Abstract
As the global emphasis on sustainable resource management intensifies, the need for efficient recycling automation becomes critical. This paper addresses the integration of blockchain technology and federated learning to enhance the automation and efficiency of recycling processes. The authors propose a novel digital product passport system that utilizes blockchain for secure data sharing and federated learning for continuous improvement of recycling automation models. Manufacturers develop baseline models using synthetic data, which are then refined by recycling centers using real-world data. The updated models are aggregated through a federated averaging algorithm. Our experimental results demonstrate that the integrated system not only enhances the accuracy and efficiency of recycling processes but also ensures the privacy and security of data across different stakeholders. The performance of the federated models shows significant improvement over traditional recycling methods. This paper provides a scalable and secure framework that supports the circular economy by enabling enhanced collaboration between manufacturers and recycling centers. The blockchain-based digital product passport system ensures data integrity and transparency, contributing to more sustainable recycling practices.
1. Introduction
As the need for circular economy and sustainable product management grows, decision-making related to reuse, recycling, and disposal throughout the product lifecycle has emerged as a critical challenge [1,2,3]. One of the tools gaining attention to promote the circular economy is the digital product passport (DPP) [4,5]. The DPP is a technology that digitizes and provides information on various products such as electronics, textiles, and furniture. Currently, it is implemented in the form of printed QR codes, allowing access to product information [6]. A DPP includes sustainability-related information such as product composition, repairability, and recyclability, enabling resource tracking and management [7]. Scanning the QR code provides access to details about the material, production history, and disposal methods of the product, thereby enhancing sustainability and recyclability.
Research on DPPs is actively being conducted across various fields. Heeß [8] designed a DPP to support the low-carbon hydrogen market, proposing a solution to ensure data reliability and transparency in the complex hydrogen supply chain while promoting sustainability and decarbonization. Mihai Hulea [9] proposed a DPP that integrates Hyperledger Fabric and decentralized identifier technology to enable tracking throughout the entire product lifecycle. Similarly, Koppelaar [10] proposed a DPP-based circular supply management system to promote the recycling and reuse of critical raw materials, exploring ways to support a sustainable circular economy through this system. While these papers demonstrate the potential applications of DPPs, they are still limited in that manufacturers merely provide information unilaterally, failing to effectively contribute to the circular economy. To address the limitations of existing studies, this paper proposes a method to bridge the information gap between manufacturers and recycling facilities by integrating federated learning (FL) into the DPP. This approach enables the effective sharing of information about the state and components of discarded products and supports the automation of recycling processes.
Currently, most recycling centers manually sort product components and waste, leading to issues such as high labor costs, time consumption, and limited recycling efficiency [11,12]. Some papers have attempted to automate sorting tasks through vision-based learning [13,14,15], but the lack of data collaboration between manufacturers and recycling centers limits model performance. Specifically, manufacturers lack information on the specific conditions of discarded products, while recycling centers face an information gap regarding the components and materials of discarded products.
To address these issues, this paper aims to explore two key research questions:
- How does integrating FL contribute to improving the performance of recycling automation models?
- What impact does a blockchain and FL-integrated DPP system have on fostering a circular economy?
This paper proposes a sustainable business model that supports recycling automation by enabling collaboration between manufacturers and recycling centers through a DPP platform. Manufacturers initially develop a vision model for discarded products using synthetic data, setting this as the baseline model. However, models developed solely with synthetic data face accuracy limitations. Therefore, each recycling center is designated as a client in an FL system to train the baseline model with real-world data. The weights of the models trained by each client are then transmitted to the manufacturer via the DPP platform, where weights are integrated to retrain the global model. The retrained global model is shared back with the recycling centers through the DPP platform, continuously improving model performance.
The contributions of this paper are as follows:
- Proposing a blockchain-based business model utilizing the DPP platform;
- Developing an FL-based automated recycling system;
- Introducing a novel system to support recycling and the circular economy.
The key benefits of this paper lie in maximizing recycling efficiency and cost savings through data collaboration between manufacturers and recycling facilities. Additionally, it establishes a technological foundation to promote the circular economy on a global scale and contributes to enhancing environmental sustainability.
This paper is structured into six sections. Section 2 reviews the literature on methodologies relevant to this paper. Section 3 discusses the proposed methodology, including the integration of federated learning into the DPP platform and the approach for storing the models. Section 4 evaluates the performance of the proposed model through prototype implementation and the analysis of the federated learning results. Finally, Section 5 discusses the implications, and Section 6 discusses limitations of the research and suggests directions for future work.
2. Related Work
2.1. Synthetic Data Generation
Deep learning in supervised learning typically requires large amounts of data. However, annotating real-world data is a time-consuming and costly process [16]. As an alternative solution, the use of synthetic data has gained traction. The utilization of synthetic data offers the significant advantage of saving time and cost [17]. However, synthetic data are generally imperfect, which can impact downstream machine learning tasks such as training predictive models [18]. Synthetic data often fail to fully capture real-world scenarios, and models trained solely on synthetic data may perform poorly on real-world data [19]. Therefore, there is a need for training strategies that can capitalize on the efficiency of synthetic data while addressing limitations by incorporating mechanisms to enhance model generalization and performance in real-world applications.
One such approach was proposed by Tremblay [20] who demonstrated that pre-training models on synthetic data to learn basic features and patterns, followed by fine-tuning with real-world data, improves performance. Their finding indicates that neural networks trained using synthetic, domain-randomized data can better generalize when combined with real-world fine-tuning compared to models trained exclusively on real-world data. Similarly, Nowruzi [21] showed that models pre-trained on synthetic data and fine-tuned with real-world data outperformed those trained on a mix of synthetic and real-world data. This suggests that synthetic data can serve as an effective foundation for learning robust representations.
2.2. Federated Learning in Various Industries
FL has emerged as data privacy and security demands have increased, and the amount of data has exploded [22]. Traditional centralized learning methods could lead to data privacy infringement and processing limitations of central servers, and have encountered difficulties in data sharing in healthcare and finance [23]. In this context, [24] introduced the concept of FL to build global models while keeping data locally in a distributed environment.
In essence, FL builds a global model by independently training models on distributed data sources and then aggregating the model updates on a central server. This enables data privacy and network costs to be reduced while keeping sensitive data locally [25]. Wang et al. (2022) proposed a hierarchical FL-based anomaly detection system for IIoT, demonstrating FL’s effectiveness in enhancing data privacy and security. This aligns with our study’s objective of leveraging FL to enable secure collaboration between manufacturers and recycling centers [26].
In this paper, we propose a method to apply the benefits of FL to recycling automation systems, building upon existing applications of FL. Specifically, we draw inspiration from [27], which demonstrated the ability to build effective models while maintaining data privacy across hospitals. Similarly, we suggest that recycling centers can independently train models on their localized, sensitive data and then aggregate these updates into a global model using FL, without sharing the raw data. Given the regional variations and sensitive nature of the data in recycling centers, it is challenging to centralize these data. FL offers a promising solution to maximize model performance while maintaining data privacy.
Additionally, building on [28], where financial institutions jointly trained fraud detection models without sharing customer data, we highlight that FL can also be applied to the recycling industry. This allows for the collaborative training of models without exposing sensitive operational data. By leveraging FL in this way, our approach addresses data management challenges in the recycling industry, contributing to the development of more efficient and effective recycling processes while safeguarding data privacy. We also refer to the FedAvg method presented in [29].
2.3. Distributed Internet
2.3.1. Blockchain Network
Blockchain provides reliability and efficiency in digital systems through features such as decentralization, immutability, transparency, and smart contracts. Smart contracts, which are blockchain-based programs written in code to execute automatically when specific conditions are met, ensure transaction transparency and trust without intermediaries [30]. Casino [31] systematically reviewed the current state of blockchain-based applications, categorizing application areas and discussing future challenges and emphasizing the versatility and potential of this technology. Moreover, Alotaibi [32] demonstrated that smart contracts save time and costs, prevent data tampering, and enhance security and efficiency. Rawat [33] proposed a decentralized framework for recording and tracking carbon emissions using blockchain, enhancing transparency and trust in carbon credit trading while preventing fraud and improving operational efficiency.
There has also been active research into data sharing with blockchain. Nguyen [34] explored blockchain utilization for securely sharing data in a mobile cloud-based electronic health record system, proving its ability to enhance the security and trust of sensitive data.
Building on this security foundation, Aydar [35] proposed a blockchain-based framework for digital identity verification, record authentication, and data sharing. It enables individuals to fully control their identity data and decide their level of data sharing, a core feature for managing data access and usage in a trusted environment.
In the prototype for applying blockchain to recycling systems, similar identity and permission management was implemented to enhance transparency in data access records. Automating functionality execution based on permissions through smart contracts ensured the system’s reliability and efficiency.
Efforts to evolve the web environment using blockchain are also underway. Alabdulwahhab [36] emphasized introducing blockchain-based protocols and Decentralized Application (DApp) to overcome Web 2.0 limitations, suggesting ways to prevent data centralization, protect privacy, and enhance transparency and trust. Similarly, Bharadiya [37] proposed integrating AI with blockchain to strengthen data reliability and security in decentralized environments while providing intelligent web services.
DApp plays a vital role in enhancing user experiences and improving data processing efficiency through blockchain technology. Glomann [38] highlighted that improving DApp usability is key to blockchain adoption, noting that complex interfaces and steep learning curves are significant barriers to technology acceptance. The authors argued for human-centered designs to make DApp more intuitive and user-friendly, enabling users to leverage blockchain features without feeling overwhelmed by technical complexity.
Accordingly, the prototype introduced a DApp to improve user experience and enable secure functionality based on permissions. The DApp design focused on enhancing trust and efficiency through a user-centered approach that leverages the strengths of blockchain technology.
2.3.2. Distributed File System
Peer-to-Peer networks are characterized by a structure where participants share their hardware resources to sustain the network [39]. Building on Krishnan [40]’s argument that such networks offer cost savings and high reliability through direct resource sharing, Alex Murray [41] highlighted the potential of decentralized internet to provide a free and cost-efficient network environment.
Among various decentralized networks, the InterPlanetary File System (IPFS) stands out as a prominent example of a distributed storage architecture. The IPFS assigns unique identifiers to all nodes and uses a distributed hash table to locate data. By generating content identifier (CID) hashes to identify files and ensure deduplication, the IPFS simultaneously provides data integrity and efficiency.
Trautwein [42] conducted a detailed analysis of the IPFS’s design and implementation, demonstrating its potential to become a core technology for data preservation and management in decentralized web environments. Meanwhile, Balduf [43] proposed a methodology for monitoring data requests in distributed storage systems, improving operational and management efficiency. To apply this efficiency to the DPP prototype, this paper implemented a system where each model file is uploaded to the IPFS and accessed using its hash value.
From a security perspective, Agrawal [44] evaluated the combination of the IPFS with blockchain technology, concluding that it offers superior security compared to traditional web-based systems. Similarly, Kumar [45] confirmed that integrating blockchain and the IPFS in the healthcare sector provides enhanced security and privacy compared to centralized systems.
This paper established a DPP system utilizing distributed file system to enhance the integrity and security of model files. This approach not only ensures user data protection but also serves as a case demonstrating the potential for decentralized resource management.
2.3.3. Blockchain Technology Application in Business
Research on blockchain business applications has been actively conducted in various fields. Giovanni [46] analyzed the efficiency of supply chain management by comparing traditional online platforms and blockchain-based platforms. While traditional platforms faced high transaction costs and service provision risks, blockchain was shown to address these issues by enhancing transaction transparency and security.
Choi [47] proposed the construction of a product origin authentication platform using blockchain, coupled with an initial coin offering for project funding. By leveraging blockchain technology to digitize and permanently store authentication information, the paper demonstrated an increase in consumer trust. The authors also theoretically analyzed optimal pricing and authentication efforts related to platform operations. Furthermore, the research identified the conditions necessary for executing an initial coin offering, involving the issuance of tokens to investors for fundraising. Notably, the paper proposed a smart contract-based wholesale price adjustment model and a profit-sharing contract model, which improve inter-firm negotiation structures and maximize economic benefits for all supply chain participants.
In addition, research has explored the utilization of blockchain for promoting a circular economy. Harish [48] suggested a digital asset tokenization mechanism for environmental, social, and governance disclosures using blockchain. By employing smart contract-based tokenization, the mechanism tracks the contributions of data providers and offers reputational rewards based on interactions with users. The paper also utilized a Stackelberg game model to analyze the impact of cost-sharing and technology adoption levels on the benefits of digital asset consumers and providers.
Zhang [49] explored the application of blockchain in mixed carbon trading systems to reduce costs and build trust within the supply chain. Blockchain technology records carbon trading information in immutable ledgers and automates the buying and selling of carbon credits through smart contracts, thereby reducing transaction costs. The paper also proposed a collaborative investment strategy to share the investment burden among supply chain members and optimize blockchain adoption levels and pricing strategies.
Also, the IPFS enables distributed storage and management of data, mitigating the storage capacity issues of blockchain and enhancing the overall scalability of the system [50]. Mahmud stated that the IPFS enables distributed data storage, thereby alleviating blockchain storage capacity issues and enhancing the overall throughput and scalability of the system [51].
These diverse studies demonstrate the potential of blockchain technology to enhance trust, efficiency, and transparency in business environments. Furthermore, blockchain contributes to promoting a circular economy, advancing sustainability, and creating new economic value.
2.4. Summary and Opportunities
The literature review has led to the following conclusions.
- Integration and Security Issues with DPPs: Current implementations of DPPs predominantly rely on simple identifiers like QR codes. This approach limits the integration and security enhancement of product data and exposes it to the risk of manipulation. Additionally, despite the regulatory requirement to implement DPPs for all products by 2030, research in this area remains insufficiently active. Current studies focus on the conceptual development of DPPs, with relatively little research on industrial application and standardization.
- Utilization and Limitations of Synthetic Data: Using synthetic data to train models holds potential for reflecting various environments. This is especially useful for generating diverse scenarios from limited real data, theoretical testing, and initial prototype development. However, relying solely on synthetic data can degrade the practicality and accuracy of models due to differences from real-world conditions. Many studies address this by combining synthetic and real data for model training. This approach enhances the model’s generalizability and performance in actual environments.
- Need for Diverse Environmental Data: Training models with data focused on a single environment can be ineffective for reflecting the complex realities of scenarios like recycling. Therefore, it is necessary to use data collected from various recycling environments to train models. This enables the model to adapt to a broader range of conditions and scenarios, providing flexibility and accuracy when applied in practice.
- Potential of Blockchain for Data Management: Blockchain technology has the potential to ensure data integrity and transparency but is not widely implemented due to high processing costs and complexity. In this paper, we aim to lighten the blockchain network by transmitting data using a distributed file system (DFS) and its hash rather than transferring raw data directly.
To address these issues, this paper proposes a new framework effectively integrating DPPs and FL. We utilize blockchain technology to enhance the security and integration of DPP data and improve the privacy and efficiency of FL, thus enhancing its applicability in real industrial settings. Models trained using FL ensure data privacy as each client independently trains models on local data. Furthermore, by utilizing data from multiple locals to train a global model, the model shows generalized performance without being biased towards specific regions or conditions.
Through this, our goal is to activate the practical application of DPPs and FL and support sustainable industrial development. This research contributes to providing more practical and effective solutions for recycling automation through the integration of digital product passports and federated learning.
3. Method
3.1. Relationship Diagram of Manufacturer and Recycling Center
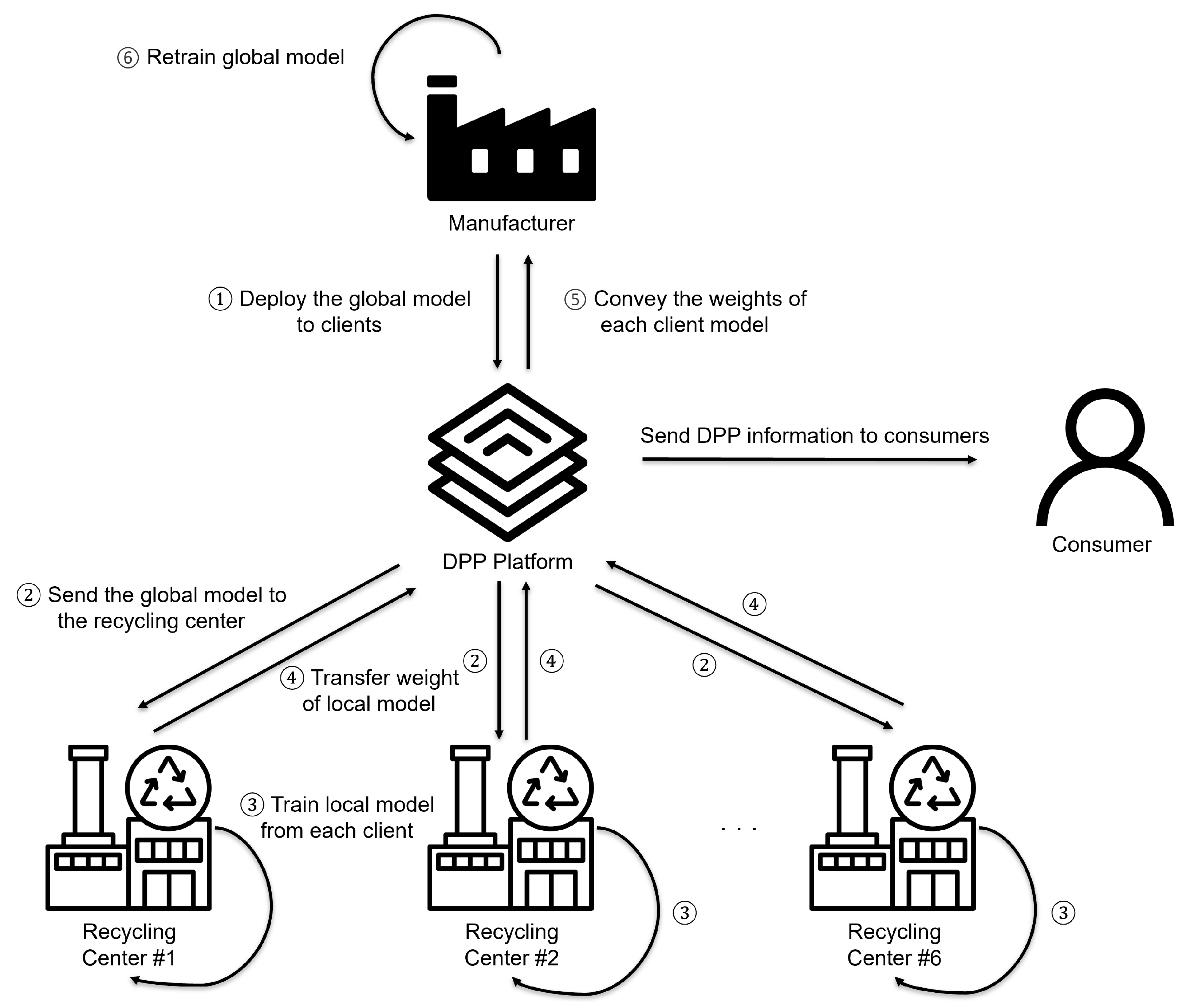
Section 3.1 describes the relationship between manufacturers and recycling centers, illustrated through the system architecture and sequence diagram. Collaboration between manufacturers and recycling centers is essential for efficient recycling automation [52]. Figure 1 represents the overall system architecture.
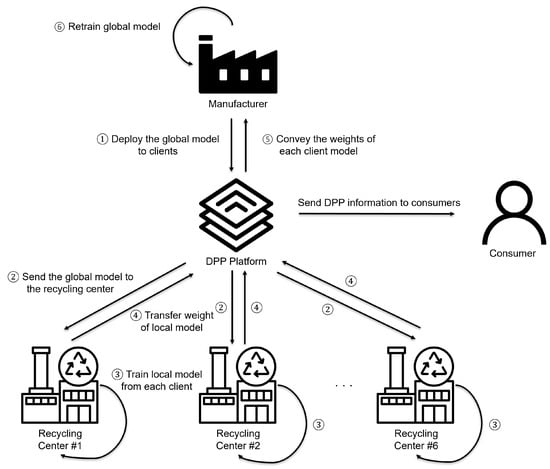
Figure 1.
Architecture of the proposed system: This figure illustrates the overall framework of the proposed system, where the manufacturer deploys the global model to clients, collects updated model weights from recycling centers, and refines the global model through federated learning. The DPP platform facilitates data exchange, enabling recycling centers to train local models while ensuring seamless information transfer to consumers.
The components of the proposed DPP platform in this paper are primarily composed of manufacturers, recycling centers, and the DPP platform itself. The manufacturer inputs the DPP information, produces a pre-trained model based on the synthetic data, and provides the information that can be used in the recycling process. After receiving the baseline model made by the manufacturer through the DPP platform, the recycling center generates real data about the discarded products with pictures of the waste that arrived at the recycling center and trains the model locally. After that, when the client model is sent to the manufacturer again using the DPP platform, the manufacturer updates the global model using the client model weight and redistributes the model again. This iterative process enables the global model to be retrained based on data collected from the local environments of each recycling center, gradually improving the system’s performance. The DPP platform securely and transparently mediates information and models between manufacturers and recycling centers through blockchain networks and data management systems. Figure 2 shows how the manager and the recycling center exchange information within the platform.
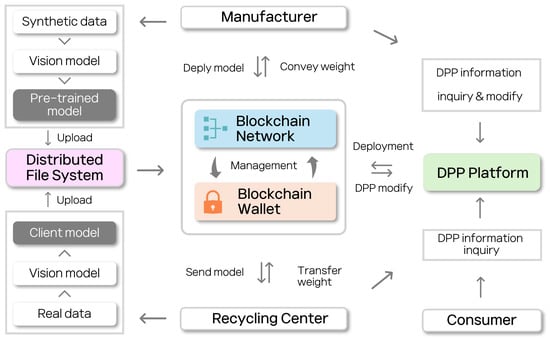
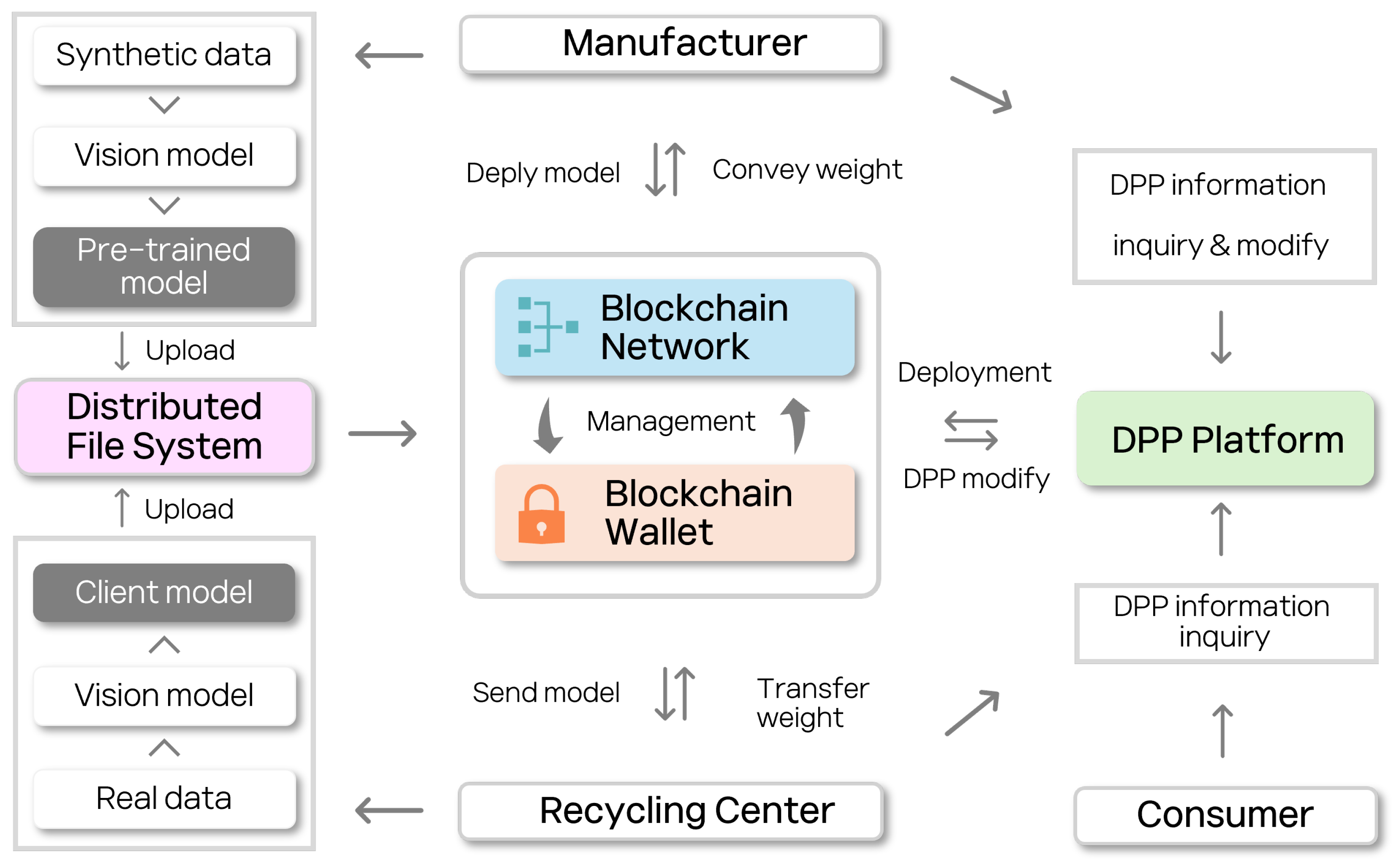
Figure 2.
Blockchain-based DPP system for recycling center and manufacturer: This figure illustrates the integration of blockchain technology with the digital product passport (DPP) system, facilitating secure and transparent data exchange between manufacturers, recycling centers, and consumers. The system leverages a distributed file system for model storage, a blockchain network for transaction management, and a DPP platform for information retrieval and modification, ensuring efficient and verifiable model deployment and recycling processes.
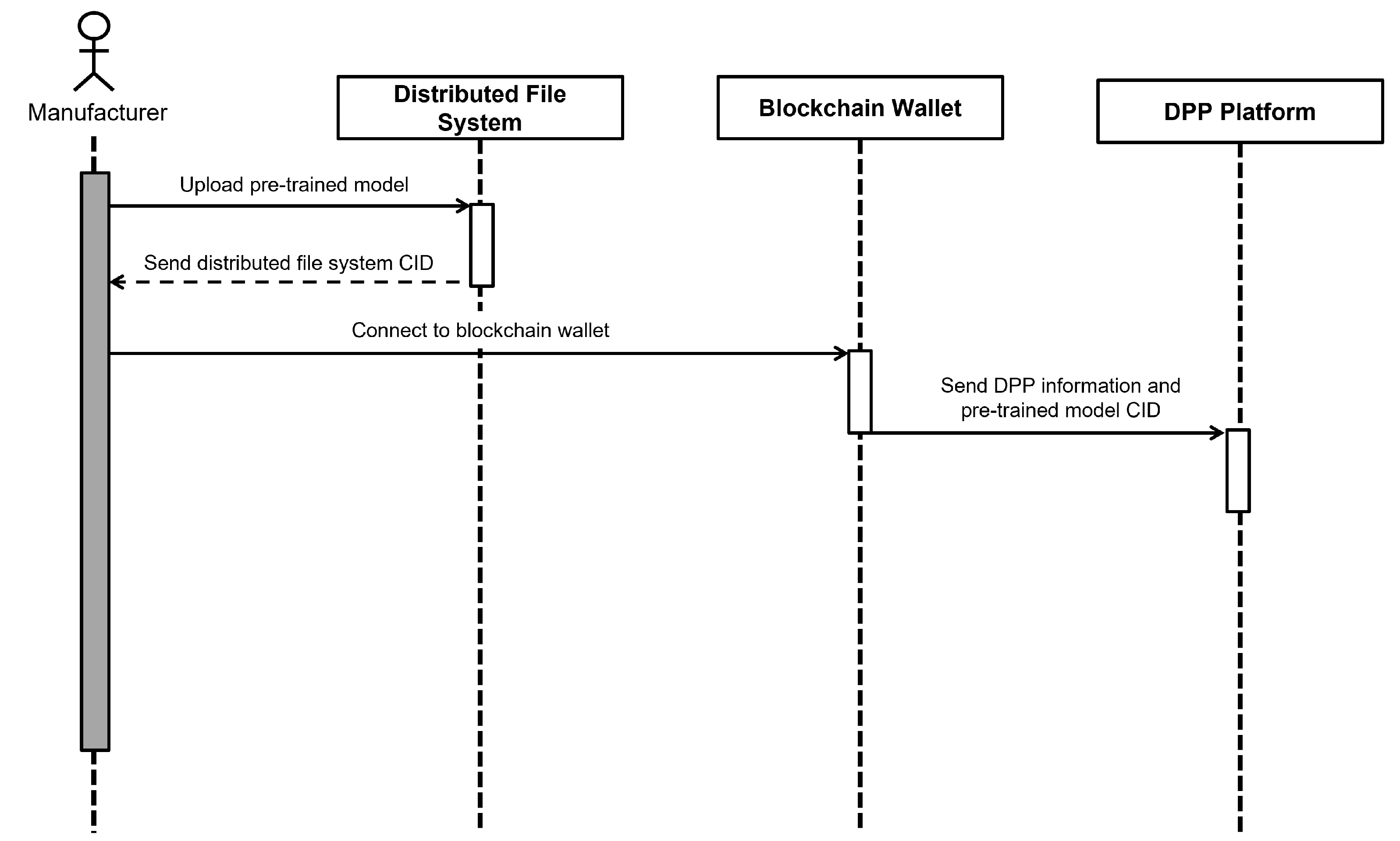
From the following sequence diagram, we will specifically show how each manufacturer and recycling center distribute and download the model. Figure 3 illustrates the sequence of tasks involved in the manufacturer deploying a pre-trained model to the DPP platform. The manufacturer uploads the model to distributed file system and receives a CID. Subsequently, the manufacturer performs user authentication via a blockchain wallet and uploads the CID to the DPP platform.
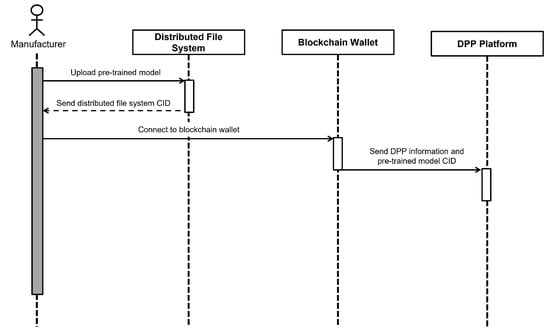
Figure 3.
Sequence diagram for deploying pre-trained models to the DPP platform.
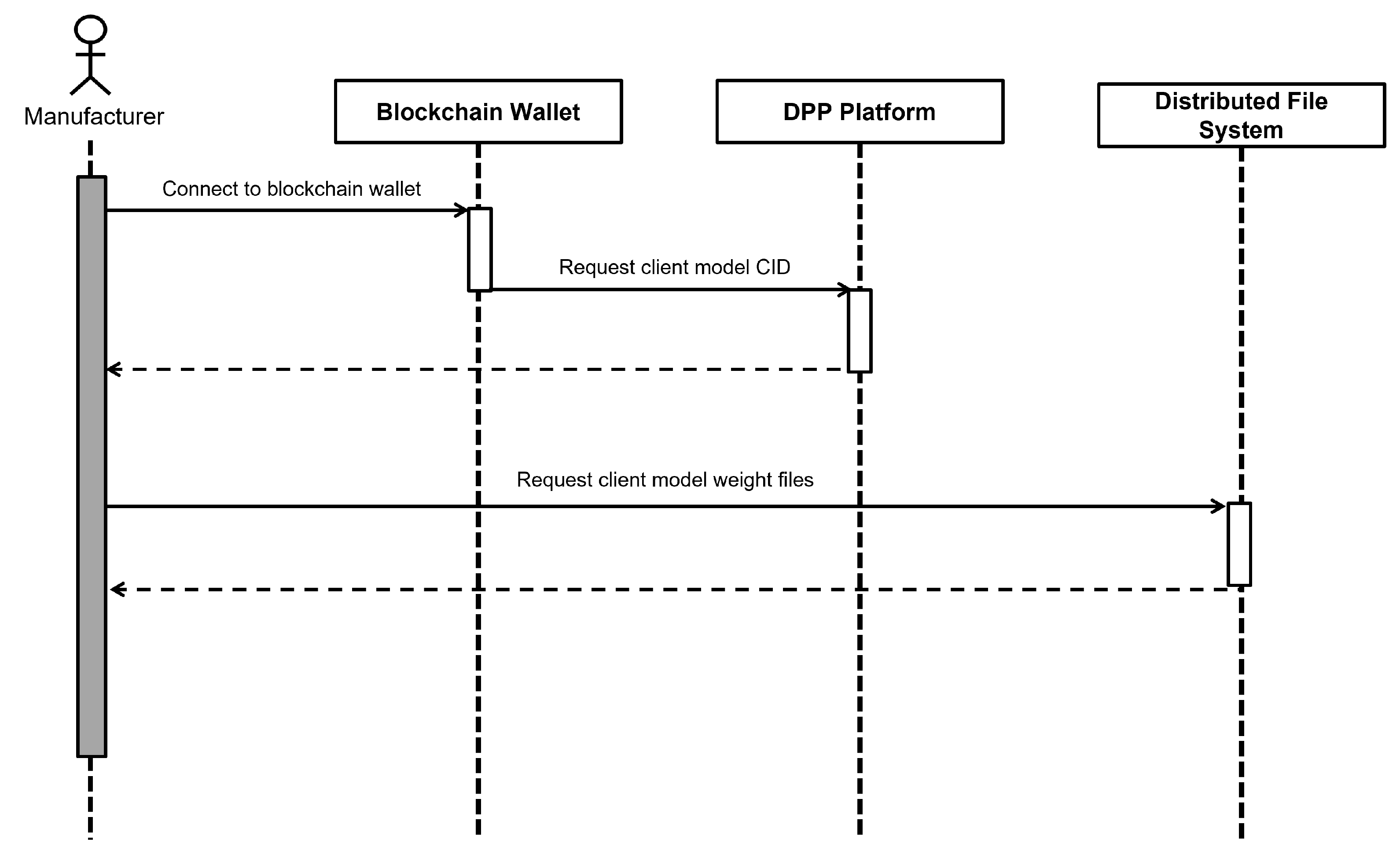
Figure 4 illustrates the process of the manufacturer downloading a client model from the DPP platform. The manufacturer connects to the blockchain wallet to perform user authentication. Then, the manufacturer requests the CID of the client model from the DPP platform. After obtaining the CID, the manufacturer requests the actual weight file associated with the client model from distributed file system. Through this process, the manufacturer can download the model trained locally by the recycling center, i.e., the client.
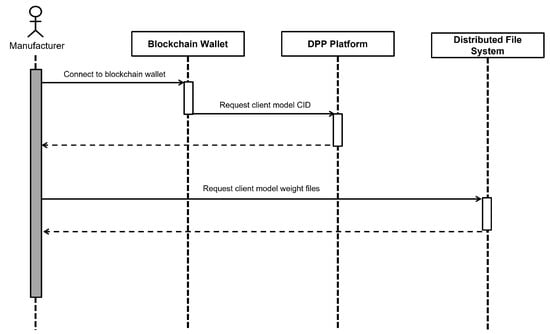
Figure 4.
Sequence diagram for manufacturer downloading client models.
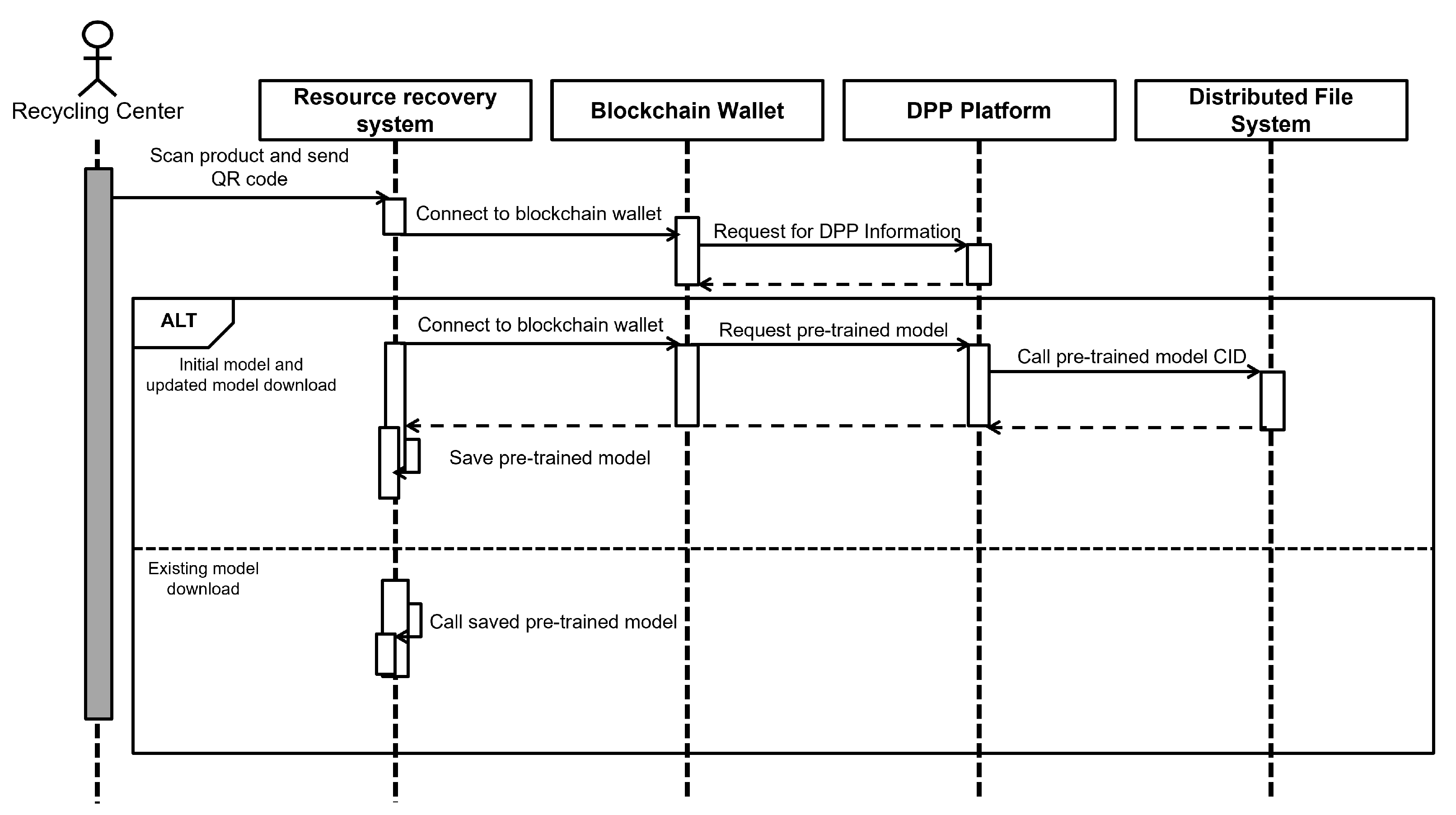
Figure 5 explains the process by which a recycling center downloads the initial and updated global models from the DPP platform. The recycling center scans the product’s QR code in the resource recovery system, connects to the blockchain wallet, and links to the DPP platform. It then requests the DPP information and the pre-trained model. If the model has been updated, the recycling center downloads the updated model. Additionally, if a previously stored model exists in the resource recovery system, that model can also be retrieved.
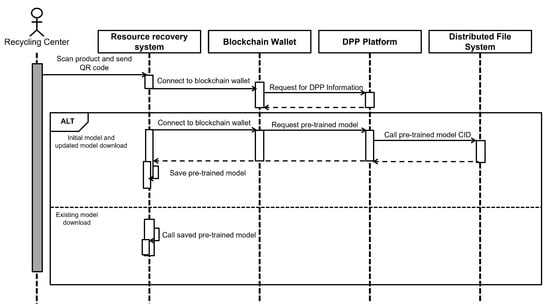
Figure 5.
Sequence diagram for recycling center downloading models from the DPP platform.
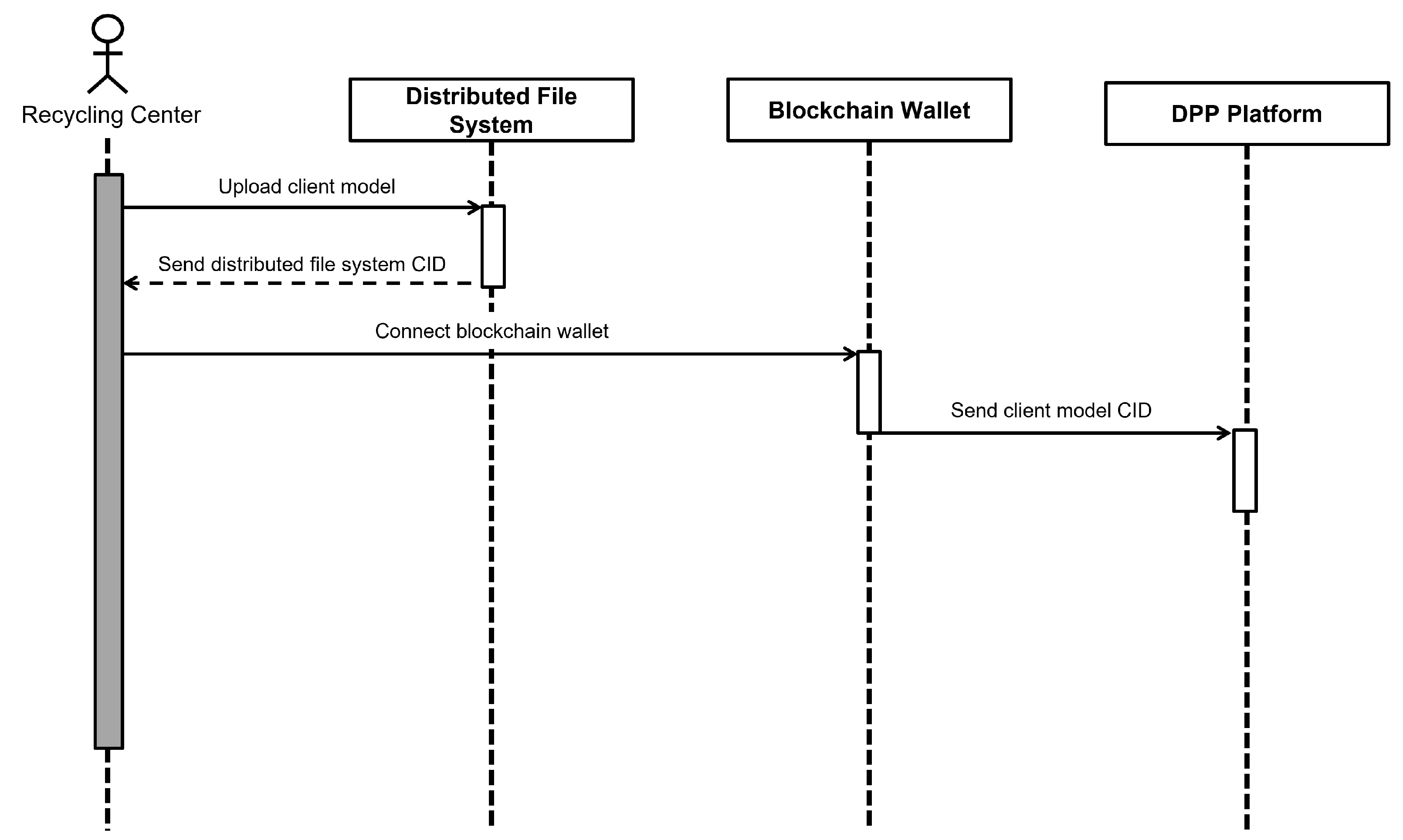
Figure 6 illustrates the process by which a recycling center deploys its locally trained model to the DPP platform. The recycling center first uploads the client model to the distributed file system, obtains the corresponding CID, and then transmits it to the DPP platform via the blockchain wallet. This process enables each recycling center to deploy the locally trained client model.
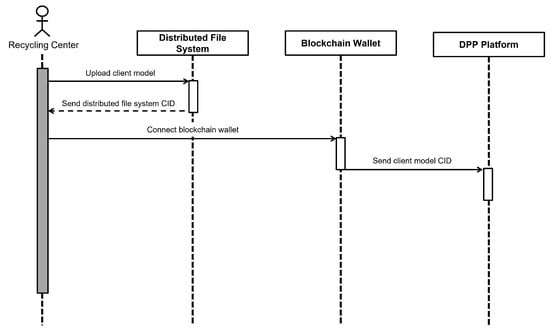
Figure 6.
Sequence diagram for recycling center deploying models to the DPP platform.
The relationship between manufacturers and recycling centers is managed by the DPP platform, a blockchain-based DApp. This structure facilitates global model updates, maintains data privacy, and tracks the contributions of each component. As the performance of the object detection models for discarded items improves through the FL of various models, it contributes to optimizing the recycling process and enhancing resource management efficiency. From the following sections, the discussion will focus on the training process of the baseline model created by the manufacturer, the client model trained with real data by the recycling centers, and the global model updated by the manufacturer, along with the execution of the prototype.
3.2. Pre-Trained Model
3.2.1. Synthetic Data Generation in Manufacturer
In this study, experiments were conducted on a pen holder. This section discusses the process of creating 3D models of a pen holder under the assumption of potential damage and contamination when it is discarded. First, the 3D file of the pen holder was imported into a 3D development tool, and colors were extracted from real pen holder photos to apply them to each component. To effectively represent the actual texture, the roughness was adjusted.
Contamination was then added to the basic pen holder model in three types: stains, bird droppings, and chewed gum. Stains were implemented by mixing a noise texture with colors in the shading process, bird droppings were imported into the image and applied to the desired areas using the Texture Painting technique, and chewed gum was created by generating a UV sphere and sculpting it to resemble the texture of chewed gum.
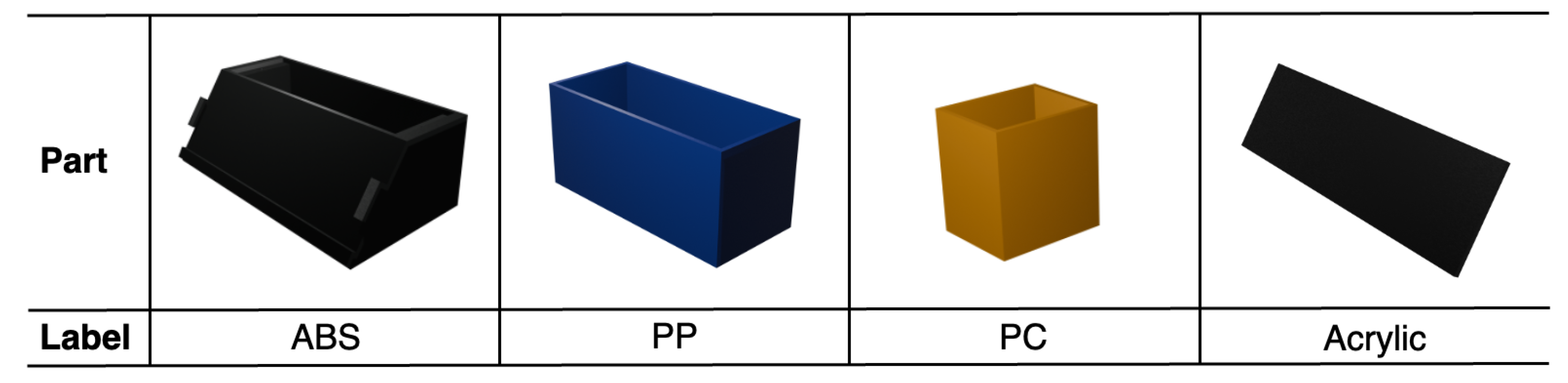
Synthetic data were generated using the Unity Perception package with data annotation techniques, including 2D bounding boxes and semantic segmentation. The materials of each pen holder component were arbitrarily categorized into four types of plastic: Acrylonitrile Butadiene Styrene (ABS) for the main body, Polypropylene (PP) for the blue part, Polycarbonate (PC) for the yellow part, and Acrylic for the nameplate. Figure 7 represents the synthetic data for each component of the pen holder.
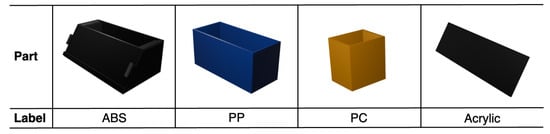
Figure 7.
Pen holder parts and material labels.
To collect photographic data for model training, multiple photos of the pen holder taken from various angles are required. To simulate this realistic photo-taking process, a script was developed using a game engine that randomly changes the camera’s position around the target object to generate diverse visual data.
The CameraRandomizer script sets the pen holder as the target object, with the camera always facing it. The horizontal angle is randomized between 0 and 360 degrees, the vertical angle between 180 and 360 degrees, and the distance between the camera and the pen holder is set to a random value between 500 and 600 units. This process is repeated for each iteration, capturing images of the pen holder from various randomized perspectives to generate diverse datasets.
In this study, nine synthetic datasets were created under the assumption of damage or contamination when the product becomes waste. Figure 8 provides examples of the generated synthetic datasets, including six variations where individual components were removed and three contamination types described earlier. The iteration count was set to 100, resulting in each dataset consisting of 100 captured frames per dataset.

Figure 8.
Examples of synthetic datasets with component removal and contamination types.
The synthetic dataset for the pen holder comprises RGB image files for each frame, semantic segmentation map files, and associated JSON files. The JSON files include annotation definitions, metadata, metric definitions, and sensor definitions for the entire dataset. These data were generated using the game engine and provided in the Synthetic Optimized Labeled Objects (SOLO) format. Subsequently, the data were converted into the Common Objects in Context (COCO) dataset format to train and evaluate object detection models. Additionally, the COCO dataset was transformed into the You Only Look Once version 8 (YOLOv8) [53] format using a platform designed to support the construction, management, and preprocessing of image datasets.
3.2.2. Pre-Trained Model for Classification Part of Recycled Product
YOLOv8 was utilized as a pre-trained model for the classification of recyclable products. Manufacturers trained the baseline model using synthetic data designed to reflect the shapes and characteristics of various recyclable products. By leveraging these synthetic data, the initial model quickly learned the key features of recyclable products. Specifically, YOLOv8’s object detection and classification capabilities were employed to effectively recognize and classify recyclable items. This pre-trained model was subsequently further trained with real-world data by the clients, incorporating the diverse variables encountered in recycling environments, thereby serving as a foundation for enhancing the model’s performance.
The initial baseline model was trained using 900 synthetic data images. The training was conducted with the following hyperparameters: a learning rate of 0.01, a batch size of 16, the Adam optimizer, and 100 epochs. No early stopping was applied during the training process.
3.3. Federated Learning
3.3.1. Client Model Trained on Real Data
This section focuses on the process of creating object detection local models based on data collected from pen holders in damaged and contaminated conditions after disposal and transport to recycling centers. These models were trained using FL. To account for the diverse environments of recycling centers, each client trained their model under conditions that reflected varying backgrounds, product positions, and light directions.
Additionally, to capture the diversity of damage and contamination states, data were collected by including scenarios such as contamination with materials like soil, missing nameplates, and missing key components like blue boxes. This data collection method aims to closely simulate the data available from actual recycling centers. To maintain consistency, all images were captured vertically from above, using the ground as a reference. The product’s position was adjusted freely to enable the model to recognize objects from various positions and angles.
To enhance data diversity, six different backgrounds were established. Figure 9 illustrates examples of real-world data with diverse backgrounds. The training dataset consists of six client environments, each with a varying number of training samples: factory (70), polyurethane (40), wood (46), gray (59), rubber (41), and brown (48). Since real-world recycling centers may experience dynamic fluctuations in data availability, we opted not to apply explicit data normalization techniques such as SMOTE or client-based weighting. Instead, the model was trained with raw data distributions to reflect real-world conditions, ensuring that the system remains adaptable when deployed in practical recycling environments.

Figure 9.
Pen holder detection under diverse conditions and backgrounds. Illustrations of training images used for FL clients to ensure detection in recycling environments.
Specifically, clients were trained on images such as (a) the conveyor belt setup in a recycling facility and (d) a gray background that highlights the pen holder clearly. Additionally, backgrounds reflecting materials used in recycling conveyor belts (e.g., rubber and polyurethane) were included in the training. Basic backgrounds, such as brown tones and wooden textures, were selected to reflect the diverse color schemes observed in recycling processes. Clients 1 to 6 were assigned in the order of (a) to (f). Variations in the pen holder’s condition, as shown in (g), (h), and (i), were also incorporated to train client models effectively. This approach to varying background conditions ensures the model maintains object detection performance in diverse scenarios encountered in recycling facilities.
Using the collected data, YOLOv8 was employed to independently train model parameters at each client site. In this study, each client model underwent fine-tuning by further training on real-world data using the baseline model as a starting point. This approach allowed us to assess how additional real-world data from different environments influence model performance. The fine-tuning process involved training each client model with real data while keeping the core architecture and pre-trained parameters of the baseline model intact. Recycling centers trained individual models tailored to their specific environments, allowing them to achieve localized training suited to their unique conditions. The client model training was conducted with the following hyperparameters: a learning rate of 0.01, a batch size of 16, the Adam optimizer, and 100 epochs. No early stopping was applied during the training process. The parameters from each client’s model were then used to update the global model through FL.
3.3.2. Federated Averaging
In this study, the federated averaging (FedAVG) technique was employed to train the model. FedAVG operates by having each client independently train a model using local data, after which the weights of these models are averaged on a central server to update the global model. In this experiment, six clients participated, each utilizing data provided by manufacturers and recycling centers to train their local models. The trained weights were then transmitted to the central server, where weights were averaged according to the FedAVG algorithm, resulting in the creation of the global model. Only one training round was conducted in this experiment.
Each client’s model weights were saved in the form of YOLOv8 ‘.pt’ files, which were then loaded onto the central server to update the global model’s weights. FedAVG was applied to compute the average for identical weight keys across all clients, which was subsequently incorporated into the global model. Through this process, the global model achieved more comprehensive performance by integrating the diverse local data from each client.
In the FL procedure, the global model was initialized with pre-trained weights on synthetic data and updated using parameters learned from the clients’ real data during each round. The number of rounds indicates the frequency of global model updates. As the rounds progress, more clients participate in the training process, improving the global model’s performance. Particularly, as the number of clients increases, the likelihood of incorporating parameters from new clients in each round also increases, contributing to enhanced accuracy of the global model. In real-world scenarios, the global model is expected to be continuously updated as each recycling center’s model trains on new data.
The primary advantage of FedAVG is that it ensures data privacy by keeping data localized during the training process. This is particularly beneficial in preventing sensitive data shared between recycling centers and manufacturers from being exposed externally. Additionally, by reflecting the contributions of each client in updating the global model, FedAVG enables the creation of a more inclusive model that captures diverse data distributions. This capability improves the efficiency of recycling processes and helps propose optimal recycling strategies that account for the product lifecycle.
3.4. Decentralized File System for Storing the Weights of Components in Federated Learning
This section demonstrates how to store models for implementing a prototype of a blockchain-based DPP system designed to enhance recycling processes. The system facilitates collaboration among stakeholders involved in the recycling process—platforms, manufacturers, and recyclers—by enabling each participant to train their models locally and share them via FL to improve the complementary performance of their models.
Specifically, in the FL environment, each recycling center uploads its locally trained client model to the blockchain network, and manufacturers use these client models to update a global model. This process contributes to improving efficiency and awareness throughout the recycling process. Blockchain technology plays a key role by ensuring the integrity and transparency of data, fostering trust-based collaboration among participants.
To handle vision models within the system, manufacturers are designed to utilize the IPFS. Each participant, including manufacturers, uploads information to be included in the DPP using the decentralized file system, receiving a unique CID in the process. These CIDs can be accessed via URLs in the format [http://ipfs.io/ipfs/CID]. CID can be issued when uploading to IPFS, and each file has different hash.
This approach facilitates efficient retrieval of distributed data fragments and ensures data integrity, which is critical in this context.
The IPFS, being a decentralized network not reliant on central servers, eliminates single points of failure and enhances data stability. Furthermore, data are managed through unique hash values, the CIDs, making it easy to verify any changes and maintain data integrity. As the IPFS stores data across multiple nodes, the loss of a specific node does not result in data loss. These features enable reliable data sharing among manufacturers, platforms, and recyclers within the DPP system, while combining with blockchain to further strengthen data transparency and integrity.
The prototype incorporates an approach where participants upload only the trained object detection models, rather than the original 3D model files, to the decentralized file system. Similarly, models updated through FL are exchanged as model files alone, reducing data transmission volume and improving network efficiency. This method allows for faster application of object detection models in the field without requiring additional processing.
Moreover, by not sharing the original 3D model files, concerns over copyright infringement are alleviated, and data security is enhanced. This lightweight approach underpins the efficiency and reliability of the IPFS-based DPP system and FL.
4. Results
4.1. Prototype Implementation
This study used a pen holder as the application item for the prototype implementation. The most important point in this paper is that manufacturers, recycling centers, and platform operators interact to operate the business around the DPP platform. The DPP platform provides the basis for each stakeholder to share and cooperate with each other. A real prototype was implemented to show that the manufacturers, recycling centers, and platform operators interact.
A prototype integrating a blockchain-based DPP with the IPFS was developed to enhance recycling efficiency by enabling participants to share improved models through FL. A virtual blockchain network was set up using Ganache, Ethereum’s local blockchain development tool, to deploy and test a DApp utilizing smart contracts.
The smart contracts were designed and implemented using the Truffle framework and Solidity programming language. Truffle provides an environment for developing, compiling, and deploying smart contracts, which were then deployed onto the Ganache network. These smart contracts were structured to enable participants to share and verify recycling data on the blockchain network. Beyond merely distributing information, the contracts included lifecycle management functions for DPP, such as creation, retrieval, modification, and deletion, enabling systematic and efficient management.
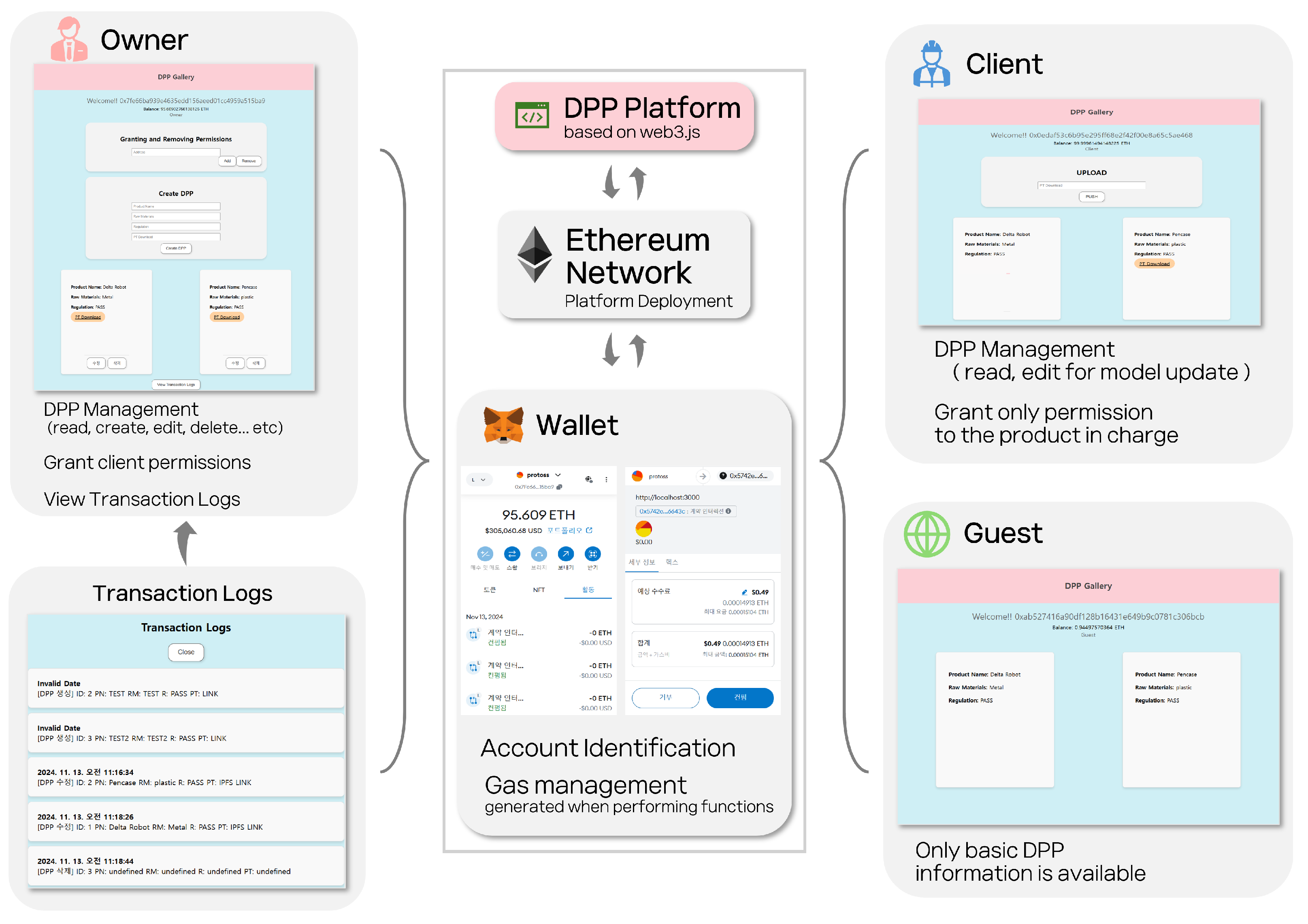
The smart contracts incorporated a role-based permission structure with three roles: owner, client, and guest. Owners, with the highest privileges, can access all functionalities and assign or revoke client permissions. Clients are granted limited access to basic DPP information and can download PT files or upload enhanced PT files. Guests have the most restricted access, limited to viewing basic DPP details without accessing specific data like PT files. This role-based structure enhances data security, allowing participants to access only the data and functions relevant to their roles, thereby achieving both reliability and efficiency.
This role-based framework underpins a collaborative model for the recycling process by creating an FL environment facilitated through smart contracts. By integrating the IPFS with blockchain, the system ensures decentralized data management while maintaining integrity, providing a foundation for effectively distributing and applying recycling recognition models.
Access to the deployed smart contracts was facilitated through the blockchain wallet Metamask, which connects to the Ganache server to enable blockchain communication via a browser. Multiple accounts were registered in Metamask to test interactions and validate role-based permissions.
A web interface enabling interaction between the DApp and blockchain network was built using the Application Binary Interface (ABI) and the contract address generated during smart contract deployment. The DApp was developed using Web3.js and React to create a user-friendly application. It visualizes DPP information in a gallery format, displaying account details, assigned permissions, and corresponding functional interfaces. Users can intuitively perform blockchain operations, such as creating, modifying, and deleting a DPP, directly through the web interface.
Figure 10 illustrates how users access the DApp deployed on the Ethereum network via a wallet, which enumerates the functions available for each permission level. The DApp not only provides functionalities but also informs users of the gas costs incurred for each operation through Metamask, immediately reflecting any changes.
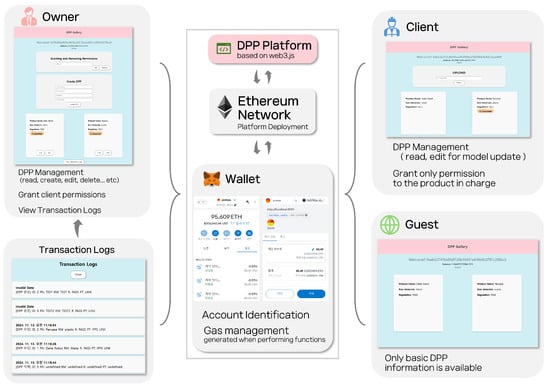
Figure 10.
The structure of a blockchain-based DPP and the permissions for each class.
This process offers users clear information about gas costs and blockchain transactions. All actions are recorded as encrypted logs on the blockchain network, permanently stored and decipherable using the ABI. The DPP platform, built with Web3.js, analyzes these logs to present actionable insights to users, supporting systematic management and review of recorded activities.
This system provides real-time visualization and management of DPP information on the blockchain, offering a secure and transparent operational environment based on user account permissions. The integration of Metamask and Web3.js enhances the DPP system’s intuitive web accessibility and efficiently facilitates interaction between users and the blockchain. This DPP system not only ensures transparent management of recycling data but also strengthens participant collaboration, laying a critical technological foundation for achieving a sustainable circular economy.
4.2. Model Performance Results
This paper evaluates three key aspects: the baseline model trained on synthetic data, the client models fine-tuned with real-world images, and the global model aggregated using FedAVG, all tested on a real-world dataset. The baseline model was trained on 900 synthetic data images, while the client models were trained on a total of 304 real data images. The final test set consisted of 31 real data images. Table 1 presents the performance of the baseline model trained solely on synthetic data. While it achieved high accuracy when tested on synthetic data, its performance declined when tested on real-world data. This result highlights the limitations of training exclusively on synthetic data, as models trained in this manner may struggle to generalize effectively to real-world scenarios. Consequently, fine-tuning with real-world images is necessary to bridge the performance gap and enhance practical applicability.

Table 1.
Performance comparison of baseline model.
Therefore, to address this limitation, we trained the baseline model further by incorporating real-world data from various environments. Each environment was considered as a separate client to simulate diverse training conditions. Table 2 presents the descriptions and results of each client model trained on pen holder images captured in different environments. The performance of client models fine-tuned with real-world data was evaluated. Each client conducted local training using real-world datasets, resulting in most client models outperforming the baseline model. Notably, Client 2 and Client 4 demonstrated high precision and recall, as well as exceptional performance in F1-Score and mAP metrics. This indicates that fine-tuning with real-world data enables models to achieve better generalization capabilities. Client 2 collected data on a highly reflective and uniform surface, which contributed to superior results in both precision and recall. In contrast, Client 6 captured data in a relatively shadowed and darker environment, leading to lower performance. This demonstrates that the background conditions of the clients significantly affect the performance of their respective client models.
Table 2.
This table presents the results of training YOLOv8 models in real-world environments across various clients. It includes Client 1 to Client 6, where each model was trained using real environmental images from their respective settings. All models were initially trained on the baseline model, which was developed using synthetic data, as described in Table 1. The results reflect the performance improvements achieved by incorporating real-world data from each client’s environment.
However, the performance of models trained in different environments exhibited significant variation. To develop a model capable of adapting to diverse real-world conditions, we employed the FedAVG method, which improves model performance by averaging the weights of all client models. The results of the FedAVG-trained model, including precision, recall, F1-Score, mAP50, and mAP50-95, are presented in Table 3. The findings indicate that, except for the recall and F1-Score of Client 2 and the precision of Client 4, the FedAVG algorithm outperformed all individual client models. Notably, the FedAVG-based model achieved the highest performance in mAP50, which assesses fundamental object detection capability, and mAP50-95, which evaluates precise localization accuracy and consistency across various conditions. These results demonstrate that using the FedAVG algorithm yields superior performance compared to a single model, making it a more effective approach for real-world object detection tasks.
Table 3.
A table presenting the results of the FedAVG algorithm. The individual YOLOv8 models used in Table 2 were aggregated using the FedAVG algorithm to enhance performance. This table illustrates the results of applying FedAVG, displaying metrics such as precision, recall, F1-Score, mAP50, and mAP50-95.
Despite the varying performance across individual client models due to differences in their respective environments, the FL-based model demonstrated relatively high performance, highlighting the effectiveness of federated learning. The global model, aggregated using the FedAVG method, was created by averaging the weights from all client models and tested on the real-world dataset. It outperformed most individual client models, achieving the highest scores in key metrics such as F1-Score and mAP50-95. This result indicates that aggregating training data from multiple clients enhances the model’s ability to generalize across diverse environments. Notably, Clients 2 and 4 exceeded the global model in certain metrics, likely because the local dataset of Clients 2 and 4 was better aligned with the evaluation conditions. Nonetheless, the FedAVG-integrated global model proved to be robust and effective in leveraging diverse client data to improve overall performance.
The baseline model trained exclusively on synthetic data did not achieve satisfactory performance in real-world environments, underscoring the necessity of fine-tuning with real-world data via client models. Additionally, global model aggregation using FedAVG effectively utilized client data to enhance overall model performance. These findings demonstrate that FL can effectively capture diverse data distributions, improving the model’s applicability in real-world scenarios.
4.3. Economic Effect of Using the Digital Product Passport Platform
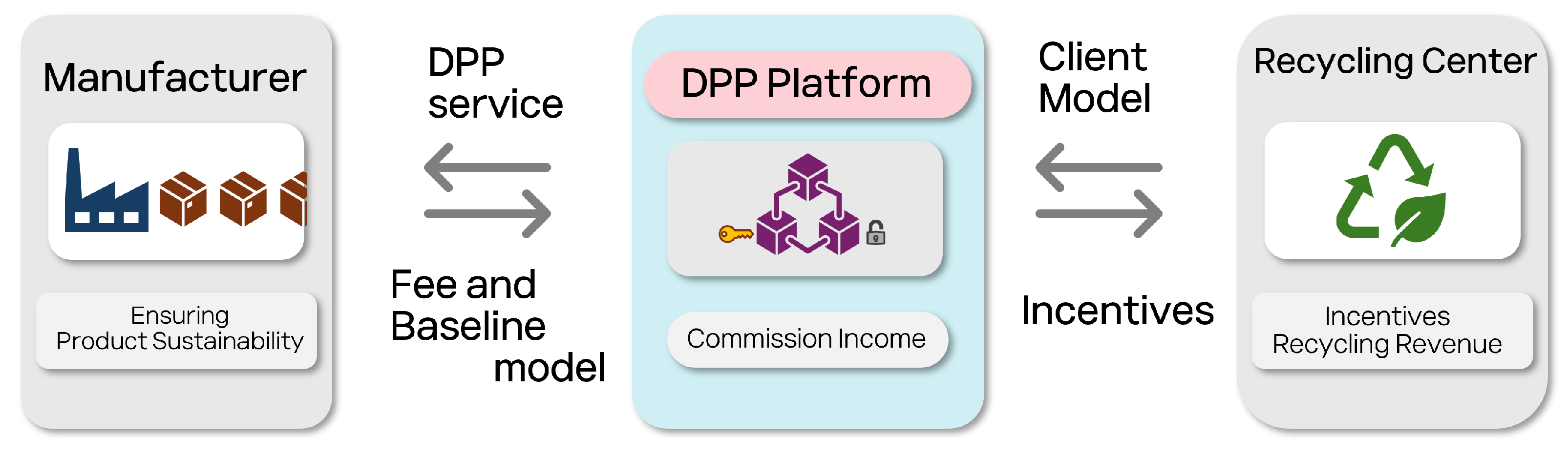
This paper discusses not only how the DPP platform is implemented, but also the economic benefits of each stakeholder using it. The DPP platform is designed as a business model in which manufacturers, recycling centers, and platform operators interact to create sustainability and economic value.
Manufacturers access the DPP platform to ensure the recyclability of parts of their products and realize environmental benefits such as reducing carbon emissions. Recycling centers utilize the information provided by the DPP platform to automate the recycling process, maximize efficiency, and receive incentives with client models learned based on data generated during the recycling process. Platform operators coordinate AI model flows between manufacturers and recycling centers, manage interactions through blockchain technology, and generate revenue through service fees and model weight brokerage.
All stakeholders provide services to each other and receive corresponding economic rewards. The DPP platform manages and coordinates the entire process, thereby building a sustainable business ecosystem. This structure allows manufacturers, recycling centers, and platform operators to work together to achieve resource circulation and economic sustainability at the same time. Figure 11 is a picture of this relationship.
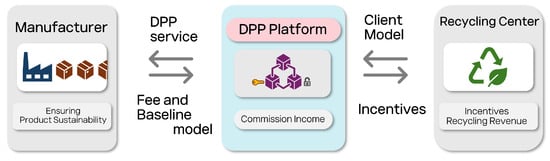
Figure 11.
Business model of the DPP platform for sustainable recycling. This model demonstrates the transactional framework among different stakeholders—manufacturers, the DPP platform, clients, and recycling centers—where direct interaction between stakeholders is minimized. Instead, the system leverages fees and baseline model contributions from manufacturers and commission income from the DPP service to generate financial incentives for data providers. These incentives aim to foster engagement and revenue generation without the direct cost burden on stakeholders, thus motivating sustained participation and enhancing the recycling process.
4.3.1. Economic Benefits for Manufacturers
Manufacturers can gain carbon credits through the DPP platform by reducing carbon emissions. Carbon credits are a type of tradable asset that companies can earn by lowering their carbon emissions, enabling them to generate additional revenue. This serves as an important mechanism for manufacturers to comply with environmental regulations while gaining financial benefits. Furthermore, by leveraging the DPP platform to increase product recyclability, manufacturers can reduce the costs associated with remanufacturing the same product. Higher recycling rates lead to reduced usage of new raw materials, resulting in more efficient resource utilization and lower manufacturing costs. As illustrated in the figure, manufacturers can ensure the sustainability of their products by using DPP services and improving their products based on the information obtained from recycling. Ultimately, this contributes to the realization of a circular economy and plays a vital role in ensuring environmental sustainability.
4.3.2. Economic Benefits for Recycling Centers
Recycling centers can efficiently process discarded products through the DPP platform. By utilizing the digital information recorded in the DPP, recycling centers can easily identify the materials used in products and how to classify them, thereby maximizing recycling efficiency. As shown in the figure, recycling centers can achieve higher accuracy in the recycling process by utilizing client models provided by the DPP platform, earning additional incentives. This incentivizes recycling centers to participate in the process and contributes to improving overall recycling rates. Additionally, recycling centers can generate extra revenue by supplying recycling data to the platform, which strengthens their economic foundation. However, variable costs may arise in transmitting and managing data, which should be factored into the platform’s operational costs. Such a cost structure helps recycling centers manage resources effectively while maintaining optimal cost efficiency.
4.3.3. Economic Benefits for the Digital Product Passport Platform
The DPP platform acts as an intermediary between manufacturers and recycling centers, earning service fees in the process. As illustrated in the figure, the DPP platform generates revenue based on fees collected from participants, ensuring sustainable operation. By utilizing blockchain technology, the platform ensures the reliability and transparency of data, enhancing its credibility and enabling participants to transact with confidence. Blockchain is employed to guarantee data integrity and minimize security risks that may arise in centralized servers. Since blockchain records are shared among all participants, data tampering is nearly impossible, thereby fostering trust among stakeholders. This trust significantly enhances the platform’s sustainability and encourages participants to actively utilize the platform. Moreover, blockchain reduces transaction costs and provides a transparent revenue structure, maximizing the economic value of the platform by fostering trust among participants.
By leveraging the DPP platform, manufacturers, recycling centers, and the platform itself can all derive economic benefits. Manufacturers can reduce costs and generate revenue through carbon credits, recycling centers gain from efficient resource processing and additional incentives, and the platform establishes a sustainable business model through service fees and blockchain-based credibility. This structure not only facilitates the realization of a circular economy but also plays a critical role in maximizing resource efficiency and achieving environmental sustainability.
5. Discussion
This paper leverages blockchain technology and DFS-based data sharing to ensure data integrity and accessibility within a decentralized environment. Utilizing DFS allows the DPP platform to securely store and share model weights and product lifecycle data using CID, which facilitates seamless and secure collaboration between manufacturers and recycling centers. Wang et al. (2021) proposed a blockchain-based authentication mechanism for the Industrial Internet of Things that enhances security and privacy by integrating transfer learning with blockchain technology. Their study highlights how blockchain can provide privacy preservation while maintaining efficient authentication processes [54]. This aligns with our approach of using blockchain and DFS to ensure data integrity and secure collaboration between manufacturers and recycling centers. By leveraging similar principles, our study demonstrates how federated learning and blockchain can collectively enhance security and scalability in recycling automation systems.
Additionally, smart contracts were developed using Solidity within the Ethereum framework, implementing a role-based access control system to manage user permissions. The system defines three distinct roles:
Owner: Authorized to modify and update DPP data. Client: Can retrieve and submit new data to the platform. Guest: Has restricted access to basic information but cannot modify records. This structure ensures that only authorized entities can access sensitive data, thereby enhancing security and preventing unauthorized modifications.
Furthermore, to ensure data immutability, all transactions are recorded on the blockchain using cryptographic hash functions. Once a record is added, it cannot be modified or deleted, ensuring transparency and security. Large datasets, such as AI model weights and product lifecycle data, are stored on the IPFS. Instead of storing raw data directly on the blockchain, only the CID is recorded, providing a reference to the actual off-chain storage. This approach preserves data integrity while optimizing storage efficiency.
The application of FL to the circular economy introduces a decentralized and privacy-preserving approach to collaborative learning. This study illustrates methods that enable collaborative model updates between manufacturers and recycling centers while maintaining data privacy. By sharing only model weights instead of raw data, FL enhances data security, reduces the risk of unauthorized data exposure, and minimizes transmission costs. The integration of blockchain further strengthens this framework by providing immutability, transparency, and role-based access control, ensuring that only authorized entities can access and update model-related information.
In the context of FL, each client independently trains models on local data and shares only the model weights with the central server. This approach significantly reduces communication costs, as weight data are considerably smaller than raw data. It eliminates the necessity of processing large volumes of data in a central location, thereby decreasing network traffic and server load. Our paper extends this concept by integrating blockchain with FL to further improve security and scalability in recycling automation systems.
The addition to this discussion addresses how the integration of these technologies can overcome technical and operational challenges for practical deployment in real-world industrial settings. It provides a detailed analysis of how blockchain and FL can be effectively utilized for processing large-scale recycling data and real-time transactions, ultimately boosting productivity and efficiency in recycling processes. This study also evaluates the commercial feasibility of these technologies and highlights potential issues that may arise during practical application, offering critical insights for future research and industry adoption.
6. Conclusions
The implementation of a blockchain-based DPP in this paper has achieved concrete results in the field of recycling automation. This paper goes beyond theoretical research by integrating blockchain and FL technologies to propose and demonstrate a practical framework. Within the DPP, this integration has enhanced the performance of waste vision models and automated decision-making processes, thereby providing a foundation for improved recycling efficiency and resource optimization.
Furthermore, this research secures data reliability and creates new business opportunities through the use of blockchain and DPPs, contributing to the activation of the circular economy and the optimization of resource recycling. The proposed system lays the groundwork for collaborative and data-driven sustainable resource management between manufacturers and recycling centers. This approach not only enhances recycling productivity but also plays a crucial role in building a strong and sustainable circular economy.
This paper does not include a direct quantitative comparison between the proposed system and other existing technologies. To address this, future research will involve a comprehensive comparative analysis. We plan to collaborate with actual recycling company partners to collect practical metrics and conduct empirical validations alongside other DPPs to perform a quantitative comparison.
Additionally, there is currently a lack of specific data on economic analysis and comparisons with existing technologies. Future research will more specifically investigate the economic benefits, including the cost savings for manufacturers and recycling centers provided by this system. A quantitative comparison with other existing technologies will also be conducted to more clearly demonstrate the advantages and innovations of the proposed system. We will also conduct future research on the environments where the DPP can be practically implemented.
These future research directions will address the gaps identified in this paper and further substantiate the practical and economic viability of the related technologies.
Author Contributions
Conceptualization, M.J.K. and J.U.; methodology, M.J.K., K.J.P., J.S.M. and J.U.; software, M.J.K., C.H.H. and J.S.M.; validation, M.J.K., C.H.H. and J.S.M.; formal analysis, M.J.K., K.J.P. and J.S.M.; investigation, M.J.K., K.J.P. and J.S.M.; resources, J.U.; data curation, M.J.K., C.H.H., K.J.P. and J.S.M.; writing—original draft preparation, M.J.K., C.H.H., K.J.P. and J.S.M.; writing—review and editing, M.J.K. and J.U.; visualization, M.J.K., C.H.H. and K.J.P.; supervision, J.U.; project administration, J.U.; funding acquisition, J.U. All authors have read and agreed to the published version of the manuscript.
Funding
This research is (partially) funded by the BK21 FOUR program of Graduate School, Kyung Hee University (GS-1-JO-NON-20241884). And this paper is supported by Korea Institute for Advancement of Technology (KIAT) grant funded by the Korea Government (MOTIE) (P0028468, Development of Manufacturing On-Device AI and Dataspace Technology).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Restrictions apply to the availability of these data. Data were obtained from ‘Autonomous Manufacturing Research Center, Korea Electronics Technology Institute’ and are available with the permission of ‘Autonomous Manufacturing Research Center, Korea Electronics Technology Institute’.
Acknowledgments
The authors thank Byunghun Song and Jieun Jung of Autonomous Manufacturing Research Center, Korea Electronics Technology Institute for providing experimental data.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| DPP | Digital product passport |
| FL | Federated learning |
| DApp | Decentralized Application |
| IPFS | InterPlanetary File System |
| CID | Content identifier |
| ABS | Acrylonitrile Butadiene Styrene |
| PP | Polypropylene |
| PC | Polycarbonate |
| SOLO | Synthetic Optimized Labeled Objects |
| COCO | Common Objects in Context |
| YOLOv8 | You Only Look Once version 8 |
| FedAVG | Federated averaging |
| ABI | Application Binary Interface |
References
- Mesa, J.A.; Esparragoza, I.; Maury, H. Trends and perspectives of sustainable product design for open architecture products: Facing the circular economy model. Int. J. Precis. Eng. Manuf.-Green Technol. 2019, 6, 377–391. [Google Scholar] [CrossRef]
- Reslan, M.; Last, N.; Mathur, N.; Morris, K.; Ferrero, V. Circular economy: A product life cycle perspective on engineering and manufacturing practices. Procedia CIRP 2022, 105, 851–858. [Google Scholar] [CrossRef]
- Chu, C.H.; Pan, J.K. A Systematic review on extended reality applications for sustainable manufacturing across the product lifecycle. Int. J. Precis. Eng. Manuf.-Green Technol. 2024, 11, 1017–1028. [Google Scholar] [CrossRef]
- Götz, T.; Berg, H.; Jansen, M.; Adisorn, T.; Cembrero, D.; Markkanen, S.; Chowdhury, T. Digital Product Passport: The Ticket to Achieving a Climate Neutral and Circular European Economy? University of Cambridge Institute for Sustainability Leadership: Cambridge, UK, 2022. [Google Scholar]
- Adisorn, T.; Tholen, L.; Götz, T. Towards a digital product passport fit for contributing to a circular economy. Energies 2021, 14, 2289. [Google Scholar] [CrossRef]
- Rumetshofer, T.; Straka, K.; Fischer, J. How the Digital Product Passport Can Lead the Plastics Industry towards a Circular Economy—A Case Study from Bottle Caps to Frisbees. Polymers 2024, 16, 1420. [Google Scholar] [CrossRef] [PubMed]
- Walden, J.; Steinbrecher, A.; Marinkovic, M. Digital product passports as enabler of the circular economy. Chem. Ing. Tech. 2021, 93, 1717–1727. [Google Scholar] [CrossRef]
- Heeß, P.; Rockstuhl, J.; Körner, M.F.; Strüker, J. Enhancing trust in global supply chains: Conceptualizing Digital Product Passports for a low-carbon hydrogen market. Electron. Mark. 2024, 34, 10. [Google Scholar] [CrossRef]
- Hulea, M.; Miron, R.; Muresan, V. Digital Product Passport Implementation Based on Multi-Blockchain Approach with Decentralized Identifier Provider. Appl. Sci. 2024, 14, 4874. [Google Scholar] [CrossRef]
- Koppelaar, R.H.; Pamidi, S.; Hajósi, E.; Herreras, L.; Leroy, P.; Jung, H.Y.; Concheso, A.; Daniel, R.; Francisco, F.B.; Parrado, C.; et al. A digital product passport for critical raw materials reuse and recycling. Sustainability 2023, 15, 1405. [Google Scholar] [CrossRef]
- Cimpan, C.; Maul, A.; Wenzel, H.; Pretz, T. Techno-economic assessment of central sorting at material recovery facilities–the case of lightweight packaging waste. J. Clean. Prod. 2016, 112, 4387–4397. [Google Scholar] [CrossRef]
- Lee, H.T.; Song, J.H.; Min, S.H.; Lee, H.S.; Song, K.Y.; Chu, C.N.; Ahn, S.H. Research trends in sustainable manufacturing: A review and future perspective based on research databases. Int. J. Precis. Eng. Manuf.-Green Technol. 2019, 6, 809–819. [Google Scholar] [CrossRef]
- Gundupalli, S.P.; Hait, S.; Thakur, A. A review on automated sorting of source-separated municipal solid waste for recycling. Waste Manag. 2017, 60, 56–74. [Google Scholar] [CrossRef] [PubMed]
- Picon, A.; Ghita, O.; Iriondo, P.M.; Bereciartua, A.; Whelan, P.F. Automation of waste recycling using hyperspectral image analysis. In Proceedings of the 2010 IEEE 15th Conference on Emerging Technologies & Factory Automation (ETFA 2010), Bilbao, Spain, 13–16 September 2010; pp. 1–4. [Google Scholar]
- Chin, L.; Lipton, J.; Yuen, M.C.; Kramer-Bottiglio, R.; Rus, D. Automated recycling separation enabled by soft robotic material classification. In Proceedings of the 2019 2nd IEEE International Conference on Soft Robotics (RoboSoft), Seoul, Republic of Korea, 14–18 April 2019; pp. 102–107. [Google Scholar]
- Reddy, Y.; Viswanath, P.; Reddy, B.E. Semi-supervised learning: A brief review. Int. J. Eng. Technol. 2018, 7, 81. [Google Scholar] [CrossRef]
- Jordon, J.; Szpruch, L.; Houssiau, F.; Bottarelli, M.; Cherubin, G.; Maple, C.; Cohen, S.N.; Weller, A. Synthetic Data—What, why and how? arXiv 2022, arXiv:2205.03257. [Google Scholar]
- Van Breugel, B.; Qian, Z.; Van Der Schaar, M. Synthetic data, real errors: How (not) to publish and use synthetic data. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; pp. 34793–34808. [Google Scholar]
- Alkhalifah, T.; Wang, H.; Ovcharenko, O. MLReal: Bridging the gap between training on synthetic data and real data applications in machine learning. Artif. Intell. Geosci. 2022, 3, 101–114. [Google Scholar] [CrossRef]
- Tremblay, J.; Prakash, A.; Acuna, D.; Brophy, M.; Jampani, V.; Anil, C.; To, T.; Cameracci, E.; Boochoon, S.; Birchfield, S. Training deep networks with synthetic data: Bridging the reality gap by domain randomization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 969–977. [Google Scholar]
- Nowruzi, F.E.; Kapoor, P.; Kolhatkar, D.; Hassanat, F.A.; Laganiere, R.; Rebut, J. How much real data do we actually need: Analyzing object detection performance using synthetic and real data. arXiv 2019, arXiv:1907.07061. [Google Scholar]
- Mammen, P.M. Federated learning: Opportunities and challenges. arXiv 2021, arXiv:2101.05428. [Google Scholar]
- Zheng, Z.; Zhou, Y.; Sun, Y.; Wang, Z.; Liu, B.; Li, K. Applications of federated learning in smart cities: Recent advances, taxonomy, and open challenges. Connect. Sci. 2022, 34, 1–28. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Peng, X.; Huang, Z.; Zhu, Y.; Saenko, K. Federated adversarial domain adaptation. arXiv 2019, arXiv:1911.02054. [Google Scholar]
- Wang, X.; Garg, S.; Lin, H.; Hu, J.; Kaddoum, G.; Piran, M.J.; Hossain, M.S. Toward accurate anomaly detection in industrial internet of things using hierarchical federated learning. IEEE Internet Things J. 2021, 9, 7110–7119. [Google Scholar] [CrossRef]
- Kumar, Y.; Singla, R. Federated learning systems for healthcare: Perspective and recent progress. In Federated Learning Systems: Towards Next-Generation AI; Springer: Cham, Switzerland, 2021; pp. 141–156. [Google Scholar]
- Liu, Y.; Huang, A.; Luo, Y.; Huang, H.; Liu, Y.; Chen, Y.; Feng, L.; Chen, T.; Yu, H.; Yang, Q. Fedvision: An online visual object detection platform powered by federated learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 13172–13179. [Google Scholar]
- Memia, A. Federated Learning for Edge Computing: Real-Time Object Detection. Master’s Thesis, University of Skövde, Skövde, Sweden, 2023. [Google Scholar]
- Wang, S.; Yuan, Y.; Wang, X.; Li, J.; Qin, R.; Wang, F.Y. An overview of smart contract: Architecture, applications, and future trends. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 108–113. [Google Scholar]
- Casino, F.; Dasaklis, T.K.; Patsakis, C. A systematic literature review of blockchain-based applications: Current status, classification and open issues. Telemat. Inform. 2019, 36, 55–81. [Google Scholar] [CrossRef]
- Alotaibi, L.S.; Alshamrani, S.S. Smart Contract: Security and Privacy. Comput. Syst. Sci. Eng. 2021, 38, 93. [Google Scholar] [CrossRef]
- Rawat, V.; Dahiya, N.; Rai, S.; Arora, A. A blockchain-based decentralized framework for carbon accounting, trading and governance. In Proceedings of the 2022 8th International Conference on Computer Technology Applications, Vienna, Austria, 12–14 May 2022; pp. 148–153. [Google Scholar]
- Nguyen, D.C.; Pathirana, P.N.; Ding, M.; Seneviratne, A. Blockchain for secure ehrs sharing of mobile cloud based e-health systems. IEEE Access 2019, 7, 66792–66806. [Google Scholar] [CrossRef]
- Aydar, M.; Ayvaz, S.; Cetin, S.C. Towards a Blockchain based digital identity verification, record attestation and record sharing system. arXiv 2019, arXiv:1906.09791. [Google Scholar]
- Alabdulwahhab, F.A. Web 3.0: The decentralized web blockchain networks and protocol innovation. In Proceedings of the 2018 1st International Conference on Computer Applications & Information Security (ICCAIS), Riyadh, Saudi Arabia,, 4–6 April 2018; pp. 1–4. [Google Scholar]
- Bharadiya, J.P. Artificial intelligence and the future of web 3.0: Opportunities and challenges ahead. Am. J. Comput. Sci. Technol. 2023, 6, 91–96. [Google Scholar]
- Glomann, L.; Schmid, M.; Kitajewa, N. Improving the blockchain user experience—-An approach to address blockchain mass adoption issues from a human-centred perspective. In Advances in Artificial Intelligence, Software and Systems Engineering, Proceedings of the AHFE 2019 International Conference on Human Factors in Artificial Intelligence and Social Computing, the AHFE International Conference on Human Factors, Software, Service and Systems Engineering, and the AHFE International Conference of Human Factors in Energy, Washington, DC, USA, 24–28 July 2019; Springer: Cham, Switzerland, 2020; pp. 608–616. [Google Scholar]
- Schollmeier, R. A definition of peer-to-peer networking for the classification of peer-to-peer architectures and applications. In Proceedings of the Proceedings First International Conference on Peer-to-Peer Computing, Linkping, Sweden, 27–29 August 2001; pp. 101–102. [Google Scholar]
- Krishnan, R.; Smith, M.D.; Telang, R. The economics of peer-to-peer networks. J. Inf. Technol. Theory Appl. 2003, 5, 31–44. [Google Scholar] [CrossRef]
- Berthon, P.; Chohan, R.; Pehlivan, E.; Rabinovich, T. Corrigendum to ‘Fixing fake news: Understanding and managing the marketer-consumer information echosystem’ [Business Horizons, 65/6 (2022), pp. 729–738]. Bus. Horizons 2023, 66, 301. [Google Scholar] [CrossRef]
- Trautwein, D.; Raman, A.; Tyson, G.; Castro, I.; Scott, W.; Schubotz, M.; Gipp, B.; Psaras, Y. Design and evaluation of IPFS: A storage layer for the decentralized web. In Proceedings of the ACM SIGCOMM 2022 Conference, Amsterdam, The Netherlands, 22–26 August 2022; pp. 739–752. [Google Scholar]
- Balduf, L.; Henningsen, S.; Florian, M.; Rust, S.; Scheuermann, B. Monitoring data requests in decentralized data storage systems: A case study of IPFS. In Proceedings of the 2022 IEEE 42nd International Conference on Distributed Computing Systems (ICDCS), Bologna, Italy, 10–13 July 2022; pp. 658–668. [Google Scholar]
- Agrawal, S.; Jain, H. An approach to develop a secure and decentralized internet. In Proceedings of the 2019 International Conference on Nascent Technologies in Engineering (ICNTE), Navi Mumbai, India, 4–5 January 2019; pp. 1–6. [Google Scholar]
- Kumar, S.; Bharti, A.K.; Amin, R. Decentralized secure storage of medical records using Blockchain and IPFS: A comparative analysis with future directions. Secur. Priv. 2021, 4, e162. [Google Scholar] [CrossRef]
- De Giovanni, P. Blockchain and smart contracts in supply chain management: A game theoretic model. Int. J. Prod. Econ. 2020, 228, 107855. [Google Scholar] [CrossRef]
- Choi, T.M.; Ouyang, X. Initial coin offerings for blockchain based product provenance authentication platforms. Int. J. Prod. Econ. 2021, 233, 107995. [Google Scholar] [CrossRef]
- Harish, A.R.; Wu, W.; Li, M.; Huang, G.Q. Blockchain-enabled digital asset tokenization for crowdsensing in environmental, social, and governance disclosure. Comput. Ind. Eng. 2023, 185, 109664. [Google Scholar] [CrossRef]
- Zhang, S.; Zheng, X.X.; Jia, F.; Liu, Z. Pricing strategy and blockchain technology investment under hybrid carbon trading schemes: A biform game analysis. Int. J. Prod. Res. 2024, 1–22. [Google Scholar] [CrossRef]
- Jayabalan, J.; Jeyanthi, N. Scalable blockchain model using off-chain IPFS storage for healthcare data security and privacy. J. Parallel Distrib. Comput. 2022, 164, 152–167. [Google Scholar] [CrossRef]
- Mahmud, M.; Sohan, M.S.H.; Reno, S.; Sikder, M.B.; Hossain, F.S. Advancements in scalability of blockchain infrastructure through IPFS and dual blockchain methodology. J. Supercomput. 2024, 80, 8383–8405. [Google Scholar] [CrossRef]
- Liu, J.; Jiang, C.; Yang, X.; Sun, S. Review of the application of acoustic emission technology in green manufacturing. Int. J. Precis. Eng. Manuf.-Green Technol. 2024, 11, 995–1016. [Google Scholar] [CrossRef]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J. ultralytics/yolov8: YOLOv8. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 9 July 2023).
- Wang, X.; Garg, S.; Lin, H.; Piran, M.J.; Hu, J.; Hossain, M.S. Enabling secure authentication in industrial iot with transfer learning empowered blockchain. IEEE Trans. Ind. Inform. 2021, 17, 7725–7733. [Google Scholar] [CrossRef]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).