
Few Shot Object Detection for SAR Images via Feature Enhancement and Dynamic Relationship Modeling



Abstract
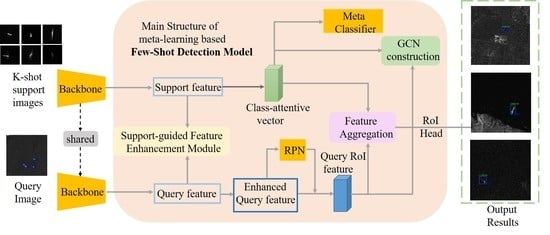
:
1. Introduction
1.1. Background
1.2. Related Work
1.3. Problems and Motivations
1.4. Contributions
2. Preliminaries
2.1. Problem Definition
2.2. Meta-Learning Structure
3. Proposed Methods
3.1. Overall Architecture
3.2. Attention Mechanism and Support-Guided Feature Enhancement
3.3. Class Attentive Vector and Feature Aggregation
3.4. GCN
3.5. Training Strategy
4. Experiments
4.1. Datasets
4.2. Implementation Details
4.3. Evaluation Metrics
- Set1: .
- Set2: .
- Set3: .
5. Results
5.1. Comparison of Results
5.2. Ablation Study
5.3. Visual Analysis
6. Discussions
6.1. Performance on Novel Classes
6.2. Adaptation Speed of Different Methods
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNN | Convolutional neural network |
| RPN | Region proposal network |
| RoI | Region of interest |
| mAP | Mean average precision |
| GCN | Graph convolution network |
References
- Xia, R.; Chen, J.; Huang, Z.; Wan, H.; Wu, B.; Sun, L.; Yao, B.; Xiang, H.; Xing, M. CRTransSar: A Visual Transformer Based on Contextual Joint Representation Learning for SAR Ship Detection. Remote Sens. 2022, 14, 1488. [Google Scholar] [CrossRef]
- Zhang, F.; Tianying, M.; Xiang, D.; Ma, F.; Sun, X.; Zhou, Y. Adversarial deception against SAR target recognition network. IEEE J. Select. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4507–4520. [Google Scholar] [CrossRef]
- Ao, W.; Xu, F.; Li, Y.; Wang, H. Detection and Discrimination of Ship Targets in Complex Background From Spaceborne ALOS-2 SAR Images. IEEE J. Select. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 536–550. [Google Scholar] [CrossRef]
- Zhang, H.; Lei, L.; Ni, W.; Tang, T.; Wu, J.; Xiang, D.; Kuang, G. Explore Better Network Framework for High-Resolution Optical and SAR Image Matching. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–18. [Google Scholar] [CrossRef]
- Robey, F.C.; Fuhrmann, D.R.; Kelly, E.J.; Nitzberg, R. A CFAR adaptive matched filter detector. IEEE Trans. Aerosp. Electron. Syst. 1992, 28, 208–216. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, Canada, 7–12 December 2015; Volume 28, pp. 91–99. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving Into High Quality Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Tang, J.; Cheng, J.; Xiang, D.; Hu, C. Large-Difference-Scale Target Detection Using a Revised Bhattacharyya Distance in SAR Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Zhao, C.; Fu, X.; Dong, J.; Qin, R.; Chang, J.; Lang, P. SAR Ship Detection Based on End-to-End Morphological Feature Pyramid Network. IEEE J. Select. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4599–4611. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhu, M.; Hu, G.; Zhou, H.; Wang, S. H2Det: A High-Speed and High-Accurate Ship Detector in SAR Images. IEEE J. Select. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 12455–12466. [Google Scholar] [CrossRef]
- Chen, S.; Zhan, R.; Wang, W.; Zhang, J. Learning Slimming SAR Ship Object Detector Through Network Pruning and Knowledge Distillation. IEEE J. Select. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 1267–1282. [Google Scholar] [CrossRef]
- Hu, Q.; Hu, S.; Liu, S. BANet: A Balance Attention Network for Anchor-Free Ship Detection in SAR Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Zhang, Y.; Cao, Y.; Feng, X.; Xie, M.; Li, X.; Xue, Y.; Qian, X. SAR Object Detection Encounters Deformed Complex Scenes and Aliased Scattered Power Distribution. IEEE J. Select. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4482–4495. [Google Scholar] [CrossRef]
- Ma, X.; Hou, S.; Wang, Y.; Wang, J.; Wang, H. Multiscale and Dense Ship Detection in SAR Images Based on Key-Point Estimation and Attention Mechanism. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Cui, Z.; Wang, X.; Liu, N.; Cao, Z.; Yang, J. Ship Detection in Large-Scale SAR Images Via Spatial Shuffle-Group Enhance Attention. IEEE Trans. Geosci. Remote Sens. 2021, 59, 379–391. [Google Scholar] [CrossRef]
- Yan, X.; Chen, Z.; Xu, A.; Wang, X.; Liang, X.; Lin, L. Meta r-cnn: Towards general solver for instance-level low-shot learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9577–9586. [Google Scholar]
- Wang, Y.X.; Ramanan, D.; Hebert, M. Meta-Learning to Detect Rare Objects. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9924–9933. [Google Scholar] [CrossRef]
- Wang, X.; Huang, T.E.; Darrell, T.; Gonzalez, J.E.; Yu, F. Frustratingly simple few-shot object detection. arXiv 2020, arXiv:2003.06957. [Google Scholar]
- Wu, J.; Liu, S.; Huang, D.; Wang, Y. Multi-scale positive sample refinement for few-shot object detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany; pp. 456–472. [Google Scholar]
- Li, A.; Li, Z. Transformation Invariant Few-Shot Object Detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Online. 20–25 June 2021; pp. 3093–3101. [Google Scholar] [CrossRef]
- Shi, J.; Jiang, Z.; Zhang, H. Few-Shot Ship Classification in Optical Remote Sensing Images Using Nearest Neighbor Prototype Representation. IEEE J. Select. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3581–3590. [Google Scholar] [CrossRef]
- Yang, M.; Bai, X.; Wang, L.; Zhou, F. Mixed Loss Graph Attention Network for Few-Shot SAR Target Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Fu, K.; Zhang, T.; Zhang, Y.; Wang, Z.; Sun, X. Few-shot SAR target classification via metalearning. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Li, X.; Deng, J.; Fang, Y. Few-Shot Object Detection on Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Kang, B.; Liu, Z.; Wang, X.; Yu, F.; Feng, J.; Darrell, T. Few-Shot Object Detection via Feature Reweighting. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 8419–8428. [Google Scholar] [CrossRef]
- Cheng, G.; Yan, B.; Shi, P.; Li, K.; Yao, X.; Guo, L.; Han, J. Prototype-CNN for few-shot object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–10. [Google Scholar] [CrossRef]
- Zhao, Z.; Tang, P.; Zhao, L.; Zhang, Z. Few-Shot Object Detection of Remote Sensing Images via Two-Stage Fine-Tuning. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Zhou, Y.; Hu, H.; Zhao, J.; Zhu, H.; Yao, R.; Du, W. Few-shot Object Detection via Context-aware Aggregation for Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Huang, X.; He, B.; Tong, M.; Wang, D.; He, C. Few-Shot Object Detection on Remote Sensing Images via Shared Attention Module and Balanced Fine-Tuning Strategy. Remote Sens. 2021, 13, 3816. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Fan, Q.; Zhuo, W.; Tang, C.K.; Tai, Y.W. Few-shot object detection with attention-RPN and multi-relation detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 16–18 June 2020; pp. 4013–4022. [Google Scholar]
- Chen, Y.; Dai, X.; Liu, M.; Chen, D.; Yuan, L.; Liu, Z. Dynamic Convolution: Attention Over Convolution Kernels. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Washington, DC, USA, 16–18 June 2020; pp. 11027–11036. [Google Scholar] [CrossRef]
- Xiao, Y.; Marlet, R. Few-shot object detection and viewpoint estimation for objects in the wild. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 192–210. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Kim, G.; Jung, H.G.; Lee, S.W. Few-Shot Object Detection via Knowledge Transfer. In Proceedings of the 2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Singapore, 8–10 February 2020; pp. 3564–3569. [Google Scholar] [CrossRef]
- Ranasinghe, K.; Naseer, M.; Hayat, M.; Khan, S.; Khan, F.S. Orthogonal projection loss. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Online. 20–25 June 2021; pp. 12333–12343. [Google Scholar]
- Hou, X.; Ao, W.; Song, Q.; Lai, J.; Wang, H.; Xu, F. FUSAR-Ship: Building a high-resolution SAR-AIS matchup dataset of Gaofen-3 for ship detection and recognition. Sci. China Inf. Sci. 2020, 63, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Xian, S.; Zhirui, W.; Yuanrui, S.; Wenhui, D.; Yue, Z.; Kun, F. AIR-SARShip-1.0: High-resolution SAR ship detection dataset. J. Radars 2019, 8, 852–862. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class Name | Cargo | Dredger | Fishing | HighSpeedCraft | LawEnforce | Other | Passenger | Reserved | Tanker | Tug | Unspecified |
| Class Index | C01 | C03 | C04 | C05 | C06 | C07 | C08 | C10 | C12 | C13 | C14 |
| Object Number | 867 | 138 | 243 | 36 | 68 | 448 | 61 | 71 | 214 | 51 | 111 |
| Split | Novel Classes | Base Classes | |||
|---|---|---|---|---|---|
| 1 | Law Enforce(C06) | Passenger(C08) | Reserved(C10) | Tug(C13) | rest |
| 2 | Fishing(C04) | Tanker(C12) | Reserved(C10) | High Speed Craft(C05) | rest |
| 3 | Dredger(C03) | Tug(C13) | Law Enforce(C06) | High Speed Craft(C05) | rest |
| Methods | Set1 | Set2 | Set3 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 10 | 5 | 3 | 10 | 5 | 3 | 10 | 5 | 3 | |
| MetaRCNN | 0.350 | 0.337 | 0.266 | 0.282 | 0.255 | 0.228 | 0.435 | 0.293 | 0.291 |
| FsdetView | 0.317 | 0.272 | 0.235 | 0.297 | 0.248 | 0.211 | 0.393 | 0.325 | 0.318 |
| TFA | 0.254 | 0.188 | 0.199 | 0.235 | 0.256 | 0.194 | 0.401 | 0.230 | 0.277 |
| FSCE | 0.355 | 0.229 | 0.260 | 0.276 | 0.236 | 0.185 | 0.413 | 0.272 | 0.283 |
| MPSR | 0.363 | 0.341 | 0.353 | 0.211 | 0.241 | 0.196 | 0.433 | 0.378 | 0.332 |
| Ours | 0.396 | 0.336 | 0.300 | 0.322 | 0.282 | 0.258 | 0.484 | 0.349 | 0.339 |
| Method | Attention | Dynamic Conv | GCN | Loss Constraint | |||
|---|---|---|---|---|---|---|---|
| FsdetView | - | - | - | - | 0.5562 | 0.3168 | 0.4692 |
| RelationGCN(Ours) | ✓ | 0.5489 | 0.3598 | 0.4802 | |||
| ✓ | ✓ | 0.5496 | 0.3829 | 0.4890 | |||
| ✓ | 0.5652 | 0.3616 | 0.4912 | ||||
| ✓ | ✓ | ✓ | 0.5710 | 0.3719 | 0.4986 | ||
| ✓ | ✓ | ✓ | ✓ | 0.5858 | 0.3959 | 0.5168 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.; Zhang, J.; Zhan, R.; Zhu, R.; Wang, W. Few Shot Object Detection for SAR Images via Feature Enhancement and Dynamic Relationship Modeling. Remote Sens. 2022, 14, 3669. https://doi.org/10.3390/rs14153669
Chen S, Zhang J, Zhan R, Zhu R, Wang W. Few Shot Object Detection for SAR Images via Feature Enhancement and Dynamic Relationship Modeling. Remote Sensing. 2022; 14(15):3669. https://doi.org/10.3390/rs14153669
Chicago/Turabian StyleChen, Shiqi, Jun Zhang, Ronghui Zhan, Rongqiang Zhu, and Wei Wang. 2022. "Few Shot Object Detection for SAR Images via Feature Enhancement and Dynamic Relationship Modeling" Remote Sensing 14, no. 15: 3669. https://doi.org/10.3390/rs14153669
APA StyleChen, S., Zhang, J., Zhan, R., Zhu, R., & Wang, W. (2022). Few Shot Object Detection for SAR Images via Feature Enhancement and Dynamic Relationship Modeling. Remote Sensing, 14(15), 3669. https://doi.org/10.3390/rs14153669