Abstract
Remote sensing products with high temporal and spatial resolution can be hardly obtained under the constrains of existing technology and cost. Therefore, the spatiotemporal fusion of remote sensing images has attracted considerable attention. Spatiotemporal fusion algorithms based on deep learning have gradually developed, but they also face some problems. For example, the amount of data affects the model’s ability to learn, and the robustness of the model is not high. The features extracted through the convolution operation alone are insufficient, and the complex fusion method also introduces noise. To solve these problems, we propose a multi-stream fusion network for remote sensing spatiotemporal fusion based on Transformer and convolution, called MSNet. We introduce the structure of the Transformer, which aims to learn the global temporal correlation of the image. At the same time, we also use a convolutional neural network to establish the relationship between input and output and to extract features. Finally, we adopt the fusion method of average weighting to avoid using complicated methods to introduce noise. To test the robustness of MSNet, we conducted experiments on three datasets and compared them with four representative spatiotemporal fusion algorithms to prove the superiority of MSNet (Spectral Angle Mapper (SAM) < 0.193 on the CIA dataset, erreur relative global adimensionnelle de synthese (ERGAS) < 1.687 on the LGC dataset, and root mean square error (RMSE) < 0.001 on the AHB dataset).
1. Introduction
At present, remote sensing images are mainly derived from many types of sensors. One type is the Moderate Resolution Imaging Spectrometer (MODIS), and the rest are Landsat series, Sentinel and some other types of data. The Landsat series is equipped with three sensors, including Enhanced Thematic Mapper Plus (“ETM+”), Thematic Mapper (“TM”), Operational Land Imager (“OLI”) and Thermal Infrared Sensor (“TIRS”). MODIS sensors are mainly mounted on Terra and Aqua satellites, which can circle the earth in half a day or a day, and the data they obtain have a high temporal resolution. MODIS data (coarse images) have sufficient time information, but their spatial resolution is very low, reaching only 250–1000 m [1]. On the contrary, the data (fine images) acquired by Landsat have a higher spatial resolution, which can reach 15 m or 30 m, and the data can capture sufficient surface detail information, but their temporal resolution is very low, and it takes 16 days for Landsat to circle the earth [1]. In practical research applications, we often need remote sensing images with both high temporal and high spatial resolution. For example, images with high spatiotemporal resolution can be used to study surface changes in heterogeneous regions [2,3], vegetation seasonal monitoring [4], real-time mapping of natural disasters such as floods [5], land cover changes [6] and so on. However, due to current technical constraints and cost constraints, and the existence of noise such as cloud cover in some areas, it is difficult to directly obtain remote sensing products with a high spatial and temporal resolution that can be used for research, and a single high-resolution image does not meet the actual demand. To solve such problems, spatiotemporal fusion has attracted much attention in recent decades. It is used to fuse two types of images through a specific method, to obtain images with a high spatial and temporal resolution that are practical for research [7,8].
2. Related Works
Generally speaking, the existing spatiotemporal fusion methods can be subdivided into four categories: reconstruction-based, unmixing-based, dictionary-based learning, and deep learning-based methods.
The essence of the reconstruction-based algorithm is to calculate the weights of similar adjacent pixels in the input spectral information and to add them. The spatiotemporal adaptive fusion algorithm (STARFM) is the first method to use reconstruction for fusion [8]. In STARFM, the change in reflection of the pixels between the coarse image and the fine image should be continuous, and the weight of adjacent pixels can be calculated to reconstruct the surface reflection image with high spatial resolution. Because it requires a large amount of calculation and the reconstruction effect of heterogeneous regions needs to be improved, Zhu et al., made improvements and proposed an enhanced version of STARFM (ESTARFM) [9]. They used two different coefficients to process the weights of neighbouring pixels in homogeneous and heterogeneous regions to achieve a better result. Inspired by STARFM, a new data fusion model for high spatial- and temporal-resolution mapping of forest disturbance based on Landsat and MODIS (STAARCH) [10] was used to map reflection changes and also achieved good results. Overall, the difference between these algorithms lies in the calculation of the weights of adjacent pixels. In most cases, these algorithms achieve good results. However, this method needs to be improved if the information changes too much over a short time.
The key of the unmixing-based fusion method is to unmix the spectral information at the predicted time, and then use the unmixed result to predict the unknown high spatiotemporal resolution image. Unmixing-based multisensor multiresolution image fusion (UMMF) [11] is the first application of the unmixing concept. It uses MODIS and Landsat images at different times for reconstruction: first, the MODIS image is spectrally unmixed, and then the unmixed result is spectrally reset on the Landsat image to obtain the final reconstruction result. However, Wu et al., considered the similarity of nonlinear time changes and spatial changes in spectral unmixing. Wu et al., improved UMMF and obtained a new spatiotemporal fusion method (STDFA) [12], which also achieved good fusion results. In addition, someone proposed a flexible spatiotemporal method for fusing satellite images with different resolutions (FSDAF) [13]. It combines the unmixing method, space insertion and STARFM to produce a new algorithm with a small amount of calculation, fast speed, and high accuracy, and it performs well in heterogeneous regions.
The method based on dictionary learning mainly learns the corresponding relationship between two types of remote sensing images to obtain prediction results. The spatiotemporal reflection fusion method spatiotemporal reflectance fusion via sparse representation (SPSTFM) [14] based on sparse representation may be the first fusion method to successfully apply dictionary learning. In SPSTFM, the coefficients of the low-resolution images and the high-resolution images should be set as the same, and at the same time, the idea of super-resolution from the field of natural images is introduced to spatiotemporal fusion. The image is reconstructed by establishing the correspondence between low-resolution images. However, in an actual situation, the same coefficient may not apply to some data obtained under the existing conditions [15]. In addition, Wei et al., studied the explicit mapping between low–high resolution images and proposed a new fusion method based on dictionary learning and compressed sensing theory—the spatiotemporal fusion of MODIS and Landsat-7 reflectance images via compressed sensing (CSSF) [16]. This method greatly improves the accuracy of the prediction results, but the training time is much higher, and the efficiency is lower. In this regard, Liu et al., proposed an extreme learning machine called ELM-FM to perform spatiotemporal fusion [17], which greatly reduces the time required and improves efficiency.
As deep learning has gradually developed in various fields in recent years, remote sensing spatiotemporal fusion methods based on deep learning have also gradually developed. For example, the method STFDCNN [18] proposed by Song et al., which uses the convolutional neural network for spatiotemporal fusion, is one of them. In STFDCNN, the image reconstruction process is a problem of super-resolution and non-linear mapping. A super-resolution network and a non-linear mapping network are constructed through an intermediate resolution image, and then the final fusion result is obtained through high-pass modulation. In addition, Liu et al., proposed a two-stream convolutional neural network for spatiotemporal fusion (StfNet) [19]. They used spatial consistency and temporal dependence to effectively extract and integrate spatial details and temporal information and achieved good results. Using the methods of convolution and deconvolution, combined with the fusion method from STARFM, Tan et al., proposed a new method of deriving high spatiotemporal remote sensing images using a deep convolutional network (DCSTFN) [20]. However, because the fusion method of deconvolution loses information during the reconstruction process, Tan et al., increased the initial input and added a residual coding block, using a composite loss function to improve the learning ability of the network, and an enhanced convolutional neural network for spatiotemporal fusion (EDCSTFN) was proposed [21]. In addition, there is also the CycleGAN-STF [22], which introduces other ideas from the field of vision to spatiotemporal fusion. This is spatiotemporal fusion through CycleGAN image generation: CycleGAN is used to generate fine images at the predicted time, and the real predicted time image is used to select the closest generated image and is finally combined with the FSDAF method for fusion. In addition, there are some other fusion methods for specific application scenarios. For example, STTFN [23], a model based on the convolutional neural network for the spatiotemporal fusion of surface temperature changes, uses a multi-scale convolutional neural network to establish a nonlinear mapping relationship and uses a weighting strategy with spatiotemporal continuity.
There are many types of spatiotemporal fusion algorithms, and they all solve the problems of information extraction and noise processing during the fusion process to a certain extent, but there are still problems to be solved. First, it is not easy to obtain the dataset. Due to the presence of noise, the data that can be directly used for research are insufficient, and in deep learning, the amount of data also affects learning ability during reconstruction. Second, the prediction effect of the same fusion model shows different performances on different datasets. Therefore, the robustness of the model is not high. Third, the time change information and spatial features in the coarse image extracted by the convolutional neural network are insufficient, and there will be losses at the same time. Finally, overly complex fusion methods may also introduce noise.
To solve the above problems, we propose a multi-stream fusion network for remote sensing spatiotemporal fusion based on Transformer and convolution, called MSNet. In MSNet, we scaled the coarse image to a smaller size to reduce the number of training parameters and shorten the learning time. We used five images in two sizes as input for reconstruction. We summarize the main contributions of our study as follows:
- Introduce the Transformer encoder [24,25] structure to learn the relationship between the local and the global time change information in the coarse image, and effectively extract the time information and some of the spatial structure information contained in the coarse image.
- Use the convolutional neural network Extract Net to establish the mapping relationship between the input and the output, to extract a large amount of time information and the spatial details contained in the coarse image and the fine image, and to use receptive fields of different sizes to learn and extract the different-sized input features included in them.
- For the time-varying information that is extracted multiple times, we firstly adopt a weighting strategy to add the information extracted by the Transformer encoder and Extract Net to avoid introducing noise through direct addition, and we then perform the subsequent fusion.
- The results of the two intermediate predictions are quite like the final reconstruction results. The overly complex fusion method introduces new noise to the area that already has noise. We use the average weighting strategy for the final rebuild to prevent noise.
- To verify the capabilities of our model, we tested our method on all three datasets and achieved the best result. Our model is more robust than the method compared in the experiment.
We compared the four types of fusion strategies mentioned in the previous article and made a table to visually show the salient points of each method. The specific content is shown in Table 1.

Table 1.
Comparison table of strengths and weaknesses of each method.
The rest of this manuscript has the following structure. In the Section 3, the overall structure and internal specific modules of the MSNet method are introduced. The Section 4 presents our results, including the dataset description, the experimental part, and its analysis. The Section 5 is our discussion. The Section 6 is the conclusion.
3. Methods
3.1. MSNet Architecture
Figure 1 shows the overall structure of MSNet, where represents the MODIS image at time , represents the Landsat image at time , and represents the prediction result of the fusion image at time based on time . Moreover, the three-dimensional blocks of different colours represent different operations, including convolution operations, activation functions ReLU and Transformer encoder, and other related operations.
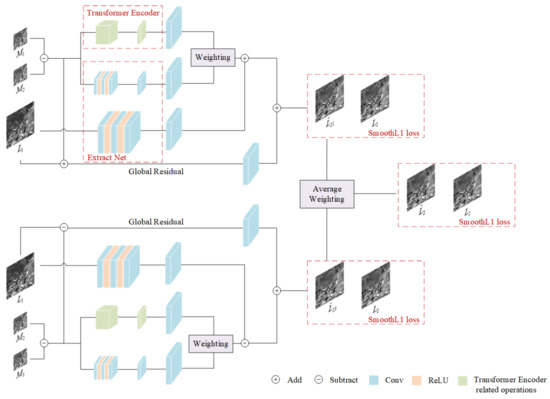
Figure 1.
MSNet architecture.
The whole of MSNet is an end-to-end structure, which can be divided into three parts:
- Transformer encoder-related operation modules, which are used to extract time-varying features and learn global temporal correlation information.
- Extract Net, which is used to establish a non-linear mapping relationship between input and output, can extract time information and spatial details of MODIS and Landsat at the same time.
- Average weighting, which uses an averaging strategy to fuse two intermediate prediction maps obtained from different a priori moments to obtain the final prediction map.
We use five images of two sizes as input, two MODIS-Landsat image pairs with a priori time , and a MODIS image with prediction time . From the structural point of view, MSNet is symmetric from top to bottom. Let us take the structure of the above half as an example to illustrate:
- First, we subtract from to obtain , which represents the changed area in the time period from to and provides time change information, while provides spatial detail information. After that, we input into the Transformer encoder module and the Extract Net module, respectively, to extract time change information, learn global temporal correlation information, and extract time and space features in MODIS images.
- Secondly, because the size of the MODIS image we input is smaller than the size of the Landsat image, to facilitate the subsequent fusion, we use the bilinear interpolation method for up-sampling, and the extracted feature layer is enlarged sixteen-fold to obtain a feature layer with the same size after Landsat processing. Because some of the information we extract and learn using the two modules overlaps, we use the weighting strategy W to assign a weight to the information extracted by the two modules during fusion. The information extracted by the Transformer encoder gives the weight , and Extract Net is ; we then obtain a fusion of feature layers.
- At the same time, we input into Extract Net to extract spatial detail information, and the obtained feature layer is added with the result obtained in the second step to obtain a feature layer fusion.
- As the number of network layers deepens, the time change information and spatial details in the input image are lost. Inspired by the residual connection of ResNet [26], DensNet [27], and STTFN [23], we added global residual learning to supplement the information that may be lost. We upsample the obtained in the first step with bilinear interpolation and add it to to obtain a residual learning block. Finally, we add the residual learning block and the result obtained in the third step to obtain a prediction result for the fused image based on time to time .
In the same way, the structure of the lower part uses a similar method to obtain the prediction image , but it is worth noting that we are predicting the fusion image at time . Therefore, in the prediction process of , the global residual block is obtained, and the third step of the fusion process is obtained by subtraction.
The structure of the upper and lower parts of MSNet can be expressed using the following formula:
where represents the related module of the Transformer encoder, represents Extract Net, represents the bilinear interpolation upsampling method, and .
Finally, we obtain two prediction maps and , and then reconstruct them using the fusion method of average weighting to obtain the final prediction result for time . The prediction result can be expressed with the following formula:
where represents the average weighting fusion method.
3.2. Transformer Encoder
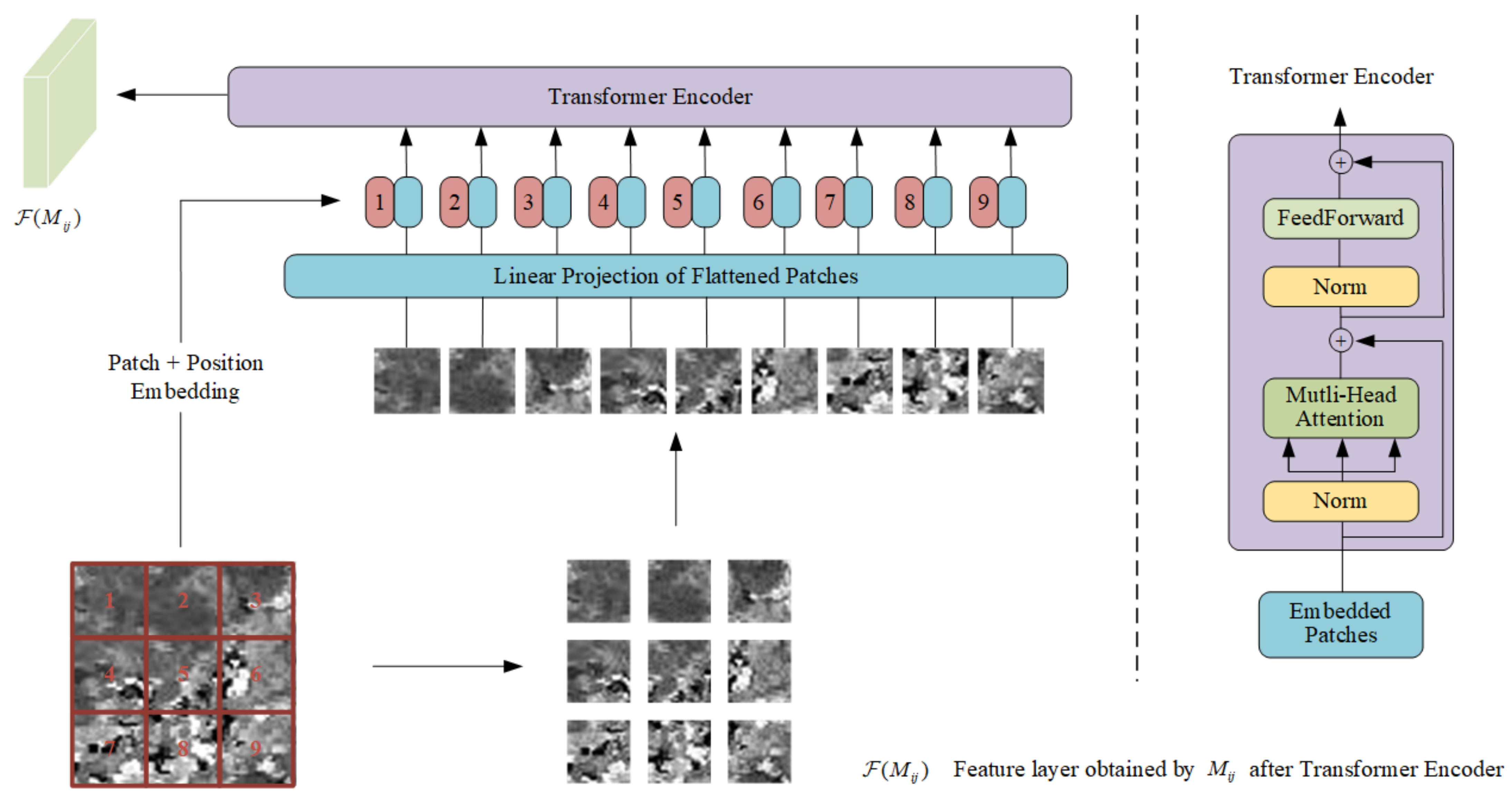
As one applications of the attention mechanism, Transformer [24] is generally used to calculate the correlation degree of the input sequence. It achieves good results not only in natural language processing, but also in applications in the field of vision. For example, Vision Transformer (ViT) [25] partially changed the original Transformer and applied it to image classification. Experiments show that it also has good results. Inspired by the application of Transformer to the attention mechanism and its development in the field of vision, we attempt to apply Transformer to the reconstruction process in spatiotemporal fusion. We selected the Encoder part of Transformer as a module for learning the degree of correlation between blocks in the time change information, that is, the global time correlation information, and it also extracts some of the time change feature information. We refer to the original Transformer and the structural implementation in ViT, and make corresponding changes to obtain the Transformer encoder that can be applied to space–time fusion as shown in Figure 2 below:
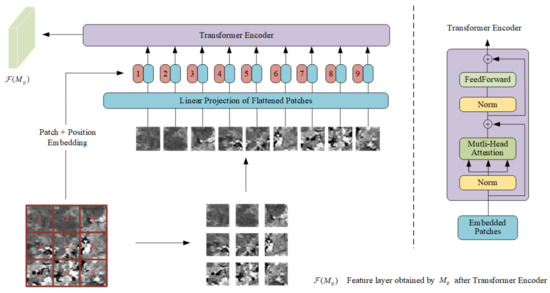
Figure 2.
Transformer encoder applied to spatiotemporal fusion.
The left part of the dotted line in Figure 2 is the specific process we use for learning. By dividing the input time change information, , into multiple small patches, and then using a trainable linear projection of flattened patches and mapping it to a new single dimension, this dimension can be used as a constant latent vector in all layers of the Transformer encoder. While the patches are flattened and embedded in the new dimension, the location information from the patches is also embedded in the new dimension as the input of our Transformer encoder. These structures are consistent with ViT. The difference is that we removed the learnable classification embedding in ViT because we don’t need to classify the input. In addition, we also removed the MLP part used to achieve classification in ViT. Through these operations, we ensure that our input and output are of the same dimension, which facilitates our subsequent fusion reconstruction.
The right part of the dotted line in Figure 2 is the specific structure of the Transformer encoder obtained by referring to the original Transformer and ViT. It is composed of a multi-head self-attention mechanism and an alternate feedforward part. The input will be normalized before each input to the submodule, and there will be residual connections after each block. The multi-head self-attention mechanism is a series of Softmax and linear operations. Our input will gradually change its dimensions during the propagation of the training process to adapt to these operations. The feedforward part is composed of linear, Gaussian error linear unit (GELU) and random deactivation dropout, where GELU is used as the activation function. In practical applications, we adjust the number of heads of the multi-head attention mechanism to adapt to different application scenarios. At the same time, for different amounts of data, when global time change information is learned, Transformer encoders of different depths are required to learn more accurately.
Through the above-mentioned position embedding, patch embedding, and self-attention mechanism in the module, we obtain the correlation between the blocks in the time change information and its characteristics during the learning process.
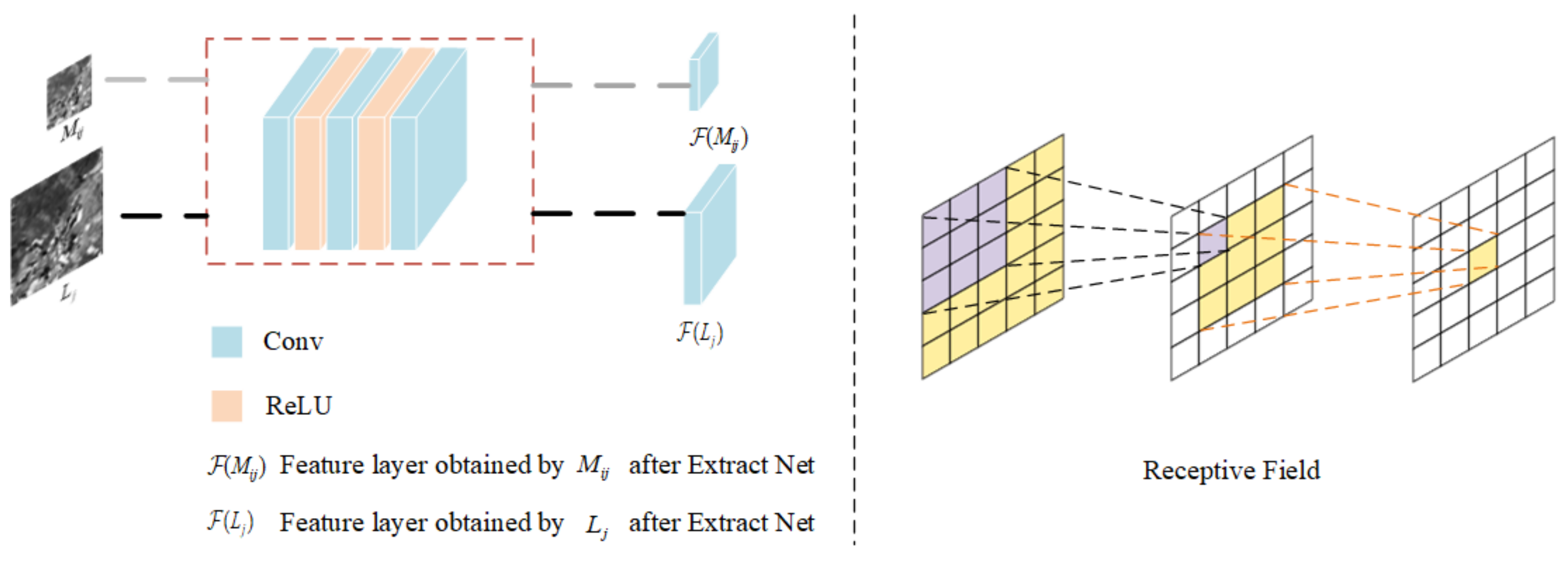
3.3. Extract Net
To extract the temporal and spatial features contained in and the high-frequency spatial detail features in , and to establish the mapping relationship between input and prediction results, we propose a five-layer convolutional neural network as our Extract Net, and our input size is different. When extracting different inputs, our convolution kernel size is also different. The size of the Extract Net convolution kernel corresponding to a small input is 3 × 3, and the size for large input is 5 × 5. Different convolution kernel sizes are used to obtain different receptive fields when inputs of different sizes are extracted, thereby enhancing the learning effect [28]. The dimensions of the output feature maps obtained after inputs of different sizes are entered into Extract Net are different, but the feature maps are sampled to the same dimension by upsampling in the follow-up for fusion reconstruction. The structure of Extract Net and receptive field are as shown in Figure 3:
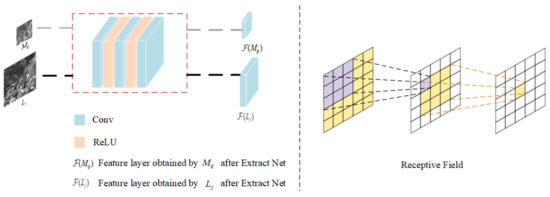
Figure 3.
Extract Net.
Specifically, we have a three-layer convolution operation, and there is a rectified linear unit (ReLU) behind the input and hidden layers for activation. For each convolution operation, it can be defined as:
where represents the input, “” represents the convolution operation, represents the weight of the current convolution layer, and represents the current offset. The output channels of the three convolution operations are different, and they are 32, 16, and 1.
After convolution, the ReLU operation makes the feature non-linear and prevents network overfitting [29]. The ReLU operation can be defined as:
We then merge the corresponding feature maps obtained after Extract Net.
3.4. Average Weighting
After the fusion of the Transformer encoder, Extract Net, and the global residuals, two prediction results and for time are obtained. The two prediction results we obtained show some overlap in the process of predicting spatial details and time changes, and our input data is consistent over the time span of the two prior times and the prediction time. Therefore, we use the average weight to obtain the final prediction result, avoiding the use of complex reconstruction methods that introduce noise. Average weighting can be defined as:
where .
3.5. Loss Function
Our method obtains two intermediate prediction results and during the prediction process, as well as the result . During the training process, we perform loss calculations on these three results to continuously adjust during the backpropagation process. The parameters are learned to obtain better convergence results. When each prediction result and its true value are calculated, we choose the smooth L1 loss function, Huber Loss [30], which can be defined as follows:
where represents our prediction results , , , are the real values, and is our sample size. When the difference between the predicted value and the real value is small, that is, when the difference is between (−1, 1), the square of the result of the subtraction can be used to make the gradient not too large. When the result is large, the calculation method of the absolute value can be used to make the gradient small enough and more stable. Our overall loss function is defined as:
where . The result of the intermediate prediction is as important as the final prediction. In the experimental comparison, we set the weight to 1 to enable our model to obtain a better convergence result.
4. Experiment
4.1. Datasets
We used three datasets to test the robustness of MSNet.
The first study area was the Coleambally Irrigation District (CIA) located in the southern part of New South Wales, Australia (NSW, 34.0034°E, 145.0675°S) [31]. This dataset was obtained from October 2001 to May 2002 and contains a total of 17 pairs of MODIS–Landsat images. The Landsat images are all from Landsat-7 ETM+, and the MODIS images are MODIS Terra MOD09GA Collection 5 data. The CIA dataset includes a total of six bands, and the image size is 1720 × 2040.
The second study area is the Lower Gwydir Basin (LGC) located in northern New South Wales, Australia (NSW, 149.2815°E, 29.0855°S) [31]. The dataset was obtained from April 2004 to April 2005 and consists of a total of 14 pairs of MODIS–Landsat images. All the Landsat images are from Landsat-5 TM, and the MODIS images are MODIS Terra MOD09GA Collection 5 data. The LGC dataset contains six bands, and the image size is 3200 × 2720.
The third research area was the Aluhorqin Banner (43.3619°N, 119.0375°E) in the central part of the Inner Mongolia Autonomous Region in northeastern China. This area has many circular pastures and farmland (AHB) [32,33]. Li et al., collected 27 cloudless MODIS–Landsat image pairs from May 2013 to December 2018, a span of more than 5 years. Due to the growth of crops and other types of vegetation, the area showed significant phenological changes. The AHB dataset contains six bands, and the image size is 2480 × 2800.
We combined all the images of the three datasets according to two prior moments (letter subscripts are 1 and 3) and an intermediate prediction moment (letter subscript is 2). Each set of training data has six images, including three pairs of MODIS–Landsat images. At the same time, when data were combined, we chose data with the same time span between the prior moment and the predicted moment as our experimental data. In addition, in order to train our network, we first cropped the three datasets to a size of 1200 × 1200. To effectively reduce the increase in the number of parameters due to the deepening of the Transformer encoder, we scaled all the MODIS data to a size of 75 × 75. Figure 4, Figure 5 and Figure 6, respectively, show the MODIS–Landsat image pairs obtained from the three datasets on three different dates. The MODIS data size used for display is 1200 × 1200. Throughout the experiment, we separately input the three datasets into MSNet for training. We use 70% of the dataset for training, 15% for verification, and 15% as a test for our final evaluation of the model’s fusion reconstruction ability.

Figure 4.
Composite MODIS (top row) and Landsat (bottom row) image pairs on 7 October (a,d), 16 October (b,e), and 1 November (c,f) 2001 from the CIA [31] dataset. The CIA dataset mainly contains significant phenological changes of irrigated farmland.

Figure 5.
Composite MODIS (top row) and Landsat (bottom row) image pairs on 29 January (a,d), 14 February (b,e), and 2 March (c,f) 2005 from the LGC [31] dataset. The LGC dataset mainly contains changes in land cover types after the flood.

Figure 6.
Composite MODIS (top row) and Landsat (bottom row) image pairs on 21 June (a,d), 7 July (b,e), and 25 September (c,f) 2015 from the AHB [32,33] dataset. The AHB dataset mainly contains significant phenological changes of the pasture.
4.2. Evaluation
To evaluate the results of our proposed spatiotemporal fusion method, we compared it with FSDAF, STARFM, STFDCNN and StfNet under the same conditions.
The first indicator we used was the Spectral Angle Mapper (SAM) [34], which measures the spectral distortion of the fusion result. It can be defined as follows:
where represents the total number of pixels in the predicted image, represents the total number of bands, represents the prediction result, represents the prediction result of the band, and represents the true value of the band. A small SAM indicates a better result.
The second metric was the root mean square error (RMSE), which is the square root of the MSE, and is used to measure the deviation between the predicted image and the observed image. It reflects a global depiction of the radiometric differences between the fusion result and the real observation image, which is defined as follows:
where represents the height of the image, represents the width of the image, represents the observed image, and represents the predicted image. The smaller the value of RMSE, the closer the predicted image is to the observed image.
The third indicator was erreur relative global adimensionnelle de synthese (ERGAS) [35], which measures the overall integration result. It can be defined as:
where and represent the spatial resolution of Landsat and MODIS images respectively; represents the real image of the band; and represents the average value of the band image. When ERGAS is small, the fusion effect is better.
The fourth index was the structural similarity (SSIM) index [18,36], which is used to measure the similarity of two images. It can be defined as:
where represents the mean value of the predicted image, represents the mean value of the real observation image, represents the covariance of the predicted image and the real observation image , represents the variance of the predicted image , represents the variance of the real observation image , and and are constants used to maintain stability. The value range of SSIM is [−1, 1]. The closer the value is to 1, the more similar are the predicted image and the observed image.
The fifth index is the correlation coefficient (CC), which is used to indicate the correlation between two images. It can be defined as:
The closer the CC is to 1, the greater the correlation between the predicted image and the real observation image.
The sixth indicator is the peak signal-to-noise ratio (PSNR) [37]. It is defined indirectly by the MSE, which can be defined as:
Then PSNR can be defined as:
where is the maximum possible pixel value of the real observation image . If each pixel is represented by an 8-bit binary value, then is 255. Generally, if the pixel value is represented by B-bit binary, then . PSNR can evaluate the quality of the image after reconstruction. A higher PSNR means that the predicted image quality is better.
4.3. Parameter Setting
For the Transformer encoder, we set the number of headers to nine and set the depth according to the data volume of the three datasets. CIA is 5, LGC is 5, and AHB is 20. The size of the patch is 15 × 15. Different Extract Net sets the size of its convolution kernel to 3 × 3 and 5 × 5. Our initial learning rate is set to 0.0008, the optimizer uses Adam, and the weight attenuation is set to 1e-6. We trained MSNet in a Windows 10 professional environment, equipped with 64 GB RAM, an Intel CoreTM i9–9900K processor running at 3.60 GHz × 16 CPUs, and an NVIDIA GeForce RTX 2080 Ti GPU.
4.4. Results and Analysis
4.4.1. Subjective Evaluation
To visually show our experimental results, Figure 7, Figure 8, Figure 9 and Figure 10 respectively show the experimental results of FSDAF [13], STARFM [8], STFDCNN [18], StfNet [19] and our proposed MSNet on the three datasets.

Figure 7.
Prediction results for the target Landsat image (16 October 2001) in the CIA [31] dataset. Additionally, comparison methods include FSDAF [13], STARFM [8], STFDCNN [18] and StfNet [19], which are represented by (b–e) in the figure respectively. In addition, (a) represents the ground truth (GT) we got, and (f) represents the method we proposed.

Figure 8.
Prediction results for the target Landsat image (14 February 2005) in the LGC [31] dataset. Additionally, comparison methods include FSDAF [13], STARFM [8], STFDCNN [18], and StfNet [19], which are represented by (b–e) in the figure respectively. In addition, (a) represents the ground truth (GT) we got, and (f) represents the method we proposed.

Figure 9.
Full prediction results for the target Landsat image (7 July 2015) in the AHB [32,33] dataset. Additionally, comparison methods include FSDAF [13], STARFM [8], STFDCNN [18], and StfNet [19], which are represented by (b–e) in the figure respectively. In addition, (a) represents the ground truth (GT) we got, and (f) represents the method we proposed.

Figure 10.
Specific prediction results for the target Landsat image (7 July 2015) in the AHB [32,33] dataset. Additionally, comparison methods include FSDAF [13], STARFM [8], STFDCNN [18], and StfNet [19], which are represented by (b–e) in the figure respectively. In addition, (a) represents the ground truth (GT) we got, and (f) represents the method we proposed.
Figure 7 shows the experimental results we obtained on the CIA dataset. We extracted some of the prediction results for display. “GT” represents the real observation image, and “Proposed” is our MSNet method. In terms of visual effects, FSDAF and STARFM are not accurate enough in predicting phenological changes. For example, there are many land parcels with black areas that cannot be accurately predicted. Relatively speaking, the prediction results obtained by the deep learning method are better, but the prediction map of StfNet is somewhat fuzzy and the result is not good. In addition, we zoom in on some areas for a more detailed display. We can see from the figure that STFDCNN, StfNet and our proposed method achieve better results for the edge processing part of the land. Moreover, the spectral information from the prediction results obtained by MSNet is closer to the true value, as reflected in the depth of the colour, which proves that our prediction results are better.
Figure 8 shows the experimental results we obtained on the LGC dataset. We extracted some of the prediction results for display. Overall, the performance of each algorithm is relatively stable, but there are differences in specific boundary processing and spectral information processing. We zoom in on some areas in the figure to show the details. We can see that the three methods, FSDAF, STARFM, and StfNet, show poor performance in processing high-frequency information in the border area. The boundaries obtained by the prediction results for FSADF and STARFM are not neat enough, and the processing results of StfNet blur the boundary information. In addition, although STFDCNN achieves good results on the boundary information, its spectral information, such as the green part, has not been processed well. In contrast, our proposed method not only achieves the accurate prediction of boundary information, but also shows better processing of spectral information, which is closer to the true value.
Figure 9 and Figure 10 are the full prediction results and the truncated partial results we obtained on the AHB dataset.
From the results in Figure 9, we can see that the prediction results for STARFM are not accurate enough for the processing of spectral information, and there is a large amount of fuzzy spectral information. In addition, although FSDAF’s prediction results are much better than STARFM for the processing of spectral information, they still have shortcomings compared with the true value, such as the insufficient degree of predicted phenological changes, which is reflected in the difference in colour. StfNet shows good results for most predictions, such as the spatial details between rivers. However, it can also be seen that there are still shortcomings in the prediction of time information, and the phenological change information in some areas is not accurately predicted. The performance of STFDCNN and our proposed method is better in terms of time information. However, in the continuous phenological change area, STFDCNN’s prediction results are not good. For example, in rectangular area in the figure, its prediction result is not good. In contrast, our proposed method achieves better results.
Figure 10 shows the details after we zoomed in on the prediction results. For small, raised shoals in the river, neither FSDAF nor STARFM can accurately predict the edge in-formation and the time information it should contain, and the prediction result is not good. Although STFDCNN and StfNet have relatively perfect spatial information pro-cessing and clear boundaries, the spectral information is still quite different from the true value. Compared with our method, our results are more accurate in the processing of spa-tial information and spectral information and are closer to the true value.
4.4.2. Objective Evaluation
To objectively evaluate our proposed algorithm, we used six evaluation indicators to evaluate various algorithms and our MSNet. Table 2, Table 3 and Table 4 show our quantitative evaluation of the prediction results obtained by various methods on three datasets, including the global indicators SAM and ERGAS, and the local indicators RMSE, SSIM, PSNR, and CC. In addition, we also boldly mark the optimal value of each indicator.
Table 2.
Quantitative assessment of different spatiotemporal fusion methods for the CIA [31] dataset.
Table 3.
Quantitative assessment of different spatiotemporal fusion methods for the LGC [31] dataset.
Table 4.
Quantitative assessment of different spatiotemporal fusion methods for the AHB [32,33] dataset.
Table 2 shows the quantitative evaluation results of the multiple fusion methods and our MSNet on the CIA dataset. We achieved optimal values on the global indicators and most of the local indicators.
Table 3 shows the evaluation results of various methods on the LGC dataset. Although our method does not achieve the optimal value for the SSIM evaluation, its value is similar and it achieves the optimal value for the global index and most of the other local indexes.
Table 4 lists the evaluation results of various methods on the AHB dataset. It can be seen that, except for some fluctuations in the evaluation results for individual bands, our method achieves the best values in the rest of the evaluation results.
5. Discussion
From the experiments on three datasets, we can see that our method obtained better forecasting results, both on the CIA dataset with phenological changes in regular areas, and on the AHB dataset with many phenological changes in irregular areas. Similarly, for the LGC dataset, which contains mainly land cover type change, our method achieved better prediction results for the processing of time information than the traditional method and the other two methods based on deep learning. The processing of time information benefits from the use of the Transformer encoder and convolutional neural network in MSNet. More importantly, the Transformer encoder we introduced learns the connection between the local and the global information and better grasps the global temporal information. It is worth noting that for datasets with different data volumes, the depth of the Transformer encoder should also be different to better adapt to the datasets. Table 5 lists the average evaluation values for the prediction results obtained without the introduction of the Transformer encoder and for Transformer encoders having different depths. When no Transformer encoder is introduced, the experimental results are relatively poor. With the changes in the depth of the Transformer encoder, we also obtained different results. When the depth is 5 on the CIA dataset, 5 on the LGC dataset, and 20 on the AHB dataset, we have also achieved better results, and they were better than when only the convolutional neural networks were used.
Table 5.
Average evaluation values of Transformer encoders of different depths on the three datasets.
In addition, Extract Nets with different receptive field sizes have different sizes of learning areas, which effectively adapt to different sizes of input and obtain better results for learning time change information and spatial detail information. Table 6 lists the average evaluation values of the prediction results of Extract Net with different receptive fields. If an Extract Net with a single receptive field size is used for different sizes of input, the result is poor.
Table 6.
Average evaluation values of Extract Nets with different sizes of receptive fields on the three datasets.
When the result is obtained through the fusion of two intermediate prediction results, the average weight method obtains a better result in processing some of the noise. We compared the results obtained by the fusion method in STFDCNN [18], and we call this fusion method TC weighting. Table 7 lists the average measured values of the prediction results obtained using different fusion methods. The fusion method that uses the averaging strategy is the correct choice.
Table 7.
Average evaluation values of MSNet using different fusion methods on the three datasets.
Although the method we proposed has achieved good results overall, there are some shortcomings in some areas. Figure 11 shows the deficiencies in the prediction of phenological change information obtained by each method in the LGC dataset. Compared with the true value, the shortcomings of each prediction result are reflected in the shade of the colour. In this regard, we analysed that this is because our method may not be easy to extract all the information contained in the small change area when focusing on the global temporal correlation. In addition, there are some points worthy of further discussion in our method. First, to reduce the number of parameters, we used the professional remote sensing image processing software ENVI to change the size of the MODIS data, but whether there was a loss of temporal information during this process requires further research to determine. Secondly, the introduction of the Transformer encoder increases the number of parameters. In addition to changing the size of the input, other methods that can reduce the number of parameters and maintain the fusion effect need to be studied in the future. Furthermore, the fusion method for improving the fusion result and avoiding the introduction of noise also needs to be studied further.

Figure 11.
Insufficient prediction results for the target Landsat image (14 February 2005) in the LGC [31] dataset. Additionally, comparison methods include FSDAF [13], STARFM [8], STFDCNN [18], and StfNet [19], which are represented by (b–e) in the figure respectively. In addition, (a) represents the ground truth (GT) we got, and (f) represents the method we proposed.
6. Conclusions
We use data from three research areas to evaluate the effectiveness of our proposed MSNet method and prove that our model is robust. The superior performance of MSNet compared with that of other methods is mainly because:
- The Transformer encoder module is used to learn global time change information. While extracting local features, it uses the self-attention mechanism and the embedding of position information to learn the relationship between local and global information, which is different from the effect of only using the convolution operation. In the end, our method achieves the desired result.
- We set up Extract Net with different convolution kernel sizes to extract the features contained in inputs of different sizes. The larger the convolution kernel, the larger the receptive field. When a larger-sized Landsat image is extracted, a large receptive field can obtain more learning content and achieve better learning results. At the same time, a small receptive field can better match the size of our time-varying information.
- For the repeated extraction of information, we added a weighting strategy when we fused the feature layer obtained and reconstructed the result from the intermediate prediction results to eliminate the noise introduced by the repeated information in the fusion process.
- When we established the complex nonlinear mapping relationship between the input and the final fusion result, we added a global residual connection for learning, thereby supplementing some of the details lost in the training process.
Our experiments showed that in the CIA and AHB datasets, which contain significant phenological changes, and in the LGC dataset with changes in land cover types, our proposed model MSNet was better than other models that use two or three pairs of original images to fuse. The prediction results on each dataset were relatively stable.
Author Contributions
Data curation, W.L.; formal analysis, W.L.; methodology, W.L. and D.C.; validation, D.C.; visualization, D.C. and Y.P.; writing—original draft, D.C.; writing—review and editing, D.C., Y.P. and C.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China [Nos. 61972060, U1713213 and 62027827], National Key Research and Development Program of China (Nos. 2019YFE0110800), Natural Science Foundation of Chongqing [cstc2020jcyj-zdxmX0025, cstc2019cxcyljrc-td0270].
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data sharing is not applicable to this article.
Acknowledgments
The authors would like to thank all of the reviewers for their valuable contributions to our work.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Justice, C.O.; Vermote, E.; Townshend, J.R.; Defries, R.; Roy, D.P.; Hall, D.K.; Salomonson, V.V.; Privette, J.L.; Riggs, G.; Strahler, A.; et al. The Moderate Resolution Imaging Spectroradiometer (MODIS): Land remote sensing for global change research. IEEE Trans. Geosci. Remote Sens. 1998, 36, 1228–1249. [Google Scholar] [CrossRef] [Green Version]
- Lin, C.; Li, Y.; Yuan, Z.; Lau, A.K.; Li, C.; Fung, J.C. Using satellite remote sensing data to estimate the high-resolution distribution of ground-level PM2.5. Remote Sens. Environ. 2015, 156, 117–128. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, Q.; Du, B.; Huang, X.; Tang, Y.Y.; Tao, D. Simultaneous spectral-spatial feature selection and extraction for hyperspectral images. IEEE Trans. Cybern. 2016, 48, 16–28. [Google Scholar] [CrossRef] [Green Version]
- Yu, Q.; Gong, P.; Clinton, N.; Biging, G.; Kelly, M.; Schirokauer, D. Object-based detailed vegetation classification with airborne high spatial resolution remote sensing imagery. Photogramm. Eng. Remote Sens. 2006, 72, 799–811. [Google Scholar] [CrossRef] [Green Version]
- White, M.A.; Nemani, R.R. Real-time monitoring and short-term forecasting of land surface phenology. Remote Sens. Environ. 2006, 104, 43–49. [Google Scholar] [CrossRef]
- Hansen, M.C.; Loveland, T.R. A review of large area monitoring of land cover change using Landsat data. Remote Sens. Environ. 2012, 122, 66–74. [Google Scholar] [CrossRef]
- Gao, F.; Masek, J.; Schwaller, M.; Hall, F. On the blending of the Landsat and MODIS surface reflectance: Predicting daily Landsat surface reflectance. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2207–2218. [Google Scholar] [CrossRef]
- Hilker, T.; Wulder, M.A.; Coops, N.C.; Seitz, N.; White, J.C.; Gao, F.; Masek, J.G.; Stenhouse, G. Generation of dense time series synthetic Landsat data through data blending with MODIS using a spatial and temporal adaptive reflectance fusion model. Remote Sens. Environ. 2009, 113, 1988–1999. [Google Scholar] [CrossRef]
- Zhu, X.; Chen, J.; Gao, F.; Chen, X.; Masek, J.G. An enhanced spatial and temporal adaptive reflectance fusion model for complex heterogeneous regions. Remote Sens. Environ. 2010, 114, 2610–2623. [Google Scholar] [CrossRef]
- Hilker, T.; Wulder, M.A.; Coops, N.C.; Linke, J.; McDermid, G.; Masek, J.G.; Gao, F.; White, J.C. A new data fusion model for high spatial-and temporal-resolution mapping of forest disturbance based on Landsat and MODIS. Remote Sens. Environ. 2009, 113, 1613–1627. [Google Scholar] [CrossRef]
- Zhukov, B.; Oertel, D.; Lanzl, F.; Reinhackel, G. Unmixing-based multisensor multiresolution image fusion. IEEE Trans. Geosci. Remote Sens. 1999, 37, 1212–1226. [Google Scholar] [CrossRef]
- Wu, M.; Niu, Z.; Wang, C.; Wu, C.; Wang, L. Use of MODIS and Landsat time series data to generate high-resolution temporal synthetic Landsat data using a spatial and temporal reflectance fusion model. J. Appl. Remote Sens. 2012, 6, 063507. [Google Scholar] [CrossRef]
- Zhu, X.; Helmer, E.H.; Gao, F.; Liu, D.; Chen, J.; Lefsky, M.A. A flexible spatiotemporal method for fusing satellite images with different resolutions. Remote Sens. Environ. 2016, 172, 165–177. [Google Scholar] [CrossRef]
- Huang, B.; Song, H. Spatiotemporal reflectance fusion via sparse representation. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3707–3716. [Google Scholar] [CrossRef]
- Belgiu, M.; Stein, A. Spatiotemporal image fusion in remote sensing. Remote Sens. 2019, 11, 818. [Google Scholar] [CrossRef] [Green Version]
- Wei, J.; Wang, L.; Liu, P.; Chen, X.; Li, W.; Zomaya, A.Y. Spatiotemporal fusion of MODIS and Landsat-7 reflectance images via compressed sensing. IEEE Trans. Geosci. Remote Sens. 2017, 55, 7126–7139. [Google Scholar] [CrossRef]
- Liu, X.; Deng, C.; Wang, S.; Huang, G.-B.; Zhao, B.; Lauren, P. Fast and accurate spatiotemporal fusion based upon extreme learning machine. IEEE Geosci. Remote Sens. Lett. 2016, 13, 2039–2043. [Google Scholar] [CrossRef]
- Song, H.; Liu, Q.; Wang, G.; Hang, R.; Huang, B. Spatiotemporal satellite image fusion using deep convolutional neural networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 821–829. [Google Scholar] [CrossRef]
- Liu, X.; Deng, C.; Chanussot, J.; Hong, D.; Zhao, B. StfNet: A two-stream convolutional neural network for spatiotemporal image fusion. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6552–6564. [Google Scholar] [CrossRef]
- Tan, Z.; Yue, P.; Di, L.; Tang, J. Deriving high spatiotemporal remote sensing images using deep convolutional network. Remote Sens. 2018, 10, 1066. [Google Scholar] [CrossRef] [Green Version]
- Tan, Z.; Di, L.; Zhang, M.; Guo, L.; Gao, M. An enhanced deep convolutional model for spatiotemporal image fusion. Remote Sens. 2019, 11, 2898. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.; Wang, L.; Feng, R.; Liu, P.; Han, W.; Chen, X. CycleGAN-STF: Spatiotemporal fusion via CycleGAN-based image generation. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5851–5865. [Google Scholar] [CrossRef]
- Yin, Z.; Wu, P.; Foody, G.M.; Wu, Y.; Liu, Z.; Du, Y.; Ling, F. Spatiotemporal fusion of land surface temperature based on a convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2020, 59, 1808–1822. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16 × 16 words: Transformers for image recognition at scale. In Proceedings of the ICLR 2021, Virtual Conference, Formerly, Vienna, Austria, 3–7 May 2021. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Huber, P.J. Robust estimation of a location parameter. In Breakthroughs in Statistics; Springer: Berlin/Heidelberg, Germany, 1992; pp. 492–518. [Google Scholar]
- Emelyanova, I.V.; McVicar, T.R.; Van Niel, T.G.; Li, L.T.; Van Dijk, A.I. Assessing the accuracy of blending Landsat–MODIS surface reflectances in two landscapes with contrasting spatial and temporal dynamics: A framework for algorithm selection. Remote Sens. Environ. 2013, 133, 193–209. [Google Scholar] [CrossRef]
- Li, Y.; Li, J.; He, L.; Chen, J.; Plaza, A. A new sensor bias-driven spatio-temporal fusion model based on convolutional neural networks. Sci. China Inf. Sci. 2020, 63, 140302. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Li, Y.; He, L.; Chen, J.; Plaza, A. Spatio-temporal fusion for remote sensing data: An overview and new benchmark. Sci. China Inf. Sci. 2020, 63, 140301. [Google Scholar] [CrossRef] [Green Version]
- Yuhas, R.H.; Goetz, A.F.; Boardman, J.W. Discrimination among semi-arid landscape endmembers using the spectral angle mapper (SAM) algorithm. In Proceedings of the Summaries 3rd Annual JPL Airborne Earth Science Workshop, Pasadena, CA, USA, 1–5 June 1992; pp. 147–149. [Google Scholar]
- Khan, M.M.; Alparone, L.; Chanussot, J. Pansharpening quality assessment using the modulation transfer functions of instruments. IEEE Trans. Geosci. Remote Sens. 2009, 47, 3880–3891. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ponomarenko, N.; Ieremeiev, O.; Lukin, V.; Egiazarian, K.; Carli, M. Modified image visual quality metrics for contrast change and mean shift accounting. In Proceedings of the 2011 11th International Conference the Experience of Designing and Application of CAD Systems in Microelectronics (CADSM), Polyana-Svalyava, Ukraine, 23–25 February 2011; pp. 305–311. [Google Scholar]








Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).