
Short-Term Traffic Flow Forecasting Method Based on Secondary Decomposition and Conventional Neural Network–Transformer

Abstract
1. Introduction
2. Literature Review
2.1. Data Decomposition
2.2. Deep Learning Forecasting Models
3. Methodology
3.1. CEEMDAN Algorithm
3.2. VMD Algorithm
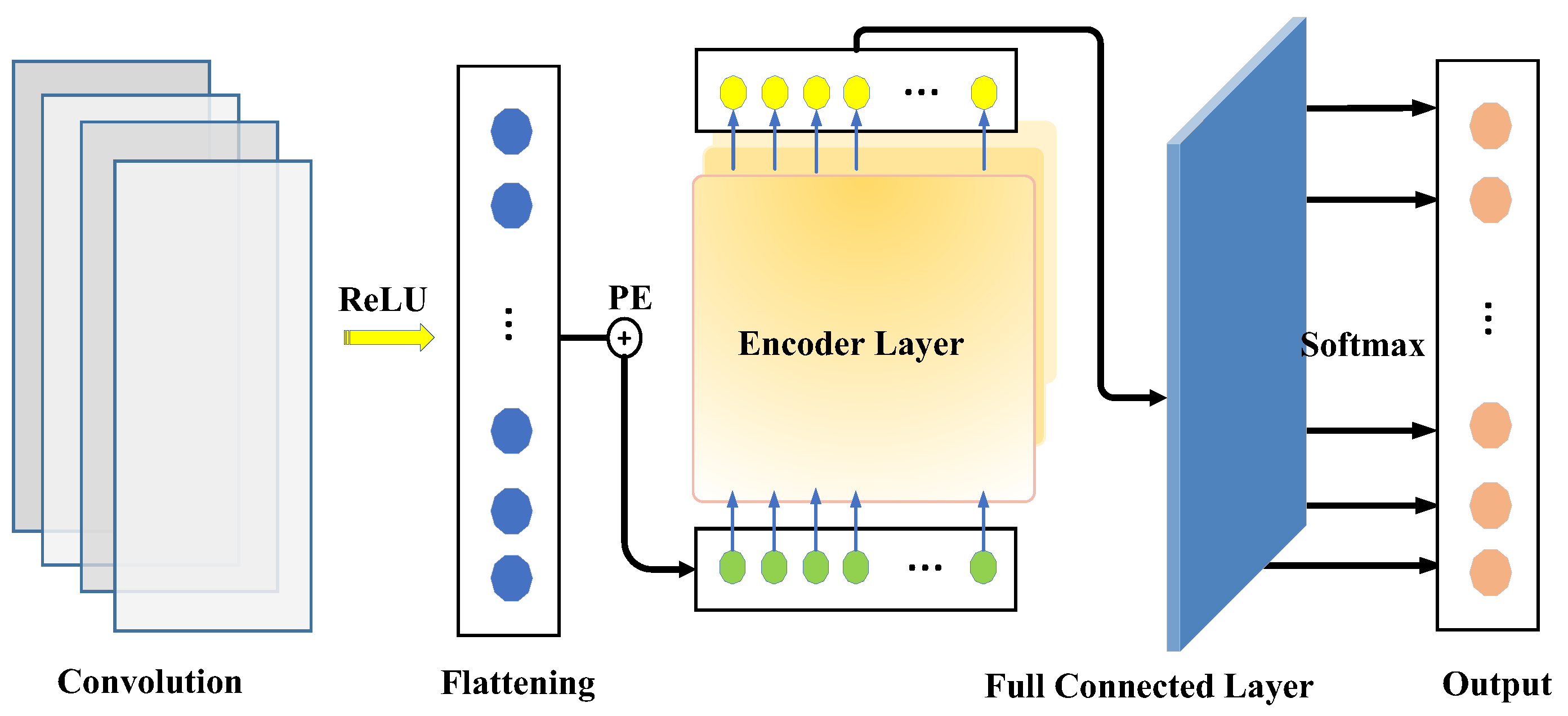
3.3. The CNN–Transformer Forecasting Model
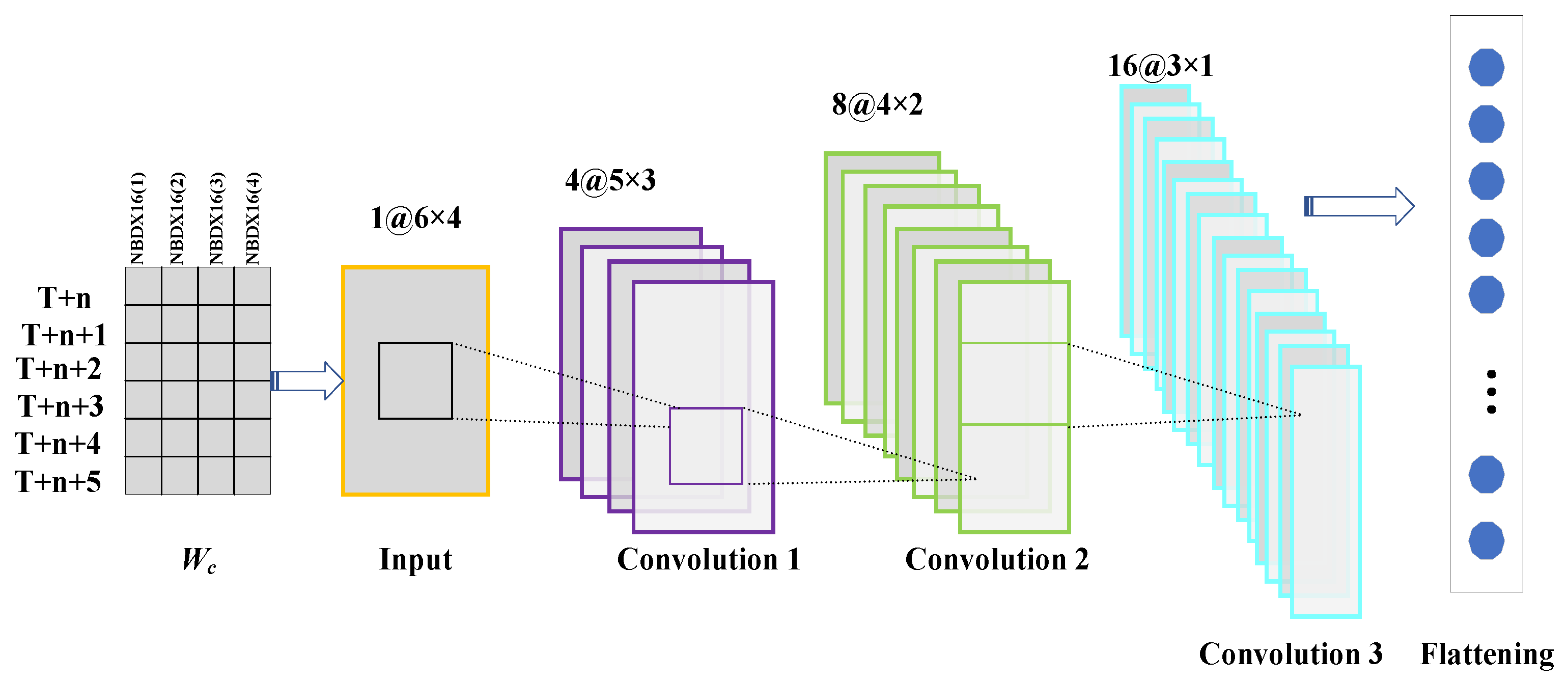
3.3.1. Implementation of the CNN Model
3.3.2. Implementation of the Transformer
3.4. The Architecture of the CEEMDAN-VMD-CNN–Transformer Model
4. Experimental Verification
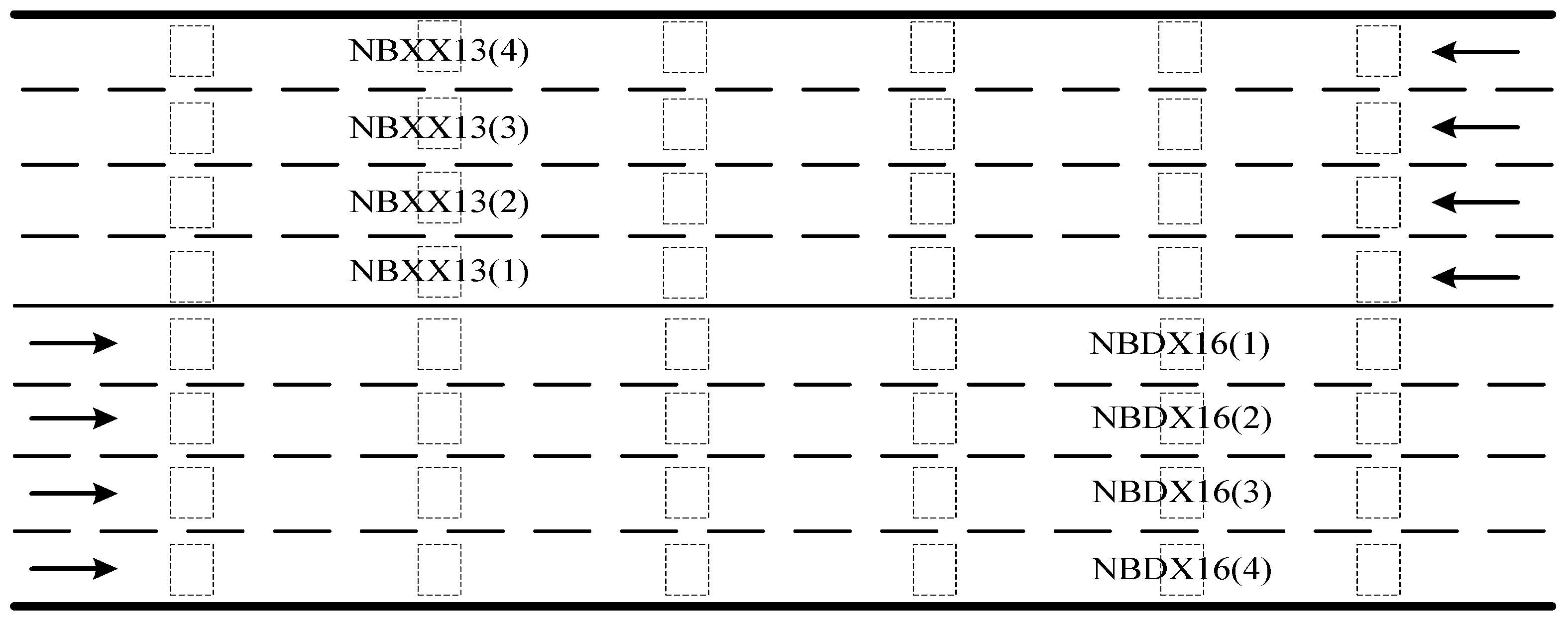
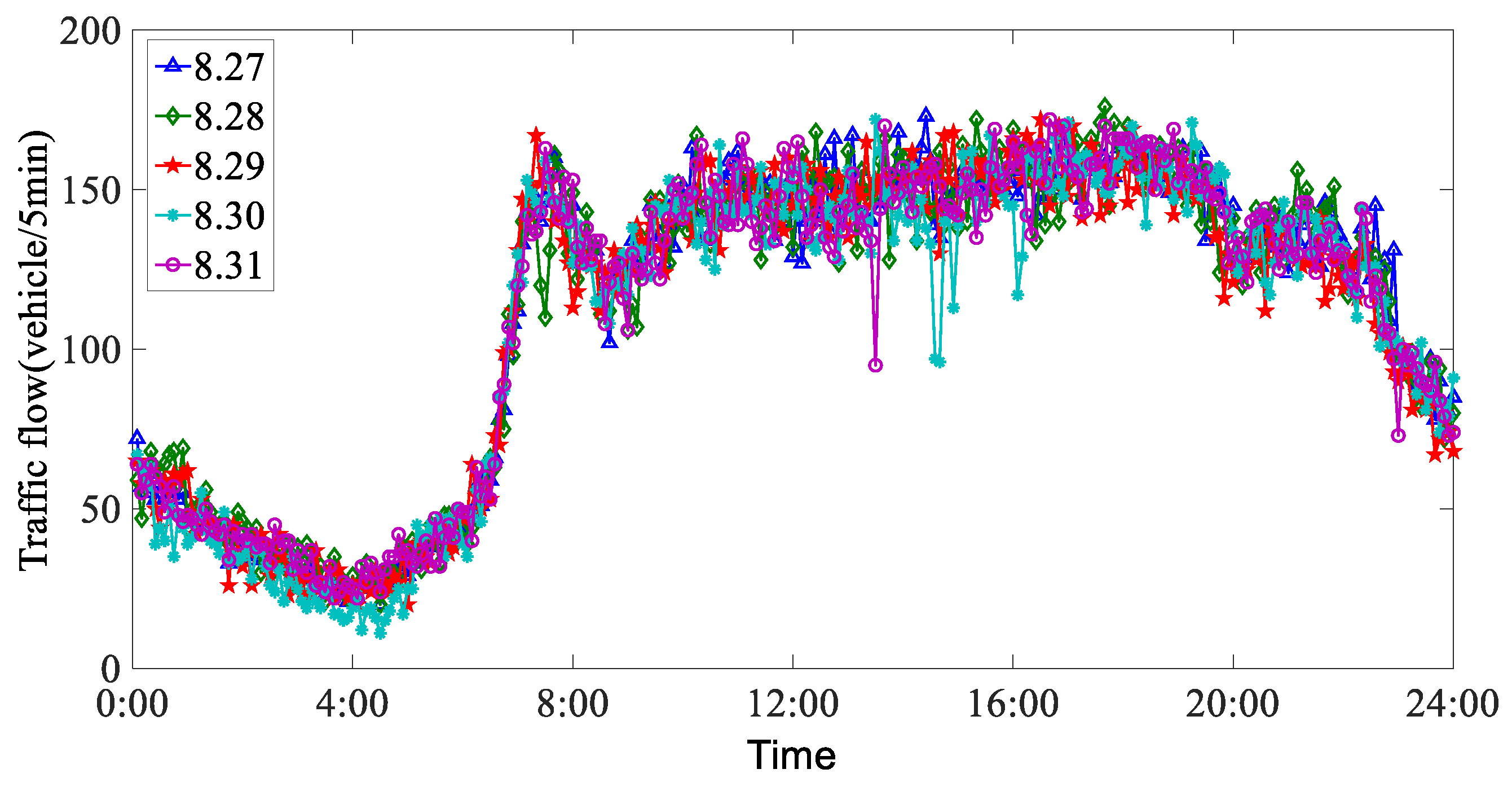
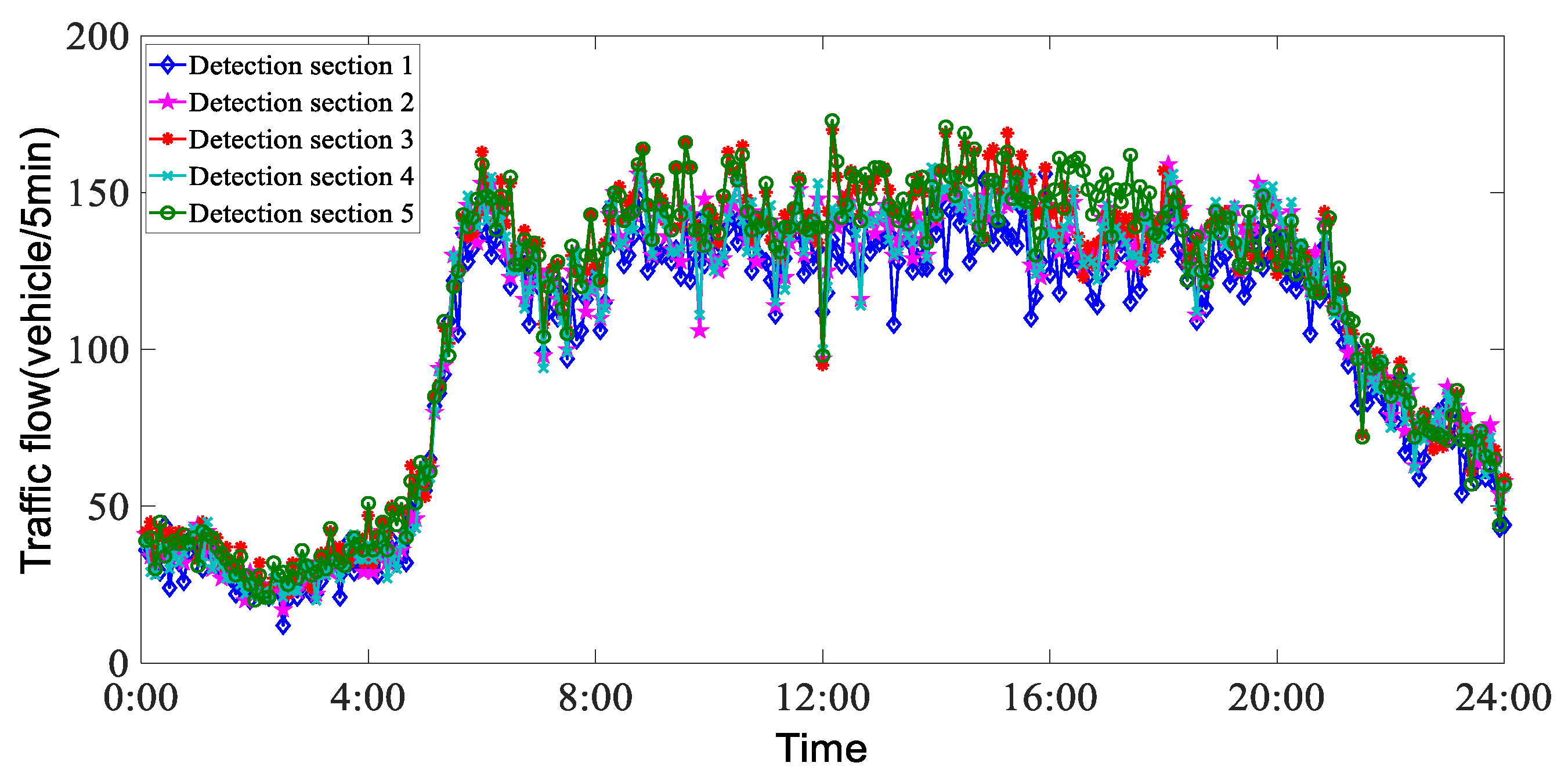
4.1. Data Source
4.2. Evaluating Indicators
4.3. CEEMDAN Results
4.4. VMD Results
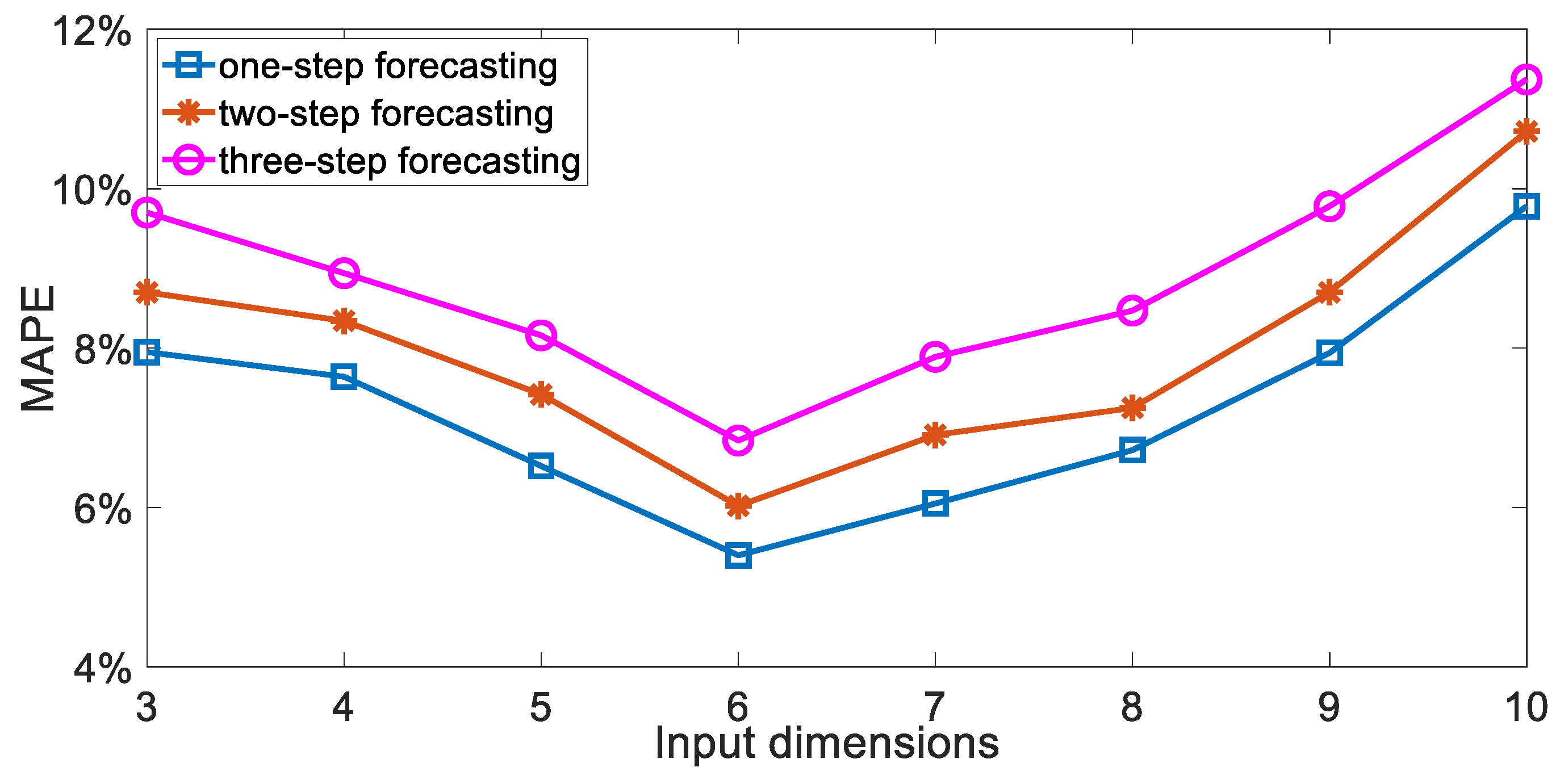
4.5. Selection of Input Dimension
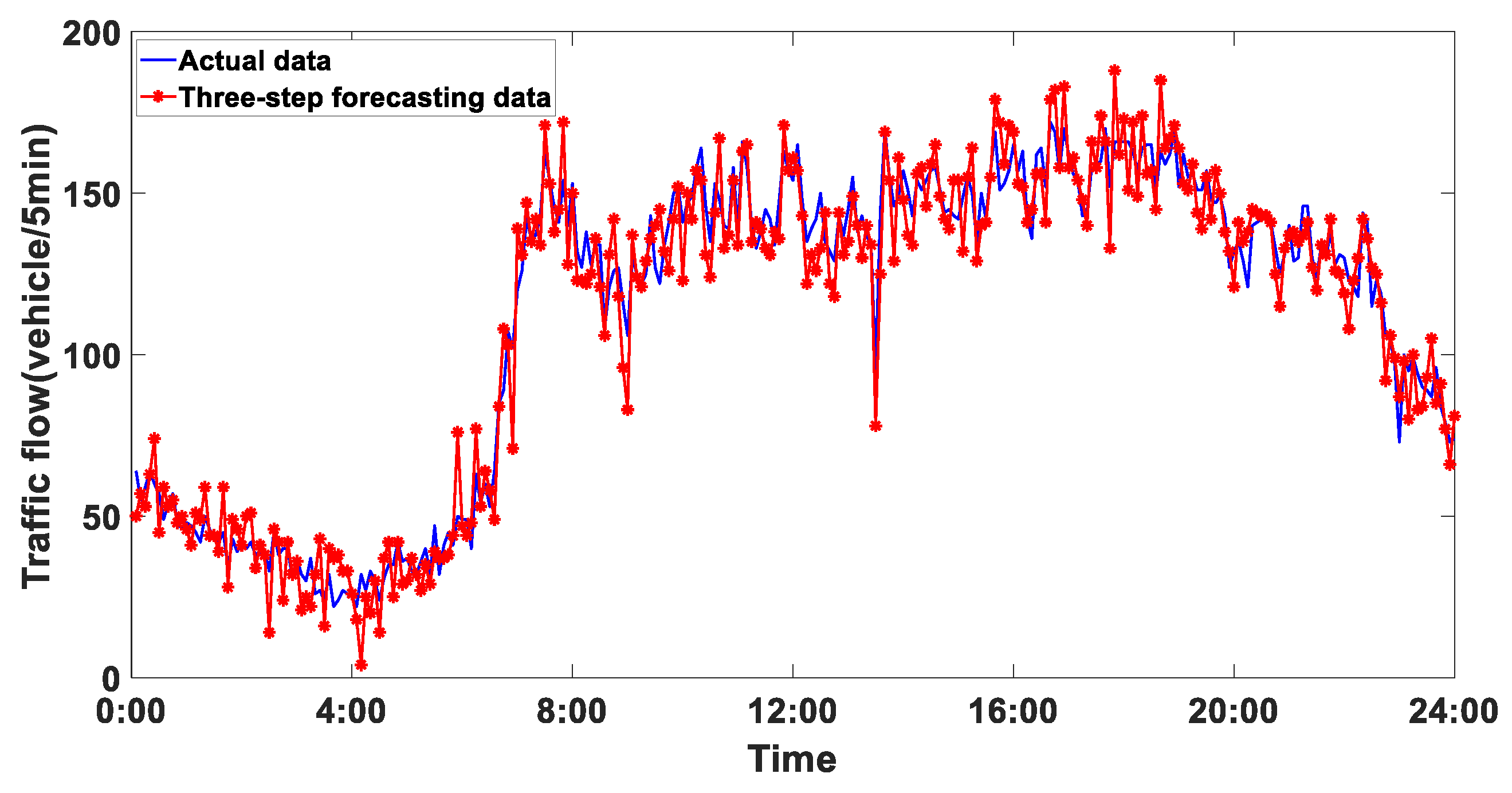
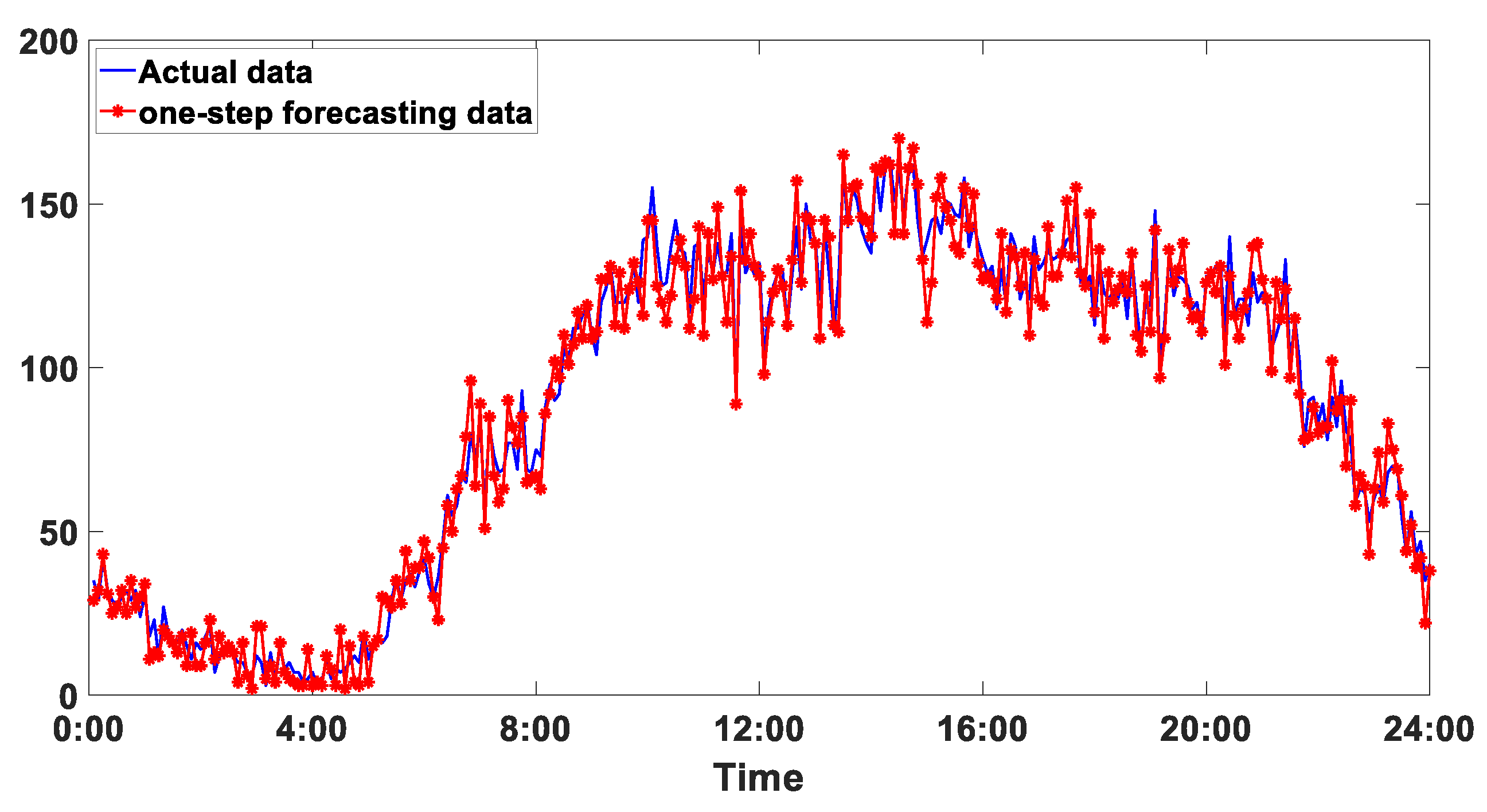
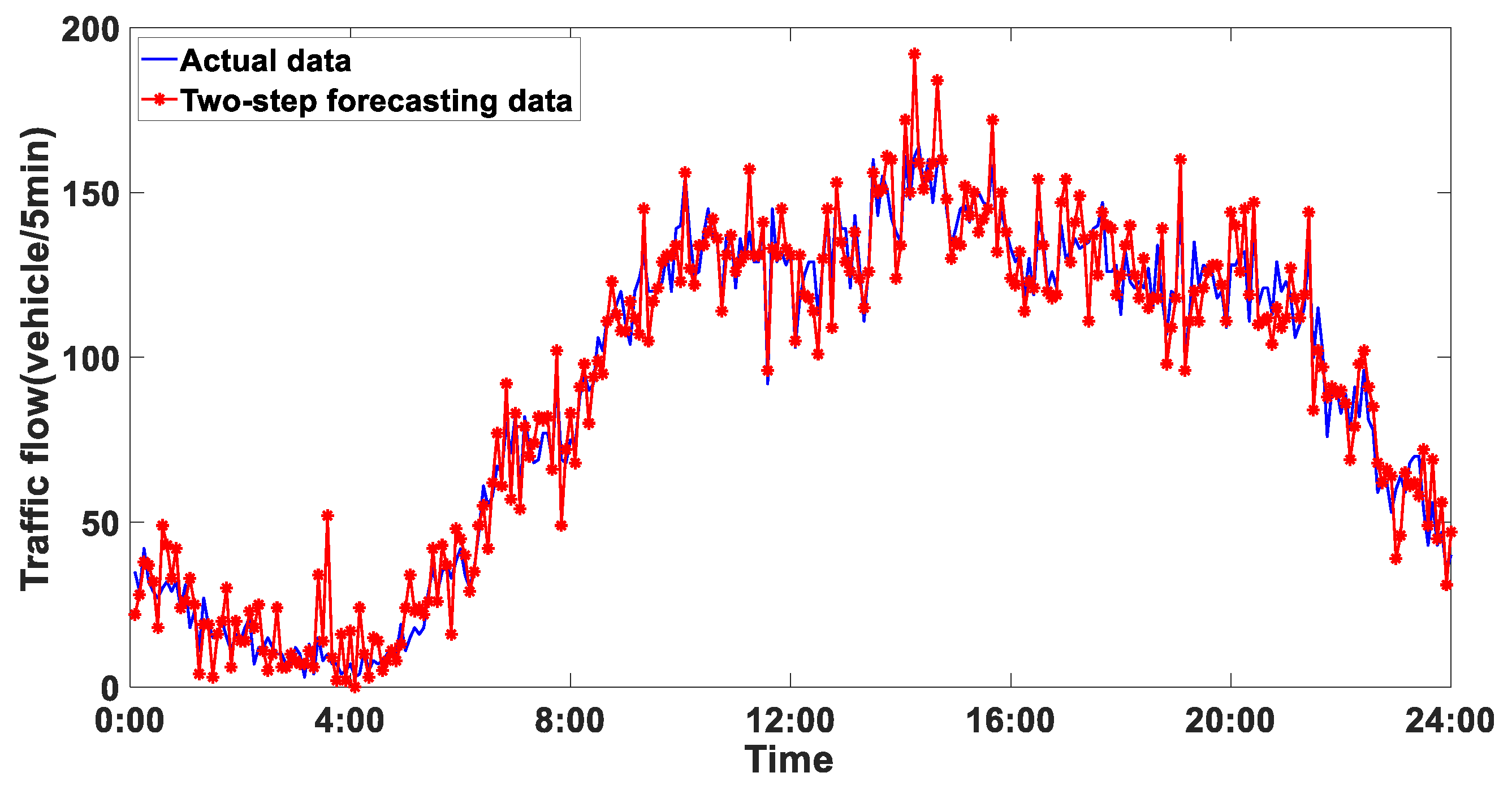
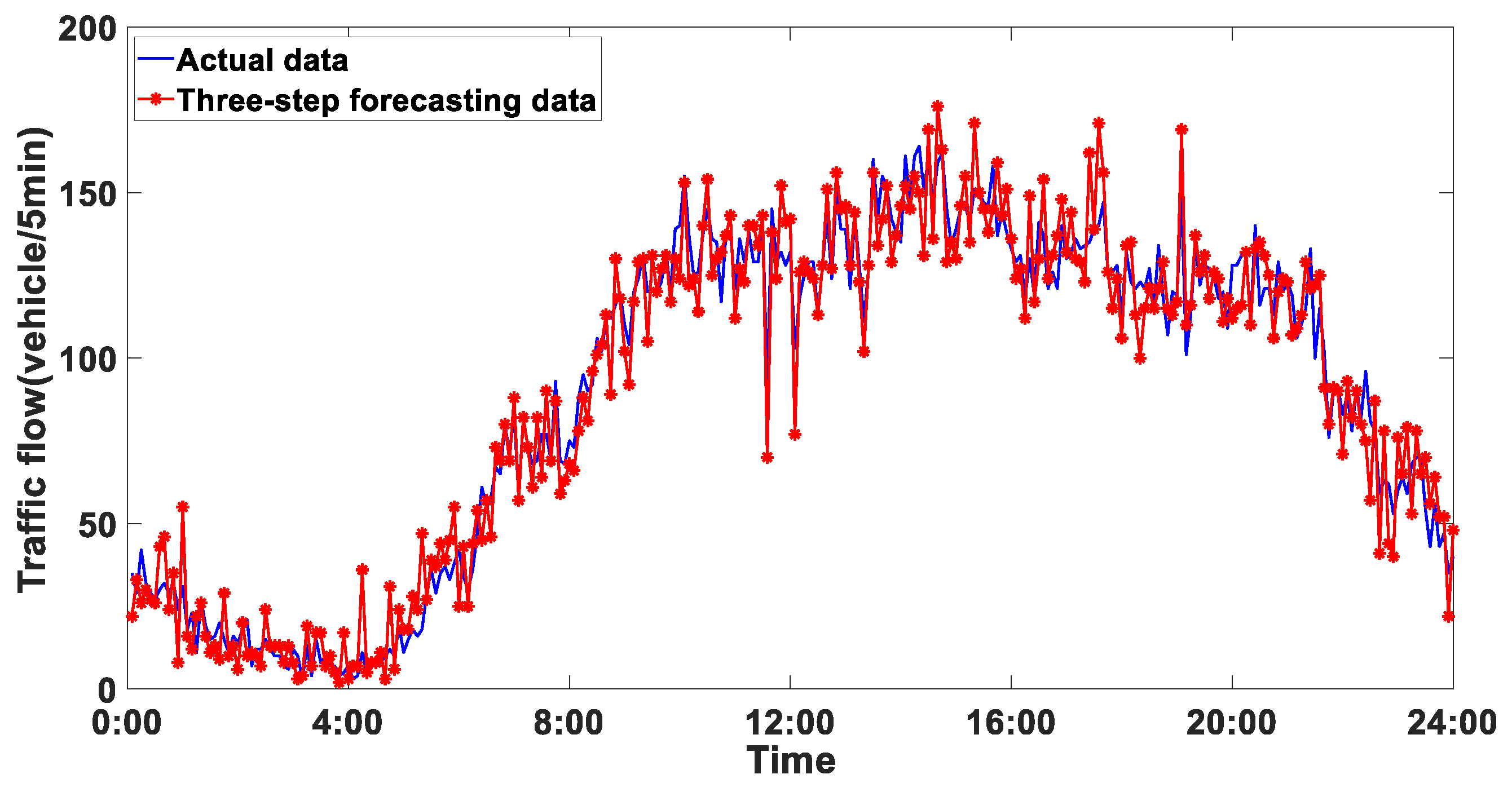
4.6. Analysis of Experimental Results
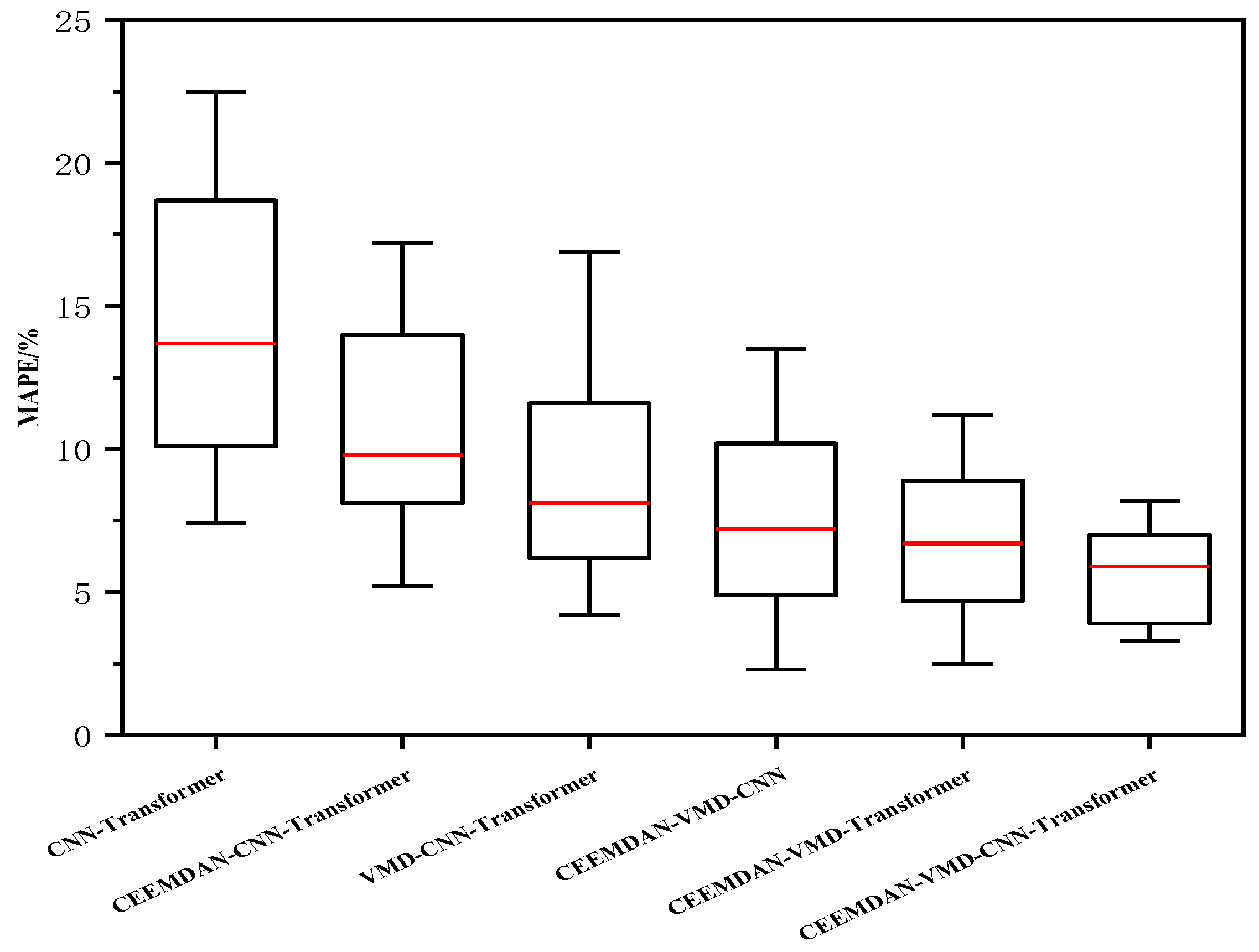
5. Comparison and Discussion
- (1)
- The methods considering data decomposition have better forecasting performance than forecasting methods without data decomposition algorithms. Taking the comparison of the CNN–Transformer method and CEEMDAN-VMD-CNN–Transformer method as an example, the CEEMDAN-VMD-CNN–Transformer method declined by 56.90%, 53.29% and 56.54% in three-step-ahead forecasting for the NBDX16(2) dataset in terms of MAE; by 24.96%, 23.20% and 21.44% in three-step-ahead forecasting in terms of RMSE; and by 52.52%, 54.02% and 53.97% in three-step-ahead forecasting in terms of MAPE.
- (2)
- The forecasting performance of the CEEMDAN-VMD-CNN–Transformer method obviously outperformed the CEEMDAN-CNN–Transformer and VMD-CNN–Transformer methods, which shows that the proposed secondary decomposition strategy is significantly effective. Taking the comparison of the CEEMDAN-CNN–Transformer method and CEEMDAN-VMD-CNN–Transformer method as an example, the CEEMDAN-VMD-CNN–Transformer method declined by 49.31%, 44.25% and 36.76% in three-step-ahead forecasting for the NBDX16(2) dataset in terms of MAE; by 17.94%, 20% and 16.15% in three-step-ahead forecasting for the NBDX16(2) dataset in terms of RMSE; and by 41.40%, 37.59% and 33.69% in three-step-ahead forecasting for the NBDX16(2) dataset in terms of MAPE. Taking the comparison of the VMD-CNN–Transformer and CEEMDAN-VMD-CNN–Transformer methods as an example, the CEEMDAN-VMD-CNN–Transformer method declined by 42.33%, 40.70% and 34.09% in three-step-ahead forecasting for the NBDX16(2) dataset in terms of MAE; by 16.13%, 16.79% and 12.74% in three-step-ahead forecasting for the NBDX16(2) dataset in terms of RMSE; and by 25.84%, 23.15% and 22.38% in three-step -head forecasting for the NBDX16(2) dataset in terms of MAPE.
- (3)
- The forecasting results of the CEEMDAN-VMD-CNN–Transformer method outperforms the CEEMDAN-VMD-Transformer and CEEMDAN-VMD-CNN models, which proves that the cascaded CNN–Transformer model can match the features of traffic flow data wonderfully. Taking the comparison of the CEEMDAN-VMD-CNN method and the CEEMDAN-VMD-CNN–Transformer method as an example, the CEEMDAN-VMD-CNN–Transformer method declined by 19.44%, 14.72% and 13.50% in three-step-ahead forecasting for the NBDX16(2) dataset in terms of MAE; by 11.11%, 11.95% and 9.90% in three-step-ahead forecasting for the NBDX16(2) dataset in terms of RMSE; and by 13.58%, 11.88% and 11.10% in three-step-ahead forecasting for the NBDX16(2) dataset in terms of MAPE. Taking the comparison of the CEEMDAN-VMD-Transformer method and the CEEMDAN-VMD-CNN–Transformer method as an example, the CEEMDAN-VMD-CNN–Transformer method declined by 9.98%, 5.38% and 9.27% in three-step-ahead forecasting for the NBDX16(2) dataset in terms of MAE; by 5.65%, 7.87% and 5.64% in three-step-ahead forecasting for the NBDX16(2) dataset in terms of RMSE; and by 1.68%, 4.30% and 5.34% in three-step-ahead forecasting for the NBDX16(2) dataset in terms of MAPE.
- (4)
- The proposed CEEMDAN-VMD-CNN–Transformer method has significant advantages over other comparative methods for three-step-ahead forecasting.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ji, J.H.; Bie, Y.M.; Wang, L.H. Optimal electric bus fleet scheduling for a route with charging facility sharing. Transp. Res. Part C Emerg. Technol. 2023, 147, 104010. [Google Scholar] [CrossRef]
- Zhang, Y.R.; Zhang, Y.L.; Ali, H. A hybrid short-term traffic flow forecasting method based on spectral analysis and statistical volatility model. Transp. Res. Part C 2014, 43, 65–78. [Google Scholar] [CrossRef]
- Lin, X.; Huang, Y. Short-term high-speed traffic flow prediction based on ARIMA-GARCH-M model. Wirel. Pers. Commun. 2021, 117, 3421–3430. [Google Scholar] [CrossRef]
- Li, D. Predicting short-term traffic flow in urban based on multivariate linear regression model. J. Intell. Fuzzy Syst. 2020, 39, 1417–1427. [Google Scholar] [CrossRef]
- Zhou, T.; Jiang, D.; Lin, Z.; Han, G.; Xu, X.; Qin, J. Hybrid dual Kalman filtering model for short-term traffic flow forecasting. IET Intell. Transp. Syst. 2019, 13, 1023–1032. [Google Scholar] [CrossRef]
- Xu, X.; Jin, X.; Xiao, D.; Ma, C.; Wong, S.C. A hybrid autoregressive fractionally integrated moving average and nonlinear autoregressive neural network model for short-term traffic flow prediction. J. Intell. Transp. Syst. 2023, 27, 1–18. [Google Scholar] [CrossRef]
- Peng, Y.N.; Xiang, W.L. Short-term traffic volume forecasting using GA-BP based on wavelet denoising and phase space reconstruction. Physica A 2020, 549, 123913. [Google Scholar] [CrossRef]
- Ma, C.X.; Tan, L.M.; Xu, X.C. Short-term traffic flow prediction based on genetic artificial neural network and exponential smoothing. Promet-Traffic Transp. 2020, 32, 747–760. [Google Scholar] [CrossRef]
- Xu, L.Q.; Du, X.D.; Wang, B.G. Short-term traffic flow prediction model of wavelet neural network based on mine evolutionary algorithm. Int. J. Pattern Recognit. Artif. Intell. 2018, 32, 1850041. [Google Scholar] [CrossRef]
- Feng, X.; Ling, X.; Zheng, H.; Chen, Z.; Xu, Y. Adaptive multi-kernel SVM with spatial-temporal correlation for short-term traffic flow prediction. IEEE Trans. Intell. Transp. Syst. 2019, 20, 2001–2013. [Google Scholar] [CrossRef]
- Toan, T.D.; Truong, V.H. Support vector machine for short-term traffic flow prediction and improvement of its model training using nearest neighbor approach. Transp. Res. Rec. 2021, 2675, 362–373. [Google Scholar] [CrossRef]
- Yang, Y.; Li, Z.; Chen, J.; Liu, Z.; Cao, J. TRELM-DROP: An impavement non-iterative algorithm for traffic flow forecast. Phys. A Stat. Mech. Its Appl. 2024, 633, 129337. [Google Scholar] [CrossRef]
- Bing, Q.; Shen, F.; Chen, X.; Zhang, W.; Hu, Y.; Qu, D. A hybrid short-term traffic flow multistep prediction method based on variational mode decomposition and long short-term memory model. Discret. Dyn. Nat. Soc. 2021, 2021, 4097149. [Google Scholar] [CrossRef]
- Huang, H.-C.; Chen, J.-Y.; Shi, B.-C.; He, H.-D. Multi-step forecasting of short-term traffic flow based on Intrinsic Pattern Transform. Phys. A Stat. Mech. Its Appl. 2023, 621, 128798. [Google Scholar] [CrossRef]
- Chen, X.; Lu, J.; Zhao, J.; Qu, Z.; Yang, Y.; Xian, J. Traffic flow prediction at varied time scales via ensemble empirical mode decomposition and artificial neural network. Sustainability 2020, 12, 3678. [Google Scholar] [CrossRef]
- Zheng, Y.; Wang, S.; Dong, C.; Li, W.; Zheng, W.; Yu, J. Urban road traffic flow prediction: A graph convolutional network embedded with wavelet decomposition and attention mechanism. Phys. A Stat. Mech. Its Appl. 2022, 608, 128274. [Google Scholar] [CrossRef]
- Wu, X.Y.; Fu, S.D.; He, Z.J. Research on short-term traffic flow combination prediction based on CEEMDAN and machine learning. Appl. Sci. 2023, 13, 308. [Google Scholar] [CrossRef]
- Yang, H.; Cheng, Y.X.; Li, G.H. A new traffic flow prediction model based on cosine similarity variational mode decomposition, extreme learning machine and iterative error compensation strategy. Eng. Appl. Artif. Intell. 2022, 115, 105234. [Google Scholar] [CrossRef]
- Liu, H.; Tian, H.-Q.; Liang, X.-F.; Li, Y.-F. Wind speed forecasting approach using secondary decomposition algorithm and Elman neural networks. Appl. Energy 2015, 157, 183–194. [Google Scholar] [CrossRef]
- Yin, H.; Ou, Z.; Huang, S.; Meng, A. A cascaded deep learning wind power prediction approach based on a two-layer of mode decomposition. Energy 2019, 189, 116316. [Google Scholar] [CrossRef]
- Sun, W.; Tan, B.; Wang, Q.Q. Multi-step wind speed forecasting based on secondary decomposition algorithm and optimized back propagation neural network. Appl. Soft Comput. 2021, 113, 107894. [Google Scholar] [CrossRef]
- Wen, Y.; Pan, S.; Li, X.; Li, Z. Highly fluctuating short-term load forecasting based on improved secondary decomposition and optimized VMD. Sustain. Energy Grids Netw. 2024, 37, 101270. [Google Scholar] [CrossRef]
- Zhang, G.; Zhang, Y.; Wang, H.; Liu, D.; Cheng, R.; Yang, D. Short-term wind speed forecasting based on adaptive secondary decomposition and robust temporal convolutional network. Energy 2024, 288, 129618. [Google Scholar] [CrossRef]
- Zhao, L.; Wen, X.; Shao, Y.; Tang, Z. Hybrid model for method for short-term traffic flow prediction based on secondary decomposition technique and ELM. Math. Probl. Eng. 2022, 2022, 9102142. [Google Scholar] [CrossRef]
- Hu, G.; Whalin, R.W.; Kwembe, T.A.; Lu, W. Short-term traffic flow prediction based on secondary hybrid decomposition and deep echo state networks. Phys. A Stat. Mech. Its Appl. 2023, 632, 129313. [Google Scholar] [CrossRef]
- Li, H.; Jin, F.; Sun, S.; Li, Y. A new secondary decomposition ensemble learning approach for carbon price forecasting. Knowl.-Based Syst. 2021, 214, 106686. [Google Scholar] [CrossRef]
- Li, J.M.; Liu, D.H. Carbon price forecasting based on secondary decomposition and feature screening. Energy 2023, 278, 127783. [Google Scholar] [CrossRef]
- Do, L.N.; Vu, H.L.; Vo, B.Q.; Liu, Z.; Phung, D. An effective spatial-temporal attention based neural network for traffic flow prediction. Transp. Res. Part C Emerg. Technol. 2019, 108, 12–28. [Google Scholar] [CrossRef]
- Zhang, W.; Yu, Y.; Qi, Y.; Shu, F.; Wang, Y. Short-term traffic flow prediction based on spatio-temporal analysis and CNN deep learning. Transp. A Transp. Sci. 2019, 15, 1688–1711. [Google Scholar] [CrossRef]
- Ma, D.F.; Song, X.; Li, P. Daily Traffic Flow Forecasting through a Contextual Convolutional Recurrent Neural Network Modeling Inter- and Intra-Day Traffic Patterns. IEEE Trans. Intell. Transp. Syst. 2020, 22, 2627–2636. [Google Scholar] [CrossRef]
- Chen, Y.; Chen, X.Q. A novel reinforced dynamic graph convolutional network model with data imputation for network-wide traffic flow prediction. Transp. Res. Part C Emerg. Technol. 2022, 143, 103820. [Google Scholar] [CrossRef]
- Redhu, P.; Kumar, K. Short-term traffic flow prediction based on optimized deep learning neural network: PSO-Bi-LSTM. Phys. A Stat. Mech. Its Appl. 2023, 625, 129001. [Google Scholar]
- Shu, W.N.; Cai, K.; Xiong, N.N. A Short-Term Traffic Flow Prediction Model Based on an Improved Gate Recurrent Unit Neural Network. IEEE Trans. Intell. Transp. Syst. 2022, 23, 16654–16665. [Google Scholar] [CrossRef]
- Liu, M.; Zhu, T.; Ye, J.; Meng, Q.; Sun, L.; Du, B. Spatio-Temporal AutoEncoder for Traffic Flow Prediction. IEEE Trans. Intell. Transp. Syst. 2023, 24, 5516–5526. [Google Scholar] [CrossRef]
- Sun, L.; Liu, M.; Liu, G.; Chen, X.; Yu, X. FD-TGCN: Fast and dynamic temporal graph convolution network for traffic flow prediction. Inf. Fusion 2024, 106, 102291. [Google Scholar] [CrossRef]
- Liu, Z.; Ding, F.; Dai, Y.; Li, L.; Chen, T.; Tan, H. Spatial-temporal graph convolution network model with traffic fundamental diagram information informed for network traffic flow prediction. Expert Syst. Appl. 2024, 249, 123543. [Google Scholar] [CrossRef]
- Wen, Y.; Xu, P.; Li, Z.; Xu, W.; Wang, X. RPConvformer: A novel Transformer-based deep neural networks for traffic flow prediction. Expert Syst. Appl. 2023, 218, 119587. [Google Scholar] [CrossRef]
- Wu, Z.; Huang, N.E. Ensemble empirical mode decomposition: A noise-assisted data analysis method. Adv. Adapt. Data Anal. 2011, 1, 1–41. [Google Scholar] [CrossRef]
- Torres, M.E.; Colominas, M.A.; Schlotthauer, G. A complete ensemble empirical mode decomposition with adaptive noise. In Proceedings of the 2011 International Conference on Acoustics Speech and Signal Processing, Prague, Czech Republic, 22–27 May 2011; pp. 4144–4147. [Google Scholar]
- Dragomiretskiy, K.; Zosso, D. Variational mode decomposition. IEEE Trans. Signal Process. 2014, 62, 531–544. [Google Scholar] [CrossRef]
- Islam, Z.; Abdel-Aty, M.; Mahmoud, N. Using CNN-LSTM to predict signal phasing and timing aided by High-Resolution detector data. Transp. Res. Part C Emerg. Technol. 2022, 141, 103742. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; pp. 5998–6008. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Decomposition Algorithm | Forecasting Model | Forecasting Target |
|---|---|---|---|
| [19] | WPD + FEEMD | Elman | Wind speed |
| [20] | EMD + VMD | CNN-LSTM | Wind power |
| [21] | VMD + SGMD | BPNN | Wind speed |
| [22] | CEEMDAN + VMD | LSTM | Load |
| [23] | CEEMDAN + VMD | CNN | Wind speed |
| [24] | EMD + LMD | ELM | Short-term traffic flow |
| [25] | CEEMDAN + WPD | ESN | Short-term traffic flow |
| [26] | CEEMD + VMD | BPNN | Carbon price |
| [27] | CEEMDAN + WTD | SVR | Carbon price |
| Our method | CEEMDAN + VMD | CNN–Transformer | Short-term traffic flow |
| K | IMF1 | IMF2 | IMF3 | IMF4 | IMF5 |
|---|---|---|---|---|---|
| 2 | 185.17 | 292.64 | |||
| 3 | 180.14 | 268.48 | 341.76 | ||
| 4 | 193.05 | 260.56 | 321.41 | 343.09 | |
| 5 | 186.98 | 244.83 | 289.09 | 327.86 | 347.96 |
| K | IMF1 | IMF2 | IMF3 | IMF4 | IMF5 |
|---|---|---|---|---|---|
| 2 | 179.06 | 299.62 | |||
| 3 | 198.08 | 289.18 | 381.06 | ||
| 4 | 193.03 | 264.87 | 326.54 | 383.22 | |
| 5 | 181.20 | 242.28 | 302.06 | 332.37 | 386.50 |
| Parameters | Value |
|---|---|
| Epochs | 300 |
| Batch size | 64 |
| Learning rate | 0.0012 |
| Convolutional kernel size | 2 × 2 |
| Encoder layer | 3 |
| Decoder (fully connected layer) | 3 |
| Attention head | 6 |
| Dropout rate | 0.2 |
| Optimizer | Adam |
| Loss function | RMSE |
| Methods | Evaluation Indicators | 1-Step | 2-Step | 3-Step |
|---|---|---|---|---|
| CNN–Transformer | MAE | 9.42 | 10.17 | 12.38 |
| RMSE | 42.74 | 44.53 | 47.25 | |
| MAPE | 11.12% | 13.07% | 14.62% | |
| CEEMDAN-CNN–Transformer | MAE | 8.01 | 8.52 | 9.14 |
| RMSE | 39.08 | 42.75 | 44.27 | |
| MAPE | 9.01% | 9.63% | 10.15% | |
| VMD-CNN–Transformer | MAE | 7.04 | 8.01 | 8.77 |
| RMSE | 38.24 | 41.10 | 42.54 | |
| MAPE | 7.12% | 7.82% | 8.67% | |
| CEEMDAN-VMD-CNN | MAE | 5.04 | 5.57 | 6.22 |
| RMSE | 36.08 | 38.84 | 41.20 | |
| MAPE | 6.11% | 6.82% | 7.57% | |
| CEEMDAN-VMD-Transformer | MAE | 4.51 | 5.02 | 5.93 |
| RMSE | 34.66 | 37.12 | 39.34 | |
| MAPE | 5.37% | 6.28% | 7.11% | |
| CEEMDAN-VMD-CNN–Transformer | MAE | 4.06 | 4.75 | 5.38 |
| RMSE | 32.07 | 34.20 | 37.12 | |
| MAPE | 5.28% | 6.01% | 6.73% |
| Methods | Evaluation Indicators | 1-Step | 2-Step | 3-Step |
|---|---|---|---|---|
| CNN–Transformer | MAE | 9.74 | 10.85 | 13.26 |
| RMSE | 43.55 | 46.14 | 49.02 | |
| MAPE | 12.20% | 13.96% | 15.79% | |
| CEEMDAN-CNN–Transformer | MAE | 8.14 | 9.02 | 9.46 |
| RMSE | 39.31 | 42.75 | 44.84 | |
| MAPE | 9.07% | 9.58% | 10.21% | |
| VMD-CNN–Transformer | MAE | 7.17 | 8.48 | 9.16 |
| RMSE | 38.15 | 41.23 | 43.08 | |
| MAPE | 7.14% | 8.26% | 8.77% | |
| CEEMDAN-VMD-CNN | MAE | 5.10 | 5.72 | 6.27 |
| RMSE | 36.12 | 39.43 | 41.87 | |
| MAPE | 6.17% | 7.25% | 8.06% | |
| CEEMDAN-VMD-Transformer | MAE | 4.58 | 5.47 | 6.02 |
| RMSE | 34.83 | 37.15 | 40.14 | |
| MAPE | 5.78% | 7.01% | 7.58% | |
| CEEMDAN-VMD-CNN–Transformer | MAE | 4.25 | 5.06 | 5.74 |
| RMSE | 33.20 | 35.12 | 38.30 | |
| MAPE | 5.33% | 6.14% | 6.85% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bing, Q.; Zhao, P.; Ren, C.; Wang, X.; Zhao, Y. Short-Term Traffic Flow Forecasting Method Based on Secondary Decomposition and Conventional Neural Network–Transformer. Sustainability 2024, 16, 4567. https://doi.org/10.3390/su16114567
Bing Q, Zhao P, Ren C, Wang X, Zhao Y. Short-Term Traffic Flow Forecasting Method Based on Secondary Decomposition and Conventional Neural Network–Transformer. Sustainability. 2024; 16(11):4567. https://doi.org/10.3390/su16114567
Chicago/Turabian StyleBing, Qichun, Panpan Zhao, Canzheng Ren, Xueqian Wang, and Yiming Zhao. 2024. "Short-Term Traffic Flow Forecasting Method Based on Secondary Decomposition and Conventional Neural Network–Transformer" Sustainability 16, no. 11: 4567. https://doi.org/10.3390/su16114567
APA StyleBing, Q., Zhao, P., Ren, C., Wang, X., & Zhao, Y. (2024). Short-Term Traffic Flow Forecasting Method Based on Secondary Decomposition and Conventional Neural Network–Transformer. Sustainability, 16(11), 4567. https://doi.org/10.3390/su16114567