [CrossRef]
- Taherdoost, H. Change Management. In E-Business Essentials; Springer Nature: Cham, Switzerland, 2023; pp. 319–349. [Google Scholar]
- Singh, G.; Singh, P.; Hedabou, M.; Masud, M.; Alshamrani, S.S. A Predictive Checkpoint Technique for Iterative Phase of Container Migration. Sustainability 2022, 14, 6538. [Google Scholar] [CrossRef]
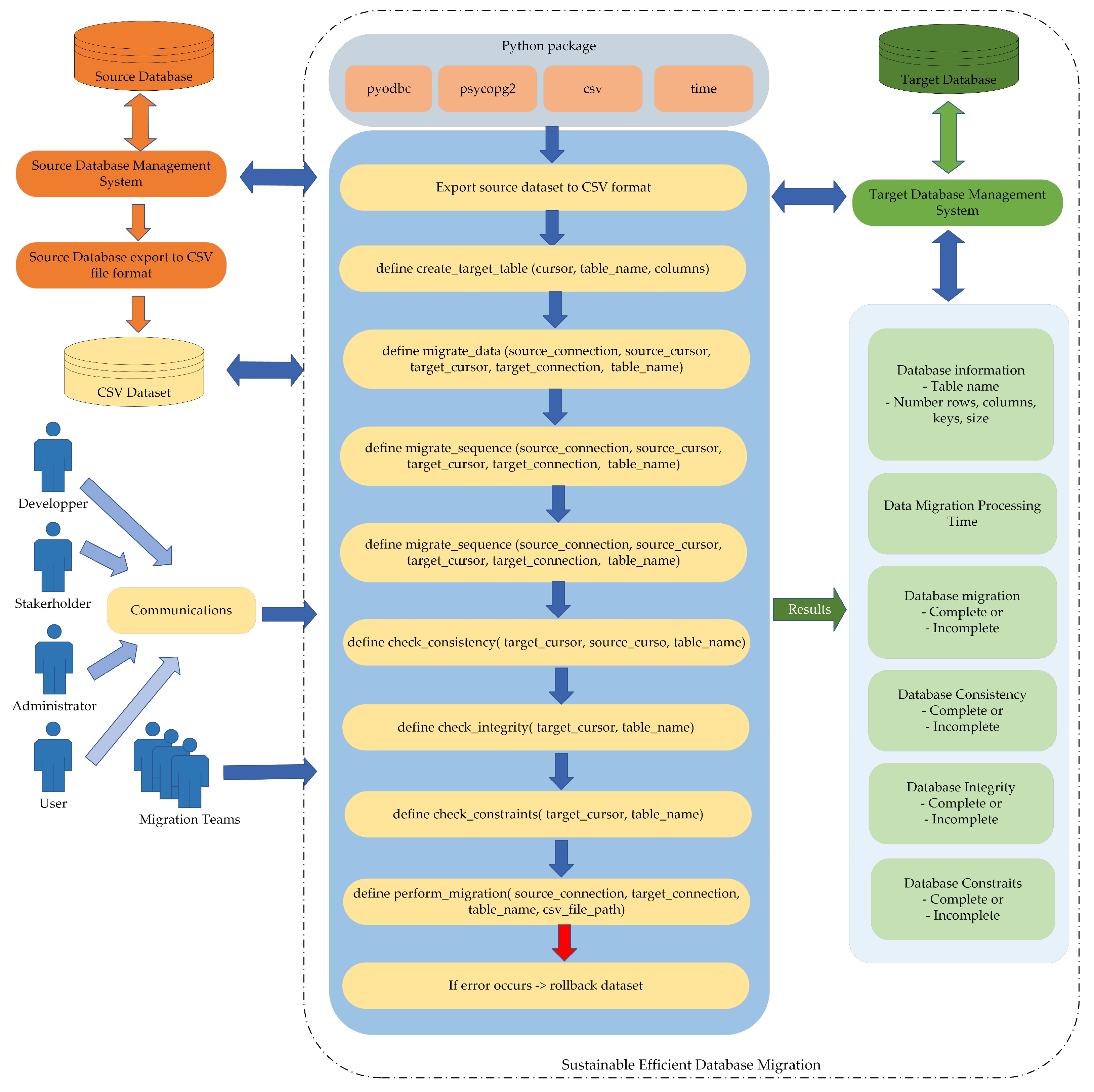

| Methodology Steps | Big Bang Data Migration | Trickle Data Migration | Zero-Downtime Data Migration | Proposed Hybrid Data Migration Framework |
|---|---|---|---|---|
| Research and Analysis | Conduct an in-depth, comprehensive analysis of the current data environment and project specifications. | Assess the part data characteristics and project objectives to determine and meet suitability gradually. | Evaluate the data infrastructure and project goals to ascertain feasibility without any failure. | Conduct a thorough analysis of the current data environment for the entire organization, considering factors such as data complexity, volume, and business continuity requirements. Evaluate the need for continuous system availability during migration and the feasibility of incremental data transfers to reduce downtime. |
| Selection of Migration Technique | Choose big bang migration for low-complexity, low-volume, and short-downtime-tolerance projects. | Optimize trickle migration for projects with moderate complexity and data volume, allowing gradual data transfer to minimize downtime. | Select zero-downtime migration for projects requiring continuous system availability with complex data and a high tolerance for zero downtime. | Utilize a combination of trickle and zero-downtime migration strategies to strike a balance between gradual data transfer and continuous system availability. Choose this strategy for projects with complex data, a high tolerance for zero downtime, and the requirement of seamless data integration without protracted interruptions in mission-critical operations. |
| Planning and Preparation | Develop a detailed migration plan outlining tasks, timelines, and resource allocation. | Plan and prepare for incremental data transfers, ensuring coordination and data integrity across phases. | Create a comprehensive migration plan, focusing on replication and synchronization to maintain system availability during the migration. | Develop a comprehensive migration plan incorporating the incremental data transfer method of trickle migration and the continuous system availability strategy of zero-downtime migration. Assign resources and establish deadlines to ensure efficient execution. Prepare a comprehensive back-up and recovery plan to protect vital data during migration. |
| Data Profiling and Preprocessing | The data are profiled to identify potential issues and are preprocessed to ensure compatibility with the target data management system. | Conduct data profiling to understand data complexities and incremental preprocessing of data for seamless integration. | Conduct data profiling to ensure data compatibility and fault-tolerant preprocessing of data for synchronization with minimal disruption. | Conduct exhaustive data profiling to comprehend the complexities and nuances of data during the trickle and zero-downtime migration phases. The data must be preprocessed to ensure compatibility with the target data system and maintain data consistency during the gradual data transfer, thereby ensuring rollback capability for data recovery. |
| Methodology Steps | Big Bang Data Migration | Trickle Data Migration | Zero-Downtime Data Migration | Proposed Hybrid Data Migration Framework |
|---|---|---|---|---|
| Testing and Validation | After data migration, establish a dedicated testing environment to verify data accuracy and consistency. | Perform rigorous testing at each migration phase to validate data integrity and identify inconsistencies. | Incrementally implement thorough testing, simulating real-time scenarios to ensure data consistency and system functionality without impacting users. | Establish a dedicated testing environment to verify the efficacy of the combined migration strategies. Perform rigorous testing at each successive phase, ensuring data integrity, consistency, and system functionality without interfering with ongoing operations. Conduct real-time simulations to evaluate system performance and ensure availability throughout the migration. |
| Execution of Migration | Transferring the entire dataset to the target data in a single migration operation. | Migrate data incrementally, moving subsets of data in controlled stages while ensuring data consistency. | Implement real-time data replication and synchronization mechanisms to achieve continuous availability and data consistency during migration. | To incrementally transfer subsets of data, execute the migration in controlled stages utilizing the trickle method. Implement real-time data replication and synchronization mechanisms, similar to zero-downtime migration, to ensure continuous data availability throughout the entire migration process. Maintain data accuracy and system stability through vigilant migration monitoring and the prompt resolution of any problems. |
| Post-Migration Evaluation | Evaluate the success of the migration process, addressing any post-migration issues that may arise. | Analyze the effectiveness of the migration, considering data consistency and user feedback to refine the process. | Assess the migration’s performance, address post-migration issues, and gather stakeholder feedback to optimize the technique. | Consider data consistency, system performance, and user feedback in evaluating the success of the combined migration strategy. Evaluate the efficacy of the trickle and zero-downtime techniques in achieving the project’s goals. To refine the methodology for future migrations and optimize data management strategies, migration result is necessary to gather input from stakeholders and end-users. |
| Documentation and Knowledge Transfer | Document the entire migration process, challenges faced, and lessons learned for future reference. | Create comprehensive documentation of the migration steps and knowledge transfer sessions for IT teams and end-users. | Document the migration methodology, share knowledge and insights gained, and provide training to ensure a seamless transition to the new system. | For future reference, document the entire migration process, including the combined trickle and zero-downtime techniques, obstacles encountered, and lessons learned. Create detailed documentation outlining the methodology and knowledge transfer sessions for IT teams and end-users to ensure a smooth transition to the new data environment. |
| Criteria | Description |
|---|---|
| Compatibility [19,46] | Compatibility refers to the ability to successfully transfer data and functionality from one data management system to another without losing functionality, compromising data integrity, or requiring significant changes to the application code. This factor pertains to the assurance that the target data management system has the necessary capabilities to manage data competently and meet application requirements. |
| Transformation [47] | Transformation involves modifying or converting data, schema, or other components from the source data to a format suitable for the target data. Adjustments are made to ensure compatibility, data integrity, and optimal performance in the new data environment. |
| Integrity [48] | The integrity of data migration refers to the maintenance of data precision, consistency, and dependability throughout the migration process, including constraints, triggers, and referential integrity between source and target data. It ensures that the data is migrated from the source to the target data without loss or corruption. |
| Performance Optimization [19,21,49] | Performance optimization in data migration is the process of improving the responsiveness and efficiency of a data management system during and after the migration process. It requires identifying and implementing techniques to improve query execution, data retrieval, and overall system performance in the new data environment. |
| Licensing and Cost [21,49] | Licensing and cost considerations in data migration involve evaluating and managing the financial facets of migrating from one data management system to another. Understanding the licensing models, costs, and potential financial implications of the source and target data management systems is required. |
| Accuracy [21,50,51] | Accuracy refers to the exactness and accuracy of the data being transferred from the source data to the target data. It involves ensuring that the migrated data represents the original data accurately and maintains its integrity throughout the migration process. |
| Reliability [48,49] | In data migration, reliability refers to the dependability and uniformity of the migration process and the resulting data management system. It entails ensuring that the migration is carried out successfully, with minimal errors or interruptions, and that the migrated data functions dependably regarding data integrity, availability, and performance. |
| Transparency and Transformation Processing [15,51,52] | Transparency in data migration refers to the visibility and clarity of the migration procedure. In contrast, transformation processing refers to the data and structure modifications and conversions performed during migration. Transparency provides clear and comprehensive visibility into the migration process, enabling stakeholders to comprehend and track the migration’s progress, actions, and potential consequences. |
| Category | Evaluation Criteria | Formula | Description |
|---|---|---|---|
| Compatibility | Data Consistency Rate (DCR) | (Number of Consistent Records/Total Number of Records) × 100 | Measures the level of consistency between the migrated data and the original source data. |
| Data Integrity Rate (DIS) | (Total Number of Correct Values/Total Number of Migrated Values) × 100 | Assesses the accuracy and completeness of the migrated data to ensure data integrity is maintained. | |
| Data Accuracy Index (DAI) | (1 − (|Total Number of Inaccurate Values|/Total Number of Migrated Values)) × 100 | Provides an index to measure the overall accuracy of the migrated data. | |
| Error Rate (ER) | (Number of Error Records/Total Number of Records) × 100 | Indicates the percentage of data records that contain errors or discrepancies in the migrated data. | |
| Transformation | Data Completeness Percentage (DCP) | (Number of Complete Records/Total Number of Records) × 100 | Measures the degree to which the migrated data are complete and reflects the entirety of the source data. |
| Data Matching Ratio (DMR) | (Number of Matched Records/ Total Number of Records) × 100 | Evaluates the accuracy of data matching during the migration process, ensuring correct record associations. | |
| Integrity | Data Consistency Index (DCI) | (1 − (|Total Number of Inconsistent Values|/Total Number of Migrated Values)) × 100 | Provides an index that reflects the consistency of data values between the source and target data. |
| Performance Optimization | Data Accuracy Percentage (DAP) | (Number of Correct Values/Total Number of Migrated Values) × 100 | Represents the overall accuracy of the migrated data. |
| Effectiveness and Accuracy Evaluation | Precision | (True Positives)/(True Positives + False Positives) | Measures the accuracy of the positive predictions made during the migration. |
| Recall | (True Positives)/(True Positives + False Negatives) | Measures the percentage of true positive matches found. |
| Support Source | Support Target | Solutions | Approach | Results |
|---|---|---|---|---|
| Data–Entity relationship | Data–Entity relationship | SQL server integration services (SSIS) | Incremental, SQL scripts, built-in features. | The system functions cannot be validated and verified despite the successful migration. The system was inoperable. |
| Replication | Incremental, SQL Scripts, PostgreSQL foreign data wrapper (FDW) to read data from SQL server tables and write it into PostgreSQL. | The system functions cannot be validated and verified despite the successful migration. The system was inoperable. | ||
| Incremental migration—Manual data pumping | Incremental SQL Scripts migrate data in smaller batches or based on manual-specific criteria. | The system functions cannot be validated and verified despite the successful migration. The system was inoperable. |
| Department | Data Source | Data Target | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Trickle Migration | Zero Downtime Migration | Proposed Hybrid Layering Framework | ||||||||
| Tables | Records | Tables | Records | Downtime | Tables | Records | Tables | Records | Downtime | |
| Public Relation (PR) | 19 | 18,940 | 19 | 18,940 | 3 | Failure occurs | - | 19 | 18,940 | 0 |
| Purchasing Order (PO) | 13 | 17,810 | 13 | 17,810 | 2 | Failure occurs | - | 13 | 17,810 | 0 |
| Sale Order (SO) | 24 | 69,030 | 24 | 69,030 | 5 | Failure occurs | - | 24 | 69,030 | 0 |
| Human Resource (HR) | 30 | 49,200 | 30 | 49,200 | 4 | Failure occurs | - | 30 | 49,200 | 0 |
| Good Receipt (GR) | 29 | 16,700 | 29 | 16,700 | 4 | Failure occurs | - | 29 | 16,700 | 0 |
| Delivery Notes (DN) | 23 | 12,190 | 23 | 12,190 | 3 | Failure occurs | - | 23 | 12,190 | 0 |
| Job Order (JO) | 26 | 69,030 | 26 | 69,030 | 4 | Failure occurs | - | 26 | 69,030 | 0 |
| Hand Over (HO) | 24 | 2370 | 24 | 2370 | 4 | Failure occurs | - | 24 | 2370 | 0 |
| Warehouse Stock (WS) | 23 | 28,760 | 23 | 28,760 | 3 | Failure occurs | - | 23 | 28,760 | 0 |
| Others | 11 | 16,520 | 11 | 16,520 | 0 | 11 | 16,520 | 11 | 16,520 | 0 |
| Total | 222 | 300,550 | 222 | 300,550 | 29 | 11 | 16,520 | 222 | 300,550 | 0 |
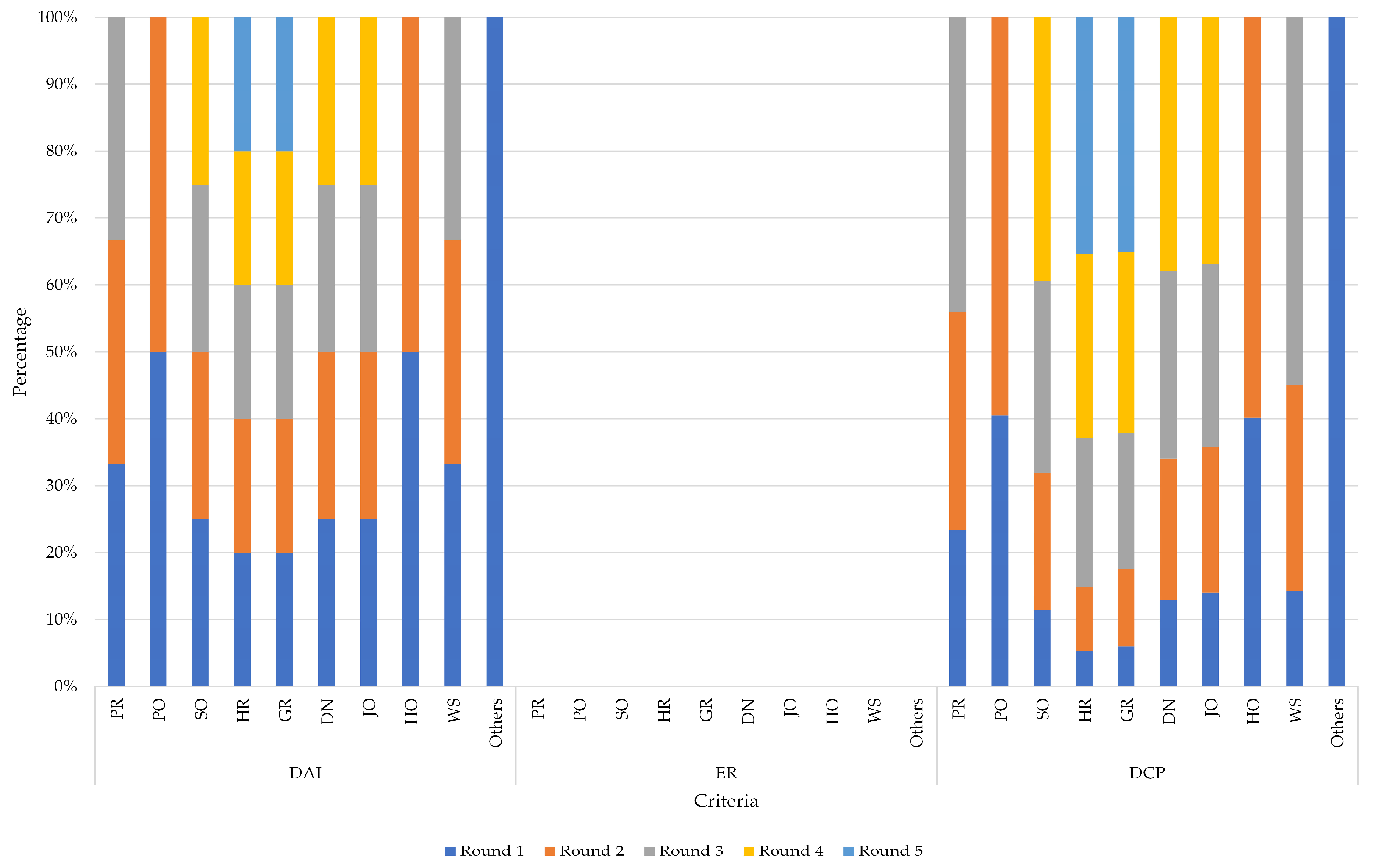
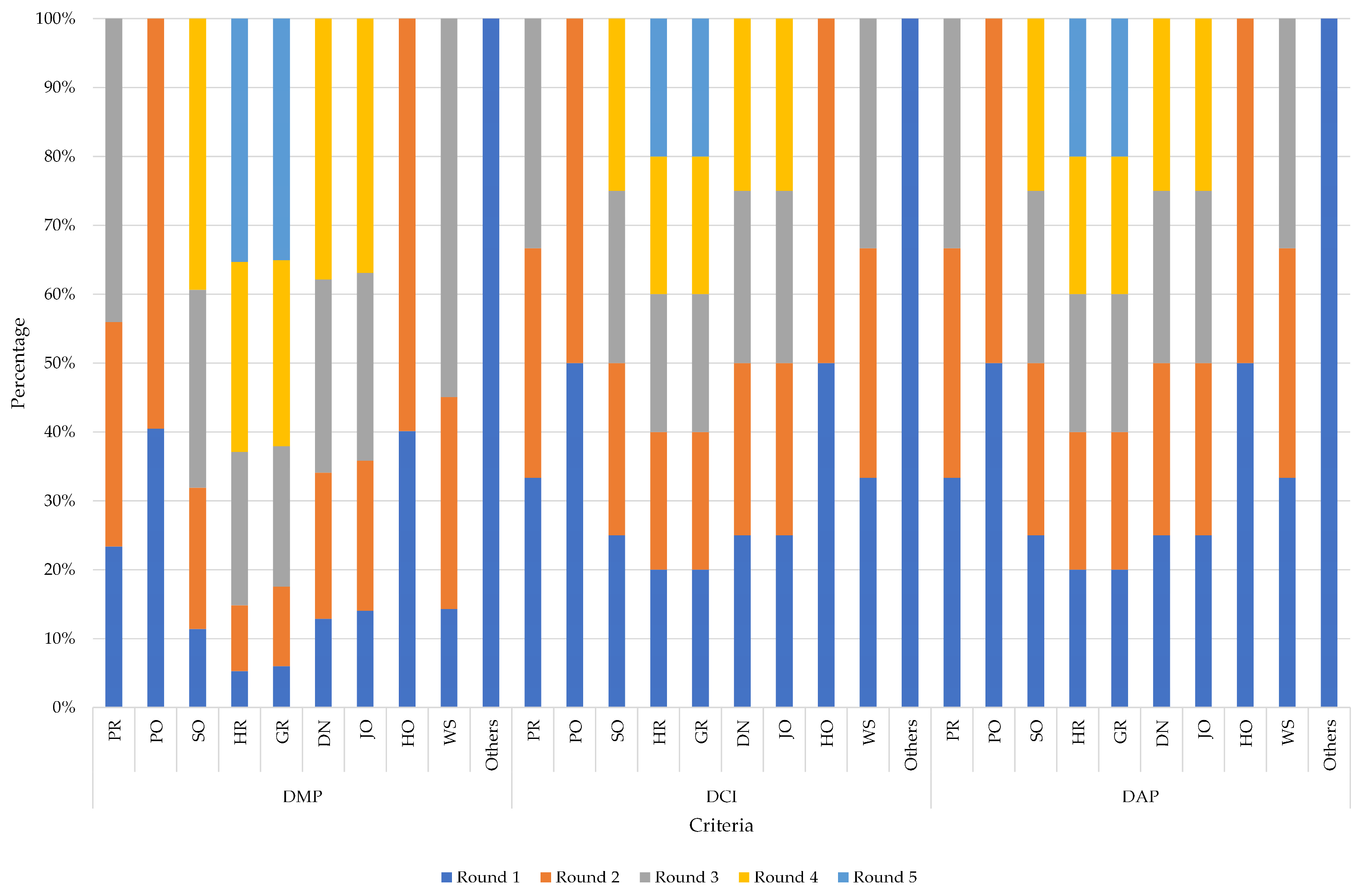
| Department | Migration Rounds | Incremental Migration | Compatibility | Transformation | Integrity | Performance | Success Rate (SR) | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| DCR | DIS | DAI | ER | DCP | DMR | DCI | DAP | ||||
| PR | 1 | 32% | 53% | 100% | 100% | 0% | 53% | 53% | 100% | 100% | 100% |
| 2 | 64% | 74% | 100% | 100% | 0% | 74% | 74% | 100% | 100% | 100% | |
| 3 | 100% | 100% | 100% | 100% | 0% | 100% | 100% | 100% | 100% | 100% | |
| PO | 1 | 54% | 68% | 100% | 100% | 0% | 68% | 68% | 100% | 100% | 100% |
| 2 | 100% | 100% | 100% | 100% | 0% | 100% | 100% | 100% | 100% | 100% | |
| SO | 1 | 25% | 29% | 100% | 100% | 0% | 29% | 29% | 100% | 100% | 100% |
| 2 | 50% | 52% | 100% | 100% | 0% | 52% | 52% | 100% | 100% | 100% | |
| 3 | 75% | 73% | 100% | 100% | 0% | 73% | 73% | 100% | 100% | 100% | |
| 4 | 100% | 100% | 100% | 100% | 0% | 100% | 100% | 100% | 100% | 100% | |
| HR | 1 | 20% | 15% | 100% | 100% | 0% | 15% | 15% | 100% | 100% | 100% |
| 2 | 40% | 27% | 100% | 100% | 0% | 27% | 27% | 100% | 100% | 100% | |
| 3 | 60% | 63% | 100% | 100% | 0% | 63% | 63% | 100% | 100% | 100% | |
| 4 | 80% | 78% | 100% | 100% | 0% | 78% | 78% | 100% | 100% | 100% | |
| 5 | 100% | 100% | 100% | 100% | 0% | 100% | 100% | 100% | 100% | 100% | |
| GR | 1 | 14% | 17% | 100% | 100% | 0% | 17% | 17% | 100% | 100% | 100% |
| 2 | 35% | 33% | 100% | 100% | 0% | 33% | 33% | 100% | 100% | 100% | |
| 3 | 52% | 58% | 100% | 100% | 0% | 58% | 58% | 100% | 100% | 100% | |
| 4 | 76% | 77% | 100% | 100% | 0% | 77% | 77% | 100% | 100% | 100% | |
| 5 | 100% | 100% | 100% | 100% | 0% | 100% | 100% | 100% | 100% | 100% | |
| DN | 1 | 26% | 34% | 100% | 100% | 0% | 34% | 34% | 100% | 100% | 100% |
| 2 | 57% | 56% | 100% | 100% | 0% | 56% | 56% | 100% | 100% | 100% | |
| 3 | 83% | 74% | 100% | 100% | 0% | 74% | 74% | 100% | 100% | 100% | |
| 4 | 100% | 100% | 100% | 100% | 0% | 100% | 100% | 100% | 100% | 100% | |
| JO | 1 | 27% | 38% | 100% | 100% | 0% | 38% | 38% | 100% | 100% | 100% |
| 2 | 54% | 59% | 100% | 100% | 0% | 59% | 59% | 100% | 100% | 100% | |
| 3 | 77% | 74% | 100% | 100% | 0% | 74% | 74% | 100% | 100% | 100% | |
| 4 | 100% | 100% | 100% | 100% | 0% | 100% | 100% | 100% | 100% | 100% | |
| HO | 1 | 54% | 67% | 100% | 100% | 0% | 67% | 67% | 100% | 100% | 100% |
| 2 | 100% | 100% | 100% | 100% | 0% | 100% | 100% | 100% | 100% | 100% | |
| WS | 1 | 35% | 26% | 100% | 100% | 0% | 26% | 26% | 100% | 100% | 100% |
| 2 | 74% | 56% | 100% | 100% | 0% | 56% | 56% | 100% | 100% | 100% | |
| 3 | 100% | 100% | 100% | 100% | 0% | 100% | 100% | 100% | 100% | 100% | |
| Others | 1 | 100% | 100% | 100% | 100% | 0% | 100% | 100% | 100% | 100% | 100% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Netinant, P.; Saengsuwan, N.; Rukhiran, M.; Pukdesree, S. Enhancing Data Management Strategies with a Hybrid Layering Framework in Assessing Data Validation and High Availability Sustainability. Sustainability 2023, 15, 15034. https://doi.org/10.3390/su152015034
Netinant P, Saengsuwan N, Rukhiran M, Pukdesree S. Enhancing Data Management Strategies with a Hybrid Layering Framework in Assessing Data Validation and High Availability Sustainability. Sustainability. 2023; 15(20):15034. https://doi.org/10.3390/su152015034
Chicago/Turabian StyleNetinant, Paniti, Nattapat Saengsuwan, Meennapa Rukhiran, and Sorapak Pukdesree. 2023. "Enhancing Data Management Strategies with a Hybrid Layering Framework in Assessing Data Validation and High Availability Sustainability" Sustainability 15, no. 20: 15034. https://doi.org/10.3390/su152015034
APA StyleNetinant, P., Saengsuwan, N., Rukhiran, M., & Pukdesree, S. (2023). Enhancing Data Management Strategies with a Hybrid Layering Framework in Assessing Data Validation and High Availability Sustainability. Sustainability, 15(20), 15034. https://doi.org/10.3390/su152015034