
Vehicle Target Detection Method for Wide-Area SAR Images Based on Coarse-Grained Judgment and Fine-Grained Detection

 and
and
Abstract
:1. Introduction
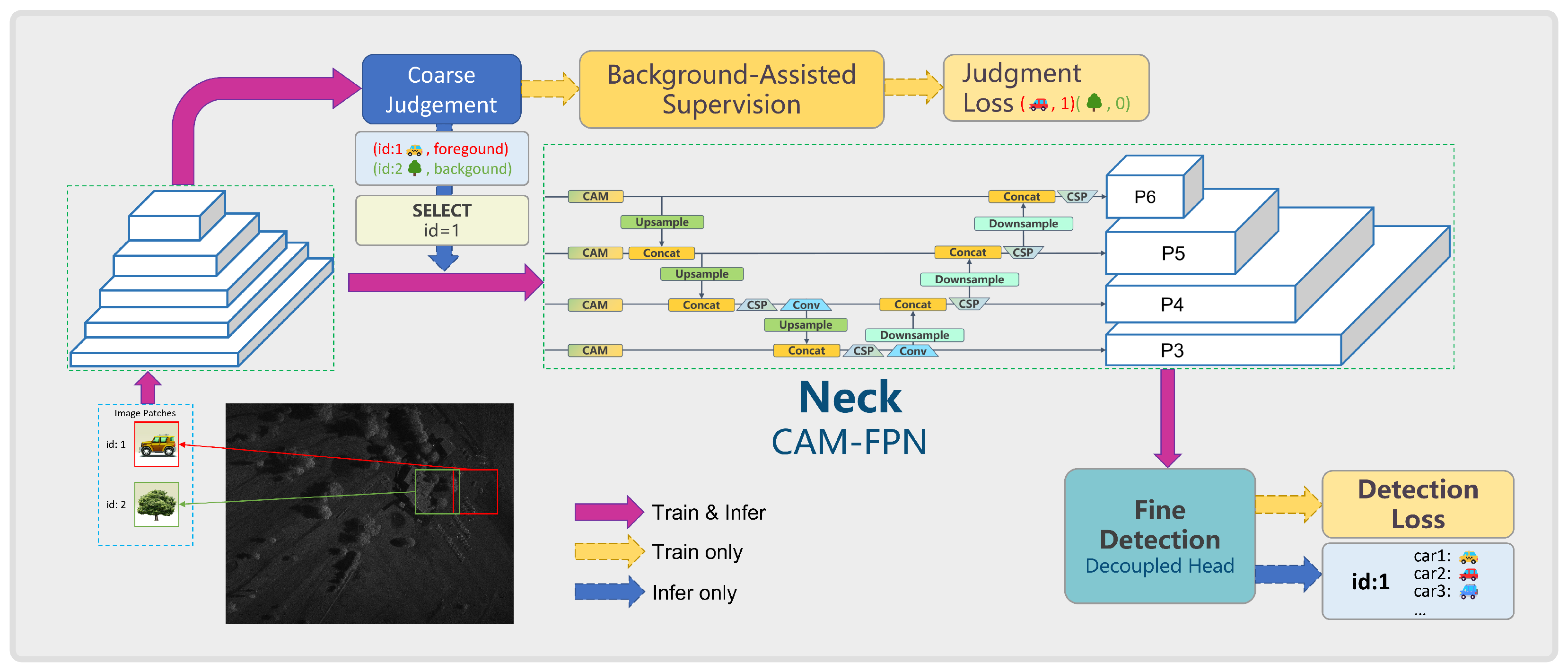
2. Methods
2.1. Coarse Judgment with Assisted Supervision
2.1.1. Coarse Judgment and Optimization
2.1.2. Judgment-Assisted Supervision
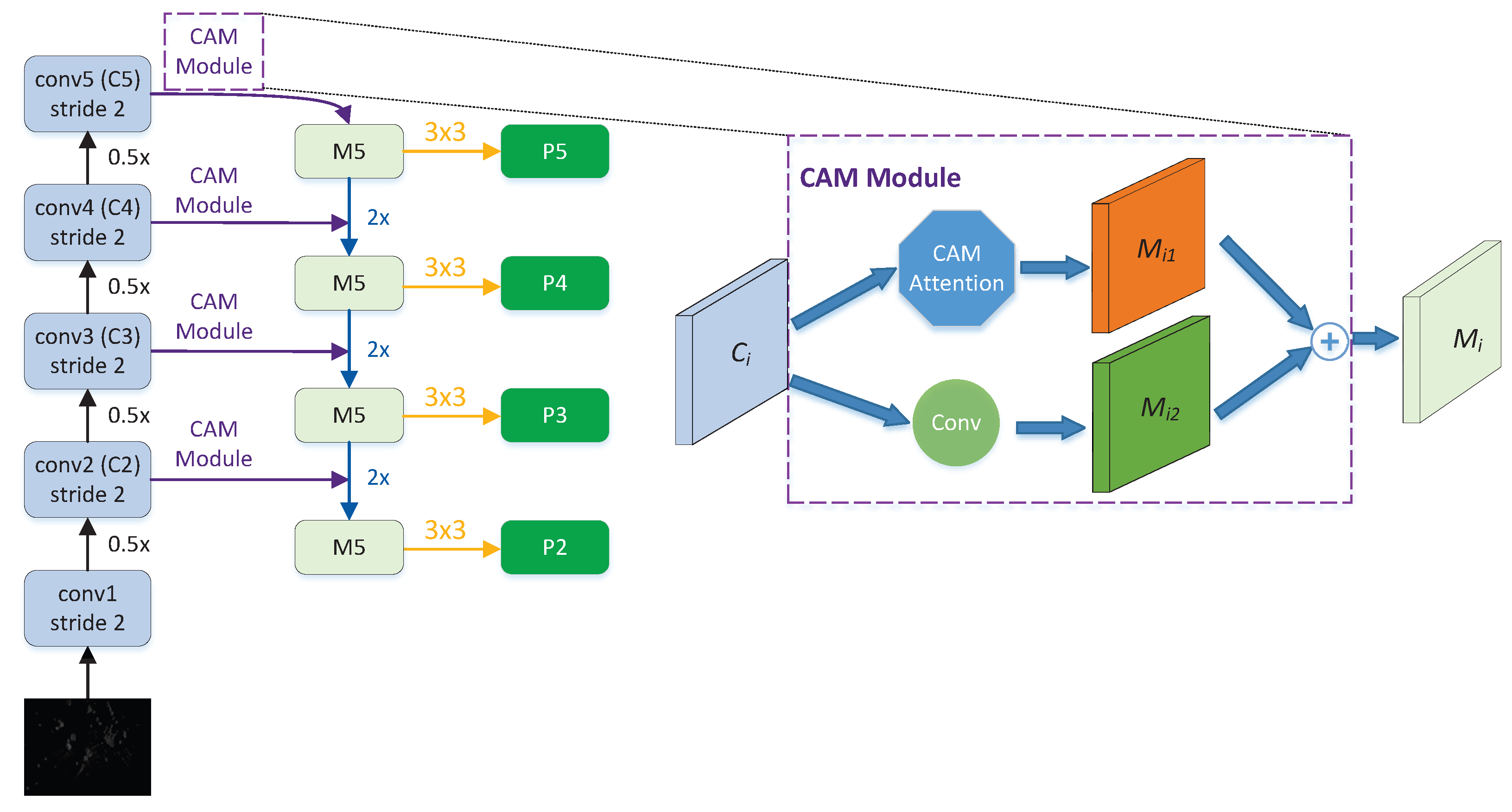
2.2. CAM and Improved Feature Pyramid Network
2.2.1. CAM Attention Layer
2.2.2. CAM-FPN: Improved FPN Network with CAM Module
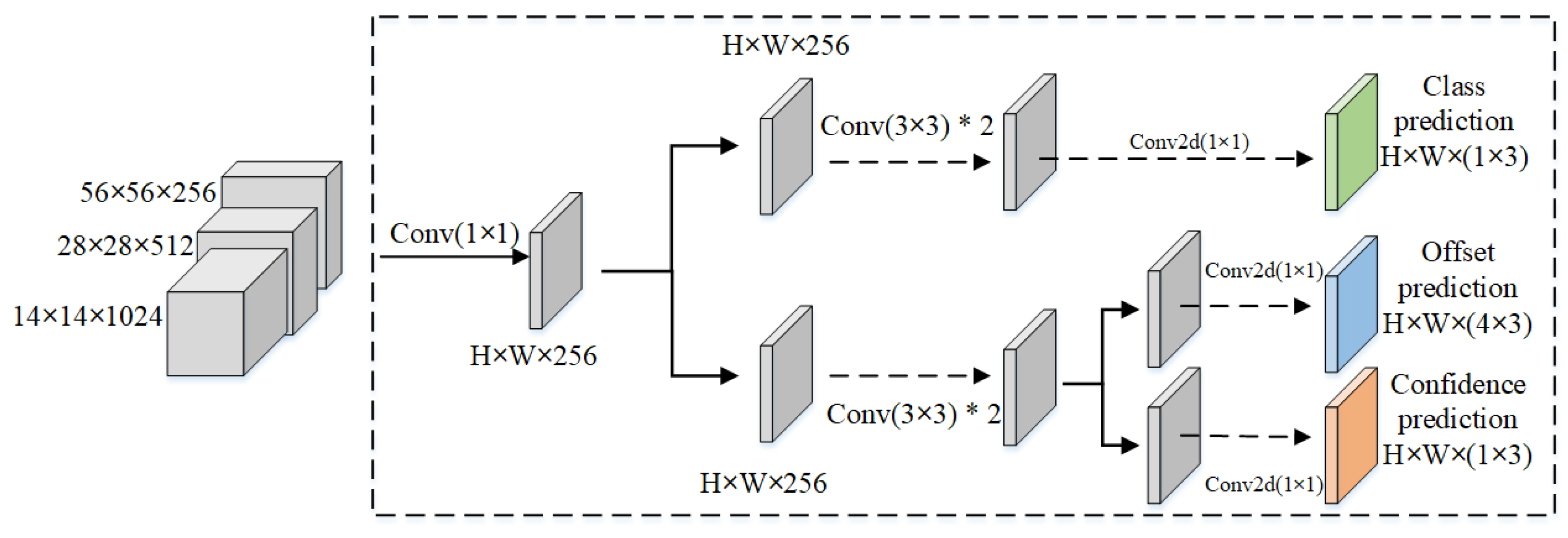
2.3. Decoupled Detection Head
3. Experiment
3.1. Dataset
3.1.1. MiniSAR Dataset
3.1.2. MSTAR Dataset
3.1.3. Wide-Area SAR Vehicle Detection Dataset, WSVD
- (1)
- Target and background fusion. To simplify program processing, we first annotated each vehicle target image using annotation software, obtaining a series of XML files that record the position information of each vehicle target image. Next, based on the insertion point coordinates in the background image, we could quickly calculate the new annotation information of the vehicle target in the background image. However, not all of the 100 clutter background images were appropriate for inserting vehicle targets, such as the two images shown in Figure 9, since it is known that a car could not appear on a tree or building. Figure 9a displays a scene of a forest area, densely blanketed with vegetation, leaving almost no visible ground surface. Figure 9b illustrates a compact region featuring a mix of structures and greenery. The structures sit tightly clustered, with meager gaps, diminishing the probability of accommodating vehicle targets. To prevent vehicles from appearing in unreasonable positions, we manually selected the insertion points in each image.The following steps describe the method of fusing and generating vehicle target images with complex background clutter images:
- (a)
- Assume that A is the target image, where the vehicle target’s bounding box is defined by the coordinates of the upper left corner and the lower right corner . Let B be the complex background image, and be the insertion point manually chosen in B.
- (b)
- First, align the upper left corner of the target image A to the insertion point , and then find a region in the background image B that matches the size of A. Next, convert both A and to HSV space, where V represents the image brightness, and compute the mean values of A and on the V channel, denoted as and , respectively. Then, multiply the V channel values of A in HSV space by , obtaining the adjusted image . Finally, convert from HSV space back to BGR space, resulting in the final image .
- (c)
- Substitute with , thus successfully embedding the target image A into the background image B.
- (2)
- Train and test set creation. From 100 complex background images, we randomly selected 75 for the training set and 23 for the test set (excluding two background images without suitable insertion points). We composited 2747 vehicle target images at 2756 manually selected insertion points in the 75 background images using the previously described method. Since the synthesized wide-area SAR images containing various military vehicle targets were too large for direct training, we applied the same cropping method as used for MiniSAR images. After cropping, we generated 1194 initial training images as DATASET_INIT. We then used a static optical expansion method based on image augmentation to process the SAR images in DATASET_INIT, creating corresponding expanded training samples. We selected 73 images for each vehicle category from the test vehicle target images, totaling 730 vehicle target images, and randomly pasted them onto the 727 insertion points in the 23 test background images. Ultimately, we constructed 23 test images. The numbers of training and test sets are provided in Table 2. Figure 10 displays two of the synthesized images. Figure 10a depicts the simulation results of fusing vehicle targets in a wide-area and flat terrain area, where multiple vehicle targets are uniformly distributed on the ground. Figure 10b demonstrates the simulation results of adding vehicle targets in a dense area with trees, vegetation and buildings, where only the regions with adequate space for vehicle parking are selected to fuse simulated vehicle targets, due to the occurrence of some areas covered by dense vegetation.
3.2. Experiments on CF-YOLO
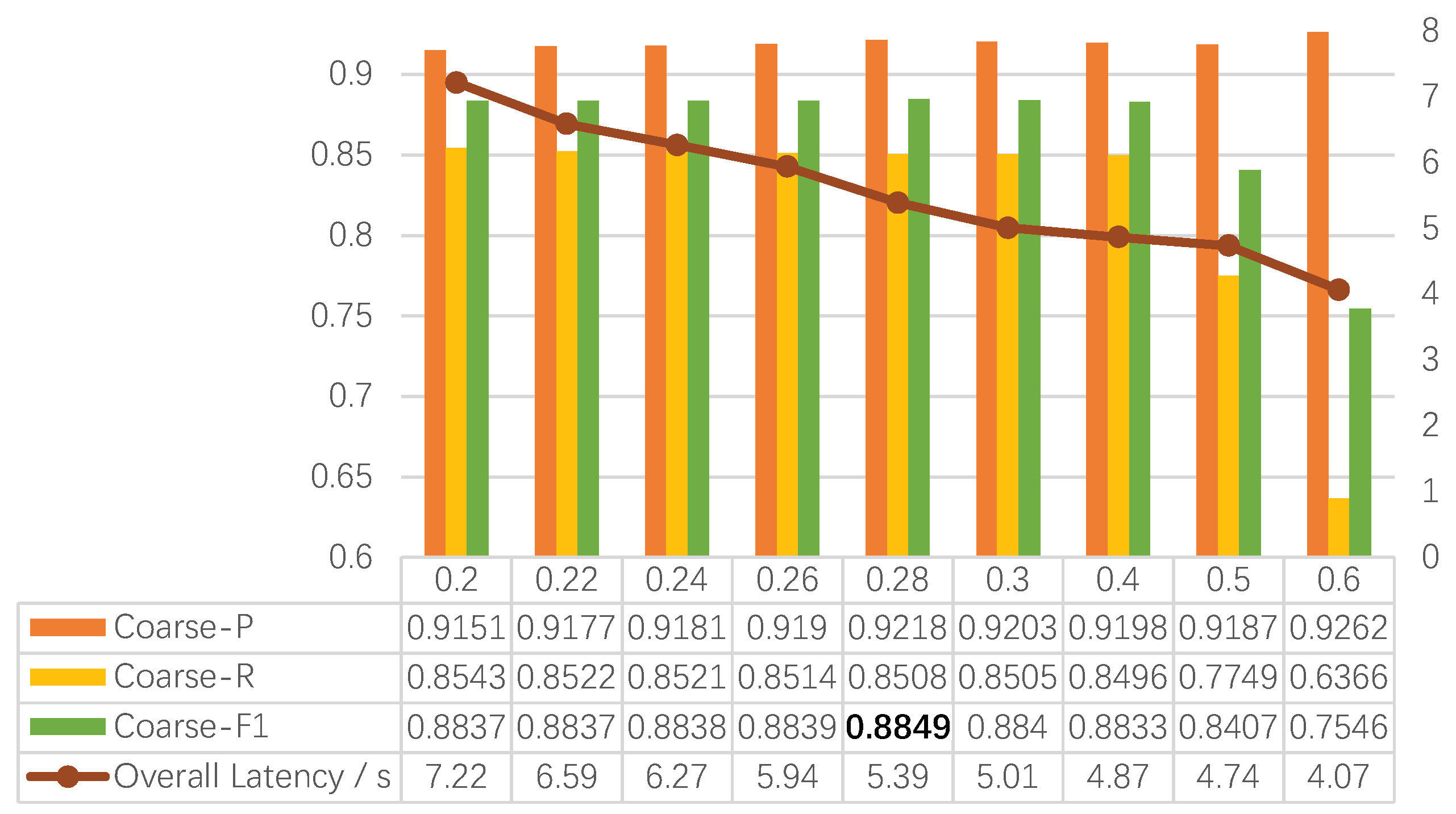
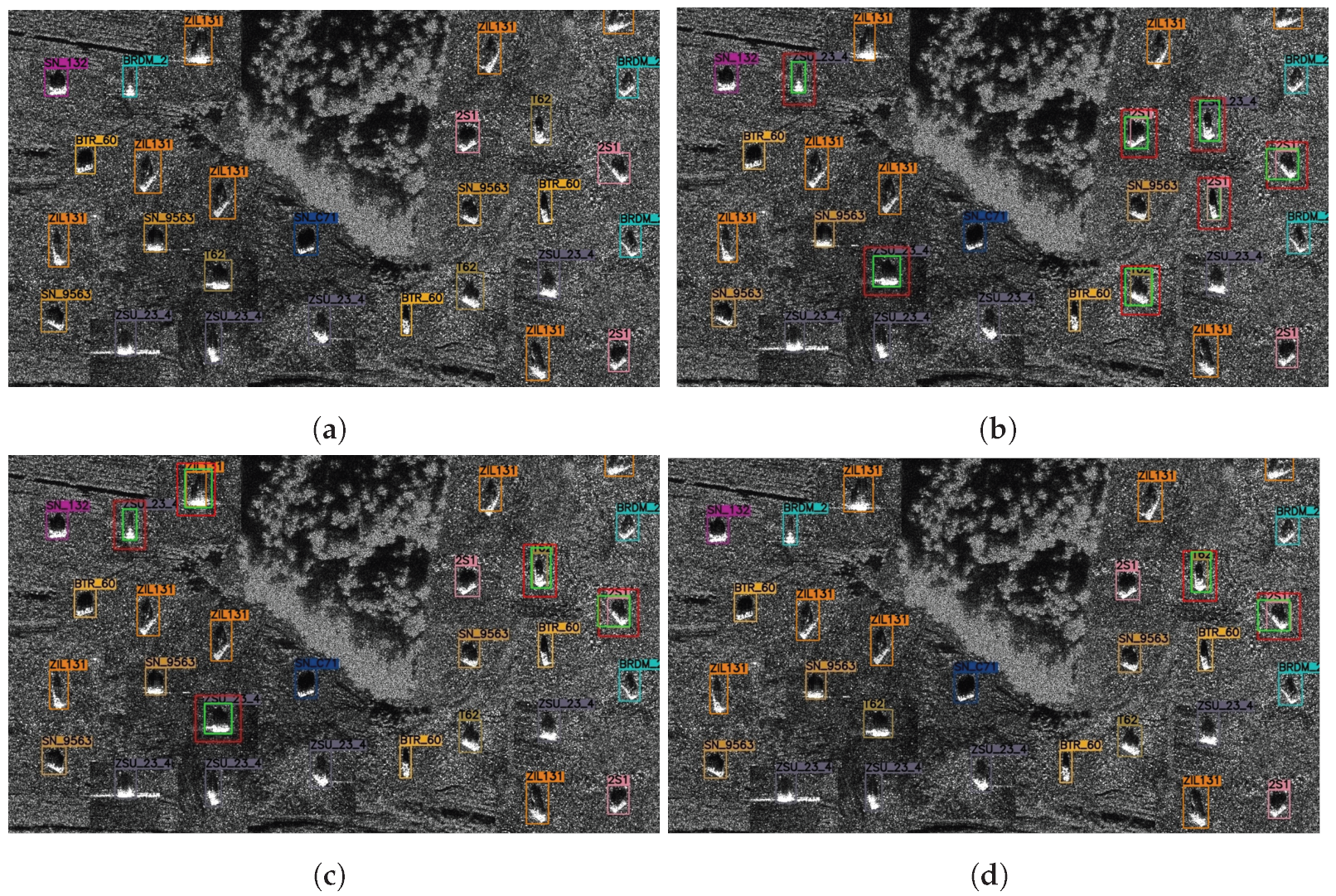
3.3. Experiments for the Coarse Judgment Branch
3.4. Comparison Experiments for Detection Optimization
3.5. Performance Comparison with Other Algorithms
3.6. Supplementary Experiments of Post-Processing of Bounding Boxes
3.7. Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Buckreuss, S.; Schättler, B.; Fritz, T.; Mittermayer, J.; Kahle, R.; Maurer, E.; Böer, J.; Bachmann, M.; Mrowka, F.; Schwarz, E.; et al. Ten years of TerraSAR-X operations. Remote Sens. 2018, 10, 873. [Google Scholar] [CrossRef] [Green Version]
- Balss, U.; Gisinger, C.; Eineder, M. Measurements on the absolute 2-D and 3-D localization accuracy of TerraSAR-X. Remote Sens. 2018, 10, 656. [Google Scholar] [CrossRef] [Green Version]
- Lanari, R.; Ali, Z.; Banano, M.; Buonanno, S.; Casu, F.; De Luca, C.; Fusco, A.; Manunta, M.; Manzo, M.; Onorato, G.; et al. Ground Deformation Analysis of the Italian Peninsula Through the Sentinel-1 P-SBAS Processing Chain. In Proceedings of the IGARSS 2020–2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 4065–4068. [Google Scholar]
- Franceschetti, G.; Lanari, R. Synthetic Aperture Radar Processing; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Shen, X.; Anagnostou, E.N.; Allen, G.H.; Brakenridge, G.R.; Kettner, A.J. Near-real-time non-obstructed flood inundation mapping using synthetic aperture radar. Remote Sens. Environ. 2019, 221, 302–315. [Google Scholar] [CrossRef]
- Novak, L.M.; Halversen, S.D.; Owirka, G.; Hiett, M. Effects of polarization and resolution on SAR ATR. IEEE Trans. Aerosp. Electron. Syst. 1997, 33, 102–116. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhu, D.; Mao, X.; Yu, X.; Zhang, J.; Li, Y. Multirotors Video Synthetic Aperture Radar: System Development and Signal Processing. IEEE Aerosp. Electron. Syst. Mag. 2020, 35, 32–43. [Google Scholar] [CrossRef]
- Hou, X.; Ao, W.; Song, Q.; Lai, J.; Wang, H.; Xu, F. FUSAR-Ship: Building a high-resolution SAR—AIS matchup dataset of Gaofen-3 for ship detection and recognition. Sci. China Inf. Sci. 2020, 63, 140303. [Google Scholar] [CrossRef] [Green Version]
- Huang, L.; Liu, B.; Li, B.; Guo, W.; Yu, W.; Zhang, Z.; Yu, W. OpenSARShip: A Dataset Dedicated to Sentinel-1 Ship Interpretation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 195–208. [Google Scholar] [CrossRef]
- Huang, Z.; Pan, Z.; Lei, B. What, Where, and How to Transfer in SAR Target Recognition Based on Deep CNNs. IEEE Trans. Geosci. Remote Sens. 2019, 58, 2324–2336. [Google Scholar] [CrossRef] [Green Version]
- Huang, P.; Xia, X.G.; Liao, G.; Yang, Z.; Zhou, J.; Liu, X. Ground moving target refocusing in SAR imagery using scaled GHAF. IEEE Trans. Geosci. Remote Sens. 2017, 56, 1030–1045. [Google Scholar] [CrossRef]
- Stacy, N.; Burgess, M.; Muller, M.; Smith, R. Ingara: An integrated airborne imaging radar system. In Proceedings of the IGARSS’96. 1996 International Geoscience and Remote Sensing Symposium, Lincoln, NE, USA, 28 May 1996; Volume 3, pp. 1618–1620. [Google Scholar]
- Chen, S.; Wang, H.; Xu, F.; Jin, Y. Target Classification Using the Deep Convolutional Networks for SAR Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4806–4817. [Google Scholar] [CrossRef]
- Singh, P.; Diwakar, M.; Shankar, A.; Shree, R.; Kumar, M. A Review on SAR Image and its Despeckling. Arch. Comput. Methods Eng. 2021, 28, 4633–4653. [Google Scholar] [CrossRef]
- Greco, M.S.; Gini, F. Statistical analysis of high-resolution SAR ground clutter data. IEEE Trans. Geosci. Remote Sens. 2007, 45, 566–575. [Google Scholar] [CrossRef]
- Posner, F.L. Texture and speckle in high resolution synthetic aperture radar clutter. IEEE Trans. Geosci. Remote Sens. 1993, 31, 192–203. [Google Scholar] [CrossRef]
- Ai, J.; Yang, X.; Song, J.; Dong, Z.; Jia, L.; Zhou, F. An Adaptively Truncated Clutter-Statistics-Based Two-Parameter CFAR Detector in SAR Imagery. IEEE J. Ocean. Eng. 2018, 43, 267–279. [Google Scholar] [CrossRef]
- Lanz, P.; Marino, A.; Simpson, M.D.; Brinkhoff, T.; Köster, F.; Möller, M. The InflateSAR Campaign: Developing Refugee Vessel Detection Capabilities with Polarimetric SAR. Remote Sens. 2023, 15, 2008. [Google Scholar] [CrossRef]
- El-Darymli, K.; McGuire, P.; Power, D.; Moloney, C. Target detection in synthetic aperture radar imagery: A state-of-the-art survey. J. Appl. Remote Sens. 2013, 7, 071598. [Google Scholar] [CrossRef] [Green Version]
- Qin, X.; Zhou, S.; Zou, H.; Gao, G. A CFAR detection algorithm for generalized gamma distributed background in high-resolution SAR images. IEEE Geosci. Remote Sens. Lett. 2012, 10, 806–810. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 17–30 June 2016. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, Hi, USA, 21–26 July 2017. [Google Scholar] [CrossRef] [Green Version]
- Farhadi, A.; Redmon, J. Yolov3: An incremental improvement. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; Springer: Berlin/Heidelberg, Germany, 2018; Volume 1804, pp. 1–6. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single Shot Multibox Detector; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Elfwing, S.; Uchibe, E.; Doya, K. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning. Neural Netw. 2018, 107, 3–11. [Google Scholar] [CrossRef]
- Ghiasi, G.; Cui, Y.; Srinivas, A.; Qian, R.; Lin, T.Y.; Cubuk, E.D.; Le, Q.V.; Zoph, B. Simple Copy-Paste is a Strong Data Augmentation Method for Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Lewis, B.; Scarnati, T.; Sudkamp, E.; Nehrbass, J.; Rosencrantz, S.; Zelnio, E. A SAR dataset for ATR development: The Synthetic and Measured Paired Labeled Experiment (SAMPLE). In Proceedings of the Algorithms for Synthetic Aperture Radar Imagery XXVI, Baltimore, MD, USA, 18 April 2019; Volume 10987, pp. 39–54. [Google Scholar]
- Laboratories, S.N. 2006—Mini SAR Complex Imagery. 2023. Available online: https://www.sandia.gov/radar/pathfinder-radar-isr-and-synthetic-aperture-radar-sar-systems/complex-data/ (accessed on 15 February 2023).
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef] [Green Version]
- Mao, A.; Mohri, M.; Zhong, Y. Cross-Entropy Loss Functions: Theoretical Analysis and Applications. arXiv 2023, arXiv:2304.07288. [Google Scholar]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef] [Green Version]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef] [Green Version]
- Lin, Z.; Ji, K.; Leng, X.; Kuang, G. Squeeze and Excitation Rank Faster R-CNN for Ship Detection in SAR Images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 751–755. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13708–13717. [Google Scholar] [CrossRef]
- Wu, Y.; Chen, Y.; Yuan, L.; Liu, Z.; Wang, L.; Li, H.; Fu, Y. Rethinking Classification and Localization for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10183–10192. [Google Scholar] [CrossRef]
- Song, G.; Liu, Y.; Wang, X. Revisiting the Sibling Head in Object Detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [Green Version]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| D7 | BTR60 | 2S1 | T62 | BRDM2 | BMP2 | ZSU234 | ZIL131 | T72 | BTR70 |
|---|---|---|---|---|---|---|---|---|---|
| Bulldozer | Armored car 1 | Howitzer car | Tank 1 | Armored car 2 | Infantry fighting vehicle | Anti-aircraft vehicle | Military truck | Tank 2 | Armored car 3 |
| Synthesized | Cropped Patches | Expansion Ratio | Expanded Patches | |
|---|---|---|---|---|
| Train Set | 75 | 1194 | 10 | 13,134 |
| Test Set | 23 | no cropping | - | - |
| Experimental Model | mAP (%) |
|---|---|
| YOLOv5 (Base) | 91.69 |
| Base + CAM-FPN (C) | 93.87 |
| Base + Decoupled head (D) | 92.51 |
| Base + Auxiliary Supervision (AS) | 92.86 |
| Base + C + D | 94.82 |
| Base + C + D + AS | 95.02 |
| Base + C + D + AS + Judgment Optimization | 95.55 |
| Threshold | Accuracy |
|---|---|
| 0.28 | 0.9571 |
| 0.4 | 0.9134 |
| 0.5 | 0.7441 |
| Model | Number of Parameters | Overall Latency (s) | mAP (%) |
|---|---|---|---|
| Imp: baseline + C + D + AS | 46,186,759 | 13.22 | 95.02 |
| Imp. + Judgment Optimization | 53,651,143 | 5.39 | 95.55 |
| Method | mAP (%) | Overall Latency (s) |
|---|---|---|
| FasterRCNN [43] | 87.86 | 17.71 |
| RetinaNet | 91.60 | 15.37 |
| CF-YOLO | 95.55 | 5.39 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, Y.; Wang, S.; Li, Q.; Mu, H.; Feng, R.; Tian, T.; Tian, J. Vehicle Target Detection Method for Wide-Area SAR Images Based on Coarse-Grained Judgment and Fine-Grained Detection. Remote Sens. 2023, 15, 3242. https://doi.org/10.3390/rs15133242
Song Y, Wang S, Li Q, Mu H, Feng R, Tian T, Tian J. Vehicle Target Detection Method for Wide-Area SAR Images Based on Coarse-Grained Judgment and Fine-Grained Detection. Remote Sensing. 2023; 15(13):3242. https://doi.org/10.3390/rs15133242
Chicago/Turabian StyleSong, Yucheng, Shuo Wang, Qing Li, Hongbin Mu, Ruyi Feng, Tian Tian, and Jinwen Tian. 2023. "Vehicle Target Detection Method for Wide-Area SAR Images Based on Coarse-Grained Judgment and Fine-Grained Detection" Remote Sensing 15, no. 13: 3242. https://doi.org/10.3390/rs15133242
APA StyleSong, Y., Wang, S., Li, Q., Mu, H., Feng, R., Tian, T., & Tian, J. (2023). Vehicle Target Detection Method for Wide-Area SAR Images Based on Coarse-Grained Judgment and Fine-Grained Detection. Remote Sensing, 15(13), 3242. https://doi.org/10.3390/rs15133242