
Hyperspectral Image Denoising by Pixel-Wise Noise Modeling and TV-Oriented Deep Image Prior


Abstract
1. Introduction
- We propose a new HSI denoising model within the probabilistic framework. The proposed model integrates a flexible noise model and a sophisticated HSI prior, which can faithfully characterize the intrinsic structures of both the noise and the clean HSI.
- We design an algorithm using the MCEM framework for solving the MAP estimation problem corresponding to the proposed model. The designed algorithm integrates the SGLD for the E-step and the ADMM for the M-step, both of which can be efficiently implemented.
- We demonstrate the applications of the proposed method on various HSI denoising examples, both synthetic and real, under different types of complex noise.
2. Related Work
2.1. Model-Driven Methods
2.2. Data-Driven Methods
3. Proposed Method
3.1. Probabilistic Model
3.1.1. Noise Modeling
3.1.2. Prior Modeling
3.1.3. Overall Model and MAP Estimation
3.2. Solving Algorithm for The MAP Estimation
3.2.1. Overall EM Process
| Algorithm 1 HSI denoising by noise modeling and DIP |
3.2.2. Monte Carlo E-Step for Updating Latent Variable
3.2.3. M-Step for Updating DIP Parameter
4. Experiments
4.1. Experimental Settings
4.1.1. Datasets
- CAVE: The Columbia Imaging and Vision Laboratory (CAVE) dataset [55] contains 31 HSIs with real-world objects in indoor scenarios. Each HSI in this dataset has 31 bands and a spatial size of .
- ICVL: The Ben-Gurion University Interdisiplinary Computational Vision Laboratory (ICVL) dataset [56] is composed of 201 HSIs with a spatial resolution over 519 spectra. The HSIs in this dataset are captured on natural outdoor scenes with complex background structures. In our experiments, we select 11 HSIs for comparison.
- Case 1 (Non-i.i.d Gaussian): The entire HSI is corrupted by the zero-mean Gaussian noise with variance 10–70 for all bands.
- Case 2 (Gaussian + Impulse): In addition to the Gaussian noise in Case 1, 10 bands of each HSI are randomly selected and added to impulse noise, whose ratio is between and .
- Case 3 (Gaussian + Deadline): In addition to the Gaussian noise in Case 1, 10 bands of each HSI are randomly selected and added to deadline noise, whose ratio is between and .
- Case 4 (Gaussian + Stripe): In addition to the Gaussian noise in Case 1, 10 bands of each HSI are randomly selected and added to stripe noise, whose ratio is between and .
- Case 5 (Mixture): Each band of HSI is randomly corrupted with at least one type of noise as that in the aforementioned cases.
4.1.2. Compared Methods and Evaluation Metrics
4.1.3. Implementation Details
4.2. Results on the Synthetic Data
4.3. Experiments on the Real HSIs
4.4. More Analyses
4.4.1. Ablation Study
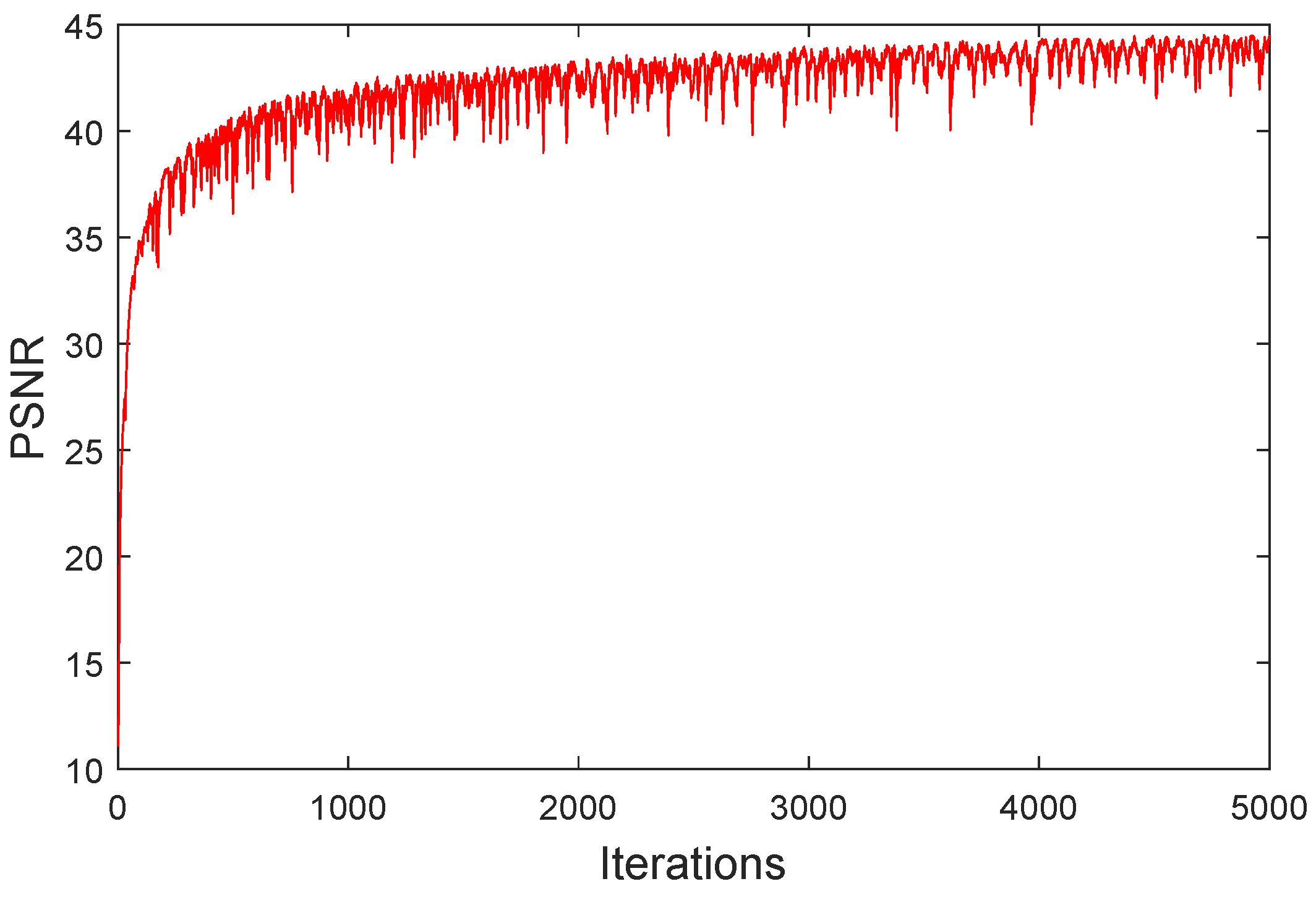
4.4.2. Computational Complexity and Convergence
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Khan, M.J.; Khan, H.S.; Yousaf, A.; Khurshid, K.; Abbas, A. Modern trends in hyperspectral image analysis: A review. IEEE Access 2018, 6, 14118–14129. [Google Scholar] [CrossRef]
- Stuart, M.B.; McGonigle, A.J.; Willmott, J.R. Hyperspectral imaging in environmental monitoring: A review of recent developments and technological advances in compact field deployable systems. Sensors 2019, 19, 3071. [Google Scholar] [CrossRef]
- Shimoni, M.; Haelterman, R.; Perneel, C. Hypersectral imaging for military and security applications: Combining myriad processing and sensing techniques. IEEE Geosci. Remote Sens. Mag. 2019, 7, 101–117. [Google Scholar] [CrossRef]
- Okada, N.; Maekawa, Y.; Owada, N.; Haga, K.; Shibayama, A.; Kawamura, Y. Automated identification of mineral types and grain size using hyperspectral imaging and deep learning for mineral processing. Minerals 2020, 10, 809. [Google Scholar] [CrossRef]
- Khan, U.; Paheding, S.; Elkin, C.P.; Devabhaktuni, V.K. Trends in deep learning for medical hyperspectral image analysis. IEEE Access 2021, 9, 79534–79548. [Google Scholar] [CrossRef]
- Yuan, Q.; Zhang, Q.; Li, J.; Shen, H.; Zhang, L. Hyperspectral image denoising employing a spatial–spectral deep residual convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2018, 57, 1205–1218. [Google Scholar] [CrossRef]
- Chang, Y.; Yan, L.; Fang, H.; Zhong, S.; Liao, W. HSI-DeNet: Hyperspectral image restoration via convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2018, 57, 667–682. [Google Scholar] [CrossRef]
- Dong, W.; Wang, H.; Wu, F.; Shi, G.; Li, X. Deep spatial–spectral representation learning for hyperspectral image denoising. IEEE Trans. Comput. Imaging 2019, 5, 635–648. [Google Scholar] [CrossRef]
- Zhuang, L.; Ng, M.K. FastHyMix: Fast and parameter-free hyperspectral image mixed noise removal. IEEE Trans. Neural Netw. Learn. Syst. 2021, 34, 4702–4716. [Google Scholar] [CrossRef]
- Luo, Y.S.; Zhao, X.L.; Jiang, T.X.; Zheng, Y.B.; Chang, Y. Hyperspectral mixed noise removal via spatial-spectral constrained unsupervised deep image prior. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 9435–9449. [Google Scholar] [CrossRef]
- Zhang, H.; He, W.; Zhang, L.; Shen, H.; Yuan, Q. Hyperspectral image restoration using low-rank matrix recovery. IEEE Trans. Geosci. Remote Sens. 2013, 52, 4729–4743. [Google Scholar] [CrossRef]
- He, W.; Zhang, H.; Zhang, L.; Shen, H. Hyperspectral image denoising via noise-adjusted iterative low-rank matrix approximation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 3050–3061. [Google Scholar] [CrossRef]
- He, W.; Zhang, H.; Zhang, L.; Shen, H. Total-variation-regularized low-rank matrix factorization for hyperspectral image restoration. IEEE Trans. Geosci. Remote Sens. 2015, 54, 178–188. [Google Scholar] [CrossRef]
- Wang, Y.; Peng, J.; Zhao, Q.; Leung, Y.; Zhao, X.L.; Meng, D. Hyperspectral image restoration via total variation regularized low-rank tensor decomposition. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 11, 1227–1243. [Google Scholar] [CrossRef]
- Xue, J.; Zhao, Y.; Huang, S.; Liao, W.; Chan, J.C.W.; Kong, S.G. Multilayer Sparsity-Based Tensor Decomposition for Low-Rank Tensor Completion. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 6916–6930. [Google Scholar] [CrossRef] [PubMed]
- Xue, J.; Zhao, Y.; Bu, Y.; Chan, J.C.W.; Kong, S.G. When Laplacian Scale Mixture Meets Three-Layer Transform: A Parametric Tensor Sparsity for Tensor Completion. IEEE Trans. Cybern. 2022, 52, 13887–13901. [Google Scholar] [CrossRef] [PubMed]
- Aggarwal, H.K.; Majumdar, A. Hyperspectral image denoising using spatio-spectral total variation. IEEE Geosci. Remote Sens. Lett. 2016, 13, 442–446. [Google Scholar] [CrossRef]
- Du, B.; Huang, Z.; Wang, N.; Zhang, Y.; Jia, X. Joint weighted nuclear norm and total variation regularization for hyperspectral image denoising. Int. J. Remote Sens. 2018, 39, 334–355. [Google Scholar] [CrossRef]
- Xie, T.; Li, S.; Sun, B. Hyperspectral images denoising via nonconvex regularized low-rank and sparse matrix decomposition. IEEE Trans. Image Process. 2019, 29, 44–56. [Google Scholar] [CrossRef] [PubMed]
- Zhuang, L.; Ng, M.K. Hyperspectral mixed noise removal by ℓ1-norm-based subspace representation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1143–1157. [Google Scholar] [CrossRef]
- Chen, Y.; Cao, X.; Zhao, Q.; Meng, D.; Xu, Z. Denoising hyperspectral image with non-iid noise structure. IEEE Trans. Cybern. 2017, 48, 1054–1066. [Google Scholar] [CrossRef] [PubMed]
- Yue, Z.; Meng, D.; Sun, Y.; Zhao, Q. Hyperspectral image restoration under complex multi-band noises. Remote Sens. 2018, 10, 1631. [Google Scholar] [CrossRef]
- Ma, T.H.; Xu, Z.; Meng, D.; Zhao, X.L. Hyperspectral image restoration combining intrinsic image characterization with robust noise modeling. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 1628–1644. [Google Scholar] [CrossRef]
- Peng, J.; Wang, H.; Cao, X.; Liu, X.; Rui, X.; Meng, D. Fast noise removal in hyperspectral images via representative coefficient total variation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Rui, X.; Cao, X.; Xie, Q.; Yue, Z.; Zhao, Q.; Meng, D. Learning an explicit weighting scheme for adapting complex HSI noise. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6739–6748. [Google Scholar]
- He, S.; Zhou, H.; Wang, Y.; Cao, W.; Han, Z. Super-resolution reconstruction of hyperspectral images via low rank tensor modeling and total variation regularization. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 6962–6965. [Google Scholar]
- Peng, J.; Xie, Q.; Zhao, Q.; Wang, Y.; Yee, L.; Meng, D. Enhanced 3DTV Regularization and Its Applications on HSI Denoising and Compressed Sensing. IEEE Trans. Image Process. 2020, 29, 7889–7903. [Google Scholar] [CrossRef]
- Huang, X.; Du, B.; Tao, D.; Zhang, L. Spatial-spectral weighted nuclear norm minimization for hyperspectral image denoising. Neurocomputing 2020, 399, 271–284. [Google Scholar] [CrossRef]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Deep image prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9446–9454. [Google Scholar]
- Sidorov, O.; Yngve Hardeberg, J. Deep hyperspectral prior: Single-image denoising, inpainting, super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Niresi, K.F.; Chi, C.Y. Unsupervised hyperspectral denoising based on deep image prior and least favorable distribution. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 5967–5983. [Google Scholar] [CrossRef]
- Welling, M.; Teh, Y.W. Bayesian learning via stochastic gradient Langevin dynamics. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), Bellevue, WA, USA, 28 June–2 July 2011; pp. 681–688. [Google Scholar]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends Mach. Learn. 2011, 3, 1–122. [Google Scholar]
- Ye, H.; Li, H.; Yang, B.; Cao, F.; Tang, Y. A novel rank approximation method for mixture noise removal of hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4457–4469. [Google Scholar] [CrossRef]
- Maggioni, M.; Katkovnik, V.; Egiazarian, K.; Foi, A. Nonlocal transform-domain filter for volumetric data denoising and reconstruction. IEEE Trans. Image Process. 2012, 22, 119–133. [Google Scholar] [CrossRef]
- Xie, Q.; Zhao, Q.; Meng, D.; Xu, Z.; Gu, S.; Zuo, W.; Zhang, L. Multispectral images denoising by intrinsic tensor sparsity regularization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1692–1700. [Google Scholar]
- Peng, Y.; Meng, D.; Xu, Z.; Gao, C.; Yang, Y.; Zhang, B. Decomposable nonlocal tensor dictionary learning for multispectral image denoising. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2949–2956. [Google Scholar]
- Zhang, H. Hyperspectral image denoising with cubic total variation model. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2012, 1, 95–98. [Google Scholar] [CrossRef]
- Jiang, T.X.; Zhuang, L.; Huang, T.Z.; Zhao, X.L.; Bioucas-Dias, J.M. Adaptive Hyperspectral Mixed Noise Removal. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5511413. [Google Scholar] [CrossRef]
- Liu, W.; Lee, J. A 3-D atrous convolution neural network for hyperspectral image denoising. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5701–5715. [Google Scholar] [CrossRef]
- Wei, K.; Fu, Y.; Huang, H. 3-D quasi-recurrent neural network for hyperspectral image denoising. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 363–375. [Google Scholar] [CrossRef] [PubMed]
- Cao, X.; Fu, X.; Xu, C.; Meng, D. Deep spatial-spectral global reasoning network for hyperspectral image denoising. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5504714. [Google Scholar] [CrossRef]
- Shi, Q.; Tang, X.; Yang, T.; Liu, R.; Zhang, L. Hyperspectral image denoising using a 3-D attention denoising network. IEEE Trans. Geosci. Remote Sens. 2021, 59, 10348–10363. [Google Scholar] [CrossRef]
- Chen, H.; Yang, G.; Zhang, H. Hider: A hyperspectral image denoising transformer with spatial–spectral constraints for hybrid noise removal. IEEE Trans. Neural Netw. Learn. Syst. 2022, 35, 8797–8811. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Fu, Y.; Zhang, Y. Spatial-spectral transformer for hyperspectral image denoising. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; pp. 1368–1376. [Google Scholar]
- Cao, X.; Zhao, Q.; Meng, D.; Chen, Y.; Xu, Z. Robust low-rank matrix factorization under general mixture noise distributions. IEEE Trans. Image Process. 2016, 25, 4677–4690. [Google Scholar] [CrossRef]
- Allard, W.K. Total variation regularization for image denoising, I. Geometric theory. SIAM J. Math. Anal. 2008, 39, 1150–1190. [Google Scholar] [CrossRef]
- Chang, Y.; Yan, L.; Fang, H.; Luo, C. Anisotropic spectral-spatial total variation model for multispectral remote sensing image destriping. IEEE Trans. Image Process. 2015, 24, 1852–1866. [Google Scholar] [CrossRef]
- Yue, Z.; Zhao, Q.; Xie, J.; Zhang, L.; Meng, D.; Wong, K.Y.K. Blind image super-resolution with elaborate degradation modeling on noise and kernel. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 28–24 June 2022; pp. 2128–2138. [Google Scholar]
- Caffo, B.S.; Jank, W.; Jones, G.L. Ascent-based Monte Carlo expectation–maximization. J. R. Stat. Soc. Ser. B Stat. Methodol. 2005, 67, 235–251. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Wei, G.C.; Tanner, M.A. A Monte Carlo implementation of the EM algorithm and the poor man’s data augmentation algorithms. J. Am. Stat. Assoc. 1990, 85, 699–704. [Google Scholar] [CrossRef]
- Celeux, G.; Chauveau, D.; Diebolt, J. Stochastic versions of the EM algorithm: An experimental study in the mixture case. J. Stat. Comput. Simul. 1996, 55, 287–314. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Yasuma, F.; Mitsunaga, T.; Iso, D.; Nayar, S.K. Generalized assorted pixel camera: Postcapture control of resolution, dynamic range, and spectrum. IEEE Trans. Image Process. 2010, 19, 2241–2253. [Google Scholar] [CrossRef] [PubMed]
- Arad, B.; Ben-Shahar, O. Sparse recovery of hyperspectral signal from natural RGB images. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part VII 14. Springer: Cham, Switzerland, 2016; pp. 19–34. [Google Scholar]
- Zhuang, L.; Ng, M.K.; Fu, X. Hyperspectral image mixed noise removal using subspace representation and deep CNN image prior. Remote Sens. 2021, 13, 4098. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Mou, X.; Zhang, D. FSIM: A Feature Similarity Index for Image Quality Assessment. IEEE Trans. Image Process. 2011, 20, 2378–2386. [Google Scholar] [CrossRef]
- Wald, L. Data Fusion: Definitions and Architectures: Fusion of Images of Different Spatial Resolutions; Presses des Mines: Paris, France, 2002. [Google Scholar]
- Yuhas, R.H.; Goetz, A.F.; Boardman, J.W. Discrimination among semi-arid landscape endmembers using the spectral angle mapper (SAM) algorithm. In Proceedings of the JPL, Summaries of the Third Annual JPL Airborne Geoscience Workshop, Pasadena, CA, USA, 1–5 June 1992; Volume 1. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Twenty-Eighth Annual Conference on Neural Information Processing Systems, Montréal, QC, Canada, 8–13 December 2014; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N., Weinberger, K., Eds.; Volume 27. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising Diffusion Probabilistic Models. In Proceedings of the Thirty-Fourth Annual Conference on Neural Information Processing Systems, Virtual, 6–12 December 2020; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Volume 33, pp. 6840–6851. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Case | Method | PSNR | FSIM | ERGAS | SAM |
|---|---|---|---|---|---|
| Gaussian | LRTDTV | 39.8796 | 0.9779 | 4.0462 | 0.0674 |
| HySuDeep | 40.1336 | 0.9848 | 4.58236 | 0.0646 | |
| S2DIP | 41.8339 | 0.9888 | 2.8531 | 0.0483 | |
| Ours | 41.5929 | 0.9862 | 2.7408 | 0.0469 | |
| Impulse | LRTDTV | 34.4736 | 0.9284 | 7.1868 | 0.1180 |
| HySuDeep | 30.4910 | 0.9170 | 12.5340 | 0.1761 | |
| S2DIP | 37.4550 | 0.9686 | 4.5624 | 0.0788 | |
| Ours | 37.2922 | 0.9707 | 4.4757 | 0.0762 | |
| Deadline | LRTDTV | 32.8379 | 0.9192 | 10.2393 | 0.1427 |
| HySuDeep | 30.5410 | 0.8218 | 11.7132 | 0.1754 | |
| S2DIP | 37.0793 | 0.9668 | 4.7088 | 0.0818 | |
| Ours | 36.9659 | 0.9669 | 4.8187 | 0.0809 | |
| Stripe | LRTDTV | 34.6507 | 0.9284 | 6.9978 | 0.1178 |
| HySuDeep | 31.2546 | 0.9175 | 10.8651 | 0.1650 | |
| S2DIP | 38.1461 | 0.9627 | 4.0421 | 0.0703 | |
| Ours | 37.4689 | 0.9720 | 4.3060 | 0.0720 | |
| Mixture | LRTDTV | 35.0809 | 0.9449 | 9.4196 | 0.1262 |
| HySuDeep | 35.5482 | 0.9575 | 8.0436 | 0.1053 | |
| S2DIP | 39.6789 | 0.9815 | 3.5289 | 0.0611 | |
| Ours | 40.2142 | 0.9822 | 3.2595 | 0.0563 |
| Case | Method | PSNR | FSIM | ERGAS | SAM |
|---|---|---|---|---|---|
| Gaussian | LRTDTV | 27.0421 | 0.9241 | 14.0443 | 0.1300 |
| HySuDeep | 27.2292 | 0.9478 | 14.1620 | 0.1790 | |
| S2DIP | 30.2844 | 0.9613 | 10.1397 | 0.0934 | |
| Ours | 30.2307 | 0.9341 | 8.2538 | 0.0818 | |
| Impulse | LRTDTV | 22.0450 | 0.8469 | 19.7787 | 0.2020 |
| HySuDeep | 22.9223 | 0.8898 | 17.4486 | 0.2149 | |
| S2DIP | 28.3008 | 0.9288 | 8.7353 | 0.1050 | |
| Ours | 28.2520 | 0.9148 | 9.8538 | 0.0937 | |
| Deadline | LRTDTV | 24.4003 | 0.8558 | 15.3513 | 0.1746 |
| HySuDeep | 23.9010 | 0.8780 | 15.0186 | 0.2036 | |
| S2DIP | 26.9224 | 0.8749 | 11.2969 | 0.1058 | |
| Ours | 27.9537 | 0.9089 | 10.5811 | 0.0968 | |
| Stripe | LRTDTV | 23.6814 | 0.8723 | 15.7636 | 0.1757 |
| HySuDeep | 23.1673 | 0.8885 | 15.5463 | 0.2043 | |
| S2DIP | 28.1406 | 0.9309 | 9.8148 | 0.1054 | |
| Ours | 28.9598 | 0.9119 | 9.1531 | 0.0955 | |
| Mixture | LRTDTV | 23.5957 | 0.8631 | 20.1767 | 0.1893 |
| HySuDeep | 24.2909 | 0.9028 | 17.1100 | 0.1889 | |
| S2DIP | 28.2247 | 0.9080 | 10.1001 | 0.0907 | |
| Ours | 27.2590 | 0.9086 | 15.0000 | 0.1263 |
| Setting | PSNR | FSIM | ERGAS | SAM |
|---|---|---|---|---|
| w/o TV terms | 38.2576 | 0.9659 | 4.3830 | 0.0712 |
| w/o E-step | 40.0899 | 0.9805 | 3.3132 | 0.0567 |
| S2DIP | 39.6789 | 0.9815 | 3.5289 | 0.0611 |
| Ours | 40.2142 | 0.9822 | 3.2595 | 0.0563 |
| Method | Time per HSI (s) | Time per Iteration (s) |
|---|---|---|
| S2DIP | 692.8 | 0.23 |
| Ours | 987.4 | 0.33 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yi, L.; Zhao, Q.; Xu, Z. Hyperspectral Image Denoising by Pixel-Wise Noise Modeling and TV-Oriented Deep Image Prior. Remote Sens. 2024, 16, 2694. https://doi.org/10.3390/rs16152694
Yi L, Zhao Q, Xu Z. Hyperspectral Image Denoising by Pixel-Wise Noise Modeling and TV-Oriented Deep Image Prior. Remote Sensing. 2024; 16(15):2694. https://doi.org/10.3390/rs16152694
Chicago/Turabian StyleYi, Lixuan, Qian Zhao, and Zongben Xu. 2024. "Hyperspectral Image Denoising by Pixel-Wise Noise Modeling and TV-Oriented Deep Image Prior" Remote Sensing 16, no. 15: 2694. https://doi.org/10.3390/rs16152694
APA StyleYi, L., Zhao, Q., & Xu, Z. (2024). Hyperspectral Image Denoising by Pixel-Wise Noise Modeling and TV-Oriented Deep Image Prior. Remote Sensing, 16(15), 2694. https://doi.org/10.3390/rs16152694