1. Introduction
Change detection is the process of identifying differences in the state of an object or phenomenon by observing it at different times [
1]. As one of the important technologies for remote sensing image analysis, change detection has played an important role in the military and in civilian life, such as military strike effect evaluation [
2,
3,
4], land use [
5,
6,
7,
8,
9], and natural disaster evaluation [
10,
11,
12,
13].
Recently, deep learning (DL) has been widely applied to the field of change detection [
14,
15,
16,
17,
18,
19] thanks to its simple process, strong feature representation ability, and excellent application performance. However, there are still many challenges in change detection. First, DL-based methods usually require a large number of labeled samples to optimize the network. However, the available open-labeled datasets for remote sensing change detection are extremely scarce and predominantly very small compared to other remote sensing image-interpretation fields [
20]. For example, The Vaihingen dataset, which is widely used in remote sensing image classification [
21,
22], only contains 33 patches, and each pair of images is about
pixels. The effective sample size of Vaihingen is about
. The SZTAKI AirChange Benchmark Set [
23,
24], which is extensively used to evaluate the performance of change detection algorithms [
14,
15,
16,
18,
25], is composed of 13 aerial image pairs with size of
pixels. Therefore, the effective sample size of SZTAKI is only about
. In comparison, the data size of change detection is more than 100 times smaller than that of the remote sensing image-classification dataset. Second, the image pairs or image sequences used for change detection are often obtained from different viewpoints [
26,
27,
28,
29]. In other words, it is difficult to capture a scene from similar viewpoints every time in remote sensing change detection. As shown in
Figure 1, the buildings were shot at different times. Due to the different viewpoints, buildings have different shadows even if the image pair has been registered, which makes the comparison of image pairs more difficult. In order to alleviate the problems caused by different viewpoints, Sakurada et al. [
26] designed a dense optical flow-based change detection network. Palazzolo et al. [
30] relied on 3D models to identify scene changes by re-projecting images onto one another. Park et al. [
27] presented a novel dual dynamic attention model to distinguish different viewpoints from semantic changes. Therefore, if the algorithms do not pay attention to the viewpoints, the result of the change detection is affected. Finally, the similarity measurement method of existing change detection methods is relatively simple. The study of similarity measurement in change detection has a long history. Traditional similarity measurement methods include image difference, image ratio, and change vector analysis (CVA) [
31]. For DL-based methods, similarity measurement also plays an important role in improving the performance of model, such as the euclidean distance used in [
14], the improved triplet loss function applied in [
15], the difference skip connections adopted in [
25], and the feature space loss designed in [
32]. Similarity measurement is one of the important factors affecting the separability of sample pairs in change detection. It is beneficial to improve the performance of change detection to make sufficient and effective comparison of the features between sample pairs.
To deal with the small training data size in change detection datasets, some scholars chose unsupervised methods [
16,
33,
34]. These methods did not require labeled training samples, but the performance of these algorithms could be improved. To cope with this problem, Xu et al. [
18] took advantages of the capsule network [
35] and designed the pseudo-siamese capsule network. Siamese network has two branches in the network that share exactly the same architecture and the same set of weights. For pseudo-siamese, it has two identical branches but the weights of two branches are not shared. The capsule network used vectors for feature extraction and dynamic routing technology for features aggregation. As shown in much existing literature [
35,
36,
37], the capsule network could use less training samples to reach the comparable performance than traditional convolutional neural networks (CNN). Moreover, the pseudo-siamese capsule network achieved satisfactory results on small open-labeled remote sensing change detection datasets, which confirmed that a capsule network was very suitable for change detection.
Unfortunately, the pseudo-siamese network still has some shortcomings. First, the pseudo-siamese capsule network [
18] did not analyze the experimental results of the image pairs that were obtained from different viewpoints. Vector-based features and the dynamic routing technology in a capsule network are beneficial to the capsule network when dealing with the pose information (e.g., translation, rotation, viewpoint, and scale). In other words, the pseudo-siamese capsule network may alleviate the problem caused by different viewpoints in image pairs to some degree. It may be limited by the open dataset in which the problem of different viewpoints is not obvious and for which the pseudo-siamese capsule network did not investigate thoroughly in the experiments. Second, the weights of the two branches in the pseudo-siamese network were not shared in order to maintain the flexibility of the model [
38], which may cause feature space offset. Therefore, the features that were extracted by the pseudo-siamese network were uncomparable. Finally, the extracted features were directly concatenated in the pseudo-siamese capsule network, which led to insufficient features comparison.
In order to alleviate the problems mentioned above, we carried out the following works. First, the AUAB dataset in which the sequence images are different in terms of illumination, season, weather, and viewpoint was collected from the Google Earth. Second, the reconstruction module on an unchanged region was designed. As a regularization method, this module drives the network to maintain the feature consistency on an unchanged region, which keeps the comparability between feature pairs. Finally, in order to make similarity measuring more efficient, the vector-based features output by the capsule network were compared for both direction and length in the forms of vector cosine and vector difference, which can alleviate the insufficient feature comparison in the pseudo-siamese capsule network.
The main contributions of this paper are summarized as follows:
This paper proposes a novel change capsule network for optical remote sensing image change detection. Compared with other DL-based change detection methods, the proposed change capsule network has good performance and robustness.
In order to make the extracted feature pairs in a change capsule network more comparable and separable, this paper designs an unchanged region reconstruction module and a vector cosine and vector difference module, respectively.
The AUAB dataset, which simulates practical applications, is collected to further analyze the viewpoints in change detection. Moreover, experiments on the AUAB dataset and the SZTAKI dataset show the effectiveness and robustness of the proposed method.
The rest of this paper is organized as follows. The background of the proposed method is introduced in
Section 2, and
Section 3 introduces the proposed method in detail. In
Section 4, the dataset and present experimental results are described to validate the effectiveness of the proposed method. In
Section 5, we discuss the results of the proposed method. Finally, the conclusion of this paper are drawn in
Section 6.
3. Proposed Method
In this section, the proposed change detection algorithm based on change capsule network is detailed. The framework is illustrated in
Figure 4. First, the features of image pairs are extracted using two identical non-shared weight capsule networks to maintain the flexibility of the model. The shape of vector-based features output by the backbone is
. Each capsule represents the feature of a pixel. Second, the unchanged region reconstruction module is adopted to make the feature space of the unchanged region more consistent. This module takes the features (the shape is
) of image 1 as input to reconstruct the unchanged region in image 2. Third, the vector-based features output by capsule network are compared for both direction and length in the forms of vector cosine and vector difference. The outputs of vector cosine and vector difference are both change probability maps that can be optimized using the ground truth. Finally, a binary change map can be produced by analyzing the result of vector cosine and vector difference.
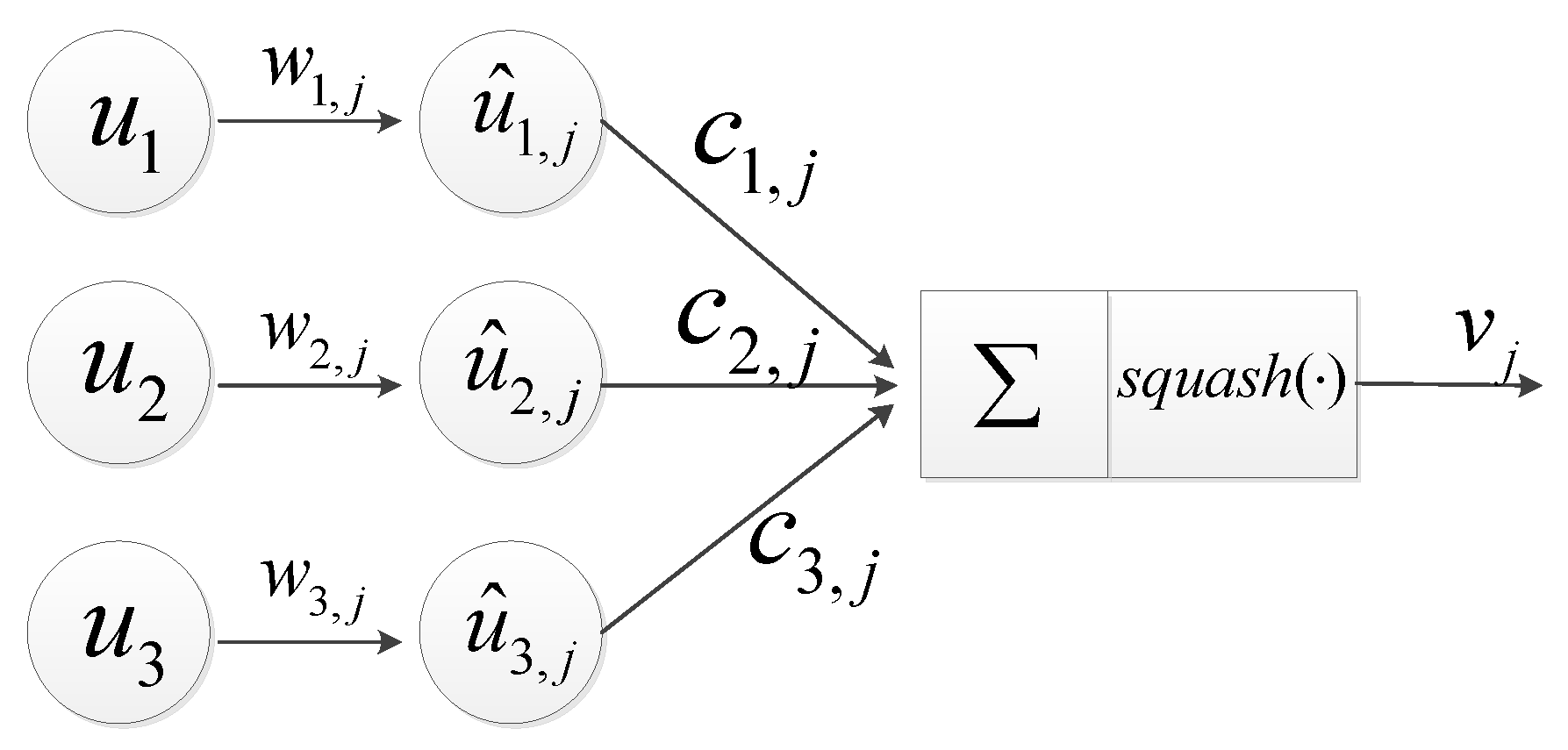
3.1. Capsule Network as Backbone
The backbone used in the change capsule network is modified from SegCaps [
51]. SegCaps improved the traditional capsule network by implementing a convolutional capsule layer and a deconvolutional capsule layer. Unlike the original capsule network [
35] that only outputs the category of the entire image, SegCaps implements the classification of each pixel of the input image. The structure of SegCaps is similar to U-net [
52], including the encoder–decoder and skip connections structure. SegCaps and its improved version have been applied to the fields of image segmentation [
51], image generation [
43], and change detection [
18]. Change capsule network uses SegCaps as the backbone to make full use of semantic and contextual information. The detailed parameter setting of the backbone is illustrated in
Figure 5. Let the size of the input image be
; then, the shape of the output vector-based features is
.
3.2. Unchanged Region Reconstruction Module
A change capsule network was designed based on the pseudo-siamese network [
18]. The pseudo-siamese network provides more flexibility than a restricted siamese network does because the weights of pseudo-siamese network are not shared [
38]. However, the weights of two unshared branches may cause feature spaces to be inconsistent, which leads to a lack of comparability in the features extracted by the network. Therefore, the reconstruction module on the unchanged region was designed. As a regularization method, this module drives the network to maintain feature consistency on the unchanged region, which improves the comparability between feature pairs.
As shown in
Figure 6, vector-based features (the shape is
) output by the backbone are reshaped to scalar-based features (the shape is
). Then, two convolutional layers for which the convolution kernel size is
are applied to the scalar-based features to obtain the global feature map (
). In order to obtain the unchanged region map and unchanged region features, a merge mechanism is designed.
Let
be the global feature map and
represent the ground truth, where
means the corresponding pixel pair unchanged and
means changed. The unchanged region features
can be obtained as follows:
Let
represent input image 2. The unchanged region map
can be obtained as follows:
In
Figure 6, a black mask is used to cover the change region, so the unchanged region map is the input image 2 without the black mask.
The unchanged region reconstruction module uses the mean squared error (MSE) loss to optimize, and the function is shown as follows:
It can be seen from Equation (
6) that the unchanged region features is more and more similar to the unchanged region map.
3.3. Comparison of Vector-Based Features
It is known that the output of the backbone is a vector for which the length is between
. Let the output vectors of the two branches be
and
, respectively, where (i,j) represents coordinates.
The vector difference between
and
is as follows:
Therefore, the length of difference vector
is as follows:
where
is the angle between two vectors.
Then, linear function
f is applied to scale
to between
. The linear function
f is as follows:
Therefore, the output of vector difference similarity comparison is
, where the value range is as follows:
The larger , the more likely the corresponding pixel pair changes. Therefore, the output of the vector difference similarity comparison can be used to optimize network parameters.
To analyze the direction of the output vector in a capsule network, we used the vector cosine. For any two vectors, their cosine value is between
. Therefore,
, where
is the angle between
and
. We also utilize a linear function
g to scale
to between
. The expression is as follows:
Therefore the output of vector cosine similarity comparison is
, for which the value range is as follows:
The larger , the larger . In other words, the larger the angle between the two vectors, the more likely the corresponding pixel point changes. Therefore, the output of vector cosine similarity comparison can be used to optimize network parameters.
There are four situations when we use vector cosine and vector difference to optimize network parameters: (1) The angle between two vectors is large and the length of the difference vector is large. (2) The angle between two vectors is small but the length of the difference vector is large. (3) The angle between two vectors is large but the length of the difference vector is small. (4) The angle between two vectors is small and the length of the difference vector is small.
Figure 7 shows the four situations, where the unit circle can represent the feature space because the length of the output vectors in capsule network is range of
. It can be seen from the above that vector cosine and vector difference is not contradictory during network optimization.
During the test time, only a simple threshold (0.5) is needed to obtain the binary results of the vector cosine similarity comparison and the vector difference similarity comparison. Let
be the binary change map of vector cosine similarity comparison,
be the binary change map of vector difference similarity comparison, and
be the final change map. There are four methods of fusion for a change capsule network inference: First, we only use the result of the vector cosine similarity comparison:
Second, we only use the result of the vector difference similarity comparison:
Third, the result of the OR gate operation on the vector cosine similarity comparison and the vector difference similarity comparison is regarded as the final binary change map. In other words, either the output of vector cosine or the output of vector difference is changed; the final result is changed. The expression is as follows:
Finally, we use the result of the AND gate operation on the vector cosine similarity comparison and the vector difference similarity comparison as the final binary change map. That is, both the results of vector cosine and vector difference are changed; the corresponding pixel is changed.
In this paper, these four fusion ways all can obtain satisfactory, but we used the AND gate operation. We analyze the reason in the experimental part.
3.4. Loss Function
The loss function of a change capsule network consists of two parts. MSE loss is used in the unchanged region reconstruction module, and Margin-focal loss [
18] is applied to the similarity comparison. Margin-focal loss takes the advantages of focal loss [
53] and margin loss [
35], which can effectively alleviate samples imbalance in capsule network. The margin-focal loss is defined as follows:
where
is the output of the vector difference similarity comparison or the vector cosine similarity comparison at spatial location
and
is the label.
is a focusing parameter, and
is a balance parameter.
and
are the margin.
The final loss function is defined as follows:
where
is the output of the vector cosine similarity comparison,
is the output of the vector difference similarity comparison,
is the binary label,
is the unchanged region features,
is the unchanged region map, and
is a balance parameter.
3.5. Detailed Change Detection Scheme
The change detection scheme in this paper is composed of two stages: training and inference.
Training: First, we use two identical non-shared weights capsule networks to extract the vector-based features of image pairs. Second, the features of image one are sent to the unchanged region reconstruction module to reconstruct the unchanged region of image two to make the feature space more consistent. Third, the vector-based features output by capsule network are compared for both direction and length in the forms of vector cosine and vector difference. Finally, we use Equation (
21) to optimize network parameters.
Inference: First, the vector-based features of image pairs are extracted using two identical non-shared weights capsule networks. Second, the extracted vector-based features are compared for both direction and length in the forms of vector cosine and vector difference. The binary result of the vector difference similarity comparison and the binary result of the vector cosine similarity comparison can be produced by a simple threshold (0.5). Finally, the binary change map can be produced by analyzing the result of vector cosine and vector difference. Only when the result of the vector cosine comparison and the result of teh vector difference comparison are both changed can the corresponding pixel be considered changed.
5. Discussion
The experimental results of the ablation experiments and the comparison experiments prove that the proposed method can effectively improve the performance of a change detection network. In the ablation experiments, the unchanged region reconstruction module and the vector cosine and vector difference module were applied to the baseline, respectively. The vector cosine and vector difference module measures the difference in the vector-based features for both length and direction, which can effectively filter noise and enlarge the separability between the changed pixels and the unchanged pixels. For the unchanged region reconstruction module, it drives the network to maintain feature consistency in the unchanged region when the image features are extracted. In the comparison experiments, the proposed method obtains better results in terms of recall, F-rate, and Kappa while maintaining high precision compared with other methods. In other words, the proposed method is more suitable for the application scenarios in which high recall is required.
Although the proposed method achieves satisfactory change detection results, the inference time and the amount of model parameters need to be further improved. Compared with FC-Siam-diff, the change capsule network is time-consuming and has a large amount of parameters. The trainable parameters of the change capsule network are about , and it takes about 2 seconds to infer an image pair with size of . For FC-Siam-diff, the trainable parameters are about and the inference time is under 0.1 seconds. Therefore, reducing the amount of model parameters and inference time can make the proposed change detection method more widely used.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}