A GA-Based Multi-View, Multi-Learner Active Learning Framework for Hyperspectral Image Classification



Abstract
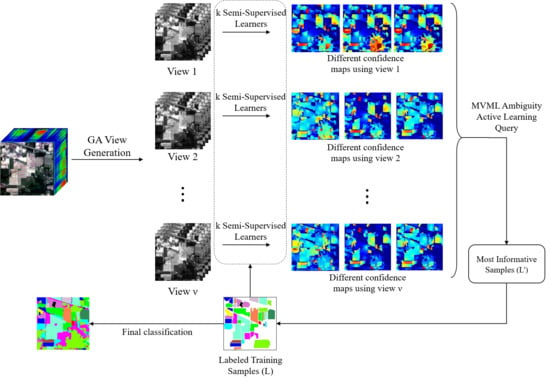
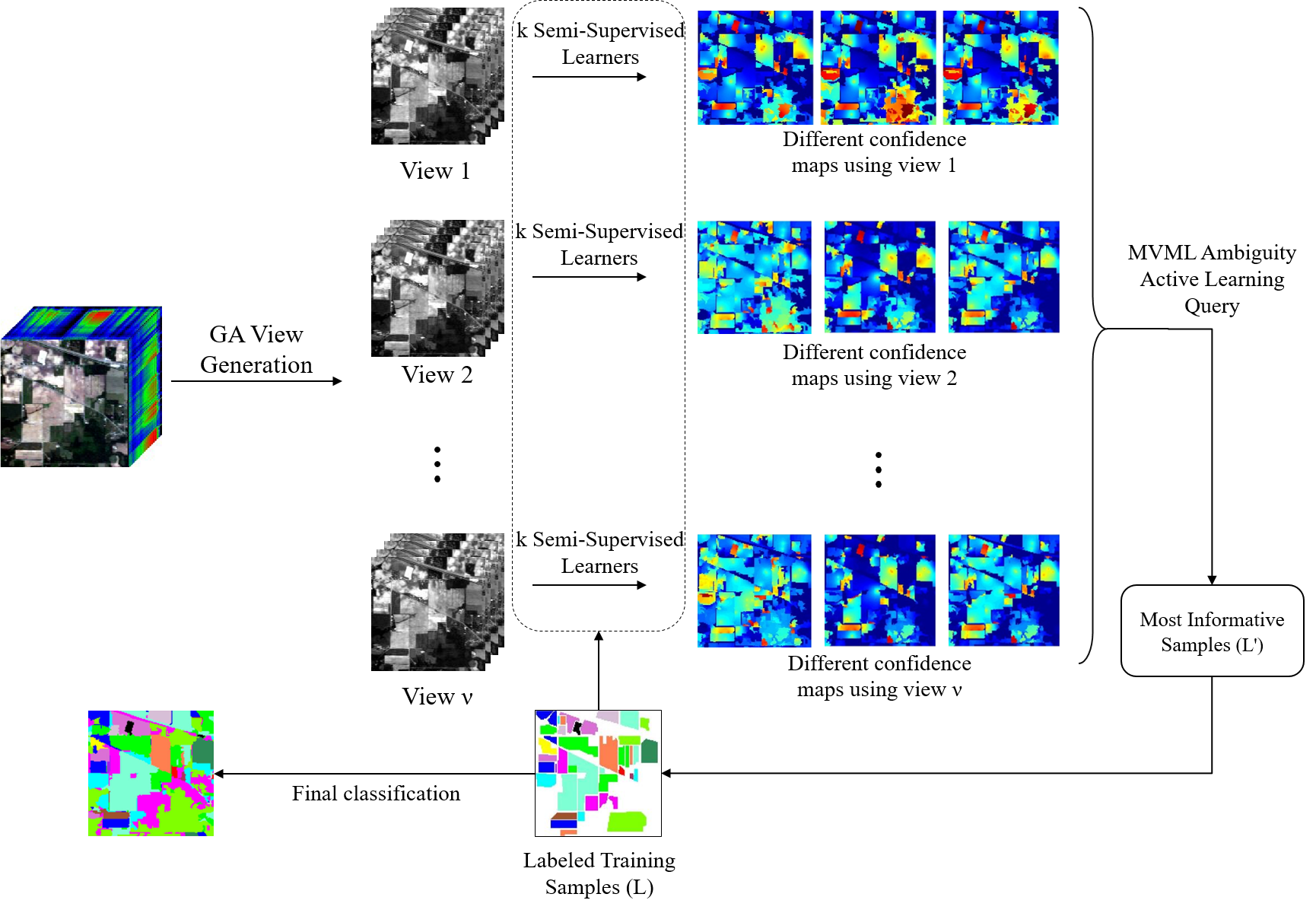
:
1. Introduction
- The introduction of a GA-based filter-wrapper view generation method for the AL method;
- The proposal of a novel probabilistic MVML heuristic called probabilistic-ambiguity;
- The implementation of a novel MVML-AL method to improve land cover classifications from hyperspectral data for the first time.
2. Materials and Methods
2.1. Active Learning
2.1.1. Single-View, Multi-Learner (SVML)
2.1.2. Multi-View, Single-Learner (MVSL)
2.1.3. Multi-View, Multi-Learner (MVML)
2.2. General Framework
2.2.1. View Generation by GA-FSS
2.2.2. MVML Sampling Strategy
2.2.3. Semi-Supervised Learning Algorithm
3. Results
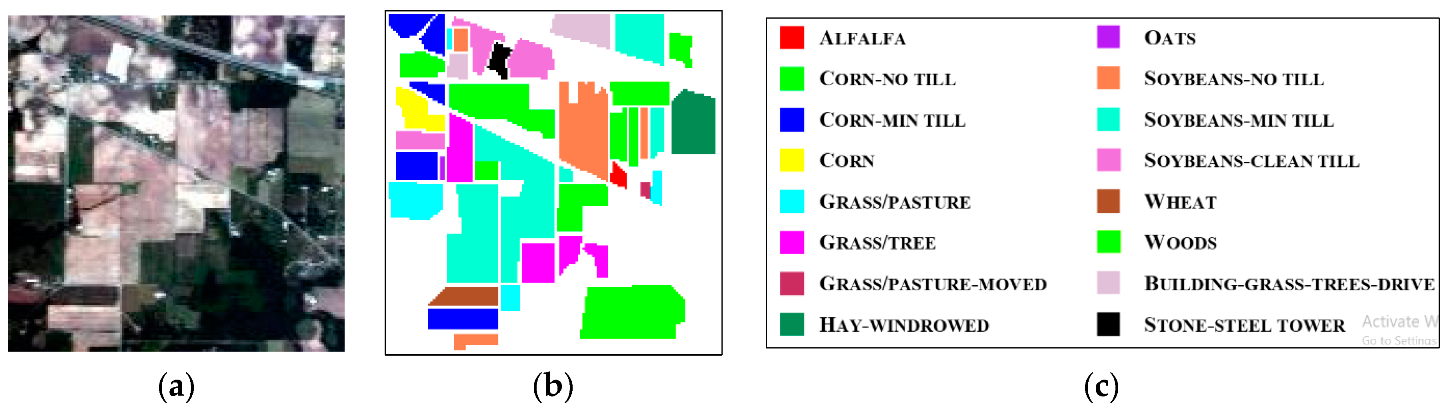
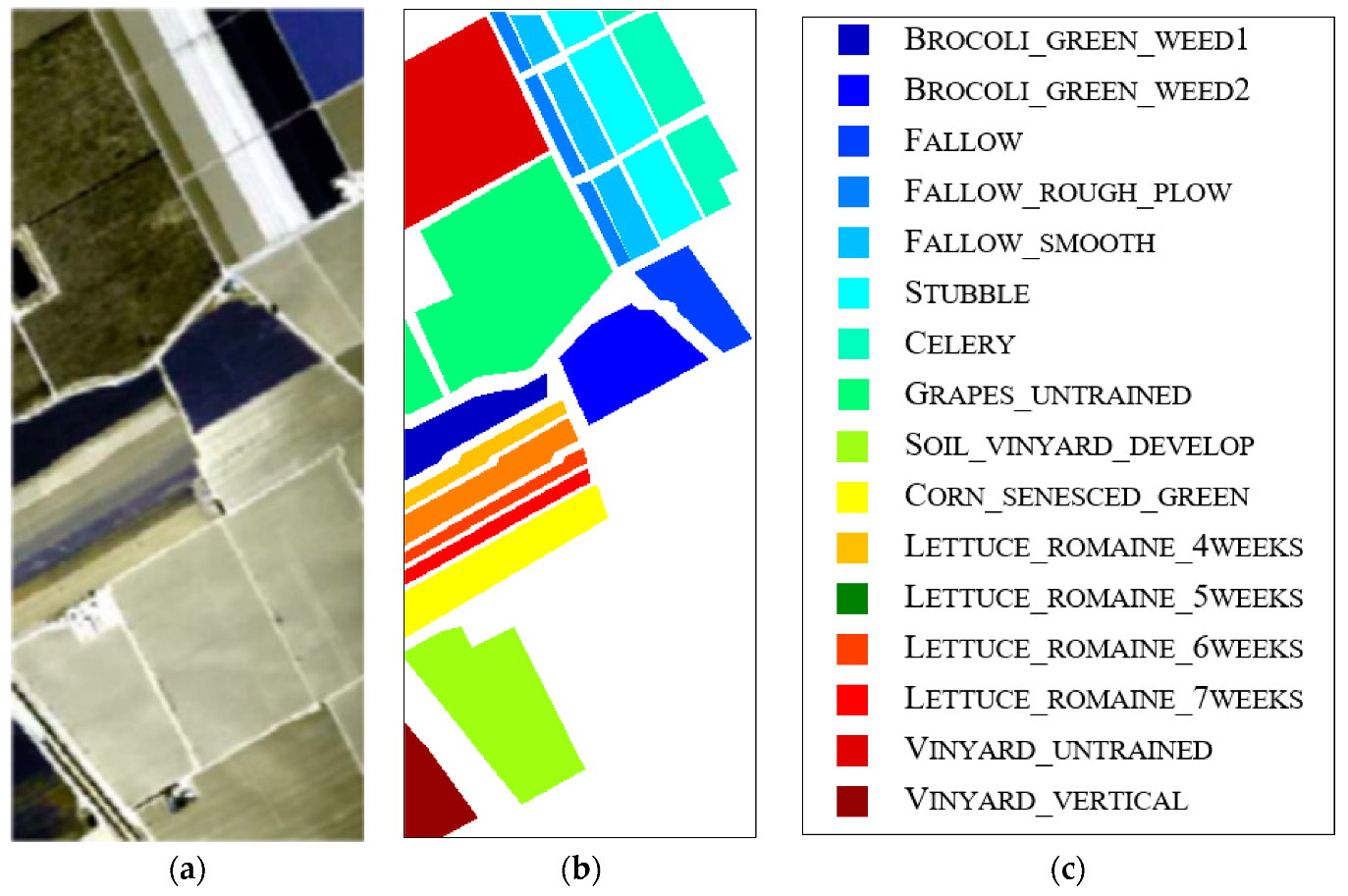
3.1. Hyperspectral Data
3.2. Experimental Setup
3.3. Experimental Results
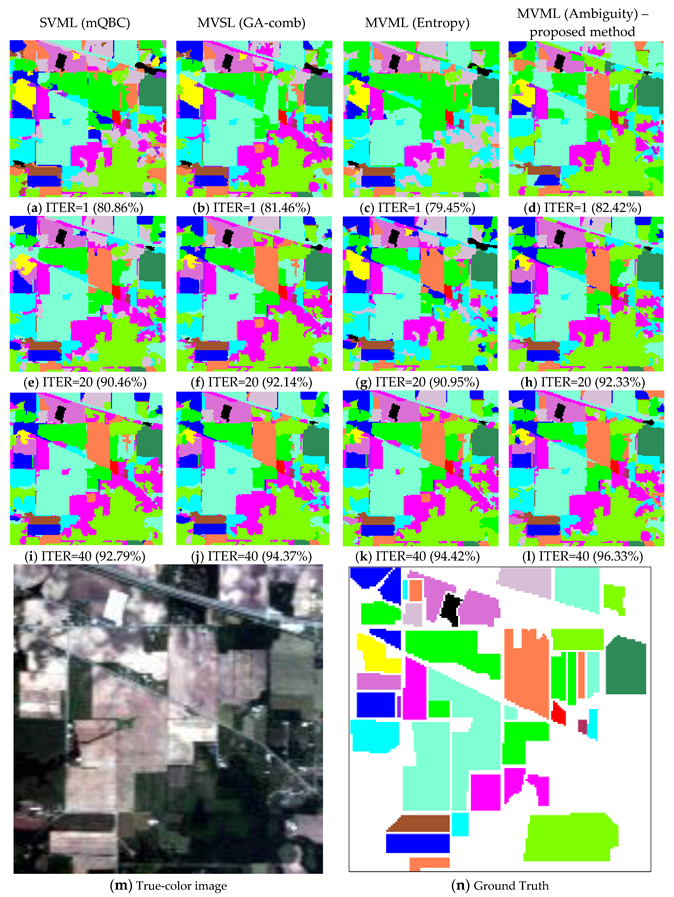
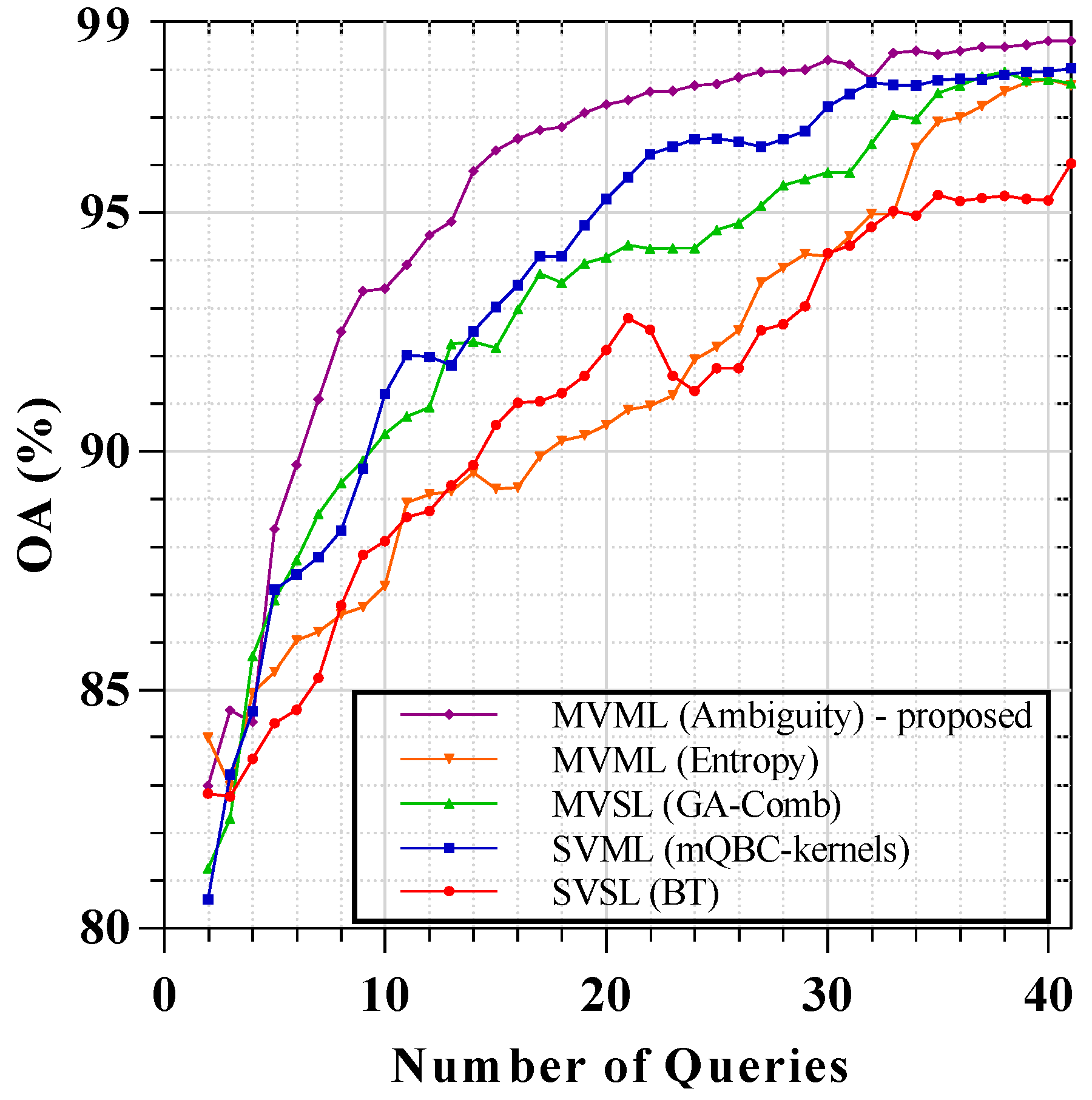
3.3.1. Results of AVIRIS Indian Pine Image
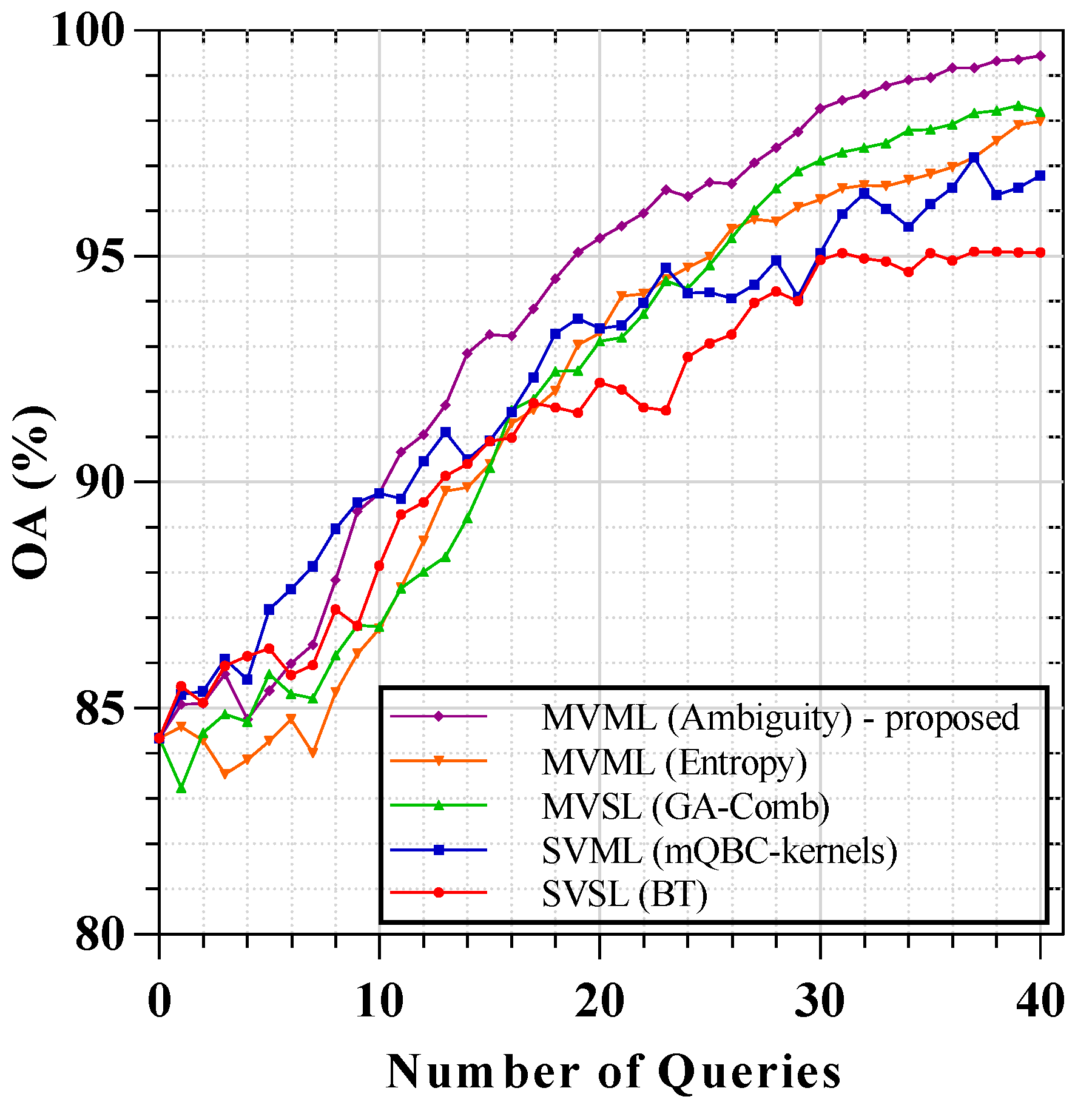
3.3.2. Results of ROSIS University of Pavia
3.3.3. Results of AVIRIS Salinas Valley
4. Discussion
4.1. Statistical Significance Analysis
4.2. Different View Generation Methods
4.2.1. Views’ Diversity Analysis
4.2.2. Views’ Efficiency Analysis
4.2.3. Time Complexity Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Persello, C.; Bruzzone, L. Active and semisupervised learning for the classification of remote sensing images. Geoscience and Remote Sensing. IEEE Trans. Geosci. Remote Sens. 2014, 52, 6937–6956. [Google Scholar] [CrossRef]
- Tuia, D.; Pasolli, E.; Emery, W. Using active learning to adapt remote sensing image classifiers. Remote Sens. Environ. 2011, 115, 2232–2242. [Google Scholar] [CrossRef]
- Settles, B. Active Learning Literature Survey; University of Wisconsin: Madison, WI, USA, 2010; Volume 52, p. 11. [Google Scholar]
- Reitmaier, T.; Sick, B. Let us know your decision: Pool-based active training of a generative classifier with the selection strategy 4DS. Inf. Sci. 2013, 230, 106–131. [Google Scholar] [CrossRef]
- Crawford, M.M.; Tuia, D.; Yang, H.L. Active learning: Any value for classification of remotely sensed data? Proc. IEEE 2013, 101, 593–608. [Google Scholar] [CrossRef] [Green Version]
- Hu, R.; Namee, B.M.; Delany, S.J. Off to a good start: Using clustering to select the initial training set in active learning. In Proceedings of the Twenty-Third International Florida Artificial Intelligence Research Society Conference (FLAIRS 2010), Menlo Park, CA, USA, 19–21 May 2010. [Google Scholar]
- Yuan, W.; Han, Y.; Guan, D.; Lee, S.; Lee, Y.K. Initial training data selection for active learning. In Proceedings of the 5th International Conference on Ubiquitous Information Management and Communication, New York, NY, USA, 21–23 February 2011; p. 5. [Google Scholar]
- Alajlan, N.; Pasolli, E.; Melgani, F.; Franzoso, A. Large-Scale Image Classification Using Active Learning. IEEE Geosci. Remote Sens. Lett. 2014, 11, 259–263. [Google Scholar] [CrossRef]
- Guo, J.; Zhou, X.; Li, J.; Plaza, A.; Prasad, S. Superpixel-Based Active Learning and Online Feature Importance Learning for Hyperspectral Image Analysis. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 347–359. [Google Scholar] [CrossRef]
- Zhang, Z.; Pasolli, E.; Crawford, M.M.; Tilton, J.C. An Active Learning Framework for Hyperspectral Image Classification Using Hierarchical Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 640–654. [Google Scholar] [CrossRef]
- Samat, A.; Li, J.; Liu, S.; Du, P.; Miao, Z.; Luo, J. Improved hyperspectral image classification by active learning using pre-designed mixed pixels. Pattern Recognit. 2016, 51, 43–58. [Google Scholar] [CrossRef]
- Dopido, I.; Li, J.; Marpu, P.R.; Plaza, A.; Bioucas-Dias, J.M.; Benediktsson, J.A. Semi-supervised self-learning for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens 2013, 51, 4032–4044. [Google Scholar] [CrossRef] [Green Version]
- Tan, K.; Hu, J.; Li, J.; Du, P. A novel semi-supervised hyperspectral image classification approach based on spatial neighborhood information and classifier combination. ISPRS J. Photogramm. Remote Sens. 2015, 105, 19–29. [Google Scholar] [CrossRef]
- Sun, B.; Kang, X.; Li, S.; Benediktsson, J.A. Random-Walker-Based Collaborative Learning for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 212–222. [Google Scholar] [CrossRef]
- Paoletti, M.; Haut, J.; Plaza, J.; Plaza, A. Deep learning classifiers for hyperspectral imaging: A review. ISPRS J. Photogramm. Remote Sens. 2019, 158, 279–317. [Google Scholar] [CrossRef]
- Lin, J.; Zhao, L.; Li, S.; Ward, R.; Wang, Z.J. Active-Learning-Incorporated Deep Transfer Learning for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 4048–4062. [Google Scholar] [CrossRef]
- Liu, P.; Zhang, H.; Eom, K.B. Active deep learning for classification of hyperspectral images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 10, 712–724. [Google Scholar] [CrossRef] [Green Version]
- Di, W.; Crawford, M.M. View generation for multiview maximum disagreement based active learning for hyperspectral image classification. Geosci. Remote Sens. IEEE Trans. 2012, 50, 1942–1954. [Google Scholar] [CrossRef]
- Ma, L.; Ma, A.; Ju, C.; Li, X. Graph-based semi-supervised learning for spectral-spatial hyperspectral image classification. Pattern Recognit. Lett. 2016, 83, 133–142. [Google Scholar] [CrossRef]
- Chen, Z.; Wang, B.; Niu, Y.; Xia, W.; Zhang, J.Q.; Hu, B. Semisupervised hyperspectral image classification based on affinity scoring. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 4967–4970. [Google Scholar]
- Zhang, Q.; Sun, S. Multiple-view multiple-learner active learning. Pattern Recognit. 2010, 43, 3113–3119. [Google Scholar] [CrossRef]
- Freund, Y.; Seung, H.S.; Shamir, E.; Tishby, N. Selective sampling using the query by committee algorithm. Mach. Learn. 1997, 28, 133–168. [Google Scholar] [CrossRef]
- Tuia, D.; Volpi, M.; Copa, L.; Kanevski, M.; Munoz-Mari, J. A survey of active learning algorithms for supervised remote sensing image classification. Sel. Top. Signal Process. IEEE J. 2010, 5, 606–617. [Google Scholar] [CrossRef]
- Mamitsuka, N.A.H. Query learning strategies using boosting and bagging. In Machine Learning: Proceedings of the Fifteenth International Conference (ICML’98); Morgan Kaufmann Publishers: Burlington, MA, USA, 1998. [Google Scholar]
- Zhou, Z.-H.; Li, M. Tri-training: Exploiting unlabeled data using three classifiers. IEEE Trans. Knowl. Data Eng. 2005, 17, 1529–1541. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Zhou, Z.H. Analyzing co-training style algorithms. In European Conference on Machine Learning; Springer: Berlin, Germany, 2007; pp. 454–465. [Google Scholar]
- Xia, T.; Tao, D.; Mei, T.; Zhang, Y. Multiview spectral embedding. IEEE Trans. Syst. Man Cybern. Part B 2010, 40, 1438–1446. [Google Scholar]
- Di, W.; Crawford, M.M. Active learning via multi-view and local proximity co-regularization for hyperspectral image classification. Sel. Top. Signal Process. IEEE J. 2011, 5, 618–628. [Google Scholar] [CrossRef] [Green Version]
- Xu, C.; Tao, D.; Xu, C. A survey on multi-view learning. arXiv 2013, arXiv:1304.5634. [Google Scholar]
- Sun, S.; Jin, F.; Tu, W. View construction for multi-view semi-supervised learning. Adv. Neural Netw. ISNN 2011, 2011, 595–601. [Google Scholar]
- Muslea, I.; Minton, S.; Knoblock, C.A. Active+ semi-supervised learning= robust multi-view learning. In Proceedings of the ICML, Sydney, Australia, 8–12 July 2002; pp. 435–442. [Google Scholar]
- Xue, B.; Zhang, M.; Browne, W.N.; Yao, X. A survey on evolutionary computation approaches to feature selection. IEEE Trans. Evol. Comput. 2016, 20, 606–626. [Google Scholar] [CrossRef] [Green Version]
- Ghareb, A.S.; Bakar, A.A.; Hamdan, A.R. Hybrid feature selection based on enhanced genetic algorithm for text categorization. Expert Syst. Appl. 2016, 49, 31–47. [Google Scholar] [CrossRef]
- Li, S.; Wu, H.; Wan, D.; Zhu, J. An effective feature selection method for hyperspectral image classification based on genetic algorithm and support vector machine. Knowl. Based Syst. 2011, 24, 40–48. [Google Scholar] [CrossRef]
- Bennasar, M.; Hicks, Y.; Setchi, R. Feature selection using Joint Mutual Information Maximisation. Expert Syst. Appl. 2015, 42, 8520–8532. [Google Scholar] [CrossRef] [Green Version]
- Zhu, X.; Ghahramani, Z.; Lafferty, J.D. Semi-supervised learning using gaussian fields and harmonic functions. In Proceedings of the 20th International Conference on Machine Learning (ICML-03), Washington, DC, USA, 21–24 August 2003; pp. 912–919. [Google Scholar]
- Camps-Valls, G.; Bandos Marsheva, T.; Zhou, D. Semi-supervised graph-based hyperspectral image classification. Geosci. Remote Sens. IEEE Trans. 2007, 45, 3044–3054. [Google Scholar] [CrossRef]
- Jamshidpour, N.; Safari, A.; Homayouni, S. Spectral–Spatial Semisupervised Hyperspectral Classification Using Adaptive Neighborhood. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 4183–4197. [Google Scholar] [CrossRef]
- Jamshidpour, N.; Homayouni, S.; Safari, A. Graph-based semi-supervised hyperspectral image classification using spatial information. In Proceedings of the 2016 8th Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing (WHISPERS), Los Angeles, CA, USA, 21–24 August 2016; pp. 1–4. [Google Scholar]
- Zhu, X.; Lafferty, J.; Ghahramani, Z. Combining active learning and semi-supervised learning using gaussian fields and harmonic functions. In Proceedings of the ICML 2003 Workshop on the Continuum from Labeled to Unlabeled Data in Machine Learning and Data Mining, Washington, DC, USA, 21 August 2003. [Google Scholar]
- Foody, G.M. Classification accuracy comparison: Hypothesis tests and the use of confidence intervals in evaluations of difference, equivalence and non-inferiority. Remote Sens. Environ. 2009, 113, 1658–1663. [Google Scholar] [CrossRef] [Green Version]
- Wan, L.; Tang, K.; Li, M.; Zhong, Y.; Qin, A. Collaborative active and semisupervised learning for hyperspectral remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2384–2396. [Google Scholar] [CrossRef]
- Sun, S.; Zhong, P.; Xiao, H.; Wang, R. An MRF model-based active learning framework for the spectral-spatial classification of hyperspectral imagery. IEEE J. Sel. Top. Signal Process. 2015, 9, 1074–1088. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | ITER = 1 | ITER = 10 | ITER = 20 | ITER = 30 | ITE = 40 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| SVSL (BT) | 76.74 | 0.8 | 83.44 | 0.68 | 87.44 | 0.36 | 90.20 | 0.35 | 91.10 | 0.04 |
| SVML (mQBC-kernels) | 80.36 | 1.06 | 86.49 | 0.62 | 90.58 | 0.39 | 92.57 | 0.18 | 93.07 | 0.08 |
| MVSL (GA-Comb) | 81.51 | 1.05 | 89.32 | 0.84 | 92.03 | 0.21 | 93.96 | 0.21 | 94.83 | 0.07 |
| MVML (entropy) | 78.29 | 0.18 | 87.99 | 0.83 | 90.74 | 0.28 | 93.80 | 0.28 | 95.39 | 0.17 |
| MVML (ambiguity) | 82.17 | 1.71 | 89.97 | 0.98 | 91.83 | 0.14 | 95.08 | 0.33 | 97.14 | 0.20 |
| Methods | ITER = 1 | ITER = 10 | ITER = 20 | ITER = 30 | ITER = 40 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| SVSL (BT) | 82.81 | 0.44 | 88.62 | 0.59 | 92.78 | 0.38 | 94.31 | 0.21 | 96.02 | 0.14 |
| SVML (mQBC-kernels) | 80.60 | 0.33 | 92.01 | 1.15 | 95.75 | 0.42 | 97.48 | 0.15 | 98.03 | 0.03 |
| MVSL (GA-Comb) | 81.25 | 1.11 | 90.72 | 0.96 | 94.32 | 0.33 | 95.84 | 0.22 | 97.70 | 0.13 |
| MVML (Entropy) | 84.00 | 0.29 | 88.92 | 0.50 | 90.87 | 0.18 | 94.49 | 0.40 | 97.66 | 0.30 |
| MVML (Ambiguity) | 82.99 | 2.77 | 93.90 | 1.13 | 97.36 | 0.30 | 98.10 | 0.02 | 98.59 | 0.08 |
| Methods | ITER = 1 | ITER = 10 | ITER = 20 | ITER = 30 | ITER = 40 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| SVSL (BT) | 85.49 | 1.14 | 88.15 | 0.38 | 92.21 | 0.27 | 94.92 | 0.30 | 95.08 | 0.00 |
| SVML (mQBC-kernels) | 85.31 | 0.96 | 89.76 | 0.43 | 93.40 | 0.38 | 95.07 | 0.24 | 96.79 | 0.09 |
| MVSL (GA-Comb) | 83.24 | −1.10 | 86.80 | 0.44 | 93.12 | 0.55 | 97.13 | 0.40 | 98.21 | 0.10 |
| MVML (Entropy) | 84.60 | 0.25 | 86.75 | 0.30 | 93.31 | 0.64 | 96.26 | 0.23 | 97.99 | 0.16 |
| MVML (Ambiguity) | 85.10 | 0.75 | 89.95 | 0.55 | 95.41 | 0.50 | 98.27 | 0.27 | 99.45 | 0.11 |
| Methods | Indian Pines | Pavia University | Salinas | ||||||
|---|---|---|---|---|---|---|---|---|---|
| CASSL [42] | 0.939 | 0.0058 | 4.189 | 0.955 | 0.0025 | 7.208 | 0.982 | 0.0034 | 3.078 |
| RWASL [14] | 0.976 | 0.0056 | −0.970 | 0.982 | 0.0046 | 0.524 | 0.991 | 0.0025 | 0.732 |
| MRF-AL [43] | 0.891 | 0.0150 | 5.007 | 0.911 | 0.0191 | 3.814 | 0.974 | 0.0087 | 2.166 |
| MVML-AL [21] | 0.953 | 0.0062 | 2.136 | 0.946 | 0.0036 | 7.786 | 0.987 | 0.0049 | 1.194 |
| MVML-AL-proposed | 0.969 | 0.0042 | ---- | 0.985 | 0.0034 | ---- | 0.993 | 0.0011 | ---- |
| Methods | Indian Pines | Pavia University | Salinas | ||||||
|---|---|---|---|---|---|---|---|---|---|
| MI | MI | MI | |||||||
| View1 | View2 | View1 | View2 | View1 | View2 | ||||
| Uniform | 3.25 | 77.54 | 0.7653 | 3.08 | 82.13 | 81.96 | 4.76 | 84.63 | 85.07 |
| Correlation | 5.21 | 76.59 | 77.36 | 3.79 | 81.02 | 81.82 | 5.09 | 84.73 | 84.85 |
| K-Means | 4.25 | 77.96 | 78.01 | 3.52 | 82.09 | 82.10 | 4.97 | 84.36 | 83.97 |
| Random | 5.26 | 75.89 | 76.34 | 3.68 | 82.09 | 82.18 | 4.82 | 84.23 | 84.36 |
| GA-filter | 1.36 | 77.63 | 77.54 | 1.13 | 82.16 | 81.86 | 1.27 | 84.75 | 84.37 |
| GA-Wrapper | 2.56 | 78.47 | 78.94 | 3.22 | 84.09 | 83.68 | 4.37 | 85.94 | 86.21 |
| GA-Comb | 1.78 | 79.37 | 78.51 | 1.20 | 83.97 | 83.62 | 1.11 | 85.47 | 85.75 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jamshidpour, N.; Safari, A.; Homayouni, S. A GA-Based Multi-View, Multi-Learner Active Learning Framework for Hyperspectral Image Classification. Remote Sens. 2020, 12, 297. https://doi.org/10.3390/rs12020297
Jamshidpour N, Safari A, Homayouni S. A GA-Based Multi-View, Multi-Learner Active Learning Framework for Hyperspectral Image Classification. Remote Sensing. 2020; 12(2):297. https://doi.org/10.3390/rs12020297
Chicago/Turabian StyleJamshidpour, Nasehe, Abdolreza Safari, and Saeid Homayouni. 2020. "A GA-Based Multi-View, Multi-Learner Active Learning Framework for Hyperspectral Image Classification" Remote Sensing 12, no. 2: 297. https://doi.org/10.3390/rs12020297
APA StyleJamshidpour, N., Safari, A., & Homayouni, S. (2020). A GA-Based Multi-View, Multi-Learner Active Learning Framework for Hyperspectral Image Classification. Remote Sensing, 12(2), 297. https://doi.org/10.3390/rs12020297