Classification of PolSAR Image Using Neural Nonlocal Stacked Sparse Autoencoders with Virtual Adversarial Regularization

Abstract
:1. Introduction
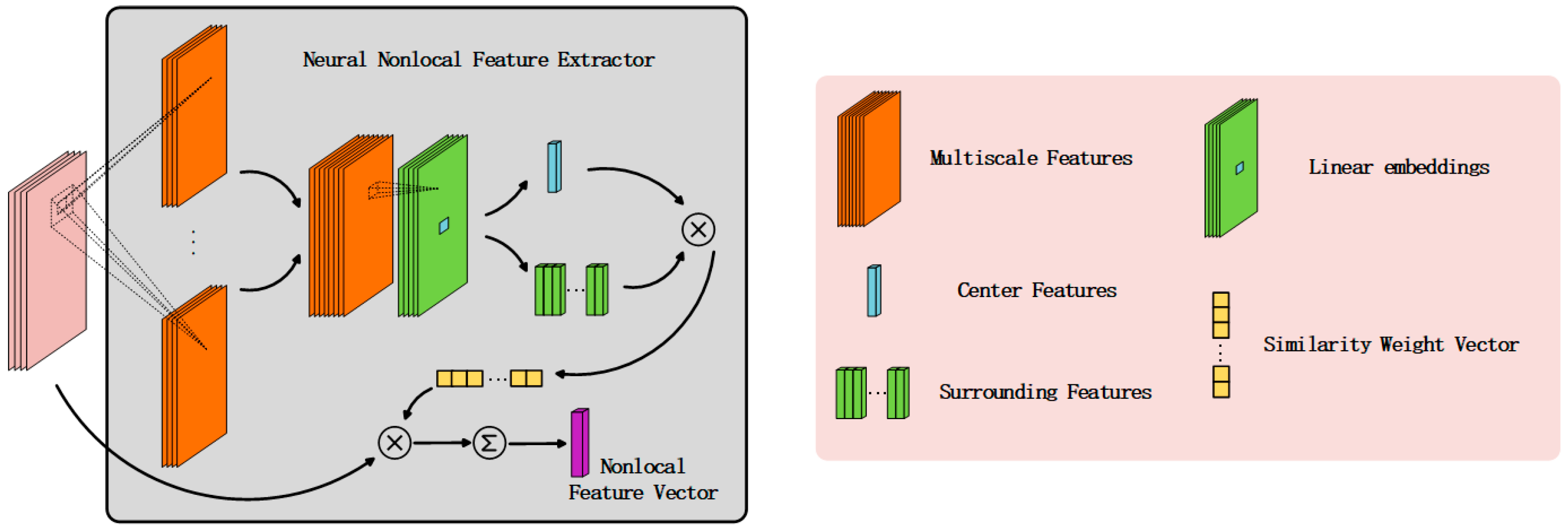
- We propose the neural nonlocal feature extractor, which introduces neural nonlocal similarity calculation into PolSAR image classification task to extract nonlocal spatial information around each pixel. The nonlocal spatial features generated by NNFE are automatically optimized, which improves the robustness and the classification accuracy of the model.
- In NNFE, we introduce a multiscale spatial information extractor implemented as convolution layers, which maps every pixel in image patches into latent space and considers both of their characteristics and their spatial information.
- Virtual adversarial training regularization term is introduced into the loss function to further improve the classification accuracy and the ability of generalization of the model.
2. Related Works
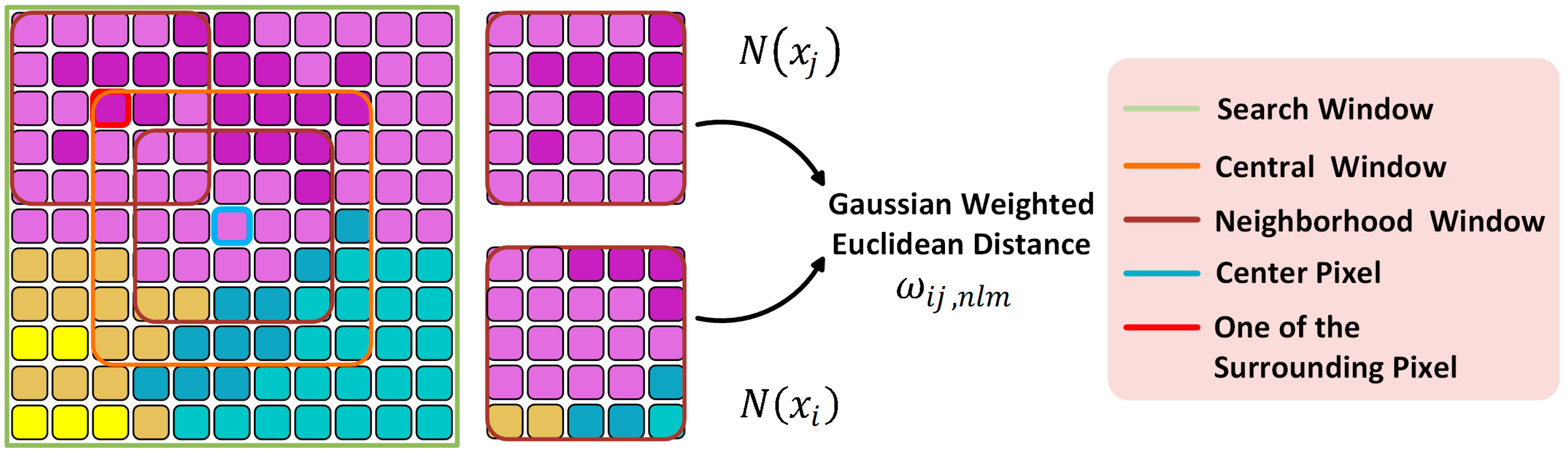
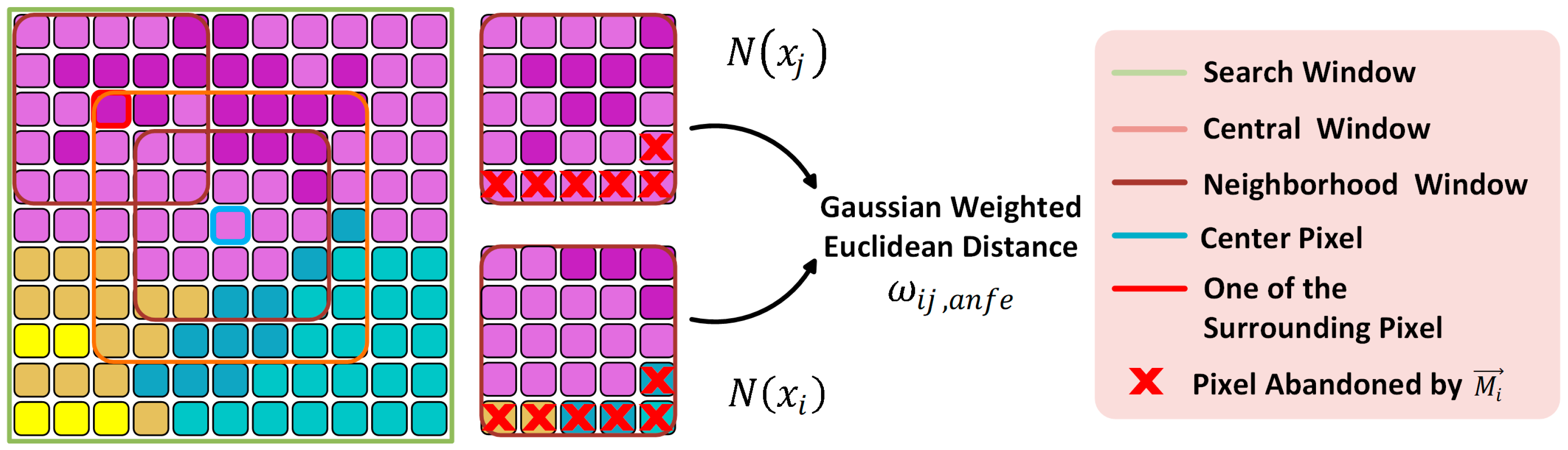
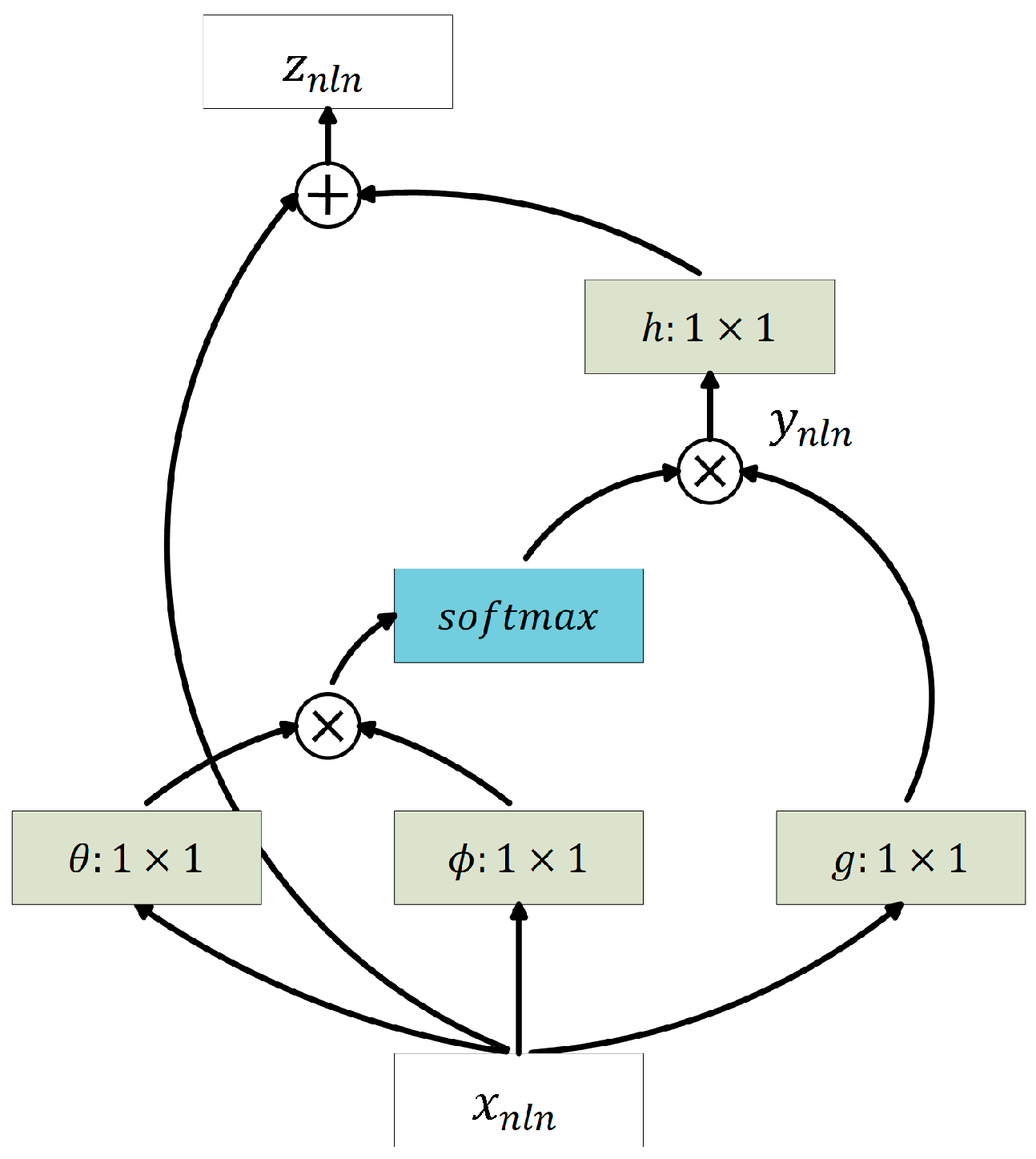
2.1. Nonlocal Feature Extraction Methods
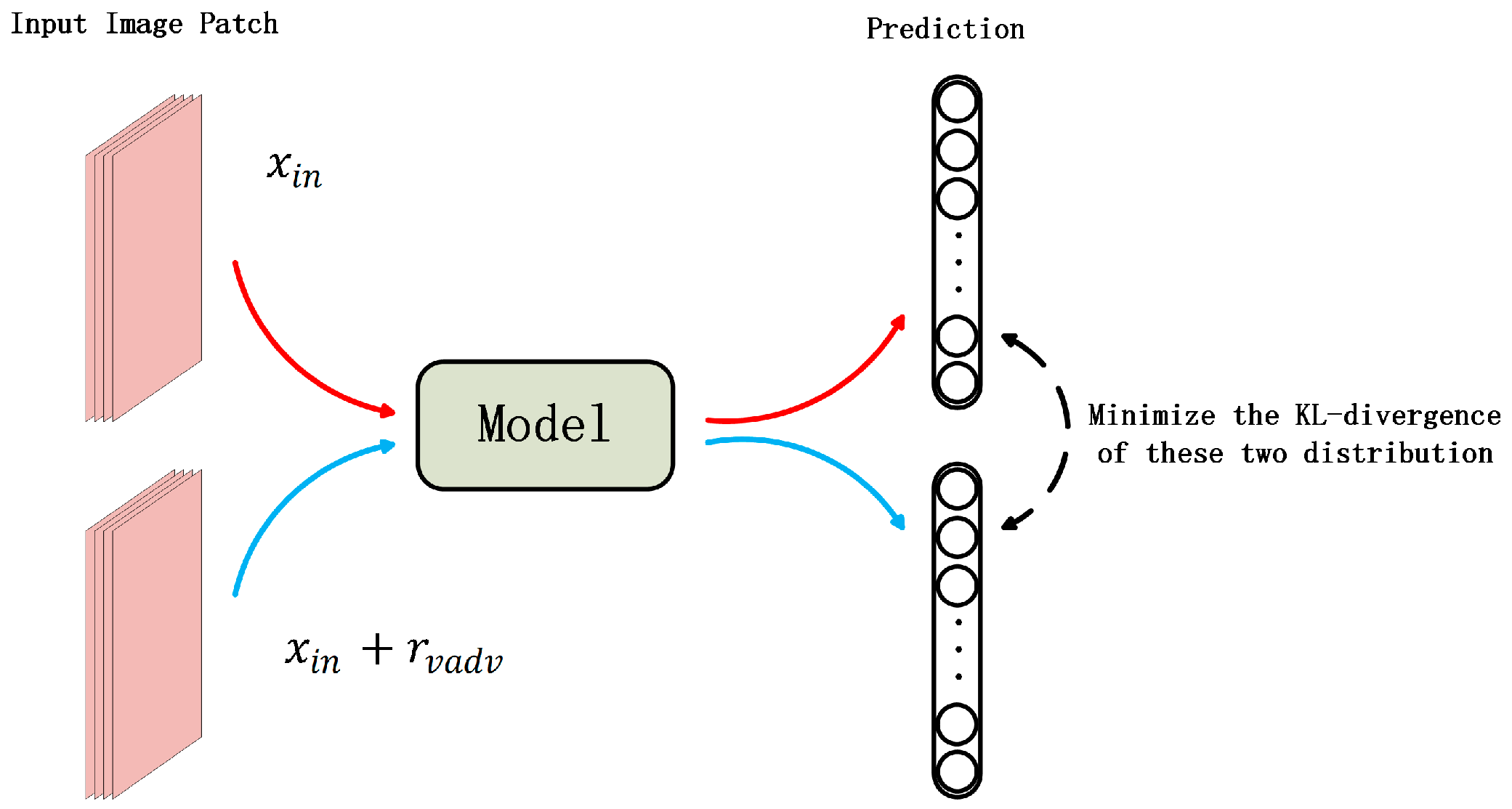
2.2. Virtual Adversarial Training Regularization
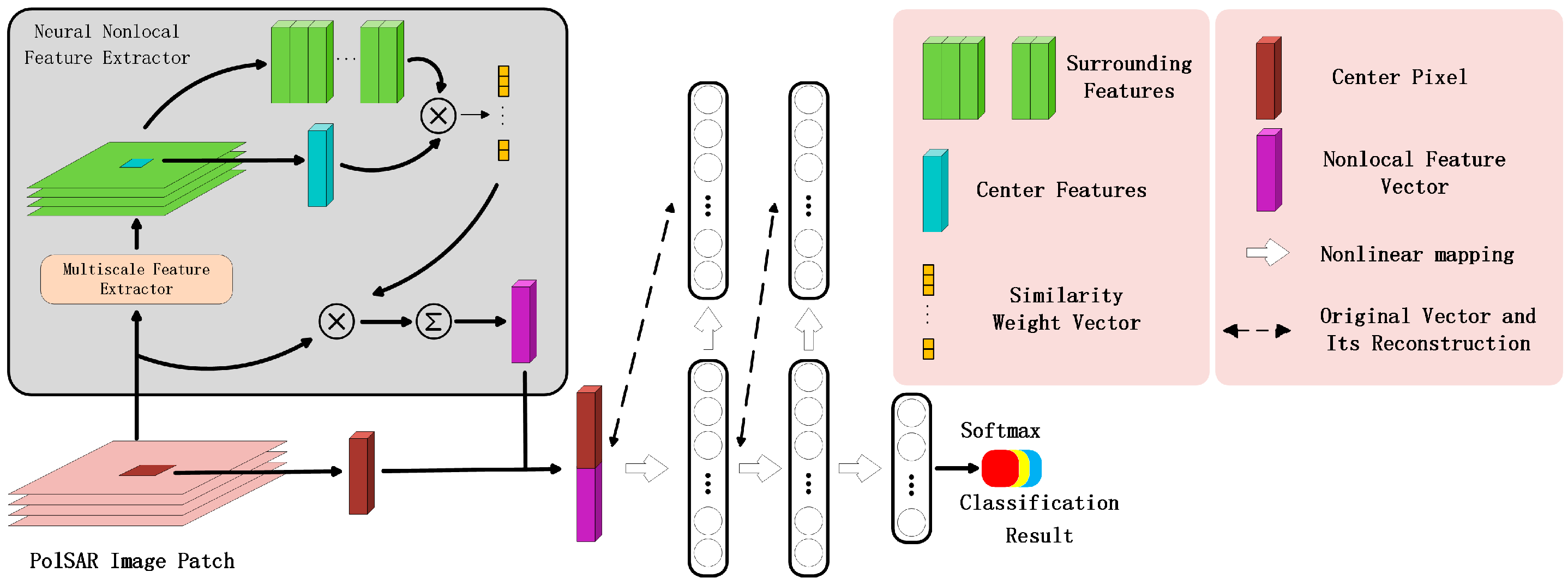
3. Proposed Method
3.1. Input Feature Preparation
3.2. Neural Nonlocal Feature Extractor
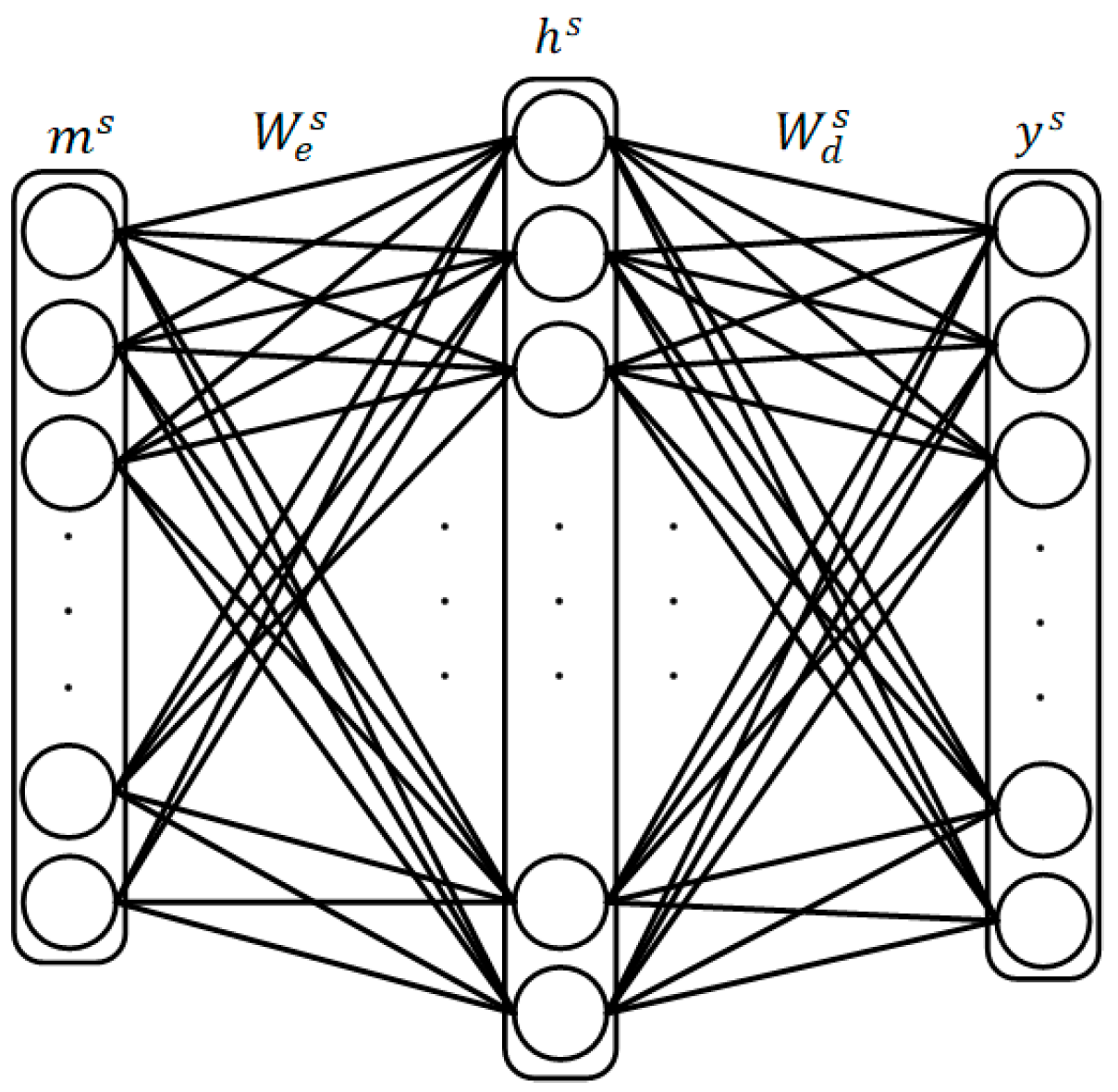
3.3. Stacked Sparse Autoencoders
3.4. Loss Function in the Fine-Tuning Stage and the VAT Regularization Term
| Algorithm 1. Calculation of Virtual Adversarial Training Disturbance |
| Input: Mini-batch size , dataset ; |
| Step 1: Randomly select samples dataset to construct a mini-batch. |
| Step 2: Sample unit vectors from an i.i.d Gaussian distribution. |
| Step 3: Calculate using Equation (16) and Equation (17) with respect to on on each sample. |
| Output: Virtual adversarial disturbance . |
3.5. Training Strategy
| Algorithm 2. The training strategy of NNSSAE-VAT |
| Input: PolSAR Image, label map; |
| Step 1: Select of samples per category from the labeled samples to construct training set. |
| Step 2: Initialize all trainable parameters . |
| Step 3: Use the auxiliary classifier to pretrain the NNFE with sample-label pairs by BP Algorithm. |
| Step 4: For the -th autoencoder in autoencoders: Train the autoencoder to reconstruct the input , minimize the L2-difference between the input and the reconstructed result . |
| Step 5: Use the main classifier to fine-tune the whole network with virtual adversarial training term in the loss function. |
| Output: The trained model , prediction map. |
4. Experiments
4.1. Experimental Settings
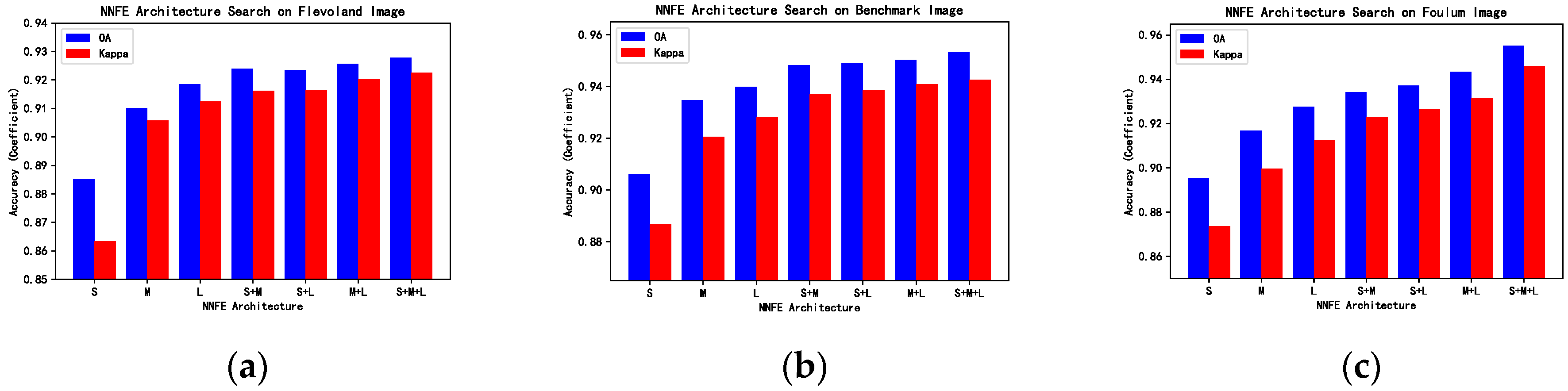
4.1.1. Networks Architecture Settings and Analyses
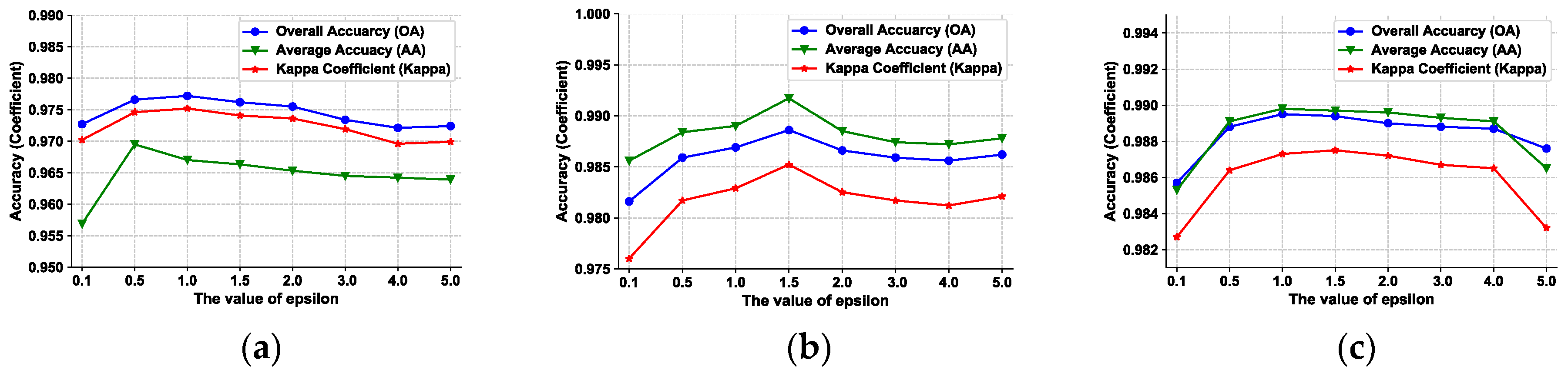
4.1.2. Parameter Settings for Virtual Adversarial Regularization Term
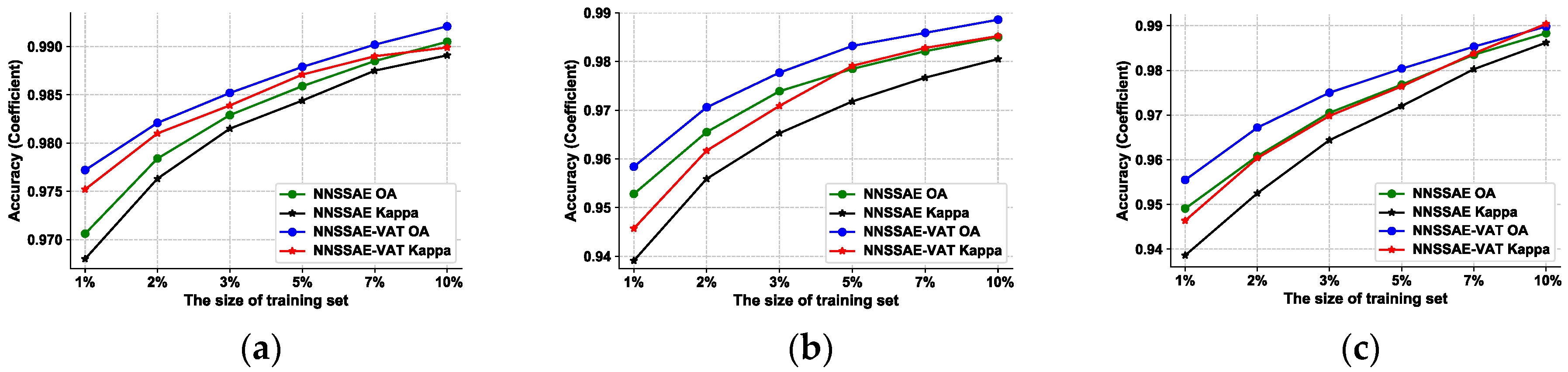
4.1.3. Influences of Different Sizes of the Training Set
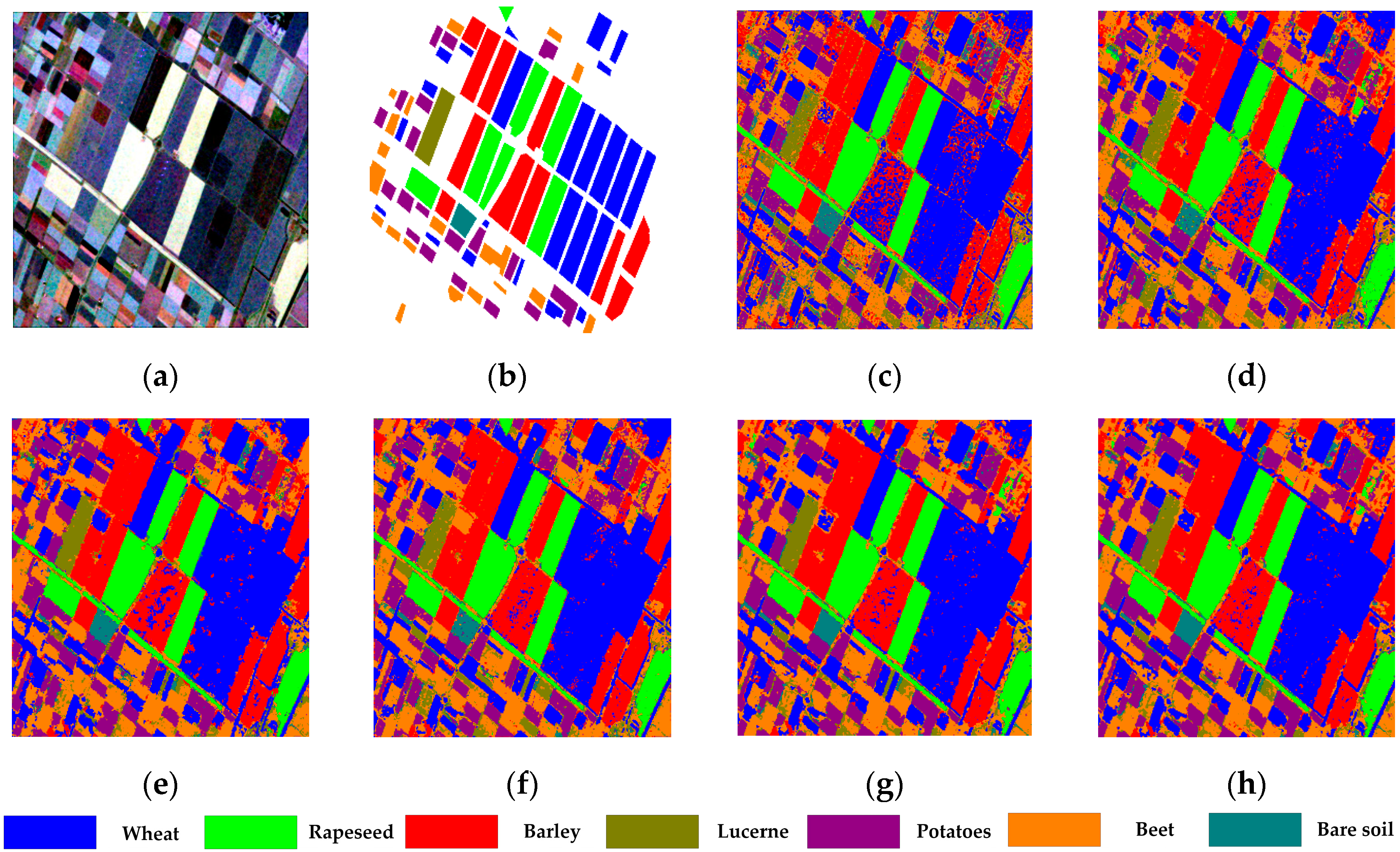
4.2. Flevoland Dataset
4.3. Benchmark Dataset
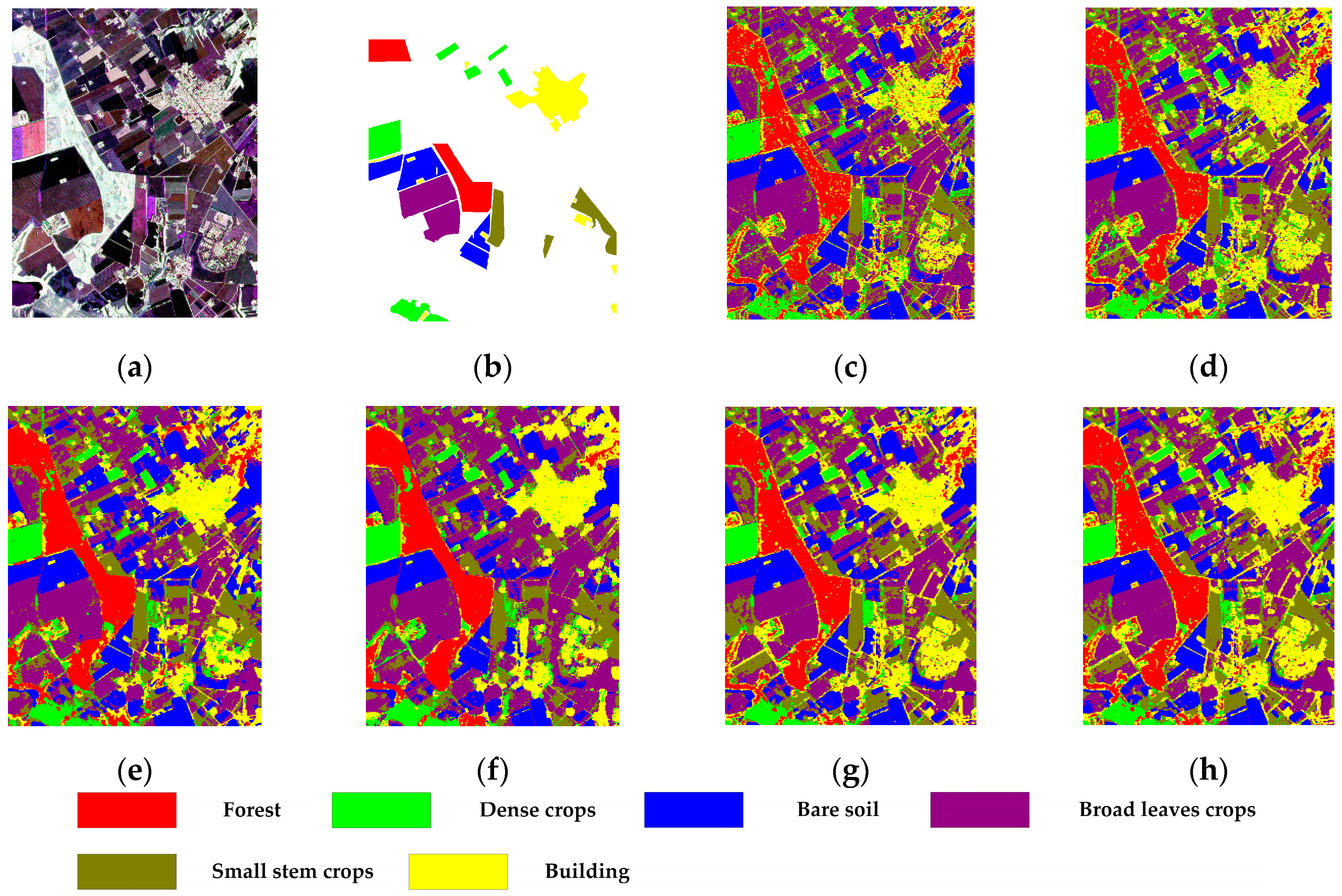
4.4. Foulum Dataset
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Hajnsek, I.; Jagdhuber, T.; Schon, H.; Papathanassiou, K.P. Potential of Estimating Soil Moisture under Vegetation Cover by Means of PolSAR. IEEE Trans. Geosci. Remote Sens. 2009, 47, 442–454. [Google Scholar] [CrossRef]
- Jiao, X.; Kovacs, J.M.; Shag, J.; McNairn, H.; Walters, D.; Ma, B.; Geng, X. Object-oriented crop mapping and monitoring using multi-temporal polarimetric RADARSAT-2 data. ISPRS J. Photogramm. Remote Sens. 2014, 96, 38–46. [Google Scholar] [CrossRef]
- Singh, G.; Yamaguchi, Y.; Boerner, W.M.; Park, S.E. Monitoring of the March 11, 2011, off-Tohoku 9.0 earthquake with super-tsunami disaster by implementing fully polarimetric high-resolution POLSAR techniques. Proc. IEEE 2013, 101, 831–846. [Google Scholar] [CrossRef]
- Chen, Q.; Li, L.; Jiang, P.; Liu, X. Building collapse extraction using modified freeman decomposition from post-disaster polarimetric SAR image. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 5769–5772. [Google Scholar]
- Liu, C.; Gierull, C.H. A new application for PolSAR imagery in the field of moving target indication/ship detection. IEEE Trans. Geosci. Remote Sens. 2007, 45, 3426–3436. [Google Scholar] [CrossRef]
- Wang, L.; Scott, K.A.; Xu, L.; Clausi, D.A. Sea ice concentration estimation during melt from dual-pol SAR scenes using deep convolutional neural networks: A case study. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4524–4533. [Google Scholar] [CrossRef]
- Lee, J.-S.; Grunes, M.R.; Ainsworth, T.L.; Du, L.-J.; Schuler, D.-L.; Cloude, S.R. Unsupervised classification using polarimetric decomposition and the complex Wishart classifier. IEEE Trans. Geosci. Remote Sens. 1999, 37, 2249–2258. [Google Scholar]
- Lee, J.S.; Grunes, M.R.; Pottier, E.; Ferro-Famil, L. Unsupervised terrain classification preserving polarimetric scattering characteristics. IEEE Trans. Geosci. Remote Sens. 2004, 42, 722–731. [Google Scholar]
- Zhang, L.; Zou, B.; Zhang, J.; Zhang, Y. Classification of Polarimetric SAR Image Based on Support Vector Machine Using Multiple-component Scattering Model and Texture Features. EURASIP J. Adv. Signal Process. 2010, 2010, 1–9. [Google Scholar] [CrossRef]
- Lardeux, C.; Frison, P.L.; Tison, C.; Stoll, B.; Fruneau, B.; Rudant, J.-P. Support vector machine for multifrequency SAR polarimetric data classification. IEEE Trans. Geosci. Remote Sens. 2009, 47, 4143–4152. [Google Scholar] [CrossRef]
- Zhang, L.; Sun, L.; Zou, B.; Moon, W. Fully polarimetric SAR image classification via sparse representation and polarimetric features. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2014, 8, 3923–3932. [Google Scholar] [CrossRef]
- Feng, J.; Cao, Z.; Pi, Y. Polarimetric contextual classification of PolSAR images using sparse representation and superpixels. Remote Sens. 2014, 6, 7158–7181. [Google Scholar] [CrossRef]
- Du, P.; Samat, A.; Waske, B.; Liu, S.; Li, Z. Random Forest and Rotation Forest for fully polarized SAR image classification using polarimetric and spatial features. J. Photogramm. Remote Sens. 2015, 105, 38–53. [Google Scholar] [CrossRef]
- Cloude, S.R.; Pottier, E. An entropy based classification scheme for land applications of polarimetric SAR. IEEE Trans. Geosci. Remote Sens. 1997, 35, 68–78. [Google Scholar] [CrossRef]
- Freeman, A.; Durden, S. A three-component scattering model for polarimetric SAR data. IEEE Trans. Geosci. Remote Sens. 1998, 36, 963–973. [Google Scholar] [CrossRef]
- Wu, Y.; Ji, K.; Yu, W.; Su, Y. Region-based classification of polarimetric SAR images using Wishart MRF. IEEE Geosci. Remote Sens. Lett. 2008, 5, 668–672. [Google Scholar] [CrossRef]
- Xie, W.; Xie, Z.; Zhao, F.; Ren, B. POLSAR Image Classification via Clustering-WAE Classification Model. IEEE Access. 2018, 6, 40041–40049. [Google Scholar] [CrossRef]
- Fukuda, S.; Hirosawa, H. Support vector machine classification of land cover: Application to polarimetric SAR data. In Proceedings of the IEEE 2001 International Geoscience and Remote Sensing Symposium (IGARSS ’01), Sydney, Australia, 9–13 July 2001; Volume 181, pp. 187–189. [Google Scholar]
- Zhang, L.; Zou, B.; Cai, H.; Zhang, Y. Multiple-component scattering model for polarimetric SAR image decomposition. IEEE Geosci. Remote Sens. Lett. 2008, 5, 603–607. [Google Scholar] [CrossRef]
- Mallat, S.; Zhang, Z.F. Matching pursuits with time-frequency dictionaries. IEEE Trans. Signal Process. 1993, 41, 3397–3415. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Bengio, Y.; Lamblin, P.; Popovici, D.; Larochelle, H.; Montreal, U. Greedy layer-wise training of deep networks. Adv. Neural Inform. Process. Syst. 2007, 19, 153–160. [Google Scholar]
- Xie, H.; Wang, S.; Liu, K.; Lin, S.; Hou, B. Multilayer feature learning for polarimetric synthetic radar data classification. In Proceedings of the IEEE Conference on International Geoscience and Remote Sensing Symposium (IGARSS), Quebec City, QC, Canada, 13–18 July 2014; pp. 2818–2821. [Google Scholar]
- Chen, W.; Gou, S.; Wang, X.; Li, X.; Jiao, L. Classification of PolSAR Images Using Multilayer Autoencoders and a Self-Paced Learning Approach. Remote Sens. 2018, 10, 110. [Google Scholar] [CrossRef]
- Hou, B.; Kou, H.; Jiao, L. Classification of polarimetric SAR images using multilayer autoencoders and superpixels. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2016, 9, 3072–3081. [Google Scholar] [CrossRef]
- Zhang, L.; Ma, W.; Zhang, D. Stacked sparse autoencoder in PolSAR data classification using local spatial information. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1359–1363. [Google Scholar] [CrossRef]
- Lecun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 2014, 1, 541–551. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, H.P.; Xu, F.; Jin, Y.Q. Polarimetric SAR Image Classification Using Deep Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2016, 99, 1–5. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, H.; Xu, F.; Jin, Y.Q. Complex-Valued Convolutional Neural Network and Its Application in Polarimetric SAR Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 1–12. [Google Scholar] [CrossRef]
- Geng, J.; Ma, X.; Fan, J.; Wang, H. Semisupervised Classification of Polarimetric SAR Image via Superpixel Restrained Deep Neural Network. IEEE Geosci. Remote Sens. Lett. 2017, 15, 122–126. [Google Scholar] [CrossRef]
- Buades, A.; Coll, B.; Morel, J.M. A non-local algorithm for image denoising. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 60–65. [Google Scholar]
- Hu, Y.; Fan, J.; Wang, J. Classification of PolSAR Images Based on Adaptive Nonlocal Stacked Sparse Autoencoder. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1050–1054. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Miyato, T.; Maeda, S.-I.; Koyama, M.; Nakae, K.; Ishii, S. Distributional Smoothing with Virtual Adversarial Training. In Proceedings of the 2016 International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Miyato, T.; Maeda, S.-I.; Ishii, S.; Koyama, M. Virtual Adversarial Training: A Regularization Method for Supervised and Semi-Supervised Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 1–14. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. In Proceedings of the 2015 International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Xie, W.; Jiao, L.; Hou, B.; Ma, W.; Zhao, J.; Zhang, S.; Liu, F. POLSAR Image Classification via Wishart-AE Model or Wishart-CAE Model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3604–3615. [Google Scholar] [CrossRef]
- Rumelhart, D.; Hinton, G.; Williams, R. Learning Representations by back-propagating errors. Nature. 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Liu, W.; Jia, T.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, FL, USA, 7–12 June 2015. [Google Scholar]
- Lee, J.S. Refined filtering of image noise using local statistics. Comput. Gr. Image Process. 1981, 15, 380–389. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | SSAE | SSAE-LS | SRDNN | ANSSAE | NNSSAE | NNSSAE-VAT |
|---|---|---|---|---|---|---|
| Stembeans | 0.9536 | 0.9395 | 0.9458 | 0.9586 | 0.9837 | 0.9801 |
| Rapeseed | 0.8151 | 0.8196 | 0.9177 | 0.9613 | 0.9255 | 0.9540 |
| Bare soil | 0.9421 | 0.9577 | 0.9616 | 0.9966 | 0.9890 | 0.9922 |
| Potatoes | 0.8649 | 0.8787 | 0.9480 | 0.9237 | 0.9610 | 0.9706 |
| Wheat 1 | 0.8976 | 0.9358 | 0.9669 | 0.9764 | 0.9659 | 0.9730 |
| Wheat 2 | 0.7793 | 0.8502 | 0.8712 | 0.9524 | 0.9431 | 0.9539 |
| Peas | 0.9404 | 0.9406 | 0.9658 | 0.9878 | 0.9873 | 0.9951 |
| Wheat 3 | 0.9179 | 0.9609 | 0.9793 | 0.9901 | 0.9876 | 0.9910 |
| Lucerne | 0.9476 | 0.9633 | 0.9479 | 0.9938 | 0.9867 | 0.9889 |
| Barley | 0.9508 | 0.9178 | 0.9544 | 0.9854 | 0.9849 | 0.9860 |
| Grasses | 0.8429 | 0.8803 | 0.9469 | 0.9601 | 0.9518 | 0.9557 |
| Beet | 0.9408 | 0.8850 | 0.9512 | 0.9533 | 0.9921 | 0.9935 |
| Building | 0.8326 | 0.7892 | 0.7710 | 0.8093 | 0.8676 | 0.8054 |
| Water | 0.9745 | 0.9774 | 0.9939 | 0.9987 | 0.9947 | 0.9953 |
| Forest | 0.8756 | 0.9264 | 0.9553 | 0.9324 | 0.9629 | 0.9712 |
| OA | 0.8975 | 0.9164 | 0.9511 | 0.9665 | 0.9706 | 0.9772 |
| AA | 0.8984 | 0.9082 | 0.9385 | 0.9586 | 0.9656 | 0.9671 |
| 0.8885 | 0.9090 | 0.9468 | 0.9641 | 0.9680 | 0.9752 |
| Class | SSAE | SSAE-LS | SRDNN | ANSSAE | NNSSAE | NNSSAE-VAT |
|---|---|---|---|---|---|---|
| Wheat | 0.9078 | 0.9430 | 0.9638 | 0.9818 | 0.9852 | 0.9877 |
| Rapeseed | 0.9970 | 0.9950 | 0.9989 | 0.9979 | 0.9984 | 0.9997 |
| Barley | 0.8322 | 0.9242 | 0.9474 | 0.9724 | 0.9751 | 0.9785 |
| Lucerne | 0.8514 | 0.9182 | 0.9741 | 0.9596 | 0.9780 | 0.9908 |
| Potatoes | 0.9600 | 0.9731 | 0.9940 | 0.9807 | 0.9920 | 0.9978 |
| Beet | 0.7916 | 0.8958 | 0.9709 | 0.9410 | 0.9802 | 0.9883 |
| Peas | 0.8579 | 0.8955 | 0.9863 | 0.9752 | 0.9985 | 0.9991 |
| OA | 0.8965 | 0.9448 | 0.9697 | 0.9779 | 0.9850 | 0.9886 |
| AA | 0.8852 | 0.9350 | 0.9765 | 0.9727 | 0.9868 | 0.9917 |
| 0.8652 | 0.9282 | 0.9638 | 0.9713 | 0.9805 | 0.9852 |
| Class | SSAE | SSAE-LS | SRDNN | ANSSAE | NNSSAE | NNSSAE-VAT |
|---|---|---|---|---|---|---|
| Forest | 0.9122 | 0.9595 | 0.9924 | 0.9966 | 0.9891 | 0.9904 |
| D.c | 0.8709 | 0.9688 | 0.9765 | 0.9834 | 0.9896 | 0.9910 |
| Bare soil | 0.9955 | 0.9967 | 0.9942 | 0.9967 | 0.9992 | 0.9993 |
| B.l.c | 0.9590 | 0.9828 | 0.9769 | 0.9791 | 0.9953 | 0.9945 |
| S.s.c | 0.9102 | 0.9719 | 0.9608 | 0.9670 | 0.9878 | 0.9896 |
| Buildings | 0.8140 | 0.8810 | 0.9620 | 0.9745 | 0.9697 | 0.9751 |
| OA | 0.9097 | 0.9582 | 0.9779 | 0.9838 | 0.9883 | 0.9898 |
| AA | 0.9103 | 0.9601 | 0.9771 | 0.9829 | 0.9884 | 0.9900 |
| 0.8918 | 0.9495 | 0.9733 | 0.9805 | 0.9859 | 0.9904 |
| Methods | Flevoland | Benchmark | Foulum | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Prep | Train | Total | Prep | Train | Total | Prep | Train | Total | |
| SSAE | – | 20.4 | 20.4 | – | 163.6 | 163.6 | – | 112.7 | 112.7 |
| SSAE-LS | – | 28.2 | 28.2 | – | 214.1 | 214.1 | – | 145.6 | 145.6 |
| SRDNN | 44.6 | 24.0 | 68.6 | 32.9 | 179.6 | 212.5 | 57.4 | 128.1 | 185.5 |
| ANSSAE | 1441.1 | 23.7 | 1464.8 | 1090.4 | 183.9 | 1274.3 | 1871.5 | 123.6 | 1995.1 |
| NNSSAE | – | 72.3 | 72.3 | – | 519.8 | 519.8 | – | 395.8 | 395.8 |
| NNSSAE-VAT | – | 81.8 | 81.8 | – | 593.5 | 593.5 | – | 440.7 | 440.7 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, R.; Wang, Y. Classification of PolSAR Image Using Neural Nonlocal Stacked Sparse Autoencoders with Virtual Adversarial Regularization. Remote Sens. 2019, 11, 1038. https://doi.org/10.3390/rs11091038
Wang R, Wang Y. Classification of PolSAR Image Using Neural Nonlocal Stacked Sparse Autoencoders with Virtual Adversarial Regularization. Remote Sensing. 2019; 11(9):1038. https://doi.org/10.3390/rs11091038
Chicago/Turabian StyleWang, Ruichuan, and Yanfei Wang. 2019. "Classification of PolSAR Image Using Neural Nonlocal Stacked Sparse Autoencoders with Virtual Adversarial Regularization" Remote Sensing 11, no. 9: 1038. https://doi.org/10.3390/rs11091038
APA StyleWang, R., & Wang, Y. (2019). Classification of PolSAR Image Using Neural Nonlocal Stacked Sparse Autoencoders with Virtual Adversarial Regularization. Remote Sensing, 11(9), 1038. https://doi.org/10.3390/rs11091038