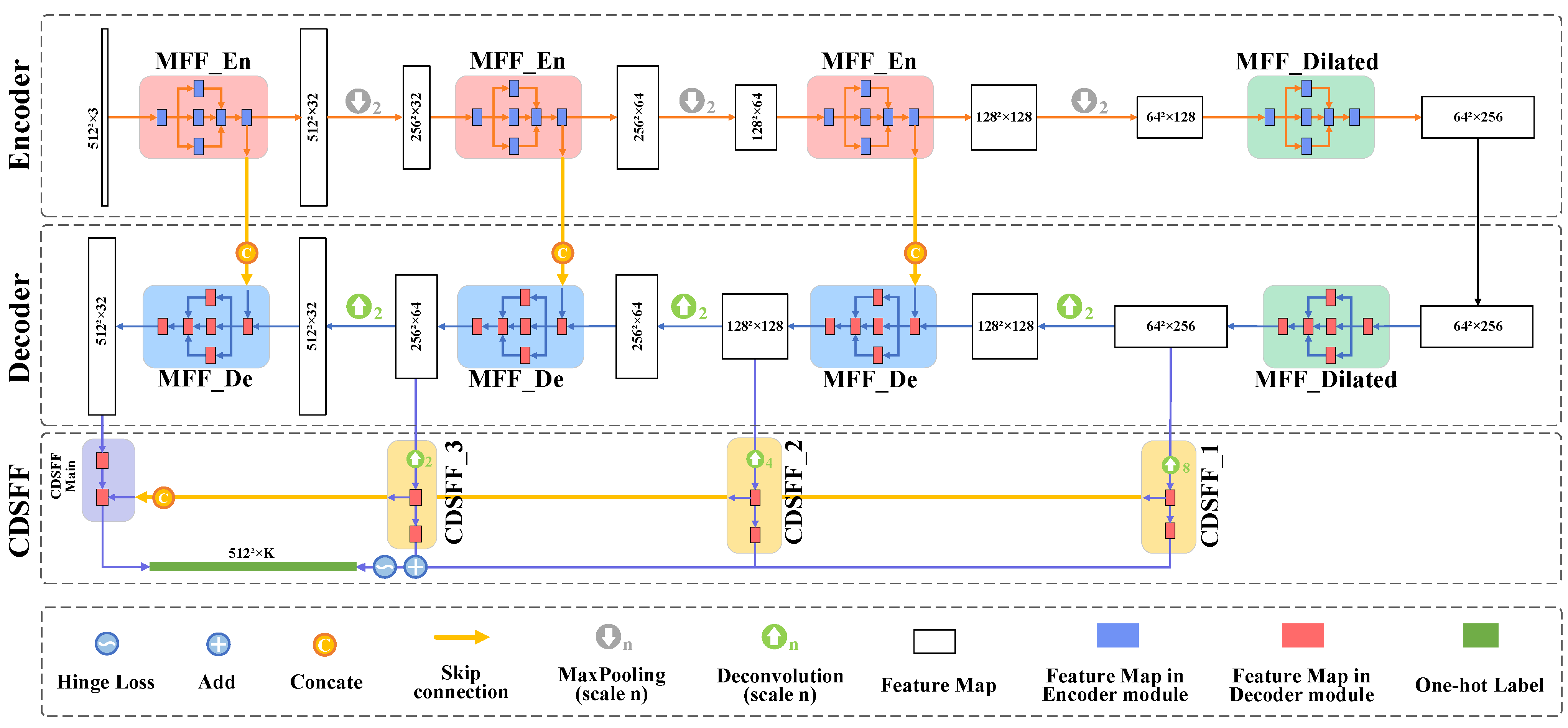
Figure 1.
The architecture of CSD-Net. The number on the blocks indicates the size of the feature maps, with K denoting the number of anticipated categories.
Figure 1.
The architecture of CSD-Net. The number on the blocks indicates the size of the feature maps, with K denoting the number of anticipated categories.
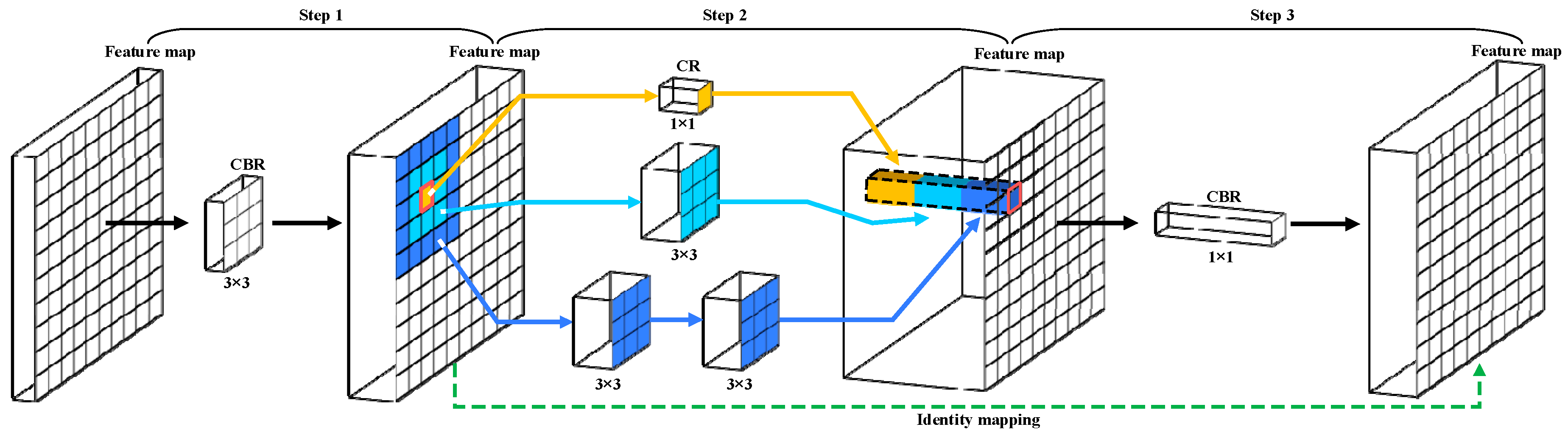
Figure 2.
The general structure of the MFF. The graphic does not show the specific structural changes caused by the skip connections and the dilated convolution. Meanwhile, different colors are utilized to emphasize the vital structures.
Figure 2.
The general structure of the MFF. The graphic does not show the specific structural changes caused by the skip connections and the dilated convolution. Meanwhile, different colors are utilized to emphasize the vital structures.
Figure 3.
The details of MFF_En and MFF_De. (a) The structure of MFF_En. (b) The structure of MFF_De. In the graph, N2 represents the size of the feature map, while C represents the number of the feature map channels.
Figure 3.
The details of MFF_En and MFF_De. (a) The structure of MFF_En. (b) The structure of MFF_De. In the graph, N2 represents the size of the feature map, while C represents the number of the feature map channels.
Figure 4.
The CDSFF structural diagrams in CSD-Net. The four feature maps with different levels are coupled by CDSFF_1, CDSFF_2, CDSFF_3, and the Main Output structure in the decoding part.
Figure 4.
The CDSFF structural diagrams in CSD-Net. The four feature maps with different levels are coupled by CDSFF_1, CDSFF_2, CDSFF_3, and the Main Output structure in the decoding part.
Figure 5.
Some annotation samples from CSWV. (a,b) The original images and corresponding masks of CSWV_M21. (c,d) The original images and corresponding masks from CSWV_S6. The red regions represent clouds, the snow is represented by the blue regions, and the gray regions are the other objects.
Figure 5.
Some annotation samples from CSWV. (a,b) The original images and corresponding masks of CSWV_M21. (c,d) The original images and corresponding masks from CSWV_S6. The red regions represent clouds, the snow is represented by the blue regions, and the gray regions are the other objects.
Figure 6.
The proportion of cloud, snow, and background pixels in different datasets. (a) The components of L8_SPARCS. (b) The components of CSWV_M21. (c) The components of CSWV_S6.
Figure 6.
The proportion of cloud, snow, and background pixels in different datasets. (a) The components of L8_SPARCS. (b) The components of CSWV_M21. (c) The components of CSWV_S6.
Figure 7.
The loss curves over the validation subset for ablation networks. (a) The ablation comparison of MFF. (b) The ablation comparison of DS. (c) The ablation comparison of FF. (d) The ablation comparison of CL. The initial loss value is shown by the light-colored line in the figures. To better show the comparison, the original (ori.) loss curves were processed by the smoothing (smo.) function and formed more smooth dark curves. The results of the experiments showed that the MFF and CDSFF were favorable for obtaining accurate detection outcomes and for guiding the network to a stable and rapid gradient descent. However, when these modules were replaced or removed, the capacity of the network to extract the features was harmed. In a word, CSD-Net with MFF and CDSFF gained the best performance.
Figure 7.
The loss curves over the validation subset for ablation networks. (a) The ablation comparison of MFF. (b) The ablation comparison of DS. (c) The ablation comparison of FF. (d) The ablation comparison of CL. The initial loss value is shown by the light-colored line in the figures. To better show the comparison, the original (ori.) loss curves were processed by the smoothing (smo.) function and formed more smooth dark curves. The results of the experiments showed that the MFF and CDSFF were favorable for obtaining accurate detection outcomes and for guiding the network to a stable and rapid gradient descent. However, when these modules were replaced or removed, the capacity of the network to extract the features was harmed. In a word, CSD-Net with MFF and CDSFF gained the best performance.
Figure 8.
Large scene visualization of cloud and snow detection results by different methods based on the L8_SPARCS dataset. The delineated areas with the green boxes were magnified to provide a more detailed visual comparison in the bottom columns.
Figure 8.
Large scene visualization of cloud and snow detection results by different methods based on the L8_SPARCS dataset. The delineated areas with the green boxes were magnified to provide a more detailed visual comparison in the bottom columns.
Figure 9.
On the L8_SPARCS dataset, the visual comparison of cloud and snow detection results for several deep learning methods. It lists the original images, the detection results of various methods, and the ground truths one by one. The delineated areas with the green boxes were magnified to provide a more detailed visual comparison.
Figure 9.
On the L8_SPARCS dataset, the visual comparison of cloud and snow detection results for several deep learning methods. It lists the original images, the detection results of various methods, and the ground truths one by one. The delineated areas with the green boxes were magnified to provide a more detailed visual comparison.
Figure 10.
Large scene visualization of cloud and snow detection results by different methods based on the CSWV_M21 dataset. The delineated areas with the green boxes were magnified to provide a more detailed visual comparison in the bottom columns.
Figure 10.
Large scene visualization of cloud and snow detection results by different methods based on the CSWV_M21 dataset. The delineated areas with the green boxes were magnified to provide a more detailed visual comparison in the bottom columns.
Figure 11.
On the CSWV_M21 dataset, the visual comparison of cloud and snow detection results for several deep learning methods. It lists the original images, the detection results of various methods, and the ground truths one by one. The delineated areas with the green boxes were magnified to provide a more detailed visual comparison.
Figure 11.
On the CSWV_M21 dataset, the visual comparison of cloud and snow detection results for several deep learning methods. It lists the original images, the detection results of various methods, and the ground truths one by one. The delineated areas with the green boxes were magnified to provide a more detailed visual comparison.
Figure 12.
Large scene visualization of cloud and snow detection results by different methods based on the CSWV_S6 dataset. The delineated areas with the green boxes were magnified to provide a more detailed visual comparison in the bottom columns.
Figure 12.
Large scene visualization of cloud and snow detection results by different methods based on the CSWV_S6 dataset. The delineated areas with the green boxes were magnified to provide a more detailed visual comparison in the bottom columns.
Figure 13.
On the CSWV_S6 dataset, the visual comparison of cloud and snow detection results for several deep learning methods. It lists the original images, the detection results of various methods, and the ground truths one by one. The delineated areas with the green boxes were magnified to provide a more detailed visual comparison.
Figure 13.
On the CSWV_S6 dataset, the visual comparison of cloud and snow detection results for several deep learning methods. It lists the original images, the detection results of various methods, and the ground truths one by one. The delineated areas with the green boxes were magnified to provide a more detailed visual comparison.
Figure 14.
The MIoU, IoUc, and IoUs of different methods. Meanwhile, the absolute difference between IoUc and IoUs was calculated and shown. (a–c) The comparison of results on L8_SPARCS, CSWV_M21, CSWV_S6, respectively.
Figure 14.
The MIoU, IoUc, and IoUs of different methods. Meanwhile, the absolute difference between IoUc and IoUs was calculated and shown. (a–c) The comparison of results on L8_SPARCS, CSWV_M21, CSWV_S6, respectively.
Figure 15.
The box graphs of accuracy metrics for various deep learning methods. (a–c) The numerical distribution of MIoU, Macro-F1, and Kappa. The cross in the box represents the median of all values, while the horizontal line denotes the mean value.
Figure 15.
The box graphs of accuracy metrics for various deep learning methods. (a–c) The numerical distribution of MIoU, Macro-F1, and Kappa. The cross in the box represents the median of all values, while the horizontal line denotes the mean value.
Figure 16.
The accuracy and complexity bubble charts of different methods. (a–c) The comparisons of the various methods based on the L8_SPARCS, CSWV_M21, and CSWV_S6, respectively. The various colors of circles symbolize different networks. The vertical axis is the value of MIoU, while the value of FLOPs is represented on the horizontal axis. The center of the circle corresponds to its MIoU and FLOPs, and the area of the circle reflects its parameter quantity.
Figure 16.
The accuracy and complexity bubble charts of different methods. (a–c) The comparisons of the various methods based on the L8_SPARCS, CSWV_M21, and CSWV_S6, respectively. The various colors of circles symbolize different networks. The vertical axis is the value of MIoU, while the value of FLOPs is represented on the horizontal axis. The center of the circle corresponds to its MIoU and FLOPs, and the area of the circle reflects its parameter quantity.
Figure 17.
The loss curves of CSD-Net with different learning rates. (a) The complete loss curve of CSD-Net during training. (b) Partial enlargement of the loss curves in the later stages of training.
Figure 17.
The loss curves of CSD-Net with different learning rates. (a) The complete loss curve of CSD-Net during training. (b) Partial enlargement of the loss curves in the later stages of training.
Figure 18.
The comparison of the three datasets based on experimental results. (a) The combination chart indicates the lowest loss over the validation subset and the highest MIoU achieved by the methods on various datasets. (b) The radar chart reflects the standard deviation of the same assessment metric for different methods.
Figure 18.
The comparison of the three datasets based on experimental results. (a) The combination chart indicates the lowest loss over the validation subset and the highest MIoU achieved by the methods on various datasets. (b) The radar chart reflects the standard deviation of the same assessment metric for different methods.
Figure 19.
The accuracy curves of transfer training and direct training. In the charts, the disparities in accuracy between both training strategies were also plotted. (a) The MIoU values of both training strategies. (b) The Macro-F1 values of both training strategies.
Figure 19.
The accuracy curves of transfer training and direct training. In the charts, the disparities in accuracy between both training strategies were also plotted. (a) The MIoU values of both training strategies. (b) The Macro-F1 values of both training strategies.
Figure 20.
The examples of transfer learning prediction results on the CSWV_M21. The number at the top indicates how many epochs of transfer learning were performed on the target dataset.
Figure 20.
The examples of transfer learning prediction results on the CSWV_M21. The number at the top indicates how many epochs of transfer learning were performed on the target dataset.
Figure 21.
The accuracy curves of transfer training, direct training, and transfer training with dynamic learning rate. (a) The MIoU values of three training strategies. (b) The Macro-F1 values of three training strategies. Difference1 is the discrepancies in accuracy between direct training and transfer training. Difference2 represents the discrepancies in accuracy between direct training and transfer training with dynamic learning rates.
Figure 21.
The accuracy curves of transfer training, direct training, and transfer training with dynamic learning rate. (a) The MIoU values of three training strategies. (b) The Macro-F1 values of three training strategies. Difference1 is the discrepancies in accuracy between direct training and transfer training. Difference2 represents the discrepancies in accuracy between direct training and transfer training with dynamic learning rates.
Figure 22.
The examples of transfer learning prediction results on the L8_SPARCS. The number at the top indicates how many epochs of transfer learning were performed on the target dataset.
Figure 22.
The examples of transfer learning prediction results on the L8_SPARCS. The number at the top indicates how many epochs of transfer learning were performed on the target dataset.
Figure 23.
Error cases in challenging cloud and snow detection scenes. (a) The remote sensing images with detection errors. (b) The delineated areas in (a) with the green boxes were magnified to provide a more detailed visual comparison.
Figure 23.
Error cases in challenging cloud and snow detection scenes. (a) The remote sensing images with detection errors. (b) The delineated areas in (a) with the green boxes were magnified to provide a more detailed visual comparison.
Table 1.
The detailed information of L8_SPARCS, CSWV_M21, and CSWV_S6 datasets.
Table 1.
The detailed information of L8_SPARCS, CSWV_M21, and CSWV_S6 datasets.
| Name | L8_SPARCS | CSWV |
|---|
| CSWV_M21 | CSWV_S6 |
|---|
| Source | Landsat8 | WorldView2 | WorldView2 |
| Scenes | 80 | 21 | 6 |
| Channels | Lack of band11 | R/G/B | R/G/B |
| Total Pixels | 8 × 107 | ~2.2 × 107 | ~2.9 × 108 |
| Pixel size | 30 m | 1–10 m | 0.5 m |
| Image size | 1000 × 1000 × 10 | Irregular size × 3 | Irregular size × 3 |
| Label | Flood | Yes | No | No |
| Water | Yes | No | No |
| Shadow | Yes | No | No |
| Shadow on wat. | Yes | No | No |
| Snow/Ice | Yes | Yes | Yes |
| Cloud | Yes | Yes | Yes |
Table 2.
The training details in different datasets.
Table 2.
The training details in different datasets.
| Dataset | Type | Train | Val. | Test | All | Epochs | Hinge Loss α | Dilation Rate |
|---|
| L8_SPARCS | Original | 220 | 60 | 40 | 320 | 120 | 0.150 | (1,2) |
| Enhanced | 880 | 240 | 40 | 1160 |
| CSWV_M21 | Original | 48 | 16 | 20 | 84 | 120 | 0.120 | (1,2) |
| Enhanced | 192 | 64 | 20 | 276 |
| CSWV_S6 | Original | 720 | 218 | 176 | 1114 | 80 | 0.075 | (2,4) |
| Enhanced | 2880 | 872 | 176 | 3928 |
| Biome | Original | 8598 | 1554 | 2825 | 12,977 | 80 | 0.200 | (1,2) |
| Enhanced | 34,392 | 6216 | 2825 | 43,433 |
| HRC_WHU | Original | 600 | 120 | 180 | 900 | 80 | 0.120 | (1,2) |
| Enhanced | 2400 | 480 | 180 | 3060 |
Table 3.
The detection accuracy, time complexity, and spatial complexity of various ablation networks on the CSWV_S6.
Table 3.
The detection accuracy, time complexity, and spatial complexity of various ablation networks on the CSWV_S6.
| Networks | (a) | (b) | (c) | (d) | (e) | (f) | (g) | (h) |
|---|
| Backbone | √ | √ | √ | √ | √ | √ | √ | √ |
| Inception V1-naive | × | × | × | × | × | × | √ | × |
| Inception V4-A | × | × | × | × | × | × | × | √ |
| MFF (single channel) | × | × | × | × | × | √ | × | × |
| MFF | × | √ | √ | √ | √ | × | × | × |
| DS | × | × | √ | × | × | × | × | × |
| DSFF | × | × | × | √ | × | × | × | × |
| CDSFF | × | × | × | × | √ | √ | √ | √ |
| MIoU | 82.89% | 85.18% | 86.52% | 86.90% | 88.54% | 85.73% | 87.09% | 85.03% |
| Macro-F1 | 90.46% | 91.79% | 92.62% | 92.86% | 93.83% | 92.12% | 92.98% | 91.70% |
| Kappa | 86.00% | 89.83% | 90.45% | 90.53% | 91.53% | 90.14% | 90.47% | 89.55% |
| OA | 94.09% | 95.87% | 96.13% | 96.14% | 96.56% | 95.99% | 96.11% | 95.73% |
| Macro-Pc | 88.56% | 90.37% | 91.70% | 91.39% | 92.84% | 90.99% | 91.82% | 90.55% |
| Macro-Rc | 93.15% | 93.40% | 93.60% | 94.46% | 94.91% | 93.33% | 94.29% | 93.02% |
| GFLOPs 1 | 40.26 | 87.88 | 87.92 | 88.06 | 88.06 | 62.16 | 80.3 | 56.44 |
| Parameters (M) 2 | 3.62 | 7.46 | 7.61 | 7.61 | 7.61 | 5.51 | 8.85 | 6.09 |
Table 4.
The cloud and snow detection accuracy comparisons on the various datasets.
Table 4.
The cloud and snow detection accuracy comparisons on the various datasets.
| Dataset | Method | MIoU | Macro-F1 | Kappa | OA | Macro-Pc | Macro-Rc |
|---|
| (a) L8_SPARCS | U-Net | 79.94% | 88.47% | 85.07% | 94.60% | 90.43% | 86.80% |
| PSPNet | 79.17% | 88.02% | 82.12% | 93.45% | 89.76% | 86.68% |
| DeeplabV3+ | 66.26% | 78.74% | 70.87% | 87.93% | 75.50% | 83.77% |
| RSNet | 79.60% | 88.17% | 85.94% | 94.79% | 90.98% | 86.87% |
| SegNet-M | 75.81% | 85.56% | 81.57% | 93.52% | 88.99% | 82.70% |
| MSCFF | 83.59% | 90.83% | 87.77% | 95.51% | 92.65% | 89.55% |
| GeoInfoNet | 75.77% | 85.72% | 79.93% | 92.09% | 86.39% | 87.15% |
| CDnetV2 | 83.19% | 90.59% | 86.02% | 94.77% | 89.69% | 91.53% |
| CSD-Net | 87.24% | 93.08% | 89.47% | 96.02% | 91.85% | 94.40% |
| (b) CSWV_M21 | U-Net | 82.41% | 90.18% | 86.77% | 92.85% | 91.61% | 89.04% |
| PSPNet | 75.59% | 85.78% | 79.95% | 89.04% | 86.26% | 85.45% |
| DeeplabV3+ | 69.51% | 81.44% | 74.78% | 85.53% | 79.68% | 84.58% |
| RSNet | 85.06% | 91.82% | 88.37% | 93.68% | 92.82% | 91.08% |
| SegNet-M | 81.10% | 89.38% | 85.19% | 91.94% | 90.03% | 88.81% |
| MSCFF | 85.91% | 92.33% | 89.27% | 94.12% | 92.13% | 92.58% |
| GeoInfoNet | 79.68% | 88.52% | 83.40% | 90.75% | 88.50% | 89.06% |
| CDnetV2 | 83.65% | 91.01% | 87.02% | 92.86% | 90.54% | 91.51% |
| CSD-Net | 87.05% | 93.01% | 90.01% | 94.51% | 92.85% | 93.19% |
| (c) CSWV_S6 | U-Net | 86.48% | 92.61% | 90.00% | 95.89% | 90.62% | 94.89% |
| PSPNet | 86.62% | 92.71% | 89.99% | 95.92% | 91.79% | 93.79% |
| DeeplabV3+ | 81.43% | 89.51% | 85.74% | 94.11% | 87.29% | 92.10% |
| RSNet | 84.53% | 91.43% | 88.44% | 95.26% | 91.25% | 92.23% |
| SegNet-M | 83.30% | 90.96% | 88.91% | 95.50% | 89.22% | 92.58% |
| MSCFF | 86.63% | 92.69% | 90.51% | 96.14% | 91.93% | 93.60% |
| GeoInfoNet | 85.45% | 92.00% | 88.95% | 95.46% | 90.32% | 93.88% |
| CDnetV2 | 86.53% | 92.63% | 90.59% | 96.20% | 91.88% | 93.42% |
| CSD-Net | 88.54% | 93.83% | 91.53% | 96.56% | 92.84% | 94.91% |
Table 5.
The value of floating point operations, the number of parameters, and the time cost for several methods.
Table 5.
The value of floating point operations, the number of parameters, and the time cost for several methods.
| Test Image | Model | FLOPs (GFLOPs) 1 | Parameters (M) 2 | Time Cost (s) |
|---|
CSWV_S6 test subset
Image size:512 2
Image number: 176 | U-Net | 219.59 | 34.51 | 5.3797 ± 0.1269 |
| PSPNet | 184.5 | 46.71 | 4.6257 ± 0.3248 |
| DeepLabV3+ | 102.94 | 41.05 | 3.0638 ± 0.0591 |
| RS-Net | 56.03 | 7.85 | 2.8704 ± 0.3622 |
| SegNet-M | 201.7 | 34.92 | 5.0814 ± 0.3821 |
| MSCFF | 354.79 | 51.88 | 9.2112 ± 0.1795 |
| GeoInfoNet | 99.83 | 14.66 | 6.6706 ± 0.5881 |
| CDnetV2 | 70.13 | 67.09 | 4.022 + 0.7158 |
| CSD-Net | 88.06 | 7.61 | 4.4721 ± 0.1397 |
Table 6.
Comparison of CSD-Net accuracy with different dilation rates.
Table 6.
Comparison of CSD-Net accuracy with different dilation rates.
| Dilation Rate | CSWV_S6 | CSWV_M21 | L8_SPARCS |
|---|
| MIoU | Macro-F1 | MIoU | Macro-F1 | MIoU | Macro-F1 |
|---|
| No dilation | 85.04 | 91.77 | 86.67 | 92.80 | 86.43 | 92.60 |
| (1, 2) | 86.34 | 92.53 | 87.05 | 93.01 | 87.28 | 93.10 |
| (2, 2) | 87.33 | 93.10 | 85.70 | 92.21 | 87.28 | 93.09 |
| (2, 3) | 86.11 | 92.36 | 84.14 | 91.27 | 81.98 | 89.81 |
| (2, 4) | 88.54 | 93.83 | 84.71 | 91.62 | 85.42 | 91.97 |
| (3, 3) | 86.16 | 92.42 | 83.58 | 90.93 | 85.79 | 92.20 |
Table 7.
Comparison of CSD-Net accuracy with different dilation rates.
Table 7.
Comparison of CSD-Net accuracy with different dilation rates.
| Hinge Loss α | CSWV_S6 | Hinge Loss α | CSWV_M21 | Hinge Loss α | L8_SPARCS |
|---|
| MIoU | Macro-F1 | MIoU | Macro-F1 | MIoU | Macro-F1 |
|---|
| α = 0 | 86.90 | 92.86 | α = 0 | 84.48 | 91.49 | α = 0 | 85.08 | 91.78 |
| α = 0.06 | 84.31 | 91.31 | α = 0.10 | 86.17 | 92.50 | α = 0.12 | 87.05 | 93.01 |
| α = 0.07 | 88.29 | 93.68 | α = 0.11 | 84.78 | 91.67 | α = 0.13 | 86.70 | 92.75 |
| α = 0.075 | 88.54 | 93.83 | α = 0.12 | 87.05 | 93.01 | α = 0.14 | 85.26 | 91.89 |
| α = 0.08 | 88.00 | 93.51 | α = 0.13 | 85.77 | 92.26 | α = 0.15 | 87.28 | 93.10 |
| α = 0.09 | 87.04 | 92.94 | α = 0.14 | 86.05 | 92.42 | α = 0.16 | 86.81 | 93.01 |
Table 8.
Quantitative evaluation results of CSD-Net with different learning rates.
Table 8.
Quantitative evaluation results of CSD-Net with different learning rates.
| Learning Rate | MIoU | Macro-F1 | Kappa | OA | Macro-Pc | Macro-Rc |
|---|
| 0.00001 | 76.53% | 86.14% | 82.98% | 92.91% | 86.13% | 87.47% |
| 0.00005 | 82.81% | 90.37% | 87.17% | 94.69% | 88.92% | 92.18% |
| 0.0001 | 88.54% | 93.83% | 91.53% | 96.56% | 92.84% | 94.91% |
| 0.0005 | 83.85% | 91.04% | 87.42% | 94.75% | 88.34% | 94.25% |
| 0.001 | 87.95% | 93.48% | 91.21% | 96.44% | 92.31% | 94.76% |
| 0.005 | 85.85% | 92.25% | 89.16% | 95.53% | 90.36% | 94.36% |
| 0.01 | 82.58% | 90.28% | 85.88% | 93.99% | 86.96% | 94.42% |
| 0.05 | 83.46% | 90.70% | 88.49% | 95.29% | 89.43% | 92.10% |
Table 9.
The quantitative evaluation comparison on the HRC_WHU dataset.
Table 9.
The quantitative evaluation comparison on the HRC_WHU dataset.
| Method | IoU | F1-Score | Kappa | OA |
|---|
| U-Net | 86.23% | 92.60% | 87.78% | 94.16% |
| PSPNet | 84.27% | 91.46% | 86.21% | 93.49% |
| DeepLabV3+ | 82.57% | 90.45% | 84.14% | 82.40% |
| RS-Net | 88.37% | 93.83% | 89.72% | 95.07% |
| SegNet-M | 85.77% | 92.34% | 87.28% | 93.91% |
| MSCFF | 85.89% | 92.41% | 87.54% | 94.07% |
| GeoInfoNet | 83.02% | 90.72% | 84.43% | 92.50% |
| CDnetV2 | 85.81% | 92.36% | 87.10% | 93.76% |
| CSD-Net | 89.65% | 94.54% | 90.97% | 95.68% |
Table 10.
The quantitative evaluation comparison on the Biome dataset.
Table 10.
The quantitative evaluation comparison on the Biome dataset.
| Method | IoU | F1-Score | Kappa | OA |
|---|
| U-Net | 70.88% | 82.96% | 75.43% | 89.51% |
| PSPNet | 74.22% | 85.20% | 78.48% | 90.73% |
| DeepLabV3+ | 70.12% | 82.43% | 74.56% | 89.09% |
| RS-Net | 73.88% | 84.98% | 78.28% | 90.70% |
| SegNet-M | 74.74% | 85.54% | 78.73% | 90.73% |
| MSCFF | 74.89% | 85.64% | 78.95% | 90.86% |
| GeoInfoNet | 70.93% | 82.99% | 75.12% | 89.23% |
| CDnetV2 | 75.61% | 86.11% | 79.74% | 91.25% |
| CSD-Net | 76.89% | 86.99% | 80.71% | 91.53% |

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}