
Automatic Identification of Forest Disturbance Drivers Based on Their Geometric Pattern in Atlantic Forests


Abstract
:
1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Satellite Image Acquisition
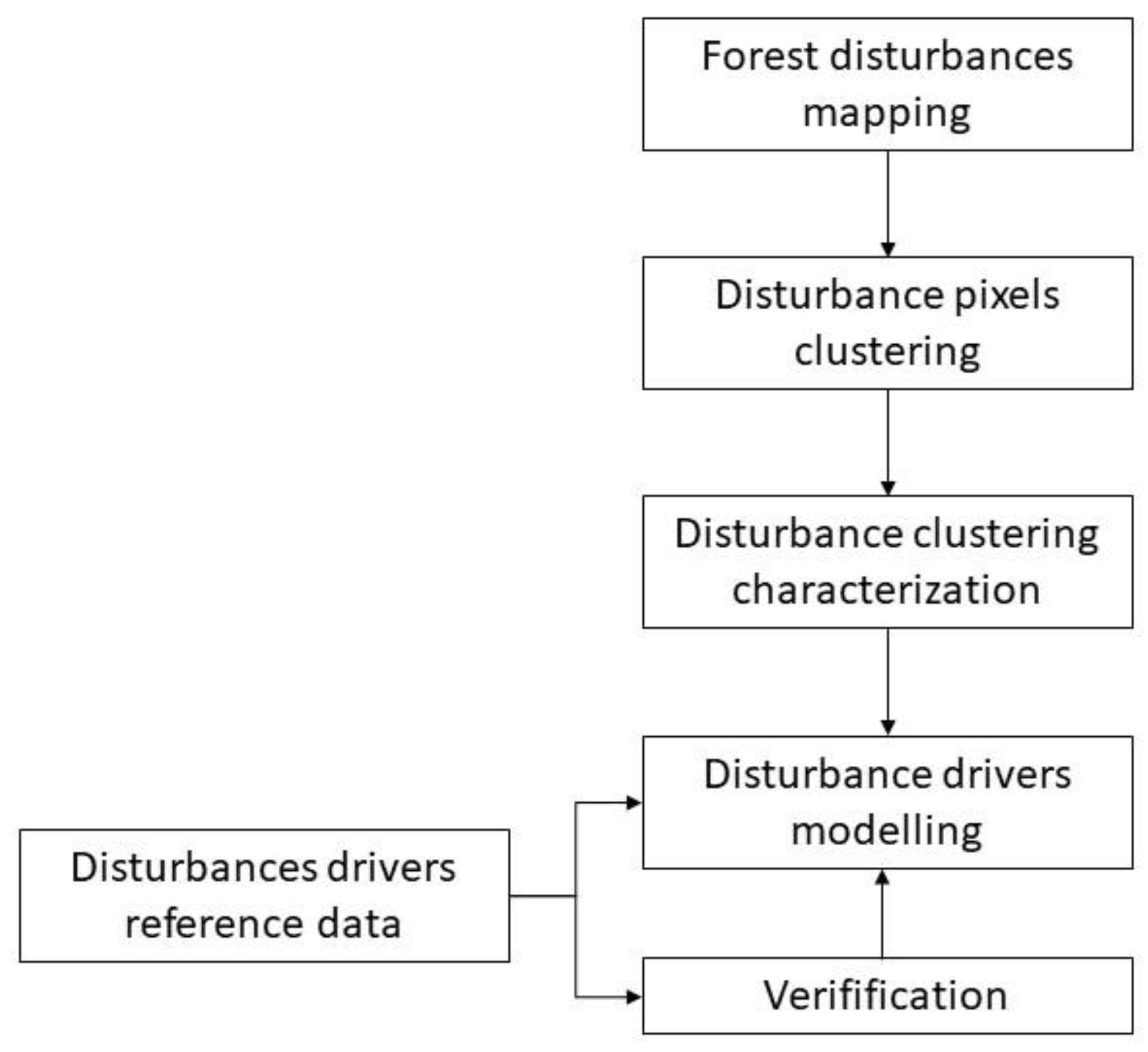
2.3. Main Method
2.3.1. Forest Disturbance Mapping
2.3.2. Disturbance Pixels Clustering
2.3.3. Disturbance Clusters Characterization
2.3.4. Disturbance Drivers Modeling (Wildfires or Harvesting)
3. Results
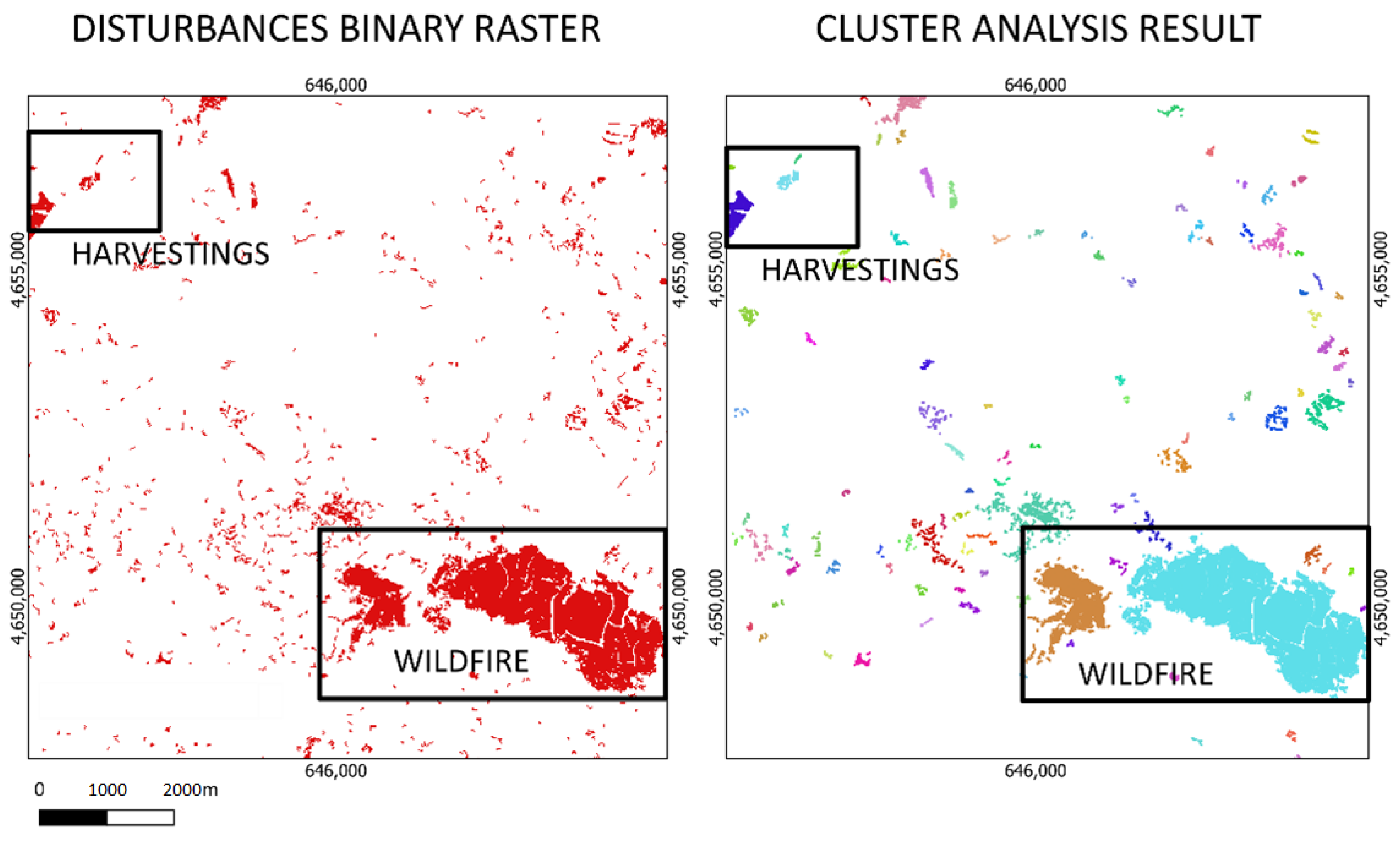
3.1. Disturbances Mapping
3.2. Disturbances Clustering
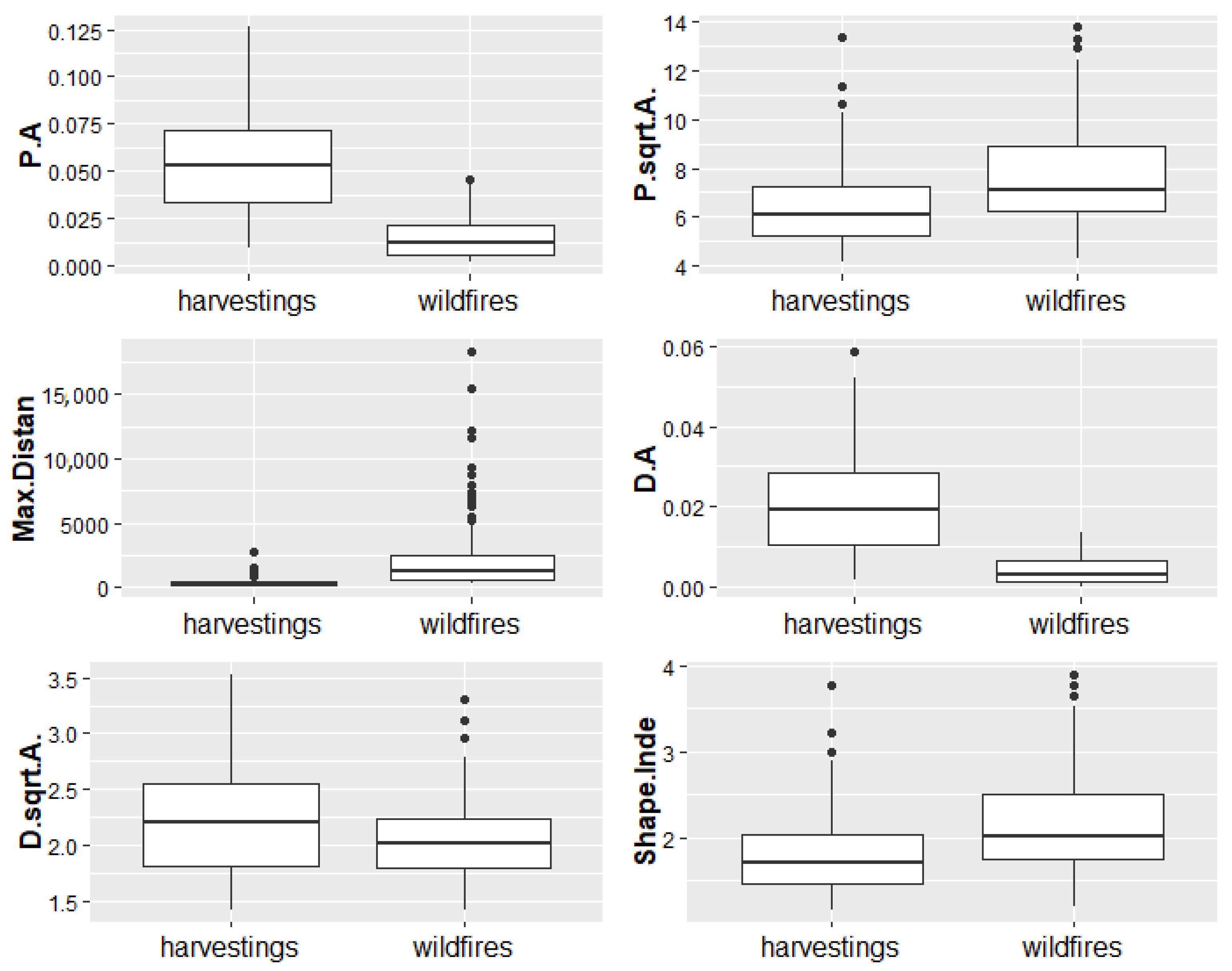
3.3. Disturbances Clusters Characterization
3.4. Disturbance Driver Modeling (Wildfire or Harvesting)
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pan, Y.; Birdsey, R.; Fang, J.; Houghton, R.; Kauppi, P.; Kurz, W.; Phillips, O.; Shvidenko, A.; Lewis, S.; Canadell, J.; et al. Large and Persistent Carbon Sink in the World’s Forests. Science 2011, 333, 988–993. [Google Scholar] [CrossRef] [Green Version]
- Forests in focus. Nat. Clim. Chang. 2021, 11, 363. [CrossRef]
- Ingalls, M.L.; Dwyer, M.B. Missing the forest for the trees? Navigating the trade-offs between mitigation and adaptation under REDD. Clim. Chang. 2016, 136, 353–366. [Google Scholar] [CrossRef]
- Seidl, R.; Thom, D.; Kautz, M.; Martin-Benito, D.; Peltoniemi, M.; Vacchiano, G.; Wild, J.; Ascoli, D.; Petr, M.; Honkaniemi, J.; et al. Forest disturbances under climate change. Nat. Clim. Chang. 2017, 7, 395–402. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- FAO. Better Data, Better Decisions. Towards Impactful Forest Monitoring; Forestry Working Paper No. 16.; FAO: Rome, Italy, 2020. [CrossRef]
- Senf, C.; Seidl, R. Mapping the forest disturbance regimes of Europe. Nat. Sustain. 2021, 4, 63–70. [Google Scholar] [CrossRef]
- United Nations. Paris Agreement. 2015. Available online: https://unfccc.int/process-and-meetings/the-paris-agreement/the-paris-agreement (accessed on 29 October 2021).
- United Nations Department of Economic and Social Affairs. The Global Forest Goals Report 2021. Realizing the Importance of Forests in a Changing World; UN: New York, NY, USA, 2021; ISBN 9789214030515. [Google Scholar] [CrossRef]
- Seidl, R.; Honkaniemi, J.; Aakala, T.; Aleinikov, A.; Angelstam, P.; Bouchard, M.; Boulanger, Y.; Burton, P.J.; De Grandpré, L.; Gauthier, S.; et al. Globally consistent climate sensitivity of natural disturbances across boreal and temperate forest ecosystems. Ecography 2021, 43, 967–978. [Google Scholar] [CrossRef]
- Wang, J.A.; Baccini, A.; Farina, M.; Randerson, J.T.; Friedl, M.A. Disturbance suppresses the aboveground carbon sink in North American boreal forests. Nat. Clim. Chang. 2021, 11, 435–441. [Google Scholar] [CrossRef]
- Dupuy, J.-L.; Fargeon, H.; Martin-StPaul, N.; Pimont, F.; Ruffault, J.; Guijarro, M.; Hernando, C.; Madrigal, J.; Fernandes, P. Climate change impact on future wildfire danger and activity in southern Europe: A review. Ann. For. Sci. 2020, 77, 35. [Google Scholar] [CrossRef]
- Moraes, I.; Azevedo-Ramos, C.; Pacheco, J. Public forests under threat in the Brazilian Amazon: Strategies for coping shifts in environmental policies and regulations. Front. For. Glob. Chang. 2021, 4, 631756. [Google Scholar] [CrossRef]
- Mitchell, A.L.; Rosenqvist, A.; Mora, B. Current remote sensing approaches to monitoring forest degradation in support of countries measurement, reporting and verification (MRV) systems for REDD++. Carbon Balance Manag. 2017, 12, 9. [Google Scholar] [CrossRef] [Green Version]
- Regulation (EU) No 995/2010 of the European Parliament and of the Council of 20 October 2010 Laying down the Obligations of Operators Who Place Timber and Timber Products on the Market; Official Journal of the European Union; European Union: Maastricht, The Netherlands, 2010.
- Wulder, M.A.; Coops, N.C.; Roy, D.P.; White, J.C.; Hermosilla, T. Land cover 2.0. Int. J. Remote Sens. 2018, 39, 4254–4284. [Google Scholar] [CrossRef] [Green Version]
- Hirschmugl, M.; Gallaun, H.; Dees, M.; Datta, P.; Deutscher, J.; Koutsias, N.; Schardt, M. Methods for Mapping Forest Disturbance and Degradation from Optical Earth Observation Data: A Review. Curr. For. Rep. 2017, 3, 32–45. [Google Scholar] [CrossRef] [Green Version]
- Masiliūnas, D.; Tsendbazar, N.-E.; Herold, M.; Verbesselt, J. BFAST Lite: A Lightweight Break Detection Method for Time Series Analysis. Remote Sens. 2021, 13, 3308. [Google Scholar] [CrossRef]
- Verbesselt, J.; Hyndman, R.; Newnham, G.; Culvenor, D. Detecting trend and seasonal changes in satellite image time series. Remote Sens. Environ. 2010, 114, 106–115. [Google Scholar] [CrossRef]
- Verbesselt, J.; Zeileis, A.; Herold, M. Near real-time disturbance detection using satellite image time series. Remote Sens. Environ. 2012, 123, 98–108. [Google Scholar] [CrossRef]
- Kennedy, R.E.; Yang, Z.; Cohen, W.B. Detecting trends in forest disturbance and recovery using yearly Landsat time series: 1. LandTrendr—Temporal segmentation algorithms. Remote Sens. Environ. 2010, 114, 2897–2910. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E. Continuous change detection and classification of land cover using all available Landsat data. Remote Sens. Environ. 2014, 144, 152–171. [Google Scholar] [CrossRef] [Green Version]
- Bustamante, M.M.C.; Roitman, I.; Aide, T.M.; Alencar, A.; Anderson, L.O.; Aragão, L.; Asner, G.P.; Barlow, J.; Berenguer, E.; Chambers, J.; et al. Toward an integrated monitoring framework to assess the effects of tropical forest degradation and recovery on carbon stocks and biodiversity. Glob. Chang. Biol. 2016, 22, 92–109. [Google Scholar] [CrossRef]
- Bowd, E.J.; McBurney, L.; Blair, D.P.; Lindenmayer, D.B. Temporal patterns of forest seedling emergence across different disturbance histories. Ecol. Evol. 2021, 11, 9254–9292. [Google Scholar] [CrossRef]
- Dragotescu, I.; Kneeshaw, D.D. A comparison of residual forest following fires and harvesting in boreal forests in Quebec, Canada. Silva Fenn. 2012, 46, 365–376. [Google Scholar] [CrossRef] [Green Version]
- Kissinger, G.; Herold, M.; De Sy, V. Drivers of Deforestation and Forest Degradation: A Synthesis Report for REDD+ Policymakers; Lexeme Consulting: Vancouver, BC, Canada, 2012. [Google Scholar]
- Patacca, M.; Schelhaas, M.; Zudin, S.; Lindner, M. Database on Forest Disturbances in Europe (DFDE)—Technical Report; Project I-Maestro (ERA-NET Cofund ForestValue); European Forest Institute: Joensuu, Finland, 2020; 18p. [Google Scholar]
- Forzieri, G.; Pecchi, M.; Girardello, M.; Mauri, A.; Klaus, M.; Nikolov, C.; Rüetschi, M.; Gardiner, B.; Tomaštík, J.; Small, D.; et al. A spatially explicit database of wind disturbances in European forests over the period 2000–2018. Earth Syst. Sci. Data 2020, 12, 257–276. [Google Scholar] [CrossRef] [Green Version]
- Ceccherini, G.; Duveiller, G.; Grassi, G.; Lemoine, G.; Avitabile, V.; Pilli, R.; Cescatti, A. Abrupt increase in harvested forest area over Europe after 2015. Nature 2020, 583, 72–77. [Google Scholar] [CrossRef]
- Schepaschenko, D.; See, L.; Lesiv, M.; Bastin, J.-F.; Mollicone, D.; Tsendbazar, N.-E.; Bastin, L.; McCallum, I.; Bayas, J.C.L.; Baklanov, A.; et al. Recent Advances in Forest Observation with Visual Interpretation of Very High-Resolution Imagery. Surv. Geophys. 2019, 40, 839–862. [Google Scholar] [CrossRef] [Green Version]
- Key, C.H.; Benson, N.C. Measuring and remote sensing of burn severity. In Joint Fire Science Conference and Workshop; Neuenschwander, L.F., Ryan, K.C., Eds.; University of Idaho: Moscow, ID, USA, 1999; Volume 2. [Google Scholar]
- Haywood, A.; Verbesselet, J.; Baker, P.J. Mapping disturbance dynamics in wet sclerophyll forests using time series Landsat. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2016, XLI-B8, 633–641. [Google Scholar] [CrossRef] [Green Version]
- Esteban, J.; Fernández-Landa, A.; Tomé, J.L.; Gómez, C.; Marchamalo, M. Identification of Silvicultural Practives in Mediterranean Forests Integrating Landsat Time Series and a Single Coverage of ALS Data. Remote Sens. 2021, 13, 3611. [Google Scholar] [CrossRef]
- Moisen, G.G.; Meyer, M.C.; Schroeder, T.A.; Liao, X.; Schleeweis, K.G.; Freeman, E.A.; Toney, C. Shape selection in Landsat time series: A tool for monitoring forest dynamics. Glob. Chang. Biol 2016, 22, 3518–3528. [Google Scholar] [CrossRef] [PubMed]
- Schroeder, T.A.; Schleeweis, K.G.; Moisen, G.G.; Toney, C.; Cohen, W.B.; Freeman, E.A.; Yang, Z.; Huang, C. Testing a Landsat-based approach for mapping disturbance causality in U.S. forests. Remote Sens. Environ. 2017, 195, 230–243. [Google Scholar] [CrossRef] [Green Version]
- Schroeder, T.A.; Wulder, M.A.; Healey, S.P.; Moisen, G.G. Mapping wildfire and clearcut harvest disturbances in boreal forests with Landsat time series data. Remote Sens. Environ. 2011, 115, 1421–1433. [Google Scholar] [CrossRef]
- Hermosilla, T.; Wulder, M.A.; White, J.C.; Coops, N.C.; Hobart, G.W. Regional detection, characterization, and attribution of annual forest change from 1984 to 2012 using Landsat-derived time-series metrics. Remote Sens. Environ. 2015, 170, 121–132. [Google Scholar] [CrossRef]
- Neigh, C.S.R.; Bolton, D.K.; Williams, J.J.; Diabate, M. Evaluating an Automated Approach for Monitoring Forest Disturbances in the Pacific Northwest from Logging, Fire and Insect Outbreaks with Landsat Time Series Data. Forests 2014, 5, 3169–3198. [Google Scholar] [CrossRef] [Green Version]
- Mcrae, D.J.; Duchesne, L.C.; Freedman, B.; Lynham, T.J.; Woodley, S. Comparisons between wildfire and forest harvesting and their implications in forest management. Environ. Rev. 2011, 9, 223–260. [Google Scholar] [CrossRef]
- Delong, S.C.; Tanner, D. Managing the pattern of forest harvest: Lessons from wildfire. Biodivers. Conserv. 1996, 5, 1191–1205. [Google Scholar] [CrossRef]
- Consellería do Medio Rural, Xunta de Galicia. 1a Revisión Del Plan Forestal de Galicia. 2015. Available online: https://mediorural.xunta.gal/fileadmin/arquivos/forestal/ordenacion/1_REVISION_PLAN_FORESTAL_CAST.pdf (accessed on 3 November 2021).
- Xunta de Galicia. Sistema de Indicadores da Administración Dixital. Producción Forestal. Available online: https://indicadores-forestal.xunta.gal/portal-bi-internet/dashboard/Dashboard.action?selectedScope=OBSFOR_BI_A02_INT&selectedLevel=OBSFOR_BI_2_INT.L0&selectedUnit=12&selectedTemporalScope=2&selectedTemporal=31/12/2020 (accessed on 3 December 2021).
- MAPA (Ministerio de Agricultura Pesca y Alimentación). Mapa Forestal de España a Escla 1:25.000 (MFE25). Available online: https://www.mapa.gob.es/es/desarrollo-rural/temas/politica-forestal/inventario-cartografia/mapa-forestal-espana/mfe_25.aspx (accessed on 3 November 2021).
- MAPA. Los Incendios Forestales en España. Decenio 2006–2015; MAPA: Madrid, Spain, 2019.
- MAPA. Estadísticas de Incendios Forestales. Available online: https://www.miteco.gob.es/es/biodiversidad/estadisticas/Incendios_default.aspx (accessed on 3 November 2021).
- MITERD. Anuario de Estadística Forestal 2018. Available online: https://www.mapa.gob.es/es/desarrollorural/estadisticas/aef_2018_documentocompleto_tcm30-543070.pdf (accessed on 21 July 2021).
- Levers, C.; Verkerk, H.; Müller DVerburg, P.; Butsic VLeitão, P.; Lindner, M.; Kuemmerle, T. Drivers of forest harvesting intensity patterns in Europe. For. Ecol. Manag. 2014, 315, 160–172. [Google Scholar] [CrossRef]
- Gobierno de España. Ministerio de Hacienda. Sede Electrónica del Catastro. 2011. Available online: https://www.sedecatastro.gob.es (accessed on 3 November 2021).
- ESA. European Comission. Sentinel-2. Available online: https://sentinels.copernicus.eu/web/sentinel/missions/sentinel-2 (accessed on 3 November 2021).
- ESA (European Space Agency). Copernicus and European Comission. Copernicus Open Access Hub. Available online: https://scihub.copernicus.eu/dhus/#/home (accessed on 23 July 2021).
- Copernicus. European Forest Fire Information System EFFIS. Available online: https://effis.jrc.ec.europa.eu/ (accessed on 3 November 2021).
- Xunta de Galicia. Consellería do Medio Rural, Inventario Forestal Continuo de Galicia (IFG). Available online: https://mediorural.xunta.gal/gl/temas/forestal/inventario-forestal-continuo (accessed on 3 November 2021).
- MTMAU (Ministerio de Transporte Movilidad y Agenda Urbana). Plan Nacional de Ortofotografía Aérea (PNOA). Available online: https://pnoa.ign.es/ (accessed on 23 July 2021).
- Alonso, L.; Picos, J.; Armesto, J. Forest Land Cover Mapping at a Regional Scale Using Multi-Temporal Sentinel-2 Imagery and RF Models. Remote Sens. 2021, 13, 2237. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Machine Learning 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD’96); AAAI Press: Portland, Oregon, 1996; pp. 226–231. [Google Scholar]
- Moreira, A.J.C.; Santos, M.Y. Concave hull: A k-nearest neighbours approach for the computation of the region occupied by a set of points. In GRAPP 2007, Proceedings of the Second International Conference on Computer Graphics Theory and Applications; Barcelona, Spain, 8–11 March 2007.
- Forman, R.T.T.; Godron, M. Landscape Ecology; John Wiley & Sons: New York, NY, USA, 1986. [Google Scholar]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Wadsworth: Boca Raton, FL, USA, 1984. [Google Scholar]
- Jin, S.; Yang, L.; Zhu, Z.; Homer, C. A land cover change detection and classification protocol for updating Alaska NLCD 2001 to 2011. Remote Sens. Environ. 2017, 195, 44–55. [Google Scholar] [CrossRef]
- López-Amoedo, A.; Álvarez, X.; Lorenzo, H.; Rodríguez, J.L. Multi-Temporal Sentinel-2 Data Analysis for Smallholding Forest Cut Control. Remote Sens. 2021, 13, 2983. [Google Scholar] [CrossRef]
- Therneau, T.; Atkinson, B. Rpart: Recursive Partitioning and Regression Trees. R Package Version 4.1-15. 2019. Available online: https://CRAN.R-project.org/package=rpart (accessed on 27 January 2021).
- Senf, C.; Seidl, R. Natural disturbances are spatially diverse but temporally synchronized across temperate forest landscapes in Europe. Glob. Chang. Biol. 2018, 24, 1201–1211. [Google Scholar] [CrossRef]
- Murillo-Sandoval, P.J.; Hilker, T.; Krawchuk, M.A.; Van Den Hoek, J. Detecting and Attributing Drivers of Forest Disturbance in the Colombian Andes Using Landsat Time-Series. Forests 2018, 9, 269. [Google Scholar] [CrossRef] [Green Version]
- De Marzo, T.; Pflugmacher, D.; Baumann, M.; Lambin, E.F.; Gasparri, I.; Kuemmerle, T. Characterizing forest disturbances across the Argentine Dry Chaco based on Landsat time series. Int. J. Appl. Earth Obs. Geoinf. 2021, 98, 102310. [Google Scholar] [CrossRef]
- Zhu, Z. Change detection using landsat time series: A review of frequencies, preprocessing, algorithms, and applications. ISPRS J. Photogramm. Remote Sens. 2017, 130, 370–384. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | Description |
|---|---|
| mdmin | The average of the minimum distance from each pixel to the nearest pixel in the cluster. To obtain this, a matrix was computed containing the distances from each pixel to its nearest pixel. Then the mean of the values contained in the minimum-distance matrix was calculated. |
| mdmax | The average of the maximum distance from each pixel to the farthest pixel in the cluster. To obtain this, a matrix was computed containing the distance from each pixel to its farthest pixel. Then the mean of the values contained in the maximum-distance matrix was calculated. |
| mdmean | The average of the average distances from each pixel to the rest of the cluster pixels. To obtain this, a matrix was computed containing the average of the distances from each pixel to the rest of the pixels. Then the mean of the values contained in the mean-distance matrix was calculated. |
| mdsd | The average of the standard deviation of the distances from each pixel to the rest of the cluster pixels. To obtain this, a matrix was computed containing the standard deviation of the distances from each pixel to the rest of the pixels. Then the mean of the values contained in the standard-deviation matrix was calculated. |
| mdkur | The average of the kurtosis of the distances from each pixel to the rest of the cluster pixels. To obtain this, a matrix was computed containing the kurtosis of the distances from each pixel to the rest of the pixels. Then the mean of the values contained in the kurtosis matrix was calculated. |
| mdskew | The average of the skewness of the distances from each pixel to the rest of the cluster pixels. To obtain this, a matrix was computed containing the skewness of the distances from each pixel to the rest of the pixels. Then the mean of the values contained in the skewness matrix was calculated. |
| Metric | Description |
|---|---|
| dmeanCOG | The average distance from each of the cluster of pixels to the cluster’s center of gravity. |
| dminCOG | The distance from the closest cluster of pixels to the cluster’s center of gravity. |
| dmaxCOG | The distance from the farthest cluster of pixels to the cluster’s center of gravity. |
| dsdCOG | The standard deviation of the distances of each of the clusters of pixels to the cluster’s center of gravity. |
| dkurtCOG | The kurtosis of the distances of each of the clusters of pixels to the cluster’s center of gravity. |
| dskewCOG | The skewness of the distances of each of the clusters of pixels to the cluster’s center of gravity. |
| Metric | Description |
|---|---|
| P.A | The perimeter of the polygon divided by its area. |
| P.sqrt.A | The perimeter of the polygon divided by the square root of its area. |
| Max.Distan | The maximum diameter calculated as the maximum distance between the vertices of two of the polygon’s parts. |
| D.A | The Max.Distan divided by the area of the polygon. |
| D.sqrt.A | The Max.Distan divided by the square root of the polygon’s area. |
| Shape Index (Shap.Inde) | The inverse of the ratio of the perimeter of the equivalent circle to the real perimeter. See Equation (1) [57]. |
| Ground Truth | |||||
|---|---|---|---|---|---|
| Decision tree | Harvestings | Wildfires | Total | UA (%) | |
| Harvestings | 34 | 5 | 39 | 87 | |
| Wildfires | 3 | 49 | 52 | 94 | |
| 22Total | 37 | 54 | 91 | ||
| PA (%) | 92 | 91 | OA (%) | 91 | |
| KI | 0.82 | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alonso, L.; Picos, J.; Armesto, J. Automatic Identification of Forest Disturbance Drivers Based on Their Geometric Pattern in Atlantic Forests. Remote Sens. 2022, 14, 697. https://doi.org/10.3390/rs14030697
Alonso L, Picos J, Armesto J. Automatic Identification of Forest Disturbance Drivers Based on Their Geometric Pattern in Atlantic Forests. Remote Sensing. 2022; 14(3):697. https://doi.org/10.3390/rs14030697
Chicago/Turabian StyleAlonso, Laura, Juan Picos, and Julia Armesto. 2022. "Automatic Identification of Forest Disturbance Drivers Based on Their Geometric Pattern in Atlantic Forests" Remote Sensing 14, no. 3: 697. https://doi.org/10.3390/rs14030697