
Bidirectional Flow Decision Tree for Reliable Remote Sensing Image Scene Classification




Abstract
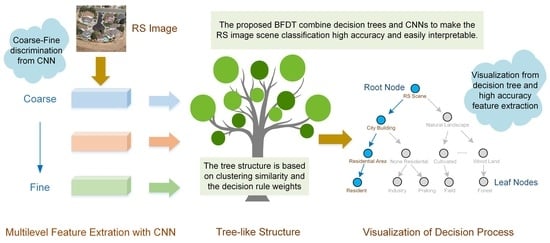
:
1. Introduction
- To preserve interpretability and achieve competitive accuracy, we integrate the decision tree model into the CNNs and train it with the cascaded softmax loss to sufficiently mine RS images’ scene structures and essential visual features. The proposed method can learn more interpretable features instead of explaining pretrained neural networks.
- We efficiently incorporate the high performance of the bottom-up mode and the strong interpretability of the top-down manner while constructing semantic and layer-based visual remote sensing image hierarchies. Thus, it can capture the hierarchical structure of images from remote sensing and make visual decisions based on them. In addition, to the best of our knowledge, this work provides the first bidirectional feature-flow decision tree, which provides a reliable RSISC.
- The proposed framework has a degree of attribute discrimination that fully utilizes the decision tree’s decision-making advantages. Moreover, it provides joint improvement of accuracy and interpretability.
2. Related Work
2.1. Conventional CNN Features-Based Methods
2.2. The Deep Learning Interpretable Method
2.3. The Deep Learning Methods in RSISC
3. Methods
3.1. Overall Architecture
3.2. Feature Extraction
3.3. Decision Rules and Process
3.3.1. Generating the Decision Path
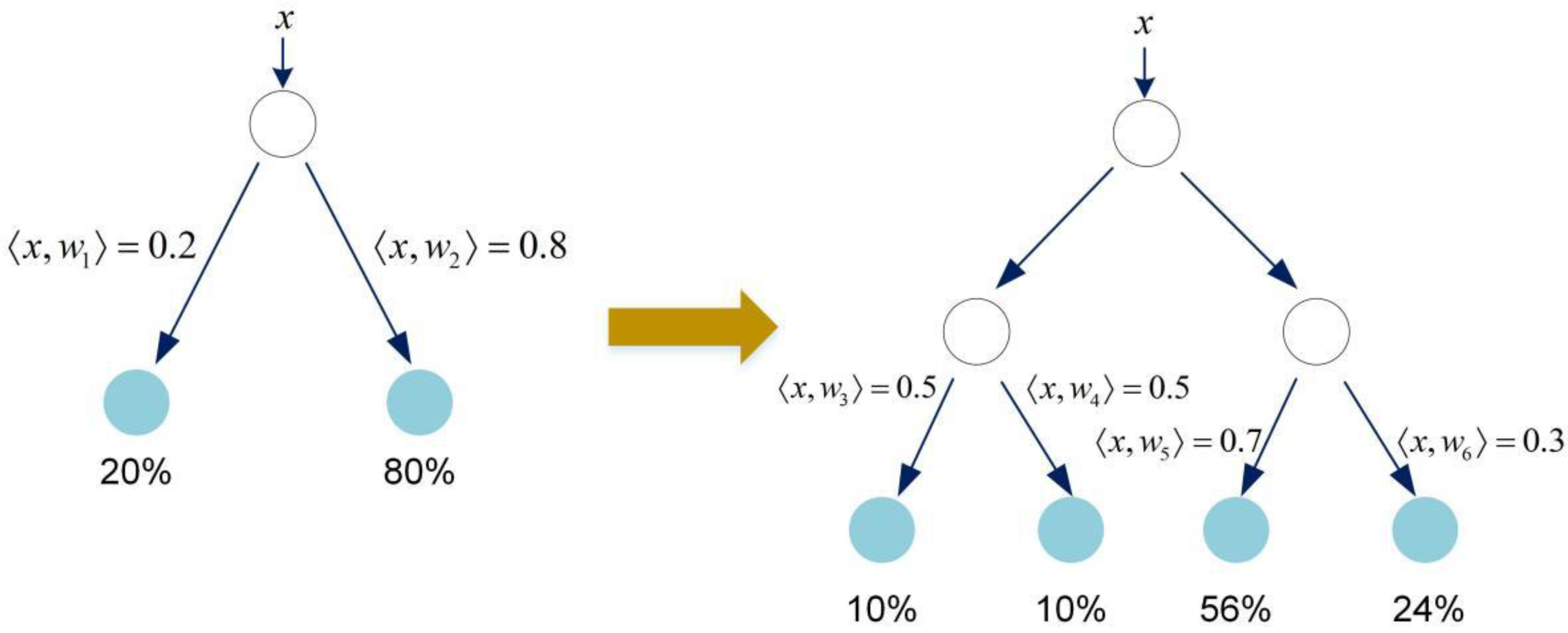
3.3.2. Decision Rule Weights
3.3.3. Node Probabilities
3.3.4. Leaf Picking
3.3.5. Loss Function
3.4. Learning Procedure
| Algorithm 1 BFDT Train |
| Input: RS Image Samples, Pre-trained CNN, T (a pre-defined hierarchy structure) Output: An BFDT model. 1: Let K be the number of samples and l indicate the level index; 2: for each l-th level in pretrained CNN do 3: for each image sample k ∈ {1, …, K} do 4: Adopt GAP to squeeze out the spatial dimensions. 5: end for 6: Adopt LDA to reduce dimension. 7: Update W, Sb, Sw by maximizing Equation (1). 8: end for 9: for each row in T do 10: Project all original features to the lower-dimensional subspace. 11: Generate nodes with k-means by Equations (4)–(6). 12: Seed decision rule weights from the pretrained CNN by Equation (7). 13: Compute node probabilities by Equation (8). 14: end for 15: Fine-tuning the BFDT model with tree supervision loss by Equation (11). |
4. Experimental Results
4.1. Datasets
- RSSCN7: The RSSCN7 dataset [33] was established by Zou, Q et al. of Wuhan University in 2015. These images are from 7 specific scene categories: lakes, meadows, forests, farmland, lots, industrial areas, residential areas, and rivers and parking. Each scene consists of 400 images of 400 × 400 pixels, with four different scales for each category and 100 samples for each scale. Some sample images are shown in Figure 6. This paper uses training ratios of 20% and 50%, and the remaining values are used for testing.
- AID: The Aerial Image dataset [34] was established by Xia et al. of Wuhan University in 2017, cropped and corrected at 600 × 600 pixels from Google Earth imagery. The dataset consists of 30 scenes with 200 to 400 images per class, and the spatial resolution of each class ranges from 0.8 m to 0.5 m. Some sample images are shown in Figure 7. As above, 20% and 50% are used as the training ratios, and the rest are used as tests.
- NWPU: The NWPU-RESISC45 dataset [35] was published by Northwestern Polytechnic University and was obtained from Google Earth. The dataset comprises 45 scenes with 700 images per scene, totaling 31,500 samples. The image size is 256 × 256, and the pixel resolution varies from 30 to 0.2 m. This dataset is the largest in scene classes and the total number of images. Therefore, it contains richer image variation, greater internal diversity, and higher interclass similarity than the other datasets considered. Some sample images are shown in Figure 8. We utilize the training ratio of 20% and the remaining 80% as test data.
4.2. Evaluation Metrics
- Overall accuracy represents the ratio of correctly classified samples in the test set to the total number of samples and demonstrates the classification performance of the entire test dataset. It is common to see how well a scene classification method works in RS images.
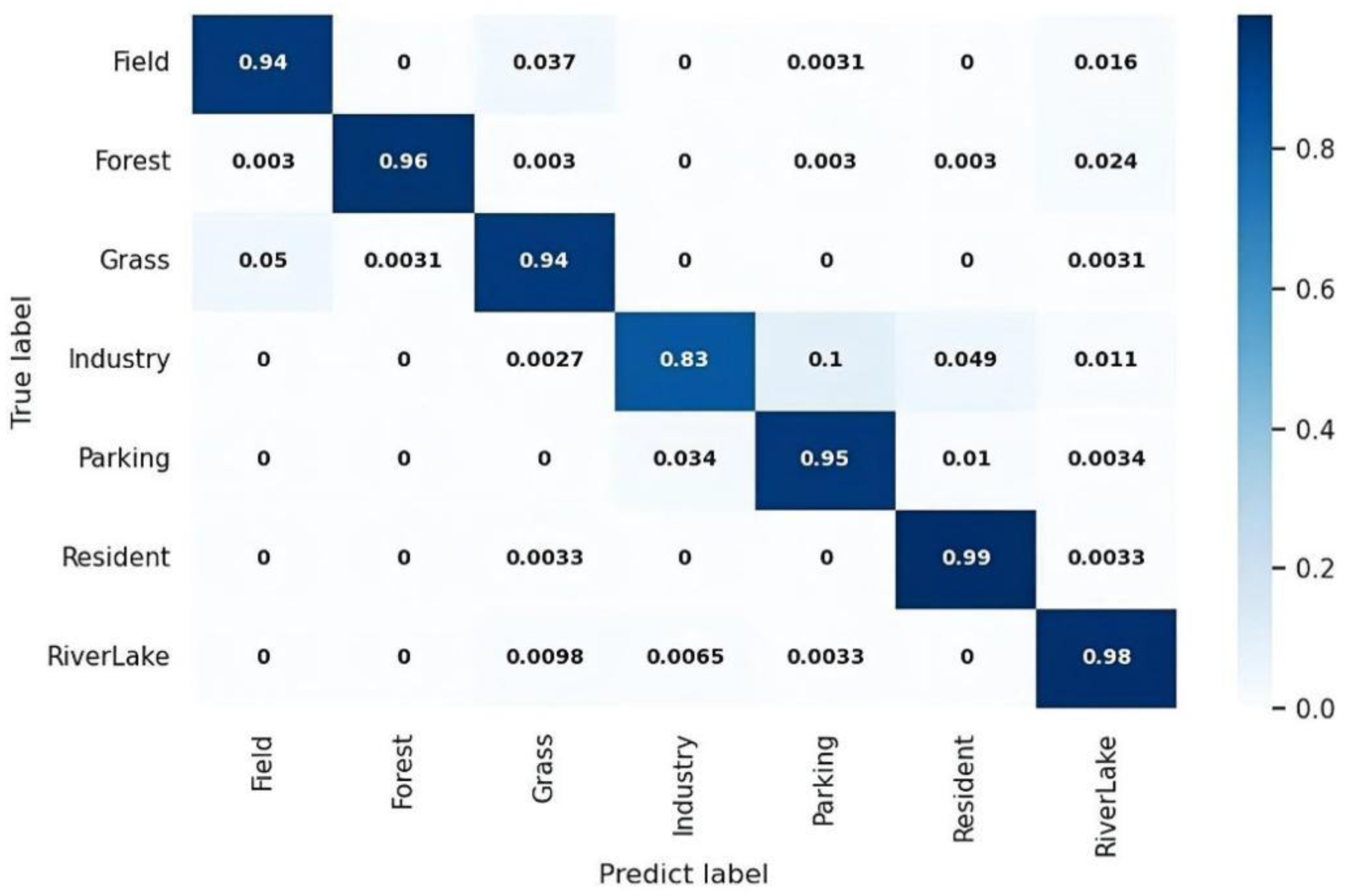
- The confusion matrix visualizes and summarizes the performance of a classification algorithm. It is an N × N squared matrix where N denotes the number of classes under consideration. Note that we used the normalized values and that the values on each row sum up to 1.
4.3. Experimental Settings
4.4. The Performance of the Proposed Method
4.4.1. Results on RSSCN7
4.4.2. Results on AID
4.4.3. Results on NWPU-RESISC45
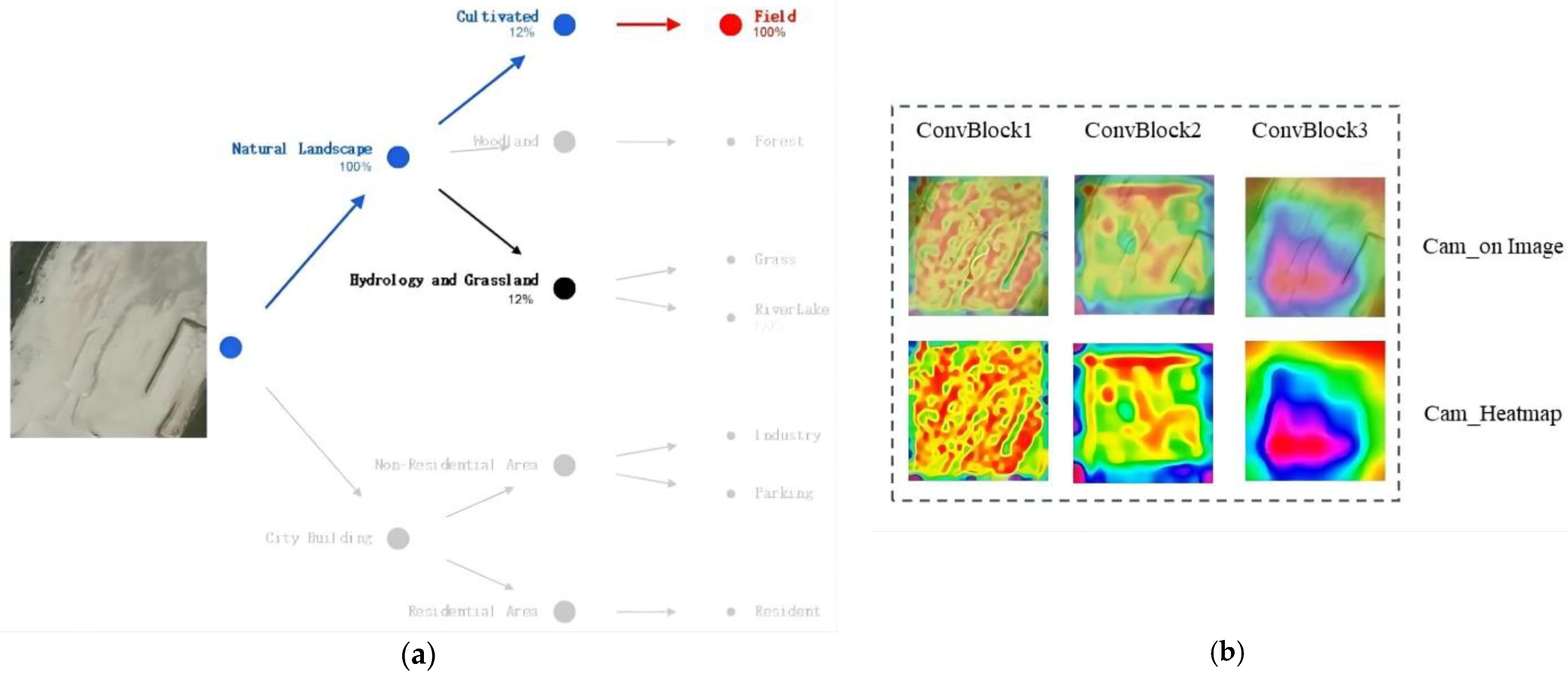
4.5. Reliability with Tree Traversal
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, L.; Zhang, L.; Du, B. Deep Learning for Remote Sensing Data: A Technical Tutorial on the State of the Art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Lv, Z.Y.; Shi, W.; Zhang, X.; Benediktsson, J.A. Landslide Inventory Mapping from Bitemporal High-Resolution Remote Sensing Images Using Change Detection and Multiscale Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1520–1532. [Google Scholar] [CrossRef]
- Longbotham, N.; Chaapel, C.; Bleiler, L.; Padwick, C.; Emery, W.J.; Pacifici, F. Very High Resolution Multiangle Urban Classification Analysis. IEEE Trans. Geosci. Remote Sens. 2012, 50, 1155–1170. [Google Scholar] [CrossRef]
- Huang, X.; Wen, D.; Li, J.; Qin, R. Multi-Level Monitoring of Subtle Urban Changes for the Megacities of China Using High-Resolution Multi-View Satellite Imagery. Remote Sens. Environ. 2017, 196, 56–75. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Risojević, V.; Babić, Z. Fusion of Global and Local Descriptors for Remote Sensing Image Classification. IEEE Geosci. Remote Sens. Lett. 2013, 10, 836–840. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution Gray-Scale and Rotation Invariant Texture Classification with Local Binary Patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Liu, N.; Wan, L.; Zhang, Y.; Zhou, T.; Huo, H.; Fang, T. Exploiting Convolutional Neural Networks with Deeply Local Description for Remote Sensing Image Classification. IEEE Access 2018, 6, 11215–11228. [Google Scholar] [CrossRef]
- Boualleg, Y.; Farah, M.; Farah, I.R. Remote Sensing Scene Classification Using Convolutional Features and Deep Forest Classifier. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1944–1948. [Google Scholar] [CrossRef]
- Cheng, G.; Ma, C.; Zhou, P.; Yao, X.; Han, J. Scene Classification of High Resolution Remote Sensing Images Using Convolutional Neural Networks. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 767–770. [Google Scholar]
- Hariharan, B.; Arbelaez, P.; Girshick, R.; Malik, J. Hypercolumns for Object Segmentation and Fine-Grained Localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 447–456. [Google Scholar]
- Zhu, Q.; Zhong, Y.; Zhang, L.; Li, D. Adaptive Deep Sparse Semantic Modeling Framework for High Spatial Resolution Image Scene Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6180–6195. [Google Scholar] [CrossRef]
- Minetto, R.; Pamplona Segundo, M.; Sarkar, S. Hydra: An Ensemble of Convolutional Neural Networks for Geospatial Land Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6530–6541. [Google Scholar] [CrossRef]
- He, N.; Fang, L.; Li, S.; Plaza, A.; Plaza, J. Remote Sensing Scene Classification Using Multilayer Stacked Covariance Pooling. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6899–6910. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, Y.; Ding, L. Scene Classification Based on Two-Stage Deep Feature Fusion. IEEE Geosci. Remote Sens. Lett. 2018, 15, 183–186. [Google Scholar] [CrossRef]
- Goel, A.; Banerjee, B.; Pižurica, A. Hierarchical Metric Learning for Optical Remote Sensing Scene Categorization. IEEE Geosci. Remote Sens. Lett. 2019, 16, 952–956. [Google Scholar] [CrossRef]
- Zhang, X.; Tan, X.; Chen, G.; Zhu, K.; Liao, P.; Wang, T. Object-Based Classification Framework of Remote Sensing Images with Graph Convolutional Networks. IEEE Geosci. Remote Sens. Lett. 2022, 19, 8010905. [Google Scholar] [CrossRef]
- Xu, C.; Zhu, G.; Shu, J. A Lightweight and Robust Lie Group-Convolutional Neural Networks Joint Representation for Remote Sensing Scene Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5501415. [Google Scholar] [CrossRef]
- Huang, S.; Zhang, H.; Pižurica, A. Subspace Clustering for Hyperspectral Images via Dictionary Learning with Adaptive Regularization. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5524017. [Google Scholar] [CrossRef]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2016), Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Song, W.; Dai, S.; Wang, J.; Huang, D.; Liotta, A.; Di Fatta, G. Bi-Gradient Verification for Grad-CAM Towards Accurate Visual Explanation for Remote Sensing Images. In Proceedings of the 2019 International Conference on Data Mining Workshops (ICDMW), Beijing, China, 8–11 November 2019; pp. 473–479. [Google Scholar]
- Huang, X.; Sun, Y.; Feng, S.; Ye, Y.; Li, X. Better Visual Interpretation for Remote Sensing Scene Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6504305. [Google Scholar] [CrossRef]
- Song, W.; Dai, S.; Huang, D.; Song, J.; Antonio, L. Median-Pooling Grad-CAM: An Efficient Inference Level Visual Explanation for CNN Networks in Remote Sensing Image Classification. In MultiMedia Modeling; Lokoč, J., Skopal, T., Schoeffmann, K., Mezaris, V., Li, X., Vrochidis, S., Patras, I., Eds.; Springer: Cham, Switzerland, 2021; pp. 134–146. [Google Scholar]
- Zhao, X.M.; Wu, J.; Chen, R.X. RMFS-CNN: New deep learning framework for remote sensing image classification. J. Image Graph. 2021, 26, 297–304. [Google Scholar]
- Wan, A.; Dunlap, L.; Ho, D.; Yin, J.; Lee, S.; Jin, H.; Petryk, S.; Bargal, S.A.; Gonzalez, J.E. NBDT: Neural-Backed Decision Trees. arXiv 2021, arXiv:2004.00221. [Google Scholar]
- Song, J.; Zhang, H.; Wang, X.; Xue, M.; Chen, Y.; Sun, L.; Tao, D.; Song, M. Tree-like Decision Distillation. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13483–13492. [Google Scholar]
- Xia, J.; Ghamisi, P.; Yokoya, N.; Iwasaki, A. Random Forest Ensembles and Extended Multiextinction Profiles for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 202–216. [Google Scholar] [CrossRef]
- Rasti, B.; Hong, D.; Hang, R.; Ghamisi, P.; Kang, X.; Chanussot, J.; Benediktsson, J.A. Feature Extraction for Hyperspectral Imagery: The Evolution from Shallow to Deep: Overview and Toolbox. IEEE Geosci. Remote Sens. Mag. 2020, 8, 60–88. [Google Scholar] [CrossRef]
- Shah, C.; Du, Q.; Xu, Y. Enhanced TabNet: Attentive Interpretable Tabular Learning for Hyperspectral Image Classification. Remote Sens. 2022, 14, 716. [Google Scholar] [CrossRef]
- Hehn, T.M.; Kooij, J.F.P.; Hamprecht, F.A. End-to-End Learning of Decision Trees and Forests. Int. J. Comput. Vis. 2020, 128, 997–1011. [Google Scholar] [CrossRef]
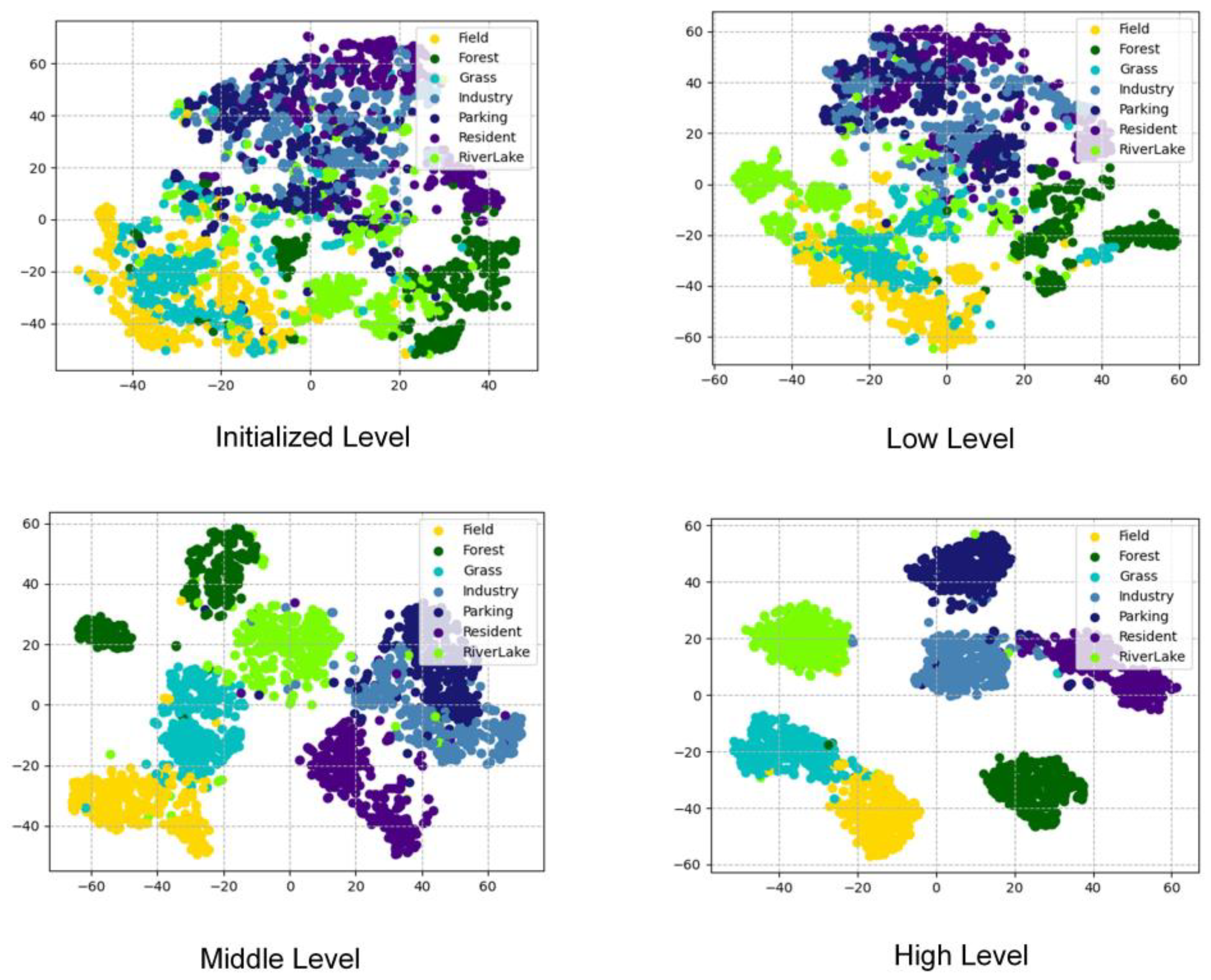
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Zou, Q.; Ni, L.; Zhang, T.; Wang, Q. Deep Learning Based Feature Selection for Remote Sensing Scene Classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2321–2325. [Google Scholar] [CrossRef]
- Xia, G.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE T Rans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Lu, X. Remote Sensing Image Scene Classification: Benchmark and State of the Art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Anwer, R.M.; Khan, F.S.; van de Weijer, J.; Molinier, M.; Laaksonen, J. Binary patterns encoded convolutional neural networks for texture recognition and remote sensing scene classification. ISPRS J. Photogramm. Remote Sens. 2018, 138, 74–85. Available online: https://pii/S0924271618300285?casa_token=WbStiLhZHHYAAAAA:waKmzyCNmAbBKAJVvR2CiLeTIhdtLKVzR66qXkzeQMAaMK7zJILfWd2AGWH3OFkLvIZ63yFXX3dr (accessed on 24 April 2022). [CrossRef]
- Wang, X.; Duan, L.; Ning, C.; Zhou, H. Relation-Attention Networks for Remote Sensing Scene Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 422–439. [Google Scholar] [CrossRef]
- Zhang, W.; Tang, P.; Zhao, L. Remote Sensing Image Scene Classification Using CNN-CapsNet. Remote Sens. 2019, 11, 494. [Google Scholar] [CrossRef]
- Zhang, G.; Xu, W.; Zhao, W.; Huang, C.; Yk, E.N.; Chen, Y.; Su, J. A Multiscale Attention Network for Remote Sensing Scene Images Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 9530–9545. [Google Scholar] [CrossRef]
- Wang, Q.; Liu, S.; Chanussot, J.; Li, X. Scene Classification with Recurrent Attention of VHR Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1155–1167. [Google Scholar] [CrossRef]
- Zhang, B.; Zhang, Y.; Wang, S. A Lightweight and Discriminative Model for Remote Sensing Scene Classification with Multidilation Pooling Module. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2636–2653. [Google Scholar] [CrossRef]
- Alhichri, H.; Alswayed, A.S.; Bazi, Y.; Ammour, N.; Alajlan, N.A. Classification of Remote Sensing Images Using EfficientNet-B3 CNN Model with Attention. IEEE Access 2021, 9, 14078–14094. [Google Scholar] [CrossRef]
- Wang, Q.; Huang, W.; Xiong, Z.; Li, X. Looking Closer at the Scene: Multiscale Representation Learning for Remote Sensing Image Scene Classification. IEEE Trans. Neural Netw. Learn. Syst. 2020, 33, 1414–1428. [Google Scholar] [CrossRef] [PubMed]
- Sun, H.; Lin, Y.; Zou, Q.; Song, S.; Fang, J.; Yu, H. Convolutional Neural Networks Based Remote Sensing Scene Classification Under Clear and Cloudy Environments. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 713–720. [Google Scholar]
- Shen, J.; Zhang, C.; Zheng, Y.; Wang, R. Decision-Level Fusion with a Pluginable Importance Factor Generator for Remote Sensing Image Scene Classification. Remote Sens. 2021, 13, 3579. [Google Scholar] [CrossRef]
- Liu, M.; Jiao, L.; Liu, X.; Li, L.; Liu, F.; Yang, S. C-CNN: Contourlet Convolutional Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 2636–2649. [Google Scholar] [CrossRef] [PubMed]
- Gao, Y.; Shi, J.; Li, J.; Wang, R. Remote sensing scene classification with dual attention-aware network. In Proceedings of the 2020 IEEE 5th International Conference on Image, Vision and Computing (ICIVC), Beijing, China, 10–12 July 2020; pp. 171–175. [Google Scholar]
- Shi, C.; Wang, T.; Wang, L. Branch Feature Fusion Convolution Network for Remote Sensing Scene Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5194–5210. [Google Scholar] [CrossRef]
- Deng, P.; Xu, K.; Huang, H. CNN-GCN-based dual-stream network for scene classification of remote sensing images. Natl. Remote Sens. Bull. 2021, 11, 2270–2282. [Google Scholar]
- Li, W.; Chen, K.; Chen, H.; Shi, Z. Geographical Knowledge-Driven Representation Learning for Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5405516. [Google Scholar] [CrossRef]
- Gao, L.; Li, N.; Li, L. Low-Rank Nonlocal Representation for Remote Sensing Scene Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 8006905. [Google Scholar] [CrossRef]
- He, N.; Fang, L.; Li, S.; Plaza, J.; Plaza, A. Skip-Connected Covariance Network for Remote Sensing Scene Classification. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 1461–1474. [Google Scholar] [CrossRef]
- Ji, J.; Zhang, T.; Jiang, L.; Zhong, W.; Xiong, H. Combining Multilevel Features for Remote Sensing Image Scene Classification with Attention Model. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1647–1651. [Google Scholar] [CrossRef]
- Shi, C.; Zhang, X.; Wang, L. A Lightweight Convolutional Neural Network Based on Channel Multi-Group Fusion for Remote Sensing Scene Classification. Remote Sens. 2021, 14, 9. [Google Scholar] [CrossRef]
- Wang, D.; Lan, J. A Deformable Convolutional Neural Network with Spatial-Channel Attention for Remote Sensing Scene Classification. Remote Sens. 2021, 13, 5076. [Google Scholar] [CrossRef]
- Li, B.; Guo, Y.; Yang, J.; Wang, L.; Wang, Y.; An, W. Gated Recurrent Multiattention Network for VHR Remote Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5606113. [Google Scholar] [CrossRef]
- Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When Deep Learning Meets Metric Learning: Remote Sensing Image Scene Classification via Learning Discriminative CNNs. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2811–2821. [Google Scholar] [CrossRef]
- Wang, S.; Guan, Y.; Shao, L. Multi-Granularity Canonical Appearance Pooling for Remote Sensing Scene Classification. IEEE Trans. Image Process. 2020, 29, 5396–5407. [Google Scholar] [CrossRef]
- Yuan, Z.; Lin, C. Research on Strong Constraint Self-Training Algorithm and Applied to Remote Sensing Image Classification. In Proceedings of the 2021 IEEE International Conference on Power Electronics, Computer Applications (ICPECA), Shenyang, China, 22–24 January 2021; pp. 981–985. [Google Scholar]
- Zhou, Y.; Liu, X.; Zhao, J.; Ma, D.; Yao, R.; Liu, B.; Zheng, Y. Remote sensing scene classification based on rotation-invariant feature learning and joint decision making. EURASIP J. Image Video Process. 2019, 2019, 3. [Google Scholar] [CrossRef]
- Belhumeur, P.N.; Hespanha, J.P.; Kriegman, D.J. Eigenfaces vs. Fisherfaces: Recognition Using Class Specific Linear Projection. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 711–720. [Google Scholar] [CrossRef]
- Hotelling, H. Analysis of a Complex of Statistical Variables into Principal Components. J. Educ. Psychol. 1933, 24, 417–441. [Google Scholar] [CrossRef]
- Momeni Pour, A.; Seyedarabi, H.; Abbasi Jahromi, S.H.; Javadzadeh, A. Automatic Detection and Monitoring of Diabetic Retinopathy Using Efficient Convolutional Neural Networks and Contrast Limited Adaptive Histogram Equalization. IEEE Access 2020, 8, 136668–136673. [Google Scholar] [CrossRef]
- Cao, R.; Fang, L.; Lu, T.; He, N. Self-Attention-Based Deep Feature Fusion for Remote Sensing Scene Classification. IEEE Geosci. Remote Sens. Lett. 2021, 18, 43–47. [Google Scholar] [CrossRef]
- Guo, X.; Hou, B.; Ren, B.; Ren, Z.; Jiao, L. Network Pruning for Remote Sensing Images Classification Based on Interpretable CNNs. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5605615. [Google Scholar] [CrossRef]
- Shi, C.; Zhao, X.; Wang, L. A Multi-Branch Feature Fusion Strategy Based on an Attention Mechanism for Remote Sensing Image Scene Classification. Remote Sens. 2021, 13, 1950. [Google Scholar] [CrossRef]
- Dumitru, C.O.; Schwarz, G.; Datcu, M. Land Cover Semantic Annotation Derived from High-Resolution SAR Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 2215–2232. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbols | Descriptions |
|---|---|
| N | The categories in a dataset |
| The features extracted from the m-th image in the n-th classification category | |
| The intraclass scatter matrix | |
| The interclass scatter matrix | |
| The averages of feature vectors from the i-th and all categories | |
| M, N | N categories in the RSISC task, and each with M-associated training images |
| SSE | The sum of squared errors |
| , | The i-th cluster and the cluster’s center |
| The i-th node in the decision tree | |
| The weights of the node | |
| L(i) | |
| The probability that node i traverses to the next node on the path to class n | |
| y | The ground truth labels |
| Datasets | Number of Scene Classes | Number of Samples per Class | Total Number of Images | Spatial Resolution | Image Size |
|---|---|---|---|---|---|
| RSSCN7 | 7 | 400 | 2800 | - | 400 × 400 |
| AID | 30 | 200–400 | 10,000 | 0.5–0.8 | 600 × 600 |
| NWPU45 | 45 | 700 | 31,500 | 0.2–30 | 256 × 256 |
| Datasets | Train | Test |
|---|---|---|
| RSSCN7 | 20%/50% | 80%/50% |
| AID | 20%/50% | 80%/50% |
| NWPU45 | 20% | 80% |
| Methods | Year | Training Ratio | |
|---|---|---|---|
| 20% | 50% | ||
| TEX-Net-LF [36] | 2018 | 92.45 ± 0.45 | 94.0 ± 0.57 |
| Fine-tune MobileNet V2 [41] | 2019 | 89.04 ± 0.17 | 92.46 ± 0.66 |
| SE-MDPMNet [41] | 2019 | 92.65 ± 0.13 | 94.71 ± 0.15 |
| Dual Attention-aware features [47] | 2020 | 91.07 ± 0.65 | 93.25 ± 0.28 |
| LCNN-BFF [48] | 2020 | - | 94.64 ± 0.21 |
| Contourlet CNN [46] | 2020 | - | 95.54 ± 0.71 |
| ResNet18 (global + local) [43] | 2020 | 93.89 ± 0.52 | 96.04 ± 0.68 |
| CGDSN [49] | 2021 | - | 95.46 ± 0.18 |
| DLFP [45] | 2021 | - | 95.49 ± 0.55 |
| GLNet (VGG) [44] | 2021 | - | 95.07 |
| GeoKR(ResNet50) [50] | 2021 | 89.33 | 91.52 |
| EfficientNetB3-Basic [42] | 2021 | 92.06 ± 0.39 | 94.39 ± 0.10 |
| EfficientNetB3-Attn-2 [42] | 2021 | 93.30 ± 0.19 | 96.17 ± 0.23 |
| LNR-ResNet50 [51] | 2022 | - | 96.8 ± 0.32 |
| BDFT (ResNet50) | 2022 | 94.11 | 96.50 |
| BDFT (AlexNet) | 2022 | 92.71 | 93.54 |
| BDFT (ResNet18) | 2022 | 95.15 ± 0.41 | 97.05 ± 0.35 |
| Methods | Year | Training Ratio | |
|---|---|---|---|
| 20% | 50% | ||
| TEX-Net-LF [36] | 2018 | 93.81 ± 0.12 | 95.73 ± 0.0.16 |
| ARCNet-VGG16 [40] | 2019 | 88.75 ± 0.40 | 93.10 ± 0.55 |
| SCCov [52] | 2019 | 93.12 ± 0.25 | 96.10 ± 0.16 |
| CNN-CapsNet [38] | 2019 | 93.60 ± 0.12 | 96.66 ± 0.11 |
| Dual Attention-aware [47] | 2020 | 94.36 ± 0.54 | 95.53 ± 0.30 |
| Contourlet CNN [46] | 2020 | - | 95.54 ± 0.71 |
| ResNet18(global + local) [43] | 2020 | 93.89 ± 0.52 | 96.04 ± 0.68 |
| VGG-VD16 [53] | 2020 | 94.75 ± 0.23 | 96.93 ± 0.16 |
| EfficientNetB3-Attn-2 [42] | 2021 | 94.45 ± 0.76 | 96.56 ± 0.12 |
| LCNN-CMGF [54] | 2021 | 93.63 ± 0.1 | 97.54 ± 0.25 |
| D-CNN [55] | 2021 | 94.63 | 96.43 |
| DLFP [45] | 2021 | 94.69 ± 0.23 | 96.67 ± 0.28 |
| MSA-Network [39] | 2021 | 93.53 ± 0.21 | 96.01 ± 0.43 |
| LGRIN [19] | 2021 | 94.74 ± 0.23 | 97.65 ± 0.25 |
| RANet [37] | 2021 | 92.71 ± 0.14 | 95.31 ± 0.37 |
| GRMA-Net-ResNet18 [56] | 2021 | 94.58 ± 0.25 | 97.05 ± 0.37 |
| BDFT (ResNet50) | 2022 | 94.85 | 96.88 |
| BDFT (AlexNet) | 2022 | 86.60 | 91.98 |
| BDFT (ResNet18) | 2022 | 95.05 ± 0.49 | 97.76 ± 0.87 |
| Methods | Year | OA (%) |
|---|---|---|
| Discriminative + AlexNet [57] | 2018 | 87.24 ± 0.12 |
| ADSSM [13] | 2018 | 94.29 ± 0.14 |
| RD [60] | 2019 | 91.03 |
| VGG-16-CapsNet [38] | 2019 | 89.18 ± 0.14 |
| Contourlet CNN [46] | 2020 | 89.57 ± 0.45 |
| Hydra (DenseNet + ResNet) [14] | 2019 | 94.51 ± 0.21 |
| Hydra (ResNet) [14] | 2019 | 91.96 ± 0.71 |
| MG-CAP with Biliner [58] | 2020 | 91.72 ± 0.16 |
| EfficientNet [63] | 2020 | 81.83 ± 0.15 |
| LCNN-BFF [48] | 2020 | 91.73 ± 0.17 |
| ResNet18(global + local) [43] | 2020 | 92.79 ± 0.11 |
| VGG_VD16 with SAFF [64] | 2020 | 87.86 ± 0.14 |
| MobileNetV2-SCS [59] | 2021 | 91.17 |
| ResNet50-SCS [59] | 2021 | 91.83 |
| ResNet101-SCS [59] | 2021 | 91.91 |
| VGG-19-0.3 [65] | 2021 | 90.19 |
| AMB-CNN [66] | 2021 | 92.42 |
| BDFT (AlexNet) | 2022 | 86.44 |
| BDFT (ResNet50) | 2022 | 94.07 |
| BDFT (ResNet18) | 2022 | 92.83 ± 0.11 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, J.; Wang, D.; Gu, Z. Bidirectional Flow Decision Tree for Reliable Remote Sensing Image Scene Classification. Remote Sens. 2022, 14, 3943. https://doi.org/10.3390/rs14163943
Feng J, Wang D, Gu Z. Bidirectional Flow Decision Tree for Reliable Remote Sensing Image Scene Classification. Remote Sensing. 2022; 14(16):3943. https://doi.org/10.3390/rs14163943
Chicago/Turabian StyleFeng, Jiangfan, Dini Wang, and Zhujun Gu. 2022. "Bidirectional Flow Decision Tree for Reliable Remote Sensing Image Scene Classification" Remote Sensing 14, no. 16: 3943. https://doi.org/10.3390/rs14163943
APA StyleFeng, J., Wang, D., & Gu, Z. (2022). Bidirectional Flow Decision Tree for Reliable Remote Sensing Image Scene Classification. Remote Sensing, 14(16), 3943. https://doi.org/10.3390/rs14163943