
MACLA-LSTM: A Novel Approach for Forecasting Water Demand

Abstract
:1. Introduction
2. Related Works
2.1. Clouded Leopard Algorithm (CLA)
2.1.1. Phase 1: Hunting (Global Search)
2.1.2. Phase 2: Daily Rest (Local Search)
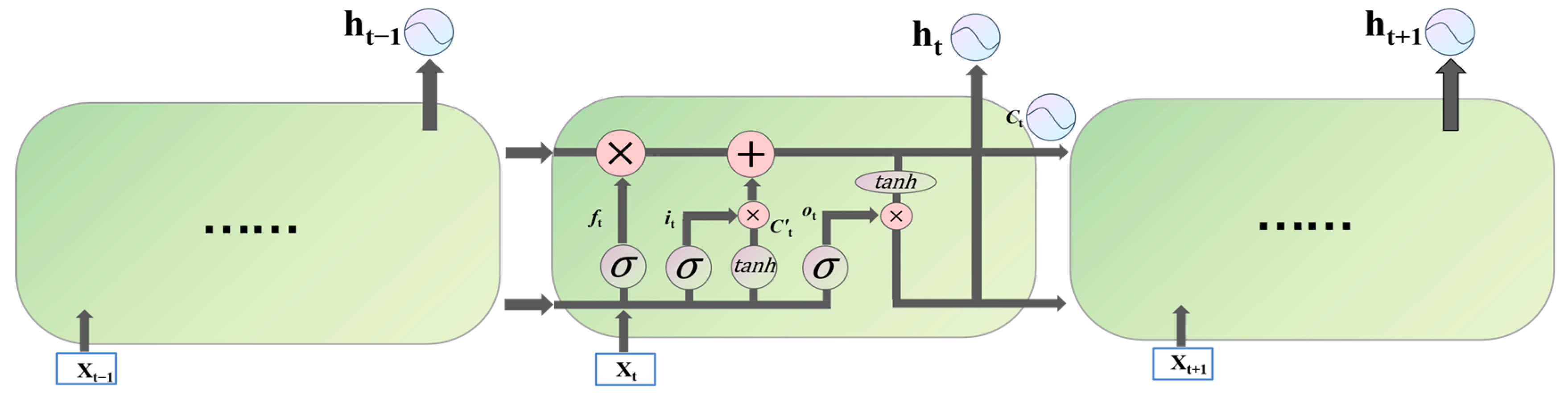
2.2. LSTM
3. Materials and Methods
3.1. Improved CLA Based on a Multiple Adaptive Mechanism
3.1.1. Initialization Based on Chaotic Mapping
3.1.2. Population Adaptive Expansion
3.1.3. Adaptive Step Size Search Parameters
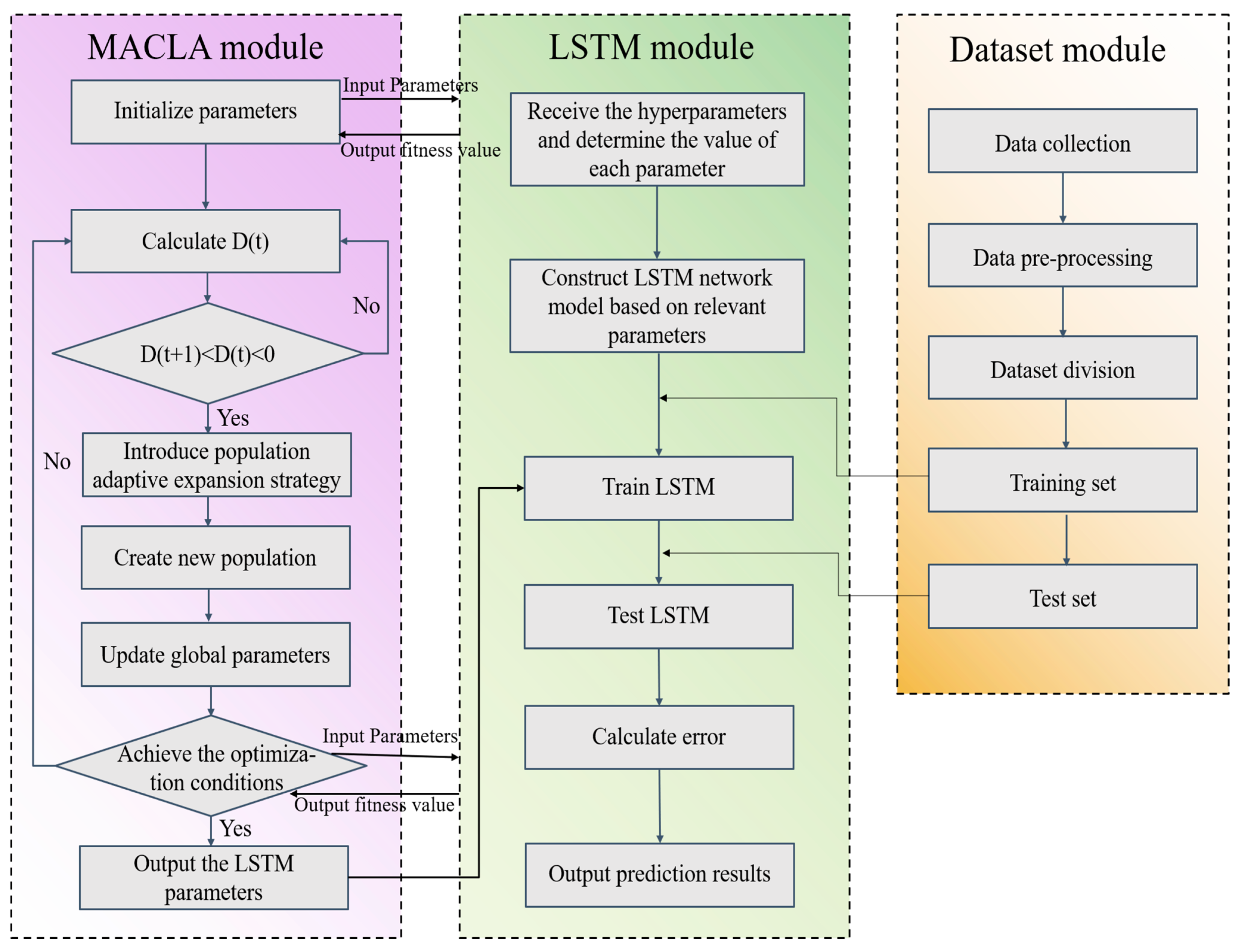
3.2. MACLA-LSTM
| Algorithm 1: MACLA |
| Input: X(w,b,n), the range of time window size (w), batch size (b), and the number of hidden layers (n) of the LSTM; Max initialization: number of initialization iterations; Max iteration: number of iterations Output: the optimal combination of time window size, batch size, and number of hidden layers parameters 1: X: w = [1, 100]; b = [1, 50]; n = [1, 5]; 2: while (t < Max initialization) do 3: ; 4: end 5: 6: while (current iteration < Max iteration) do 7: while (i < N−1) do 8: if < 0 do 9: is the result of population adaptive expansion# 10: end if 11: end 12: while (I < N−1) do 13: 14: if do 15: 16: else 17: 18: end if 19: if do 20: 21: else 22: 23: end if 24: 25: 26: end 27: end 28: Generate the optimal combination of time window size, batch size and number of hidden layers parameters Note: The content after # is a further explanation of the current content. |
4. Experiment
4.1. Evaluation Metrics
4.2. Experimental Setting
4.3. Analysis of the MACLA Effect
4.4. Analysis of MACLA-LSTM Effect
4.4.1. Data and Preprocessing
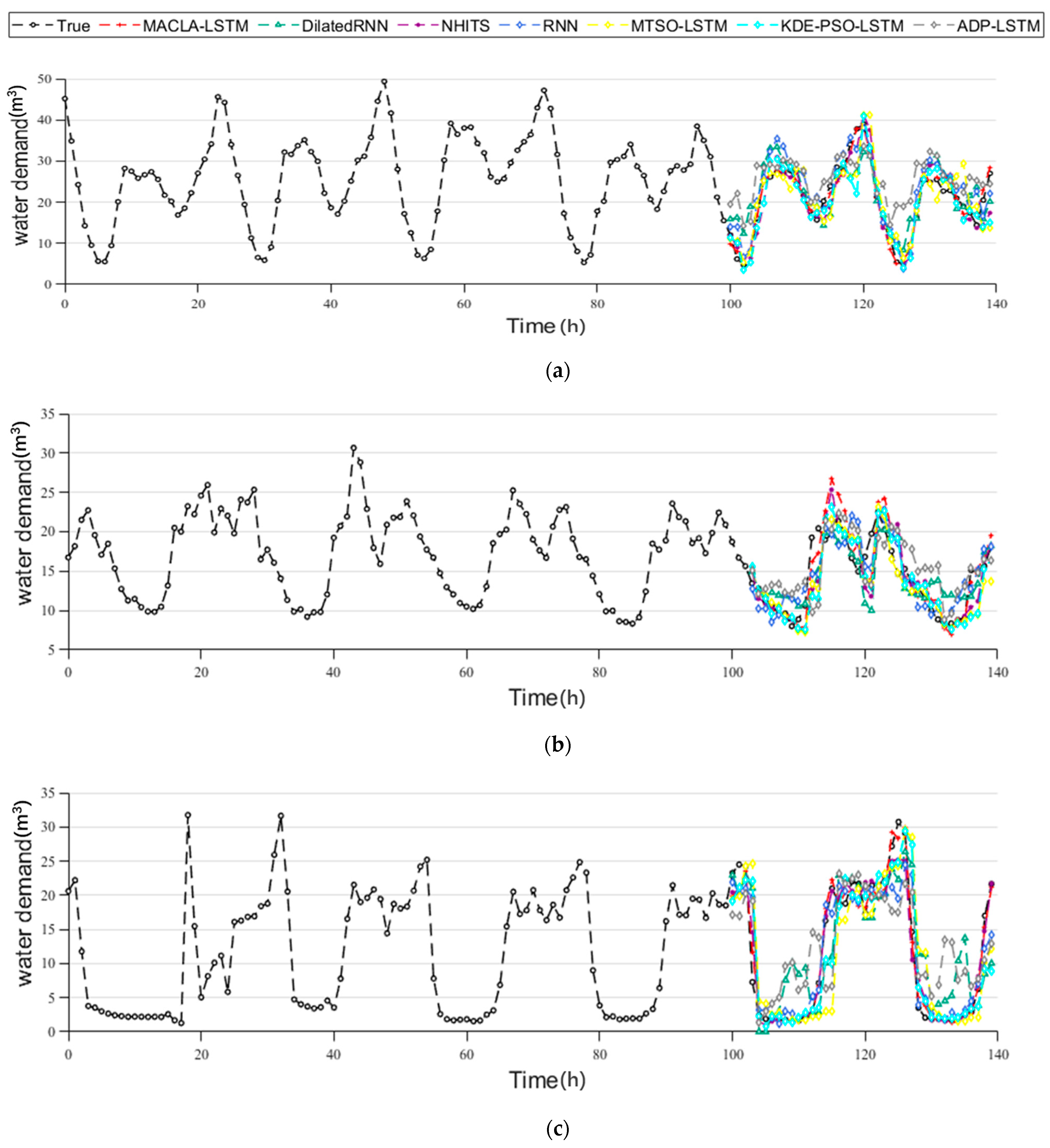
4.4.2. Results Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Choi, H.; Suh, S.; Kim, S.; Han, E.J.; Ki, S.J. Assessing the Performance of Deep Learning Algorithms for Short-Term Surface Water Quality Prediction. Sustainability 2021, 13, 10690. [Google Scholar] [CrossRef]
- Xu, Z.; Lv, Z.; Li, J.; Shi, A. A novel approach for predicting water demand with complex patterns based on ensemble learning. Water Resour. Manag. 2022, 36, 4293–4312. [Google Scholar] [CrossRef]
- Niu, Z.; Wang, C.; Zhang, Y.; Wei, X.; Gao, X. Leakage rate model of urban water supply networks using principal component regression analysis. Trans. Tianjin Univ. 2018, 24, 172–181. [Google Scholar] [CrossRef]
- Olsson, G. Urban water supply automation–today and tomorrow. J. Water Supply Res. Technol. -AQUA 2021, 70, 420–437. [Google Scholar] [CrossRef]
- Kozłowski, E.; Kowalska, B.; Kowalski, D.; Mazurkiewicz, D. Water demand forecasting by trend and harmonic analysis. Arch. Civ. Mech. Eng. 2018, 18, 140–148. [Google Scholar] [CrossRef]
- Luna, T.; Ribau, J.; Figueiredo, D.; Alves, R. Improving energy efficiency in water supply systems with pump scheduling optimization. J. Clean. Prod. 2019, 213, 342–356. [Google Scholar] [CrossRef]
- Xu, W.; Chen, J.; Zhang, X.J. Scale effects of the monthly streamflow prediction using a state-of-the-art deep learning model. Water Resour. Manag. 2022, 36, 3609–3625. [Google Scholar] [CrossRef]
- Sherstinsky, A. Fundamentals of recurrent neural network (RNN) and long short-term memory (LSTM) network. Phys. D Nonlinear Phenom. 2020, 404, 132306. [Google Scholar] [CrossRef] [Green Version]
- Chen, Z.; Ma, Q.; Lin, Z. Time-Aware Multi-Scale RNNs for Time Series Modeling. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence (IJCAI-21), Montreal, QC, Canada, 19–27 August 2021; pp. 2285–2291. [Google Scholar]
- Chang, S.; Zhang, Y.; Han, W.; Yu, M.; Guo, X.; Tan, W.; Cui, X.; Witbrock, M.; Hasegawa-Johnson, M.A.; Huang, T.S. Dilated recurrent neural networks. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A review of recurrent neural networks: LSTM cells and network architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef]
- Nasser, A.A.; Rashad, M.Z.; Hussein, S.E. A two-layer water demand prediction system in urban areas based on micro-services and LSTM neural networks. IEEE Access 2020, 8, 147647–147661. [Google Scholar] [CrossRef]
- Zanfei, A.; Brentan, B.M.; Menapace, A.; Righetti, M.; Herrera, M. Graph convolutional recurrent neural networks for water demand forecasting. Water Resour. Res. 2022, 58, e2022W–e32299W. [Google Scholar] [CrossRef]
- Li, W.; Wang, G.; Gandomi, A.H. A survey of learning-based intelligent optimization algorithms. Arch. Comput. Method. Eng. 2021, 28, 3781–3799. [Google Scholar] [CrossRef]
- Kim, C.; Batra, R.; Chen, L.; Tran, H.; Ramprasad, R. Polymer design using genetic algorithm and machine learning. Comp. Mater. Sci. 2021, 186, 110067. [Google Scholar] [CrossRef]
- Grefenstette, J.J. Genetic algorithms and machine learning. In Proceedings of the Sixth Annual Conference on Computational Learning Theory, Santa Cruz, CA, USA, 26–28 July 1993; pp. 3–4. [Google Scholar]
- Naik, A.; Satapathy, S.C. Past present future: A new human-based algorithm for stochastic optimization. Soft Comput. 2021, 25, 12915–12976. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Yang, F.; Wang, P.; Zhang, Y.; Zheng, L.; Lu, J. Survey of swarm intelligence optimization algorithms. In Proceedings of the 2017 IEEE International Conference on Unmanned Systems (ICUS), Beijing, China, 27–29 October 2017; pp. 544–549. [Google Scholar]
- Attiya, I.; Abd Elaziz, M.; Abualigah, L.; Nguyen, T.N.; Abd El-Latif, A.A. An improved hybrid swarm intelligence for scheduling iot application tasks in the cloud. IEEE T. Ind. Inform. 2022, 18, 6264–6272. [Google Scholar] [CrossRef]
- Bharathi, P.; Ramachandran, M.; Ramu, K.; Chinnasamy, S. A Study on Various Particle Swarm Optimization Techniques used in Current Scenario. Des. Model. Fabr. Adv. Robot. 2022, 1, 15–26. [Google Scholar]
- Song, G.; Zhang, Y.; Bao, F.; Qin, C. Stock prediction model based on particle swarm optimization LSTM. J. Beijing Univ. Aeronaut. Astronaut. 2019, 45, 2533–2542. [Google Scholar]
- Tuerxun, W.; Xu, C.; Guo, H.; Guo, L.; Zeng, N.; Cheng, Z. An ultra-short-term wind speed prediction model using LSTM based on modified tuna swarm optimization and successive variational mode decomposition. Energy Sci. Eng. 2022, 26, 105804. [Google Scholar] [CrossRef]
- Zhang, G.; Tan, F.; Wu, Y. Ship motion attitude prediction based on an adaptive dynamic particle swarm optimization algorithm and bidirectional LSTM neural network. IEEE Access 2020, 8, 90087–90098. [Google Scholar] [CrossRef]
- Faramarzi, A.; Heidarinejad, M.; Mirjalili, S.; Gandomi, A.H. Marine Predators Algorithm: A nature-inspired metaheuristic. Expert Syst. Appl. 2020, 152, 113377. [Google Scholar] [CrossRef]
- Kaur, S.; Awasthi, L.K.; Sangal, A.L.; Dhiman, G. Tunicate Swarm Algorithm: A new bio-inspired based metaheuristic paradigm for global optimization. Eng. Appl. Artif. Intel. 2020, 90, 103541. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. The whale optimization algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Du, B.; Huang, S.; Guo, J.; Tang, H.; Wang, L.; Zhou, S. Interval forecasting for urban water demand using PSO optimized KDE distribution and LSTM neural networks. Appl. Soft Comput. 2022, 122, 108875. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Explanation | Value |
|---|---|---|
| represents jth decision variable of ith clouded leopard | - | |
| N | the total number of clouded leopards | - |
| m | the number of decision variables | in our study, m = 3 |
| a random number | in set {0, 1} | |
| the maximum value of decision variables | discussed in the MACLA pseudo-code | |
| the minimum value of decision variables | discussed in the MACLA pseudo-code |
| Method | Equation | Parameter Value |
|---|---|---|
| Logistic | Equation (15) | |
| Tent | ||
| Logistic-tent | ||
| SPM | ||
| Piecewise | ||
| Singer |
| Method | Parameter | Value |
|---|---|---|
| MPA | Constant number | p = 0.5 |
| Random vector | R is a vector of uniform random numbers from [0, 1] | |
| Fish aggregating devices (FADs) | FADs = 0.2 | |
| Binary vector | U = 0 or 1 | |
| TSA | Pmin and Pmax | Pmin = 1, Pmax = 4 |
| C1, C2, C3 | random numbers lie in the range [0, 1] | |
| WOA | Convergence parameter (a) | Linear reduction from 2 to 0 |
| Random vector (r) | In [0, 1] | |
| Random number (l) | In [−1, 1] |
| F | MACLA | MPA | TSA | WOA | |
|---|---|---|---|---|---|
| F1([−100, 100]) | Mean | 0 | 3.17 × 10−19 | 0.0038 | 27.7122 |
| Best | 0 | 7.30 × 10−20 | 4.42 × 10−5 | 2.5181 | |
| Worst | 0 | 6.32 × 10−19 | 0.0278 | 68.2198 | |
| Std | 0 | 1.70 × 10−19 | 0.0066 | 23.1465 | |
| Median | 0 | 2.81 × 10−19 | 0.0012 | 24.7617 | |
| ET | 1.7862 | 2.2537 | 1.2056 | 0.5108 | |
| Rank | 1 | 2 | 3 | 4 | |
| F2([−10, 10]) | Mean | 0 | 5.98 × 10−28 | 3.10 × 10−28 | 6.51 × 10−104 |
| Best | 0 | 3.57 × 10−30 | 2.30 × 10−10 | 1.07 × 10−113 | |
| Worst | 0 | 2.76 × 10−27 | 8.19 × 10−28 | 1.21 × 10−102 | |
| Std | 0 | 8.19 × 10−28 | 2.71 × 10−28 | 2.28 × 10−103 | |
| Median | 0 | 2.61 × 10−29 | 7.08 × 10−29 | 5.72 × 10−107 | |
| ET | 2.1056 | 2.7646 | 1.4123 | 0.5983 | |
| Rank | 1 | 4 | 3 | 2 | |
| F3([−100, 100]) | Mean | 0 | 9.61 × 10−50 | 3.89 × 10−46 | 2.11 × 10−153 |
| Best | 0 | 9.42 × 10−53 | 4.13 × 10−50 | 3.02 × 10−168 | |
| Worst | 0 | 7.76 × 10−49 | 3.11 × 10−44 | 3.72 × 10−152 | |
| Std | 0 | 2.51 × 10−49 | 2.56 × 10−45 | 4.41 × 10−153 | |
| Median | 0 | 2.87 × 10−50 | 6.76 × 10−48 | 7.21 × 10−157 | |
| ET | 1.7856 | 2.4564 | 1.4501 | 0.5691 | |
| Rank | 1 | 3 | 4 | 2 | |
| F4([−500, 500]) | Mean | −10,312.3 | −9571.9 | −5909.3 | −8624.4 |
| Best | −12,412.1 | −11,341.2 | −7198.0 | −10,128.2 | |
| Worst | −8123.4 | −9012.3 | −5012.3 | −7527.2 | |
| Std | 1569.7 | 547.2 | 589.7 | 699.3 | |
| Median | −11,002.2 | −9578.1 | −6102.4 | −9184.5 | |
| ET | 2.8721 | 2.7671 | 1.7652 | 0.9752 | |
| Rank | 1 | 2 | 4 | 3 |
| Date | Current Recording Time | Current Cumulative Water Consumption | Last Recorded Time | Last Cumulative Water Consumption | Water Demand (m3) |
|---|---|---|---|---|---|
| 6 July 2022 07:00 | 6 July 2022 | 273,342.280 | 6 July 2022 | 273,330.640 | 11.640 |
| 6 July 2022 06:00 | 6 July 2022 | 273,330.640 | 6 July 2022 | 273,319.000 | 11.640 |
| 6 July 2022 05:00 | 6 July 2022 | 273,319.000 | 6 July 2022 | 273,309.000 | 10.000 |
| 6 July 2022 04:00 | 6 July 2022 | 273,309.000 | 6 July 2022 | 273,299.530 | 9.470 |
| 6 July 2022 03:00 | 6 July 2022 | 273,299.530 | 6 July 2022 | 273,287.100 | 12.430 |
| 6 July 2022 02:00 | 6 July 2022 | 273,287.100 | 6 July 2022 | 273,270.300 | 16.800 |
| 6 July 2022 07:00 | 6 July 2022 | 273,342.280 | 6 July 2022 | 273,330.640 | 11.640 |
| …… | …… | …… | …… | …… | …… |
| 1 January 2021 13:00 | 1 January 2021 | 15,406.443 | 26 April 2021 | 15,386.870 | 19.573 |
| 1 January 2021 12:00 | 1 January 2021 | 15,386.870 | 26 April 2021 | 15,364.255 | 22.615 |
| 1 January 2021 11:00 | 1 January 2021 | 15,364.255 | 26 April 2021 | 15,341.004 | 23.251 |
| 1 January 2021 10:00 | 1 January 2021 | 15,341.004 | 26 April 2021 | 15,318.378 | 22.626 |
| 1 January 2021 09:00 | 1 January 2021 | 15,318.378 | 26 April 2021 | 15,295.885 | 22.493 |
| 1 January 2021 08:00 | 1 January 2021 | 15,295.885 | 26 April 2021 | 15,271.406 | 24.479 |
| 1 January 2021 07:00 | 1 January 2021 | 15,271.406 | 26 April 2021 | 15,249.089 | 22.317 |
| Method | MAE ⬇ | MSE ⬇ | R2 (%) ⬆ |
|---|---|---|---|
| RNN [15] | 3.69 | 18.52 | 95.91 |
| 3.31 | 17.48 | 96.03 | |
| 2.64 | 15.14 | 93.69 | |
| NHITS [24] | 2.11 | 8.12 | 97.55 |
| 1.41 | 3.80 | 98.26 | |
| 1.61 | 5.70 | 97.62 | |
| Dilated RNN [16] | 2.36 | 8.97 | 95.60 |
| 2.28 | 8.01 | 96.33 | |
| 2.83 | 9.45 | 95.81 | |
| MTSO-LSTM [23] | 2.52 | 7.62 | 96.08 |
| 2.37 | 8.04 | 96.52 | |
| 1.97 | 7.47 | 94.97 | |
| ADP-LSTM [24] | 4.76 | 8.65 | 94.81 |
| 5.01 | 9.16 | 93.29 | |
| 5.64 | 10.22 | 92.71 | |
| KDE-PSO-LSTM [28] | 1.41 | 3.89 | 97.65 |
| 1.28 | 2.16 | 97.91 | |
| 1.22 | 3.08 | 96.21 | |
| MACLA-LSTM | 1.12 | 2.22 | 99.51 |
| 0.89 | 1.21 | 99.44 | |
| 1.09 | 2.38 | 99.01 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, K.; Ye, Z.; Wang, Z.; Liu, B.; Feng, T. MACLA-LSTM: A Novel Approach for Forecasting Water Demand. Sustainability 2023, 15, 3628. https://doi.org/10.3390/su15043628
Wang K, Ye Z, Wang Z, Liu B, Feng T. MACLA-LSTM: A Novel Approach for Forecasting Water Demand. Sustainability. 2023; 15(4):3628. https://doi.org/10.3390/su15043628
Chicago/Turabian StyleWang, Ke, Zanting Ye, Zhangquan Wang, Banteng Liu, and Tianheng Feng. 2023. "MACLA-LSTM: A Novel Approach for Forecasting Water Demand" Sustainability 15, no. 4: 3628. https://doi.org/10.3390/su15043628