Abstract
The explosive growth of spatial data and the widespread use of spatial databases emphasize the need for spatial data mining. The subsets of features frequently located together in a geographic space are called spatial co-location patterns. It is difficult to discover co-location patterns because of the huge amount of data brought by the instances of spatial features. A large fraction of the computation time is devoted to generating row instances and candidate co-location patterns. This paper makes three main contributions for mining co-location patterns. First, the definition of maximal instances is given and a row instance (RI)-tree is constructed to find maximal instances from a spatial data set. Second, a fast method for generating all row instances and candidate co-locations is proposed and the feasibility of this method is proved. Third, a maximal instance algorithm with no join operations for mining co-location patterns is proposed. Finally, experimental evaluations using synthetic data sets and a real data set show that maximal instance algorithm is feasible and has better performance.
1. Introduction
Spatial co-location mining is to mine the positive relationship of different spatial features in spatial data. It is somewhat difficult to find co-location instances since the instances of spatial features are embedded in a continuous space and share neighbor relationships. Association rule mining algorithms cannot be directly applied to co-location pattern mining since there are no pre-defined transactions in spatial data sets [1]. Thus, the following three basic approaches have been proposed for mining co-locations: Huang, et al. first proposed a join-based approach [1,2]. This approach mines co-locations by using the concept of proximity neighborhood and identifies co-location instances by joining table instances, ensuring the correctness and completeness of this approach. Then, the partial-join approach [3] and the join-less approach [4,5] were proposed for fast mining of co-location patterns. The partial-join approach first transactionizes continuous spatial data (builds cliques) to identify the intraX instances of co-location (belonging to a clique) and the interX instances of co-location (belonging between two cliques) and then joins the intraX instances and the interX instances, respectively, to calculate the value of the participation index. This approach mines co-location patterns more efficiently than the join-based approach since it reduces a large number of join operations. The join-less approach uses the star neighborhood to identify spatial relationships. It is more efficient compared with the join-based approach and the partial-join approach since it generates co-location patterns without join operations.
In recent years, inspired by the transaction-based approach [6] and the transaction-free approach [7] in pattern mining, researchers have proposed many advanced/improved co-location mining approaches. The problem of mining co-location patterns with rare spatial events was first addressed by Huang et al. [8]. The concept of maximal clique has been proposed and applied for co-location mining in the literature, for example, [9,10,11]. Yao et al. proposed an adaptive maximal co-location (AMCM) algorithm to address two limitations in the co-location mining method [12]. A multi-level method was developed to identify regional co-location patterns in two steps: first, global co-location patterns were detected and other non-prevalent co-location patterns were identified as candidates for regional co-location patterns; second, an adaptive spatial clustering method was applied to detect the sub-regions where regional co-location patterns are prevalent [13]. Some researchers have studied the relationship between the spatial co-location pattern and clustering [14,15,16], which provides a new idea for co-location mining algorithm. Ouyang et al. studied the co-location mining problem for fuzzy objects and proposed two new kinds of co-location pattern mining for fuzzy objects, single co-location pattern mining (SCP) and range co-location pattern mining (RCP), for mining co-location patterns at a membership threshold or within a membership range [17]. Zhou et al. have also made a lot of contributions to the co-location problem [18,19,20]. A novel clique-based approach for discovering complete and correct prevalent co-location patterns was proposed by Bao and Wang [21]. Celik et al. designed an indexing structure for co-location patterns and proposed algorithms (Zoloc-Miner) to discover zonal co-location patterns efficiently for dynamic parameters [22]. The concept of negative co-location patterns was defined by Jiang et al. [23]. Based on the analysis of the relationship between negative and positive participation indexes, they proposed methods for negative participation index calculation and negative pattern pruning strategies. Yu investigated a projection-based co-location pattern mining paradigm [24].
Although those approaches have solved the problem of co-location mining, they still have shortcomings—for example, the join-based approach requires a large number of join operations, building cliques is time consuming in the partial-join approach, and the computation time of the join-less approach increases with an increase in the co-location size. Most of these shortcomings are caused by instance join and excessive calculation of the participation index. For this reason, this paper presents a maximal instance algorithm for the fast mining of co-location patterns. The major contributions are the following:
- A maximal instance algorithm for mining co-location patterns is presented. This algorithm can generate row instances and co-locations without join operations, which can make co-location mining more efficient.
- The concept of maximal instance is introduced and used to generate all row instances of co-locations.
- Experiments show that the maximal instance algorithm is feasible and has better performance.
2. Maximal Instance Algorithm
In Figure 1a, each instance is uniquely identified by , where T is the spatial feature type and i is the unique ID inside each spatial feature type, and the lines between instances represent neighbor relationships. Figure 1b shows the instances of co-location being generated by instance joins. A maximal instance is a row instance that does not appear as a subset of another row instance. In other words, maximal instances cannot combine with other instances to generate row instances of higher-size co-locations. For example, in Figure 1a is not a maximal instance since it is a subset of the row instance , which in turn is a maximal instance. A maximal instance must be a maximal clique (a maximal clique is defined as a clique that does not appear as a subset of another clique in the same co-location pattern), but a maximal clique may not be a maximal instance since maximal cliques may not be row instances. Assuming , , and ( is an instance of A, and and are instances of B) form a clique, i.e., they are neighbors to each other, {, , } is a maximal clique rather than a maximal instance as it is not a row instance. However, is a maximal instance and also a maximal clique.
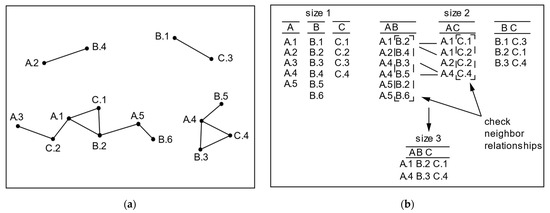
Figure 1.
(a) An example data set; (b) instance joins.
2.1. Generation of Row Instances
The generation of row instances is the basic part of co-location mining because only when all row instances are found can the participation index of co-locations be calculated. How to find row instances of co-locations is discussed here.
In the process of generating row instances of all co-locations, there are some differences between our algorithm and previous algorithms. The generation of row instances in the join-based algorithm, based on a join operation, can be represented by formula (1), and the detailed instance join process for the example data set (in Figure 1a) is shown in Figure 1b. The k-size row instances are generated from k-1-size row instances, i.e., high-size row instances are generated by the join operation between low-size row instances. For example, the 2-row instance and can be joined to generate a 3-row instance . This method for mining co-location is time consuming due to the large number of join operations required as the number of features and their instances increases.
Here, is a set of spatial event types (i.e., ) and is a set of row instances of i-size co-locations. In a join-based algorithm, the set of all row instances is a merge of , and , i.e., . Every time the size of co-locations is increased, a join operation needs to be performed, resulting in k-1 being the number of times join operations are needed to generate a k-size row instance. The larger the k, the more the number of join operations needed and the more the execution time consumed. Therefore, the method (called the join-based method in this paper) of generating row instances by join operations is inefficient.
By reviewing the generation of row instances in the join-based algorithm, the relationship between a high-size row instance H generated from L and a low-size row instance L is obvious: L is a subset of H since H must contain the instances in L. In addition, if a high-size row instance exists, it must also exist for its corresponding low-size row instances. The corresponding low-size row instances are actually subsets of the high-size row instances. So, Lemma 1 can be obtained. According to Lemma 1, instead of using low-size row instances to generate high-size row instances, as in traditional algorithms, this paper thinks backward: using high-size row instances to generate low-size row instances.
Lemma 1.
An arbitrary non-empty subset of a k-size row instance must be a row instance of co-location.
Proof of Lemma 1.
This lemma is proved from the definition and generation process of row instances. (1) By definition, a row instance is essentially an R-proximity neighborhood, and the definition of R-proximity neighborhoods is given by Huang as follows: an R-proximity neighborhood is a set of instances that form a clique under the relation R. Accordingly, a set I is a row instance if any two instances in I satisfy the neighborhood relation. (2) Huang et al. gave a detailed introduction to the generation of row instances [1]. Similar to the generation of candidate co-locations, row instances are generated by a join strategy. An example in Figure 1 is used to illustrate the generation of row instances. Row instances and are joined to generate . Then the neighbor relationship between and . is a true row instance if has a neighbor relationship with . On the contrary, , generated by joining and , fails to be a row instance since has no neighbor relationship with . Thus, any two instances in a row instance satisfy the neighbor relationship. Let be a set of instances in a k-size row instance. Because k-size row instances are generated from k-1-size row instances, a conclusion is drawn: is a proper subset of (shown as the formula ). Therefore, it can be inferred that . So, any set is a proper subset of (), i.e., . If row instances are treated as sets, the following conclusion can be drawn: . Here, is a set of k-size row instances and . In summary, an arbitrary non-empty subset of a k-size row instance must be a row instance of co-locations. □
Accordingly, (1) a maximal instance is the maximal row instance for a co-location and it cannot join with another instance to generate a high-size row instance and (2) a further conclusion can be drawn from Lemma 1 that non-empty subsets of maximal instances are all row instances of co-locations. Once all maximal instances are found, all row instances can be generated by finding non-empty subsets of them. This method (shown in formula (2), is a set of maximal instances) for generating row instances does not require join operations, which can reduce a lot of computing time. The set of all row instances is a merge of non-empty subsets of maximal instances. Empty sets are not considered here since it is meaningless.
A simple comparison is made to illustrate that this method is more efficient than the join-based method for generating row instances. The join-based method generates row instances by join operations. First, 2-size row instances are generated by joining spatial instances that have a neighbor relationship. Then high-size row instances are generated size by size until no higher-size row instances are generated. k-1 is the number of join operations required to generate all row instances, which is time consuming. Our method is to first generate the highest-size row instances (maximal instances) and then generate all row instances by finding non-empty subsets of the highest-size row instances, which requires no join operations and finding subsets only once. One obvious difference between the two methods is that the join-based method generates row instances from low sizes to high sizes and our method generates row instances from the highest size to low sizes. A large number of join operations are not needed in our method, which makes our method less time consuming.
Let k be the number of maximal instances, represent a maximal instance (), represent the set of non-empty subsets of , be the power set of , be the number of instances in , and be the number of row instances. The two lemmas can be derived: ; . The proofs are as follows. It should be noted that the universal set here is the set of spatial instances I.
Lemma 2.
.
Proof of Lemma 2.
First, according to the conclusion that non-empty subsets of maximal instances are all row instances of co-locations, there is . Second, since , the power set of , is defined as a set of all subsets of ; is the set of non-empty subsets of . Therefore,
□
Lemma 3.
.
Proof of Lemma 3.

For an n-set, the total number of subsets is , so , and since . Therefore, . □
As shown in Table 1, , is a set of maximal instances found from the example data set in Figure 1a. Row instances of all co-locations listed in the second column of Table 1 are non-empty subsets of maximal instances, and the number of row instances can be calculated by Lemma 3.
□
Table 1.
Enumeration of the maximal instance and co-location instances.
2.2. RI-Tree Construction
As described in Section 2.1, maximal instances are used to generate the row instances of co-locations. The RI-tree for finding maximal instances is introduced in this section.
A maximal instance m should satisfy the following two conditions: (1) m is a row instance of a co-location and (2) m cannot join with other instances to generate a high-size row instance.
An RI-tree is a kind of rooted tree. The root of the RI-tree is labeled as F (F is a set of all spatial instances). A branch of the RI-tree is constructed as a corresponding connective sub-graph in the graph G. The node in the RI-tree represents the row instance of co-location patterns. The node u is the parent of the node v, and when v is a row instance of size k co-locations, u is one of the row instances of size k-1 co-locations. An RI-tree is constructed to generate maximal instances, which is the key of co-location mining. As shown in Figure 2, a set of spatial instances with their spatial relationships (i.e., Euclidean distance) is input, and an algorithm implemented in Python outputs all maximal instances. In this process, neighbor relationships between instances of the same spatial feature type are not taken into consideration since our goal is to find the positive relationship between different spatial feature types.

Figure 2.
Algorithm for generating maximal instances.
Based on the definitions of RI-tree and maximal instance, there is the process of constructing an RI-tree.
Process of constructing an RI-tree:
- (1)
- Create the root of the RI-tree and label it as F.
- (2)
- Push all spatial instances into a set F in alphabetic and numerical descending order.
- (3)
- Pop an instance from and delete it in . Then create a child node of the root F for this instance.
- (4)
- Find out the instances that are neighbors of this instance, have different spatial features from this instance, and are bigger than this instance.
- If not, return to (3).
- If so, push them into a set T in alphabetic descending order and create a child node for them.
- (5)
- Find out the instances that are neighbors of the last instance in T and delete them in .
- If not, push T in M; return to (3).
- If so and if they also have a neighborhood relationship with the rest of the instances in T, put them at the end of T and create a child node for them. Return to (5).
- If so but if they are not all neighbors with other instances in T, push T in M, create another child node of the root for the last instance in T, and generate a new T by combining it with the last instance in T. Return to (5).
- (6)
- Repeat the operation above till is empty.
Figure 3 shows the process of constructing an RI-tree for the example data set in Figure 1a. The leaf nodes of this RI-tree, such as , , , , , , , , and , are maximal instances of the example data set. Let us take as an example to illustrate the gene ratio of a maximal instance. is a spatial instance popped from the example data set. Create a child node of for and because of the neighbor relationship between and . Then find out the instance that has a neighbor relationship with and check whether there is a neighbor relationship between and . A child node is created for and because of the neighbor relationship between and . The spatial instance has a neighbor relationship with but not with and , so is a maximal instance.
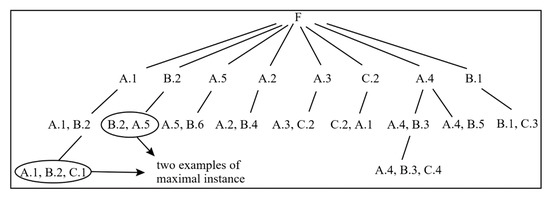
Figure 3.
The process of constructing a row instance (RI)-tree.
2.2.1. Rules of an RI-Tree
- Before building an RI-tree, all spatial instances are put into the set F. The instance will be deleted from F if a child node of the root is created for it or if it has a neighbor relationship with the child node of the root. For example, a child node of the root is created for , so will be deleted from F; and are deleted from F since they have neighbor relationships with ( is a child node of the root).
- Each node is a row instance of the co-location, and note that not all row instances are listed in the RI-tree but all neighbor relationships are contained in the RI-tree. The number of row instances is very large if there are a lot of instances in the spatial data. The aim of an RI-tree is to generate the maximal instance; there is no need to list all row instances in an RI-tree. A node in an RI-tree contains neighbor relationships between all instances in the node.
- The nodes of the n-th layer of an RI-tree are n-1-size row instances. The spatial instances in F are selected as the child node of the root, i.e., nodes in the second layer of the RI-tree. From layer 3 to layer n, there are size 2 row instances, size 3 row instances, , and n-1-size row instances. The highest size of the row instance of the example data in Figure 1 is 3 since the RI-tree constructed for this example data has only four layers.
- After creating a child node of the root, scan its neighbor relationships. The neighbor relationships are identified by the Euclidean distance metric. Two instances have a neighbor relationship if their Euclidean distance is less than the user-defined minimum distance threshold [1]. If this node has a neighbor relationship with another instance, a child node of this node will be created under this branch for these two instances; if there is no common neighbor of instances in this node, another instance will be popped from F and a child node of the root will be created for it. For example, instance is a child node of the root and the node “” is created under this branch since has a neighbor relationship with . There is no common neighbor of and , but still has relationship with , so a new child node of the root is created for , and the node has “” as a child node.
- The RI-tree is built from left to right. When a leaf node appears in one branch of the RI-tree, another branch can be established. A node is a leaf node if there is no common neighbor of instances in this node, which means the end of the branch where this node is located.
- The leaf nodes of an RI-tree are maximal instances because a leaf node is a row instance in which all instances are neighbors and no other instance can join with it to generate a high-size row instance. It is obvious that the leaf node meets the conditions of maximal instance. The number of maximal instances equals the number of branches of the RI-tree.
2.2.2. Completeness of the RI-Tree
None of the neighbor relationships is omitted in the process of finding maximal instances. All the spatial instances are scanned, and all neighbor relationships between instances of different spatial types are considered in the process of constructing an RI-tree. Although not all neighbor relationships are shown in the RI-tree, they are considered when creating nodes. For example, the node “” contains the neighbor relationships between and , and , and and , although the neighbor relationships between and on one hand and and on the other are not shown in the RI-tree. The neighbor relationships are also not duplicated. Once all neighbor relationships of an instance are identified, this instance will be deleted in F.
2.3. Generation of Co-Locations
Candidate co-location generation: The basic algorithms rely on a combinatorial approach and use apriori_gen [25] to generate size k+1 candidate co-locations from size-k-prevalent co-locations. However, this paper generates candidate co-locations from maximal instances, which does not require any join operations. is a candidate co-location if is a maximal instance, is an instance of spatial event types , and . For example, is a maximal instance, so is a candidate co-location. Candidate co-locations are also generated from candidate co-locations that are not prevalent. Candidate co-locations generated from maximal instances are not all prevalent. Candidate co-locations that fail to be a prevalent pattern are selected, and their subsets are corresponding low-size candidate co-locations. That is because of the anti-monotonicity of the participation index. If (C is a candidate co-location,), there must exist (c is a subset of C) and c may be a prevalent co-location, so c is a candidate co-location. Taking Figure 1 as an example, if is set to 0.4, is not a prevalent co-location since , where pr is the participation ratio. Therefore, , and (subsets of ) are candidate co-locations.
Pruning: To make our algorithm more efficient, this step introduces the pruning strategies that can greatly reduce the unnecessary calculation time. Prevalence-based pruning [1] is also used in our algorithm. The refinement filtering of co-locations is done by the participation index values calculated from their co-location instances. Prevalent co-locations satisfying a given threshold are selected. Actually, there is no need to calculate the participation index of each candidate co-location. Because the participation ratio and the participation index are antimonotone (monotonically nonincreasing) as the size of the co-location increases [1]), if a high-size candidate co-location is prevalent, subsets of this candidate co-location are all prevalent. Therefore, participation indexes of high-size candidate co-locations (generated by maximal instances) are prioritized. If the participation index values are above a given threshold, there is no need to calculate the participation indexes of subsets of a high-size candidate co-location; if the participation index values are below a given threshold, the participation indexes of the subsets of high-size candidate co-locations need to be calculated.
The second pruning strategy can be explained by Lemma 4.
Lemma 4.
Subsets of a candidate co-location are prevalent if it is a prevalent co-location.
Proof of Lemma 4.
This lemma is proved by the antimonotone property of the participation index. is a candidate co-location; is a subset of ; and k and n () are the number of instances in and the number of instances in , respectively. From the above formula, it can be concluded that the participation index of a candidate co-location is less than or equal to that of its subset. If , then must be established, so the following conclusion can be drawn: subsets of a candidate co-location are prevalent if it is a prevalent co-location.
□
Quite a lot of maximal instances are generated in the process of mining co-locations from the real data set introduced in Section 4. is a candidate co-location since there are row instances of in maximal instances, and is the highest-size candidate co-location since there are only five facility types in the real data set. The participation index of is calculated first. When is set to 1, . fails to be a prevalent co-location if is set to 0.4. Therefore, , , , , and , which are the subsets of , become candidate co-locations. In the subsets of , those row instances that contain four instances are row instances of size 4 co-locations. The size 4 maximal instances are also row instances of size 4 co-locations. By calculating their participation indexes, it is clear that is a prevalent co-location with . According to the anti-monotonicity of the participation index, the participation indexes of , , , and must be greater than 0.48. , , , and are prevalent co-locations, so there is no need to calculate their participation indexes, which saves a lot of time. This is the pruning strategy mentioned above.
2.4. Discussions for Maximal Instance Algorithm
The idea of the presented algorithm is different from the existing algorithms. The differences are as follows:
- The existing methods identify high-size row instances from low-size row instances, but the presented algorithm first identifies the highest-size row instances (maximal instances) based on the relationship of spatial instances and then generates all low-size row instances from highest-size row instances.
- The existing methods generate candidate patterns by joining row instances, but the presented algorithm generates candidate patterns from maximal instances without join operations.
2.4.1. Comparison Analysis of Row Instance Generation
The reason why our method for generating all row instances is more efficient than the join-based algorithm is demonstrated in detail here. Let and be the computation cost of generating all row instances by the join-based algorithm and our method. The following equations show the computation cost functions:
represents the computation cost of a join operation, represents the computation cost of generating all maximal instances, and represents the computation cost of finding the subsets of maximal instances. because generating maximal instances is also a scanning process of neighbor relationship and .
Therefore,
Apparently, . So the conclusion can be drawn that our method of generating all row instances is more efficient than the join-based algorithm.
2.4.2. Comparison Analysis of Maximal Instance Algorithm
The computational cost of our algorithm with three basic algorithms is compared here. Each algorithm has an initial step of materializing neighborhoods. The join-based algorithm first gathers the neighbor pairs per candidate co-location, the partial-join algorithm first generates the disjoint clique neighborhoods using a simple grid partitioning, the join-less algorithm first generates the star neighborhoods, and our algorithm first generates maximal instances. S represents a spatial data set; , , , and represent the computational costs of the initial steps in each algorithm; and , , and represent the cost of generating size 2 co-locations in the join-less algorithm, the partial-join algorithm, and the join-based algorithm, respectively. Let , and be the total computation cost of our algorithm, the join-less algorithm, the partial-join algorithm, and the join-based algorithm, respectively. The following equations show the total cost functions:
Here, k is greater than 2.
Yoo and Shekhar [5] proposed the following comparative relationships:
because (1) the join-less algorithm involves an additional cost to generate the star neighborhoods from the neighbor pairs compared with join-based algorithm and (2) an additional cost is incurred when finding all size 2 inter-instances with cut relationships in the partial-join algorithm, the overall cost is expected to be a little greater than the cost to generate the star neighborhood set.
Lemma 5.
.
Proof of Lemma 5.
The star neighborhood partition model in the join-less algorithm takes each spatial object as a central object and finds out the remaining objects in its neighborhood. Thus, this process is performed n times, where n is the number of spatial objects. The process of generating all maximal instances needs to be executed times, where is the number of maximal instances. Apparently, , so the star neighborhood partition model in the join-less method is more time consuming than the process of generating the maximal instance in our method.
□
Lemma 6.
.
Proof of Lemma 6.
Gathering the neighbor pairs per candidate co-location is the most basic operation in co-location mining. The neighbor pairs are used to generate maximal instances, and it involves additional cost compared with gathering the neighbor pairs per candidate co-location and calculating their prevalence measures. □
According to Lemma 5 and Lemma 6, the following equation can be reached:
The advantage of the maximal instance algorithm lies in the latter part. Three basic algorithms generate bigger-size co-locations size by size after generating size 2 co-locations. This operation needs to be repeated k-2 times to generate all co-locations. No operation can be omitted, and a cross-size operation is not allowed (size k co-locations cannot be directly generated from size k-2 co-locations; size k co-locations are generated from size k-1 co-locations after generating size k-1 co-locations from size k-2 co-locations). Therefore, the execution time of each join operation should be added to the total computational costs of the three basic algorithms.
However, once the maximal instance algorithm generates maximal instances, row instances of all size co-locations can be generated from the subsets of maximal instances. There is no need for a join operation. A large amount of time consumption is avoided in this part; the bigger the size of the co-locations, the more obvious the effect, and thus the following equations:
On the basis of Equations (5)–(8), we can say that our algorithm has a lower computational cost than the three basic algorithms.
2.5. Overview of the Maximal Instance Algorithm
This section introduces the steps in the maximal instance algorithm. As shown in Figure 4, this algorithm has four steps in the flow chart. The participation index is still used as the prevalence measure to determine whether a co-location pattern is prevalent. As shown in Figure 5, the maximal instance algorithm takes a set E of spatial event types, a set I of instances, a distance threshold , and a minimal prevalent threshold . The algorithm outputs a correct set of co-location patterns with participation index . The set of candidate size 1 co-locations and the set of prevalent size 1 co-locations are initialized to E, since the value of the participate index is 1 for all size 1 co-locations. The set of row instances of size 1 co-locations is initialized to I.
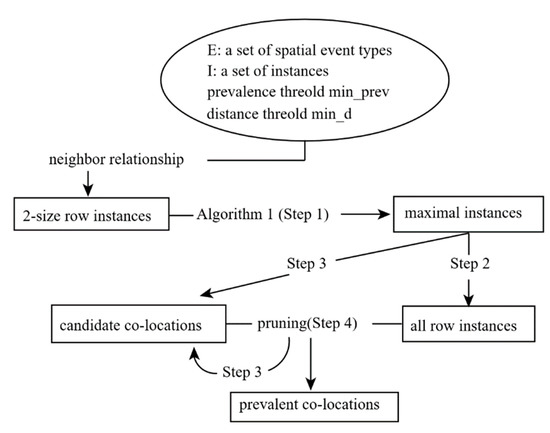
Figure 4.
The flow of the maximal instance algorithm.

Figure 5.
Algorithm for generating co-location patterns.
Step 1 (maximal instance generation): Our algorithm aims to find the maximal instances first, which is the key to co-location mining. A set of spatial instances with their spatial relationships (i.e., Euclidean distance) is input, each instance is a vector , and an algorithm implemented in Python outputs all maximal instances. In this process, the neighbor relationships between instances of the same spatial feature type are not taken into consideration since our goal is to find the positive relationship between different spatial feature types.
Step 2 (row instance generation): Row instances of co-locations are generated by finding subsets of maximal instances instead of join operations between row instances.
Step 3 (candidate co-location generation): is a candidate co-location if is a maximal instance, is an instance of spatial event types , and . For example, is a maximal instance, so is a candidate co-location, and a candidate co-location is also generated from candidate co-locations that are not prevalent.
Step 4 (pruning): There are two pruning strategies in the maximal instance algorithm: (1) prevalence-based pruning is also used in our algorithm, and (2) participation indexes of high-size candidate co-locations (generated by maximal instances) are prioritized. If the participation index values are above a given threshold, there is no need to calculate the participation indexes of subsets of the high-size candidate co-location; if the participation index values are below a given threshold, the participation indexes of subsets of high-size candidate co-locations need to be calculated.
3. Experiments
In this section, experiments are carried with synthetic data sets and a real data set to evaluate our algorithm.
3.1. Synthetic Data Set
The synthetic data sets are generated in Python, as shown in Figure 6. There are 60 different spatial event types in a synthetic data set. The number of instances of each spatial feature stored in the set Value is a random number between 5 and 10. E is a set of all spatial event types, and I is a set of instances. Each instance is a point distributed in a spatial framework (150100), and these point data have their own unique coordinates. The neighbor relationships of the synthetic data sets are generated by calculating the Euclidean distance of those points and stored in the set R.
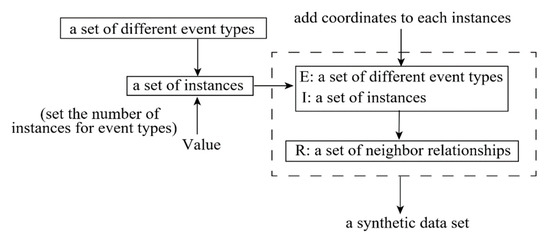
Figure 6.
Generation process of a synthetic data set.
3.2. Real Data Set
The real data set is about college and university locations, hospital locations, library locations, nursing home locations from Maine E911 address data from MainePUC, and point locations of the mineral collecting sites in Maine [26]. Each event in this data set with a different spatial feature types has a unique event ID. Contained in each event is county, town, latitude, longitude, and other information. Location information with only latitude and longitude is considered in this experiment. The event numbers of spatial feature types are shown in Table 2.
Table 2.
Description of event numbers of spatial feature types.
3.3. Experiment Results
A summary of our experiment result is presented here. A real data set of college and university locations, hospital locations, library locations, nursing home locations from Maine E911 address data from MainePUC, and point locations of the mineral collecting sites in Maine is studied in this paper. The longitude and latitude of each facility are used as coordinates to calculate the Euclidean distance. The effects of on the number of neighbor relationships, participation ratio, and participation index are evaluated. Table 2 shows the number of events for each spatial feature type in the real data set.
Table 3 shows the participation indexes of co-location patterns. When is set to 0.4 and is set to 0.5, co-location patterns , , , , , and are prevalent and their participation indexes are 0.61, 0.63, 0.81, 0.59, 0.53, and 0.73, respectively. The co-location means hospitals are frequently located together in a geographic space with colleges and universities. For example, the University of Southern Maine is adjacent to two hospitals in the south, namely Maine Medical Center and Northern Light Mercy Hospital. The co-location means libraries are frequently located together in a geographic space with colleges and universities. This is mainly because some libraries are located inside universities and colleges. For example, the largest library in Maine, the Fogler Library, is located in the University of Maine.
Table 3.
The participation indexes of co-location patterns.
The result quality comparison
Firstly, the quality of the generated maximal instance is tested in terms of the total number of maximal instances, the number of maximal instances per size, and the number of maximal instances with errors and repetitions. The quality result of the maximal instances is shown in the Table 4. There are 1342 maximal instances in total. After removing the repetition, the number of size 2, size 3, size 4, and size 5 maximal instances is 1268, 17, 5, and 3, respectively. These 1342 maximal instances are not all correct. Among them, seven maximal instances with a size greater than 5 are errors. The maximum size of maximal instances is 5 since there are only five feature types in the real data set. Moreover, there are 42 repeated maximal instances in the size 2 maximal instances, but this phenomenon does not appear in the other higher-size maximal instances. It can be seen that the quality of the generated maximal instances is relatively good. These maximal instances of errors and repetitions have little effect on the experimental results.
Table 4.
The quality of maximum instances.
Figure 7 shows a comparison of row instances generated by the join-based algorithm a and the maximal instance algorithm. Row instance is the basis of co-location participation index. Only when the number of row instances is clear can the participation index of co-locations be calculated and whether co-locations are frequent be judged. Therefore, this paper used the join-based algorithm and the maximal instance algorithm to generate all the row instances, recorded the number of row instances in each size, and made a comparison. The results show that the number of size 3, size 4, and size 5 row instances generated by the two algorithms is the same and only the number of size 2 row instances is slightly different. The maximal instance algorithm generates 42 more size 2 row instances than the join-based algorithm, which is because the maximal instance algorithm generates 42 repeated maximal instances in the size 2 maximal instances. The impact of these 42 row instances on participation is very small.
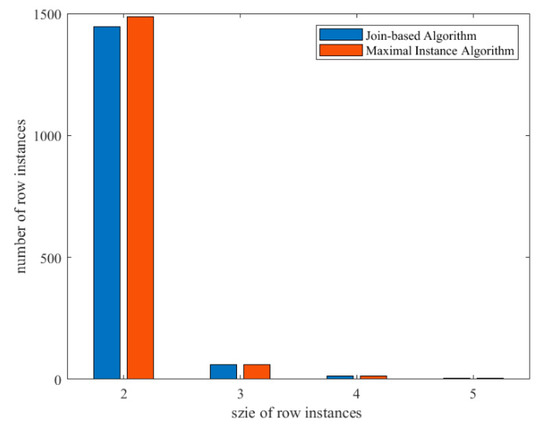
Figure 7.
Comparison of row instances generated by the join-based algorithm a and the maximal instance algorithm.
On comparing the results, it is clear that the maximal instance algorithm only has a slight difference in the size 2 instance, which will not have a great impact on the quality of the generated co-locations.
Effect ofon the number of neighbor relationships
The effects of on the number of neighbor relationships are evaluated. The value of is changed while the other experimental parameters remain unchanged. The number of neighbor relationships between any two spatial feature types is checked successively. The result is shown in Figure 8. In general, the number of neighbor relationships between any two types increases with an increase in the value of . With the increase in , the numbers of neighbor relationships of and are far more than that of other patterns. Because of the large number of events of type U, H, and L, the numbers of neighbor relationships of and increase sharply to more than 7000 when increases to 0.9.
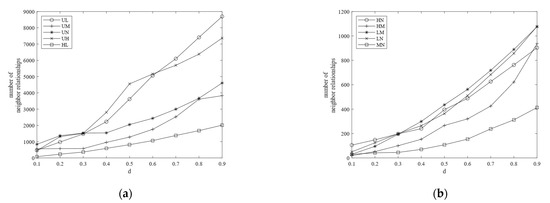
Figure 8.
(a) The number of neighbor relationships of , , , and ; (b) the number of neighbor relationships of , , , and .
Effect ofon participation ratio and participation index
The effects of on participation ratio and participation index are evaluated. The value of the parameter is changed to observe the values of the participation ratio and the participation index of co-locations. Figure 9 shows the change in the participation ratio of co-locations , , , , , and . It is obvious that the values of the participation ratio increase with an increase in . The changes in the participation indexes of different co-locations are shown in Figure 10a,b. The following observations can be made:
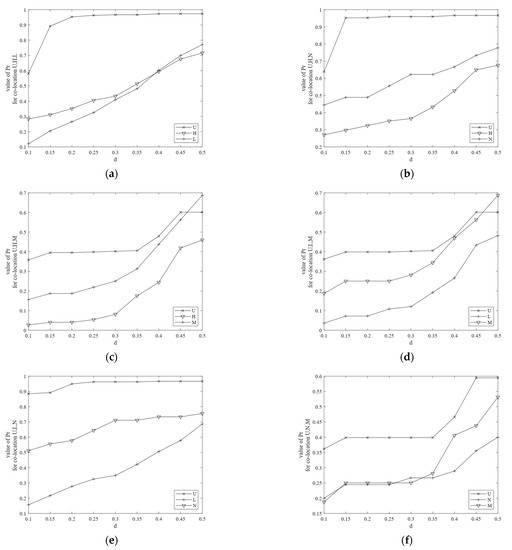
Figure 9.
(a) Pr of co-location ; (b) Pr of co-location ; (c) Pr of co-location ; (d) Pr of co-location ; (e) Pr of co-location ; (f) Pr of co-location .
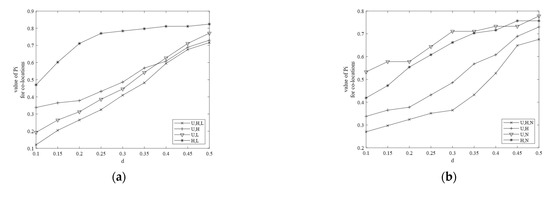
Figure 10.
(a) Pi of , , and ; (b) Pi of , , and .
- (1)
- (the value of the participation index of ) is always smaller than , , and , and the same is the case in Figure 10b, where is always smaller than , , and . This is because the participation ratio and the participation index are antimonotone (monotonically nonincreasing) as the size of the co-location increases [1] and it shows that our results are correct.
- (2)
3.4. Experimental Evaluation
The synthetic data sets are used to check whether our algorithm has better performance. Two comparative experiments on running time were done to evaluate the performance of the maximal instance algorithm. As shown in Figure 11, the running time of generating row instances is compared when changes. The time to generate maximal instances is used to indicate the time to generate row instances of the maximal instance algorithm, because once maximal instances are found, row instances are found. The result shows that the running time increases with an increase in and the maximal instance algorithm consumes less time. Figure 12 shows the effect of the number of spatial instances on the running time, and no matter how the number of spatial instances changes, the maximal instance algorithm still consumes less time. Obviously, the maximal instance algorithm has better performance in the process of generating prevalent co-locations since there is no need for join operations in the maximal instance algorithm. Therefore, it can be concluded that the maximal instance algorithm is more efficient than the three basic algorithms.
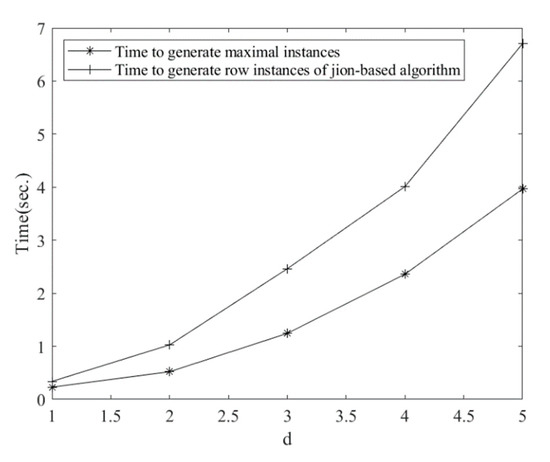
Figure 11.
The effect of on the running time.
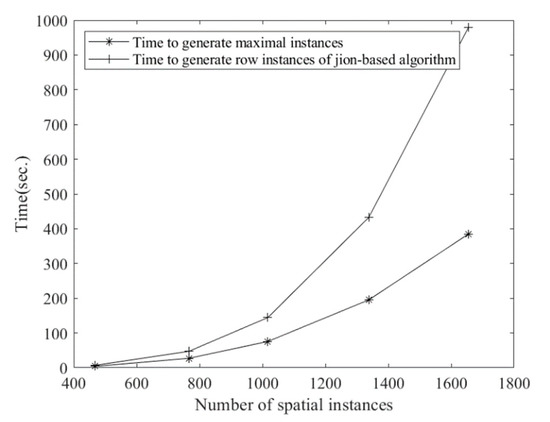
Figure 12.
The effect of the number of spatial instances on the running time.
4. Conclusions and Future Work
This paper proposes a new concept of maximal instances that is fundamental to our work and proves that generating row instances by maximal instances can make sense. A comparison with generating row instances by join operations proves that generating row instances by maximal instances is more efficient. An RI-tree is constructed to find maximal instances from a spatial data set. The proposed algorithm, the maximal instance algorithm, is based on maximal instances to mine co-location patterns. Since join operations are needed in this algorithm, it can reduce a lot of computing time. A detailed comparison with the three basic algorithms (join-based algorithm, partial-join algorithm, join-less algorithm) shows the advantage of our algorithm in terms of time consumption.
Synthetic data sets and a real data set are used to examine the effect of our algorithm. The real data set is about college and university locations, hospital locations, library locations, nursing home locations from Maine E911 address data from MainePUC, and point locations of the mineral collecting sites in Maine. This data set has five spatial feature types: college and university, hospital, library, nursing home, and mineral collecting site. The prevalent co-locations , , , , , and are generated when is set to 0.4 and is set to 0.5 ( , ). The participation indexes of the co-locations vary with a change in the experimental parameter and satisfy anti-monotonicity, and comparative experiments on running time show that the maximal instance algorithm has better performance.
Many application domains include spatio-temporal features. Scientists in these domains are interested in understanding the evolution of the co-location patterns among stationary features as well as co-location patterns over moving feature types. In future work, it will be interesting to explore methods to answer temporal questions such as how a co-location changes over time as well as methods to identify moving object co-location patterns.
Author Contributions
Conceptualization, G.Z.; methodology, Q.L.; software, Q.L.; validation, Q.L.; formal analysis, Q.L.; investigation, G.Z., Q.L. and G.D.; resources, G.Z.; data curation, Q.L.; writing—original draft preparation, Q.L.; writing—review and editing, G.Z. and G.D; visualization, Q.L.; supervision, G.Z. and G.D.; project administration, G.Z.; funding acquisition, G.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science of China under grant numbers 41431179 and 41961065; the Guangxi Innovative Development Grand Grant under grant numbers GuikeAA18118038 and GuikeAA18242048; and the National Key Research and Development Program of China under grant number 2016YFB0502501 and the BaGuiScholars Program of Guangxi.
Data Availability Statement
Data available in a publicly accessible repository.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Huang, Y.; Shekhar, S.; Xiong, H. Discovering colocation patterns from spatial data sets: A general approach. IEEE Trans. Knowl. Data Eng. 2004, 16, 1472–1485. [Google Scholar] [CrossRef]
- Shekhar, S.; Huang, Y. Discovering Spatial co-location patterns: A summary of results. In Advances in Spatial and Temporal Databases; Jensen, C.S., Schneider, M., Seeger, B., Tsotras, V.J., Eds.; Springer: Berlin/Heidelberg, Germany, 2001; p. 2121. [Google Scholar]
- Yoo, J.S.; Shekhar, S.; Smith, J.; Kumquat, J.P. A partial join approach for mining co-location patterns. In Proceedings of the 12th annual ACM international workshop on Geographic information systems—GIS ’04, Washington, DC, USA, 12–13 November 2004; pp. 241–249. [Google Scholar] [CrossRef]
- Yoo, J.S.; Shekhar, S.; Celik, M. A Join-Less Approach for Co-Location Pattern Mining: A Summary of Results. In Proceedings of the Fifth IEEE International Conference on Data Mining (ICDM’05), Houston, TX, USA, 27–30 November 2005; p. 4. [Google Scholar]
- Yoo, J.S.; Shekhar, S. A join-less approach for mining spatial co-location pattern. IEEE Trans. Knowl. Data Eng. 2006, 18, 1323–1337. [Google Scholar]
- Djenouri, Y.; Lin, J.C.-W.; Nørvåg, K.; Ramampiaro, H. Highly Efficient Pattern Mining Based on Transaction Decomposition. In Proceedings of the 2019 IEEE 35th International Conference on Data Engineering (ICDE), Macao, China, 8–11 April 2019; pp. 1646–1649. [Google Scholar]
- Zhang, B.; Lin, J.C.-W.; Shao, Y.; Fournier-Viger, P.; Djenouri, Y. Maintenance of Discovered High Average-Utility Itemsets in Dynamic Databases. Appl. Sci. 2018, 8, 769. [Google Scholar] [CrossRef]
- Huang, Y.; Pei, J.; Xiong, H. Mining Co-Location Patterns with Rare Events from Spatial Data Sets. GeoInformatica 2006, 10, 239–260. [Google Scholar] [CrossRef]
- Verhein, F.; Al-Naymat, G. Fast Mining of Complex Spatial Co-location Patterns Using GLIMIT. In Proceedings of the Seventh IEEE International Conference on Data Mining Workshops (ICDMW 2007), Omaha, NE, USA, 28–31 October 2007; pp. 679–684. [Google Scholar]
- Al-Naymat, G. Enumeration of maximal clique for mining spatial co-location patterns. In Proceedings of the 2008 IEEE/ACS International Conference on Computer Systems and Applications, Doha, Qatar, 31 March–4 April 2008; pp. 126–133. [Google Scholar]
- Kim, S.K.; Kim, Y.; Kim, U. Maximal cliques generating algorithm for spatial colocation pattern mining. In Secure and Trust Computing, Data Management and Applications; Park, J.J., Lopez, J., Yeo, S.S., Shon, T., Taniar, D., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; Volume 186, pp. 241–250. [Google Scholar]
- Yao, X.; Wang, D.; Peng, L.; Chi, T. An adaptive maximal co-location mining algorithm. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 5551–5554. [Google Scholar] [CrossRef]
- Deng, M.; Cai, J.; Liu, Q.; He, Z.; Tang, J. Multi-level method for discovery of regional co-location patterns. Int. J. Geogr. Inf. Sci. 2017, 31, 1–25. [Google Scholar] [CrossRef]
- Huang, Y.; Zhang, P.; Zhang, C. On the Relationships between Clustering and Spatial Co-Location Pattern Mining. Int. J. Artif. Intell. Tools 2008, 17, 55–70. [Google Scholar] [CrossRef]
- Jiamthapthaksin, R.; Eick, C.F.; Vilalta, R. A framework for multi-objective clustering and its application to co-location mining. In Advanced Data Mining and Applications; Huang, R., Yang, Q., Pei, J., Gama, J., Meng, X., Li, X., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5678, pp. 188–199. [Google Scholar]
- Yu, W. Identifying and Analyzing the Prevalent Regions of a Co-Location Pattern Using Polygons Clustering Approach. ISPRS Int. J. Geo-Infor. 2017, 6, 259. [Google Scholar] [CrossRef]
- Ouyang, Z.; Wang, L.; Wu, P. Spatial Co-Location Pattern Discovery from Fuzzy Objects. Int. J. Artif. Intell. Tools 2017, 26. [Google Scholar] [CrossRef]
- Zhou, G.; Wang, L. Co-location decision tree for enhancing decision-making of pavement maintenance and rehabilitation. Transp. Res. Part C: Emerg. Technol. 2012, 21, 287–305. [Google Scholar] [CrossRef]
- Zhou, G.; Zhang, R.; Zhang, D. Manifold Learning Co-Location Decision Tree for Remotely Sensed Imagery Classification. Remote Sens. 2016, 8, 855. [Google Scholar] [CrossRef]
- Zhou, G.; Li, Q.; Deng, G.; Yue, T.; Zhou, X. Mining Co-Location Patterns with Clustering Items from Spatial Data Sets. ISPRS-Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, XLII-3, 2505–2509. [Google Scholar] [CrossRef]
- Bao, X.; Wang, L. A clique-based approach for co-location pattern mining. Inf. Sci. 2019, 490, 244–264. [Google Scholar] [CrossRef]
- Celik, M.; Kang, J.M.; Shekhar, S. Zonal co-location pattern discovery with dynamic parameters. In Proceedings of the Seventh IEEE International Conference on Data Mining, Omaha, NE, USA, 28–31 October 2007. [Google Scholar]
- Jiang, Y.; Wang, L.; Chen, H. Discovering both positive and negative co-location rules from spatial data sets. Software Engi-neering and Data Mining (SEDM). In Proceedings of the 2010 2nd International Conference on IEEE, Chengdu, China, 23–25 June 2010. [Google Scholar]
- Yu, P. FP-Tree. based Spatial Co-Location Pattern Mining; University of North Texas: Denton, TX, USA, 2005. [Google Scholar]
- Agrawal, R.; Srikant, R. Fast algorithms for mining association rules. In Readings in Database Systems, 3rd ed.; Stonebraker, M., Hellerstein, J.M., Eds.; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1998; pp. 580–592. [Google Scholar]
- ArcGIS Hub. Available online: https://hub.arcgis.com/ (accessed on 20 February 2021).












Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).