1. Introduction
Mapping land use using high resolution (HR) satellite images is important for urban planning, socio-economic analysis, and geo-information database updating [
1,
2,
3,
4]. Particularly, the rapid urbanization and population growth pose big challenges for sustainable urban development, requiring updated and fine-detailed land use information for decision making [
5,
6]. In the past decade, remote sensing technologies have developed rapidly, and many satellites have been launched. A vast amount of remote sensing images that were acquired from various platforms and sensors can be accessed now. Among them, (very) high spatial resolution remote sensing images, usually with a resolution finer than 5 m acquired from Worldview, GeoEye, GaoFen-2 (GF2), and ZiYuan-3 (ZY3) satellites, provide detailed images of the earth. These images have a high potential for land use mapping at the land parcel or local neighborhood levels [
7,
8,
9,
10,
11].
Automatic image classification is an essential operation for mapping land use from remote sensing images. In the literature, many studies have been conducted for remote sensing image classification [
12,
13,
14,
15]. Initially, the methods of land use image classification were developed for classifying land cover types based upon a number of low-level image features, e.g., spectral, textural, and contextual features [
16,
17]. These low-level image features can be used in order to separate land use between relatively coarse categories from low- and medium-resolution remote sensing images. However, they fail to effectively describe the properties of land use categories, e.g., residential, commercial, and industrial land, at urban neighborhood level [
18]. Particularly, on a high-resolution satellite image, a homogeneous land use area reflects various spectral signatures, which correspond to different types of land cover objects. Here a land use unit refers to a homogeneous land use area, such as a land parcel or a street block. The spatial arrangement of land cover objects can be complicated within a land use unit, leading to difficulties in effectively characterizing the structural properties of land use units [
9]. Thus, it is necessary to derive high-level image features in order to improve the separability between land use types, e.g., using landscape metrics [
19], visual bag-of-words (BOW) [
20,
21], or latent Dirichlet allocation model [
22]. So far, the complex topological relations between land cover objects are insufficiently dealt with by the above-mentioned methods.
Existing studies have shown that the mining of topological relations between land cover objects improves land use classification performance by differentiating complex urban structures [
23,
24]. The main assumption underlying land use classification is that land use units with similar structures are more likely to have similar functional properties. For example, Li [
9] proposed a hierarchical Bayesian model for extracting land use information while using very high resolution (VHR) remote sensing images, in which the type of land use is inferred based upon functional variables represented by the spatial arrangement of land cover objects. The land cover objects are preliminarily classified from images, for which many methods can be found in the literature [
25,
26,
27,
28,
29]. A widely used method refers to object-based land cover classification by traditional machine learning algorithms, like support vector machine or random forest that is based upon spectral, textural, and geometrical information [
28,
30]. The classification can be further improved by including more advanced features, e.g., derived from extended multi-attribute profiles [
26]. Furthermore, recent studies have shown that state-of-the-art land cover classifications tend to be achieved by deep learning methods [
25,
27]. An effective technique for describing and quantifying the topology of neighboring land cover objects is based upon graph theory. In a graph, the land cover objects and their relationships can be encoded as graph attributes and edges. By doing so, the problem of characterizing the spatial structure of land use is transformed to the derivation of structural features from a graph that represents the topology of land cover objects within land use units. Walde [
24] investigated handcrafted graph features (by feature engineering) in order to measure the structural properties of city blocks for classifying urban structure types. However, deriving graph features in a handcrafted manner requires considerable expert knowledge, limiting the generalizability of a classification method using these features. Lehner [
31] investigated a tree-structured framework based upon object-based image analysis for urban structure type classification, in which a (sub)tree represents the topology of objects. The construction of this framework for a different application also relies on expert knowledge.
By contrast, automatically deriving high-level structural features from graph-structured data has been used in network analysis, information mining, and computer vision [
32,
33,
34]. Graph kernels measure the similarity between graphs, and they can be integrated with a kernel-based classifier, like support vector machine (SVM), for graph classification. [
33] grouped existing graph kernels into neighborhood aggregation methods (e.g., based on the Weisfeiler–Lehman algorithm), assignment- and matching-based methods, subgraph patterns, walks and paths, and kernels for graphs with continuous labels. Another popular strategy for handling graph-structured data is based on graph neural networks (GNNs) [
32,
35], achieving the state-of-the-art performance in graph feature extraction and graph classification. Among them, an important variant of graph neural networks refers to graph convolutional network (GCN) [
36]. Recently, Li [
11] applied GCNs to urban land use classification from very high resolution (VHR) satellite images with 0.5 m spatial resolution, and obtained promising results.
This study is an extension of [
11], with the aim to exploit the spatial arrangement of land cover objects by graph-based methods for land use mapping from high resolution satellite images. We focus on extracting high-level structural features of land use while using GCNs, and comparing with methods using feature engineering and graph kernels. Previous studies investigated land use classification by GCNs while using VHR images with a spatial resolution of less than 1m. In this study, we also analyze the applicability of these graph-based methods to land use classifications using high resolution remote sensing images with a spatial resolution of 2.5 m.
The remaining of this paper is organized, as follows.
Section 2 introduces the study areas and data,
Section 3 illustrates the graph-based methods used for graph feature learning and land use classification,
Section 4 gives the experimental results and corresponding analysis. The discussion and conclusions are provided in
Section 5 and
Section 6, respectively.
2. Study Areas and Data
The study area is located in the core region of Fuzhou City, the capital city of Fujian province, China (
Figure 1). It covers 210
, and it contains a large variety of land cover and land use types. For the Fuzhou study area, we acquired two remote sensing images, from the GF2 satellite on 18 February 2020 and the ZY3 satellite on 10 April 2020. The GF2 image was captured by a PMS1 sensor having four 2.5 m resolution multi-spectral bands and one 0.78 m resolution panchromatic band. The ZY3 image has four multi-spectral bands with 6.78 m and one panchromatic band with 2.38 m resolution. We executed pansharpening to fuse multi-spectral and panchromatic bands for both images [
37], and resampled the pansharpened images to 0.8 m and 2.5 m for experiment convenience. The processed GF2 image has a size of
pixels for the Fuzhou study area, and the ZY3 image has
pixels.
We collected ground truth land use data over the study area from the local surveying department to delineate homogeneous land use units. The land use samples that were used to train and test land use classification algorithms were collected based on land use units derived from the ground truth data. These data were derived from the 3rd National Land Survey Project, and produced at the end of 2019. The classification system of the ground-truth land use data follows the (Chinese) National Land Use Classification Standard (GB/T 21010-2017 ), with 12 first-level land use classes and 73 second-level classes. These data are the most detailed and accurate land use data available and, thus, are suitable for this study. Moreover, we re-organized the official land use system at the first level into seven land use classes, see
Table 1. We distinguish six main land use classes of high-density residential (RH), low-density residential (RL), commercial (CM), industrial and warehouses (IW), green space and entertainment land (GE), and undeveloped land (UN) from high resolution remote sensing images. We group the rest of land use classes into
others (OT), including public management and services, transportation, water body, and land for special use or with multiple categories. We map water body separately because water body can be easily identified based upon the ratio of water coverage.
3. Methods
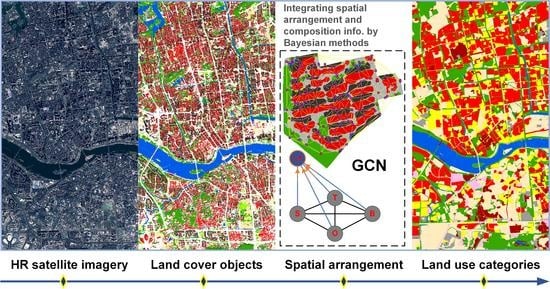
Figure 2 illustrates the workflow of land use mapping while using graph-based methods. Specifically, we model the topological relationships between neighboring land cover objects preliminarily obtained from remote sensing images into a planar graph. Three feature extraction methods based upon GCNs, feature engineering, and graph kernels are used to learn structural features from graph-structured data. The extracted structural features that are integrated with the features regarding the spatial composition of land use are then used for land use classification.
3.1. Land Cover Classification
Land cover classification is first conducted in order to obtain key types of land cover objects. In this section, we apply a deep learning method based upon UNet [
38] to obtain the land cover map from a HR image. UNet is a popular network for semantic segmentation in computer vision, and has been successfully used for land cover classification from remote sensing images. When compared with traditional image classification methods that are based on machine learning, UNet can automatically derive high-level semantic features of images, and perform semantic segmentation in an end-to-end way. In this study, the adopted UNet uses four multispectral bands of HR images for classifying seven land cover types [
39], i.e.,
trees, grass, shadow, water, bare soil, buildings, and
others.
The main parameters of the UNet classification were set, as follows: stochastic gradient descent with momentum optimizer was used with the momentum value of 0.9, and the initial learning rate was set to 0.05 with the L2 regularization. The UNet used four channels of a HR image. The training dataset of the UNet classification was collected by digitizing the HR images into ground truth land cover areas. Because the two images (GF2 and ZY3) were acquired in the same year, we collected the training dataset (i.e., reference land cover areas) that was mainly based on the GF2 image, and then re-used the dataset with a slight correction to classify land cover on the ZY3 image.
3.2. Characterizing Urban Structures by Graphs
The arrangement of land cover objects and their structures plays an important role in separating the land use types from a HR image. We use graph theory to model the topological relations between neighboring land cover objects. The pairwise relations between land cover objects are represented in a graph. Let be a graph with a set of nodes and a set of edges , where n and m are the number of nodes and edges, respectively. A node v refers to either a land cover object or a land use unit, which corresponds to or , respectively, and an edge e refers to the linkage of two nodes. Besides, features can be assigned to each node, leading to a feature matrix for all nodes . High-level structural features are extracted from graph-structured data, and then used for land use classification.
To create a graph
, we first need to determine graph nodes
, i.e., the basic spatial objects for analysis, and obtain their edges
to model their pairwise relations. In this study, we used image objects created from image segmentation as nodes, while graph edges describe the spatial adjacency of images objects in a land use unit. More specifically, the image segmentation was conducted by multi-resolution segmentation implemented in eCognition software. For the GF2 image, we set the scale parameter to 60, while 30 for the ZY3 image because of a lower spatial resolution. The obtained image objects were over-segmented to maintain fine spatial details [
11]. The adjacency relationships between neighboring image objects was specified by an adjacency matrix, which was computed from a Delaunay triangulation that was built based upon the centroids of image segments (
Figure 2). The use of Delaunay triangulation in order to determine the adjacency of neighboring spatial objects was previously investigated in [
40].
3.2.1. Graph Features Derived via Graph Convolutional Networks
For a graph
, GCN learns hidden representations
for each node
v by aggregating its neighborhood information. Let
be the feature vector of node
at the
lth GCN layer, and
be the feature matrix of all nodes
. A
lth layer GCN aggregates information via the following layer-wise propagation rule [
36],
where
is the adjacency matrix of graph
with added self-connections,
I is the identity matrix,
is a degree matrix of
with
,
is a learned weight matrix,
equals
, and
represents an activation function, such as the ReLU function. The label of nodes
can be predicted as
at the last layer of the GCN while using the
function,
where
.
In this section, we use a two-layer GCN for land use classification [
11]. More specifically, we create a subgraph
for each land use unit based upon two types of nodes, which correspond to a number of land cover nodes
and a land use node
. A land cover node refers to a land cover object within the land use unit, and the its edges model the linkage between the adjacent land cover objects. For the land use node, its edges model the linkage between land cover objects and the land use unit. In urban areas, the number of land cover objects vary between different land use units, leading to big variation among subgraphs
representing land use units. Li [
11] proposed compressing a graph that models the relations between land cover objects into the graph that models the relations between land cover types by creating a AUM. We use the same strategy in order to compress the size of graphs with respect to land use units.
Moreover, we use Bayesian methods in order to integrate information regarding spatial arrangement and spatial composition. Let
C be the class variable of land use types with the number of
classes,
be the attribute variable of spatial arrangement, and
be the attribute variable of spatial composition. We assumed that the variable
is independent of
. Based upon Bayes’ theorem [
11], the label of unclassified land use units can be assigned by
Here, the prior probability
was set equally for all land use classes, the conditional probability
was approximated by the probabilistic output of
by GCN. Regarding parameter settings associated with the used GCN model, we set the number of hidden units to 24, the maximum number of epochs to 400, the initial learning rate to 0.01 using a L2 loss, and the drop rate to 0.5 [
11]. The conditional probability of
was approximated by the probabilistic output of a SVM classification while using histogram intersection kernel [
41], based on spatial composition features. More specifically, the spatial composition features refer to the coverage ratio and density of a specific land cover class within a land use unit [
9].
3.2.2. Graph Features Derived via Graph Kernels
In machine learning and pattern recognition, kernel methods have also been popularly used for handling graph-structured data, referring to graph kernels, particularly with the SVM classifier. We compare land use classifications between the structural features that were extracted by GCNs and graph kernels.
Given data points
, a kernel
k is a function
, where
denotes a mapping from
to a feature space
, e.g., a Hilbert space [
42]. We are interested in constructing kernels for graph-structured data analysis, corresponding to graph kernels, i.e.,
where
and
refer to graphs. Recently, Kriege [
33] conducted a comprehensive review on graph kernels by analyzing their expressivity, non-linear decision boundaries, accuracy, and agreement for benchmark graph-structured datasets. Among them, the Weisfeiler–Lehman subtree kernel [
43] achieved the best overall performance and the state-of-the-art in graph classification, motivating our choice of graph kernel in this study. This kernel is a successful instance of the Weisfeiler–Lehman kernel framework [
43], which is built upon the Weisfeiler–Lehman test of isomorphism [
44]. Given two graphs
and
, the two graphs are considered to be isomorphic if and only if a pair of nodes in
is connected by an edge in the same way as the corresponding pair of nodes in
. See [
43] for a detailed description on the Weisfeiler–Lehman subtree kernel. For the subtree kernel, we set its main parameter, i.e., the number of iterations, to 6.
3.2.3. Graph Features Derived via Feature Engineering
Extracting graph features via feature engineering, referred to as handcrafted graph features, has also been studied in the past [
24,
45,
46]. For example, Walde [
24] investigated a number of graph features based on graph centrality, adjacency unit matrix (AUM), graph connectivity, and geometry in order to classify urban structure types. These features are also used in our study for land use classification (
Table 2). Based upon handcrafted graph features, we use a random forest to classify land use units into different land use classes. For the random forest algorithm, we set its main parameter, i.e., the number of trees, to 500.
3.3. Performance Evaluation and Accuracy Assessment
We extracted high-level structural features by GCNs, and applied a Bayesian classifier (as mentioned in
Section 3.2.1) to land use classification on both GF2 and ZY3 images. We labeled this classification as
for convenience (No. 1 in
Table 3). In order to evaluate the performance of this method, we compared with nine different methods using spatial arrangement and composition features, leading to three categories (
Table 3). The choice of these methods was motivated, as follows.
, SVM classification only uses features of spatial composition. It is a traditional method, and it can serve as a baseline to compare with classifications using features of spatial arrangement.
, SVM classification only uses landscape metrics: fractal dimension, landscape shape index, and Shannon’s diversity index. These metrics were investigated by existing studies [
19], and they demonstrated their effectiveness in characterizing spatial structures.
, SVM classification uses both spatial composition features and landscape metrics [
9]. The above-mentioned two methods only characterizes the spatial properties of land use units from one aspect, i.e., either spatial composition or spatial structures. We believe that the integration of the two aspects can improve classification performance.
, GCN classification that automatically derives high-level structural features while using a GCN. This method has been recently applied to land use classification from VHR remote sensing images [
11]. It is also of great interest to use this method on HR images.
, SVM classification uses the Weisfeiler–Lehman subtree kernel. It is an automatic method for graph feature learning. [
43] stated that the subtree kernel achieved the best overall performance among many others. Therefore, the
can be seen as a state-of-the-art method while using graph kernels.
, random forest classification uses handcrafted graph features [
24]. It is a common practice to manually derive features for graph-structured data analysis. The adopted method achieved successful results in classifying urban structure types [
24]. Therefore, we consider it to be a suitable benchmark method for land use classification.
and , Bayesian classifications by combining spatial composition features and structural features that are derived from graph kernels and feature engineering, i.e., and .
, a variant of
by taking the type of building roofs into account when computing the spatial arrangement and composition features. We further divided classified buildings into
dark roof, gray roof, brick-color roof, blue roof, and
bright roof based on spectral features while using a SVM classifier [
9].
We compute a confusion matrix [
49] based on sample points collected by visual interpretation while using a stratified sampling strategy in order to evaluate the accuracy of the land cover map derived from a high resolution remote sensing image. The confusion matrix is also used to assess the accuracy of land use classifications.
5. Discussion
This study focused on the comparison of land use classifications between different graph-based methods, and between different high resolution remote sensing images. We investigated three kinds of graph-based methods, i.e., by the handcrafted method (i.e., feature engineering), graph kernels, and graph convolutional networks (GCNs), in order to extract structural features for the classification. The GCNs and graph kernels methods have been recently used as state-of-the-art methods for dealing with graph-structural data. We compared ten different land use classifications that are based upon the extracted structural features, and experimented on two remote sensing images, i.e., a very high resolution (VHR) image from the GF2 satellite with a spatial resolution of 0.8 m and a high resolution (HR) image from the ZY3 satellite of 2.5m. Our results reveal that the structural features that are derived from GCNs and graph kernels provide better classification performance than that using handcrafted methods, and they have a high potential for different applications. In general, the classification accuracies that were obtained by the GF2 image are higher than that of the ZY3 image, due to a higher spatial resolution. Nonetheless, the ZY3 satellite has a larger swath, and can be used for collecting images with broader coverage, facilitating to land use mapping over large areas. Previous research has highlighted the importance of the spatial arrangement of land cover objects for land use mapping from VHR images [
9], and shown that graph-based methods, like GCNs [
11], can effectively model the spatial arrangement information. However, to the best of our knowledge, little research has been conducted on the comparison of land use classifications between popular graph-based methods while using VHR images, particularly less using HR images. This study contributes to adding such gap information.
We model the pair-wise relations between neighboring land cover objects into a graph. Thus, it is essential to identify key types of land cover objects preliminarily. This study uses a deep learning method that is based upon the UNet model in order to classify land cover from the GF2 and ZY3 images. The classified land cover maps from the two images show similar attribute accuracies in terms of confusion matrix when using a point-by-point evaluation. Regarding the geometrical accuracy, the classified land cover map of the GF2 image has a better delineation of the boundaries of individual land cover objects than the ZY3 image due to higher spatial resolution (
Figure 6). For example, on a ZY3 image of 2.5 m resolution, small buildings and buildings in densely populated areas are difficult to be delineated. This difficulty may affect the modelling of urban structures based on the pair-wise relations of land cover objects. This could also explain that the highest user accuracy of the classified land use map of the ZY3 image was given by
industrial and warehouses class, where the buildings usually have relatively homogeneous spectral reflectance and regular shapes. Besides, a previous study showed that the classification accuracy of land use is positively correlated with the accuracy of classified land cover [
9].
A number of methods using the structural features that were extracted from graph-structured data are applied to land use classifications. Among them, we highlighted the use of graph kernels and GCNs for automatically learning high-level structural features. Recent studies investigated the effectiveness of using GCNs for feature learning from graph-structured data, and provided a technique for data compression by adjacency unit matrix (AUM) [
11]. As follow-up research of [
11], this study added the extraction of high-level structural features that are based on a state-of-the-art graph kernel, i.e., the Weisfeiler–Lehman subtree kernel [
43]. Our results showed that both GCNs and graph kernels performed better than the handcrafted method in terms of classification accuracy. When comparing with graph kernels, the GCNs achieved the best classification performance in terms of classification accuracy. On the other hand, graph kernels can be naturally integrated with support vector machine, showing merits from the perspective of the applicability of methods. In this study, the parameters that are associated with feature learning and classification methods were set according to the literature. Further work can be conducted in order to analyze the effect of key parameters on classification performance. It is also interesting to compare the land use classifications while using high-level structural features that were learnt from graph-structured data with those using deep image features learnt from grid-structured data [
50,
51,
52], leading to our future study. Moreover, from the statistical point of view, further improvement can be conducted in order to increase the number of training and testing land use samples using a more sophisticated sampling strategy for accuracy assessment and performance evaluation.
We tested the effectiveness of the proposed method for land use mapping on one study area in Fuzhou, China. One may be interested in the applicability of the method to other areas of the world. This method follows a hierarchical land use classification framework that was proposed in [
9]. The framework starts from the classification of land cover, proceeds to the characterization of spatial arrangement and composition of land use, and ends at the classification of land use. It also highlights the importance of characterizing spatial arrangement effectively. This study used a data-driven method that was based on GCN to automatically learn high-level structural features in order to characterize the spatial arrangement. Hence, we expect this method can also be used in other different areas. Although the proposed land use classification achieved satisfactory results in this study by giving 40 land use samples per class, it is helpful to conduct a sensitivity analysis of the effect of the number of samples on the learning power of spatial arrangement features by GCN, and on the subsequent land use classification, leading to future study.
The derivation of homogenous land use units is essential in classifying land use with high accuracy, because the errors that are involved in the delineation of land use boundaries affect classification accuracy [
53]. We used official data regarding land use boundaries from the local surveying department to obtain land use units. By doing so, the produced land use maps maintain high geometric accuracy. On the other hand, such practice may constrain the use of the classification method for cases without existing data of land use boundaries. For such cases, it is important to investigate an automatic method in order to directly obtain land use units from remote sensing images, which is out of the scope of this study. However, such an investigation leads to a challenging topic and it is insufficiently addressed in the literature.
Last but not the least, in this study, we distinguished six main land use classes, i.e., high-density residential, low-density residential, commercial, industrial and warehouses, green space and entertainment land, and undeveloped land from high resolution remote sensing images, while grouping the rest into others. Within the class of others, land use may involve different subclasses, such as land for special use or with multiple categories, showing a large variety of characteristics. Future efforts can be conducted to refine the definition of land use classes, or look for more effective strategy to deal with mixed land use type.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}