

Oriented Object Detection in Aerial Images Based on the Scaled Smooth L1 Loss Function

Abstract
1. Introduction
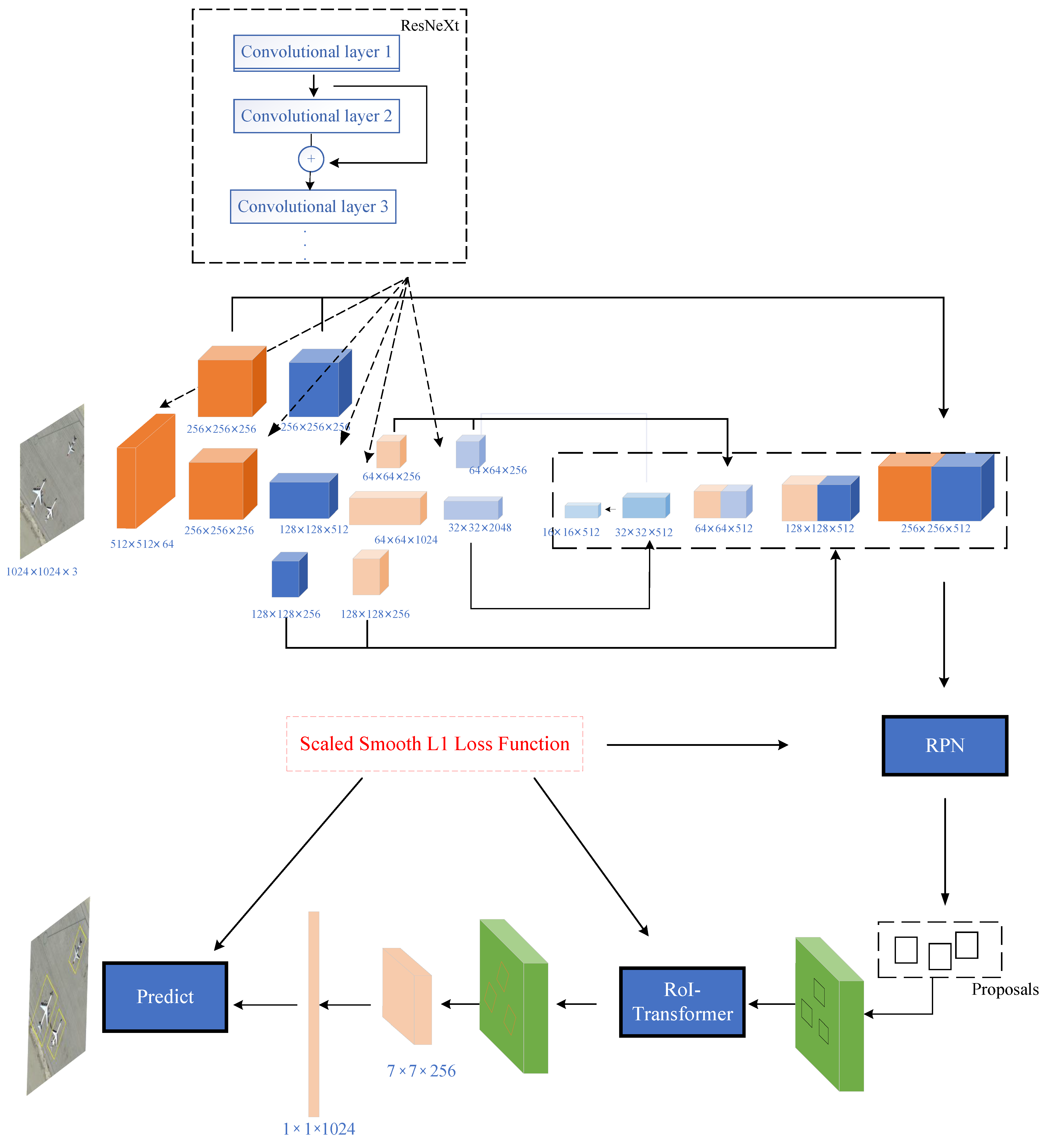
2. The Proposed Method
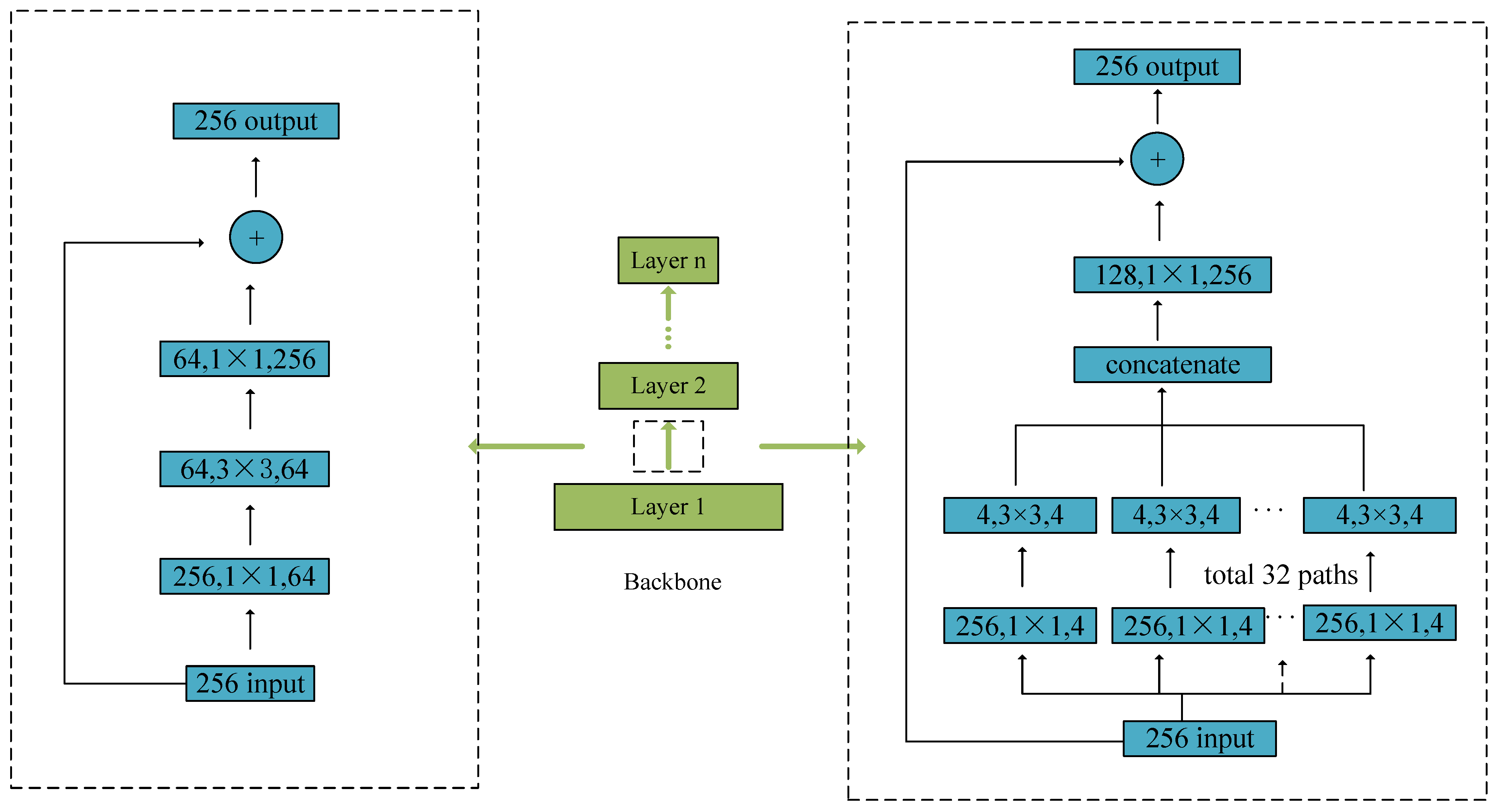
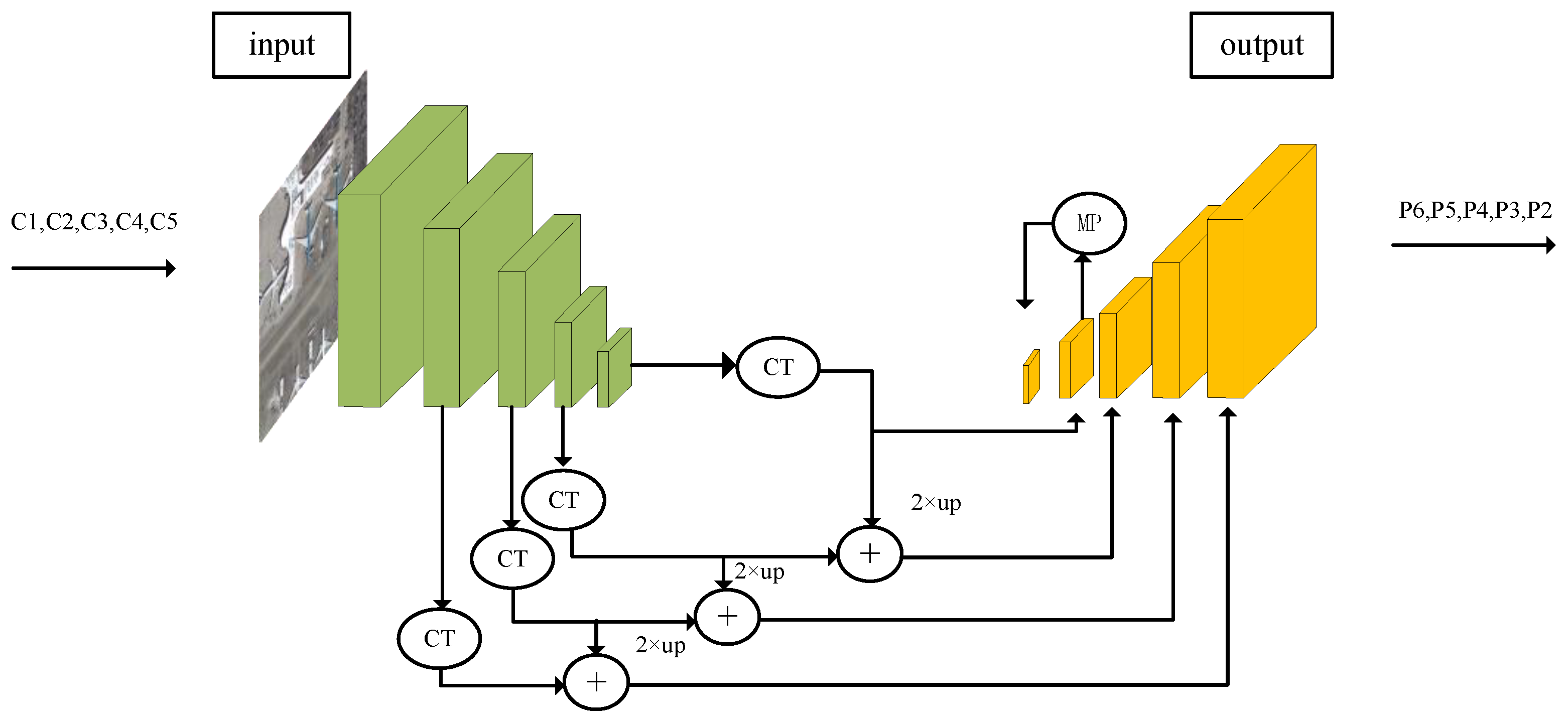
2.1. Feature Extraction Network
2.2. Feature Fusion Network
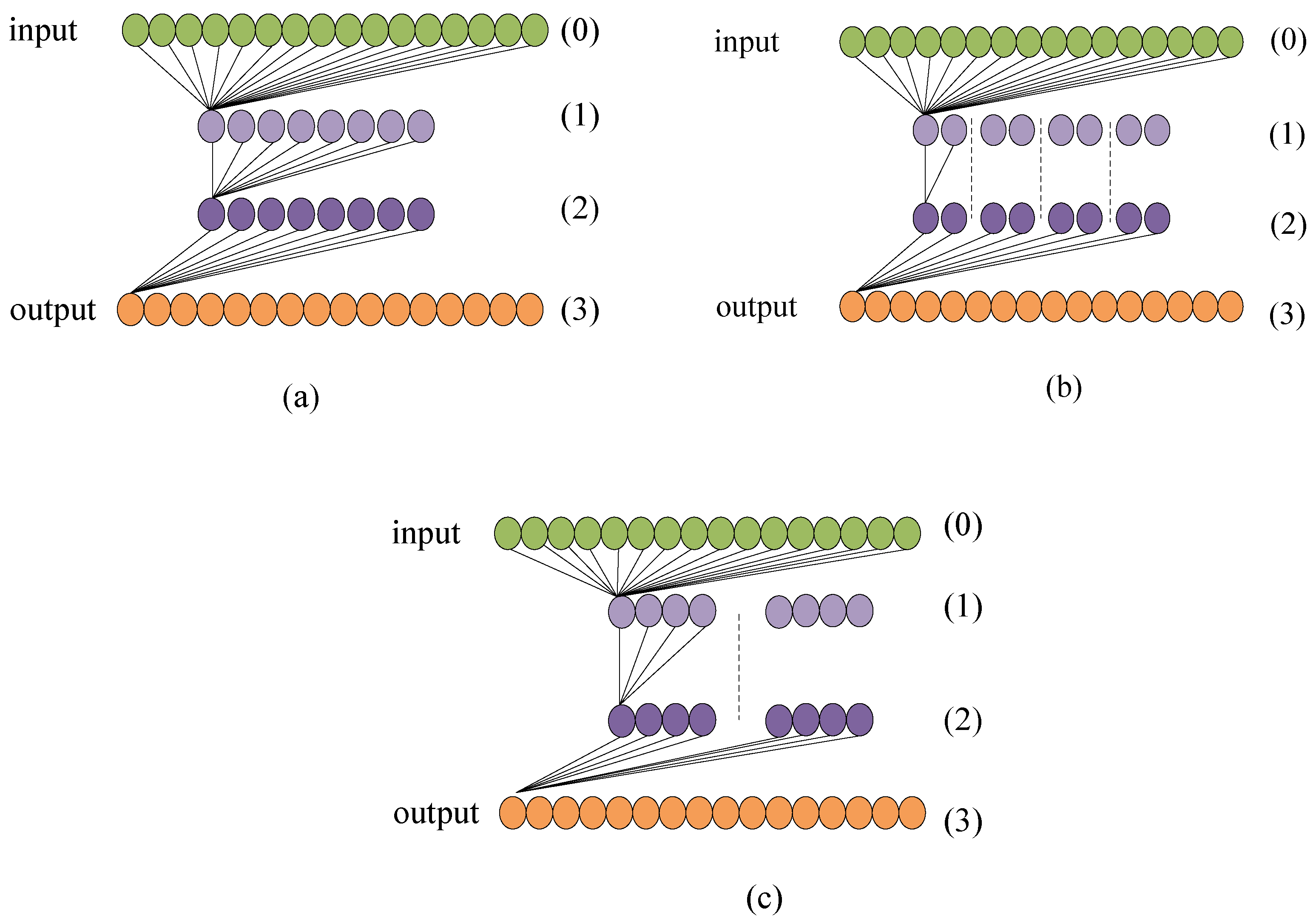
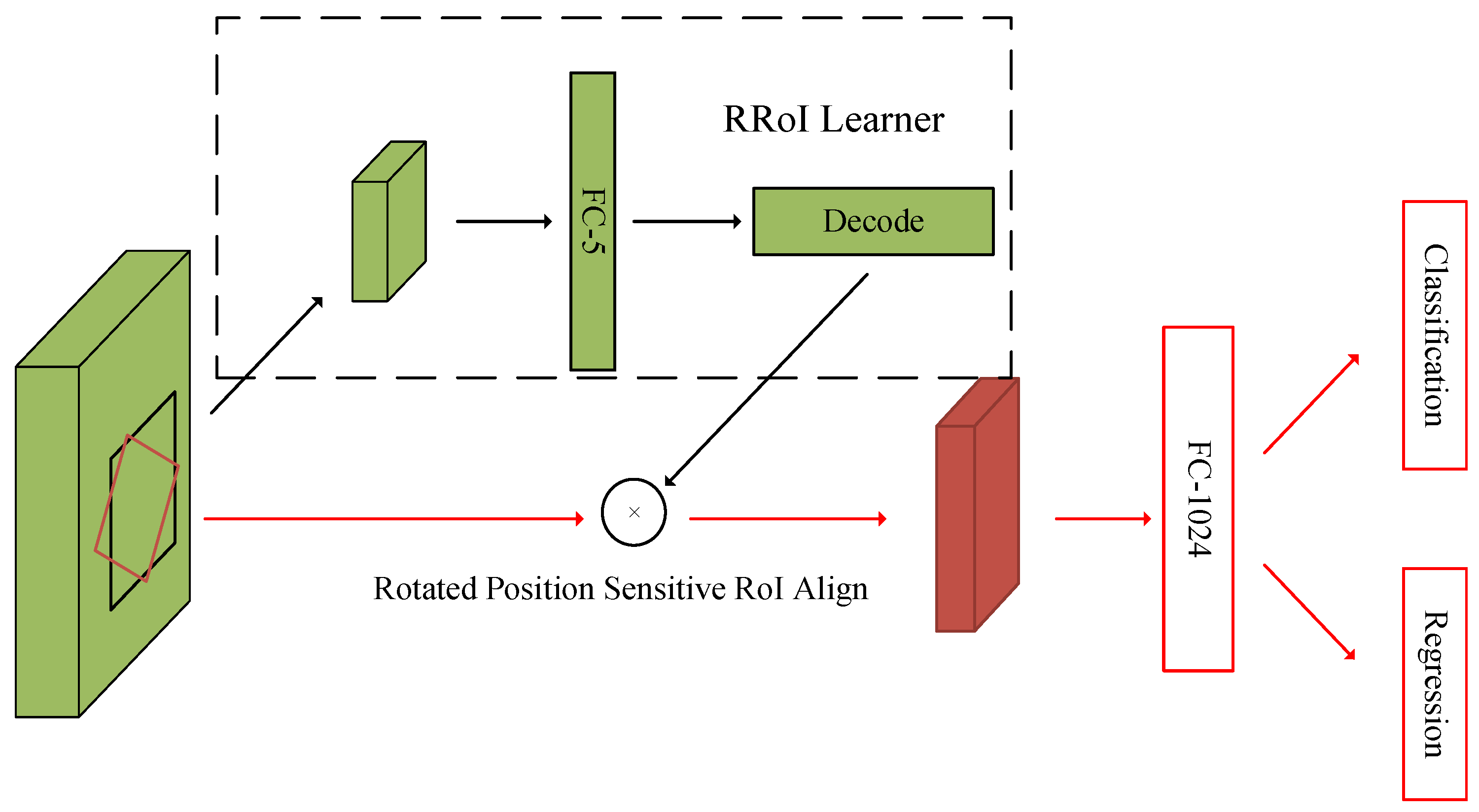
2.3. The Structure of the RoI-Transformer
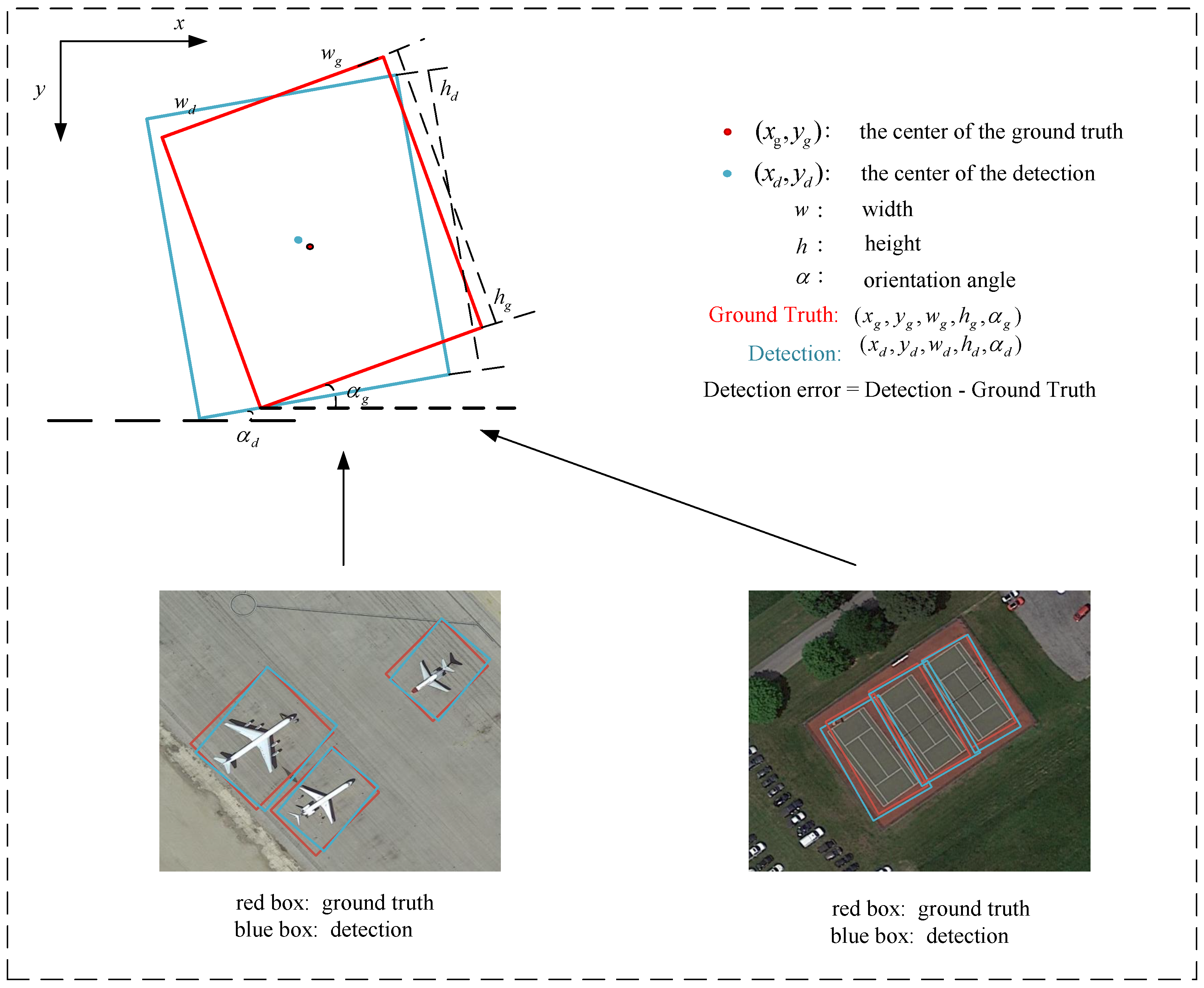
2.4. Rotated Bounding Box Regression and Classification
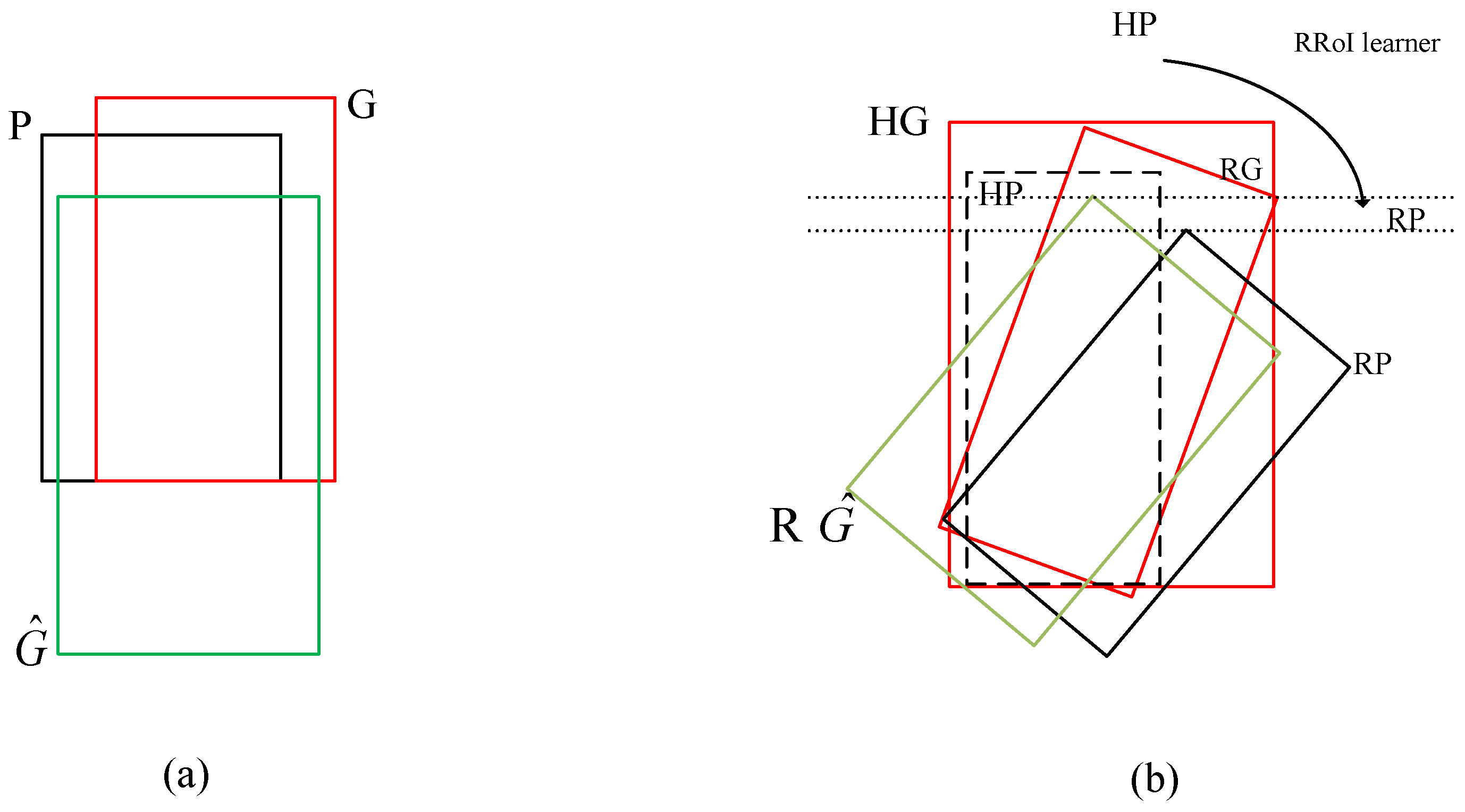
2.4.1. The Scaled Smooth L Loss Function
2.4.2. Rotated Bounding Box Regression
2.4.3. Classification
3. Experimental Settings and Implementation Details
- Experimental Platform: In order to evaluate the performance of the proposed method comprehensively and provide baseline, a normal experimental platform is used. The environments are Intel i7-9750, memory 20 GB, a single NVIDIA Tesla V100 GPU with 16 GB of memory, along with the PyTorch 1.1.0 and Python 3.7.
- Datasets: The DOTA [38] dataset is a public open-access dataset for object detection in aerial images at large scales. It provides two kinds of annotations for oriented and horizontal bounding boxes, respectively. The aerial images of DOTA are collected from Google Earth and satellites, including Julang-1(JL-1) and GF-2. DOTA contains 2806 aerial images. It consists of a training set (1411 images), validation set (458 images), and testing set (937 images). The sizes of the images change from 800 × 800 pixels to 4000 × 4000 pixels. There are 188,282 instances including plane (PL), basketball diamond (BD), bridge (BR), ground field track (GFT), small vehicle (SV), large vehicle (LV), ship (SH), tennis court (TC), basketball court (BC), storage tank (ST), soccer ball field (SBF), roundabout (RA), harbor (HA), swimming pool (SP), and helicopter (HC), 15 categories in total.
- Evaluation Metrics: In object detection, precision and recall are commonly used to evaluate the effectiveness of a method in addition to mean average precision (mAP). We also adopted precision and recall to comprehensively evaluate the effectiveness of the proposed method. Precision is an indicator that represents the percentage of detected objects that are ’ground-truth’. The recall reflects the ratio with which all true samples can be rightly detected. More precisely, the precision and recall are calculated as follows:where TP is the number of targets the model predicts correctly, FP denotes the number of targets predicted incorrectly, FN is the number of targets predicted incorrectly with the true label. With precision and recall, the AP can be defined bywhere u represents class u, is the recall for class u, denotes the precision corresponding to the recall . mAP is the average of classes AP, which is an indicator reflecting the comprehensive performance. The calculation for mAP is as follows:where N represents the number of the total categories.
- Implementation: To better evaluate the performance of our method, the hyperparameters in our experiments are set to be the same. The batch size is set at 2. The initial learning rate is . The momentum is . The weight decay is and the optimization strategy is the SGD (stochastic gradient decent) algorithm [68]. The normalization strategy is batch normalization [69]. The initial weight of the backbone is pre-trained on the ImageNet [70] dataset.
4. Experimental Results and Analysis
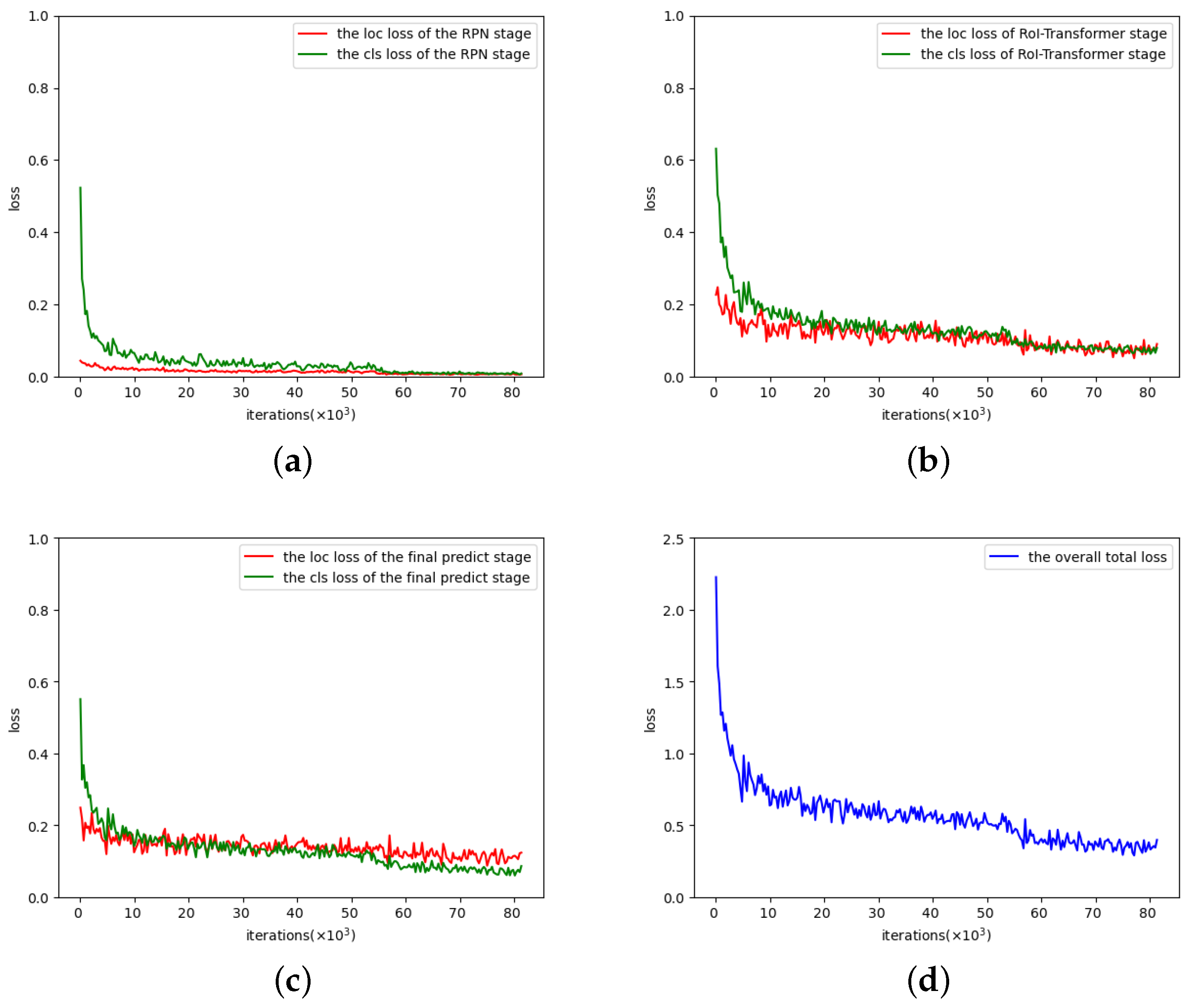
4.1. Effective Experiments
4.2. Comparisons and Analysis of Different Backbones
4.3. Analysis of Performance under Different Scale Factors
4.4. Comparisons and Analysis of Different Frameworks
4.5. The Validation Experiments on Other Datasets
4.6. Discussion
- (I)
- As described in Section 2.4.1, the scale factor is pre-specified, and it corresponds to the whole collection of images from the source dataset. The experimental results on the DOTA show that the best value for the scale factor is about 2.0 from the perspective of the overall indicator mAP. However, there are still two issues worth mentioning. First, from the experimental results, when the scale factor takes the value between 2.0 and 3.0, our method performs better than the others in comparison. This suggests that the best value for the scale factor could be an interval . In return, our model is robust with respect to the scale factor, which ensures our model has a good generalization ability to other datasets. Second, the present scale factor is pre-specified (i.e., experimentally set). Hence, from both theoretical and practical viewpoints, a self-adaptive (i.e., automatic) way of the scale factor setting is expected.
- (II)
- Although the proposed method performs better overall (i.e., according to the indicator mAP), it did not perform better in all of these object categories on DOTA, see Table 3. About this issue, we suppose that it is most likely related to what scope the scale factor corresponds to. As pointed in the above item (I), the present corresponds to the whole collection of all images, regardless of the differences between different categories of objects. At this point, it is also worth exploring a category-based self-adaptive approach to determine .
- (III)
- As we can see from Table 3 and Table 5, the improvement of the mAP in our method is at least 0.9 and at most 1.4 on HRSC2016, which is lower than that of at least 1.26 and at most 16.49 on DOTA. Notice that the object in the HRSC2016 dataset belongs to the single category (ship), although the objects have different sizes, aspect ratios, and orientations. Therefore, we suppose that this issue is most likely related to the uniformity of the categories of objects to some extent.
- (IV)
- Since the main focus of this paper is to explore the potential impact of the variance in the detection error on the performance of detection, we temporarily chose Faster R-CNN as our baseline, which is a classic detector in two-stage detectors. The results show that the scale factor has a significant impact on the detection performance, and the best scale factor is experimentally about 2.0 rather than 1.0, as in the common smooth L loss function. However, we have not yet explored a similar investigation under other baselines adopted in two-stage approaches. Moreover, one might consider similar explorations in one-stage approaches, e.g., YOLO.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lim, J.; Astrid, M.; Yoon, H.; Lee, S. Small object detection using context and attention. In Proceedings of the 2021 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Jeju Island, Republic of Korea, 13–16 April 2021; pp. 181–186. [Google Scholar]
- EIMikaty, M.; Stathaki, T. Detection of Cars in High-Resolution Aerial images of Complex Urban Environments. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5913–5924. [Google Scholar] [CrossRef]
- Wang, G.; Wang, X.; Fan, B.; Pan, C. Feature extraction by rotation-invariant matrix representation for object detection in aerial image. IEEE Geosci. Remote Sens. Lett. 2017, 14, 851–855. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. RIFD-CNN: Rotation-Invariant and Fisher Discriminative Convolutional Neural Networks for Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 2884–2893. [Google Scholar]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J.; Zou, H. Toward fast and accurate vehicle detection in aerial images using coupled region-based convolutional neural networks. J-STARS 2017, 10, 3652–3664. [Google Scholar] [CrossRef]
- Long, Y.; Gong, Y.; Xiao, Z.; Liu, Q. Accurate Object Localization in Remote Sensing images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2486–2494. [Google Scholar] [CrossRef]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; Lecun, Y. OverFeat: Integrated recognition, localization and detection using convolutional networks. In Proceedings of the International Conference on Learning Representations, Banff, AB, Canada, 14–26 April 2014. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A. SSD: Single Shot MultiBox Detector. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. In Proceedings of the Computer Vision—ECCV 2018 15th European Conference, Munich, Germany, 8–14 September 2018; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2018; pp. 765–781. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef]
- Chen, S.; Zhan, R.; Zhang, J. Geospatial Object Detection in Remote Sensing Imagery Based on Multiscale Single-Shot Detector with Activated Semantics. Remote Sens. 2018, 10, 820. [Google Scholar] [CrossRef]
- Wen, G.; Cao, P.; Wang, H.; Chen, H.; Liu, X.; Xu, J.; Zaiane, Q. MS-SSD: Multi-scale single shot detector for ship detection in remote sensing images. Appl. Intell. 2023, 53, 1586–1604. [Google Scholar] [CrossRef]
- Etten, A.V. You Only Look Twice: Rapid Multi-Scale Object Detection In Satellite Imagery. arXiv 2018, arXiv:1805.09512. [Google Scholar]
- Cheng, X.; Zhang, C. C-2-YOLO: Rotating Object Detection Network for Remote Sensing images with Complex Backgrounds. In Proceedings of the 2022 IEEE International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022. [Google Scholar]
- Dong, X.; Qin, Y.; Gao, Y.; Fu, R.; Liu, S.; Ye, Y. Attention-Based Multi-Level Feature Fusion for Object Detection in Remote Sensing images. Remote Sens. 2022, 14, 3735. [Google Scholar] [CrossRef]
- Lin, T.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Han, J.; Ding, J.; Li, J.; Xia, G. Align Deep Features for Oriented Object Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5602511. [Google Scholar] [CrossRef]
- Liu, Y.; Li, Q.; Yuan, Y.; Du, Q.; Wang, Q. ABNet: Adaptive Balanced Network for Multiscale Object Detection in Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5614914. [Google Scholar] [CrossRef]
- Liu, Y.; He, G.; Wang, Z.; Li, W.; Huang, H. NRT-YOLO: Improved YOLOv5 Based on Nested Residual Transformer for Tiny Remote Sensing Object Detection. Sensors 2022, 22, 4953. [Google Scholar] [CrossRef] [PubMed]
- Zakria, Z.; Deng, J.; Kumar, R.; Khokhar, M.; Cai, J.; Kumar, J. Multiscale and Direction Target Detecting in Remote Sensing images via Modified YOLO-v4. IEEE J.-Stars 2022, 15, 1039–1048. [Google Scholar] [CrossRef]
- Zhou, Q.; Zhang, W.; Li, R.; Wang, J.; Zhen, S.; Niu, F. Improved YOLOv5-S object detection method for optical remote sensing images based on contextual transformer. J. Electron. Imaging 2022, 31, 4. [Google Scholar] [CrossRef]
- YOLOrs Sharma, M.; Dhanaraj, M.; Karnam, S.; Chachlakis, D.G.; Ptucha, R.; Markopoulos, P.P.; Saber, E. YOLOrs: Object Detection in Multimodal Remote Sensing Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 1497–1508. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, L.; Liu, T.; Wang, Y. YOLSO: You Only Look Small Object. J. Vis. Commun. Image R. 2021, 81, 103348. [Google Scholar] [CrossRef]
- Mt-yolov6 Pytorch Object Detection Model. Available online: https://models.roboflow.com/object-detection/mt-yolov6 (accessed on 23 June 2022).
- Yolov7 Pytorch Object Detection Model. Available online: https://models.roboflow.com/object-detection/yolov7 (accessed on 6 July 2022).
- Uijlings, J.R.R.; van de Sande, K.E.A.; Gevers, T.; Smeulders, A.W.M. Selective search for object recognition. Int. J. Comput. Vis. (IJCV) 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Li, Z.; Wang, Y.; Zhang, N.; Zhang, Y.; Zhao, Z.; Xu, D.; Ben, G.; Gao, Y. Deep Learning-Based Object Detection Techniques for Remote Sensing images: A Survey. Remote Sens. 2022, 14, 2385. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Learning rotation-invariant convolution neural networks for object detection in VHR optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Neubeck, A.; Van Gool, L. Efficient non-maximum suppression. In Proceedings of the 2006 International Conference on Pattern Recognition (ICPR06), Hong Kong, China, 20–24 August 2006; pp. 850–855. [Google Scholar]
- Liu, Z.; Wang, H.; Weng, L.; Yang, Y. Ship rotated bounding box space for ship extraction from high-resolution optical satellite images with complex backgrounds. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1074–1078. [Google Scholar] [CrossRef]
- Xia, G.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. Dota: A large-scale dataset for object detection in aerial images. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Liu, K.; Mattyus, K. Fast multiclass vehicle detection on aerial images. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1938–1942. [Google Scholar]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-oriented scene text detection via rotation proposals. IEEE Trans. Multimed. 2018, 20, 3111–3122. [Google Scholar] [CrossRef]
- Zhang, Z.; Guo, W.; Zhu, S.; Yu, W. Toward arbitrary-oriented ship detection with rotated region proposal and discrimination networks. IEEE Geosci. Remote Sens. Lett. 2018, 99, 1745–1749. [Google Scholar] [CrossRef]
- Yang, X.; Sun, H.; Fu, K.; Yang, J.; Sun, X.; Yan, M.; Guo, Z. Automatic ship detection in remote sensing images from google earth of complex scenes based on multiscale rotation dense feature pyramid networks. Remote Sens. 2018, 10, 132. [Google Scholar] [CrossRef]
- Azimi, S.; Vig, E.; Bahmanyar, R.; Korner, M.; Reinartz, P. Towards multi-class object detection in unconstrained remote sensing imagery. arXiv 2018, arXiv:1807.02700. [Google Scholar]
- Yu, D.; Ji, S. A New Spatial-Oriented Object Detection Framework for Remote Sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4407416. [Google Scholar] [CrossRef]
- Ma, T.; Mao, M.; Zheng, H.; Gao, P.; Wang, X.; Han, S.; Ding, E.; Zhang, B.; Doermann, D. Oriented object detection with transformer. arXiv 2021, arXiv:2106.03146. [Google Scholar]
- Liu, L.; Pan, Z.; Lei, B. Learning a rotation invariant detector with rotatable bounding box. arXiv 2017, arXiv:1711.09405. [Google Scholar]
- Liu, Z.; Hu, J.; Weng, L.; Yang, Y. Rotated region based cnn for ship detection. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 900–904. [Google Scholar]
- Yang, X.; Yan, J. Arbitrary-oriented object detection with circular smooth label. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 677–694. [Google Scholar]
- Xu, Y.; Fu, M.; Wang, Q.; Wang, Y.; Chen, K.; Xia, G.; Bai, X. Gliding vertex on the horizontal bounding box for multi-oriented object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 1452–1459. [Google Scholar] [CrossRef] [PubMed]
- Huang, Z.; Li, W.; Xia, X.; Wang, H.; Jie, F.; Tao, R. LO-Det: Lightweight Oriented Object Detection in Remote Sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 223373–223384. [Google Scholar] [CrossRef]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.; Lu, Q. Learning roi transformer for oriented object detection in aerial images. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 2844–2853. [Google Scholar]
- Li, Z.; Peng, C.; Yu, G.; Zhang, X.; Deng, Y.; Sun, J. Light-Head R-CNN: In defense of two-stage object detector. arXiv 2017, arXiv:1711.07264. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. Scrdet: Towards more robust detection for small, cluttered and rotated objects. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8231–8240. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Xie, S.; Girshick, R.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. In Proceedings of the 2016 Conference on Neural Information Processing Systems (NIPS), Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Li, J.; Tian, Y.; Xu, Y.; Hu, X.; Zhang, Z.; Wang, H.; Xiao, Y. MM-RCNN: Toward Few-Shot Object Detection in Remote Sensing images with Meta Memory. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5635114. [Google Scholar] [CrossRef]
- Shivappriya, S.; Priyadarsini, M.; Stateczny, A.; Puttamadappa, C.; Parameshachari, B. Cascade Object Detection and Remote Sensing Object Detection Method Based on Trainable Activation Function. Remote Sens. 2021, 13, 200. [Google Scholar] [CrossRef]
- Samanta, S.; Panda, M.; Ramasubbareddy, S.; Sankar, S.; Burgos, D. Spatial-Resolution Independent Object Detection Framework for Aerial Imagery. CMC Comput. Mater. Contin. 2021, 68, 1937–1948. [Google Scholar] [CrossRef]
- Liu, R.; Yu, Z.; Mo, D.; Cai, Y. An Improved Faster-RCNN Algorithm for Object Detection in Remote Sensing images. In Proceedings of the Chinese Control Conference (CCC), Shenyang, China, 27–29 July 2020; pp. 7188–7192. [Google Scholar]
- Zhang, Y.; Song, C.; Zhang, D. Small-scale aircraft detection in remote sensing images based on Faster-RCNN. Multimed. Tools Appl. 2022, 81, 13. [Google Scholar] [CrossRef]
- Luo, M.; Tian, Y.; Zhang, S.; Huang, L.; Wang, H.; Liu, Z.; Yang, L. Individual Tree Detection in Coal Mine Afforestation Area Based on Improved Faster RCNN in UAV RGB images. Remote Sens. 2022, 14, 5545. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Liu, Z.; Yuan, L.; Weng, L.; Yang, Y. A High Resolution Optical Satellite Image Dataset for Ship Recognition and Some New Baselines. In Proceedings of the 2017 International Conference on Pattern Recognition Applications and Methods (ICPRAM), Porto, Portugal, 24–26 February 2017; pp. 324–331. [Google Scholar]
- Schmidt, M.; Le Roux, N.; Bach, F. Minimizing finite sums with the stochastic average gradient. Math. Program. 2017, 162, 83–112. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 2015 International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Li, F. ImageNet:A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Jiang, Y.; Zhu, X.; Wang, X.; Yang, X.; Li, W.; Wang, H.; Fu, P.; Luo, Z. R2cnn: Rotational region cnn for robust scene text detection. arXiv 2017, arXiv:1706.09579. [Google Scholar]
- Liao, M.; Zhu, Z.; Shi, B.; Xia, G.; Bai, X. Rotation-sensitive regression for oriented scene text detection. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 5909–5918. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Backbone | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ResNet50 | 80.66 | 73.15 | 42.70 | 65.44 | 71.73 | 71.23 | 76.18 | 90.31 | 83.25 | 73.41 | 51.02 | 56.97 | 63.78 | 61.93 | 49.37 | 67.41 |
| ResNet101 | 80.60 | 77.74 | 44.82 | 67.51 | 72.24 | 71.93 | 75.29 | 90.54 | 84.36 | 74.55 | 50.61 | 61.33 | 65.16 | 66.20 | 55.46 | 69.22 |
| ResNet101 * | 80.47 | 75.18 | 42.07 | 67.30 | 72.08 | 71.74 | 67.86 | 90.01 | 78.84 | 68.98 | 48.56 | 61.35 | 63.76 | 68.18 | 55.32 | 67.45 |
| ResNeXt50 | 87.13 | 74.61 | 45.56 | 70.73 | 72.60 | 72.22 | 75.37 | 90.05 | 84.31 | 75.80 | 49.94 | 61.85 | 66.33 | 65.67 | 54.85 | 69.80 |
| ResNeXt101 | 80.72 | 76.95 | 44.58 | 70.35 | 72.55 | 73.23 | 75.66 | 90.54 | 80.83 | 75.67 | 49.53 | 59.38 | 65.86 | 66.59 | 51.64 | 68.94 |
| ResNeXt101 * | 80.27 | 76.19 | 44.37 | 67.18 | 72.56 | 72.68 | 67.99 | 90.39 | 81.21 | 75.59 | 45.27 | 59.75 | 64.81 | 66.91 | 51.79 | 67.81 |
| PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | mAP | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.5 | 81.34 | 74.69 | 43.78 | 63.78 | 71.95 | 72.08 | 75.29 | 89.70 | 85.30 | 74.21 | 49.39 | 59.21 | 65.53 | 58.58 | 52.07 | 67.79 |
| 1.0 | 87.13 | 74.61 | 45.56 | 70.73 | 72.60 | 72.22 | 75.37 | 90.05 | 84.31 | 75.80 | 49.94 | 61.85 | 66.33 | 65.67 | 54.85 | 69.80 |
| 1.5 | 86.47 | 78.73 | 45.19 | 70.01 | 72.12 | 72.46 | 68.62 | 90.37 | 84.77 | 76.03 | 54.76 | 60.28 | 66.09 | 68.66 | 58.57 | 70.21 |
| 2.0 | 87.32 | 80.15 | 45.93 | 68.98 | 72.46 | 72.68 | 76.02 | 90.60 | 84.61 | 75.82 | 53.34 | 62.24 | 65.84 | 68.82 | 57.52 | 70.82 |
| 2.5 | 86.81 | 76.10 | 46.35 | 70.18 | 72.76 | 72.60 | 75.61 | 90.71 | 84.58 | 74.38 | 49.03 | 61.22 | 65.94 | 68.65 | 58.46 | 70.23 |
| 3.0 | 87.26 | 76.32 | 45.53 | 69.90 | 71.95 | 73.21 | 69.01 | 90.74 | 82.77 | 76.21 | 49.29 | 62.20 | 66.11 | 68.84 | 57.35 | 69.78 |
| Method | PL | BD | BR | GIF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FR-O [38] | 79.42 | 77.13 | 17.7 | 64.05 | 35.3 | 38.02 | 37.16 | 89.41 | 69.64 | 59.28 | 50.30 | 52.91 | 47.89 | 47.40 | 46.30 | 54.33 |
| RRPN [40] | 80.94 | 65.75 | 35.34 | 67.44 | 59.92 | 50.91 | 55.81 | 90.67 | 66.92 | 72.39 | 55.06 | 52.23 | 55.14 | 53.35 | 48.22 | 61.01 |
| RCNN [71] | 88.52 | 71.20 | 31.66 | 59.30 | 51.85 | 56.19 | 57.25 | 90.81 | 72.84 | 67.38 | 56.69 | 52.84 | 53.08 | 51.94 | 53.58 | 60.67 |
| RoI-Trans * [51] | 88.64 | 78.52 | 43.44 | 75.92 | 68.81 | 73.68 | 83.59 | 90.74 | 77.27 | 81.46 | 58.39 | 53.54 | 62.83 | 58.93 | 47.67 | 69.56 |
| Ours | 87.32 | 80.15 | 45.93 | 68.98 | 72.46 | 72.68 | 76.02 | 90.60 | 84.61 | 75.82 | 53.34 | 62.24 | 65.84 | 68.82 | 57.52 | 70.82 |
| Scale Factor | mAP | Precision | Recall |
|---|---|---|---|
| 1.0 | 85.3 | 55.75 | 90.48 |
| 2.0 | 87.1 | 65.17 | 91.66 |
| 3.0 | 86.5 | 65.03 | 90.48 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, L.; Zheng, C.; Hu, Y. Oriented Object Detection in Aerial Images Based on the Scaled Smooth L1 Loss Function. Remote Sens. 2023, 15, 1350. https://doi.org/10.3390/rs15051350
Wei L, Zheng C, Hu Y. Oriented Object Detection in Aerial Images Based on the Scaled Smooth L1 Loss Function. Remote Sensing. 2023; 15(5):1350. https://doi.org/10.3390/rs15051350
Chicago/Turabian StyleWei, Linhai, Chen Zheng, and Yijun Hu. 2023. "Oriented Object Detection in Aerial Images Based on the Scaled Smooth L1 Loss Function" Remote Sensing 15, no. 5: 1350. https://doi.org/10.3390/rs15051350
APA StyleWei, L., Zheng, C., & Hu, Y. (2023). Oriented Object Detection in Aerial Images Based on the Scaled Smooth L1 Loss Function. Remote Sensing, 15(5), 1350. https://doi.org/10.3390/rs15051350