In this section, we introduce the proposed scale-sensitive detection network—HSSCenterNet. We first introduce an improvement over the detection part of CenterNet, which makes it possible to generate tilted bounding boxes. Then, we will introduce in detail the structure of the proposed network. Finally, we introduce the training and test strategies.
3.1. Tilted Bounding Box
The use of tilted bounding boxes in optical remote sensing images to detect ships has more advantages than the use of horizontal bounding boxes: (1) The ship target is elongated, and the boundary of the tilted bounding box is close to the outline of the ship, avoiding excessive background information to introduce noise; (2) Ship targets are often arranged closely together, and the tilted bounding boxes are marked more clearly to avoid the problem of overlapping labels in horizontal bounding boxes; (3) The tilted bounding boxes can express the orientation information of the ship, which is an important feature of the ship. Tilted bounding boxes can also be subdivided into two categories: rotational bounding box and orientational bounding box. The difference between the rotation bounding box and the orientational bounding box is that the rotation bounding box itself has no direction but only expresses the posture of the rectangle. Rotating
around its center still represents the same rotation bounding box; while the orientational bounding box itself has a direction, for example, the arrow in
Figure 1c indicates the direction of the tilted bounding box, rotating
around its center will indicate another tilted bounding box.
The tilted bounding box needs to indicate the posture or direction of the target, and there are many ways to indicate it. The most common is to use the
quintuple to represent an tilted box, as shown in
Figure 2a. Literature [
36] and Literature [
37] both use five-parameter notation, and they agree:
represents the geometric center of the box;
w and
h represent the width and height of the box, respectively;
is the long side of the box and the included angle of the x-axis of the image coordinate system is
. When the angle is around
and
the box will be very close, making it difficult for the network to return. SCRDet [
38] also uses
five-parameter notation, but it adopts the same convention as OpenCV:
is still the geometric center of the tilted box;
represents the angle of the x-axis positively and counter-clockwise rotated to the first side of the rectangle. This side is defined as
w, and the other side is defined as
h; then
. Under this convention, the ‘first side’ is difficult to parameterize in the neural network, which will bring difficulties to the learning process. The improved five-parameter notation uses
, as shown in
Figure 2b:
and
are the two endpoints of one side, and
h is the other side’s length. The eight-parameter method directly uses the coordinates of the four vertices of the rectangle to represent an oblique bounding box, as shown in
Figure 2c. P-RSDet [
39] first predicts the geometric center
of the box, and uses
as the origin to establish a polar coordinate system. The four vertices of the rectangle are expressed as
, as shown in
Figure 2d, where
, let
, then
can be expressed as a tilted bounding box.
Figure 2e replaces the angle
with a direction vector
on the basis of (a) to indicate the posture and orientation of the tilted bounding box. If the direction of the ship is specified in the annotation data, this representation method is good; but if the direction of the ship is not specified in the annotation data, the direction vector
may point to the bow or the stern of the ship, causing confusion.
This paper proposes a representation method of the tilted bounding box as shown in
Figure 2f.
is the geometric center of the tilted bounding box. The long and short sides of the tilted bounding box are
w and
h,
and
is a unit vector of equal size and opposite direction, then
,
. In this paper,
are called dual direction vectors. When the direction is not specified, the method indicates a rotating tilt bounding box; when the direction is specified, the method indicates a direction tilted bounding box.
A number of anchor-free methods have been proposed in the past several years [
30,
40,
41,
42]. CenterNet [
30] is a typical and smart anchor-free design for object detection. We choose CenterNet as the basic detection framework and Resnet50 [
43] as the basic backbone network for feature extraction. The original CenterNet detection part uses three branches to predict the center point heat map, center offset compensation, and the width and height of the box to output the horizontal detection bounding box. This article adds a fourth branch to it to predict the box pose, as shown in
Figure 3. The box pose prediction branch is also composed of a two-layer convolutional network, the number of convolution kernels in the first layer is 256, and the number of convolution kernels in the second layer is 4. Therefore, the number of tensor channels output by the block pose prediction branch is 4, and each channel represents 4 values of the dual direction vector. The improvement of the detection part of CenterNet in this paper enables the neural network to handle both the horizontal bounding box and the tilted bounding box object detection task.
3.2. The Structure of the Network Model
From the analysis and research in the previous content, we can know that the convolutional features of the backbone network have different characterization characteristics for ship targets of different scales. The use of fusion features can adjust the object detection performance of various scales, but it is difficult to balance the detection performance of full-scale targets in a single convolution feature. That being the case, why can we not adopt the strategy of “divide and conquer, destroy each” and use suitable convolution features to detect ship targets of different scales? Ship targets in each scale range are detected using the convolution features that best match their characterization characteristics, so that the problem of finding a global optimal solution can be transformed into a problem of finding multiple local optimal solutions.
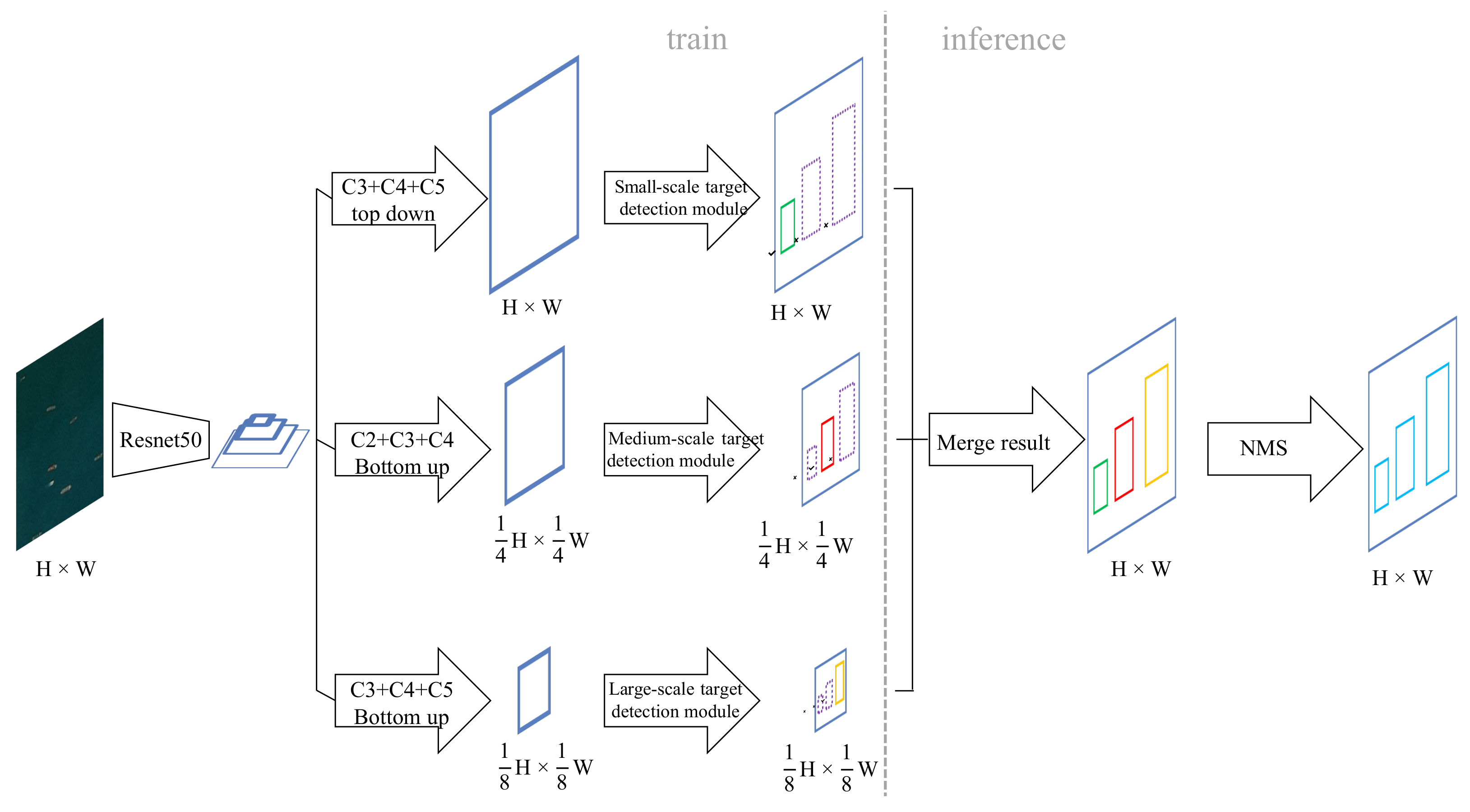
Based on the above ideas, we propose a hierarchical scale sensitive CenterNet (HSSCenterNet) object detection algorithm. The network structure and data flow are shown in
Figure 4. The image is input into the feature-extraction network, which obtains four basic features, and Resnet50 is employed as the basic network. Next, the features are passed into three branches, which deal with the ship-detection tasks of small-scale, medium-scale, and large-scale, respectively. For small-scale ship targets, C3, C4, and C5 of the four basic features are selected to fuse along the top-down path, and feature maps are resized to be consistent with the input image to obtain the small-scale fusion feature. Afterwards, the fusion feature is input into the small-scale object detection module, which will only use the fusion features to detect small-scale ship targets. For the medium-scale ship target, C2, C3, C4 features will be selected to fuse along the bottom-up path, and feature maps are resized to
of the input image to obtain the medium-scale fusion feature. Similarly, the fusion feature will be processed by the medium-scale object detection module. C3, C4, and C5 features will be fused along a bottom-up path for large-scale ship detection, and the feature maps will be resized to
of the input image. The network structure of the detection modules of large, medium, and small scales is the same, and they all use the improved CenterNet detection part, as shown in
Figure 3. That is to say, the three detection branches will output the center point heat map, the width and height value of the target box, the center point quantization compensation value, and the dual direction vector of the box, but each branch will only predict the result of the corresponding scale. Then, since the results of the three different scales are predicted based on different convolution feature sizes, they are scaled and merged to the original input image size. Finally, the non-maximum suppression algorithm is used to de-duplicate the combined results to obtain the final detection result.
HSSCenterNet is essentially a multi-task network architecture. It decomposes the object detection task into three subtasks: large-scale object detection, medium-scale object detection, and small-scale object detection. Each subtask shares the weight of the basic feature extraction network, and the parameters of each branch network are independent of each other, and the training and inference of the three are not interfering with each other.
3.3. Network Model Training
Let denote the input image, the width is W and the height is H. For ship targets in each scale range, the neural network outputs the center point heat map , center point offset compensation , box size , and the bounding box pose , where represents the small-scale, the medium-scale, and the large-scale, respectively. Assuming that there is a ship target in the training sample image I, the coordinates of the upper left and lower right corners of its box are . Then its center point is , and the coordinate of point p is . Its size is , and s is expressed as .
Center point heat map
, where
is downsampling rate and
C is the number of categories. Here
, because there is only one category of ship. The prediction result
indicates that the point corresponds to the center of a target box, and
indicates the background. For the ship target of each scale in the image
I, the center point of the box is
p, and the category is
. The corresponding point of point
p on the center point heat map is
. We use Gaussian kernel to spread the center point of the training sample on the heat map
Above,
, where the standard deviation
related to the box size. If the Gaussian distributions of the two center points coincide, take the larger value. We use an improved focal loss supervised neural network to predict the center point heat map, which is an optimized objective function for pixel logistic regression with penalty terms:
where
and
are the hyperparameters in focal loss, and
is the number of target center points with scale ∗ in image
I.
is used to normalize the focal loss values of the center points of all positive samples of this scale. In this experiment,
and
are set.
Since the size of the center point heat map is different from the input image, there is a quantitative offset from the predicted coordinates on the center point heat map. The offset compensation of the center point of each target box is
. The offset compensation prediction is trained using the L1 loss function:
In the training, the loss value is only calculated for the pixel where the point
is located, and other positions are not involved in the calculation. After predicting the center point
p of the target box, it is also necessary to predict the width and height of the box, or the size of the box
. The dimension of the target box where point p is located is
. Similar to the center offset compensation, the optimization goal of the box size is also the L1 loss function:
When predicting the width and height of the box, it will not be regularized or obtained from the center point heat map, but directly return to the size of the target in the coordinate system of the input image. If you perform the task of detecting tilted bounding boxes, you also need to predict the pose of the bounding box
, that is, the labeled dual vector of the target box where the point p is located as
, and the predicted dual direction vector is
. The optimization goal of the tilt bounding box attitude prediction network consists of three parts. The first part is the
loss function:
The two vectors,
, and
, are equal in size and opposite in direction. This constraint is regarded as the second part of the optimization objective
,
and they are also unit vectors at the same time. The third part of the optimization objective is
,
Therefore, the tilt box pose loss function can be formulated as
where the parameters are empirically set as
. The network we designed uses three branches to detect targets of different scales. The optimization goal of each detection branch are as follows,
where the parameters
are also empirically set in the experiment. As a results, the optimization goal of the entire network is formulated by
Obviously, if there is no restriction, each scale detection branch will be affected by samples of other scales during training. For example, the small object detection branch will calculate the loss value of the large and medium target samples during training, and the small object detection branch will receive the interference from large and medium scale samples when returning the gradient update weight parameter in . The same is true for the medium-scale and large-scale object detection branches.
In order to avoid a single branch from being affected by targets of other scales during training, TridentNet [
26] uses the proposed region selection mechanism proposed by SNIP [
23]. We also use this mechanism. Assuming that the ship target width and height calculated in the forward direction during training are
w and
h, respectively, then only when
, the gradient of the target sample participates in the reverse calculation. Here
and
, respectively, represent the upper and lower limits of the effective scale of the scale
detection branch. Since SNIP [
23] and TridentNet [
26] use Faster-RCNN [
11] as the basic detection bounding boxwork, it is very convenient and reasonable to use the selection mechanism in RPN and RCNN. When training an RPN, you only need to select a valid sample when the training sample assigns a label to the anchor box. When training RCNN, you only need to select valid samples when the training samples assign labels to the proposed region. However, CenterNet is a single-stage non-anchor bounding box detection bounding boxwork, and it is difficult to screen effective samples as clearly as the anchor bounding box mechanism. The three detection branches of TridentNet are calculated in the same coordinate reference system, and the three detection branches of the HSSCenterNet we designed have been scaled at different sampling rates, which means that the coordinate reference systems calculated by the three are not the same. Therefore, when generating training label data, it is necessary to generate three sets of label data corresponding to the sample sizes of the three detection branches.
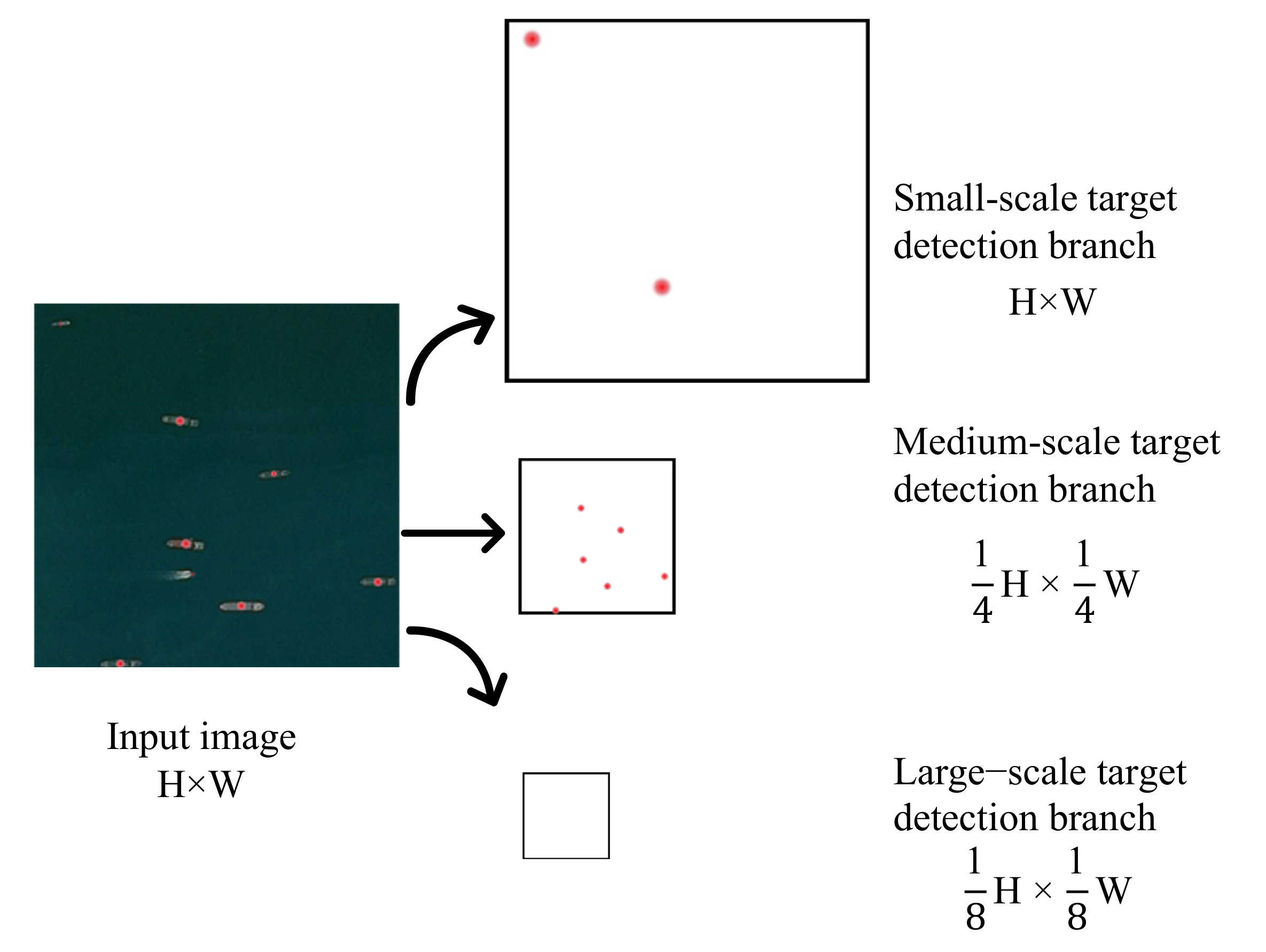
As shown in
Figure 5, the input image size is
, and there are 3 heat maps at the center of the target box. The size of the heat map corresponding to the center point of the small-scale detection branch is
, which only includes the center point distribution of small-scale ships; the size of the center point heat map corresponding to the medium-scale detection branch is
, and this map only contains the center point distribution of medium-scale ships; the size of the center point heat map corresponding to the large-scale detection branch is
, which only includes the center point distribution of large-scale ships. If the training image does not contain a ship target within the range of a certain detection branch scale, a blank heat map is used instead. For example, the training image in
Figure 5 does not contain large-scale ship targets, and the heat map corresponding to the large-scale detection branch is still generated. This is to facilitate the use of larger batch sizes when training the model.
As explained in the previous subsection, the standard deviation of the Gaussian distribution
on the heat map in the standard CenterNet is
, where
r is the radius of the distribution circle of the actual label bounding box distribution of the positive sample. The distribution radius
r is related to the intersection of the actual labeling bounding box and the distribution of positive samples than the threshold
t and the size of the labeling bounding box
,
, where
p represents the center point of the labeling bounding box. Since the size of the convolution feature used for detection of each branch is different, the standard deviation
of the two-dimensional Gaussian distribution on the heat map corresponding to the center point of each branch is also different, and the specific settings are as follows:
At the same time, the training data of center point offset and box size should be divided into three groups according to the size. In short, the annotation data of a training image needs to be divided into three parts, corresponding to three detection branches of different scales.
This hierarchical multi-scale training mechanism (HMSTM) can make it possible to distinguish scale differences. From the perspective of the backward calculation process when returning the gradient and updating the weight, the parameters of the small-scale detection branch are only updated by small-scale target samples, and the parameters of the medium-scale detection branch are only updated by the medium-scale target samples. The parameters are only updated by large-scale target samples. When the weight of the basic feature extraction network is updated, its gradient is the sum of the three branch return gradients, which means that the parameters of the basic network are updated by all samples.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}