
Measuring Labor Market Status Using Remote Sensing Data


Abstract
:1. Introduction
- Interpolation of Sparse Survey Data. As Bangladesh’s Labor Force Survey (LFS) has only been conducted intermittently (e.g., 2005–2006, 2013, and 2015–2016) [6,7,8] we employ interpolation strategies [9] to generate more continuous annual and quarterly proxies for labor market outcomes, allowing us to fill data gaps and gain insights into trends that are potentially overlooked by traditional methods.
- Integration of High-Frequency Remote Sensing Data. To capitalize on the real-time capabilities of remote sensing, we incorporate monthly observations of NTL and EVI into our forecasting framework. While macroeconomic series like industrial production indices are updated quarterly or annually, satellite imagery is often available at much higher frequencies, enabling us to detect sudden shifts in local economic conditions.
- Mixed-Frequency Forecasting (MIDAS) and Comparison with Traditional Models. We adopt a MIDAS approach [10], which integrates various data frequencies into a single model, enabling higher-resolution tracking of employment trends. Additionally, we compare our forecasts to a traditional ARIMA baseline, emphasizing how remote sensing variables can reveal district-level idiosyncrasies often overlooked by aggregate-only models.
1.1. Research Purpose and Motivation
1.2. Organization of This Paper
2. Data
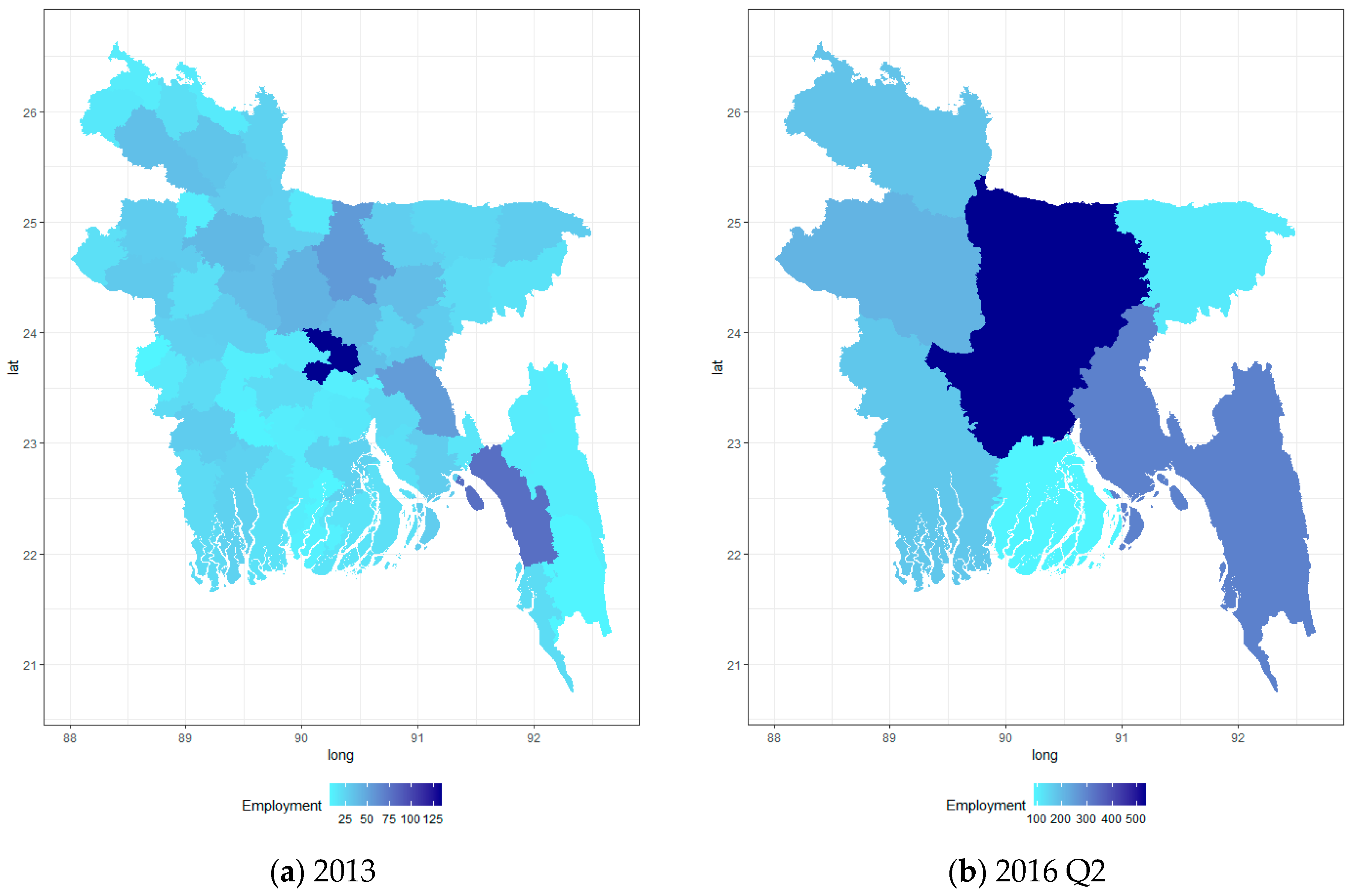
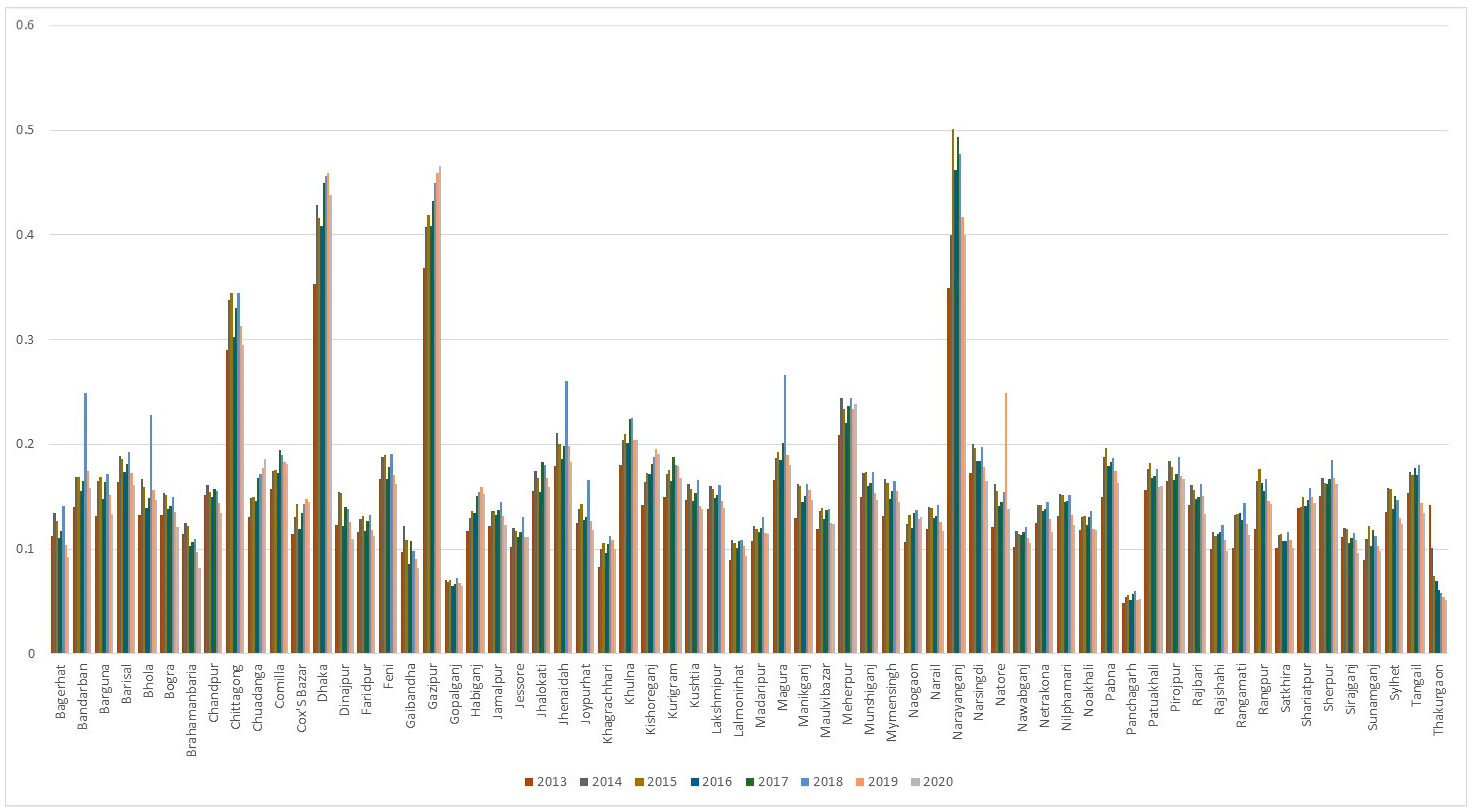
2.1. Survey-Based Employment Measures
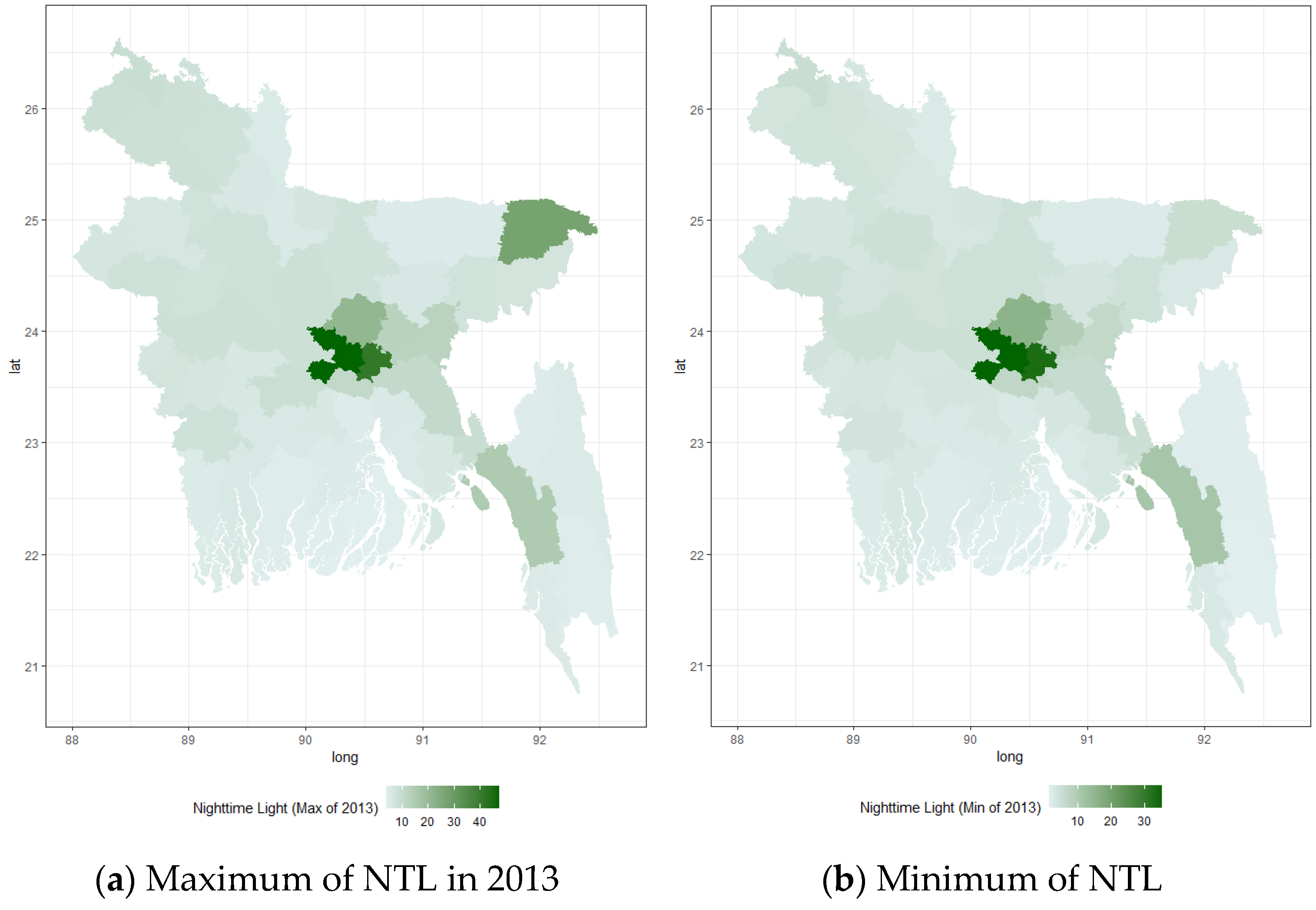
2.2. Satellite-Derived Indicators
- Nighttime Lights (NTL): Obtained from the Visible Infrared Imaging Radiometer Suite (VIIRS) and, historically, from DMSP-OLS archives. These data are available at relatively high frequency (monthly composites or better) and provide a proxy for overall economic intensity.
- Enhanced Vegetation Index (EVI): Derived from Landsat imagery and updated biweekly or monthly, EVI tracks vegetation cover changes that can correspond to shifts in agricultural or other land-use activities.
2.2.1. Nighttime Lights (NTL)
2.2.2. Enhanced Vegetation Index (EVI)
2.3. Macroeconomic Control Variables
- Gross Domestic Product (GDP): Annual aggregates, occasionally extrapolated or back-casted for earlier years.
- Industrial Production Index: Typically reported quarterly, reflecting trends in manufacturing output.
- Property Rental Index, Wage Rate Index: When data are disaggregated by district or urban/rural area, we utilize them to enhance the interpolation of missing labor figures.
- CPI, Inflation, and Compensation of Employees: Annual or quarterly measures that proxy macroeconomic climate and wage conditions.
2.4. Data Assembly and Preprocessing
- District Boundaries: We used shape files from the GADM to align the remote sensing grids with the administrative districts. This step is critical for ensuring consistency between the LFS-based data (originally categorized by district) and the satellite-based measures (which need pixel-level clipping or summation).
- Time Alignment: LFS data points exist only for specific years (2005–2006, 2013, 2015–2016), while remote sensing and macroeconomic series are available at monthly or quarterly intervals. Consequently, each dataset must be resampled or aggregated carefully to create consistent time series for annual, quarterly, or monthly analyses.
- Outlier Detection and Cleaning: Outliers in NTL data outliers (e.g., from ephemeral lighting or sensor drift) and EVI data (e.g., cloud cover misclassification) are flagged and treated cautiously. Consistent with our sustainability emphasis, extreme variations might indicate localized shocks, such as floods, droughts, or industrial booms rather than a measurement error.
- Interpolation: Due to the sparsity of LFS data, we employ interpolation methods [9] in conjunction with ILO-estimated labor figures, wage indices, and other auxiliary series. This procedure yields more frequent estimates (annual or quarterly) of district-level employment rates, distinguishing between “decent” and “non-decent” jobs. Section 3.3 discusses this in detail.
2.5. Linking Data to Sustainability Goals
3. Model
3.1. MIDAS Framework
3.2. Target Variable
- Employer (self-employed with paid employees)
- Self-employed (non-agriculture)
- Paid employee (non-agriculture)
3.3. Interpolation Strategy
- 1.
- Employment-to-population ratio by sex, age and rural/urban areas
- 2.
- Employment by sex, rural/urban areas and occupationThis variable distinguishes the employment by the following occupation:
- Managers
- Professionals
- Technicians and associate professionals
- Clerical support workers
- Service and sales workers
- Craft and related trades workers
- Plant and machine operators, and assemblers
- Elementary occupations and skilled agricultural, forestry and fishery workers
- 3.
- Labor force participation rate by sex, age and rural/urban areas
4. Empirical Results
4.1. Forecasting Model
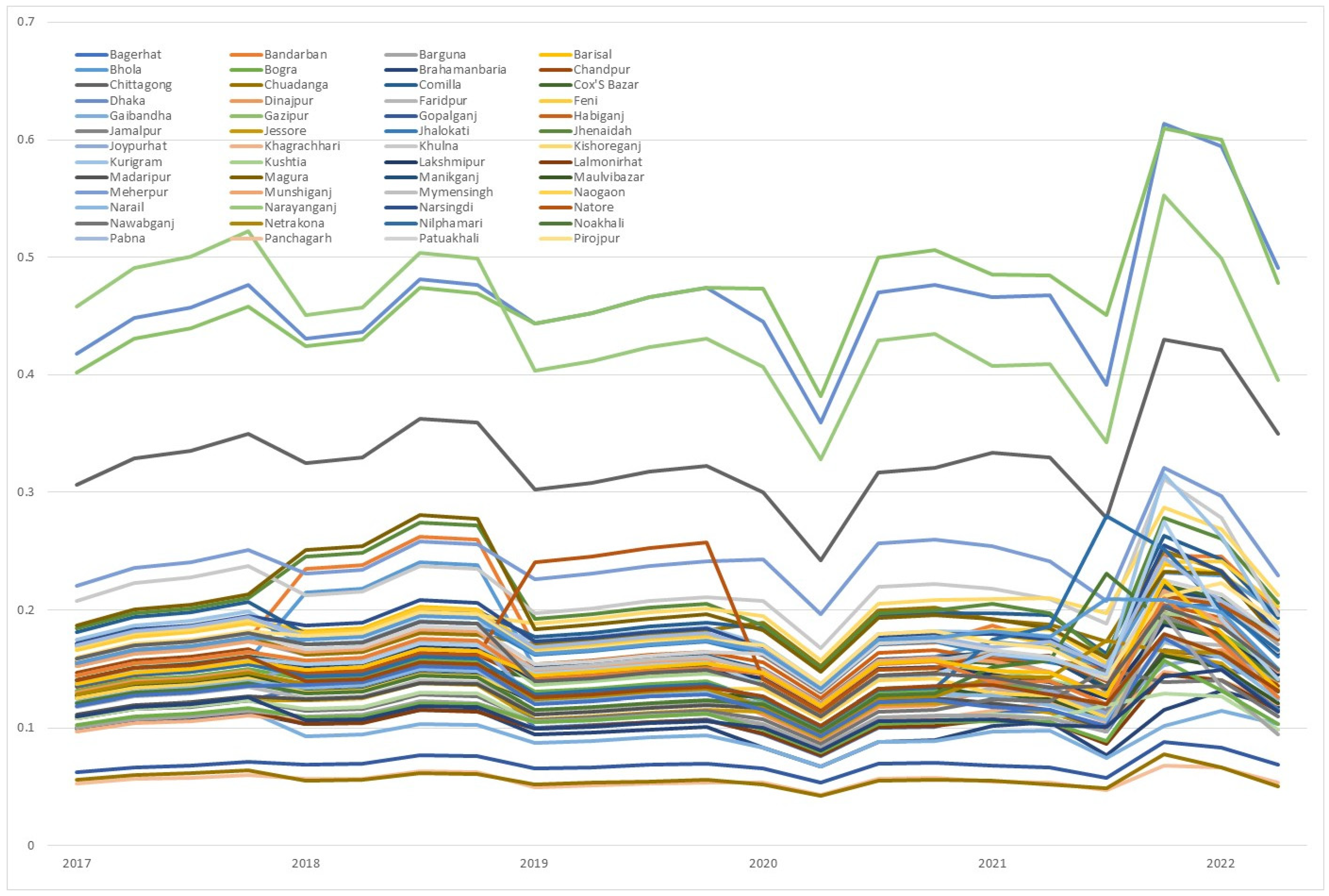
4.2. Estimation Result
5. Conclusions
5.1. Key Findings
5.2. Limitations
5.3. Directions for Future Research
5.4. Concluding Remarks
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Burgess, R.; Hansen, M.; Olken, B.A.; Potapov, P.; Sieber, S. The Political Economy of Deforestation in the Tropics. Q. J. Econ. 2012, 127, 1707–1754. [Google Scholar] [CrossRef]
- Chen, X.; Nordhaus, W.D. Using luminosity data as a proxy for economic statistics. Proc. Natl. Acad. Sci. USA 2011, 108, 8589–8594. [Google Scholar] [PubMed]
- Henderson, J.V.; Storeygard, A.; Weil, D.N. Measuring Economic Growth from Outer Space. Am. Econ. Rev. 2012, 102, 994–1028. [Google Scholar] [PubMed]
- Rahman, S.; Mohiuddin, H.; Kafy, A.-A.; Sheel, P.K.; Di, L. Classification of cities in Bangladesh based on remote sensing derived spatial characteristics. J. Urban Manag. 2019, 8, 206–224. [Google Scholar]
- Wahed, M.; Rizvee, R.A.; Haque, R.R.; Ali, A.M.; Zaber, M.; Ali, A.A. What Can Nighttime Lights Tell Us about Bangladesh? In Proceedings of the 2020 IEEE Region 10 Symposium (TENSYMP), Dhaka, Bangladesh, 5–7 June 2020; pp. 1612–1615. [Google Scholar]
- Bangladesh Bureau of Statistics. Labor Force Survey 2005–2006; The Bangladesh Bureau of Statistics: Dhaka, Bangladesh, 2006.
- Bangladesh Bureau of Statistics. Labor Force Survey 2013; The Bangladesh Bureau of Statistics: Dhaka, Bangladesh, 2013.
- Bangladesh Bureau of Statistics. Labor Force Survey 2015–2016; The Bangladesh Bureau of Statistics: Dhaka, Bangladesh, 2016.
- Chow, G.C.; Lin, A.-L. Best Linear Unbiased Estimation of Missing Observations in an Economic Time Series. J. Am. Stat. Assoc. 1976, 71, 719–721. [Google Scholar]
- Ghysels, E.; Santa-Clara, P.; Valkanov, R. The midas touch: Mixed data sampling regression models. In CIRANO Working Papers, 2004s-20; CIRANO: Barcelona, Spain, 2004. [Google Scholar]
- Keola, S.; Andersson, M.; Hall, O. Monitoring Economic Development from Space: Using Nighttime Light and Land Cover Data to Measure Economic Growth. World Dev. 2015, 66, 322–334. [Google Scholar]
- Faber, B.; Gaubert, C. Tourism and Economic Development: Evidence from Mexico’s Coastline. Am. Econ. Rev. 2016, 109, 2245–2293. [Google Scholar] [CrossRef]
- Foster, A.D.; Rosenzweig, M.R. Economic Growth and the Rise of Forests. Q. J. Econ. 2003, 118, 601–637. [Google Scholar] [CrossRef]
- Foster, A.; Gutierrez, E.; Kumar, N. Voluntary Compliance, Pollution Levels, and Infant Mortality in Mexico. Am. Econ. Rev. 2009, 99, 191–197. [Google Scholar] [PubMed]
- Costinot, A.; Donaldson, D.; Smith, C. Evolving Comparative Advantage and the Impact of Climate Change in Agricultural Markets: Evidence from 1.7 Million Fields Around the World. J. Political Econ. 2016, 124, 205–248. [Google Scholar]
- Jayachandran, S.; de Laat, J.; Lambin, E.F.; Stanton, C.Y. Cash for Carbon: A Randomized Controlled Trial of Payments for Ecosystem Services to Reduce Deforestation; Northwestern University: Evanston, IL, USA, 2016. [Google Scholar]
- Marx, B.; Stoker, T.M.; Suri, T. There is No Free House: Ethnic Patronage in a Kenyan Slum. Am. Econ. J. Appl. Econ. 2015, 11, 36–70. Available online: http://www.mit.edu/~tavneet/Marx_Stoker_Suri.pdf (accessed on 16 March 2025). [CrossRef]
- Donaldson, D.; Storeygard, A. The View from Above: Applications of Satellite Data in Economics. J. Econ. Perspect. 2016, 30, 171–198. [Google Scholar] [CrossRef]
- Hu, Y.; Yao, J. Illuminating Economic Growth. In IMF Working Paper WP/19/77; International Monetary Fund: Washington, DC, USA, 2019. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Source | Economics Applications | Highest Resolution | Pricing | Availability by Years | Examples | Address |
|---|---|---|---|---|---|---|
| Landsat | Urban land cover, beaches, forest cover, mineral deposits | 30 m | Free | 1972—(8 satellites) | [12,13] | https://goo.gl/Xhqya5, accessed on 16 March 2025 |
| MODIS | Airborne pollution, fish abundance | 250 m | Free | 1999—(Terra); 2002—(Aqua) | [1,14] | https://goo.gl/NhHU6x, accessed on 16 March 2025 |
| Night lights (DMSP-OLS, VIIRS) | Income, electricity use | ~1 km | Free digital annual (DMSP-OLS) and monthly (VIIRS) composites | Digital archive 1992–2013+ (VIIRS 2012–; film archive 1972–1991) | [2,3] | https://goo.gl/vdIksu, accessed on 16 March 2025 |
| SRTM | Elevation, terrain roughness | 30 m | Free | 2000 (static) | Ref. [15] via Global AgroEcological Zones (GAEZ) data | https://goo.gl/6zKR4x, accessed on 16 March 2025 |
| DigitalGlobe (including Quickbird, Ikonos) | Urban land cover, forests | <1 m | Not free | 1999—(6 satellites) | [16,17] | https://goo.gl/0rL1nW, accessed on 16 March 2025 |
| Dependent | Explanatory | Sources | |
|---|---|---|---|
| Employment (From the survey) | Remote Sensing data | Daily
|
|
| From the survey (as control variables) |
|
| |
| Formal data (as control variables) | Annual
|
| |
| Employment Status | Agriculture | Industry | Service | Not Specified | Total |
|---|---|---|---|---|---|
| 1 [Employer (Self-employed with paid employee)] | 612,116 | 310,375 | 750,686 | 7565 | 1,680,742 |
| 2 [Self—employed] | 11,727,356 | 2,008,217 | 11,614,597 | 72,823 | 25,422,993 |
| 3 [Contributing family member] | 7,278,337 | 280,103 | 926,659 | 16,313 | 8,501,412 |
| 4 [Paid Employee] | 265,633 | 5,892,673 | 7,169,274 | 56,904 | 13,384,483 |
| 5 [Day laborer] | 4,489,995 | 4,253,450 | 1,494,065 | 9888 | 10,247,398 |
| 6 [Apprentices/intern/trainees (If paid)] | — | 26,270 | 41,224 | 134 | 67,628 |
| 7 [Domestic worker] | 13,146 | 36,483 | 503,511 | 2074 | 555,214 |
| 9 [Others (Specify)] | 58,732 | 87,234 | 129,928 | 1759 | 277,653 |
| Subtotal | 24,445,315 | 12,894,805 | 22,629,944 | 167,459 | 60,137,523 |
| Not employed(including Not in Labor Force) | — | — | — | 98,345,011 | 120,275,046 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, H.H. Measuring Labor Market Status Using Remote Sensing Data. Sustainability 2025, 17, 2807. https://doi.org/10.3390/su17072807
Kim HH. Measuring Labor Market Status Using Remote Sensing Data. Sustainability. 2025; 17(7):2807. https://doi.org/10.3390/su17072807
Chicago/Turabian StyleKim, Hyun Hak. 2025. "Measuring Labor Market Status Using Remote Sensing Data" Sustainability 17, no. 7: 2807. https://doi.org/10.3390/su17072807
APA StyleKim, H. H. (2025). Measuring Labor Market Status Using Remote Sensing Data. Sustainability, 17(7), 2807. https://doi.org/10.3390/su17072807