Abstract
With the development of deep learning, the performance of image semantic segmentation in remote sensing has been constantly improved. However, the performance usually degrades while testing on different datasets because of the domain gap. To achieve feasible performance, extensive pixel-wise annotations are acquired in a new environment, which is time-consuming and labor-intensive. Therefore, unsupervised domain adaptation (UDA) has been proposed to alleviate the effort of labeling. However, most previous approaches are based on outdated network architectures that hinder the improvement of performance in UDA. Since the effects of recent architectures for UDA have been barely studied, we reveal the potential of Transformer in UDA for remote sensing with a self-training framework. Additionally, two training strategies have been proposed to enhance the performance of UDA: (1) Gradual Class Weights (GCW) to stabilize the model on the source domain by addressing the class-imbalance problem; (2) Local Dynamic Quality (LDQ) to improve the quality of the pseudo-labels via distinguishing the discrete and clustered pseudo-labels on the target domain. Overall, our proposed method improves the state-of-the-art performance by 8.23% mIoU on Potsdam→Vaihingen and 9.2% mIoU on Vaihingen→Potsdam and facilitates learning even for difficult classes such as clutter/background.
1. Introduction
Remote sensing (RS) image-semantic segmentation is aimed at analyzing the pixel-level content of RS images and classifying each pixel in RS images with a predefined ground truth label. It has received increasing attention and research interest due to its application in city planning, flood control, and environmental monitoring.
In the past few years, many semantic segmentation algorithms based on deep neural networks (DNNs) have been proposed and achieved overwhelming performance, such as fully convolutional networks [,,], Encoder-Decoder based models [], and Transformers [,,,]. However, these methods require a large amount of annotated data to work properly with specific datasets and have degraded performance due to the discrepancy between feature distributions in different datasets and named domain gap (or domain shift). Datasets with different feature distributions are considered as different domains. The domain gap mainly occurs due to the diversity of data acquisition conditions, such as color, lighting, and camera settings. Therefore, in practical applications, these supervised methods are limited to specific scenes and still need laborious annotations to perform well in different datasets.
Domain adaptation (DA), a subcategory of transfer learning, has been recently proposed to address the domain gap. It enables a model to learn and transfer the domain-invariant knowledge between different domains. DA methods can be supervised, semi-supervised or unsupervised based on whether it has access to the labels of the target domain. In particular, unsupervised domain adaptation (UDA) is aimed at transferring the model from a labeled source domain to an unlabeled target domain. Currently, existing UDA works can be divided into generative-based methods, adversarial-learning methods, and self-training (ST) methods [].
Specifically, generative-based works use image translation or style transferring to make the images from different domains visually similar. Then, semantic segmentation models can be trained with the translated images and the original labels. Yang et al. [] used the Fast Fourier Transform (FFT) to replace the low-level frequencies of the target images with that of the source images before reconstituting the image via the inverse FFT. Ma et al. [] adopted gamma correction and histogram mapping on source images to perform distribution alignment in a Lab color space. In remote sensing, graph matching [] and histogram matching [] were applied to perform image-to-image translation. To obtain more accurate and appropriate translation results, generative adversarial networks (GANs) [,,,] have been widely used in previous UDA methods [,,,,,] for RS semantic segmentation. The potential issue of generative-based methods is that the performance of semantic segmentation models heavily rely on the quality of translated images, as pixel-level flaws could significantly influence the accuracy.
Adversarial-learning methods introduce a discriminator network to help segmentation networks minimize the discrepancy between source and target feature distributions. The segmentation network predicts the segmentation results for the source and target images. The discriminator takes the feature maps from the segmentation network and tries to predict the domain of the input. To fool the discriminator, the segmentation network finally outputs feature maps with similar distribution for images from the source and target domains. Tsai et al. [] established that source and target domains share strong similarities in semantic layout. They constructed a multi-level adversarial network to exploit structural consistency in the output space across domains. Vu et al. [] used a discriminator to make the target’s entropy distribution similar to the source. Cai et al. [] proposed a bidirectional adversarial-learning framework to maintain bidirectional semantic consistency. However, the discriminator networks are highly sensitive to hyper-parameters and are difficult to train to learn similar feature distributions in different domains.
Unlike the first two UDA methods, self-training (ST) methods do not rely on any auxiliary networks. ST strategies can transfer knowledge across domains with segmentation networks only, which is far more elegant. ST methods follow the “easy-to-hard” scheme where the highly confident predictions inferred from unlabeled target data are treated as pseudo-labels and the labeled source data and pseudo-labeled target data are used jointly to get a better performance in the target domain. Zou et al. [] proposed one of the first iterative ST techniques in semantic segmentation by treating pseudo-labels as discrete latent variables, which are computed through the minimization of a unified training objective. Vu et al. [] introduced direct entropy minimization to self-training as a way to encourage the model to produce high-confident predictions instead of using a threshold to indicate high-confident ones. Yan et al. [] combined the self-learning method with the adversarial-learning method on RS images by a cross-mean teacher framework exploiting the pseudo-labels near the edge. To alleviate the issue of faulty UDA pseudo-labels in semantic segmentation, each pseudo-label is weighted by the proportion of pixels with confidence above a certain threshold [,], named the quality of pseudo-labels.
In addition, most previous UDA methods evaluate their performance with classical architectures such as DeepLabV2 [] and DeepLabV3+ [] which have been outperformed by the modern vision transformer [,,] and limit the overall performance of UDA methods. In recent studies, Xu et al. [] first introduced the transformer into the supervised semantic segmentation of RS images. Hoyer et al. [] were also the first to systematically study the influence of recent transformer architectures on UDA semantic segmentation.
Meanwhile, UDA is concerned with transferring knowledge from a labeled domain to an unlabeled domain, which is domain-relevant. From the perspective of domain-irrelevant methods, we can focus on improving the generalization of models by increasing the size of training data and addressing the class-imbalance problem.
Data augmentation, a technique of generating perturbed images, has been found to improve the generalization ability of models in various tasks. For instance, Zhang et al. [] enhanced the dataset by linear combinations of data and corresponding labels. Yun et al. [] composited new images by cutting a rectangular region from one image and pasting it on another, a technique recently adopted by Gao et al. [] for semantic segmentation of RS images. Chen et al. [] used a variety of spatial/geometric and appearance transformations to learn good representations and gain great accuracy by a simple classification model in a self-supervised learning method. In semi-supervised learning, Olsson et al. [] mixed unlabeled data to generate augmented images and labels named ClassMix. The mask’s shape for mixing is determined by category and is not necessarily rectangular. To be specific, a mask may contain all the pixels of a class. However, in the strategy of ClassMix, half of the classes are selected to generate the mask []. Then, it was developed by Tranheden et al. [] in the image-semantic segmentation UDA task, where the masked slices of images and labels are generated in the source domain and are pasted to the target domain, thus making the target images contain slices of the source images.
The imbalanced category proportions compromise the performance of most standard learning algorithms, which expect balanced class distributions. When presented with complex imbalanced datasets such as RS datasets, these algorithms might fail to properly represent the distributive characteristics of the data, thus providing unfavorable accuracy across the classes of the data. To address the class-imbalance problem, basic strategies can be divided into two categories, i.e., preprocessing and cost-sensitive learning []. However, most of them have either high computational complexities or many hyper-parameters to tuning. In deep learning, Zou et al. addressed the class-imbalance problem by setting different class weights based on the inverse of their corresponding proportions in the dataset []. In UDA, Yan et al. [] introduced class-specific auxiliary weights for exploiting the class prior probability on source and target domains. Recently, Hoyer et al. [] sampled source data with rare classes more frequently in order to learn them better and earlier. On the other hand, some data with common classes may be rarely sampled or not sampled at all, which might result in degraded performance.
However, three challenges still exist in UDA for RS image-semantic segmentation: (i) The potential of a vision Transformer for UDA semantic segmentation of RS images has not been discussed. (ii) In ST methods [,], the correct and incorrect pseudo-label in an image gets the same weight depending on the ratio of high-confident pixels. (iii) Due to the randomness of sampling, the changes in category proportions during the training process have not been considered in [,] for addressing the class-imbalance problem in UDA semantic segmentation.
In this paper, we apply Transformer [] and cross-domain mixed sampling [] to a self-training UDA framework for RS image-semantic segmentation. Then, two strategies are proposed to boost the performance of the framework. First, we introduce a strategy of Gradual Class Weights to dynamically adjust class weights in the source domain for addressing the class-imbalance problem. Secondly, a novel way to calculate the quality of pseudo-labels is proposed to guide the adaptation to the target domain. The implementation code is available at https://github.com/Levantespot/UDA_for_RS, accessed on 21 August 2022. The three main contributions of our work can be summarized as follows:
- 1.
- We demonstrate the remarkable performance of Transformer in self-training UDA of RS images compared to the previous methods using DeepLabV3+ [];
- 2.
- Two strategies, Gradual Class Weights, and Local Dynamic Quality are proposed to improve the performance of the self-training UDA framework. Both of them are easy to implement and embed in any existing semantic segmentation model;
- 3.
- We outperformed state-of-the-art UDA methods of RS images on the Potsdam and Vaihingen datasets, which indicates that our method can improve the performance of cross-domain semantic segmentation and minimize the domain gap effectively.
2. Methods
In this section, we provide an overview of our self-training framework, where the pseudo-labels are generated by teacher model from the target images to guide the student network to better transfer knowledge from the source to the target domain. In addition, we will briefly compare the difference between the network structure of the convolutional neural network (CNN) and the vision Transformer. Then, the class imbalance issue is alleviated by Gradual Class Weights (GCW), where the weights of classes are updated based on the current source image . Finally, we illustrate the implementations of the Local Dynamic Quality (LDQ), where the quality of pseudo-labels is estimated based on the states of their neighbors. The overall self-training UDA framework is shown in Figure 1.
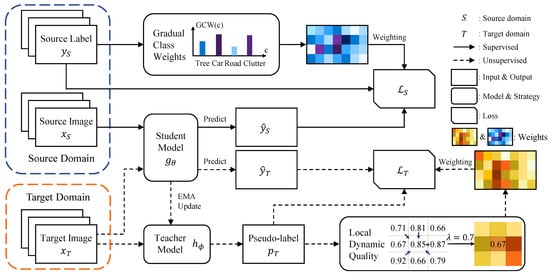
Figure 1.
Overview of our self-training framework with Gradual Class Weights and Local Dynamic Quality. Source images and source labels are trained together in a supervised way with GCW. Pseudo-labels are generated by teacher model in place of the target labels . Target images and pseudo-labels are trained together with LDQ. The darker the color is in GCW and LDQ, the larger the weight of the corresponding class and pseudo-label is.
2.1. Self-Training (ST) for UDA
In UDA for RS, we define two sets of images collected from different satellites or locations as different domains. To simplify the problem, images in the source and target domains have the same resolution of with 3 channels and the same set of semantic classes in both domains. One having both images and corresponding labels is the source domain , where C is the number of categories while the other with only images available is known as the target domain . The subscripts S and T denote the source and target domains, respectively. Note that the target labels are only accessible at the testing stage. The label at spatial location in is a one-hot vector with a length of C, denoted as , . The objective of UDA methods is to train a model using source images and source labels to achieve a good performance on target images without having access to the target labels . In the self-training UDA framework, a student model is first trained on the source domain in a supervised way, where denotes its parameters. The objective function with cross-entropy loss is formulated as shown in Equation (1):
where , are the n-th source image and the corresponding label, denotes the c-th scalar of a vector, denotes the normalized probabilities predicted by of each class at location in image , and is the weight as a function of class c and index n of the image and will be discussed in Section 2.3.
To address the domain gap, ST approaches use pseudo-labels to transfer the knowledge from the source to the target domain. In the basic version of ST methods, the student model generates the pseudo-labels . To reduce abrupt changes in the model parameters due to the large gap between the source and target domains, the exponentially moving average (EMA) and teacher model are introduced to make the generation of pseudo-labels more reliable. In EMA, the teacher model is updated based on the student model , formulated as shown in Equation (2):
where and are the parameters of student model and teacher model , respectively, t denotes the training step, and hyper-parameter indicates how important the current state of weights is. The generation of pseudo-labels is formulated as shown in Equation (3):
where denotes the one-hot pseudo-label at location in the pseudo-labels , and denotes the normalized probabilities of each class in image at location . Note that no gradient will be backpropagated into the teacher model through this procedure. Since there is no guarantee that these generated pseudo-labels are corrected, we use LDQ to quantify the reliability and quality of each pseudo-label at location . They are denoted as and will be discussed later in Section 2.4. The pseudo-labels and their quality are jointly used to train on the target domain as shown in Equation (4):
Note that the models and have the same network architecture. The pseudo-labels are generated online, i.e., the teacher model generates pseudo-labels for every image at each iteration.
2.2. Transformer for Semantic Segmentation
We will briefly review what makes CNNs successful and then compare them to the key components of vision Transformers. Generally, CNNs leverage the basic information such as texture and color that make up the visual elements through a large number of convolutional filters. For example, convolutional filters capture the key points, lines, and curves in shallow layers, while filters in deeper layers extract more abstract details and focus on discriminative structures [,]. Since CNNs are locally sensitive, different receptive fields (RF) of the input image are perceived in different layers, as shown in Figure 2. From the perspective of information flow, the receptive field determines the area where the model can learn the information of the input image. Furthermore, CNNs capture local structures of an image in the early stages and extract a larger range of global features in the deeper layers.
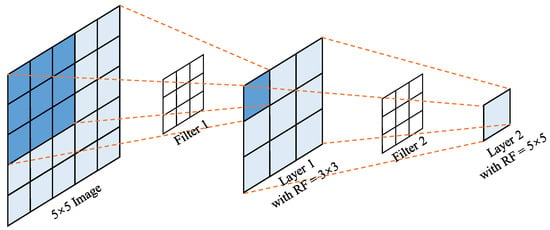
Figure 2.
The receptive fields of CNNs in different layers. As the convolution proceeds, the range of receptive fields gradually increases. Layer 1 gets an RF of 3 × 3 (blue area in the image), while 5 × 5 for layer 2 (light blue area in the image). Note that the two filters are both fixed at testing.
However, the learned convolutional filters are fixed at testing, which hinders the generalization of CNNs. To make the model more adaptive and general, vision Transformers [,,,] bring the self-attention mechanism from natural language processing to computer vision. The self-attention mechanism is illustrated in Figure 3. The fixed convolutional filters are replaced with weights that can be computed dynamically based on the similarity or affinity between every pair of patches, thus enabling capturing “long-term” information and dependencies between sequence elements. Therefore, vision Transformers have a larger receptive field to extract finer features at the encoding stage.
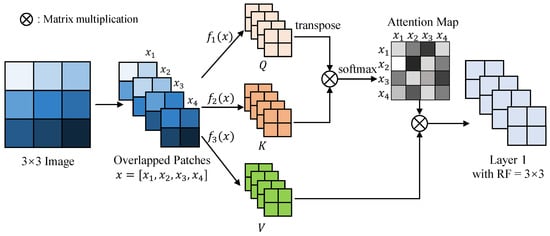
Figure 3.
A simplified illustration of the self-attention mechanism in vision Transformer. The self-attention mechanism takes the overlapped patches of an image as input. These patches are encoded in three ways, i.e., , to get three matrices Q, K, V, short for Query, Key, and Value, respectively. The softmax result of the matrix product of Q and K is called the attention map, which represents the similarity or weights between each pair of patches. The darker the color in the attention map, the stronger the relationship between the two patches. The attention map is multiplied with the matrix V to get the feature layer 1, which is the output of the self-attention module. Unlike the convolution, self-attention module has a receptive field of the entire input.
2.3. Gradual Class Weights (GCW)
Class imbalance is a common and plaguing situation where the distribution of data is skewed since some classes appear much more frequently than others. For example, the common class roads occur more frequently than the rare class cars, resulting in less information about the cars and poor model generalization. To efficiently alleviate this issue, Zou et al. [] assigned a weight to each class, inversely proportional to the frequency in the whole training dataset. As a result, the rare classes receive more attention than the common classes. The frequency of class c is defined in Equation (5):
where denotes the one-hot source label at location , and denotes the c-th scalar of a vector. However, due to the randomness in sampling, the distribution of the class will be different from that calculated on the whole dataset in advance. To address the mismatched distribution, the weights will be updated iteratively for each image. In addition, inspired by gradual warmup [], where small learning rates are used to reduce volatility in the early stages of training, it is assumed that class weights also need the warmup to keep the model more stable and robust in the early training stages. Notably, instead of directly initializing the class weights to the distributions estimated from the first sample, they are initialized to 1 and then are updated iteratively by an exponentially weighted average. The pseudo-code of the proposed GCW is presented in Algorithm 1, where denotes all the source labels with a size of , denotes the frequency of class c in the source domain, represents the original class weights only based on , and T denotes the temperature parameter []. A higher T leads to a more uniform distribution while a lower one makes the model pay more attention to the rare classes.
| Algorithm 1 Gradual Class Weights |
|
2.4. Local Dynamic Quality (LDQ) of Pseudo-Labels
In some previous ST works [,], only pseudo-labels with probabilities greater than a fixed threshold are used for training, and they are known as high-quality pseudo-labels. Equation (6) depicts the procedure of determining the quality of the pseudo-label at location .
where 1 and 0 indicate high quality and low quality, respectively, denotes the teacher model used to generate pseudo-labels as it is more stable than the student model . The threshold is typically determined via grid search, where a manually specified subset of the thresholds is searched exhaustively, the best value will then be chosen as the pseudo-label threshold . Once the threshold is determined, it will not be changed during the training stage. Intuitively, a higher threshold leads to more accurate, high-quality pseudo-labels but may also result in fewer samples available for training in the early training stage, because the model should have lower confidence during the early training stages than after many iterations.
To alleviate the influence of faulty UDA pseudo-labels in semantic segmentation, the image-wise ratio of high-quality pseudo-labels in an image is estimated to weigh the sample [,]. Therefore, we proposed a pixel-wise quality of pseudo-labels named local dynamic quality (LDQ), where each pseudo-label is assigned a different weight based on the pixels around it. The main idea underlying our method is intuitive: discrete pseudo-labels are more likely to be misclassified and should have relatively lower quality. On the contrary, the clustered ones deserve higher quality. In particular, the quality of a pseudo-label is calculated based on the ratio of high-quality surrounding pseudo-labels, which can be efficiently calculated through convolution. The formula for LDQ is demonstrated in Equation (7):
where denotes the quality of a pseudo-label at location , denotes the depth of neighbors, and is known as the size of the convolution kernel. In contrast to [,], all pseudo-labels, correct or incorrect, are used for training as the pixels-wise quality weights the influence of each pseudo-label.
3. Results
In this section, we introduce the source and target datasets, describe the experimental details, and finally illustrate the obtained results.
3.1. Dataset Description
The Potsdam (POT) dataset [] contains 38 patches of a typical historic city with large building blocks, narrow streets, and dense settlement structures with a resolution of 6000 × 6000 pixels over Potsdam City, and the ground sampling distance is 5 cm. In total, 24 and 14 patches are used for training and testing, respectively.
The Vaihingen (VAI) dataset [] contains 33 patches of a relatively small village with many detached buildings and few multi-story buildings with a resolution ranging from 1996 × 1995 to 3816 × 2550 pixels, and the ground sampling distance is 9 cm. In total, 16 and 17 patches are used for training and testing, respectively.
Both datasets have the same six categories: impervious surfaces, buildings, low vegetation, trees, cars, and clutter/background. The clutter/background class consists of water bodies and other objects which are of no interest in semantic object classification in urban scenes. Note that Potsdam has two band modes; RGB (red, green, and blue) and IRRG (near-infrared, red, and green), while Vaihingen has only IRRG mode. We use Potsdam in RGB mode and Vaihingen in IRRG mode. In IRRG mode, things may look different from natural images, e.g., trees and low vegetation are red. Since Potsdam is a city and Vaihingen is a village, there are more cars and apartments in the POT dataset, while there are more houses and farmland in the VAI dataset.
Since the two datasets are the same in task objective and label space but different in feature distribution and band mode, they are suitable for evaluating the performance of UDA methods. In this paper, we used two different settings of domain adaptation. The first one is transferring from the Potsdam dataset to the Vaihingen dataset, presented as POT→VAI, and the other is the opposite, denoted as VAI→POT. Note that the only difference between the source and target domains is that no labels are accessible in the target domain during training. Meanwhile, to make images and labels fit into the GPU memory properly, all images are cropped into 512 × 512 pixels’ patches with overlaps of 256 pixels. In this setting, 344 training data and 398 testing data are generated from VAI, while 3456 and 2016 are for POT.
3.2. Implementation Details
Preprocessing: Our implementation is based on the PyTorch [] and MMSegmentation []. We use the preprocessing pipeline provided by the MMSegmentation [], where resizing, cropping, flipping, normalization, and padding are randomly applied to the data. The pixels between the boundaries are ignored during training. In accordance with [,], we mix the target data with the source data in the same way and use the same data augmentation parameters of colorjitter, where the brightness, contrast, saturation, and hue of images are randomly changed.
Network Architecture: Since both local and global features are important in semantic segmentation, feature fusion [] is usually required in CNNs to obtain high-precision segmentation results. Hoyer et al. [] designed a Transformer with context-aware multilevel feature fusion, named DAFormer, to exploit both coarse-grained and fine-grained features. Since they achieved the best results in UDA semantic segmentation, we adopt DAFormer [] as the network architecture for both student model and teacher model . DAFormer [] used the MiT-B5 encoder [] pre-trained on ImageNet [] to produce a feature pyramid with channels = [64, 128, 320, 512]. Then, its decoder embeds each feature to 256 channels with the same size of , followed by the depth-wise dilated separable convolutions [] with the dilation rates of 1, 6, 12, and 18.
Training: Student model is trained with the AdamW [] optimizer using betas = (0.9, 0.999), a learning rate of for the encoder and for the decoder, a weight decay of 0.01, linear learning rate warmup with , and linear decay of 0.01 afterwards. The used to update the teacher model is set to . Then, two networks are trained for 4000 iterations with a batch size of 8 consisting of 4 source and 4 target data. For GCW, the temperature T is set to 0.1 to pay more attention to the pixels of the rare class, and the mixing parameter is set to 0.9 to smoothly update the class distribution. In LDQ, we set the threshold of pseudo-labels to .
3.3. Quantitative Results
In accordance with the previous UDA methods of RS semantic segmentation, F1-score and Intersection over Union (IoU) have been used to evaluate the methods. The metrics are formulated as shown in Equations (8) and (9):
where , , and denote the number of true positive pixels, false positive pixels, and false negative pixels, respectively. IoU is also known as the Jaccard index, and the F1-score is known as the Dice coefficient.
Since there are six different classes in VAI and POT datasets, F1-score and IoU are first calculated for every class followed by the mean IoU (mIoU) and mean F1-score (mF1) calculated by averaging the results of all the classes. The results of our method are shown in four experiments and are reported in Table 1 and Table 2. We build our baseline (B/L) with a self-training framework (discussed in Section 2.1), DAFormer [] network, the mixing strategy in [], and learning rate warmup []. Then, GCW and LDQ are first added separately to the baseline and finally combined at the same time. To make our results more reliable, all results are obtained by averaging over three runs with the same parameters and architecture. Compared to the baseline on POT→VAI, GCW improves the performance by 9.97% of mIoU and 8.47% of mF1. It especially improves the performance of the roads, trees, and vegetation, while LDQ greatly increases the results of the clutter. As the two results of GCW and LDQ are complementary in many classes, our method generates more robust results when using both GCW and LDQ. On VAI→POT, the performance of LDQ is more desirable than GCW in the clutter, car, and tree classes, while it degraded in the vegetation class. In addition, the final experiment conducted with GCW and LDQ achieved close to optimum results. However, all the experiments generated inferior results close to zero in the clutter class on VAI→POT.

Table 1.
Quantitative results (%) on POT→VAI.
Table 2.
Quantitative results (%) on VAI→POT.
3.4. Visualization Results
Figure 4 and Figure 5 depict the predicted results for baseline, baseline with GCW, baseline with LDQ, and baseline with GCW and LDQ on POT→VAI and VAI→POT, respectively. Note that the thick black lines in panels (b) are the boundaries ignored during training.
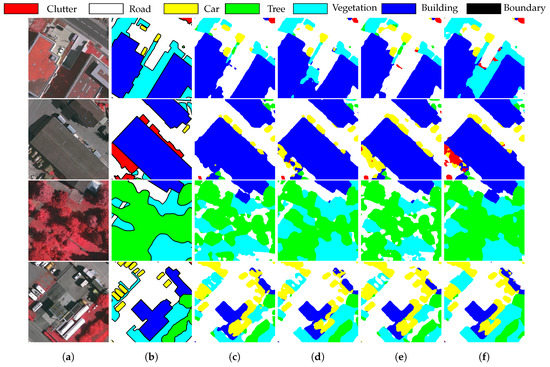
Figure 4.
Predictions of the validation images from VAI on POT→VAI. (a) Target images. (b) Ground truth. (c) Baseline. (d) Baseline with GCW. (e) Baseline with LDQ. (f) Baseline with GCW and LDQ.
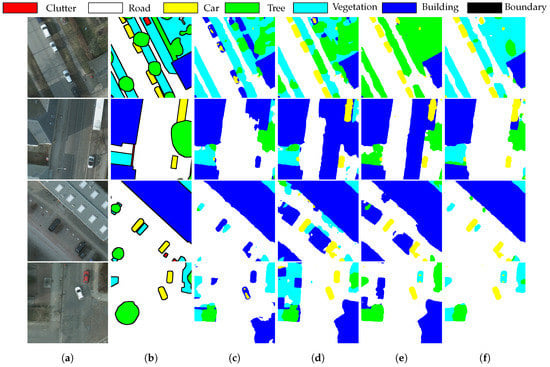
Figure 5.
Predictions of the validation images from POT on VAI→POT. (a) Target images. (b) Ground truth. (c) Baseline. (d) Baseline with GCW. (e) Baseline with LDQ. (f) Baseline with GCW and LDQ.
3.5. Comparisons with Other Methods
We compare our results with five methods of remote sensing domain adaptation: CycleGAN [] is a generative network transferring images from a source domain to a target domain, AdaptSegNet [] is a multi-level adversarial discriminator network exploiting structural consistency, MUCSS [] combines DualGAN [] network with ST strategies, CSC-Aug [] combines style translation with the consistency principle, and RDG-OSA [] proposed the resize-residual DualGAN [] with an output space adaptation method. These previous UDA works use either DeepLabv2 [] or DeepLabv3+ [] as the semantic segmentation framework. Note that the results of all methods are using the same datasets POT and VAI. In addition, we take the average results of all methods to ensure fairness. A comprehensive comparison with these works is shown in Table 1 and Table 2 for POT→VAI and VAI→POT, respectively.
Our baseline is surprisingly competitive and even better compared to other state-of-the-art techniques, which demonstrates that the Transformer generalizes better to the new domain than the previous CNNs. Compared to CSC-Aug [], our method increases the mIoU and mF1 by 8.23% and 9.16% on POT→VAI, respectively. While compared to RDG-OSA [], it increases by 9.2% and 7.77%, respectively, on VAI→POT. Generally, our proposed method almost outperforms all the previous works both in IoU and F1-score, except for the car class on POT→VAI and the clutter class on VAI→POT.
4. Discussion
In this section, we first explore strategies and hyper-parameters in detail. Since our experiments show that the results on POT→VAI are more stable and reliable than that on VAI→POT, we focus on the consequences of the strategies mainly via experiments on POT→VAI. Then, we discuss the limitations of the proposed method, the possible reasons for unstable results on VAI→POT, and possible further improvements.
4.1. GCW
In supervised learning, it is often beneficial to change the loss weights of each class to obtain better performance because most datasets are class-imbalanced. However, it is more complicated in domain adaptation problems where the same class may have different or conflicting feature and texture distributions in the source and target domains. Therefore, we investigate the influence of the class weights on UDA performance via three experiments, where the first one equally sets the weights of all classes to 1, the second experiment applies GCW to dynamically change the class weights, and the last experiment initializes the class weights to the final result of GCW as the final weights are approximately equal to the mean of those calculated from the entire dataset. All experiments are performed based on the baseline. Table 3 shows that the GCW can improve the performance of each class compared to the first approach, while the prior invariant weights in the third method severely degrade the results.
Table 3.
The IoU (%) of each class with different class weights on POT→VAI.
Figure 6 illustrates the change process of the class weights calculated by GCW, where the class weights of road, building, and vegetation are close to 0.5 while that of the car and clutter class are higher than 1.5, which indicates that the latter two appear much less frequently than the first three. Remarkably, most of the class weights at 800 iterations of training are close to themselves in the final rounds, which means that GCW and the third method are almost identical after 800 rounds. However, the model gets no extra performance by directly initializing the class weights to the final values but the degraded behaviors, as demonstrated in Figure 7. Therefore, we conclude that the proposed GCW that gradually adjusts the class weights serves by avoiding a sudden change of the class weights and allowing healthy convergence at the start of training, which is similar to a gradual warmup []. It reveals the significance of model stability in the UDA: the model could get unsatisfied results even if it performs well in early iterations because of the disagreement of feature distribution between the source and target domains. On the other hand, while the result curves of the GCW and equal weights have similar trends in Figure 7, the former has a higher IoU and more compact confidence interval almost for all the categories and iterations, indicating better performance and stability, respectively. To sum up, the model of UDA can still benefit from the well-focused class weights tenderly.
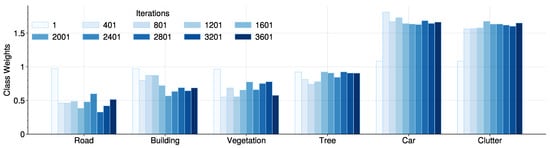
Figure 6.
The weights of each category as calculated by GCW during the training on POT→VAI.
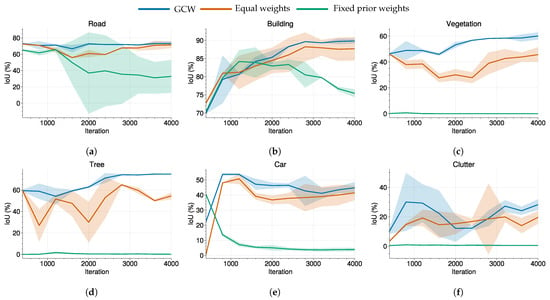
Figure 7.
IoU of each category during the training on POT→VAI. The shaded areas correspond to the 95% confidence intervals. (a) Road. (b) Building. (c) Vegetation. (d) Tree. (e) Car. (f) Clutter.
4.2. LDQ
To begin, we compare our pixel-wise Local Dynamic Quality with the equal quality and image-wise quality [,] in Table 4. It should be noted that the results for the hyper-parameters discussed later are for LDQ applied alone. When LDQ and GCW are used together, we find that the best experimental results are obtained with different hyper-parameters. To be consistent with experiments in Table 1, we used the same or in the following experiments. In equal quality, all generated pseudo-labels are considered correct. In addition, image-wise quality assigns the proportion of pseudo-labels exceeding a threshold of the maximum softmax probability to all these pseudo-labels. In Table 4, our strategy of pixel-wise quality has the best overall performance among these methods. The performance improvement is mainly from the clutter class, where the IoU increased by compared to image-wise quality.
Table 4.
The IoU (%) of each class with different methods of quality on POT→VAI. In LDQ, pseudo-labels’ threshold , and . The results are averaged over three runs.
To better understand the effect of LDQ, we investigate two critical hyper-parameters in LDQ, namely the pseudo-labels threshold and the depth of neighbors K. The first parameter plays a significant role in ST to determine the samples used for training in the target domain [,] and the quality generated by LDQ, while second one controls the range for computing the quality of the pseudo-labels.
First, we explore the influence of threshold on the generation of the high-quality pseudo-labels of the target domain during training via three experiments, where LDQ is applied with three different values and same parameter . To rule out the effect of the performance gap, we choose three experiments with similar quantitative results which can be found in Table A1 in Appendix A. Additionally, three metrics are defined to describe the results: (1) : percentage of high-quality pseudo-labels, (2) : percentage of correct ones in , and (3) : percentage of correct high-quality pseudo-labels.
where is defined in Equation (6) which denotes whether the pseudo-label is high-quality, denotes the Iverson bracket, while denotes the target label at location . Both and are one-hot vectors. The results of , and are illustrated in Figure 8, Figure 9 and Figure 10, respectively. Please note that the pixels around the boundary (black areas in Figure 4 and Figure 5) are ignored in the results.
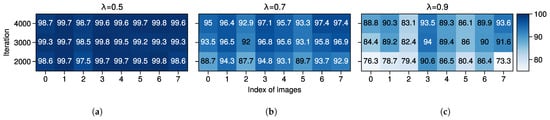
Figure 8.
: Percentage (%) of high-quality pseudo-labels with different threshold on POT→VAI, calculated from eight randomly selected images. (a) = 0.5. (b) = 0.7. (c) = 0.9.

Figure 9.
: Percentage of correct ones in with different threshold on POT→VAI, calculated from the same images in Figure 8. (a) = 0.5. (b) = 0.7. (c) = 0.9.
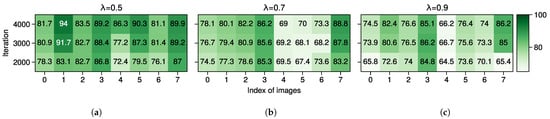
Figure 10.
: Percentage (%) of correct high-quality pseudo-labels with different threshold on POT→VAI, calculated from the same images in Figure 8. (a) = 0.5. (b) = 0.7. (c) = 0.9.
As shown in Figure 8, the results are per our intuitions: (1) the larger the pseudo-label threshold is, the more strict the LDQ will become, and (2) the more iterations the model learns, the more confident it will become in the target domain. Note that the word “strict” describes the strength of the criteria for determining the quality of pseudo-labels, regardless of their correctness. In Figure 9, with the largest threshold , most of the generated pseudo-labels are more accurate and trustworthy compared to the results when except for images 1 and 4. However, with the iteration of the training stage, the correct ratio of some pseudo-labels even decreases, e.g., image 4 in Figure 9b and images 2 and 3 in Figure 9. These results are reasonable since it is challenging to determine whether the generated pseudo-labels are high-quality merely by a threshold value . The results of are shown in Figure 10, which indicates the ratio of correct pseudo-labels practically learned by our model. According to the results, the model learns the maximum proportion of correct pseudo-labels when among these images. The accuracy of pseudo-labels is highest overall when the , as shown in Figure 9c. The least high-quality pseudo-labels are generated in Figure 10c, resulting in a low proportion of correct pseudo-labels learned by the model. This suggests that during the adaptation from POT to VAI, samples with confidence slightly above 0.5 are mostly correct, while those with particularly high confidence are the least correct. We believe that the presence of some features with the same distribution but different categories in the two datasets, i.e., domain gaps, seriously misleads the model. In summary, a larger threshold model generates pseudo-labels with higher accuracy, but it might limit the number of high-quality pseudo-labels, both of which require some trade-off in use. A larger threshold induces the model to predict more accurate but fewer high-quality pseudo-labels, so there is a trade-off between accuracy and quantity.
We investigate the effect of K by analyzing the mean quality of the correct and incorrect pseudo-labels calculated through Equation (7). Similarly, these experiments are conducted with different K but the same pseudo-labels’ threshold , and the results are shown in Figure 11 and Figure 12. The quantitative performance can be found in Table A2 in Appendix A. In the case of , and 4, the average quality of incorrect pseudo-labels is reduced by 11.91%, 11.07%, and 19.14%, respectively, compared to the correct ones at iteration 4000. In comparison to the image-wise quality [,], our strategy improved the quality of pseudo-labels with very little overhead. As for the values of K, it is suggested to pick a proper K to ensure that is below the width of the minimal segmentation target since the data near the boundary are harder to classify and usually get lower confidence.
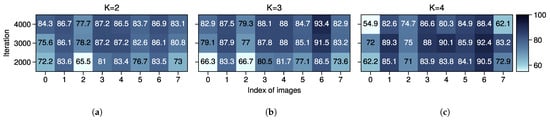
Figure 11.
Averaged quality (%) of incorrect pseudo-labels with different K on POT→VAI, calculated from the same images in Figure 8. (a) K = 2. (b) K = 3. (c) K = 4.
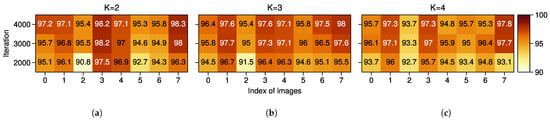
Figure 12.
Averaged quality (%) of correct pseudo-labels with different K on POT→VAI, calculated from the same images in Figure 8. (a) K = 2. (b) K = 3. (c) K = 4.
4.3. Computational Complex Analysis
In this paper, the number of all parameters for the DAFormer [] with MiT-B5 encoder [] is 85.15 M, compared to 62.7 M for DeepLabV3+ []. Although the vision Transformer is larger than CNNs, no auxiliary networks are needed in the self-training framework, so there is no other overhead. For example, the generative-based network structure of ResiDualGAN [] contains two generators and two discriminators, each with 41.82 M and 6.96 M parameters, respectively. Each generator and discriminator has 41.82 M and 6.96 M parameters, respectively, for a total of 97.56 M parameters. As a result, the computational complexity of our method is completely acceptable.
4.4. Limitations
We have verified the effectiveness of the Transformer and proposed GCW and LDQ in UDA for semantic segmentation of RS images. However, there are many unsolved and unexplored issues in our proposed framework. Due to computational constraints, only one type of Transformer with limited iterations has been tested to support our claims. The potential of the vision Transformer in UDA of RS semantic segmentation could be explored in further studies using network architectures such as those proposed in [,,,].
Hoyer et al. [] demonstrated that Transformer outperforms most previous UDA methods using DeepLabV2 [] or DeepLabV3+ []. However, their experiments are based on pre-training and large datasets, which are difficult to achieve in the field of remote sensing. While adapting to a large dataset from a tiny dataset, there might be insufficient data and features available for the elaborate Transformer to learn, which thus derives some inferior and unstable performance. For example, the overall performance on the POT→VAI is better than on VAI→POT since there is more training data in POT. Additionally, the IoU for the clutter category on VAI→POT is close to 0. Therefore, further studies are required to facilitate improvements in the UDA performance with Transformers on small datasets.
In Figure 6, the values of GCW fluctuate at the beginning but eventually become steady. Accordingly, the model does not gain significant additional performance in later iterations but only retrains the advantages obtained in the early stages. The GCW formula could be changed in subsequent iterations to improve domain adaptation to the target domain.
The LDQ is based on the assumption that the model predicts with low confidence for incorrect predictions while producing high confidence for correct predictions. However, it may break down in some cases, such as the domain adaptation between two domains with particularly large gaps. As illustrated in Table 1 and Table 2, the performance with LDQ degrades in some classes compared to the baseline. For instance, the IoU of the car class reduces by 2.91% on POT→VAI, while it decreased from 41.98% to 6.91% on VAI→POT in the vegetation class. Since the results become much more feasible by combining GCW and LDQ, it is suggested to use LDQ with robust strategies for better performance.
5. Conclusions
In this article, we reveal the remarkable potential of the vision Transformer for the task of unsupervised domain adaptation for remote sensing image-semantic segmentation. Additionally, Gradual Class Weights (GCW) and Local Dynamic Quality (LDQ), two simple but effective training strategies working on the source and target domains, respectively, are introduced to stabilize and boost the performance of UDA. Compared to other UDA methods for RS image-semantic segmentation using DeepLabV3+ [], our method improves the state-of-the-art performance by 8.23% mIoU on POT→VAI and 9.2% mIoU on VAI→POT. Notably, GCW improved the performance by addressing the class imbalance problem and allowing healthy convergence at the beginning of the training stage. In addition, LDQ serves by reducing and increasing the weights of the incorrect and correct pseudo-labels, respectively. The two strategies can be effortlessly embedded in various types of semantic segmentation domain-adaptation methods to boost performance. Furthermore, our strategies enable the model to learn even the difficult classes such as clutter/background. In our future work, we will focus on improving UDA performance with Transformers on small datasets.
Author Contributions
Conceptualization, W.L.; methodology, W.L. and H.G.; software, W.L.; validation, Y.S. and B.M.M.; formal analysis, W.L. and B.M.M.; investigation, W.L. and Y.S.; resources, W.L. and H.G.; data curation, W.L. and Y.S.; writing—original draft preparation, W.L. and Y.S.; writing—review and editing, W.L., H.G. and B.M.M.; visualization, W.L.; supervision, H.G. and B.M.M.; project administration, W.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Ministry of Science and Technology of Sichuan Province Program of China, grant number 2022YFG0038.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The Potsdam and Vaihingen datasets are published by the International Society for Photogrammetry and Remote Sensing (ISPRS) and can be accessed at https://www.isprs.org/education/benchmarks/UrbanSemLab/default.aspx, accessed on 21 August 2022.
Acknowledgments
We sincerely thank the anonymous reviewers for their constructive comments and suggestions, which have greatly helped to improve this paper.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
In Section 4.2, we investigated the effects of LDQ with different and K. We choose experiments with similar performance, rather than the best results or mean results, to explore the subtle change between different hyper-parameters. Therefore, some results may differ from the results in Table 1. For reference, detailed quantitative results with different and K are provided in Table A1 and Table A2, respectively.
Table A1.
The IoU (%) of each class with different pseudo-label thresholds on POT→VAI.
Table A1.
The IoU (%) of each class with different pseudo-label thresholds on POT→VAI.
| Clutter | Road | Car | Tree | Vegetation | Building | Overall | |
|---|---|---|---|---|---|---|---|
| 0.5 | 29.59 | 74.86 | 41.2 | 72.56 | 61.28 | 89.92 | 61.57 |
| 0.7 | 31.84 | 70.36 | 39.73 | 75.66 | 55.49 | 90.05 | 60.52 |
| 0.9 | 48.11 | 69.47 | 44.72 | 66.52 | 46.21 | 89.84 | 60.81 |
Table A2.
The IoU (%) of each class with different K on POT→VAI.
Table A2.
The IoU (%) of each class with different K on POT→VAI.
| K | Clutter | Road | Car | Tree | Vegetation | Building | Overall |
|---|---|---|---|---|---|---|---|
| 2 | 32.32 | 70.68 | 41.18 | 65.08 | 37.08 | 89.13 | 55.91 |
| 3 | 38.4 | 64.3 | 36.8 | 63.7 | 42.24 | 89.86 | 55.88 |
| 4 | 35.07 | 69.77 | 36.6 | 53.8 | 46.6 | 88.17 | 55 |
References
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6881–6890. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Xu, Z.; Zhang, W.; Zhang, T.; Yang, Z.; Li, J. Efficient transformer for remote sensing image segmentation. Remote Sens. 2021, 13, 3585. [Google Scholar] [CrossRef]
- Zhang, P.; Zhang, B.; Zhang, T.; Chen, D.; Wang, Y.; Wen, F. Prototypical Pseudo Label Denoising and Target Structure Learning for Domain Adaptive Semantic Segmentation. arXiv 2021, arXiv:2101.10979. [Google Scholar]
- Toldo, M.; Maracani, A.; Michieli, U.; Zanuttigh, P. Unsupervised domain adaptation in semantic segmentation: A review. Technologies 2020, 8, 35. [Google Scholar] [CrossRef]
- Yang, Y.; Soatto, S. Fda: Fourier domain adaptation for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4085–4095. [Google Scholar]
- Ma, H.; Lin, X.; Wu, Z.; Yu, Y. Coarse-to-fine domain adaptive semantic segmentation with photometric alignment and category-center regularization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4051–4060. [Google Scholar]
- Tuia, D.; Munoz-Mari, J.; Gomez-Chova, L.; Malo, J. Graph matching for adaptation in remote sensing. IEEE Trans. Geosci. Remote Sens. 2012, 51, 329–341. [Google Scholar] [CrossRef]
- Rakwatin, P.; Takeuchi, W.; Yasuoka, Y. Restoration of Aqua MODIS band 6 using histogram matching and local least squares fitting. IEEE Trans. Geosci. Remote Sens. 2008, 47, 613–627. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. Dualgan: Unsupervised dual learning for image-to-image translation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2849–2857. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Hoffman, J.; Tzeng, E.; Park, T.; Zhu, J.Y.; Isola, P.; Saenko, K.; Efros, A.; Darrell, T. Cycada: Cycle-consistent adversarial domain adaptation. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1989–1998. [Google Scholar]
- Benjdira, B.; Bazi, Y.; Koubaa, A.; Ouni, K. Unsupervised domain adaptation using generative adversarial networks for semantic segmentation of aerial images. Remote Sens. 2019, 11, 1369. [Google Scholar] [CrossRef]
- Tsai, Y.H.; Hung, W.C.; Schulter, S.; Sohn, K.; Yang, M.H.; Chandraker, M. Learning to adapt structured output space for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7472–7481. [Google Scholar]
- Li, Y.; Shi, T.; Zhang, Y.; Chen, W.; Wang, Z.; Li, H. Learning deep semantic segmentation network under multiple weakly-supervised constraints for cross-domain remote sensing image semantic segmentation. ISPRS J. Photogramm. Remote Sens. 2021, 175, 20–33. [Google Scholar] [CrossRef]
- Cai, Y.; Yang, Y.; Zheng, Q.; Shen, Z.; Shang, Y.; Yin, J.; Shi, Z. BiFDANet: Unsupervised Bidirectional Domain Adaptation for Semantic Segmentation of Remote Sensing Images. Remote Sens. 2022, 14, 190. [Google Scholar] [CrossRef]
- Gao, H.; Zhao, Y.; Guo, P.; Sun, Z.; Chen, X.; Tang, Y. Cycle and Self-Supervised Consistency Training for Adapting Semantic Segmentation of Aerial Images. Remote Sens. 2022, 14, 1527. [Google Scholar] [CrossRef]
- Zhao, Y.; Gao, H.; Guo, P.; Sun, Z. ResiDualGAN: Resize-Residual DualGAN for Cross-Domain Remote Sensing Images Semantic Segmentation. arXiv 2022, arXiv:2201.11523. [Google Scholar]
- Vu, T.H.; Jain, H.; Bucher, M.; Cord, M.; Pérez, P. Advent: Adversarial entropy minimization for domain adaptation in semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 2517–2526. [Google Scholar]
- Zou, Y.; Yu, Z.; Kumar, B.; Wang, J. Unsupervised domain adaptation for semantic segmentation via class-balanced self-training. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 289–305. [Google Scholar]
- Yan, L.; Fan, B.; Xiang, S.; Pan, C. CMT: Cross Mean Teacher Unsupervised Domain Adaptation for VHR Image Semantic Segmentation. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Olsson, V.; Tranheden, W.; Pinto, J.; Svensson, L. Classmix: Segmentation-based data augmentation for semi-supervised learning. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2021; pp. 1369–1378. [Google Scholar]
- Tranheden, W.; Olsson, V.; Pinto, J.; Svensson, L. Dacs: Domain adaptation via cross-domain mixed sampling. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2021; pp. 1379–1389. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Hoyer, L.; Dai, D.; Van Gool, L. Daformer: Improving network architectures and training strategies for domain-adaptive semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 9924–9935. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6023–6032. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Haixiang, G.; Yijing, L.; Shang, J.; Mingyun, G.; Yuanyue, H.; Bing, G. Learning from class-imbalanced data: Review of methods and applications. Expert Syst. Appl. 2017, 73, 220–239. [Google Scholar] [CrossRef]
- Yan, H.; Ding, Y.; Li, P.; Wang, Q.; Xu, Y.; Zuo, W. Mind the class weight bias: Weighted maximum mean discrepancy for unsupervised domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2272–2281. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 818–833. [Google Scholar]
- Olah, C.; Mordvintsev, A.; Schubert, L. Feature Visualization. Distill 2017, 2, e7. [Google Scholar] [CrossRef]
- Goyal, P.; Dollár, P.; Girshick, R.; Noordhuis, P.; Wesolowski, L.; Kyrola, A.; Tulloch, A.; Jia, Y.; He, K. Accurate, large minibatch sgd: Training imagenet in 1 hour. arXiv 2017, arXiv:1706.02677. [Google Scholar]
- International Society for Photogrammetry and Remote Sensing. 2D Semantic Labeling Contest-Potsdam. Available online: https://www.isprs.org/education/benchmarks/UrbanSemLab/2d-sem-label-potsdam.aspx (accessed on 21 August 2022).
- International Society for Photogrammetry and Remote Sensing. 2D Semantic Labeling Contest-Vaihingen. Available online: https://www.isprs.org/education/benchmarks/UrbanSemLab/2d-sem-label-vaihingen.aspx (accessed on 21 August 2022).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Vancouver, BC, Canada, 2019; pp. 8024–8035. [Google Scholar]
- Contributors, M. MMSegmentation: OpenMMLab Semantic Segmentation Toolbox and Benchmark. 2020. Available online: https://github.com/open-mmlab/mmsegmentation (accessed on 21 August 2022).
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Mehta, S.; Rastegari, M.; Shapiro, L.; Hajishirzi, H. Espnetv2: A light-weight, power efficient, and general purpose convolutional neural network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9190–9200. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).