
Prediction of Sea Surface Temperature by Combining Interdimensional and Self-Attention with Neural Networks

Abstract
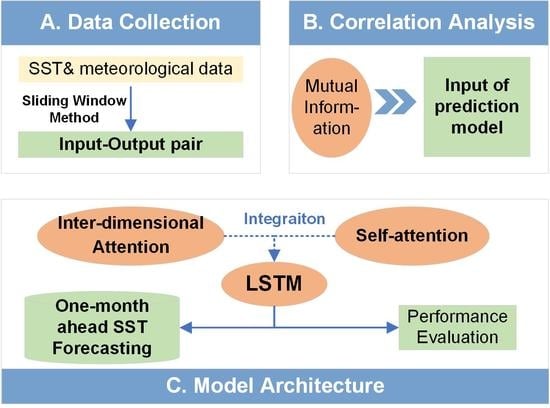
:
1. Introduction
- The determining factors affecting SST distribution and variation, in other words, the input of the LSTM prediction model, is selected by the correlation analysis of mutual information.
- To focus on important historical moments and important variables, a special matrix, that is similar to the position coding matrix, is obtained by multiplying the multi-dimensional data by a weight matrix W (where W is obtained by network training).
- The input data are smoothed using a self-attention mechanism during the training process.
2. Methodology
2.1. Correlation Analysis
2.2. Model Architecture
2.2.1. Interdimensional Attention Strategy
2.2.2. Self-Attention Smoothing Strategy
2.3. Evaluation Metrics
3. Model Implementation and Experiment Results
3.1. Study Area and Data Sets
3.2. Implementation Detail
3.3. Experiment Results
3.3.1. SST Distribution and Variation
3.3.2. Correlation of SST with Other Meteorological Factors
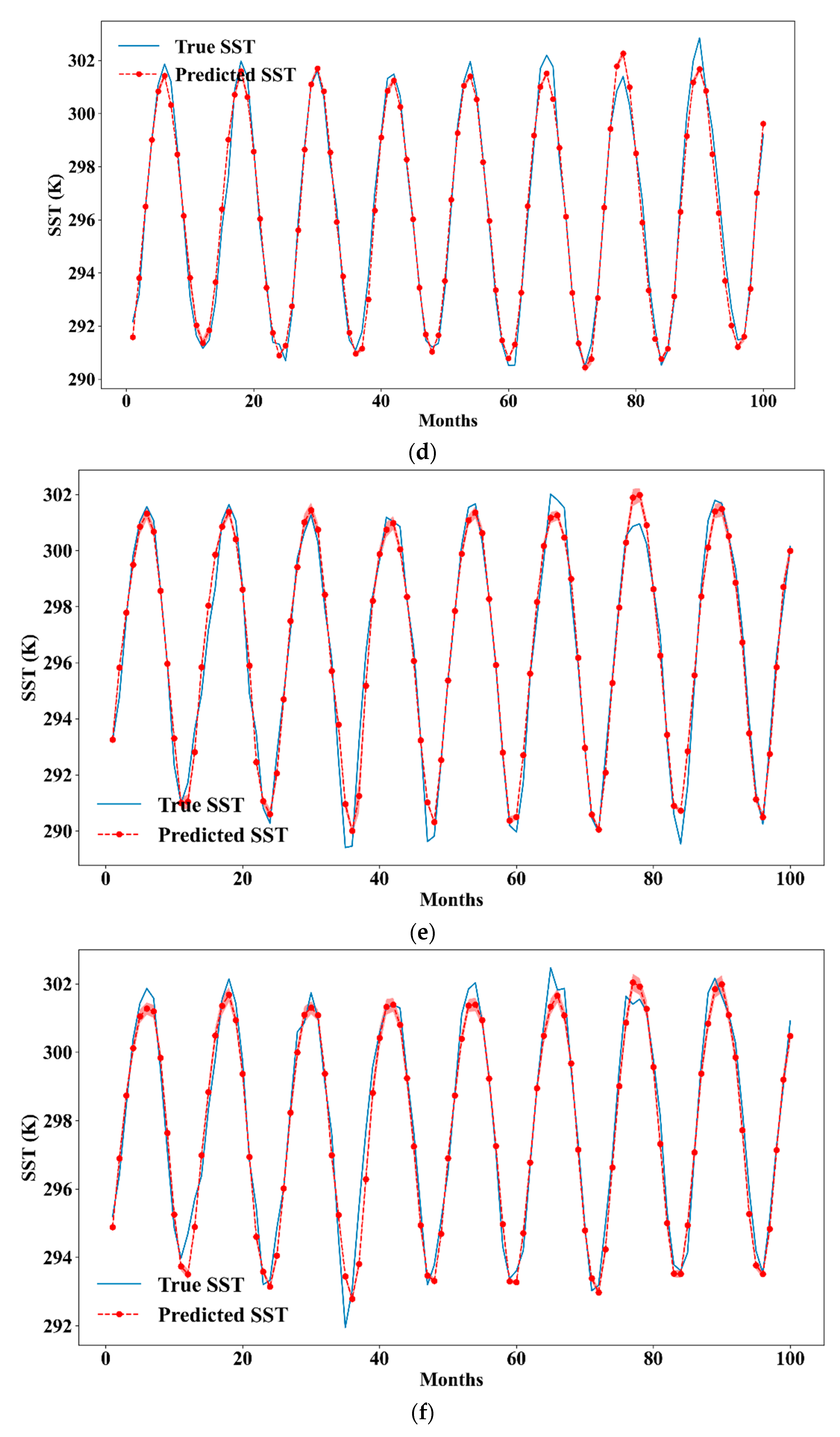
3.3.3. SST Prediction Results
4. Discussion
4.1. Performance Comparison with Other Models
4.2. Overfitting Issue Varification
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- O’carroll, A.G.; Armstrong, E.M.; Beggs, H.M.; Bouali, M.; Casey, K.S.; Corlett, G.K.; Dash, P.; Donlon, C.L.; Gentemann, C.L.; Høyer, J.L.; et al. Observational Needs of Sea Surface Temperature. Front. Mar. Sci. 2019, 6, 1–27. [Google Scholar] [CrossRef]
- Kim, M.; Yang, H.; Kim, J. Sea Surface Temperature and High Water Temperature Occurrence Prediction Using a Long Short-Term Memory Model. Remote Sens. 2020, 12, 3654–3674. [Google Scholar] [CrossRef]
- Baoleerqimuge, R.G.Y. Sea Surface Temperature Observation Methods and Comparison of Commonly Used Sea Surface Temperature Datasets. Adv. Meteorol. Sci. Technol. 2013, 3, 52–57. [Google Scholar] [CrossRef]
- Hou, X.Y.; Guo, Z.H.; Cui, Y.K. Marine big data: Concept, applications and platform construction. Bull. Mar. Sci. 2017, 36, 361–369. [Google Scholar] [CrossRef]
- Jiang, X.W.; Xi, M.; Song, Q.T. A Comparison of Six Sea Surface Temperature Analyses. Acta Oceanol. Sin. 2013, 35, 88–97. [Google Scholar] [CrossRef]
- Wang, C.Q.; Li, X.; Zhang, Y.F.; Zu, Z.Q.; Zhang, R.Y. A comparative study of three SST reanalysis products and buoys data over the China offshore area. Acta Oceanol. Sin. 2020, 42, 118–128. [Google Scholar] [CrossRef]
- Sarkar, P.P.; Janardhan, P.; Roy, P. Prediction of sea surface temperatures using deep learning neural networks. SN Appl. Sci. 2020, 2, 1458. [Google Scholar] [CrossRef]
- Wolff, S.; O’Donncha, F.; Chen, B. Statistical and machine learning ensemble modelling to forecast sea surface temperature. J. Mar. Syst. 2020, 208, 103347. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Lins, I.D.; Araujo, M.; das Chagas Moura, M.; Silva, M.A.; Droguett, E.L. Prediction of sea surface temperature in the tropical Atlantic by support vector machines. Comput. Stat. Data Anal. 2013, 61, 187–198. [Google Scholar] [CrossRef]
- Li, W.; Lei, G.; Qu, L.Q. Prediction of sea surface temperature in the South China Sea by artificial neural networks. IEEE Geosci. Remote. Sens. Lett. 2020, 17, 558–562. [Google Scholar] [CrossRef]
- Zhu, L.Q.; Liu, Q.; Liu, X.D.; Zhang, Y.H. RSST-ARGM: A data-driven approach to long-term sea surface temperature prediction. J. Wirel. Commun. Netw. 2021, 2021, 171. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Qiu, X.P. Neural Networks and Deep Learning; China Machine Press: Beijing, China, 2020; pp. 139–141. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Shi, X.J.; Chen, Z.R.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. In Proceedings of the International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 802–810. [Google Scholar]
- Xu, B.N.; Jiang, J.R.; Hao, H.Q.; Lin, P.F.; He, D.D. A Deep Learning Model of ENSO Prediction Based on Regional Sea Surface Temperature Anomaly Prediction. Electron. Sci. Technol. Appl. 2017, 8, 65–76. [Google Scholar] [CrossRef]
- Yang, Y.; Dong, J.; Sun, X.; Lima, E.; Mu, Q.; Wang, X. A CFCC-LSTM model for sea surface temperature prediction. IEEE Geosci. Remote. Sens. Lett. 2018, 15, 207–211. [Google Scholar] [CrossRef]
- Zhu, G.C.; Hu, S. Study on sea surface temperature model based on LSTM-RNN. J Appl. Oceanogr. 2019, 38, 191–197. [Google Scholar] [CrossRef]
- Sun, T.; Feng, Y.; Li, C.; Zhang, X. High Precision Sea Surface Temperature Prediction of Long Period and Large Area in the Indian Ocean Based on the Temporal Convolutional Network and Internet of Things. Sensors 2022, 22, 1636. [Google Scholar] [CrossRef] [PubMed]
- Aydınlı, H.O.; Ekincek, A.; Aykanat-Atay, M.; Sarıtaş, B.; Özenen-Kavlak, M. Sea surface temperature prediction model for the Black Sea by employing time-series satellite data: A machine learning approach. Appl. Geomat. 2022, 1–10. [Google Scholar] [CrossRef]
- Patil, K.; Deo, M.; Ravichandran, M. Prediction of sea surface temperature by combining numerical and neural techniques. J. Atmos. Ocean. Technol. 2016, 33, 1715–1726. [Google Scholar] [CrossRef]
- Xiao, C.; Chen, N.; Hu, C.; Wang, K.; Chen, Z. Short and mid-term sea surface temperature prediction using time-series satellite data and LSTM-AdaBoost combination approach. Remote Sens. Environ. 2019, 233, 111358. [Google Scholar] [CrossRef]
- Xiao, C.; Chen, N.; Hu, C.; Wang, K.; Xu, Z.; Cai, Y.; Xu, L.; Chen, Z.; Gong, J. A spatiotemporal deep learning model for sea surface temperature field prediction using time-series satellite data. Environ. Model Softw. 2019, 120, 104502. [Google Scholar] [CrossRef]
- He, Q.; Cha, C.; Song, W.; Hao, Z.Z.; Huang, D.M. Sea surface temperature prediction algorithm based on STL model. Mar. Environ. Sci. 2020, 39, 104–111. [Google Scholar] [CrossRef]
- de Mattos Neto, P.S.G.; Cavalcanti, G.D.C.; de, O.S.J.D.S.; Silva, E.G. Hybrid Systems Using Residual Modeling for Sea Surface Temperature Forecasting. Sci. Rep. 2022, 12, 487. [Google Scholar] [CrossRef]
- Jahanbakht, M.; Xiang, W.; Azghadi, M.R. Sea Surface Temperature Forecasting With Ensemble of Stacked Deep Neural Networks. IEEE Geosci. Remote. Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Liu, X.; Li, N.; Guo, J.; Fan, Z.; Lu, X.; Liu, W.; Liu, B. Multi-step-ahead Prediction of Ocean SSTA Based on Hybrid Empirical Mode Decomposition and Gated Recurrent Unit Model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 7525–7538. [Google Scholar] [CrossRef]
- Lara-Benítez, P.; Carranza-García, M.; Riquelme, J.C. An experimental review on deep learning architectures for time series forecasting. Int. J. Neural Syst. 2021, 31, 2130001. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. arXiv 2017. [Google Scholar] [CrossRef]
- Li, S.; Jin, X.; Xuan, Y.; Zhou, X.; Chen, W.; Wang, Y.-X.; Yan, X. Enhancing the locality and breaking the memory bottleneck of transformer on time series forecasting. In Proceedings of the Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 1–11. [Google Scholar]
- Xie, J.; Zhang, J.; Yu, J.; Xu, L. An adaptive scale sea surface temperature predicting method based on deep learning with attention mechanism. IEEE Geosci. Remote. Sens. Lett. 2019, 17, 740–744. [Google Scholar] [CrossRef]
- Mohammadi Farsani, R.; Pazouki, E. A transformer self-attention model for time series forecasting. J. Electr. Comput. Eng. Innov. 2021, 9, 1–10. [Google Scholar] [CrossRef]
- Xu, W.X.; Shen, Y.D. Bus travel time prediction based on Attention-LSTM neural network. Mod. Electron. Technol. 2022, 45, 83–87. [Google Scholar] [CrossRef]
- Liu, X.X. Correlation Analysis and Variable Selection for multivariateTime Series based a on Mutual Informationerles. Master’s Thesis, Dalian University of technology, Dalian, China, 2013. [Google Scholar]
- De Winter, J.C.; Gosling, S.D.; Potter, J. Comparing the Pearson and Spearman correlation coefficients across distributions and sample sizes: A tutorial using simulations and empirical data. Psychol. Methods 2016, 21, 273–290. [Google Scholar] [CrossRef]
- Li, G.J. Research on Time Series Forecasting Based on Multivariate Analysis. Master’s Thesis, Tianjin University of Technology, Tianjin, China, 2021. [Google Scholar]
- Kozachenko, L.F.; Leonenko, N.N. Sample estimate of the entropy of a random vector. Probl. Inf. Transm. 1987, 23, 9–16. [Google Scholar]
- Kraskov, A.; Stögbauer, H.; Grassberger, P. Estimating mutual information. Phys. Rev. E 2004, 69, 66138. [Google Scholar] [CrossRef]
- Hersbach, H.; Bell, B.; Berrisford, P.; Biavati, G.; Horányi, A.; Muñoz Sabater, J.; Nicolas, J.; Peubey, C.; Radu, R.; Rozum, I.; et al. ERA5 monthly averaged data on single levels from 1959 to present. Copernic. Clim. Change Serv. (C3S) Clim. Data Store (CDS) 2019, 10, 252–266. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Ocean Region | Range | Average Depth (m) | Characteristics | |
|---|---|---|---|---|---|
| Longitude (E°) | Latitude (N°) | ||||
| 1 | Bohai Sea and North Yellow Sea | 119~125 | 37~41 | 18 | Nearly closed |
| 2 | South Yellow Sea | 119~125 | 31~37 | 44 | Semi-closed |
| 3 | East China Sea | 121~125 | 29~31 | 370 | Marginal sea |
| 4 | 119~125 | 25~29 | |||
| 5 | Taiwan Strait | 119~121 | 24~25 | 60 | Narrow strait |
| 6 | 117~120 | 22~24 | |||
| 7 | South China Sea | 106~125 | 5~21 | 1212 | Open sea area |
| Parameters | Name | Unit |
|---|---|---|
| SST | Sea surface temperature | K |
| u10 | Eastward component of the 10 m wind | m/s |
| v10 | Northward component of the 10 m wind | m/s |
| msl | Mean sea level pressure | Pa |
| ssr | Surface net solar radiation | J/m2 |
| ssrc | Surface net solar radiation clear sky | J/m2 |
| str | Surface net thermal radiation | J/m2 |
| strc | Surface net thermal radiation clear sky | J/m2 |
| ssrd | Surface solar radiation downward | J/m2 |
| ssrdc | Surface solar radiation downward clear sky | J/m2 |
| strd | Surface solar radiation downwards | J/m2 |
| strdc | Surface thermal radiation downward clear sky | J/m2 |
| Key Parameters | Model Methods or Values |
|---|---|
| Length of training data sets | 300 |
| Length of validation data sets | 50 |
| Length of testing data sets | 100 |
| Architecture of the model | Attention + LSTM + Dense |
| Input dimension | 12 × 4 |
| Output dimension | 1 |
| No. of neural of hidden layer | 80 |
| Optimizer | Adam |
| Epoch | 400 |
| Batch size | 40 |
| Dropout | 0.1 |
| Loss function | RMSE |
| Region ID | R2 | RMSE | MAE | MAPE |
|---|---|---|---|---|
| 1 | 0.9910 | 0.7551 | 0.6211 | 0.2170 |
| 2 | 0.9829 | 0.8789 | 0.6803 | 0.2336 |
| 3 | 0.9827 | 0.7547 | 0.5936 | 0.2029 |
| 4 | 0.9827 | 0.5120 | 0.4100 | 0.1382 |
| 5 | 0.9727 | 0.6515 | 0.5065 | 0.1711 |
| 6 | 0.9649 | 0.5666 | 0.4531 | 0.1521 |
| 7 | 0.9138 | 0.3928 | 0.3213 | 0.1067 |
| Region ID | LSTM Only with SST Only as Input | LSTM Only | Our Model |
|---|---|---|---|
| 1 | 1.0157 | 0.9226 | 0.7551 |
| 2 | 1.0302 | 0.8657 | 0.8789 |
| 3 | 1.0481 | 0.7853 | 0.7547 |
| 4 | 0.8388 | 0.7301 | 0.5120 |
| 5 | 1.2139 | 0.8768 | 0.6515 |
| 6 | 0.7678 | 0.6487 | 0.5666 |
| 7 | 0.4140 | 0.4018 | 0.3928 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, X.; He, J.; Wang, B.; Wu, J. Prediction of Sea Surface Temperature by Combining Interdimensional and Self-Attention with Neural Networks. Remote Sens. 2022, 14, 4737. https://doi.org/10.3390/rs14194737
Guo X, He J, Wang B, Wu J. Prediction of Sea Surface Temperature by Combining Interdimensional and Self-Attention with Neural Networks. Remote Sensing. 2022; 14(19):4737. https://doi.org/10.3390/rs14194737
Chicago/Turabian StyleGuo, Xing, Jianghai He, Biao Wang, and Jiaji Wu. 2022. "Prediction of Sea Surface Temperature by Combining Interdimensional and Self-Attention with Neural Networks" Remote Sensing 14, no. 19: 4737. https://doi.org/10.3390/rs14194737