1. Introduction
Machine learning, and in particular deep learning, have become increasingly popular in recent years. However, deep learning algorithms are still primarily trained using supervised learning, which requires a substantial amount of annotated training data. There exist many publicly available datasets for training deep learning systems [
1]; however, when it comes to domain-specific applications such as plant detection and recognition, the availability of data is significantly reduced [
2].
Alternatively, generative models can be used to extend the amount of available data by producing artificial data samples that mimic properties of real data. Recently, a new type of generative models called generative adversarial networks (GANs) were introduced by Goodfellow et al. [
3]. While GAN models can be used in many different generative applications, they are most often used for generating artificial images. A strength of the GAN models is that they can be trained using an unsupervised and/or supervised end-to-end learning approach [
4,
5,
6]. Previous research has shown that artificial GAN samples can be used as data augmentation to increase the performance of several visual recognition tasks [
7,
8,
9,
10].
GAN models have also been applied to the modeling of plants or plant seedlings. The primary focus has been on increasing the amount of available training data for applications, such as leaf counting [
11,
12] or species classification [
13]. The aforementioned models all use a supervised learning approach, conditioning the models based on leaf count, plant species, or full segmentation masks. Besides this conditioning, the models provide little control over the appearance of the generated samples. In other domains, unsupervised learning schemes have been used to adopt greater control of over the appearance of the generated samples. For example, the infoGAN model by Chen et al. [
4] has shown that it is possible to adapt dominating modalities in the data by adding additional unsupervised conditioning on the model.
In this work, we present an extension of the WacGAN model by [
13], which is used to produce artificial images of plant seedlings. We designate this extended model WacGAN-info. The extension consists of adding an unsupervised learning branch to the GAN configuration, similar to infoGAN [
4], which enables control over the artificial samples’ visual appearance through an additional set of latent input variables. The unsupervised learning branch also enables the WacGAN-info model to produce samples that visually and quantitatively have a greater resemblance to real plant seedlings, compared with those produced by the WacGAN model. Additionally, we show that the GAN disciminator network can be used as a tool to prevalidate the quality of the artificial WacGAN-info samples. This prevalidation enables us to remove samples with poor class representation from the artificial data distribution, which leads to a further increase in resemblance to real samples.
2. Methods
GANs are a configuration of two neural network architectures: a generator network, G, and a discriminator network, D. Both networks are trained using an adversarial learning scheme, where the two networks are competing against each other. D is responsible for distinguishing between the samples from the real and artificial data distributions, whereas G produces artificial samples that mimic real samples in order to cheat D into making mistakes.
The GAN model presented in this work is an extension of the WacGAN model by Madsen et al. [
13]. The extension incorporates an additional unsupervised learning branch, as inspired by the infoGAN model by Chen et al. [
4]. We designate this configuration WacGAN-info. WacGAN-info is a semi-supervised generative model that is capable of producing visually distinct samples for each class while still maintaining a relatively high amount of variance within each of these. The model also provides control of the visual content through a set of latent variables. This is achieved by adding a noise variable to the generator input, which the discriminator output is forced to recreate from the generated sample.
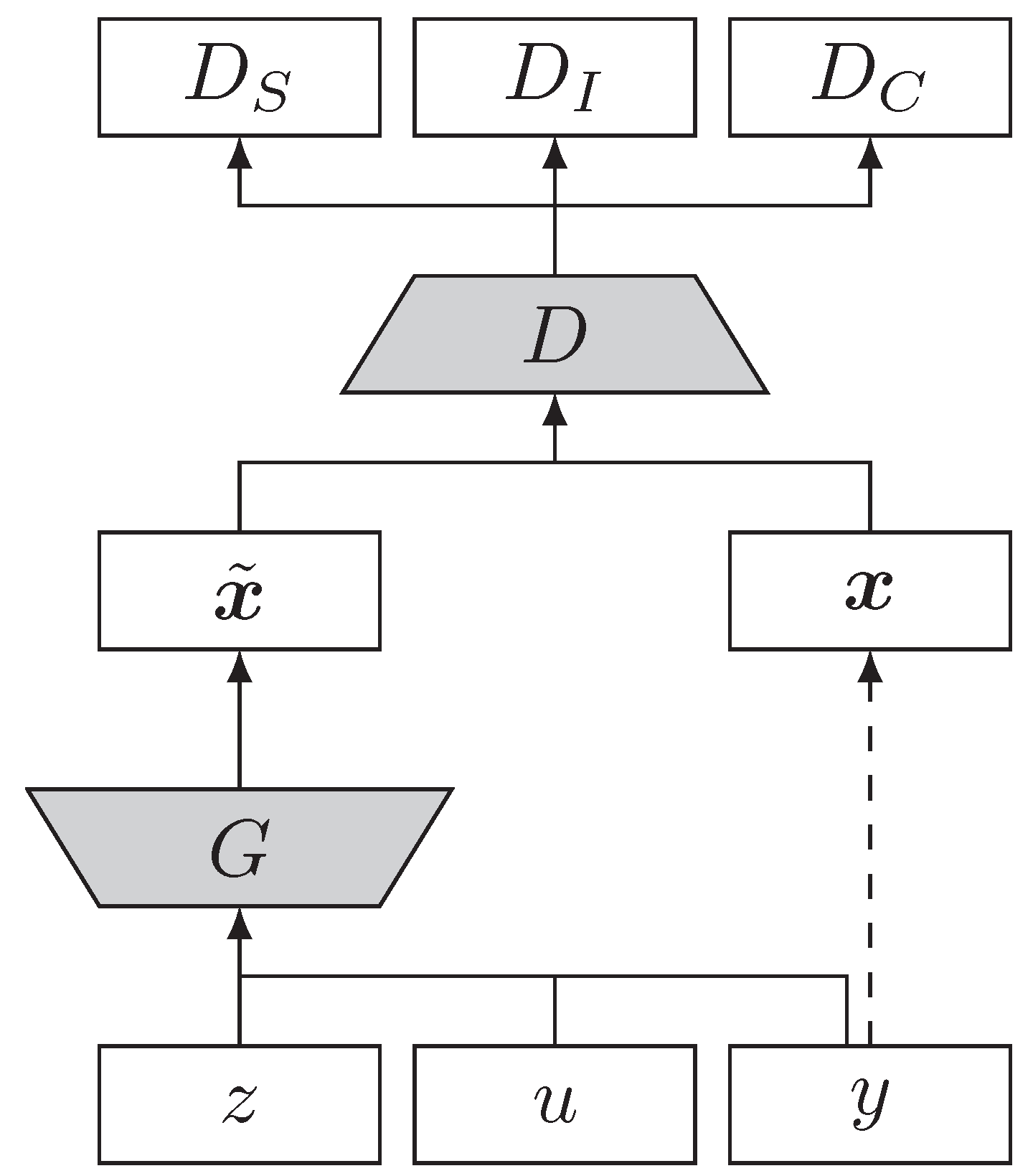
The configuration of WacGAN-info is visualized in
Figure 1. The figure shows how
G inputs three vectors:
z,
y, and
u, representing random noise, class encoding, and latent info encoding, respectively. The output from
G is an artificial data sample,
. Additionally,
D inputs either real data samples,
, or artificial data samples,
. The output of
D are three parallel signals:
,
, and
, which correspond to the estimation of the data source distribution (real or artificial samples), the class, and the latent info variable, respectively.
2.1. Objective Function
The objective function is divided into three parts: a source loss, , a class loss, , and an info loss, .
The source loss,
, is responsible for distinguishing between the real and artificial data distributions given the discriminator output,
.
is implemented as a Wasserstein loss with gradient penalty, which provides a high degree of diversity in the generated samples [
16].
is given by
where
is the real data distribution and
is the artificial data distribution implicitly defined by
, [
16].
is a random sample distribution generated from random interpolation between the real and artificial samples [
16].
The class loss,
, is responsible for guiding the generator to produce samples, which are visually distinguishable for each separate class.
is implemented as the cross-entropy loss between the one-hot encoded class label,
y, and the output of the discriminator’s classification branch,
[
4,
23].
is given by:
where
is the number of classes.
Finally, the info loss,
, ensures information preservation throughout the network, thus allowing the content of the generated samples to be controlled through a set of latent variables,
u, as inspired by Chen et al. [
4].
is implemented as the mean square loss between the intended info variables
u and the predicted info variables of the discriminator
and is given by
where
is the number of latent variables.
The discriminator is trained to minimize , whereas the generator is trained to minimize . and are weight terms used to regulate the relative importance between the source loss, the class loss, and the info loss. The values of the and are determined empirically through experiments.
2.2. Network Design
The network architectures of the WacGAN-info model are inspired by the ACGAN model by [
6]. As WacGAN-info is an extension of previous work [
13], we apply the same modifications of the original ACGAN architecture. Additionally, the networks have been modified to accommodate for the additional information branch by adding a set of latent variables,
u, as input to the generator and an additional output,
, to the discriminator to reproduce
u.
u are drawn from a random uniform distribution
.
u are concatenated with the categorical class encoding
y and the noise vector
z. The
is implemented as a fully connected layer in parallel with the source discriminator,
, and the class discriminator,
, (
Figure 1). The full implementation is summarized in
Appendix A.1.
2.3. Evaluation
The artificial samples were evaluated qualitatively and quantitatively to assess their quality. In the qualitative evaluation, we performed a visual inspection of the artificial samples to provide a subjective assessment of the sample’s quality. The visual inspection was primarily used to assess the realism of the artificial samples (Does the sample look as a realistic plant?), as to our knowledge, there does not exist a quantitative metric to measure the realism of images.
In the quantitative evaluation, the class discriminability (How well does the artificial sample represent the intended species?) was evaluated by processing each sample using an external state-of-the-art classifier trained for plant species classification. Previously, the inception score [
24] has been widely adopted as a metric for measuring the class discriminability in GAN research [
5,
6,
16,
21]. Madsen et al. [
13] apply a similar approach where the external classifier is instead based on the ResNet-101 architecture [
25], which is fine-tuned for plant seedling classification. To be able to directly compare the results, we applied the same external classifier as in [
13]. The configuration of the external ResNet-101 classifier is summarized in
Appendix A.2. The class discriminability is reported as the recognition accuracy, which indicates how often the artificial samples are correctly classified as the intended species by the external classifier [
13]. Perfectly generated artificial samples will be indistinguishable from the real samples in terms of classification accuracy by the ResNet-101 classifier.
We applied the same leave-
p-out cross validation scheme as Madsen et al. [
13] to avoid data leakage in the quantitative results [
26] and to be able to directly compare our results to Madsen et al. [
13]. By splitting the real data into four parts and using a
p of
, we get six combinations of training and test sets. For each combination, the external ResNet-101 classifier was trained on the associated training set and the WacGAN-info model was trained on the corresponding test set. Thus, the WacGAN-info model could be used to generate an additional test-set of artificial samples for the class discriminability test on the ResNet-101 classifier.
3. Results
Both the WacGAN-info model and the external ResNet-101 classifier were trained on the segmented plant seedling dataset (sPSD) by Giselsson et al. [
27]. This dataset consists of segmented RBG images of plant seedlings from twelve different species. However, in this work, we have ignored all grass species as these are not properly instance segmented. This left nine species (
) remaining in the dataset. The plant species are identified by their European and Mediterranean Plant Protection Organization (EPPO) codes [
28] throughput the paper. Due to the network’s architecture, the WacGAN-info model only supports input images with a resolution of
pixels. To maintain a relatively low resizing factor, all images with a resolution of >400 pixels in either dimension are excluded from the dataset. This results in a resizing factor of
. The remaining species and number of samples for each of these are summarized in
Table 1.
To train the WacGAN-info model, all of the images were preprocessed by: zero-padding to achieve a resolution of pixels, random rotation of the image, central crop of pixels, and finally, resizing to pixels using bilinear interpolation. This data augmentation approach is also used for training of the external ResNet-101 classifiers.
The regularization weights,
and
, are set to
and 15, respectively. As mentioned, these values are determined empirically and provide a good trade-off between intra- and inter-class diversity in the artificial samples, while allowing the latent variables to adapt dominating modalities in the data. The length of the noise vector,
z, is set to 128, as inspired by previous work [
13]. The following results are produced using two latent variables (
). A full summary of the hyperparameters can be found in
Appendix A.1.
3.1. Visual Image Quality Assessment
Table 2 show examples of artificial plant seedlings generated using the WacGAN-info model. The table also includes examples of real plant seedlings and artificial samples from the WacGAN model to provide references for the visual evaluation. The 16 WacGAN-info samples for each species were generated using the same fixed random noise vectors—only the class encoding changes. This shows that the WacGAN-info model is capable of producing visually distinct samples for each of the different species present in the sPSD, as the appearance of the samples changes for each column.
The artificial samples themselves are composed of a number of leaves that are distributed around the image/plant center. Compared to the samples produced in Madsen et al. [
13], the WacGAN-info model is capable of generating more detailed shape and textural features; e.g., the WacGAN-info model has become better at generating thin features such as stems or small leaves. The texture across a single leaf can also assume different gradients of green, whereas previously, the texture mainly consisted of a single green color. Additionally, the borders between the plant and background are more smooth for the WacGAN-info sample, whereas the WacGAN samples [
13] are more rough around the edges.
At closer inspection of the generated samples, some image artefacts can be observed. The artefacts can be described as pixel errors, which mainly occur along the border of the artificial samples or in a systematic grid in the texture.
Figure 2 shows a severe example of these errors.
3.1.1. Disentangled Information Space
Figure 3 shows how the appearance of the artificial samples depends on the values of the two latent variables,
and
. Although a few outliers are observed, the latent variables can, in this example, be used to control the rotation and the size of the artificial plant samples; e.g., the samples in the left-hand side of the plot are larger compared to those in the right-hand side, indicating that the size of the artificial samples is inversely related to the value of
. Additionally, the samples in the bottom of the plot are primarily oriented vertically with respect to the primary axis of the plant, whereas samples in the top are oriented horizontally, indicating that
models the rotation of the samples.
Figure 3 only show the results from a single species, but a similar trend is observed across the other species as well. It should be noted that this specific trend is not unanimous across the six different models as they are trained on different parts of sPSD.
3.2. Class Discriminability
To assess the class discriminability of the artificial samples, 10,000 samples from each class ere generated from each of the six WacGAN-info generators and subsequently evaluated on the corresponding external ResNet101 classifiers along with the corresponding real data test sets (
Table 3). The artificial data achieves
average recognition accuracy when analyzed on the external classifiers. The average accuracy for recognizing real data samples is of course better compared to the artificial. However, the best-performing class on the artificial data (STEME) performs better than the worst-performing class on the real data (CAPBP). The average recognition accuracy for each class shows a strong positive linear correlation to the number of real samples for each class in both the real data (
) and the artificial data (
).
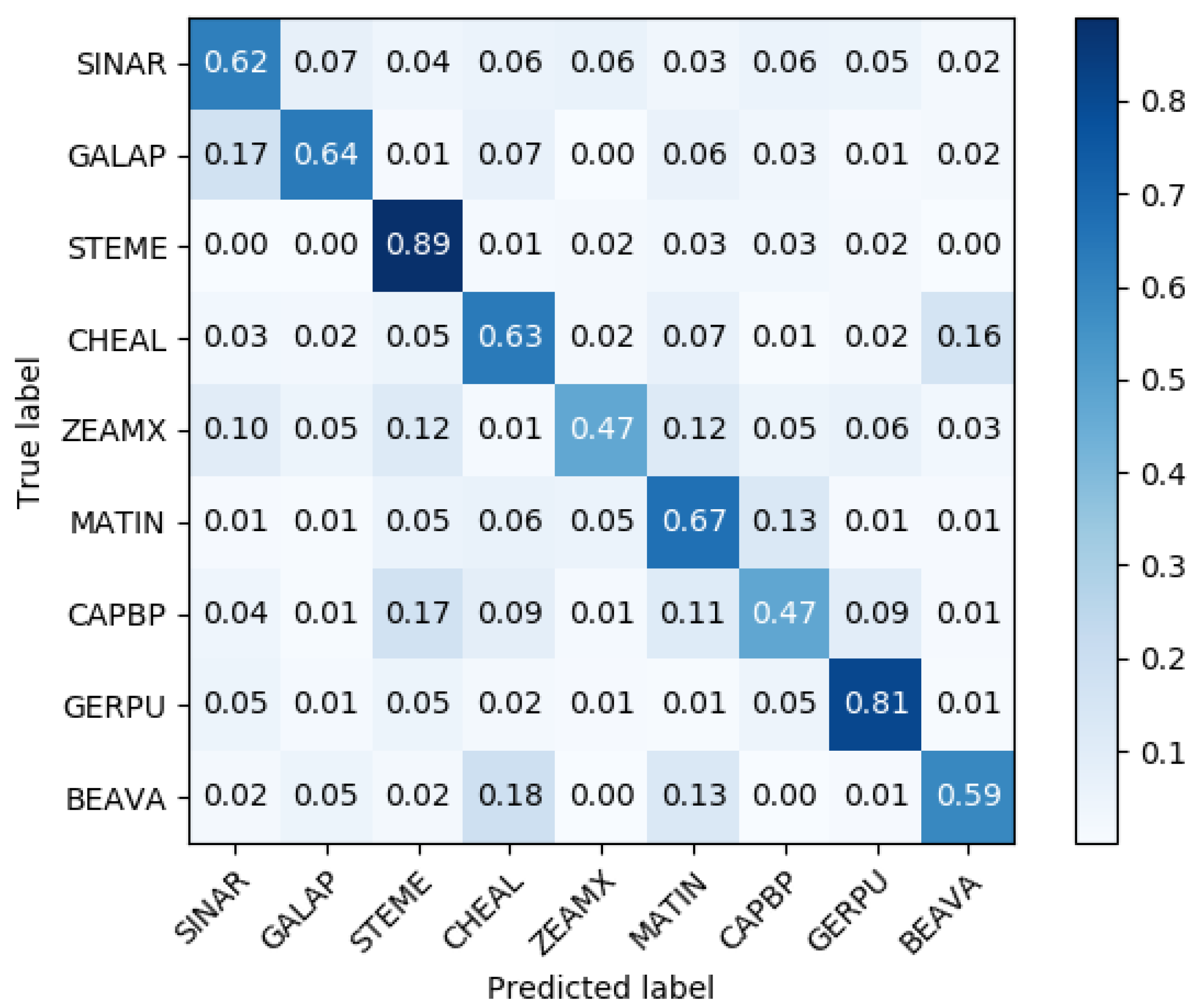
From the confusion matrix (
Figure 4), it is clear that there is a good correspondence between the true labels and the predicted labels on the artificially generated data. The misclassifications (the off-diagonal entries in the confusion matrix) are generally fairly uniformly distributed among the other species; however, a few notable misclassifications do appear, which are significantly larger than the other misclassifications. These can be grouped into two groups: (1) one-way misclassifications and (2) two-way misclassifications. The two-way misclassifications are misclassifications between two species, which are both significantly larger than the other misclassifications (CHEAL ⇄ BEAVA, and MATIN ⇄ CAPBP). The misclassifications between CHEAL and BEAVA occur in samples mimicking the early growth stages, where both species are highly similar with respect to visual appearance. A large portion of the mislcassifications from BEAVA to CHEAL also includes examples of large broad leafs mixed with more elongated leafs, traits that occur in the real examples of CHEAL but not BEAVA. In the one-way misclassifications, there is only a significant misclassification from one species to the other, but not the other way around (CAPBP → {STEME, GERPU, CHEAL}, ZEAMX → {STEME, MATIN, SINAR}, GALAP → SINAR, and BEAVA → MATIN). These misclassifications generally happen from species with relatively few samples to species with relatively many classes in the real dataset. A notable exception to this is the misclassification of GALAP as SINAR, which contain approximately the same number of samples in the real dataset. These misclassifications consists of two medium-sized round leafs connected by a small stem. Although the GALAP real data does contain samples with these leafs, the trait occurs much more frequently in the SINAR real data.
Using the GAN Descriminator to Prevalidate Sample Quality
The recognition accuracies reported in
Table 3 are based on all samples generated by the WacGAN-info model. However, the classification branch of the discriminator,
, can be used to perform a prevalidation of the artificial samples. Due to the softmax activation,
outputs a confidence of how well a sample represents each class. Thus, by examining the discriminator’s confidence in the intended class for each artificial sample, we can assure better class representations.
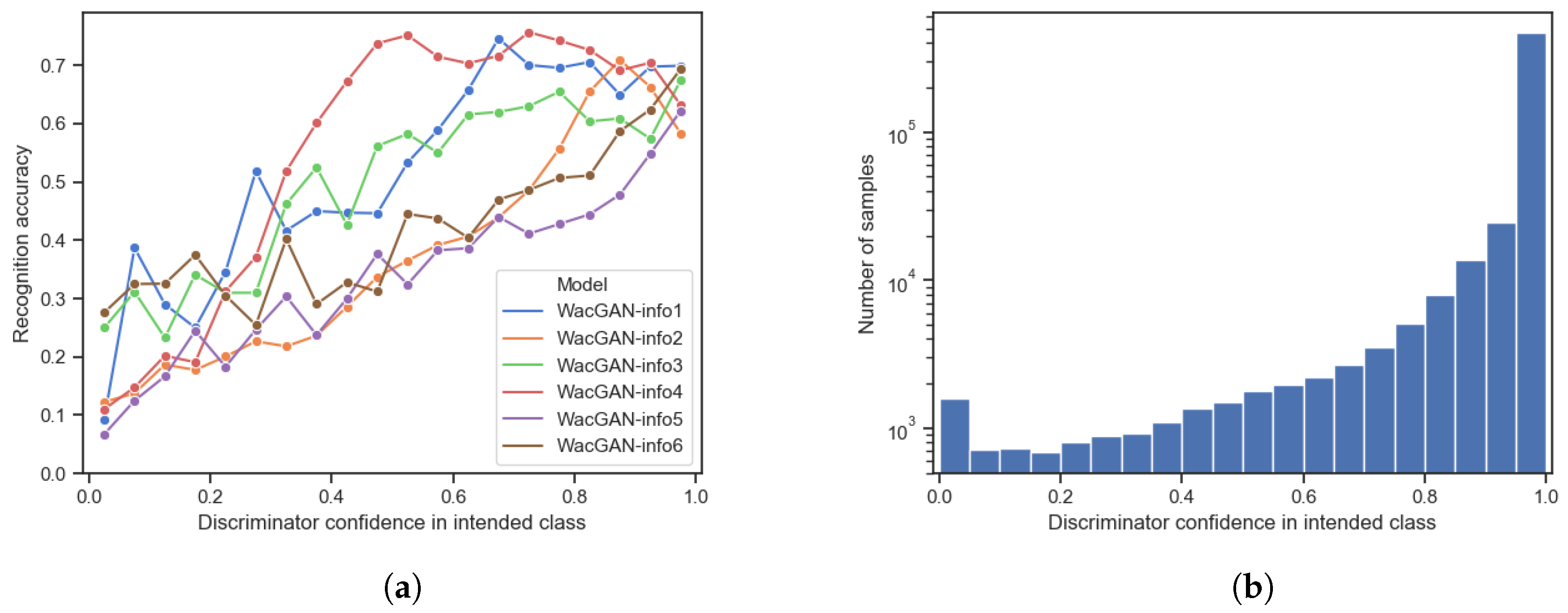
Figure 5 shows the average recognition accuracy (
Figure 5a) and the sample distribution (
Figure 5b) as a function of the discriminator’s confidence in the samples representing the intended class. The figure shows that the artificial samples generally get recognized as the intended class more often by the external classifier, if the discriminator also has high confidence in the samples belonging to the intended class. Thus, it is possible to remove samples with poor class representations by applying a threshold on the discriminator’s confidence in each sample. Additionally,
Figure 5b shows that the WacGAN-info discriminator has high confidence in the majority of the artificial samples, so if we threshold on the discriminator confidence, we only remove a small part of the data; e.g., by including only samples with a discriminator confidence greater than
, the average recognition accuracy across the six models increases from
to
, while still including the
of the artificial samples.
4. Discussion
The results show that the WacGAN-info model is capable of producing artificial samples that resemble real plant seedlings. Furthermore, it seems that the model is capable of reproducing samples that are relatively distinguishable across the nine different plant species while simultaneously ensuring a relatively high degree of variability in the samples for each class.
Although the WacGAN-info samples visually resemble real plant seedlings, there are still some obvious errors in the artificial samples. The errors are mainly related to unrealistic or inaccurate reproductions of the plant leaves, where multiple leaves have merged into one or one has been split into two or more; e.g., inspecting the samples of ZEAMX, some of these resemble dicots although ZEAMX is a monocot species (see the first and last samples in
Table 2). These visual errors may be reduced by increasing the class loss weight,
, which seems to provide better inter-class diversity but comes at the cost of reducing the intra-class diversity.
The observed pixel errors in the samples are probably related to the applied generator architecture as the border errors could be related to the relatively large output kernel (
) and the grid pattern matches with strides of 2 used for the up-sampling. Similar errors were observed in the original ACGAN [
6] paper and in the previous work by Madsen et al. [
13]; however, based on visual inspection, the issue seems to have been reduced for the WacGAN-info model.
Section 3.1.1 shows that it is possible to control the appearance of the generated samples through the latent information variables. As expected, the information variables capture dominating modalities in the data, such as the size and rotation of the samples. Although the two latent variables control similar properties in all six WacGAN-info models, it should be noted that the specific trend observed in
Figure 3 is not representative of all models. This is an effect of the models being trained on different dataset splits and due to the unsupervised learning scheme applied in the information learning branch, which causes the models to adopt slightly different trends. In this work, we only present results using two uniformly distributed information variables (
); the setup can easily be extended to facilitate more, but adding more latent variables quickly increases the complexity of interpreting their underlying representation.
The class discriminability test (
Section 3.2) also shows that the artificial samples resemble the intended species to a relatively high degree. The reported average recognition accuracy is
(see
Table 3), which is well above uniformly distributed random guessing, which would yield
. Compared to Madsen et al. [
13], this result shows a 5.4% point increase in the overall recognition accuracy and a 4.4% point decrease in the standard deviation thereof. As this work is an extension of Madsen et al. [
13], the GAN setup is relatively similar. tThe main difference is that the WacGAN-info model includes the additional latent information variables
u and information discriminator
. This shows that the addition of the latent information variables not only helps control the appearance of the generated samples but also helps to increase the discriminability of the species.
The observed errors in the class discriminability test appear to mainly stem from class imbalance in the real training data, as artificial samples from species with more training samples generally achieve higher recognition accuracies. This issue might be reduced by balancing the distribution between the classes in the training. Additionally, the observed errors are also related to species, which are visually similar at the early growth stages. This is probably a result of the models incapability of reproducing small textural and shape details. Through visual inspection of the errors, it is also observed that some samples include attributes that are not present in the “true” species, but only in the “misclassified” samples. This shows attribute leakage between the species examples produced by the generator and that the generator has not fully learned what constitutes each species and what separates them. This leakage mainly occurs in the generated samples of larger plants. Many plant species develop their visual characteristics as they grow larger. However, in this work, we have removed many of the larger samples (>400 pixels in either dimension) to maintain a relatively small resizing factor in the preprocessing of the images. By including these larger images in the training, it might be possible to learn more about the individual species characteristics and avoid some of the above-mentioned errors. However, to include these larger images, we would need larger network architectures for the generator and the discriminator, which would make the training more unstable [
6]. A potential solution could be to apply a more advanced conditioning scheme [
21,
22] or a progressive growing GAN training approach [
29].
Section 3.2 showed that it is possible to remove samples with poor class representation from the artificial data distribution by evaluating the discriminator’s confidence in each artificial sample. This enables us to only select samples that have a relatively higher resemblance to real plant seedlings, which is relevant if the samples are used for data augmentation purposes or in transfer learning, as previously shown in [
13]. However, the selection process may remove some variability from the artificial samples, but probably not anything too severe since
of the samples remain even with a
confidence threshold of >0.95.
5. Conclusions
In this paper, we have shown that the WacGAN-info model is capable of producing artificial samples from nine different species. The artificial samples resemble the intended species with an average recognition accuracy of evaluated using an external state-of-the-art classification model, which is an improvement of points compared to previous work. The observed errors are mostly related to class imbalances in the training data or to the applied network models, which are incapable pf reproducing small textural and shape details in the samples. We have also shown that it is possible to apply an unsupervised conditioning scheme in the training of WacGAN-info, which enables control over the visual appearance of the samples through a set of latent variables. Specifically, we show that it is possible to control the orientation and size of the samples through two latent variables. Finally, we have shown that it is possible to apply the discriminator as a quality assessment tool, which can be used to remove samples with poor class representation from the artificial data distribution, further increasing the recognition accuracy to .

 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













