Abstract
Precipitation nowcasting has long been a challenging problem in meteorology. While recent studies have introduced deep neural networks into this area and achieved promising results, these models still struggle with the rapid evolution of rainfall and extremely imbalanced data distribution, resulting in poor forecasting performance for convective scenarios. In this article, we evaluate the amount of information in different precipitation nowcasting tasks of varying lengths using mutual information. We propose two strategies: the mutual information-based reweighting strategy (MIR) and a mutual information-based training strategy (time superimposing strategy (TSS)). MIR reinforces neural network models to improve the forecasting accuracy for convective scenarios while maintaining prediction performance for rainless scenarios and overall nowcasting image quality. The TSS strategy enhances the model’s forecasting performance by adopting a curriculum learning-like method. Although the proposed strategies are simple, the experimental results show that they are effective and can be applied to various state-of-the-art models.
1. Introduction
Precipitation nowcasting aims to predict the kilometer-wise rainfall intensity within the next two hours [1]. It plays a vital role in daily life, such as traffic planning, disaster alerts, and agriculture [2]. Precipitation nowcasting is often defined as a spatiotemporal sequence prediction task [3,4,5,6,7]. A sequence of historical radar echo images is taken in and a sequence of future radar echo images is predicted [3]. In this paper, we denote the historical radar echo images as X and the future (to be predicted) radar echo images as Y. The rainfall intensity distribution of the whole dataset will be (or , because both X and Y are drawn from the same distribution), and the precipitation nowcasting task can be represented as .
However, due to the highly skewed distribution of rainfall intensities, the traditional approach has a limited ability to forecast heavy rainfall scenarios [8]. For instance, using the Italian dataset TAASRAD19 [9] as an example, the number of pixels with a radar reflective intensity greater than 50 dBZ accounts for only 0.066% of the total number of pixels, and only 0.45% of pixels are greater than 40 dBZ. The same situation also exists in the ECP dataset [10] and HKO-7 dataset [11], as illustrated in Figure 1. Radar echo intensity (dBZ) does not correspond to the rainfall intensity (mm/h). The conversion from radar reflectivity to rainfall intensity requires a precipitation estimation algorithm, such as the Z–R relation formula. This paper focuses on radar echo intensity prediction; rainfall intensity can be estimated from the predicted radar echo intensity using an estimation algorithm [3].
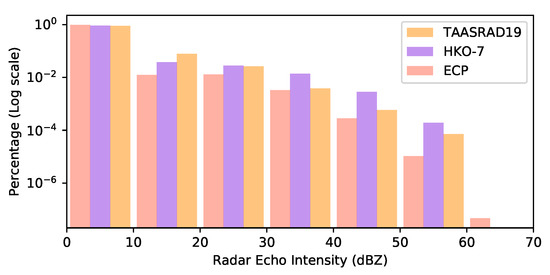
Figure 1.
Distribution of different radar echo intensity levels. ECP and TAASRAD19 were collected from the north temperate zone, and HKO-7 was collected from the tropics.
Heavy rainfall scenarios are often rare; however, if left unaddressed, they will have more severe consequences than moderate to light rainfall scenarios. Therefore, efforts have been devoted to improving the heavy rain forecasting performance, with reweighting and resampling being the most popular strategies [8,11,12]. These strategies could increase the heavy rainfall sample weights based on .
However, adjusting the sample weights or prediction losses based on would undermine the conditional distribution , downgrading the majority classes’ performance and hurting the overall rainfall prediction accuracy.
In this work, we propose a new strategy, mutual-information-based reweighting (MIR), to improve the nowcasting prediction for imbalanced rainfall data. Mutual information measures the dependence between random variables X and Y, with high mutual information corresponding to high-dependency X and Y (easy-to-learn) tasks, and low mutual information corresponding to low-dependency (hard-to-learn) tasks [13].
In the task of precipitation nowcasting, we calculate the mutual information of the radar echo data and observe that tasks with more mutual information exhibit greater resilience to the issue of data imbalance. Specifically, when the mutual information is high, MIR employs relatively mild reweighting factors to preserve the original distribution of . Conversely, for tasks with low mutual information, MIR employs higher reweighting factors to enhance the prediction performance. This approach boosts the performance of the minority groups without negatively impacting the overall prediction performance.
Furthermore, we propose a simple curriculum-style training strategy, the time superimposing strategy (TSS). The primary advantage of curriculum learning is that it enables machines to start learning with more manageable tasks and gradually progress to more challenging ones. Inspired by this, TSS first trains the model with the highest mutual information task and gradually stacks the lower mutual information tasks into the training task set. Regarding implementation, the TSS strategy only requires control over the forecast time length during loss calculation during the training phase, which can be achieved by adding just one or two lines of code.
This work is an extension of our previous work [14], which fused MIR and TSS together. In this paper, we elaborate on the MIR and TSS strategies separately, provide a more detailed experimental analysis, and extensively discuss different aspects of the proposed strategies.
The remainder of this paper is organized as follows. Section 2 briefly reviews the related works about deep learning models and the data imbalance problem in precipitation nowcasting. In Section 3, we describe how to compute the mutual information for the precipitation nowcasting task. Then, a reweighting strategy, MIR (Section 3.2), and a curriculum-learning-style training strategy, TSS (Section 3.3), are proposed based on the mutual information of the training tasks. Extensive experiments in Section 4 reveal that the proposed MIR and TSS strategies reinforce the state-of-the-art models’ performances using a large gap without downgrading the overall prediction performance. Section 5 discusses several research questions. The conclusions are shown in Section 6.
2. Related Works
2.1. Models for Precipitation Nowcasting
Precipitation nowcasting models can be classified into three categories: numerical weather prediction methods, extrapolation-based methods, and deep-learning-based end-to-end methods [10]. This paper concentrates on the latter due to their exceptional performance. To be more specific, deep learning models can be categorized into two types: ConvLSTM-based and UNet-based models [15].
The ConvLSTM proposed by Shi et al. is a notable achievement in this field. This replaces the fully connected layer in the long short-term memory (LSTM) [16] with a convolution layer and extends LSTM to the image domain. Subsequently, many ConvLSTM-based models emerged [17]. For example, in TrajGRU [11], the convolution layer was transformed into a non-local version and analogically integrated with GRUs to allow for the active learning of location-variant patterns. PredRNN, introduced by Wang et al. [18], separates the spatial and temporal memory and communicates them at distinct LSTM levels. Another model by Espeholt et al. [19] uses a ConvLSTM-based approach for large-scale precipitation forecasting, which is capable of predicting up to 12 hours in advance.
Nowcasting models based on UNet [20], such as RainNet [21], vanilla UNet [22], and MSST-Net [23], have recently emerged, thanks to the faster training capability of CNN compared to RNN. Agrawa et al. [22] treated forecasting as an image-to-image translation, and thus adopted UNet to classify at a high resolution in terms of both space and intensity, which was similar to the SmaAt-UNet [24] approach. Moreover, they equipped the basic UNet with the attention modules and achieved competitive accuracy, notably reducing the number of trainable parameters. T-UNet [25] combines TrajGRU and UNet to further improve the model’s forecasting ability.
Furthermore, GAN was adopted in the precipitation nowcasting tasks to improve the imagery quality [26]. DGMR, proposed by Ravuri et al. [12], adopts a UNet encoder and a ConvLSTM decoder to solve the blurry problem from the perspective of generative models. These models improve the nowcasting performance compared to the original ConvLSTM model by modifying the network structure to enhance the fitting ability. We argue that fitting ability is not the only key factor in this task. Rethinking the nowcasting problem in the task from a data perspective helped us to acquire better nowcasting models in this paper.
2.2. Data Imbalance
The data imbalance problem is prevalent in various forms of natural data [27]. The research on data imbalance has a long history and generally refers to the problem where the uneven distribution of affects the model training. The basic assumption is that the of the training data is unbalanced, making it easy for the model to train trivial solutions, which leads to a good performance in the majority class and poor performance in the minority class [28]. In Section 3.2, we challenge this assumption using a toy classification problem.
Resampling and reweighting are two common strategies for addressing the data imbalance problem. The typical strategy is over-sampling or up-weighting minority classes [29]. However, in precipitation nowcasting, the resampling method is usually performed patch-wise or sample-wise, which is less feasible for the pixel-level imbalanced precipitation data [8]. Reweighting methods are proposed to adjust the importance of different rainfall intensity samples to balance the impact of data imbalance using the reweighted loss for different rainfall intensities [8,11]. Ravuri et al. [12] adopted the importance of sampling and reweighting to reduce the number of rainless samples. Although these works improve the forecast indicators for the minority class (heavy rainfall), they compromise the model performance on the majority class and the overall image quality.
There are other ways to mitigate the data imbalance problem. Feature selection techniques help to pre-process the data [30]. Recent studies also indicated that semi-supervised and self-supervised learning strategies alleviate the influence of imbalanced data [31]. In contrast to these works, we rethink the data imbalance assumption and analyze the data imbalance problem by considering mutual information.
3. Methodology
In this section, we begin by explaining the process of calculating conditional distribution and mutual information, which is essential when identifying tasks with a high or low information content. Next, we explore the connection between mutual information and the data imbalance problem, and present a novel mutual information-based reweighting approach that addresses the limitations of existing methods. Finally, we introduce a curriculum-style learning strategy that guides the model to learn tasks progressively. This approach prioritizes tasks with a high level of mutual information, allowing for the model to master them before moving on to those with lower mutual information.
3.1. Estimating the Mutual Information on Precipitation Nowcasting Tasks
Existing deep-learning-based models [10,11,18] usually regard the precipitation nowcasting task as a spatiotemporal forecasting problem. Models encode information from a sequence of historical radar echo images and generate a sequence of m future radar echo images that are most likely to occur, which can be formulated as
where is the radar echo image sequence, is the temporal length, and H and W are the height and the width of images, respectively. Each pixel in the rainfall data has an echo intensity value within , corresponding to the rainfall intensity.
In information theory, the mutual information is proposed to quantify the information gain achieved by Y by knowing X, and vice versa [13]. This is defined as , where information entropy and conditional entropy . When X and Y are independent, and ; when X determines Y, .
However, calculating the mutual information in a high-dimensional task is challenging. Mutual information measures the dependence between random variables X and Y, which involves an estimate of the probability density distribution and an estimate of the marginal distributions and . When the task is low-dimensional, it is relatively easy to obtain sufficient training data to estimate ; however, when the task is high-dimensional, it is hard to obtain extensive enough training datasets to estimate . This phenomenon is called the curse of dimensionality. As a result, previous researchers usually train large and over-parameterized generative models with limited training data to approximate .
To avoid training an approximated generative model for estimation, we transfer the high-dimensional radar echo image intensity prediction task into a one-dimensional radar echo pixel intensity prediction task. More specifically, in this section, we regard the precipitation nowcasting task as a series of pixel prediction tasks with different forecasting lengths. As the dimension of Y shrinks to 1, estimating and is straightforward and easy. In this way, mutual information is calculated.
To calculate the joint probability distribution, we first propose redefining the precipitation nowcasting task at the pixel level:
where denotes the value of the pixel i at time , refers to the set of spatiotemporal neighbors (Here, neighbors of pixel i are the pixels from the length-l cube centered at pixel i) of pixel i at time , and represents the value of pixel i at time , where . It is important to note that . Equations (1) and (2) are equivalent only if covers current as well as all past image pixels.
Next, we employ a three-dimensional Gaussian convolution, , of size on each pixel i to merge the information of spatiotemporal neighboring pixels.
During this procedure, only the first-order spatiotemporal information is kept, and higher-order information such as standard deviation and gradient direction is lost. Then, Equation (2) could be rewritten as:
Third, we compute the conditional distribution across the whole training dataset, which approximates . The conditional probability is computed as:
Finally, mutual information is computed as:
Here, the probability and can be obtained similarly, as . The mutual information indicates the degree to which X determines Y; therefore, we can use it to measure the degree to which determines .
Figure 2 displays two conditional distribution matrices. To facilitate interpretation, the rainfall intensity is divided into five categories of equal size. The mutual information for the three precipitation nowcasting datasets with different t values is shown in Figure 3, where . It should be noted that the mutual information does not always monotonically decrease with increasing t. For instance, the mutual information fluctuates periodically when dealing with periodic data as t increases.
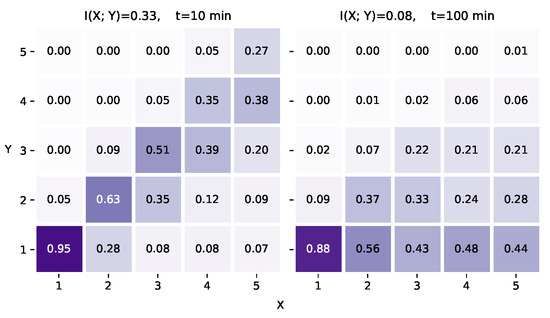
Figure 2.
The conditional distributions of two precipitation nowcasting tasks on one dataset. Left: Task predicting future radar echo intensity in the next 10 min. Right: Task predicting future intensity in the next 100 min. The radar echo intensity (0–70 dBZ) is evenly divided into five categories, and the X and Y axes stand for the index of each category. The value in each cell represents the corresponding joint probability . Take in the bottom-left corner of the left image as an example: if the current intensity is in category 1 (0–14 dBZ), the probability that the intensity in 10 min is still category 1 is .
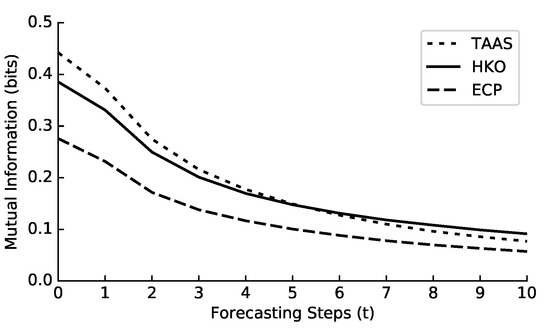
Figure 3.
Mutual information of tasks with different forecasting lengths from three precipitation datasets.
3.2. Mutual Information-Based Reweighting (MIR) Strategy
While reweighting methods based on may decrease the quality of generated images, sacrificing part of the majority’s performance to improve the minority is still acceptable in precipitation nowcasting, where heavy rainfall is more critical. This subsection proposes a new reweighting scheme that considers mutual information to adjust the weighting factors. To better understand the relationship between data imbalances and mutual information, consider a binary classification experiment.
3.2.1. Motivating Example
In this experiment, the training data are sampled from two one-dimensional Gaussian distributions A and B, where , , and . The objective is to train a binary classifier to distinguish whether a testing sample is generated from A or B. The testing dataset is balanced, and a three-layer, fully connected network is used as the model.
Table 1 displays the mean absolute error (MAE) for different levels of imbalance ratios and settings. The mutual information values are indicated within the brackets. The model’s prediction is considered correct when the MAE equals to 0, and is regarded as random guessing when the MAE equals 0.5.

Table 1.
MAE of the imbalanced binary classification problem. The imbalance ratio refers to the ratio of the number of samples in class A to the number of samples in class B.
Traditionally, the data imbalance issue has been associated with the reduced performance of minority classes due to the imbalanced . This holds true when is constant. However, when the imbalance ratio is constant, the MAE decreases as and mutual information increases, indicating that the impact of data imbalance is reduced. The model becomes resilient to data imbalances when the standard deviation equals one, and . This experiment demonstrates that the imbalanced distribution does not necessarily lead to poor performance for the minority class. High mutual information tasks result in better model training when the imbalance ratio is constant compared to low mutual information tasks.
In an imbalanced setting, such as 1:99, the mutual information is lower than in a balanced setting because the information entropy , representing the upper bound of mutual information. Therefore, the trend of mutual information values within each imbalance ratio is more important than the value itself. When the imbalance ratio or is constant, mutual information can help to identify settings that are more resilient to the impact of data imbalance. Thus, it is unnecessary to use reweighting strategies for high mutual information tasks, avoiding the side effect of image quality degradation.
3.2.2. MIR Strategy
Figure 3 shows that mutual information is high for small values of t. Therefore, a rebalancing strategy is unnecessary and could lead to misinformation in . To address this issue, we propose a reweighting ratio , as the exponential factor of the reweighting factor w, based on :
where w uses the same reweighting factors as WMSE [11]. The new weighting factor is directly multiplied by the respective loss to derive the reweighted loss. A simple solution is because mutual information negatively correlates with t. The proposed meets the requirement of an unweighted loss at higher mutual information and a precipitous for lower mutual information. This approach avoids degrading image quality and undermining the original distribution of reweighting strategies.
In this paper, we adopted the same weighting factor w of following the weighted mean square error (WMSE) [11], which is
Since the degree to which affecting the model’s resistance of data imbalance was unknown, we tried several different naive solutions:
- (a)
- Linear to t: , where , is a constant that controls the expected growing speed of . The code is shown in Algorithm 1.
- (b)
- Exponential: , where is a constant that depends on the expected growing speed of , and in this paper.
- (c)
- Linear to :. When , . As shown in Figure 4, this solution is similar to a special version of the linear solution.
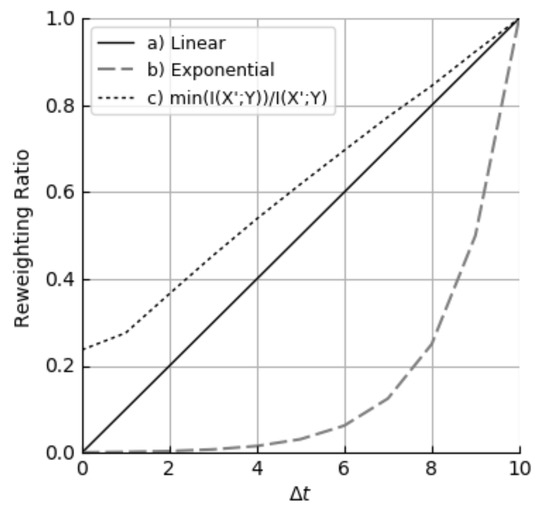 Figure 4. Three strategies of MIR.
Figure 4. Three strategies of MIR.
| Algorithm 1 MIR Strategy |
|
3.3. Time Superimposing Strategy (TSS)
Traditionally, neural network models are simultaneously trained with all tasks, from to . The graph in Figure 3 illustrates that the training task at provides the highest amount of information. As the forecasting length t increases, the mutual information steadily decreases. We adopt a curriculum learning approach to improve training efficiency and reorganize the training order of different forecasting length tasks. A straightforward strategy is to start with high mutual information tasks and gradually move to low mutual information tasks.
Suppose there is a set of training tasks, and the model is trained with all the tasks in the set during every iteration of the training process. The task set starts with only the task for , and progressively incorporates other forecasting tasks with increasing lengths until .
To be specific, the initial training task is . In the next stage, we simultaneously train and . In stage three, we simultaneously train , , and , and so on.
We name this method the time superimposing strategy (TSS). TSS could be simplified into a loss function controlling forecasting length. The TSS with fixed training iterations per stage is shown in Algorithm 2. More TSS variants are discussed in Section 4.3.
| Algorithm 2 TSS Strategy |
|
4. Experiment
4.1. Experimental Settings
4.1.1. Dataset
Three radar echo datasets were considered in the experiments: TAASRAD19 [9], HKO-7 [11], and East China Precipitation dataset [10]. We refer to these as TAAS, HKO, and ECP, respectively. Dataset details are shown in Table 2. We adopted the abnormal detection method in the Ref. [9] to mask the noise pixels. Sequences with a raining area less than 5% were removed during pre-processing. Datasets were split based on the chronological order of observations: the first 70% of the dataset was used for training, the next 10% for validation, and the last 20% for testing.
Table 2.
Summary of three precipitation datasets.
Neural network models on precipitation nowcasting tasks often make consecutive ten echo frames forecasting, which is used to evaluate the model prediction performance [3]. In this study, our goal was to predict precipitation about two hours ahead accurately. Therefore, we trained models to predict a consecutive sequence of 10 echo frames, and the time interval between neighboring frames should be around 12 min so that the final echo frame will be reached about two hours later. The original time interval between two adjacent echo frames in TAAS was 5 min, and 6 min for HKO and ECP; when running the experiment, we extended the interval between echo frames by two times for computational efficiency (10 min for TAAS, and 12 min for HKO and ECP).
4.1.2. Criterion
We adopted two meteorological indicators: critical success index (CSI) and Heidke skill score (HSS). CSI and HSS are defined as:
where z (dBZ) is the threshold and TP, FN, FP, and TN are True Positive, False Negative, False Positive, and True Negative, respectively. Here, we empirically chose 20 dBZ to denote a drizzle, 30 dBZ for moderate, and 40 dBZ for heavy rain. It was also necessary to evaluate how the predicted radar echo images match the corresponding ground truth. Thus, we also reported results for two popular computer vision criteria: the structure similarity index measure (SSIM) [32] and mean square error (MSE).
SSIM assessed the similarity between two images, x and y; this can be defined as: The brightness similarity is represented by , the contrast similarity is represented by , and the structural similarity is represented by . The mean values of x and y are and , respectively, and their standard deviations are and , respectively. is the cross-correlation between x and y. Small positive constants , , and were added to prevent division by zero and numerical instability. These values were calculated based on a certain local patch in the image.
4.1.3. Implementation Details
We set the model’s input echo frame sequence length to 5 and the output sequence length to 10. Radar echo images were resized to . All models were optimized for 50,000 iterations, using the ADAM optimizer with a learning rate of 0.001 with a batchsize . The loss function was L1 + L2 loss. Our experiments were implemented with PyTorch, and the training processes were conducted on 4 Nvidia Tesla A100 GPUs.
4.2. Results of MIR and TSS
We applied MIR and TSS to ConvLSTM, a well-known model, and present the results on three precipitation nowcasting datasets in Table 3. We also evaluated two other strategies, Scheduled Sampling (SS) [33] and WMSE [11], as competitors. SS is a curriculum strategy used by PredRNN that adopts a sampling procedure at each timestep t and adjusts the sampling rate based on the index of training iterations. However, this is incompatible with pyramid-shaped networks such as TrajGRU, DGMR, and UNet. Meanwhile, WMSE is a reweighting strategy utilized by TrajGRU that improves minority performances by a large margin but downgrades the performance of 20dBZ and the overall image quality.
Table 3.
Results of ConvLSTM on three datasets. ↑ stands for the higher, which denotes a better result. ↓ stands for the lower, which denotes a better result. The values of 20, 30, and 40 dBZ denote the thresholds of criterion CSI and HSS, and avg is their mean.
Table 3 shows that ConvLSTM + TSS outperforms ConvLSTM and ConvLSTM + SS in all criteria. Notably, the proposed MIR strategy improves both the minority and majority performance as CSI and HSS are higher on 20, 30, and 40 dBZ than WMSE. However, both MIR and WMSE decrease MSE and SSIM, and WMSE performs worse. ConvLSTM + TSS + MIR achieves much better performance than all baseline strategies. We can conclude that TSS and MIR assist the model in learning more information by handling high mutual information tasks.
We demonstrated a forecasting example in Figure 5. Both UNet and ConvLSTM predicted the correct trend with the wrong position. However, ConvLSTM + TSS and ConvLSTM + TSS + MIR managed to forecast a relatively correct position. MIR encourages the model to make more heavy rainfall predictions.
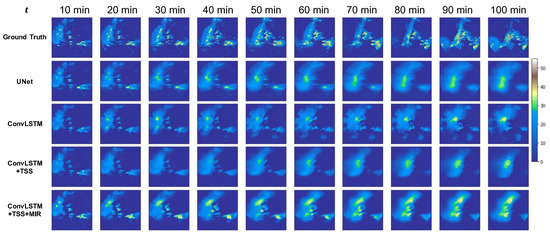
Figure 5.
Radar reflectivity predictions of different strategies.
Furthermore, we applied MIR and TSS to six models to assess the universality of the proposed strategies. As shown in Table 4, we can see that TSS enhances the performance of both majority and minority classes, as Model + TSS exhibits better overall performance on CSIavg and HSSavg than the model that does not utilize TSS. Moreover, when comparing Model + TSS with Model + TSS + MIR, we observe that MIR significantly improves the performance of the minority class without compromising the majority performance and the overall image quality. By leveraging TSS and MIR, ConvLSTM (2015) outperforms the latest precipitation nowcasting models.
Table 4.
Results of TSS and MIR on various models on the TAAS dataset.
4.3. Hyperparameters of MIR and TSS
4.3.1. MIR
Table 5 presents the results of several MIR variants, including three strategies ((a), (b), and (c)) described in Section 3.2, where and are hyperparameters controlling the reweighting factor of MIR. The results are divided into two categories, with and without TSS, demonstrating that models utilizing TSS outperform those without it. Additionally, the MIR strategy can further improve the model’s overall performance. Among the reweighting methods, our proposed shows excellent performance (with the second-highest ) and does not require any hyperparameters. Method (a) achieves the best with and .
Table 5.
MIR strategies on HKO-7. False TSS stands for the t fixed to 10.
4.3.2. TSS
The model’s performance is influenced by the number of training iterations L for each forecasting length t. Table 6 shows the performances of multiple TSS variants with different L. The 1k indicates that the model was trained for 1000 iterations for each , with a total of 10,000 iterations. After 10,000 iterations, the model may not converge but will continue training, with t being 10 for the remaining training iterations. We proposed two other L changing strategies: and . For instance, means . We observed that the model’s performance gradually improved after , so we selected to reduce computational cost and reported the model’s performance at in this article. The L changing strategies are illustrated in Figure 6.
Table 6.
The TSS strategy with different L on ConvLSTM.
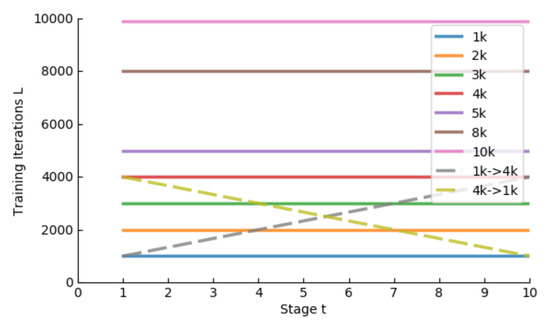
Figure 6.
TSS strategies with different L. t stands for the number of frames for training in Algorithm 2.
5. Discussion
5.1. How Does MIR Work?
Figure 7 displays the visualization of for TAAS. The figure exhibits the conditional distributions for five different forecasting lengths: , where ∞ represents infinity. At , is equal to , and and . We present the original , balanced , and MIR balanced from top to bottom, respectively.
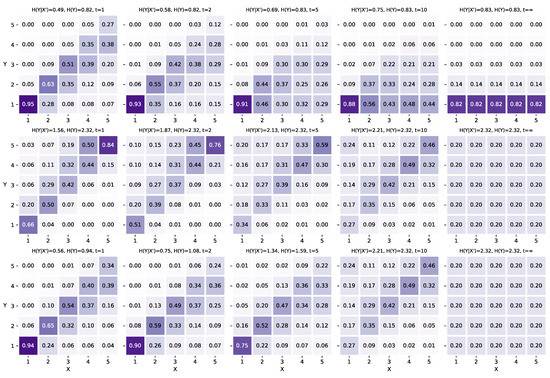
Figure 7.
(Top) of TAAS dataset. (Middle) balanced . (Bottom) MIR reweighting strategy. Smaller corresponds to larger . The radar echo intensity (0–70 dBZ) is divided into five categories evenly. X and Y axes stand for the index of the category.
Five images in the top row of Figure 7 show that with t increasing, the conditional distribution approaches the long-tailed distribution . The mutual information is high for or , which indicates that these tasks are relatively easy to learn. In contrast, for or , the mutual information is low, making it difficult for the models to learn the information. When predicting an echo image occurring in the infinite future (), is equal to .
The most simple and straightforward strategy to re-weight the training samples is to balance to a uniform distribution, and we visualize the corresponding conditional distribution in the middle row of Figure 7. Compared with the original in the first row, when t is either small (such as 1 and 2) or large (such as 5, 10, and ∞), all Y have a more uniformed probability. It indicates that this strategy stops the imbalanced tendency when t is large, but it changes the conditional distribution for easy-to-learn tasks at smaller t. For instance, when , the rebalanced matrix has smaller values under the diagonal than the original matrix. Since smaller t tasks are relatively easy to learn, this rebalancing strategy does not provide any benefit in this scenario.
Figure 7 presents the original conditional distribution , the marginal distribution , and the MIR-balanced . The MIR approach leverages two main strategies: (i) preservation of the conditional distribution of high mutual information tasks, such as and , and (ii) readjustment of the conditional distribution for low mutual information tasks with large t. This results in the MIR-balanced having higher mutual information at smaller t and a relatively even distribution for large t.
5.2. What Is the Relationship between Mutual Information and Model Performance?
As discussed in Section 3.2, the mutual information is negatively correlated with t, and the model shows better resistance to the data imbalance problem in high mutual information scenarios. To verify the impact of the mutual information on the performance of precipitation nowcasting models, we conducted experiments on two models and three precipitation datasets with 1, 2, 5, and 10 for the training phase. Setting allowed for the loss function to be calculated with all 10 predicted frames. The forecasting length of all experiments was 10 frames in the inference phase, and all the results were averaged across 10 timesteps. Table 7 records the experiment results on three datasets and the two most well-known models: an RNN model ConvLSTM and a CNN model UNet. Although ConvLSTM and UNet were proposed 7 years ago, these two models still ranked top in recent precipitation nowcasting contests due to their simple structure and good compatibility.
Table 7.
Performance with different ts.
As shown in Table 7, in terms of minority classes (CSI and HSS), both ConvLSTM and UNet achieve better performance at smaller t, and worse performance at larger t. This demonstrates that larger tasks provide models with better data imbalance resistance.
Furthermore, according to Xu et al. (2019) [35], UNet outperforms ConvLSTM in terms of 20 dBZ, 30 dBZ, and mean squared error (MSE), indicating that UNet is more adept at capturing low-frequency information. Nevertheless, UNet exhibits inferior performance in the structural similarity index (SSIM), which may be attributed to the rough fusion and expansion of the temporal axis utilized by UNet. Additionally, the Markov chain formulation of ConLSTM enables it to produce smoother results, which could also account for its superior performance.
5.3. Mutual Information across Datasets
The mutual information among the three datasets significantly differs. In Section 3, Figure 3 indicates that mutual information of HKO-7 declines slower than TAASRAD19. Considering the goal of enhancing the amount of information available for training tasks, HKO-7 appears to be a better training set. Hence, we conducted experiments involving the exchange of training and test sets for all three datasets. As per the results presented in Table 8, the HKO-7 training variants outperformed the other variants, including the consistent results from Table 7.
Table 8.
Switching the training set and the testing set of three datasets. * stands for TSS + MIR.
5.4. Limitations of Reweighting
Table 9 presents the experimental results of the WMSE variants with , , SS, and the TSS strategy evaluated on the TAASRAD19 dataset. The WMSE approach, which incorporates reweighting, substantially improves the CSI and HSS performance measures at 40 dBZ. However, compared to the non-weighting methods, the WMSE strategy results in an average (Average of 4 settings in Table 9) performance degradation of 5.2% for SSIM and 21.1% for MSE. For MIR, these figures are 0.04% and 3.5%, respectively, indicating that the WMSE method achieves a trade-off between image quality and minority class performance.
Table 9.
Reweighting strategy on the ConvLSTM of the TAASRAD19 dataset.
5.5. Limitations of MIR and TSS
TSS is a curriculum learning method that trains tasks in an order of increasing difficulty. It employs the mutual information of each task to control the training sequence. However, TSS only applies to the prediction part and not the encoding part, which limits its effectiveness on separate encoder–decoder networks such as TrajGRU. ConvLSTM uses the same model parameters for each time step, whereas UNet uses different parameters for each time step. Therefore, TSS is also limited for UNet since it has specific parameters for each timestep. Additionally, UNet encodes and generates all frames simultaneously, which reduces the need for a curriculum learning style strategy, as the parameters are relatively independent. To address this, MIR weakens the reweighting factors for high mutual information tasks, reinforcing the simplest reweighting strategy. This has been successful with both RNN and CNN structured precipitation nowcasting models.
However, the approximation method in Equation (3) degrades the higher-order information of the data and adds uncertainty to the approximated . Improving the approximation method can lead to a more precise .
6. Conclusions and Future Work
In the precipitation nowcasting task, previous studies have attributed poor prediction performances regarding heavy rainfall samples to the data imbalance issue. We found that prediction performance is related to both mutual information (MI) and data imbalance.
In this paper, we redefined the precipitation nowcasting task at the pixel level to estimate the conditional distribution and the mutual information . We found that higher corresponds to better data imbalance resistance. Inspired by this finding, a reweighting method, MIR, preserves more information by assigning smooth weighting factors for high data. MIR successfully avoids downgrading the performance of the majority class. By studying the relationship between and the forecasting timespan t, we found that a smaller t benefits the model’s training. Combining this feature with the merit of curriculum learning, ordered from easy to hard, we proposed a curriculum-learning-style training strategy. The experimental results demonstrated the superiority of the proposed strategies. With the help of the approximated and , we also tried to explain how -based reweighting works and to find an informative precipitation dataset. This work is only a preliminary exploration since is not fully utilized. More mutual information-based strategies remain to be discovered.
Author Contributions
Conceptualization, Y.C. and X.Z.; data curation, Y.C. and H.S.; formal analysis, Y.C.; funding acquisition, J.Z.; investigation, Y.C.; methodology, Y.C. and D.Z.; project administration, J.Z.; resources, Y.C.; software, Y.C.; supervision, H.S.; validation, H.S. and J.Z.; visualization, Y.C.; writing—original draft, Y.C.; writing—review and editing, D.Z., H.S. and J.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (Nos. 62176059, 62101136).
Informed Consent Statement
Not applicable.
Data Availability Statement
All three radar echo datasets are publicly available. TAASRAD19 can be downloaded from https://doi.org/10.3390/atmos11030267, https://doi.org/10.3390/rs11242922 (accessed on 1 March 2023). HKO-7 can be found at https://github.com/sxjscience/HKO-7 (accessed on 1 March 2023). ECP is available at https://doi.org/10.7910/DVN/2GKMQJ (accessed on 1 March 2023).
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| MIR | Mutual Information based Reweighting |
| TSS | Time Superimposing Strategy |
| LSTM | Long Short-term Memory |
| CNN | Convolution Neural Network |
| RNN | Recurrent Neural Network |
| CSI | Critical Success Index |
| HSS | Heidke Skill Score |
| SSIM | Structure Similarity Index Measure |
| MAE | Mean Absolute Error |
| MSE | Mean Square Error |
References
- Lebedev, V.; Ivashkin, V.; Rudenko, I.; Ganshin, A.; Molchanov, A.; Ovcharenko, S.; Grokhovetskiy, R.; Bushmarinov, I.; Solomentsev, D. Precipitation nowcasting with satellite imagery. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2680–2688. [Google Scholar]
- Sun, Z.; Sandoval, L.; Crystal-Ornelas, R.; Mousavi, S.M.; Wang, J.; Lin, C.; Cristea, N.; Tong, D.; Carande, W.H.; Ma, X.; et al. A review of Earth Artificial Intelligence. Comput. Geosci. 2022, 159, 105034. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.; Woo, W. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. In Proceedings of the International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 802–810. [Google Scholar]
- Niu, D.; Huang, J.; Zang, Z.; Xu, L.; Che, H.; Tang, Y. Two-stage spatiotemporal context refinement network for precipitation nowcasting. Remote Sens. 2021, 13, 4285. [Google Scholar] [CrossRef]
- Huang, Q.; Chen, S.; Tan, J. TSRC: A Deep Learning Model for Precipitation Short-Term Forecasting over China Using Radar Echo Data. Remote Sens. 2023, 15, 142. [Google Scholar] [CrossRef]
- Tuyen, D.N.; Tuan, T.M.; Le, X.H.; Tung, N.T.; Chau, T.K.; Van Hai, P.; Gerogiannis, V.C.; Son, L.H. RainPredRNN: A New Approach for Precipitation Nowcasting with Weather Radar Echo Images Based on Deep Learning. Axioms 2022, 11, 107. [Google Scholar] [CrossRef]
- Zhang, F.; Wang, X.; Guan, J. A Novel Multi-Input Multi-Output Recurrent Neural Network Based on Multimodal Fusion and Spatiotemporal Prediction for 0–4 Hour Precipitation Nowcasting. Atmosphere 2021, 12, 1596. [Google Scholar] [CrossRef]
- Cao, Y.; Chen, L.; Zhang, D.; Ma, L.; Shan, H. Hybrid Weighting Loss for Precipitation Nowcasting from Radar Images. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 3738–3742. [Google Scholar]
- Franch, G.; Maggio, V.; Coviello, L.; Pendesini, M.; Jurman, G.; Furlanello, C. TAASRAD19, a high-resolution weather radar reflectivity dataset for precipitation nowcasting. Sci. Data 2020, 7, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Cao, Y.; Ma, L.; Zhang, J. A Deep Learning-Based Methodology for Precipitation Nowcasting With Radar. Earth Space Sci. 2020, 7, e2019EA000812. [Google Scholar] [CrossRef]
- Shi, X.; Gao, Z.; Lausen, L.; Wang, H.; Yeung, D.Y.; Wong, W.; Woo, W. Deep learning for precipitation nowcasting: A benchmark and a new model. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5617–5627. [Google Scholar]
- Ravuri, S.; Lenc, K.; Willson, M.; Kangin, D.; Lam, R.; Mirowski, P.; Fitzsimons, M.; Athanassiadou, M.; Kashem, S.; Madge, S.; et al. Skilful precipitation nowcasting using deep generative models of radar. Nature 2021, 597, 672–677. [Google Scholar] [CrossRef] [PubMed]
- Brillouin, L. Science and Information Theory; Courier Corporation: North Chelmsford, MA, USA, 2013. [Google Scholar]
- Cao, Y.; Zhang, D.; Zheng, X.; Shan, H.; Zhang, J. Mutual Information based Reweighting for Precipitation Nowcasting. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023. [Google Scholar]
- Gao, Z.; Shi, X.; Wang, H.; Yeung, D.Y.; Woo, W.c.; Wong, W.K. Deep learning and the weather forecasting problem: Precipitation nowcasting. Deep Learning for the Earth Sciences: A Comprehensive Approach to Remote Sensing, Climate Science, and Geosciences; Wiley: Hoboken, NJ, USA, 2021; pp. 218–239. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Sun, N.; Zhou, Z.; Li, Q.; Jing, J. Three-Dimensional Gridded Radar Echo Extrapolation for Convective Storm Nowcasting Based on 3D-ConvLSTM Model. Remote Sens. 2022, 14, 4256. [Google Scholar] [CrossRef]
- Wang, Y.; Wu, H.; Zhang, J.; Gao, Z.; Wang, J.; Philip, S.Y.; Long, M. Predrnn: A recurrent neural network for spatiotemporal predictive learning. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 2208–2225. [Google Scholar] [CrossRef]
- Espeholt, L.; Agrawal, S.; Sønderby, C.; Kumar, M.; Heek, J.; Bromberg, C.; Gazen, C.; Hickey, J.; Bell, A.; Kalchbrenner, N. Skillful Twelve Hour Precipitation Forecasts using Large Context Neural Networks. arXiv 2021, arXiv:2111.07470. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Ayzel, G.; Scheffer, T.; Heistermann, M. RainNet v1. 0: A convolutional neural network for radar-based precipitation nowcasting. Geosci. Model Dev. 2020, 13, 2631–2644. [Google Scholar] [CrossRef]
- Agrawal, S.; Barrington, L.; Bromberg, C.; Burge, J.; Gazen, C.; Hickey, J. Machine learning for precipitation nowcasting from radar images. arXiv 2019, arXiv:1912.12132. [Google Scholar]
- Ye, Y.; Gao, F.; Cheng, W.; Liu, C.; Zhang, S. MSSTNet: A Multi-Scale Spatiotemporal Prediction Neural Network for Precipitation Nowcasting. Remote Sens. 2023, 15, 137. [Google Scholar] [CrossRef]
- Trebing, K.; Stanczyk, T.; Mehrkanoon, S. Smaat-unet: Precipitation nowcasting using a small attention-unet architecture. Pattern Recognit. Lett. 2021, 145, 178–186. [Google Scholar] [CrossRef]
- Zeng, Q.; Li, H.; Zhang, T.; He, J.; Zhang, F.; Wang, H.; Qing, Z.; Yu, Q.; Shen, B. Prediction of Radar Echo Space-Time Sequence Based on Improving TrajGRU Deep-Learning Model. Remote Sens. 2022, 14, 5042. [Google Scholar] [CrossRef]
- Xu, L.; Niu, D.; Zhang, T.; Chen, P.; Chen, X.; Li, Y. Two-Stage UA-GAN for Precipitation Nowcasting. Remote Sens. 2022, 14, 5948. [Google Scholar] [CrossRef]
- Chawla, N.V.; Japkowicz, N.; Kotcz, A. Special issue on learning from imbalanced data sets. ACM SIGKDD Explor. Newsl. 2004, 6, 1–6. [Google Scholar] [CrossRef]
- Yang, Y.; Zha, K.; Chen, Y.; Wang, H.; Katabi, D. Delving into deep imbalanced regression. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 11842–11851. [Google Scholar]
- Johnson, J.M.; Khoshgoftaar, T.M. Survey on deep learning with class imbalance. J. Big Data 2019, 6, 1–54. [Google Scholar] [CrossRef]
- Liu, H.; Zhou, M.; Liu, Q. An embedded feature selection method for imbalanced data classification. IEEE/CAA J. Autom. Sin. 2019, 6, 703–715. [Google Scholar] [CrossRef]
- Yang, Y.; Xu, Z. Rethinking the value of labels for improving class-imbalanced learning. Adv. Neural Inf. Process. Syst. 2020, 33, 19290–19301. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Bengio, S.; Vinyals, O.; Jaitly, N.; Shazeer, N. Scheduled sampling for sequence prediction with recurrent neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–10 December 2015; Volume 28. [Google Scholar]
- Wang, Y.; Long, M.; Wang, J.; Gao, Z.; Yu, P.S. PredRNN: Recurrent Neural Networks for Predictive Learning using Spatiotemporal LSTMs. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Xu, Z.Q.J.; Zhang, Y.; Xiao, Y. Training behavior of deep neural network in frequency domain. In Proceedings of the International Conference on Neural Information Processing, Bali, Indonesia, 8–12 December 2019; pp. 264–274. [Google Scholar]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).