

Data Matters: Rethinking the Data Distribution in Semi-Supervised Oriented SAR Ship Detection


Abstract
1. Introduction
- i.
- A dataset with complex scenarios can improve the generalization ability of the trained model, but currently, there are only a few indicators to qualitatively judge the complexity of data, such as nearshore and offshore, and there are no indicators that can be quantified.
- ii.
- The training process of DL models requires diverse and a large amount of labeled data. However, labeling ship targets in SAR images is time-consuming and expensive.
- iii.
- The traditional horizontal bounding box (HBB)-labeling method has difficulty describing the complex shapes and diverse directions of ship targets, and the HBB-labeling method often results in a large overlap area when ships are densely berthed near the shore, as shown in Figure 1a.
- iv.
- As shown in Figure 1b, there is much unavoidable speckle noise, strong sea clutter, and high sidelobe levels, caused by strong scattering points in SAR images, which increases the difficulty of detection to some extent.

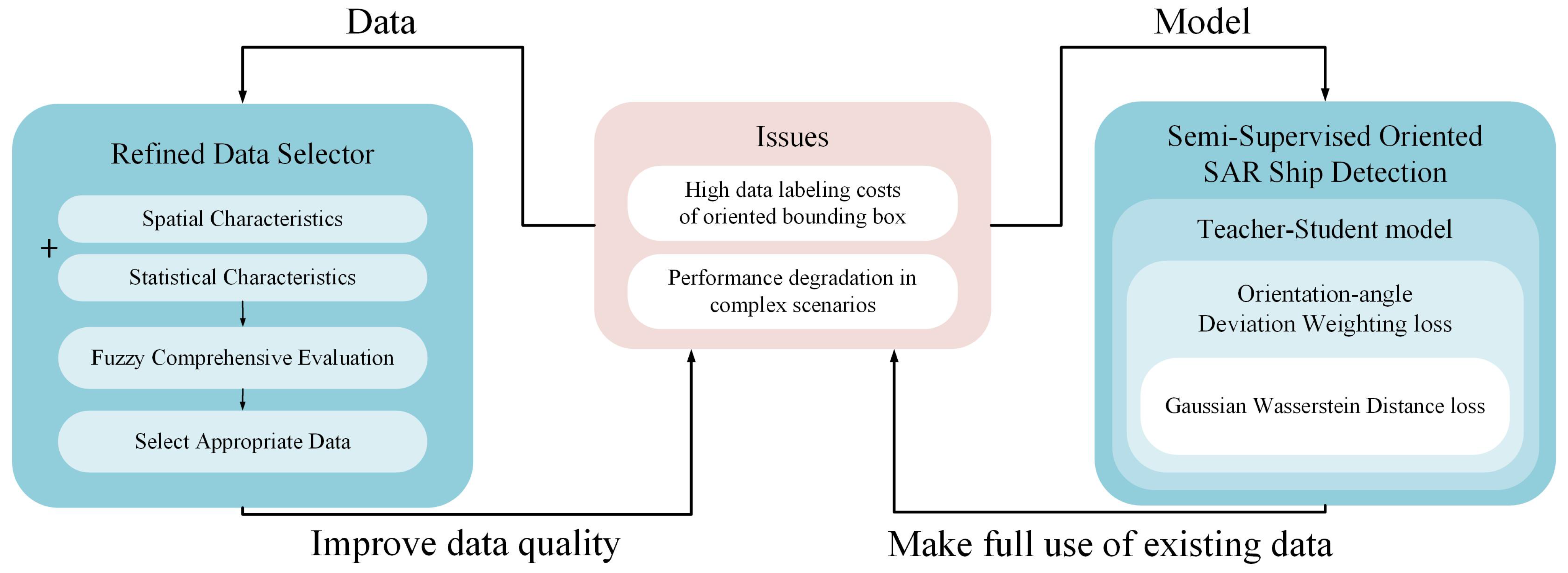
- We propose a novel framework based on a semi-supervised oriented object-detection (SOOD) [5] model according to the characteristics of the SAR ship-detection task. An orientation-angle deviation weighting (ODW) loss is proposed, which uses the GWD loss for bounding box regression.
- We propose a data-scoring mechanism based on FCE. According to the statistical characteristics of the data pixel gray-scale values and their spatial characteristics after graphics processing, a reasonable membership function is set, and each picture in the dataset is scored by FCE. Finally, the comprehensive scores of the data that are similar to the intuition are obtained.
- We propose a refined data selector (RDS) to select data with an appropriate score distribution. With the same amount of labeled data, the RDS can improve the training performance of the semi-supervised training algorithm model as much as possible. Therefore, when generating a new dataset of SAR ship detection data, the proposed method can be used to pre-select the data slices, which can reduce the burden of labeling and obtain data with more abundant scenes.
2. Related Works
2.1. SAR Ship Detection
2.2. Addressing Labeling Costs
3. Methods
3.1. Refined Data Selector
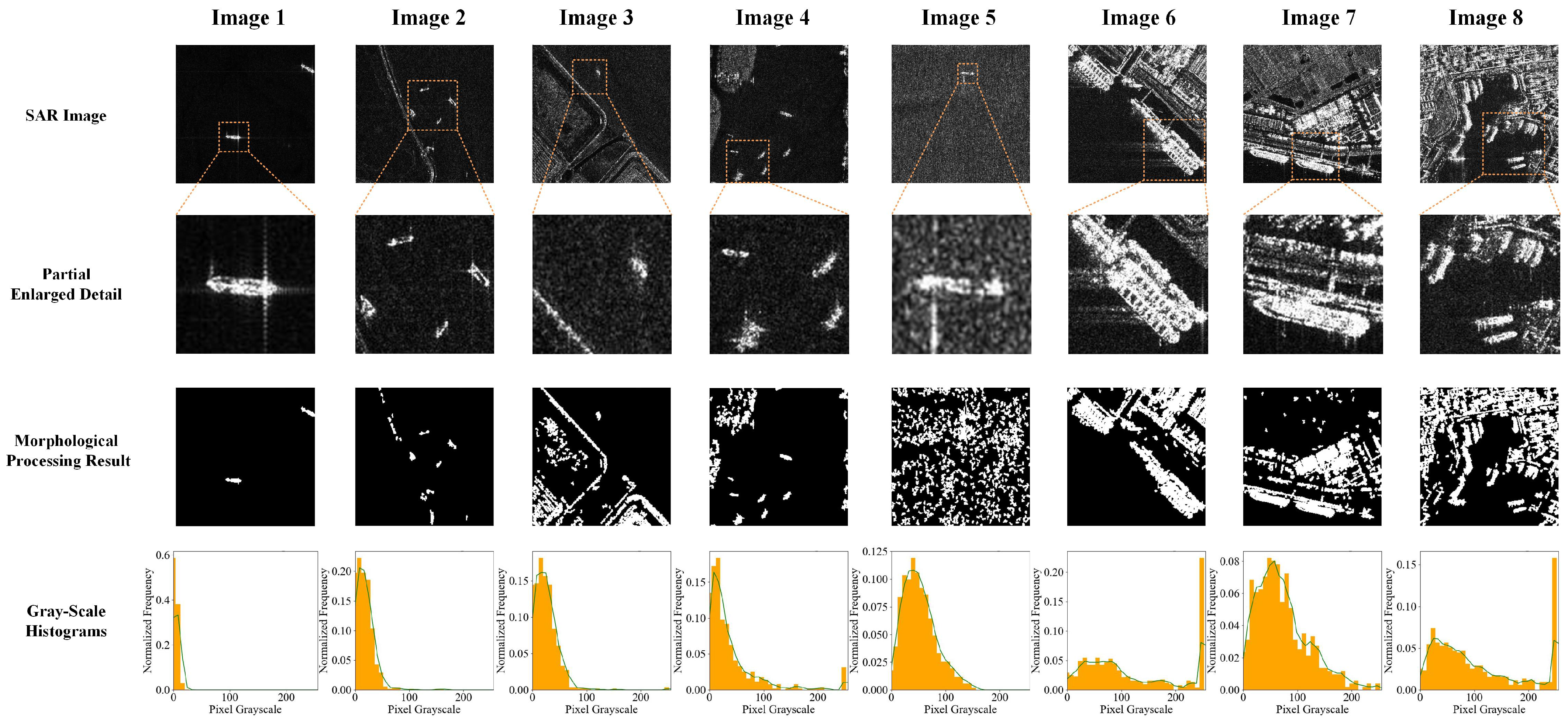
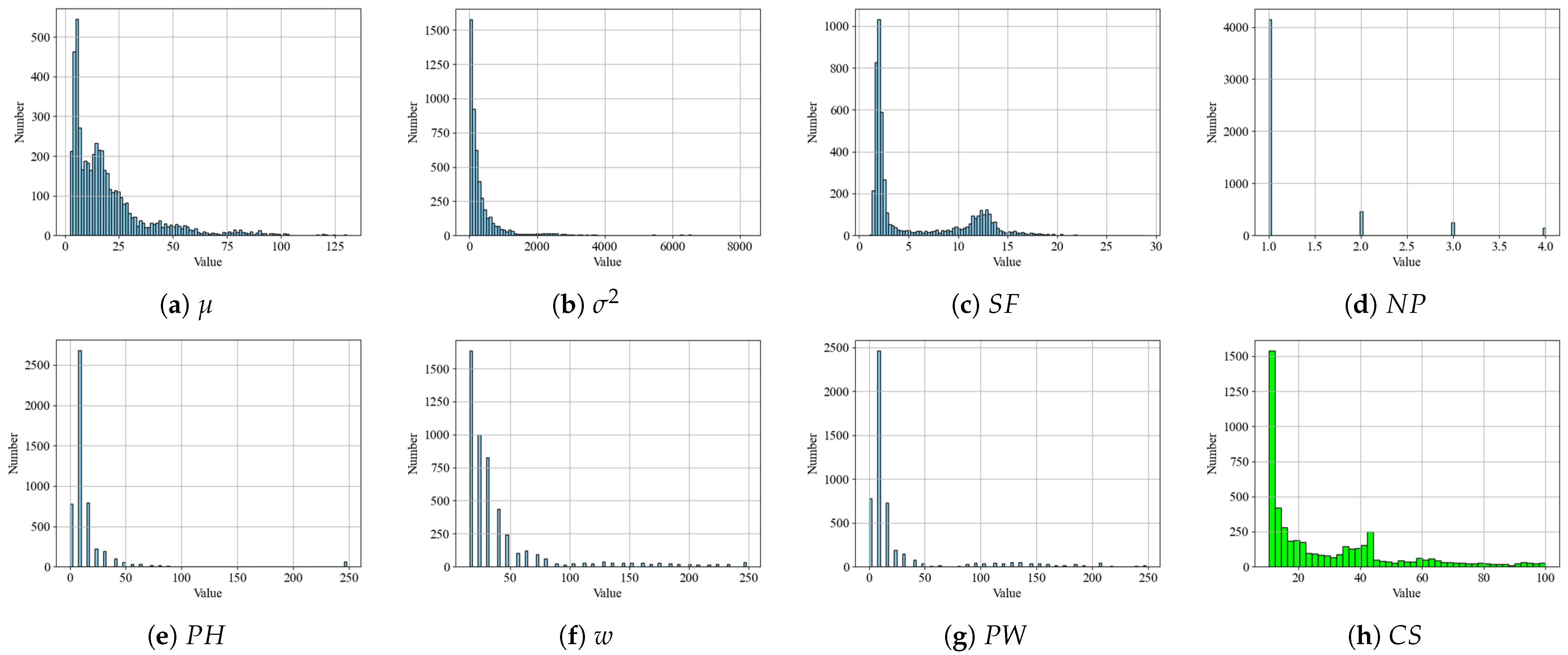
3.1.1. Construction of Evaluation Indicators
Mean and Variance
Number of Peaks , Position of Highest Peak , Width of Widest Peak w, and Position of Widest Peak
Spatial Factor
3.1.2. Fuzzy Comprehensive Evaluation
Factor Set and Evaluation Set
Comprehensive Evaluation Matrix
3.1.3. Choice of Appropriate Data
3.2. Orientation-Angle Deviation Weighting Loss
4. Experiments and Analysis
4.1. Datasets’ Description
- RSDD-SAR: There were 1%, 2%, 5%, and 10% of the 5000 training data selected as labeled data by random sampling and RDS sampling, respectively, and the remaining training data were selected as unlabeled data for semi-supervised training.
- Mixture datasets: All 5000 training data of RSDD-SAR were taken as labeled data, and a total of 15764 images from the SSDD, HRSID, and LS-SSDD were taken as the unlabeled dataset for extended experiments.
4.2. Implementation Details
4.3. Evaluation Metrics
4.4. Main Results and Analysis
4.4.1. Results of FCE
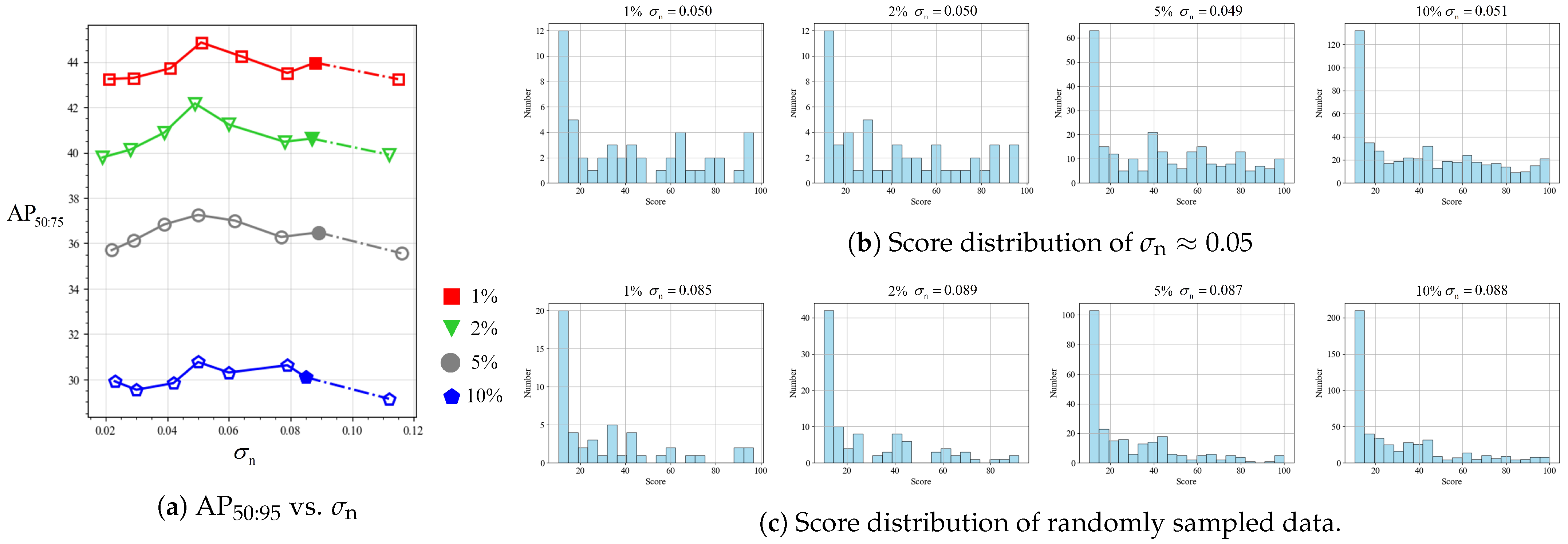
4.4.2. Relationship between Detection Performance and Data Distribution
4.4.3. Comparison with Representative Methods
Partially Labeled Data
Fully Labeled Data
4.4.4. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AIS | automatic identification system |
| BCE | binary cross-entropy |
| CFAR | constant false alarm rate |
| DL | deep learning |
| EMA | exponential moving average |
| GC | global consistency |
| GPU | Graphics Processing Unit |
| GWD | Gaussian Wasserstein distance |
| HBB | horizontal bounding box |
| OBB | oriented bounding box |
| ODW | orientation-angle deviation weighting |
| RAW | rotation-aware adaptive weighting |
| RDS | refined data selector |
| RIoU | rotated intersection over union |
| SAR | synthetic aperture radar |
| SCR | Signal-to-Clutter Ratio |
| SGD | stochastic gradient descent |
| SOOD | semi-supervised oriented object detection |
References
- Li, J.; Xu, C.; Su, H.; Gao, L.; Wang, T. Deep Learning for SAR Ship Detection: Past, Present and Future. Remote Sens. 2022, 14, 2712–2752. [Google Scholar] [CrossRef]
- Li, J.; Chen, J.; Cheng, P.; Yu, Z.; Yu, L.; Chi, C. A Survey on Deep-Learning-Based Real-Time SAR Ship Detection. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2023, 16, 3218–3247. [Google Scholar] [CrossRef]
- Meng, L.; Chen, Y.; Li, W.; Zhao, R. Fuzzy Comprehensive Evaluation Model for Water Resources Carrying Capacity in Tarim River Basin, Xinjiang, China. Chin. Geogr. Sci. 2009, 19, 89–95. [Google Scholar] [CrossRef]
- Yang, X.; Yan, J.; Ming, Q.; Wang, W.; Zhang, X.; Tian, Q. Rethinking Rotated Object Detection with Gaussian Wasserstein Distance Loss. In Proceedings of the 38th International Conference on Machine Learning (ICML2021), Online, 1 July 2021; pp. 11830–11841. [Google Scholar]
- Hua, W.; Liang, D.; Li, J.; Liu, X.; Zou, Z.; Ye, X.; Bai, X. SOOD: Towards Semi-Supervised Oriented Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR2023), Vancouver, BC, Canada, 18–22 June 2023; pp. 15558–15567. [Google Scholar]
- Li, T.; Liu, Z.; Xie, R.; Ran, L. An Improved Superpixel-Level CFAR Detection Method for Ship Targets in High-Resolution SAR Images. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2018, 11, 184–194. [Google Scholar] [CrossRef]
- Wang, X.Q.; Li, G.; Zhang, X.P.; He, Y. A Fast CFAR Algorithm Based on Density-Censoring Operation for Ship Detection in SAR Images. IEEE Geosci. Remote Sens. Lett. 2021, 28, 1085–1089. [Google Scholar] [CrossRef]
- Zhai, L.; Li, Y.; Su, Y. Inshore Ship Detection via Saliency and Context Information in High-Resolution SAR Images. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1870–1874. [Google Scholar] [CrossRef]
- Pappas, O.; Achim, A.; Bull, D. Superpixel-Level CFAR Detectors for Ship Detection in SAR Imagery. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1397–1401. [Google Scholar] [CrossRef]
- Li, T.; Liu, Z.; Ran, L.; Xie, R. Target Detection by Exploiting Superpixel-Level Statistical Dissimilarity for SAR Imagery. IEEE Geosci. Remote Sens. Lett. 2018, 15, 562–566. [Google Scholar] [CrossRef]
- Wang, X.Q.; Li, G.; Zhang, X.P.; He, Y. Ship detection in SAR images via local contrast of Fisher vectors. IEEE Trans. Geosci. Remote Sens. 2020, 58, 6467–6479. [Google Scholar] [CrossRef]
- Gao, G.; Shi, G. CFAR Ship Detection in Nonhomogeneous Sea Clutter Using Polarimetric SAR Data Based on the Notch Filter. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4811–4824. [Google Scholar] [CrossRef]
- Liu, T.; Yang, Z.; Yang, J.; Gao, G. CFAR Ship Detection Methods Using Compact Polarimetric SAR in a K-Wishart Distribution. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2019, 12, 3737–3745. [Google Scholar] [CrossRef]
- Liu, T.; Zhang, J.; Gao, G.; Yang, J.; Marino, A. CFAR Ship Detection in Polarimetric Synthetic Aperture Radar Images Based on Whitening Filter. IEEE Trans. Geosci. Remote Sens. 2019, 58, 58–81. [Google Scholar] [CrossRef]
- Zhang, T.; Yang, Z.; Gan, H.P.; Xiang, D.L.; Zhu, S.; Yang, J. PolSAR Ship Detection Using the Joint Polarimetric Information. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8225–8241. [Google Scholar] [CrossRef]
- Zhang, T.; Ji, J.S.; Li, X.F.; Yu, W.X.; Xiong, H.L. Ship Detection From PolSAR Imagery Using the Complete Polarimetric Covariance Difference Matrix. IEEE Trans. Geosci. Remote Sens. 2019, 57, 2824–2839. [Google Scholar] [CrossRef]
- Liao, M.S.; Wang, C.C.; Wang, Y.; Jiang, L.M. Using SAR Images to Detect Ships From Sea Clutter. IEEE Geosci. Remote Sens. Lett. 2008, 5, 194–198. [Google Scholar] [CrossRef]
- Xing, X.W.; Ji, K.F.; Zou, H.X.; Sun, J.X.; Zhou, S.L. High resolution SAR imagery ship detection based on EXS-C-CFAR in Alpha-stable clutters. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS2011), Vancouver, BC, Canada, 24–29 July 2011; pp. 316–319. [Google Scholar]
- Cui, Y.; Yang, J.; Yamaguchi, Y. CFAR ship detection in SAR images based on lognormal mixture models. In Proceedings of the 3rd International Asia-Pacific Conference on Synthetic Aperture Radar (APSAR2011), Seoul, Republic of Korea, 26–30 September 2011; pp. 1–3. [Google Scholar]
- Ai, J.Q.; Pei, Z.L.; Yao, B.D.; Wang, Z.C.; Xing, M.D. AIS Data Aided Rayleigh CFAR Ship Detection Algorithm of Multiple-Target Environment in SAR Images. IEEE Trans. Aerosp. Electron. Syst. 2022, 58, 1266–1282. [Google Scholar] [CrossRef]
- Bezerra, D.X.; Lorenzzetti, J.A.; Paes, R.L. Marine Environmental Impact on CFAR Ship Detection as Measured by Wave Age in SAR Images. Remote Sens. 2023, 15, 3441–3458. [Google Scholar] [CrossRef]
- Fu, J.; Sun, X.; Wang, Z.; Fu, K. An Anchor-Free Method Based on Feature Balancing and Refinement Network for Multiscale Ship Detection in SAR Images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 1331–1344. [Google Scholar] [CrossRef]
- Hu, Q.; Hu, S.; Liu, S. BANet: A Balance Attention Network for Anchor-Free Ship Detection in SAR Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5222212. [Google Scholar] [CrossRef]
- Chen, B.; Yu, C.; Zhao, S.; Song, H. An Anchor-Free Method Based on Transformers and Adaptive Features for Arbitrarily Oriented Ship Detection in SAR Images. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2023, 17, 2012–2028. [Google Scholar] [CrossRef]
- Zhou, Y.; Jiang, X.; Xu, G.; Yang, X.; Liu, X.; Li, Z. PVT-SAR: An Arbitrarily Oriented SAR Ship Detector with Pyramid Vision Transformer. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2022, 16, 291–305. [Google Scholar] [CrossRef]
- Zhou, S.C.; Zhang, M.; Xu, L.; Yu, D.H.; Li, J.J.; Fan, F.; Zhang, L.Y.; Liu, Y. Lightweight SAR Ship Detection Network Based on Transformer and Feature Enhancement. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2024, 17, 4845–4858. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, X.; Wang, N.; Gao, X. A Robust One-Stage Detector for Multiscale Ship Detection with Complex Background in Massive SAR Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5217712. [Google Scholar] [CrossRef]
- Wei, S.; Su, H.; Ming, J.; Wang, C.; Yan, M.; Kumar, D.; Shi, J.; Zhang, X. Precise and Robust Ship Detection for High-Resolution SAR Imagery Based on HR-SDNet. Remote Sens. 2020, 12, 167. [Google Scholar] [CrossRef]
- Li, D.; Liang, Q.; Liu, H.; Liu, Q.; Liu, H.; Liao, G. A Novel Multidimensional Domain Deep Learning Network for SAR Ship Detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5203213. [Google Scholar] [CrossRef]
- Sohn, K.; Zhang, Z.; Li, C.L.; Zhang, H.; Lee, C.Y.; Pfister, T. A Simple Semi-Supervised Learning Framework for Object Detection. arXiv 2020, arXiv:2005.04757. [Google Scholar]
- Yang, Q.; Wei, X.; Wang, B.; Hua, X.; Zhang, L. Interactive Self-Training With Mean Teachers for Semi-Supervised Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR2021), Online, 19–25 June 2021; pp. 5937–5946. [Google Scholar]
- Xu, M.; Zhang, Z.; Hu, H.; Wang, J.; Wang, L.; Wei, F.; Bai, X.; Liu, Z. End-to-End Semi-Supervised Object Detection with Soft Teacher. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV2021), Online, 11–17 October 2021; pp. 3060–3069. [Google Scholar]
- Liu, Y.C.; Ma, C.Y.; He, Z.; Kuo, C.W.; Chen, K.; Zhang, P.; Wu, B.; Kira, Z.; Vajda, P. Unbiased Teacher for Semi-Supervised Object Detection. arXiv 2021, arXiv:2102.09480. [Google Scholar]
- Zhou, H.; Ge, Z.; Liu, S.; Mao, W.; Li, Z.; Yu, H.; Sun, J. Dense Teacher: Dense Pseudo-Labels for Semi-Supervised Object Detection. In Proceedings of the European Conference on Computer Vision (ECCV2022), Tel Aviv, Israel, 23–27 October 2022; pp. 35–50. [Google Scholar]
- Xu, B.; Chen, M.; Guan, W.; Hu, L. Efficient Teacher: Semi-Supervised Object Detection for Yolov5. arXiv 2023, arXiv:2302.07577. [Google Scholar]
- Zhang, J.; Lin, X.; Zhang, W.; Wang, K.; Tan, X.; Han, J.; Ding, E.; Wang, J.; Li, G. Semi-Detr: Semi-Supervised Object Detection with Detection Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR2023), Vancouver, BC, Canada, 17–24 June 2023; pp. 23809–23818. [Google Scholar]
- Liu, C.; Zhang, W.; Lin, X.; Zhang, W.; Tan, X.; Han, J.; Li, X.; Ding, E.; Wang, J. Ambiguity-Resistant Semi-Supervised Learning for Dense Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR2023), Vancouver, BC, Canada, 18–22 June 2023; pp. 15579–15588. [Google Scholar]
- Ren, P.; Xiao, Y.; Chang, X.; Huang, P.-Y.; Li, Z.; Gupta, B.B.; Chen, X.; Wang, X. A Survey of Deep Active Learning 2021. arXiv 2020, arXiv:2009.00236. [Google Scholar]
- Xie, Y.C.; Lu, H.; Yan, J.C.; Yang, X.K.; Tomizuka, M.; Zhan, W. Active Finetuning: Exploiting Annotation Budget in the Pretraining-Finetuning Paradigm. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR2023), Vancouver, BC, Canada, 18–22 June 2023; pp. 23715–23724. [Google Scholar]
- Bengar, J.Z.; Weijer, J.; Twardowski, B.; Raducanu, B. Reducing Label Effort: Self-Supervised Meets Active Learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV2021), Online, 11–17 October 2021; pp. 1631–1639. [Google Scholar]
- Babaee, M.; Tsoukalas, S.; Rigoll, G.; Datcu, M. Visualization-Based Active Learning for the Annotation of SAR Images. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2015, 8, 4687–4698. [Google Scholar] [CrossRef]
- Bi, H.X.; Xu, F.; Wei, Z.Q.; Xue, Y.; Xu, Z.B. An Active Deep Learning Approach for Minimally Supervised PolSAR Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9378–9395. [Google Scholar] [CrossRef]
- Zhao, S.Y.; Luo, Y.; Zhang, T.; Guo, W.W.; Zhang, Z.H. Active Learning SAR Image Classification Method Crossing Different Imaging Platforms. IEEE Geosci. Remote Sens. Lett. 2022, 19, 4514105. [Google Scholar] [CrossRef]
- Xu, C.A.; Su, H.; Li, W.J.; Liu, Y.; Yao, L.B.; Gao, L.; Yan, W.J.; Wang, T.Y. RSDD-SAR: Rotated Ship Detection Dataset in SAR Images. J. Radars 2022, 11, 581–599. [Google Scholar]
- Zhang, T.; Zhang, X.; Li, J.; Xu, X.; Wang, B.; Zhan, X.; Xu, Y.; Ke, X.; Zeng, T.; Su, H. SAR Ship Detection Dataset (SSDD): Official Release and Comprehensive Data Analysis. Remote Sens. 2021, 13, 3690–3730. [Google Scholar] [CrossRef]
- Wei, S.; Zeng, X.; Qu, Q.; Wang, M.; Su, H.; Shi, J. HRSID: A High-Resolution SAR Images Dataset for Ship Detection and Instance Segmentation. IEEE Access 2020, 8, 120234–120254. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Ke, X.; Zhan, X.; Shi, J.; Wei, S.; Pan, D.; Li, J.; Su, H.; Zhou, Y. LS-SSDD-v1. 0: A Deep Learning Dataset Dedicated to Small Ship Detection from Large-Scale Sentinel-1 SAR Images. Remote Sens. 2020, 12, 2997–3033. [Google Scholar] [CrossRef]
- Zhou, Y.; Yang, X.; Zhang, G.; Wang, J.; Liu, Y.; Hou, L.; Jiang, X.; Liu, X.; Yan, J.; Lyu, C. MMrotate: A Rotated Object Detection Benchmark Using Pytorch. In Proceedings of the 30th ACM International Conference on Multimedia (ACMMM 2022), Lisbon, Portugal, 10 October 2022; pp. 7331–7334. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully Convolutional One-Stage Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV2019), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR2016), Las Vegas, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV2017), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Yang, X.; Yan, J.; Feng, Z.; He, T. R3Det: Refined Single-Stage Detector with Feature Refinement for Rotating Object. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI2021), Online, 2–9 February 2021; pp. 3163–3171. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.; Lu, Q. Learning RoI Transformer for Oriented Object Detection in Aerial Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR2019), Long Beach, CA, USA, 16–20 June 2019; pp. 2849–2858. [Google Scholar]
- Han, J.; Ding, J.; Xue, N.; Xia, G. ReDet: A Rotation-Equivariant Detector for Aerial Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR2021), Online, 19–25 June 2021; pp. 2786–2795. [Google Scholar]




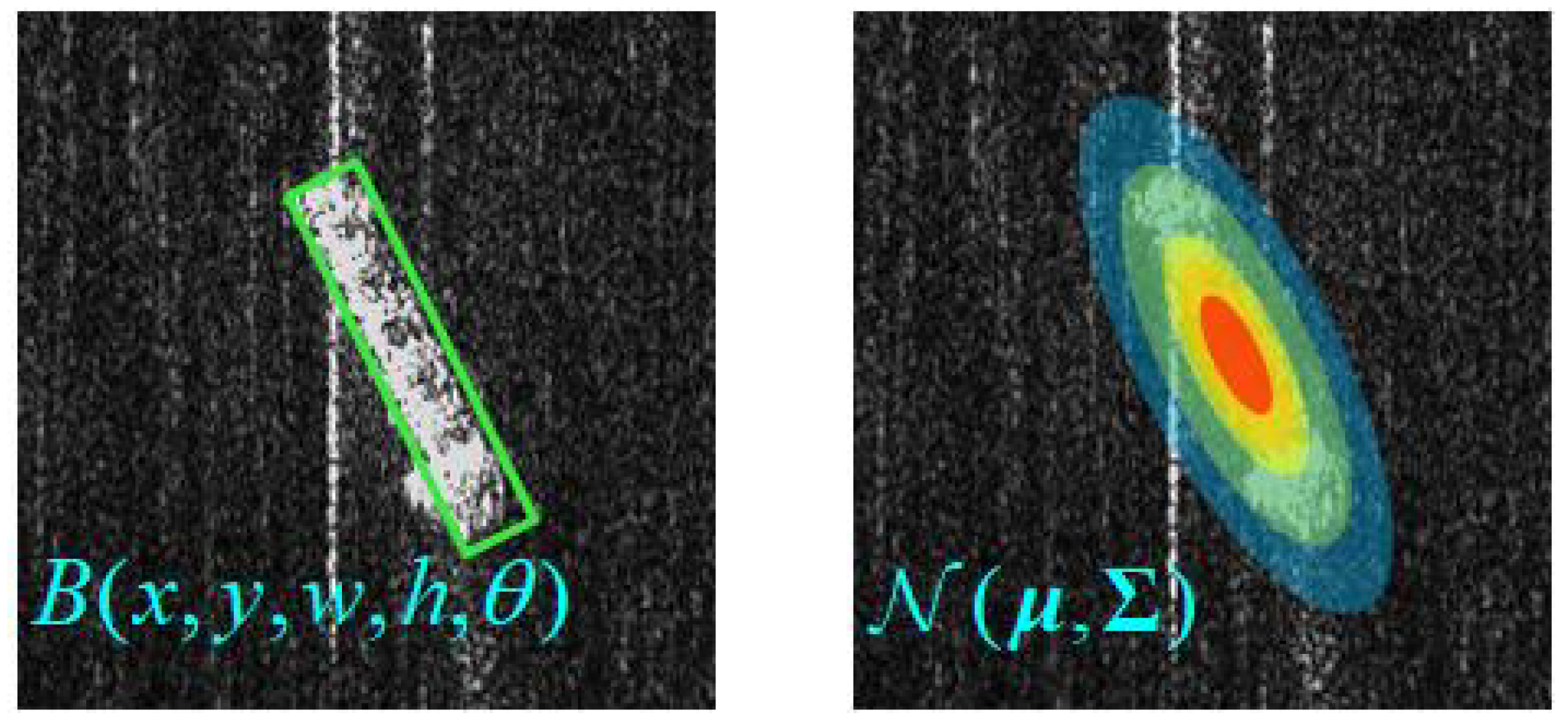



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component | Description | Function |
|---|---|---|
| RDS | Select appropriate indicators to evaluate SAR images; use FCE for comprehensive assessment; filter data based on the final scores. | Obtain scores for SAR images, and acquire a higher quality SAR dataset. |
| Spatial Characteristics | Obtained from the number, area, and spacing of connected regions after binarization, dilation, and other morphological operations. | Describing the spatial distribution of high-intensity pixels in SAR images and used as evaluation indicators for FCE. |
| Statistical Characteristics | Including the mean and variance of SAR image gray-scale values, as well as some features of the histogram. | Describing the statistical distribution of SAR image pixels and used as evaluation indicators for FCE. |
| FCE | Membership functions are derived from the distribution of evaluation indicators, and single factor evaluation is performed for different indicators. The final score is calculated using the weighted average fuzzy product. | Obtain comprehensive scores for SAR images for data-selection purposes. |
| Select Appropriate Data | After obtaining the final scores, data selection is performed through interval sampling. | As the name implies. |
| Semi-Supervised Oriented SAR Ship Detection | A teacher–student model that combines supervised and unsupervised learning, using ODW loss as the unsupervised learning loss function. | Make full use of existing labeled data, and leverage a large amount of unlabeled data to improve generalization ability. |
| Teacher-Student Model | During the unsupervised learning phase, only the student model is trained, and the teacher model is updated using the EMA at the end of each iteration. | It allows for end-to-end semi-supervised learning. |
| ODW Loss | The deviation between the student model’s predictions and the teacher model’s generated pseudo-labels is used as the weights to dynamically weight the unsupervised training loss. | This improves the accuracy of the model’s bounding box angle regression. |
| GWD Loss | The OBB is modeled as a two-dimensional Gaussian distribution, and the Wasserstein distance between the student model’s predictions and the pseudo-labels, as well as the ground truth, is calculated as the bounding box regression loss function. | As part of the ODW loss, this approach enhances the accuracy of the model’s bounding box predictions, especially in low-SCR and high sidelobe effect scenarios. |
| Dataset | Resolution (m) | Image Size | Number of Images | Number of Ships | Annotations |
|---|---|---|---|---|---|
| RSDD-SAR | 2–20 | 512 | 7000 | 10,263 | OBB |
| SSDD+ | 1–15 | 214–668 | 1160 | 2540 | OBB |
| HRSID | 0.5, 1, 3 | 800 | 5604 | 16,951 | OBB |
| LS-SSDD 1 | 5 × 20 | 800 | 9000 | 6016 | HBB |
| Image 1 | Image 2 | Image 3 | Image 4 | Image 5 | Image 6 | Image 7 | Image 8 | |
|---|---|---|---|---|---|---|---|---|
| Description | Offshore | Bridge | Inshore | Island | Low SCR | Shoreside | Harbor | Harbor |
| 8.6 | 22.4 | 38.3 | 27.6 | 51.3 | 71.8 | 82.2 | 79.1 | |
| 156.9 | 512.2 | 1230.6 | 1000.9 | 822.6 | 6256.5 | 5778.7 | 6900.2 | |
| 2.3 | 3.4 | 8.1 | 5.7 | 13.5 | 5.7 | 6.9 | 10.8 | |
| 1 | 2 | 3 | 4 | 1 | 3 | 3 | 4 | |
| 8.0 | 8.0 | 16.0 | 8.0 | 40.0 | 248.0 | 56.0 | 248.0 | |
| w | 16.0 | 40.0 | 48.0 | 112.0 | 72.0 | 112.0 | 248.0 | 144.0 |
| 8.0 | 8.0 | 16.0 | 88.0 | 40.0 | 32.0 | 240.0 | 112.0 | |
| 11.3 | 27.6 | 49.7 | 54.6 | 65.0 | 77.5 | 84.1 | 91.3 |
| Setting | Method | 1% | 2% | 5% | 10% |
|---|---|---|---|---|---|
| Supervised | RetinaNet | 18.95 ± 0.52 | 23.23 ± 0.23 | 30.45 ± 0.14 | 34.77 ± 0.16 |
| R3Det | 21.73 ± 0.33 | 26.92 ± 0.17 | 33.62 ± 0.21 | 37.23 ± 0.23 | |
| FCOS | 23.44 ± 0.18 | 28.07 ± 0.24 | 34.92 ± 0.25 | 38.40 ± 0.21 | |
| Faster R-CNN | 23.15 ± 0.45 | 28.88 ± 0.34 | 35.30 ± 0.24 | 39.01 ± 0.18 | |
| RoI Transformer | 22.88 ± 0.32 | 27.92 ± 0.19 | 34.41 ± 0.18 | 39.08 ± 0.17 | |
| ReDet | 23.03 ± 0.24 | 28.54 ± 0.22 | 35.32 ± 0.17 | 39.12 ± 0.09 | |
| Semi-supervised | Dense Teacher | 26.56 ± 0.16 | 31.19 ± 0.36 | 36.39 ± 0.11 | 40.42 ± 0.12 |
| SOOD | 27.14 ± 0.25 | 32.48 ± 0.20 | 37.42 ± 0.15 | 42.79 ± 0.14 | |
| Ours | 30.09 ± 0.14 | 36.48 ± 0.24 | 40.62 ± 0.31 | 43.97 ± 0.18 | |
| Ours * | 30.62 ± 0.40 | 37.25 ± 0.22 | 42.17 ± 0.18 | 44.86 ± 0.23 |
| Method | |||
|---|---|---|---|
| Supervised | 47.37 | 85.70 | 48.40 |
| Dense Teacher | 48.73 (+1.36) | 88.40 (+2.70) | 50.90 (+2.50) |
| SOOD | 49.23 (+1.86) | 88.80 (+3.10) | 51.30 (+2.90) |
| Ours | 50.97 (+3.60) | 89.20 (+3.50) | 52.80 (+4.40) |
| RAW 1 | ODW | GWD | 1% | ||
|---|---|---|---|---|---|
| - | - | - | 26.56 | 58.00 | 16.40 |
| ✓ | - | - | 27.14 (+0.58) | 63.00 (+5.00) | 16.70 (+0.30) |
| - | - | ✓ | 28.65 (+2.09) | 64.60 (+6.60) | 17.60 (+1.20) |
| - | ✓ | - | 28.95 (+2.39) | 66.20 (+8.20) | 18.70 (+2.30) |
| - | ✓ | ✓ | 30.09 (+3.53) | 68.00 (+10.00) | 19.60 (+3.20) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Y.; Lang, P.; Yin, J.; He, Y.; Yang, J. Data Matters: Rethinking the Data Distribution in Semi-Supervised Oriented SAR Ship Detection. Remote Sens. 2024, 16, 2551. https://doi.org/10.3390/rs16142551
Yang Y, Lang P, Yin J, He Y, Yang J. Data Matters: Rethinking the Data Distribution in Semi-Supervised Oriented SAR Ship Detection. Remote Sensing. 2024; 16(14):2551. https://doi.org/10.3390/rs16142551
Chicago/Turabian StyleYang, Yimin, Ping Lang, Junjun Yin, Yaomin He, and Jian Yang. 2024. "Data Matters: Rethinking the Data Distribution in Semi-Supervised Oriented SAR Ship Detection" Remote Sensing 16, no. 14: 2551. https://doi.org/10.3390/rs16142551
APA StyleYang, Y., Lang, P., Yin, J., He, Y., & Yang, J. (2024). Data Matters: Rethinking the Data Distribution in Semi-Supervised Oriented SAR Ship Detection. Remote Sensing, 16(14), 2551. https://doi.org/10.3390/rs16142551