
Improving Order-Picking Performance in E-Commerce Warehouses through Entropy-Based Hierarchical Scattering


Abstract
:1. Introduction
Significance of This Research
2. Relevant Literature on Scattered Storage
2.1. Overview of the Existing Scattering Measures
2.1.1. Explosion Ratio (ER) [14]
2.1.2. Warehouse Heterogeneity (β) [26]
2.1.3. Entropy of Stock (Ey) [22]
2.2. Research Gaps Addressed in This Study
- (i)
- The explosion ratio (ER) was proposed by Onal et al. [14].
- (ii)
- Warehouse heterogeneity (β), proposed by Weidinger [26], measures the scattering of stock based on the number of clusters of contiguous locations into which the inventory of each SKU is split.
- (iii)
- Pawar et al. [22] proposed an entropy-based measure (Ey) for the scattering of stock.
3. A New Approach for the Scattering of Stock in a Warehouse
3.1. Concept of Hierarchical Scattering
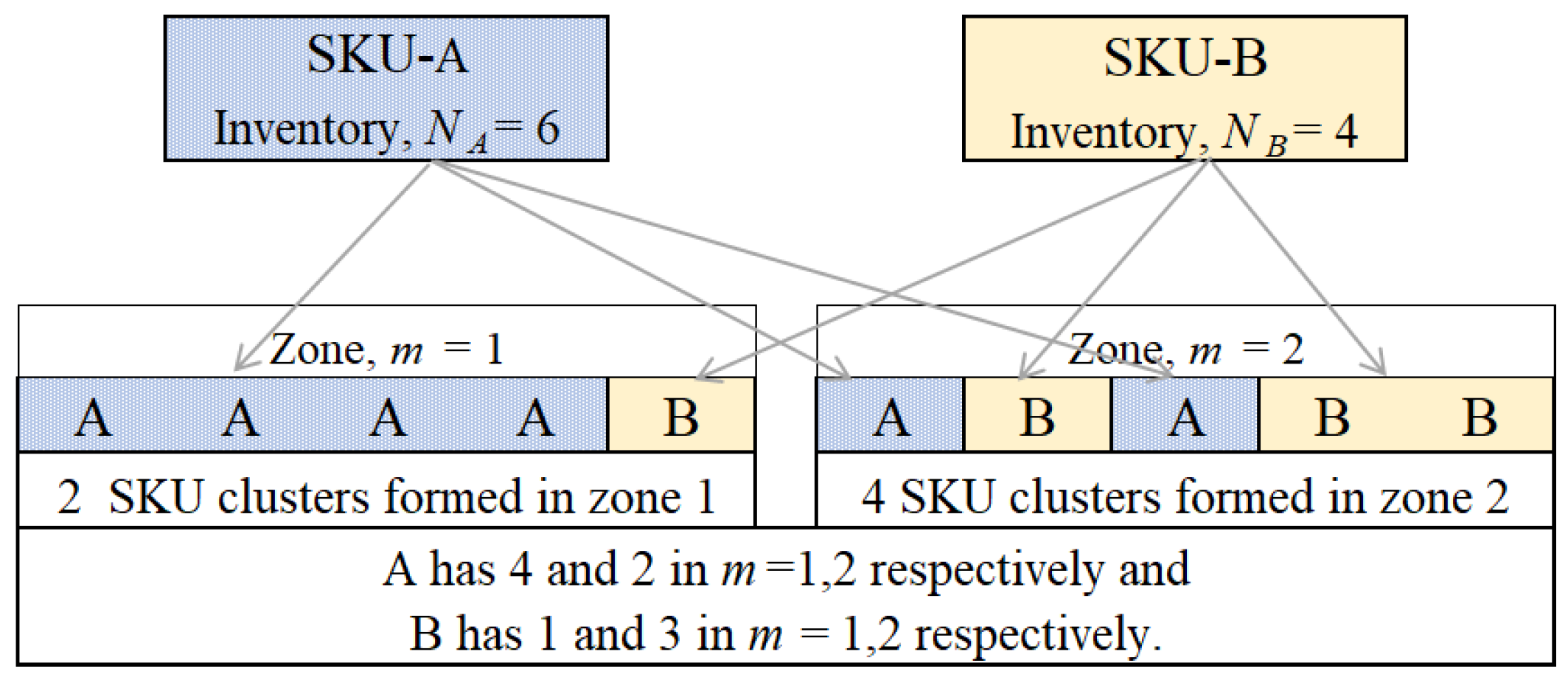
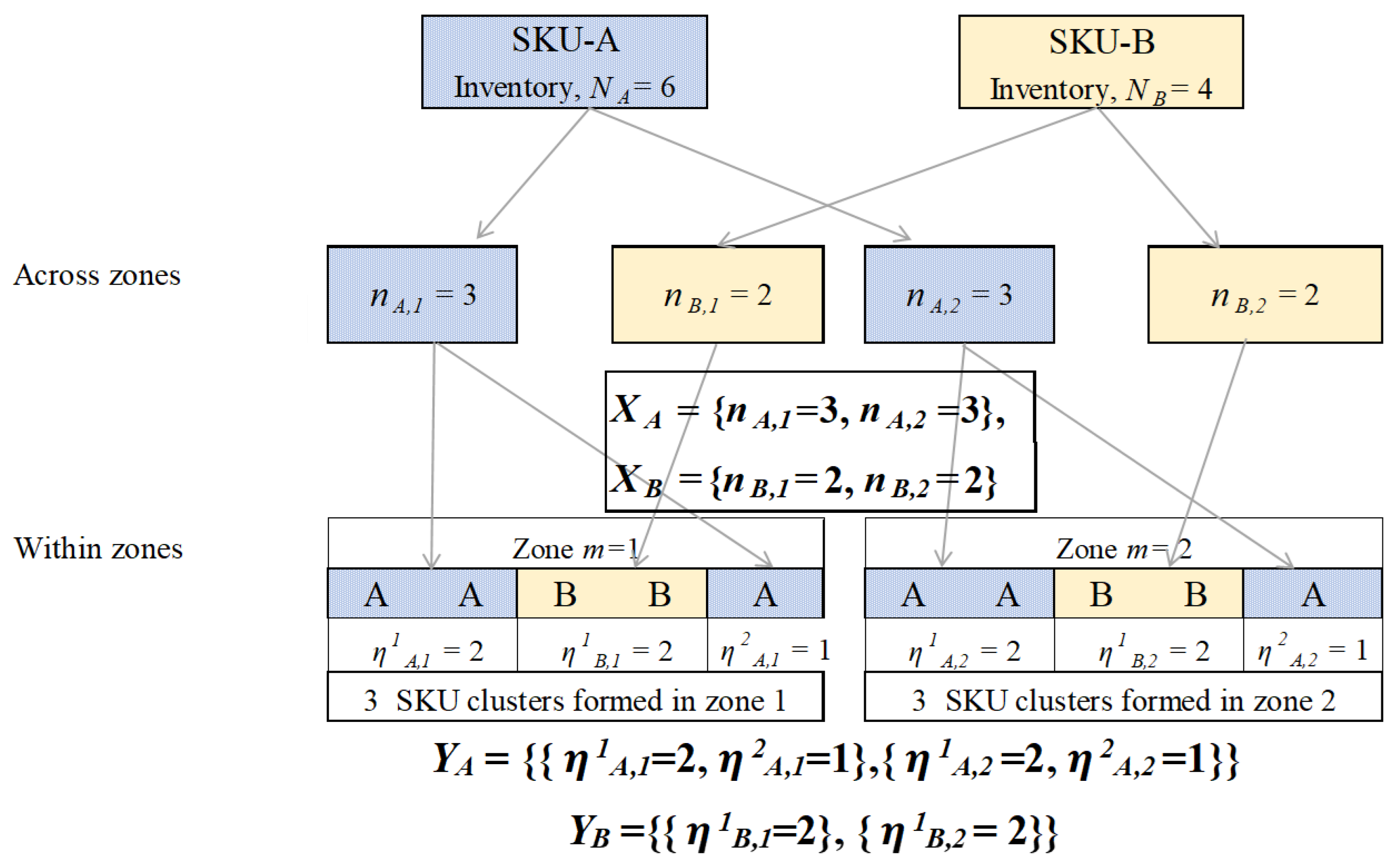
3.1.1. Across-Zone Scattering of Stock
3.1.2. Within-Zone Scattering of Stock
3.2. An Illustration of Hierarchical Scattering
3.3. Limitations of Existing Measures in Capturing Both within- and across-Zone Scattering
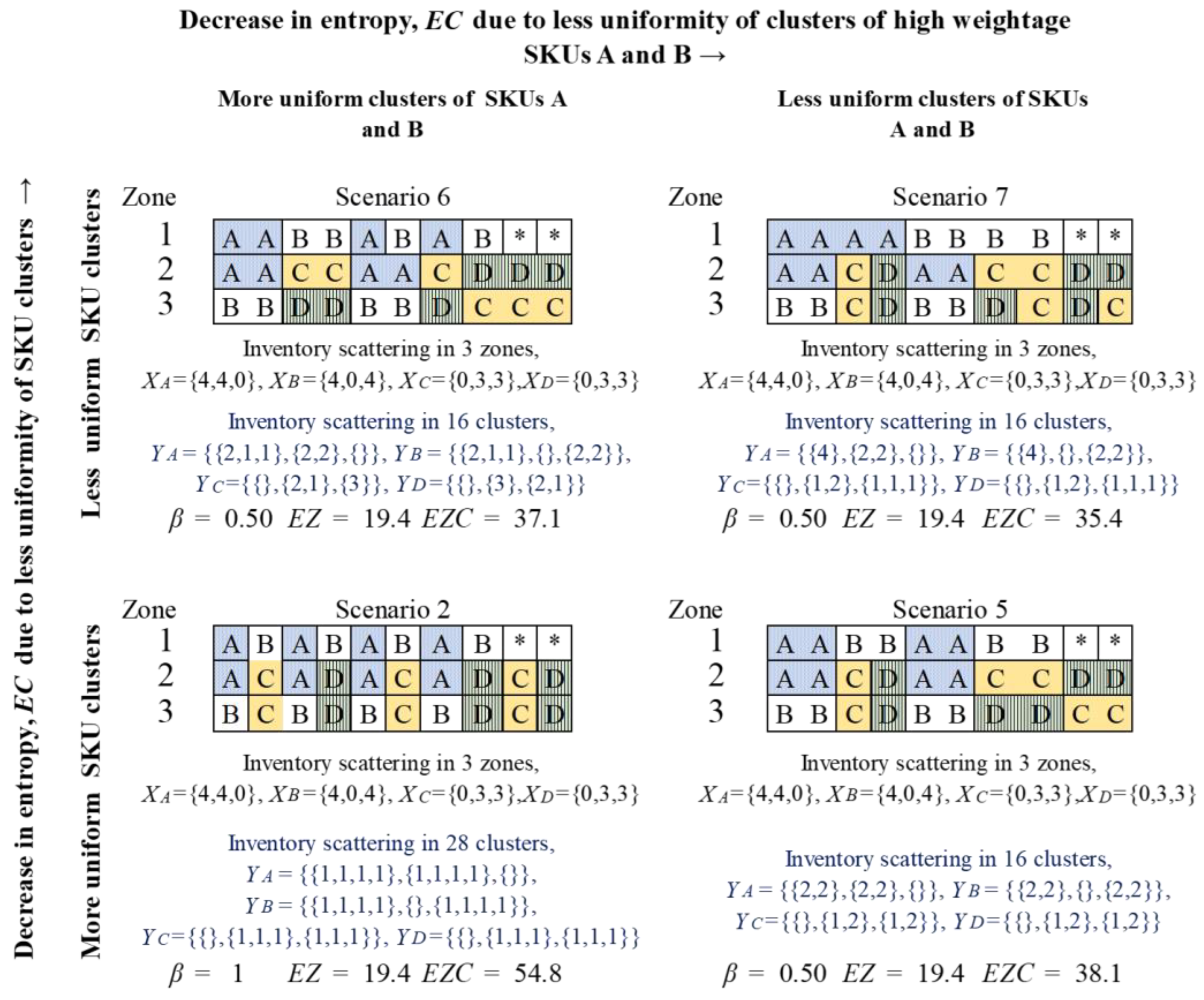
3.4. Benefits of Hierarchical Approach towards Scattering
3.4.1. Uniformity of Scattering of SKU Inventory across Zones
3.4.2. Uniformity in Size of Clusters for Each SKU within Zones
3.4.3. Total Number of Clusters for Each SKU
4. Developing an Entropy Measure for Hierarchical Scattering and Scattered Storage Policy
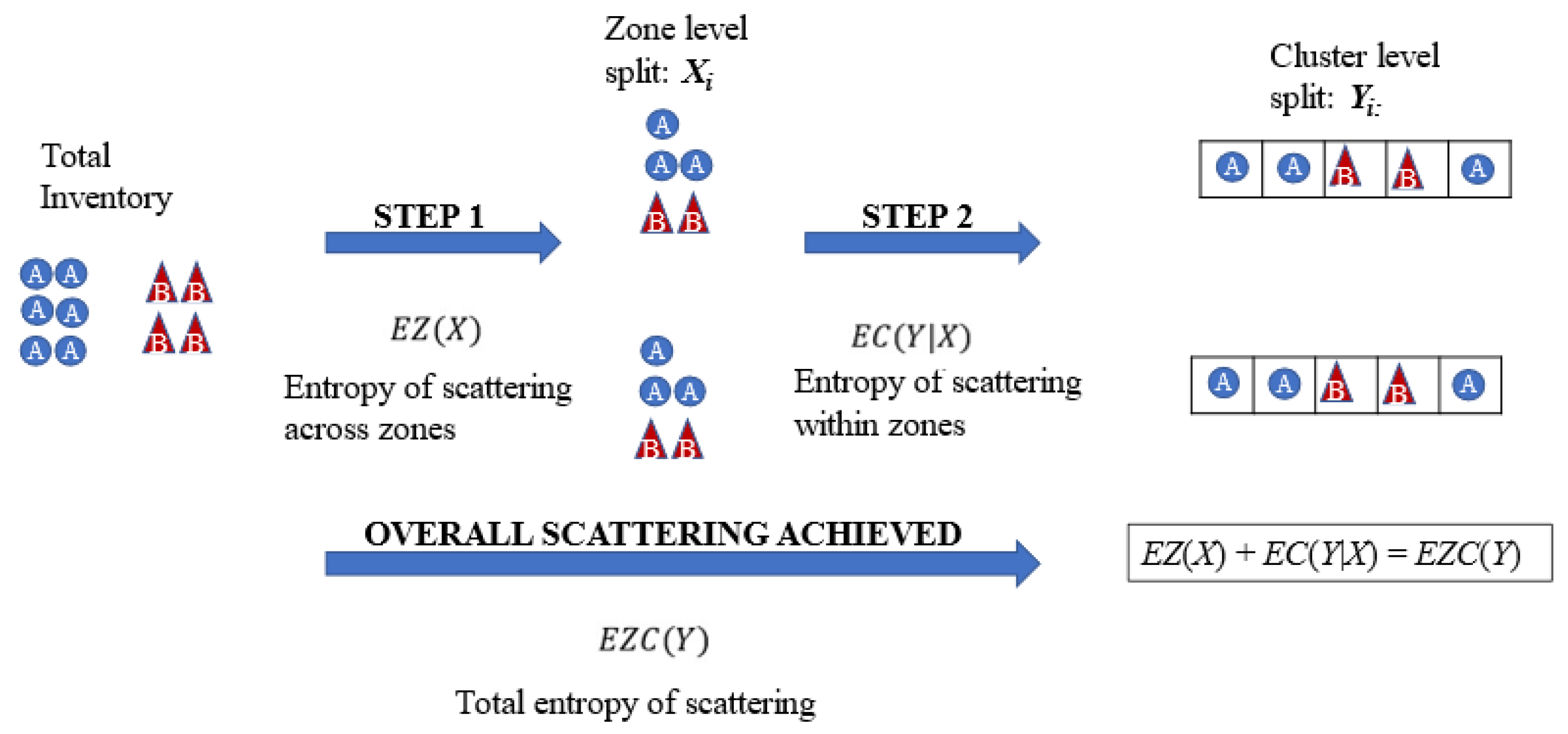
4.1. Entropy of Scattering across Zones: EZ
4.2. Entropy of Scattering within Zones: EC
4.3. Total Entropy of Scattering across All Clusters in All Zones: EZC
4.4. Some Properties for EZ, EC, and EZC
4.5. Features of the Proposed Entropy Measures in Relation to the Existing Measures
5. Entropy-Based Storage Location Assignment (ESLAP)
5.1. Proposed Heuristic for Scattered Storage Assignment Policy (SSP)
5.2. Comparison of the Heuristic with Genetic Algorithm Meta Heuristic
6. Simulation Study
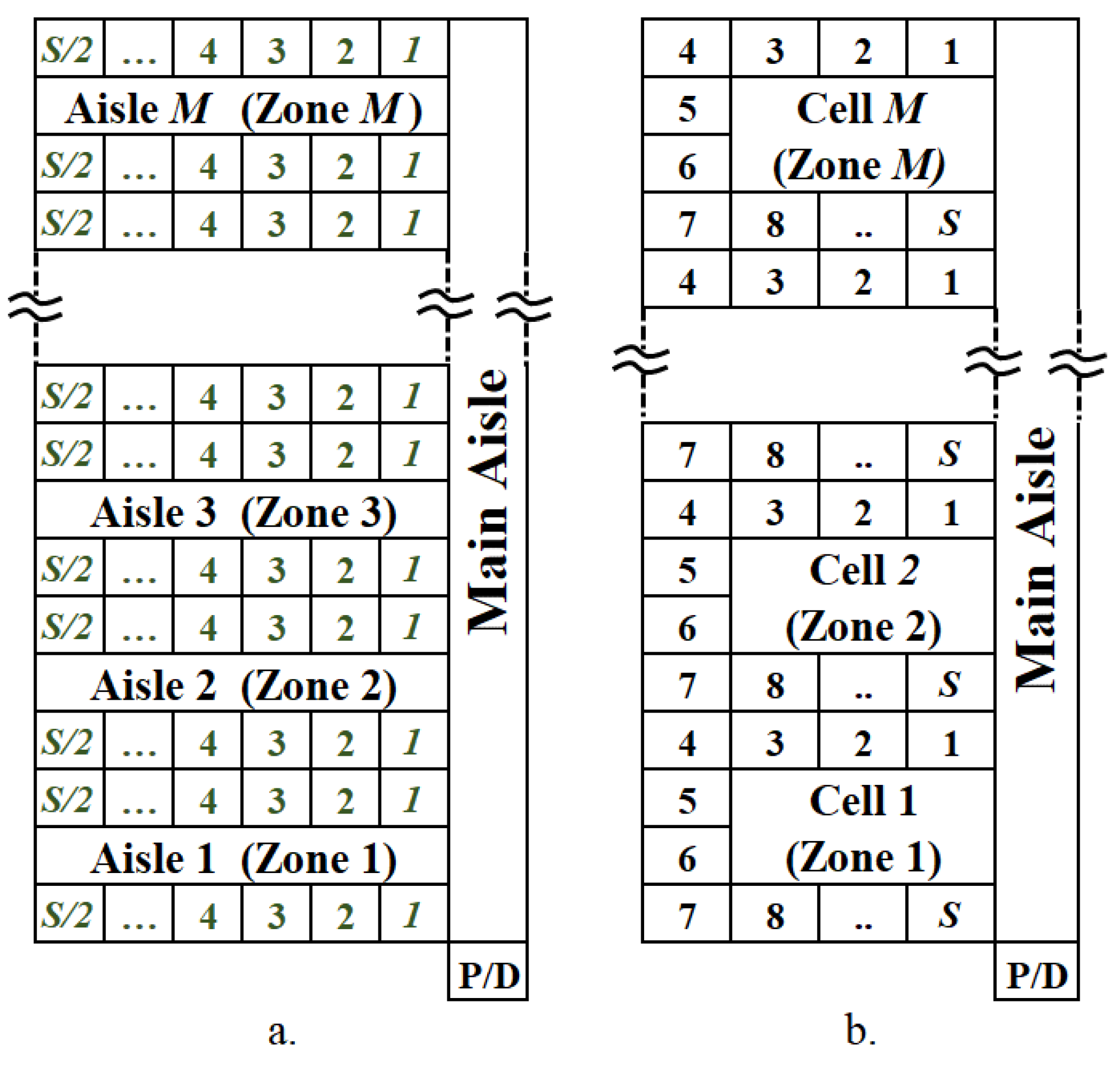
6.1. Warehouse Setup
6.2. Benchmark Storage Assignment Policy and Order-Picking Heuristic
6.2.1. Closest Open Location Assignment (COL) Policy
- Step 1: List the SKUs present in the incoming stock in the nonincreasing order of the SKU-level stock norms. Consider the first SKU for storage assignment.
- Step 2: Select the aisle that is closest to the pickup/drop location and has one or more empty locations.
- Step 3: In the selected aisle, assign the stock of the SKU under consideration to the empty locations in ascending order of their distance from the main aisle. If the selected aisle becomes filled, select the next closest aisle to the pickup/drop location with one or more empty locations.
- Step 4: If all stock of the SKU under consideration is assigned to storage locations, move to the next SKU in the list until all the incoming stock is assigned.
6.2.2. Order-Picking Heuristic
- Step 1: For each aisle, calculate the number of items from the cart that are available in the aisle for picking. Select the aisle with the availability of the maximum number of available items. In case of a tie, select the aisle closest to the pickup/drop location.
- Step 2: For each item available in the selected aisle, select the pick location containing the item closest to the main aisle.
- Step 3: Remove the items found in the aisle selected in Step 2 from the pending items of the cart. If the cart has any items where the pick location has not been identified, proceed to Step 1.
- Step 4: Create the picking route for the worker, starting and ending at the pickup/drop location and visiting each aisle with pick locations only once.
6.3. Different Simulated Warehouse Operating Conditions
6.4. Simulation Steps
- Start with a filled warehouse with all 900 locations occupied with an inventory of I SKUs as per their inventory norms. Obtain the initial stock arrangement by using SSP(Q = 1) on an empty warehouse. Use the same initial stock arrangement for all simulation runs.
- Measure the entropy of the stock arrangement. Complete the order picking for the day’s picking workload (W). Measure the order-picking travel distance.
- On the next day, replenish the warehouse to the stock norms using the specified storage assignment policy, measure the entropy of stock arrangement, and proceed with order picking. Measure the order-picking travel distance.
- Repeat step 3 for 150 days. Report the data of the last 100 days of simulation to remove the effect of the initial transient phase.
6.5. Performance Measures and Parameters
7. Results
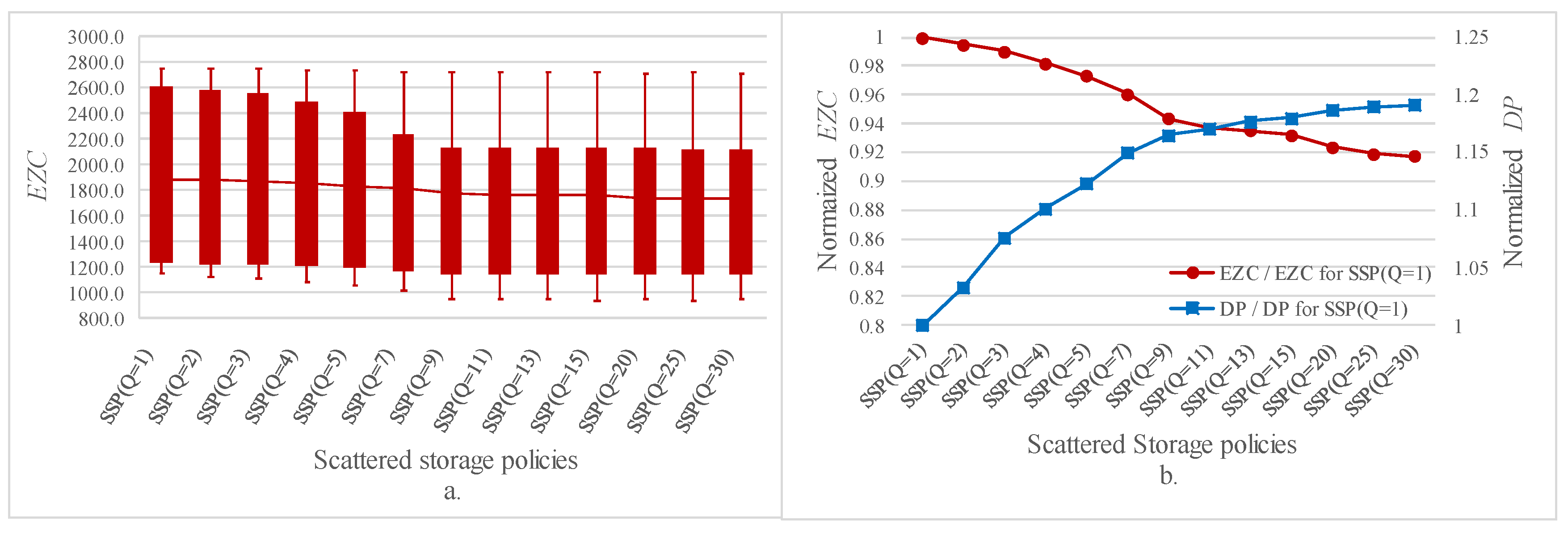
7.1. Variation in the Total Entropy (EZC) with Different Levels of Scattering
7.2. Variation in Picking Performance with Different Levels of Scattering
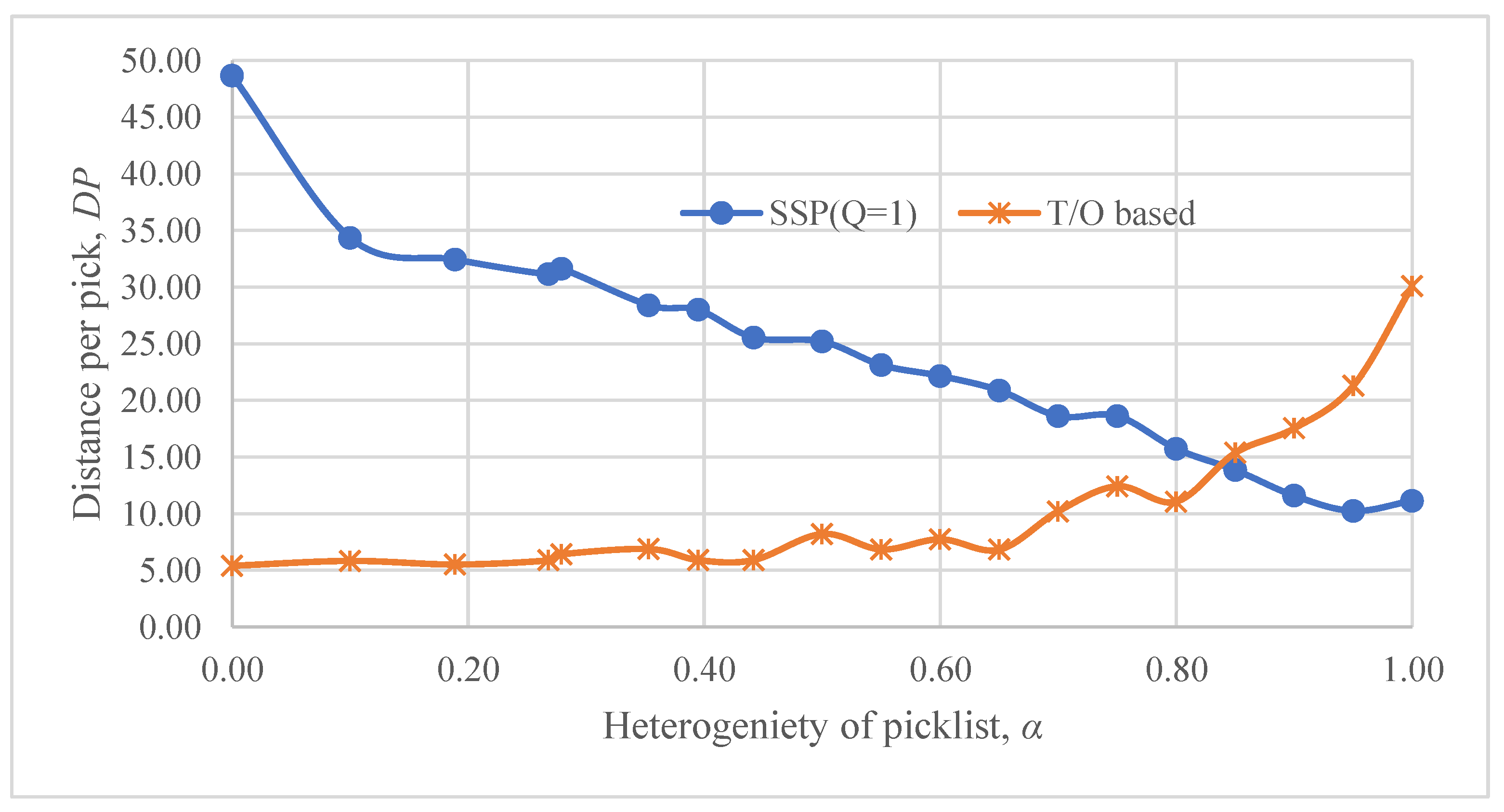
7.3. Sensitivity of Pick Distance to the Warehouse Operating Parameters
8. Discussion and Managerial Implications
Impact of Picklist Diversity on the Performance of Various SSPs
9. Conclusions
9.1. Theoretical Implications of This Study
9.2. Important Implications of Results
9.3. Future Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Global E-Commerce Share of Retail Sales 2027 | Statista. Available online: https://www.statista.com/statistics/534123/e-commerce-share-of-retail-sales-worldwide/ (accessed on 2 April 2024).
- Boysen, N.; Stephan, K.; Weidinger, F. Manual Order Consolidation with Put Walls: The Batched Order Bin Sequencing Problem. EURO J. Transp. Logist. 2019, 8, 169–193. [Google Scholar] [CrossRef]
- Boysen, N.; de Koster, R.; Weidinger, F. Warehousing in the E-Commerce Era: A Survey. Eur. J. Oper. Res. 2019, 277, 396–411. [Google Scholar] [CrossRef]
- de Koster, R.; Le-Duc, T.; Roodbergen, K.J. Design and Control of Warehouse Order Picking: A Literature Review. Eur. J. Oper. Res. 2007, 182, 481–501. [Google Scholar] [CrossRef]
- Schneider, E.; Copsey, S.; Irastorza, X. OSH [Occupational Safety and Health] in Figures: Work-Related Musculoskeletal Disorders in the EU-Facts and Figures; Office for Official Publications of the European Communities: Luxembourg, 2010. [Google Scholar]
- Kadefors, R.; Forsman, M. Ergonomic Evaluation of Complex Work: A Participative Approach Employing Video–Computer Interaction, Exemplified in a Study of Order Picking. Int. J. Ind. Ergon. 2000, 25, 435–445. [Google Scholar] [CrossRef]
- Lavender, S.A.; Marras, W.S.; Ferguson, S.A.; Splittstoesser, R.E.; Yang, G. Developing Physical Exposure-Based Back Injury Risk Models Applicable to Manual Handling Jobs in Distribution Centers. J. Occup. Environ. Hyg. 2012, 9, 450–459. [Google Scholar] [CrossRef] [PubMed]
- Hamberg-van Reenen, H.H.; van der Beek, A.J.; Blatter, B.; van der Grinten, M.P.; van Mechelen, W.; Bongers, P.M. Does Musculoskeletal Discomfort at Work Predict Future Musculoskeletal Pain? Ergonomics 2008, 51, 637–648. [Google Scholar] [CrossRef] [PubMed]
- Gutelius, B.; Pinto, S. Pain Points: Data on Work Intensity, Monitoring, and Health at Amazon Warehouses; Center for Urban Economic Development, University of Illinois Chicago: Chicago, IL, USA, 2023. [Google Scholar] [CrossRef]
- Primed for Pain: Amazon’s Epidemic of Workplace Injuries. Available online: https://thesoc.org/amazon-primed-for-pain/ (accessed on 6 April 2024).
- Gray, A.E.; Karmarkar, U.S.; Seidmann, A. Design and Operation of an Order-Consolidation Warehouse: Models and Application. Eur. J. Oper. Res. 1992, 58, 14–36. [Google Scholar] [CrossRef]
- Tompkins, J.; White, J.; Bozer, Y.A.; Frazelle, E.H.; Tanchoco, J.; Trevino, J. Facilities Planning—4th Edition by J.A. Tompkins, J.A. White, Y.A. Bozer and J.M.A. Tanchoco. Int. J. Prod. Res. 1996, 49, 7519–7520. [Google Scholar] [CrossRef]
- van Gils, T.; Ramaekers, K.; Caris, A.; de Koster, R.B.M. Designing Efficient Order Picking Systems by Combining Planning Problems: State-of-the-Art Classification and Review. Eur. J. Oper. Res. 2018, 267, 1–15. [Google Scholar] [CrossRef]
- Onal, S.; Zhang, J.; Das, S. Modelling and Performance Evaluation of Explosive Storage Policies in Internet Fulfilment Warehouses. Int. J. Prod. Res. 2017, 55, 5902–5915. [Google Scholar] [CrossRef]
- Weidinger, F.; Boysen, N. Scattered Storage: How to Distribute Stock Keeping Units All around a Mixed-Shelves Warehouse. Transp. Sci. 2018, 52, 1412–1427. [Google Scholar] [CrossRef]
- Reyes, J.J.R.; Solano-Charris, E.L.; Montoya-Torres, J.R. The Storage Location Assignment Problem: A Literature Review. Int. J. Ind. Eng. Comput. 2019, 10, 199–224. [Google Scholar] [CrossRef]
- Bahrami, B.; Piri, H.; Aghezzaf, E.H. Class-Based Storage Location Assignment: An Overview of the Literature. In Proceedings of the ICINCO 2019—Proceedings of the 16th International Conference on Informatics in Control, Automation and Robotics, Prague, Czech Republic, 29–31 July 2019; Volume 1, pp. 390–397. [Google Scholar] [CrossRef]
- Gu, J.; Goetschalckx, M.; McGinnis, L.F. Research on Warehouse Design and Performance Evaluation: A Comprehensive Review. Eur. J. Oper. Res. 2010, 203, 539–549. [Google Scholar] [CrossRef]
- Cormier, G.; Gunn, E.A. A Review of Warehouse Models. Eur. J. Oper. Res. 1992, 58, 3–13. [Google Scholar] [CrossRef]
- van den Berg, J.P. A Literature Survey on Planning and Control of Warehousing Systems. IIE Trans. 1999, 31, 751–762. [Google Scholar] [CrossRef]
- Zhang, J.; Onal, S.; Das, S. The Dynamic Stocking Location Problem—Dispersing Inventory in Fulfillment Warehouses with Explosive Storage. Int. J. Prod. Econ. 2020, 224, 107550. [Google Scholar] [CrossRef]
- Pawar, N.S.; Rao, S.S.; Adil, G.K. A New Measure for Scattering of Stocks in E-Commerce Warehouses. IFAC-PapersOnLine 2022, 55, 1357–1362. [Google Scholar] [CrossRef]
- Pang, K.W.; Chan, H.L. Data Mining-Based Algorithm for Storage Location Assignment in a Randomised Warehouse. Int. J. Prod. Res. 2017, 55, 4035–4052. [Google Scholar] [CrossRef]
- Jiang, W.; Liu, J.; Dong, Y.; Wang, L. Assignment of Duplicate Storage Locations in Distribution Centres to Minimise Walking Distance in Order Picking. Int. J. Prod. Res. 2020, 59, 4457–4471. [Google Scholar] [CrossRef]
- Krishnamoorthy, S.; Roy, D. An Utility-Based Storage Assignment Strategy for e-Commerce Warehouse Management. In Proceedings of the IEEE International Conference on Data Mining Workshops, ICDMW 2019, Beijing, China, 8–11 November 2019; pp. 997–1004. [Google Scholar] [CrossRef]
- Weidinger, F. Picker Routing in Rectangular Mixed Shelves Warehouses. Comput. Oper. Res. 2018, 95, 139–150. [Google Scholar] [CrossRef]
- Erlander, S. Accessibility, Entropy and the Distribution and Assignment of Traffic. Transp. Res. 1977, 11, 149–153. [Google Scholar] [CrossRef]
- Hackbart, M.M.; Anderson, D.A. On Measuring Economic Diversification. Land. Econ. 1975, 51, 374. [Google Scholar] [CrossRef]
- Conforte, A.J.; Tuszynski, J.A.; da Silva, F.A.B.; Carels, N. Signaling Complexity Measured by Shannon Entropy and Its Application in Personalized Medicine. Front. Genet. 2019, 10, 930. [Google Scholar] [CrossRef] [PubMed]
- Martin, M.; Rey, J. On the Role of Shannon’s Entropy as a Measure of Heterogeneity. Geoderma 1998, 83, 206–214. [Google Scholar] [CrossRef]
- Shannon, C.E.; Weaver, W. The Mathematical Theory of Communication; University of Illinois Press: Urbana, IL, USA, 1949. [Google Scholar]
- Guiasu, S.; Shenitzer, A. The Principle of Maximum Entropy. Math. Intell. 1985, 7, 42–48. [Google Scholar] [CrossRef]
- Trindade, M.A.M.; Sousa, P.S.A.; Moreira, M.R.A. Ramping up a Heuristic Procedure for Storage Location Assignment Problem with Precedence Constraints. Flex. Serv. Manuf. J. 2022, 34, 646–669. [Google Scholar] [CrossRef] [PubMed]
- Frazelle, E.A.; Sharp, G.P. Correlated Assignment Strategy Can Improve Any Order-Picking Operation. Ind. Eng. 1989, 21, 33–37. [Google Scholar]
- Petersen, C.G. An Evaluation of Order Picking Routeing Policies. Int. J. Oper. Prod. Manag. 1997, 17, 1098–1111. [Google Scholar] [CrossRef]
- Roodbergen, K.J.; De Koster, R. Routing Methods for Warehouses with Multiple Cross Aisles. Int. J. Prod. Res. 2001, 39, 1865–1883. [Google Scholar] [CrossRef]
- Chen, C.; Gong, Y.; de Koster, R.B.M.; van Nunen, J.A.E.E. A Flexible Evaluative Framework for Order Picking Systems. Prod. Oper. Manag. 2010, 19, 70–82. [Google Scholar] [CrossRef]
- Fang, S.C.; Rajasekera, J.R.; Tsao, H.S.J. Entropy Optimization and Mathematical Programming; Springer: Boston, MA, USA, 1997. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| REFW | Retail e-commerce fulfilment warehouse |
| SKU | Stock keeping unit |
| MSD | Musculoskeletal disorders |
| ER | Explosion ratio |
| ESLAP | Entropy-based storage location assignment problem |
| SSP | Scattered storage policy |
| SSP(Q) | Scattered storage policy with lot size Q |
| NLIP | Nonlinear integer program |
| GA | Genetic algorithm |
| COL | Closest open location |
| T/O | Product turnover |
| Measure | Aspects of Scattering Considered in the Measure (“√” Indicates Considered, and “-” Indicates Not Considered) | ||||
|---|---|---|---|---|---|
| Nature of Clusters Formed | Geographical Spread of Warehouse Inventory | ||||
| Number of Clusters | Spread of Clusters across Many Different SKUs | Uniformity in Cluster Sizes | Spreading Inventory across Several Zones in the Warehouse | Uniformity of Spread of Inventory across Zones | |
| Heterogeneity (β) [26] | √ | - | - | - | - |
| Explosion ratio (ER) [14] | √ | - | - | - | - |
| Entropy (Ey) [22] | - | - | - | √ | √ |
| Measure proposed in this study | √ | √ | √ | √ | √ |
| SSP(Q = 1) | Genetic Algorithm | |||
|---|---|---|---|---|
| Warehouse Size (# of Storage Locations) | Initial Warehouse Occupancy | Entropy * | Entropy (% Improvement (+ve) over SSP(Q = 1)) | (Computational Time in Seconds, # of Generations) |
| Size 1 (50) | 25% | 83.3 | 85.0, (+2.0%) ** | (49, 51) |
| 50% | 85.0 | 85.2, (+0.3%) | (56, 51) | |
| 75% | 87.5 | 87.5, (+0.0%) | (67, 52) | |
| 100% | 87.8 | 87.8, (+0.0%) | (82, 53) | |
| Size 2 (300) | 25% | 1025.9 | 1029.9, (+0.4%) | (252, 81) |
| 50% | 1044.3 | 1044.8, (+0.1%) | (590, 122) | |
| 75% | 1055.5 | 1057.5, (+0.2%) | (1216, 153) | |
| 100% | 1051.1 | 1058.0, (+0.7%) | (1500, 127) | |
| Size 3 (900) | 25% | 4052.4 | 4055.5, (+0.1%) | (1714, 144) |
| 50% | 4116.7 | 4086.2, (−0.7%) | (1800, 52) | |
| 75% | 4141.0 | 4072.9, (−1.6%) | (1800, 19) | |
| 100% | 4136.1 | 4049.5, (−2.1%) | (1800, 10) | |
| Warehouse Parameter | Values/Settings |
|---|---|
| SKU density (Hs %) | 5.56, 11.11, 22.22, 33.33 |
| Number of locations per aisle (S) | 10, 25, 50, 75, 100 |
| Workload (number of daily orders) (W) | 300, 500 |
| Picker cart size (K) | 5, 10, 15, 20, 25 |
| Cart Size | Workload | SKU Density | |||
|---|---|---|---|---|---|
| Reference Case, Hs = 5.56% | Hs = 11.11% | Hs = 22.22% | Hs = 33.33% | ||
| DP (Hs = 5.56%) | % Increase in DP over DP (Hs = 5.56%) | ||||
| K = 5 | W = 300 | 38.2 | 20% | 48% | 64% |
| W = 500 | 41.9 | 19% | 42% | 55% | |
| K = 10 | W = 300 | 24.7 | 26% | 59% | 80% |
| W = 500 | 27.3 | 23% | 52% | 69% | |
| K = 15 | W = 300 | 19.1 | 28% | 65% | 90% |
| W = 500 | 21.5 | 25% | 56% | 76% | |
| K = 25 | W = 300 | 16.0 | 30% | 69% | 95% |
| W = 500 | 17.8 | 27% | 61% | 81% | |
| K = 25 | W = 300 | 14.0 | 30% | 71% | 98% |
| W = 500 | 15.5 | 28% | 63% | 85% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pawar, N.S.; Rao, S.S.; Adil, G.K. Improving Order-Picking Performance in E-Commerce Warehouses through Entropy-Based Hierarchical Scattering. Sustainability 2024, 16, 5953. https://doi.org/10.3390/su16145953
Pawar NS, Rao SS, Adil GK. Improving Order-Picking Performance in E-Commerce Warehouses through Entropy-Based Hierarchical Scattering. Sustainability. 2024; 16(14):5953. https://doi.org/10.3390/su16145953
Chicago/Turabian StylePawar, Nilendra Singh, Subir S. Rao, and Gajendra K. Adil. 2024. "Improving Order-Picking Performance in E-Commerce Warehouses through Entropy-Based Hierarchical Scattering" Sustainability 16, no. 14: 5953. https://doi.org/10.3390/su16145953
APA StylePawar, N. S., Rao, S. S., & Adil, G. K. (2024). Improving Order-Picking Performance in E-Commerce Warehouses through Entropy-Based Hierarchical Scattering. Sustainability, 16(14), 5953. https://doi.org/10.3390/su16145953