
Bivariate Landslide Susceptibility Analysis: Clarification, Optimization, Open Software, and Preliminary Comparison

Abstract
:1. Introduction
2. Clarification
2.1. Clarification of Names
- (1)
- If several names indicate an identical method, we used the most recognized one. For example, “information value” [14], “landslide index” [15], “statistical index” [16], and “relative effect” [17] indicate the same method, and among them, “information value” is the most recognized one (Figure 1a). Similarly, the “index of entropy” [21] is more recognized than the “entropy index” [22] (Figure 1a), and “fuzzy logic” [25] is more recognized than “fuzzy set” [26] and “fuzzy approach” [27] (Figure 1a). In addition, “Dempster–Shafer” [23] is more recognized than “belief function” [24] in reasoning [31].
- (2)
- Some names that have multiple indications are not used. They are “likelihood ratio” and “landslide index”. “Likelihood ratio” has been used to indicate both “frequency ratio” [13,32,33] as well as “sufficiency ratio” and “necessity ratio” in the “weight of evidence” method [34]. “Landslide index” has been used to indicate the “information value” method [15], a form of landslide occurrence probability [35], and a method of evaluating landslide susceptibility results [36].
- (3)
- For some bivariate methods, new names are introduced and used to obtain more straightforward impressions of their principles. They are “frequency contrast”, “weight contrast”, and “sufficiency ratio” (see Section 2.2).
2.2. Clarification of Principles
2.2.1. Empirical Conditional Probabilities
2.2.2. Mathematical and Physical Constraints
Mathematical Nonzero-Probability Constraint
Physical Flat-Area Constraint
2.2.3. Conditional-Probability-Based Bivariate Methods
Frequency Contrast Method
Frequency Ratio Method
Information Value Method
Certainty Factor Method
Cosine Amplitude Method
Weight of Evidence Method
Weight Contrast Method
Sufficiency Ratio Method
2.2.4. Other Bivariate Methods
2.3. Clarification of Correlations
- (1)
- Different conditional-probability-based bivariate methods are intrinsically strongly correlated. The strong intrinsic correlations between conditional-probability-based bivariate methods are due to the shared use of conditional probabilities in defining favorability functions (Table 1). The frequency contrast, frequency ratio, information value, and certainty factor methods use the same two conditional probabilities to constitute favorability functions. The weight contrast and sufficiency ratio methods originated from the weight of evidence method, so they share the same group of conditional probabilities to constitute favorability functions. The cosine amplitude method also shares conditional probabilities with the other methods.
- (2)
- Different conditional-probability-based bivariate methods are expected to have a very close or even the same performance. Intrinsic, strong correlations between conditional-probability-based bivariate methods (Table 1) will lead to comparable performances. Landslide susceptibility assessment, essentially, is sequencing mapping units according to relative probabilities of landslide occurrence, and in this study, sequence grid cells according to the LSI value, which is the combination of favorability values given by all considered predisposing factors. For some favorability functions, although they will yield different favorability values for identical grid cells, the order of grid cells sequenced according to favorability values will not change; therefore, they may yield the same order of LSI value for identical grid cells, i.e., relative landslide occurrence probabilities of grid cells may not change. Mathematical explanations are presented as follows.
- (1)
- For an identical predisposing factor, favorability layers produced by the frequency contrast, frequency ratio, information value, certainty factor, and sufficiency ratio methods will have the same order of grid cells sequenced according to favorability values.
- (2)
- For an identical predisposing factor, favorability layers produced by the weight of evidence and weight contrast methods will have the same order of grid cells sequenced according to favorability values.
- (1)
- For an identical predisposing factor, favorability layers produced by the weight of evidence and weight contrast methods, as well as that produced by the cosine amplitude method, may have the same order of grid cells sequenced according to favorability values as those produced by the frequency contrast, frequency ratio, information value, certainty factor, and sufficiency ratio methods. This means favorability layers produced by all eight conditional-probability-based bivariate methods may have the same order of grid cells. This will happen in circumstances where, for a classified factor layer, p(L|) is negatively correlated with p(L|Fi,j), and p(Fi,j|L) is positively correlated with p(L|Fi,j). One simple example of those circumstances is that all factor classes have the same cell count (N(Fi,j)), in which the order of favorability values will be determined by N(L∩Fi,j).
- (2)
- For some conditional-probability-based bivariate methods, they may produce LSI layers with the same order of grid cells sequenced according to LSI values, i.e., they may produce essentially the same landslide susceptibility result. A necessary condition is that, for any identical predisposing factor, they will produce favorability layers with the same order of grid cells. However, this is not a sufficient condition. Given that two methods yield the same order of grid cells for each identical predisposing factor, they may still yield different orders of grid cells in the final LSI layer, which is a combination of favorability layers for all factors (Table 3).
3. Optimization
- (1)
- Differentiation of factor types. If the factor has classified values, go to step (2). If the factor has continuous factor values, go to step (3).
- (2)
- Generation of favorability layers for factors with classified values. First, empirical conditional probabilities for each class are derived based on the training landslide dataset. Then, favorability values for each class are calculated according to the favorability function of the bivariate method. Finally, a favorability layer for this factor with classified values can be produced based on favorability values for all classes.
- (3)
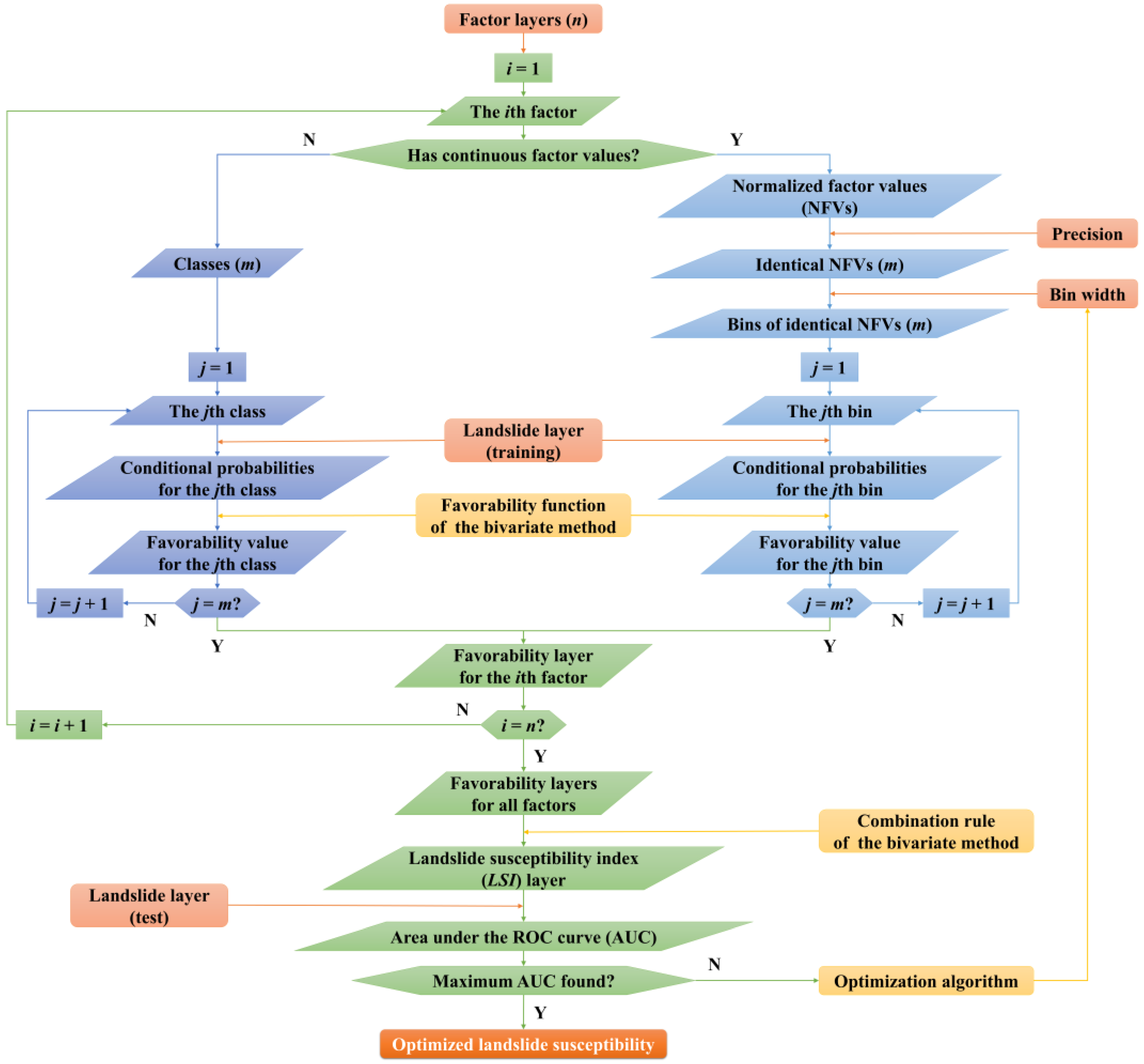
- Generation of favorability layers for factors with continuous factor values. This step is the core of classification-free modification.
- (4)
- Generation of the landslide susceptibility index (LSI) layer. After favorability layers for all factors are obtained, an LSI layer can be produced according to the combination rule of the bivariate method, which will be a simple direct summation except for the certainty factor and weight of evidence methods (Table 1). In addition, in the LSI layer, zero slope grid cells will be set to null to satisfy the flat-area physical constraint, which can also be achieved by setting null grid cells with a null aspect.
- (5)
- Optimization of landslide susceptibility analysis. An LSI layer with a maximum prediction rate, i.e., a maximum AUC evaluated using the test landslide dataset, will provide an optimal assessment of landslide susceptibility. Given the landslide layer and the factor layers, favorability layers for factors with classified values are determined, while the generation of favorability layers for factors with continuous factor values is controlled by precision and bin width. Therefore, precision and bin width control the generation of the LSI layer. Here, optimization is implemented by searching an optimal bin width that yields a maximum prediction rate for predefined precisions (Figure 3). There are two reasons for only optimizing bin width [12]. First, precision is enumerable and finite in count. Second, precision has been shown to have a minor effect on the optimal result. The derived landslide susceptibility is dominated by bin width. A case study has shown that a precision of 2 can yield nearly the same optimal result as those yielded by precisions of 3, 4, 5, and 6. It is, therefore, not necessary to use large precision in optimization, which will significantly prolong the processing time.
4. Open Software
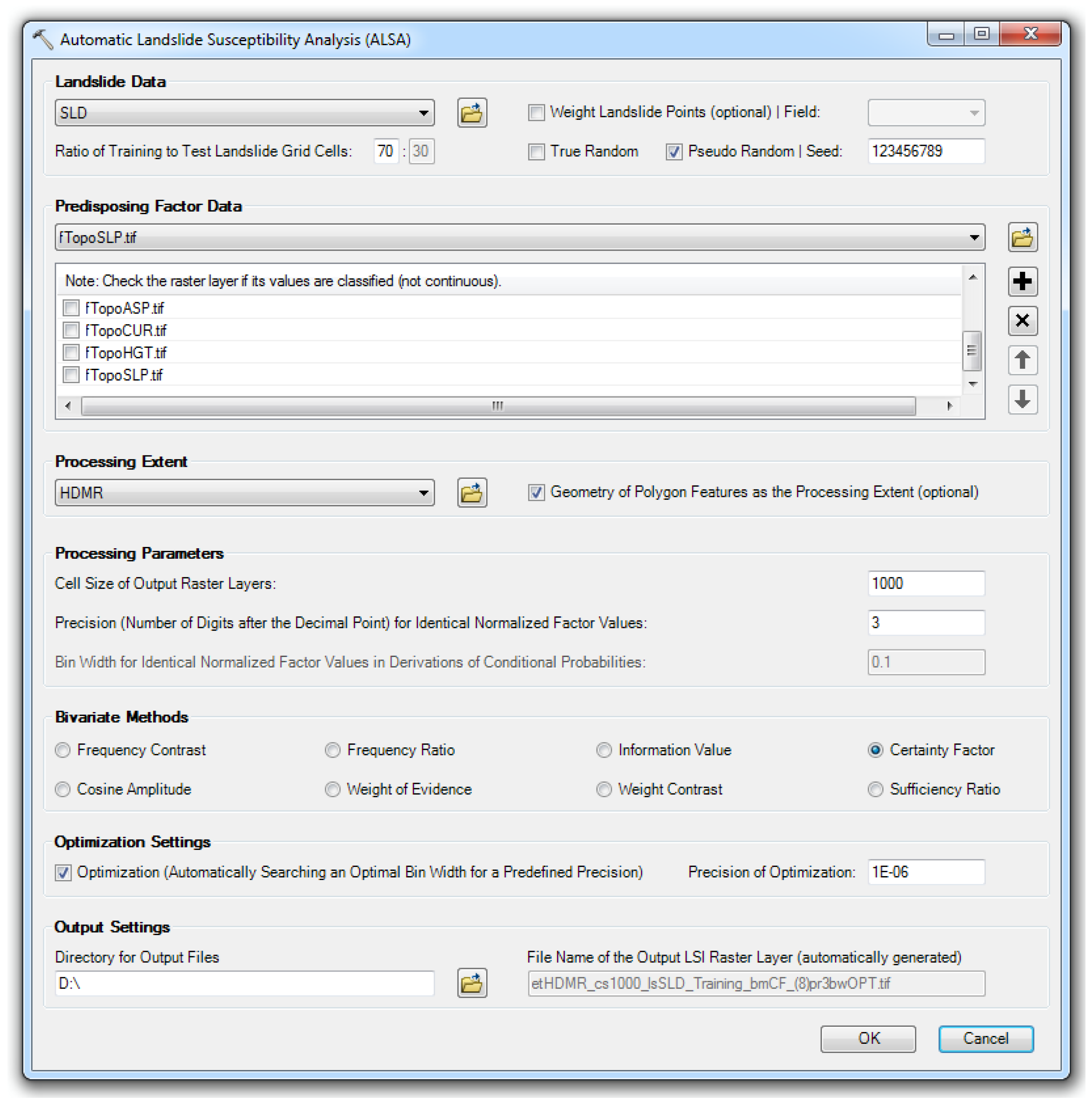
- (1)
- Landslide data. Landslide data can be either points or polygons. Weight setting is an option for the point landslide layer so that sizes (areas) of landslides can be represented. Landslide grid cells can be split into training and test datasets according to the predefined ratio. Pseudo random is an option so that it is possible to use the identical division of training and test datasets in different runs.
- (2)
- Predisposing factor data. Predisposing factor data must be in a raster format. The checkbox in front of a classified factor layer should be checked. If all factors are classified, i.e., all checkboxes are checked, inputs for precision and bin width, as well as optimization settings, will become disabled, which further means that conventional bivariate methods will be used.
- (3)
- Processing extent. A rectangular processing extent will be automatically inherited from the extent of a selected data layer. If a polygon layer is selected, the geometry of polygon features can be used as the processing extent, which is not necessarily a rectangle. Coordinate systems of the landslide data, the predisposing factor data, and the data defining the processing extent must be the same.
- (4)
- Processing parameters. Processing parameters include the cell size of output raster layers and precision and bin width for the classification-free modification. Inputs for precision and bin width will be enabled if there is at least one factor with continuous factor values, while bin width input will be disabled if optimization is chosen because an optimal bin width will be generated.
- (5)
- Bivariate methods. Alternatives are the eight conditional-probability-based bivariate methods, i.e., frequency contrast, frequency ratio, information value, certainty factor, cosine amplitude, the weight of evidence, weight contrast, and sufficiency ratio methods.
- (6)
- Optimization settings. Optimization settings will be enabled if there is at least one factor with continuous factor values. If optimization is chosen, settings for optimization precision will be enabled, and bin width input will be disabled because an optimal bin width will be generated.
- (7)
- Output settings. Users should define the directory for output files, and file names of output files, including that of the output LSI raster layer, will be automatically generated so that the inputs and settings can be indicated.
5. Preliminary Comparison
5.1. Study Area and Data
5.2. Results and Comparisons
- (1)
- Different conditional-probability-based bivariate methods have a very close or even the same performance. This observation supports the theoretical interpretation of the close correlations between different conditional-probability-based bivariate methods. The certainty factor method has the highest prediction rates, and the information value method has almost the same prediction rates, with a percent difference close to zero (0.02) (Table 4). The cosine amplitude method has the lowest prediction rates, with a percent decrease of 3.44 compared to the certainty factor method (Table 4). The other five methods, i.e., the frequency contrast, frequency ratio, weight of evidence, weight contrast, and sufficiency ratio methods, have almost the same prediction rates, which are also very close to those of the certainty factor method (percent decreases less than 1.00) (Table 4). Particularly, for all scenarios, the frequency contrast and frequency ratio methods have the same prediction rates (Table 4).
- (2)
- Optimal bivariate methods perform better than conventional bivariate methods. For all eight conditional-probability-based bivariate methods, the optimal model has higher prediction rates than the conventional models (Table 4). In the applications of conventional bivariate methods, scenarios with more factor classes generally have higher prediction rates (Table 4). The percent increases in the prediction rate of the optimal model are 1.02, 1.67, and 4.10, respectively, when compared with conventional models with 10, 5, and 3 factor classes (Table 4). This is consistent with the intuition that the more factor classes, the closer the conventional model is to the optimal model in terms of classification-free modification.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fell, R.; Corominas, J.; Bonnard, C.; Cascini, L.; Leroi, E.; Savage, W.Z. Guidelines for Landslide Susceptibility, Hazard and Risk Zoning for Land Use Planning. Eng. Geol. 2008, 102, 85–98. [Google Scholar] [CrossRef] [Green Version]
- Li, L.; Lan, H. Integration of Spatial Probability and Size in Slope-Unit-Based Landslide Susceptibility Assessment: A Case Study. Int. J. Environ. Res. Public Health 2020, 17, 8055. [Google Scholar] [CrossRef] [PubMed]
- Reichenbach, P.; Rossi, M.; Malamud, B.D.; Mihir, M.; Guzzetti, F. A Review of Statistically-Based Landslide Susceptibility Models. Earth-Sci. Rev. 2018, 180, 60–91. [Google Scholar] [CrossRef]
- Corominas, J.; van Westen, C.; Frattini, P.; Cascini, L.; Malet, J.P.; Fotopoulou, S.; Catani, F.; Van Den Eeckhaut, M.; Mavrouli, O.; Agliardi, F.; et al. Recommendations for the Quantitative Analysis of Landslide Risk. Bull. Eng. Geol. Environ. 2014, 73, 209–263. [Google Scholar] [CrossRef] [Green Version]
- Li, L.; Lan, H.; Guo, C.; Zhang, Y.; Li, Q.; Wu, Y. A Modified Frequency Ratio Method for Landslide Susceptibility Assessment. Landslides 2017, 14, 727–741. [Google Scholar] [CrossRef]
- Chung, C.-J.F.; Fabbri, A.G. The Representation of Geoscience Information for Data Integration. Nat. Resour. Res. 1993, 2, 122–139. [Google Scholar] [CrossRef]
- Dou, J.; Yunus, A.P.; Bui, D.T.; Sahana, M.; Chen, C.W.; Zhu, Z.; Wang, W.; Pham, B.T. Evaluating Gis-Based Multiple Statistical Models and Data Mining for Earthquake and Rainfall-Induced Landslide Susceptibility Using the Lidar Dem. Remote Sens. 2019, 11, 638. [Google Scholar] [CrossRef] [Green Version]
- Korup, O.; Stolle, A. Landslide Prediction from Machine Learning. Geol. Today 2014, 30, 26–33. [Google Scholar] [CrossRef]
- Liu, L.L.; Zhang, J.; Li, J.Z.; Huang, F.; Wang, L.C. A bibliometric Analysis of the Landslide Susceptibility Research (1999–2021). Geocart. Int. 2022; in press. [Google Scholar] [CrossRef]
- Yang, Z.; Liu, C.; Nie, R.; Zhang, W.; Zhang, L.; Zhang, Z.; Li, W.; Liu, G.; Dai, X.; Zhang, D.; et al. Research on Uncertainty of Landslide Susceptibility Prediction—Bibliometrics and Knowledge Graph Analysis. Remote Sens. 2022, 14, 3879. [Google Scholar] [CrossRef]
- Süzen, M.L.; Doyuran, V. Data Driven Bivariate Landslide Susceptibility Assessment Using Geographical Information Systems: A Method and Application to Asarsuyu Catchment, Turkey. Eng. Geol. 2004, 71, 303–321. [Google Scholar] [CrossRef]
- Zhang, Y.; Lan, H.; Li, L.; Wu, Y.; Chen, J.; Tian, N. Optimizing the Frequency Ratio Method for Landslide Susceptibility Assessment: A Case Study of the Caiyuan Basin in the Southeast Mountainous Area of China. J. Mt. Sci. 2020, 17, 340–357. [Google Scholar] [CrossRef]
- Lee, S. Application of Likelihood Ratio and Logistic Regression Models to Landslide Susceptibility Mapping Using GIS. Environ. Manag. 2004, 34, 223–232. [Google Scholar] [CrossRef] [PubMed]
- van Westen, C.J. Application of Geographic Information Systems to Landslide Hazard Zonation. Ph.D. Thesis, International Institute for Geo-Information Science and Earth Observation, Enschede, The Netherlands, 1993. Available online: http://www.itc.nl/library/Papers_1993/phd/vanwesten.pdf (accessed on 28 May 2022).
- van Westen, C.J. Chapter 5: Statistical Landslide Hazard Analysis. In ILWIS Applications Guide; International Institute for Geo-Information Science and Earth Observation: Enschede, The Netherlands, 1997; pp. 73–84. Available online: https://www.itc.nl/ilwis/pdf/appch05.pdf (accessed on 4 August 2022).
- Rautela, P.; Lakhera, R.C. Landslide Risk Analysis between Giri and Tons Rivers in Himachal Himalaya (India). Int. J. Appl. Earth Obs. Geoinf. 2000, 2, 153–160. [Google Scholar] [CrossRef]
- Ghafoori, M.; Sadeghi, H.; Lashkaripour, G.R.; Alimohammadi, B. Landslide Hazard Zonation Using the Relative Effect Method. In The 10th IAEG International Congress (IAEG2006); Paper Number 474; The Geological Society of London: London, UK, 2006. [Google Scholar]
- Lan, H.; Zhou, C.; Wang, L.; Zhang, H.; Li, R. Landslide Hazard Spatial Analysis and Prediction Using GIS in the Xiaojiang Watershed, Yunnan, China. Eng. Geol. 2004, 76, 109–128. [Google Scholar] [CrossRef]
- Kanungo, D.P.; Arora, M.K.; Sarkar, S.; Gupta, R.P. A Comparative Study of Conventional, ANN Black Box, Fuzzy and Combined Neural and Fuzzy Weighting Procedures for Landslide Susceptibility Zonation in Darjeeling Himalayas. Eng. Geol. 2006, 85, 347–366. [Google Scholar] [CrossRef]
- van Westen, C.J.; Rengers, N.; Soeters, R. Use of Geomorphological Information in Indirect Landslide Susceptibility Assessment. Nat. Hazards 2003, 30, 399–419. [Google Scholar] [CrossRef]
- Constantin, M.; Bednarik, M.; Jurchescu, M.C.; Vlaicu, M. Landslide Susceptibility Assessment Using the Bivariate Statistical Analysis and the Index of Entropy in the Sibiciu Basin (Romania). Environ. Earth Sci. 2011, 63, 397–406. [Google Scholar] [CrossRef]
- Bednarik, M.; Magulová, B.; Matys, M.; Marschalko, M. Landslide Susceptibility Assessment of the Kraľovany-Liptovský Mikuláš Railway Case Study. Phys. Chem. Earth 2010, 35, 162–171. [Google Scholar] [CrossRef]
- Park, N.W. Application of Dempster-Shafer Theory of Evidence to GIS-Based Landslide Susceptibility Analysis. Environ. Earth Sci. 2011, 62, 367–376. [Google Scholar] [CrossRef]
- An, P.; Moon, W.M.; Bonham-Carter, G.F. Uncertainty Management in Integration of Exploration Data Using the Belief Function. Nat. Resour. Res. 1994, 3, 60–71. [Google Scholar] [CrossRef]
- Lee, S. Application and Verification of Fuzzy Algebraic Operators to Landslide Susceptibility Mapping. Environ. Geol. 2007, 52, 615–623. [Google Scholar] [CrossRef]
- Peethambaran, B.; Anbalagan, R.; Shihabudheen, K.V. Landslide Susceptibility Mapping in and around Mussoorie Township Using Fuzzy Set Procedure, MamLand and Improved Fuzzy Expert System—A Comparative Study. Nat. Hazards 2019, 96, 121–147. [Google Scholar] [CrossRef]
- Leonardi, G.; Palamara, R.; Cirianni, F. Landslide Susceptibility Mapping Using a Fuzzy Approach. Procedia Eng. 2016, 161, 380–387. [Google Scholar] [CrossRef]
- Bonham-Carter, G.F.; Agterberg, F.P.; Wright, D.F. Weights of Evidence Modelling: A New Approach to Mapping Mineral Potential. In Statistical Applications in the Earth Sciences; Agterberg, G.F., Bonham-Carter, G.F., Eds.; Geological Survey of Canada: Ottawa, ON, Canada, 1989; pp. 171–183. [Google Scholar]
- Regmi, N.R.; Giardino, J.R.; Vitek, J.D. Modeling Susceptibility to Landslides Using the Weight of Evidence Approach: Western Colorado, USA. Geomorphology 2010, 115, 172–187. [Google Scholar] [CrossRef]
- Lee, S.; Min, K. Statistical Analysis of Landslide Susceptibility at Yongin, Korea. Environ. Geol. 2001, 40, 1095–1113. [Google Scholar] [CrossRef]
- Denœux, T. 40 Years of Dempster–Shafer Theory. Int. J. Approx. Reason. 2016, 79, 1–6. [Google Scholar] [CrossRef]
- Kanungo, D.P.; Sarkar, S.; Sharma, S. Combining Neural Network with Fuzzy, Certainty Factor and Likelihood Ratio Concepts for Spatial Prediction of Landslides. Nat. Hazards 2011, 59, 1491–1512. [Google Scholar] [CrossRef]
- Akgun, A. A Comparison of Landslide Susceptibility Maps Produced by Logistic Regression, Multi-Criteria Decision, and Likelihood Ratio Methods: A Case Study at İzmir, Turkey. Landslides 2012, 9, 93–106. [Google Scholar] [CrossRef]
- Bonham-Carter, G.F. Geographic Information Systems for Geoscientists: Modelling with GIS; Pergamon (Elsevier Science Ltd.): Kidlington, UK, 1994. [Google Scholar] [CrossRef]
- Trigila, A.; Iadanza, C.; Spizzichino, D. Quality Assessment of the Italian Landslide Inventory Using GIS Processing. Landslides 2010, 7, 455–470. [Google Scholar] [CrossRef]
- Shahabi, H.; Hashim, M. Landslide Susceptibility Mapping Using GIS-Based Statistical Models and Remote Sensing Data in Tropical Environment. Sci. Rep. 2015, 5, 9899. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shortliffe, E.H.; Buchanan, B.G. A Model of Inexact Reasoning in Medicine. Math. Biosci. 1975, 23, 351–379. [Google Scholar] [CrossRef]
- Heckerman, D. Probabilistic Interpretations for Mycin’s Certainty Factors. Mach. Intell. Pattern Recogn. 1986, 4, 167–196. [Google Scholar] [CrossRef]
- Ross, T.J. Fuzzy Logic with Engineering Applications, 4th ed.; Wiley: West Sussex, UK, 2017. [Google Scholar]
- Neuhäuser, B.; Terhorst, B. Landslide Susceptibility Assessment Using “Weights-of-Evidence” Applied to a Study Area at the Jurassic Escarpment (SW-Germany). Geomorphology 2007, 86, 12–24. [Google Scholar] [CrossRef]
- Carranza, E.J.M.; Hale, M. Evidential belief functions for data-driven geologically constrained mapping of gold potential, Baguio district, Philippines. Ore Geol. Rev. 2003, 22, 117–132. [Google Scholar] [CrossRef]
- Zhu, A.X.; Wang, R.; Qiao, J.; Qin, C.Z.; Chen, Y.; Liu, J.; Du, F.; Lin, Y.; Zhu, T. An Expert Knowledge-Based Approach to Landslide Susceptibility Mapping Using GIS and Fuzzy Logic. Geomorphology 2014, 214, 128–138. [Google Scholar] [CrossRef]
- Yang, Q.; Zheng, D.; Liu, Y. Physico-geographical feature and economic development of the dry valleys in the Hengduan Mountains, southwest China (in Chinese with English abstract). J. Arid Land Resour. Environ. 1988, 2, 17–24. [Google Scholar] [CrossRef]
- Lan, H.; Wu, F.; Zhou, C.; Wang, L. Spatial hazard analysis and prediction on rainfall-induced landslide using GIS. Chin. Sci. Bull. 2003, 48, 703–708. [Google Scholar] [CrossRef]
- Lan, H.; Zhang, N.; Li, L.; Tian, N.; Zhang, Y.; Liu, S.; Lin, G.; Tian, C.; Wu, Y.; Yao, J.; et al. Risk analysis of major engineering geological hazards for Sichuan-Tibet railway in the phase of feasibility study (in Chinese with English abstract). J. Eng. Geol. 2021, 29, 326–341. [Google Scholar] [CrossRef]
- Lan, H.; Tian, N.; Li, L.; Liu, H.; Peng, J.; Cui, P.; Zhou, C.; Macciotta, R.; Clague, J.J. Poverty Control Policy May Affect the Transition of Geological Disaster Risk in China. Humanit. Soc. Sci. Commun. 2022, 9, 80. [Google Scholar] [CrossRef]
- Meng, Y.; Lan, H.; Li, L.; Wu, Y.; Li, Q. Characteristics of Surface Deformation Detected by X-Band SAR Interferometry over Sichuan-Tibet Grid Connection Project Area, China. Remote Sens. 2015, 7, 12265–12281. [Google Scholar] [CrossRef] [Green Version]
- Wei, L.; Hu, K.; Liu, S. Spatial Distribution of Debris Flow-Prone Catchments in Hengduan Mountainous Area in Southwestern China. Arab. J. Geosci. 2021, 14, 2650. [Google Scholar] [CrossRef]
- Cui, P.; Ge, Y.; Li, S.; Li, Z.; Xu, X.; Zhou, G.G.D.; Chen, H.; Wang, H.; Lei, Y.; Zhou, L.; et al. Scientific Challenges in Disaster Risk Reduction for the Sichuan–Tibet Railway. Eng. Geol. 2022, 309, 106837. [Google Scholar] [CrossRef]
- Li, J.; Liu, Z.; Wang, R.; Zhang, X.; Liu, X.; Yao, Z. Analysis of Debris Flow Triggering Conditions for Different Rainfall Patterns Based on Satellite Rainfall Products in Hengduan Mountain Region, China. Remote Sens. 2022, 14, 2731. [Google Scholar] [CrossRef]
- Sun, X.; Zhang, G.; Wang, J.; Li, C.; Wu, S.; Li, Y. Spatiotemporal Variation of Flash Floods in the Hengduan Mountains Region Affected by Rainfall Properties and Land Use. Nat. Hazards 2022, 111, 465–488. [Google Scholar] [CrossRef]
- Li, H.; Qi, S.; Chen, H.; Liao, H.; Cui, Y.; Zhou, J. Mass Movement and Formation Process Analysis of the Two Sequential Landslide Dam Events in Jinsha River, Southwest China. Landslides 2019, 16, 2247–2258. [Google Scholar] [CrossRef]
- Yang, W.; Wang, Y.; Sun, S.; Wang, Y.; Ma, C. Using Sentinel-2 Time Series to Detect Slope Movement before the Jinsha River Landslide. Landslides 2019, 16, 1313–1324. [Google Scholar] [CrossRef]
- Chen, Z.; Chen, S.; Wang, L.; Zhong, Q.; Zhang, Q.; Jin, S. Back Analysis of the Breach Flood of the “11.03” Baige Barrier Lake at the Upper Jinsha River (in Chinese with English abstract). Sci. Sin. Technol. 2020, 50, 763–774. [Google Scholar] [CrossRef]
- Fan, X.; Xu, Q.; Scaringi, G.; Dai, L.; Li, W.; Dong, X.; Zhu, X.; Pei, X.; Dai, K.; Havenith, H.B. Failure Mechanism and Kinematics of the Deadly June 24th 2017 Xinmo Landslide, Maoxian, Sichuan, China. Landslides 2017, 14, 2129–2146. [Google Scholar] [CrossRef]
- Ouyang, C.; Zhao, W.; He, S.; Wang, D.; Zhou, S.; An, H.; Wang, Z.; Cheng, D. Numerical Modeling and Dynamic Analysis of the 2017 Xinmo Landslide in Maoxian County, China. J. Mt. Sci. 2017, 14, 1701–1711. [Google Scholar] [CrossRef]
- Shao, C.; Li, Y.; Lan, H.; Li, P.; Zhou, R.; Ding, H.; Yan, Z.; Dong, S.; Yan, L.; Deng, T. The Role of Active Faults and Sliding Mechanism Analysis of the 2017 Maoxian Postseismic Landslide in Sichuan, China. Bull. Eng. Geol. Environ. 2019, 78, 5635–5651. [Google Scholar] [CrossRef]
- Tang, C.; Ma, G.; Chang, M.; Li, W.; Zhang, D.; Jia, T.; Zhou, Z. Landslides Triggered by the 20 April 2013 Lushan Earthquake, Sichuan Province, China. Eng. Geol. 2015, 187, 45–55. [Google Scholar] [CrossRef]
- Xu, C.; Xu, X.; Shyu, J.B.H. Database and Spatial Distribution of Landslides Triggered by the Lushan, China Mw 6.6 Earthquake of 20 April 2013. Geomorphology 2015, 248, 77–92. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z.; Lan, H.; Gao, X.; Li, L.; Meng, Y.; Wu, Y. Urgent Landslide Susceptibility Assessment in the 2013 Lushan Earthquake-Impacted Area, Sichuan Province, China. Nat. Hazards 2015, 75, 2467–2487. [Google Scholar] [CrossRef]
- Yin, Y.; Wang, F.; Sun, P. Landslide Hazards Triggered by the 2008 Wenchuan Earthquake, Sichuan, China. Landslides 2009, 6, 139–152. [Google Scholar] [CrossRef]
- Qi, S.; Xu, Q.; Lan, H.; Zhang, B.; Liu, J. Spatial Distribution Analysis of Landslides Triggered by 2008.5.12 Wenchuan Earthquake, China. Eng. Geol. 2010, 116, 95–108. [Google Scholar] [CrossRef]
- Zhang, Y.; Cheng, Y.; Yin, Y.; Lan, H.; Wang, J.; Fu, X. High-Position Debris Flow: A Long-Term Active Geohazard after the Wenchuan Earthquake. Eng. Geol. 2014, 180, 45–54. [Google Scholar] [CrossRef]
- Liu, X.; Zhao, C.; Zhang, Q.; Lu, Z.; Li, Z.; Yang, C.; Zhu, W.; Jing, L.; Chen, L.; Liu, C. Integration of Sentinel-1 and ALOS/PALSAR-2 SAR Datasets for Mapping Active Landslides along the Jinsha River Corridor, China. Eng. Geol. 2021, 284, 106033. [Google Scholar] [CrossRef]
- Zhang, J.; Zhu, W.; Cheng, Y.; Li, Z. Landslide Detection in the Linzhi–Ya’an Section along the Sichuan–Tibet Railway Based on InSAR and Hot Spot Analysis Methods. Remote Sens. 2021, 13, 3566. [Google Scholar] [CrossRef]
- Yao, J.; Lan, H.; Li, L.; Cao, Y.; Wu, Y.; Zhang, Y.; Zhou, C. Characteristics of a Rapid Landsliding Area along Jinsha River Revealed by Multi-Temporal Remote Sensing and Its Risks to Sichuan-Tibet Railway. Landslides 2022, 19, 703–718. [Google Scholar] [CrossRef]
- Sun, X.; Chen, J.; Li, Y.; Rene, N.N. Landslide Susceptibility Mapping along a Rapidly Uplifting River Valley of the Upper Jinsha River, Southeastern Tibetan Plateau, China. Remote Sens. 2022, 14, 1730. [Google Scholar] [CrossRef]
- Wu, R.; Zhang, Y.; Guo, C.; Yang, Z.; Tang, J.; Su, F. Landslide Susceptibility Assessment in Mountainous Area: A Case Study of Sichuan–Tibet Railway, China. Environ. Earth Sci. 2020, 79, 157. [Google Scholar] [CrossRef]
- Wang, S.; Zhuang, J.; Mu, J.; Zheng, J.; Zhan, J.; Wang, J.; Fu, Y. Evaluation of Landslide Susceptibility of the Ya’an–Linzhi Section of the Sichuan–Tibet Railway Based on Deep Learning. Environ. Earth Sci. 2022, 81, 250. [Google Scholar] [CrossRef]
- Wu, W.; Zhang, Q.; Singh, V.P.; Wang, G.; Zhao, J.; Shen, Z.; Sun, S. A Data-Driven Model on Google Earth Engine for Landslide Susceptibility Assessment in the Hengduan Mountains, the Qinghai–Tibetan Plateau. Remote Sens. 2022, 14, 4662. [Google Scholar] [CrossRef]
- Zhao, J.; Zhang, Q.; Wang, D.; Wu, W.; Yuan, R. Machine Learning-Based Evaluation of Susceptibility to Geological Hazards in the Hengduan Mountains Region, China. Int. J. Disaster Risk Sci. 2022, 13, 305–316. [Google Scholar] [CrossRef]
- Geological Disaster Dataset of China; RESDC (Resource and Environment Science and Data Center). 2020. Available online: https://www.resdc.cn/data.aspx?DATAID=290 (accessed on 29 October 2020).
- 1:1M National Basic Geographic Information Dataset of China; NCSFGI (National Catalogue Service for Geographic Information). 2018. Available online: https://www.webmap.cn/commres.do?method=result100W (accessed on 11 September 2018).
- Spatial Interpolation Dataset of Annual Precipitation Since 1980 of China; RESDC (Resource and Environment Science and Data Center). 2019. Available online: https://www.resdc.cn/data.aspx?DATAID=229 (accessed on 15 August 2019).
- Canavesi, V.; Segoni, S.; Rosi, A.; Ting, X.; Nery, T.; Catani, F.; Casagli, N. Different Approaches to Use Morphometric Attributes in Landslide Susceptibility Mapping Based on Meso-Scale Spatial Units: A Case Study in Rio de Janeiro (Brazil). Remote Sens. 2020, 12, 1826. [Google Scholar] [CrossRef]
- Huang, F.; Tao, S.; Li, D.; Lian, Z.; Catani, F.; Huang, J.; Li, K.; Zhang, C. Landslide Susceptibility Prediction Considering Neighborhood Characteristics of Landslide Spatial Datasets and Hydrological Slope Units Using Remote Sensing and GIS Technologies. Remote Sens. 2022, 14, 4436. [Google Scholar] [CrossRef]
- Hussin, H.Y.; Zumpano, V.; Reichenbach, P.; Sterlacchini, S.; Micu, M.; van Westen, C.; Bălteanu, D. Different Landslide Sampling Strategies in a Grid-Based Bi-Variate Statistical Susceptibility Model. Geomorphology 2016, 253, 508–523. [Google Scholar] [CrossRef]
- Shu, H.; Guo, Z.; Qi, S.; Song, D.; Pourghasemi, H.R.; Ma, J. Integrating Landslide Typology with Weighted Frequency Ratio Model for Landslide Susceptibility Mapping: A Case Study from Lanzhou City of Northwestern China. Remote Sens. 2021, 13, 3623. [Google Scholar] [CrossRef]
- Yang, X.; Liu, R.; Yang, M.; Chen, J.; Liu, T.; Yang, Y.; Chen, W.; Wang, Y. Incorporating Landslide Spatial Information and Correlated Features among Conditioning Factors for Landslide Susceptibility Mapping. Remote Sens. 2021, 13, 2166. [Google Scholar] [CrossRef]
- Qin, C.Z.; Bao, L.L.; Zhu, A.X.; Wang, R.X.; Hu, X.M. Uncertainty Due to DEM Error in Landslide Susceptibility Mapping. Int. J. Geogr. Inf. Sci. 2013, 27, 1364–1380. [Google Scholar] [CrossRef]
- Luti, T.; Segoni, S.; Catani, F.; Munaf, M.; Casagli, N. Integration of Remotely Sensed Soil Sealing Data in Landslide Susceptibility Mapping. Remote Sens. 2020, 12, 1486. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, W.; Zhang, Z.; Xu, Q.; Li, W. Risk Factor Detection and Landslide Susceptibility Mapping Using Geo-Detector and Random Forest Models: The 2018 Hokkaido Eastern Iburi Earthquake. Remote Sens. 2021, 13, 1157. [Google Scholar] [CrossRef]
- Barbosa, N.; Andreani, L.; Gloaguen, R.; Ratschbacher, L. Window-Based Morphometric Indices as Predictive Variables for Landslide Susceptibility Models. Remote Sens. 2021, 13, 451. [Google Scholar] [CrossRef]
- Thiery, Y.; Maquaire, O.; Fressard, M. Application of Expert Rules in Indirect Approaches for Landslide Susceptibility Assessment. Landslides 2014, 11, 411–424. [Google Scholar] [CrossRef]
- Yu, L.; Zhou, C.; Wang, Y.; Cao, Y.; Peres, D.J. Coupling Data- and Knowledge-Driven Methods for Landslide Susceptibility Mapping in Human-Modified Environments: A Case Study from Wanzhou County, Three Gorges Reservoir Area, China. Remote Sens. 2022, 14, 774. [Google Scholar] [CrossRef]
- Mohammady, M.; Pourghasemi, H.R.; Pradhan, B. Landslide Susceptibility Mapping at Golestan Province, Iran: A Comparison between Frequency Ratio, Dempster-Shafer, and Weights-of-Evidence Models. J. Asian Earth Sci. 2012, 61, 221–236. [Google Scholar] [CrossRef]
- Guo, C.; Montgomery, D.R.; Zhang, Y.; Wang, K.; Yang, Z. Quantitative Assessment of Landslide Susceptibility along the Xianshuihe Fault Zone, Tibetan Plateau, China. Geomorphology 2015, 248, 93–110. [Google Scholar] [CrossRef]
- Hong, H.; Chen, W.; Xu, C.; Youssef, A.M.; Pradhan, B.; Tien Bui, D. Rainfall-Induced Landslide Susceptibility Assessment at the Chongren Area (China) Using Frequency Ratio, Certainty Factor, and Index of Entropy. Geocart. Int. 2017, 32, 139–154. [Google Scholar] [CrossRef]
- Wang, Q.; Guo, Y.; Li, W.; He, J.; Wu, Z. Predictive Modeling of Landslide Hazards in Wen County, Northwestern China Based on Information Value, Weights-of-Evidence, and Certainty Factor. Geomat. Nat. Hazards Risk 2019, 10, 820–835. [Google Scholar] [CrossRef] [Green Version]
- Kavoura, K.; Sabatakakis, N. Investigating Landslide Susceptibility Procedures in Greece. Landslides 2020, 17, 127–145. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Conditional Probabilities | Favorability Function | Combination Rule | Reference |
|---|---|---|---|---|
| Frequency contrast | p(L|Fi), p(L|Fi,j) | Direct summation | e.g., [14] in 1993 | |
| Frequency ratio | p(L|Fi), p(L|Fi,j) | Direct summation | e.g., [5] in 2017 | |
| Information value | p(L|Fi), p(L|Fi,j) | Direct summation | e.g., [14] in 1993 | |
| Certainty factor | p(L|Fi), p(L|Fi,j) | Combination rule of certainty factor | e.g., [18] in 2004 | |
| Cosine amplitude | p(L|Fi,j), p(Fi,j|L) | Direct summation | e.g., [19] in 2006 | |
| Weight of evidence | p(Fi,j|L), p(Fi,j|), p(|L), p(|) | Direct summation, logit transformation | e.g., [28] in 1989 | |
| Weight contrast | p(Fi,j|L), p(Fi,j|), p(|L), p(|) | Direct summation | e.g., [29] in 2010 | |
| Sufficiency ratio | p(Fi,j|L), p(Fi,j|) | Direct summation | e.g., [30] in 2001 |
| Concept | Explanation |
|---|---|
| Landslide susceptibility | Landslide susceptibility is an assessment of the relative spatial probability of landslides, and, more comprehensively, should include an assessment of landslide type and size whenever possible. In most studies, landslide susceptibility only estimates where landslides are likely to occur. |
| Favorability value | The favorability value quantifies the “degree of favorability to landslides” of a particular value of a particular predisposing factor for landslides. Traditionally, it quantifies the degree of favorability of a particular class of a particular factor. |
| Favorability layer | A favorability layer for a particular factor layer is produced when all factor values are replaced by their corresponding favorability values. |
| Favorability function | A favorability function is the function used to calculate favorability values for factor values. Favorability function and combination rule are two core components defining a bivariate method. |
| Combination rule | The combination rule is the rule used in combining the favorability layers of all factors to form a landslide susceptibility index (LSI) layer. For a particular location, each factor will give a favorability value. The combination of all favorability values given by all factors at a particular location is the LSI value of that location. |
| Conditional probability | Conditional probability in this paper is the occurrence probability of landslides given a factor value or a set of factor values. Conditional probabilities are usually derived from empirical data. Empirical conditional probabilities are commonly used in favorability functions to calculate favorability values for factor values. |
| Method | Grid Cell | Favorability Value | Landslide Susceptibility Index (LSI) | |
|---|---|---|---|---|
| Factor Ⅰ | Factor Ⅱ | |||
| Frequency ratio | A | 1.010000 | 0.990000 | 2.000000 |
| B | 1.020000 | 0.980100 | 2.000100 | |
| Information value | A | 0.004321 | −0.004365 | −0.000044 |
| B | 0.008600 | −0.008730 | −0.000130 | |
| Method | Prediction Rate | ||||||
|---|---|---|---|---|---|---|---|
| Optimal | Conventional | Average | |||||
| 10 Classes | 5 Classes | 3 Classes | Value | Percent Difference | |||
| Frequency contrast | 0.8662952 | 0.8584045 | 0.8493557 | 0.8291332 | 0.8507972 | 0.51 | |
| Frequency ratio | 0.8662952 | 0.8584045 | 0.8493557 | 0.8291332 | 0.8507972 | 0.51 | |
| Information value | 0.8672740 | 0.8622345 | 0.8545712 | 0.8360119 | 0.8550229 | 0.02 | |
| Certainty factor | 0.8675016 | 0.8622918 | 0.8548182 | 0.8360542 | 0.8551665 | N.A. | |
| Cosine amplitude | 0.8431700 | 0.8217469 | 0.8314922 | 0.8103809 | 0.8266975 | 3.44 | |
| Weight of evidence | 0.8575339 | 0.8531959 | 0.8482106 | 0.8280323 | 0.8467432 | 0.99 | |
| Weight contrast | 0.8660074 | 0.8559619 | 0.8502049 | 0.8303770 | 0.8506378 | 0.53 | |
| Sufficiency ratio | 0.8662463 | 0.8583069 | 0.8492890 | 0.8291290 | 0.8507428 | 0.52 | |
| Average | Value | 0.8625405 | 0.8538184 | 0.8484122 | 0.8285315 | N.A. | |
| Percent difference | N.A. | 1.02 | 1.67 | 4.10 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, L.; Lan, H. Bivariate Landslide Susceptibility Analysis: Clarification, Optimization, Open Software, and Preliminary Comparison. Remote Sens. 2023, 15, 1418. https://doi.org/10.3390/rs15051418
Li L, Lan H. Bivariate Landslide Susceptibility Analysis: Clarification, Optimization, Open Software, and Preliminary Comparison. Remote Sensing. 2023; 15(5):1418. https://doi.org/10.3390/rs15051418
Chicago/Turabian StyleLi, Langping, and Hengxing Lan. 2023. "Bivariate Landslide Susceptibility Analysis: Clarification, Optimization, Open Software, and Preliminary Comparison" Remote Sensing 15, no. 5: 1418. https://doi.org/10.3390/rs15051418
APA StyleLi, L., & Lan, H. (2023). Bivariate Landslide Susceptibility Analysis: Clarification, Optimization, Open Software, and Preliminary Comparison. Remote Sensing, 15(5), 1418. https://doi.org/10.3390/rs15051418