
Synergizing a Deep Learning and Enhanced Graph-Partitioning Algorithm for Accurate Individual Rubber Tree-Crown Segmentation from Unmanned Aerial Vehicle Light-Detection and Ranging Data



Abstract
:1. Introduction
2. Materials
2.1. Study Area
2.2. LiDAR Data Acquisition and Field Measurements
2.3. Data Processing
3. Methods
3.1. Improved Deep Learning Network for Branch and Leaf Separation
3.1.1. Feature Abstraction Layer
3.1.2. Feature Propagation Layer
3.2. Graph-Based ITC Segmentation
3.2.1. Inverted CHM Generation
3.2.2. Component Merging from Inverted CHM
3.2.3. ITC Segmentation at Component Scale
3.3. Assessment of Model Accuracy
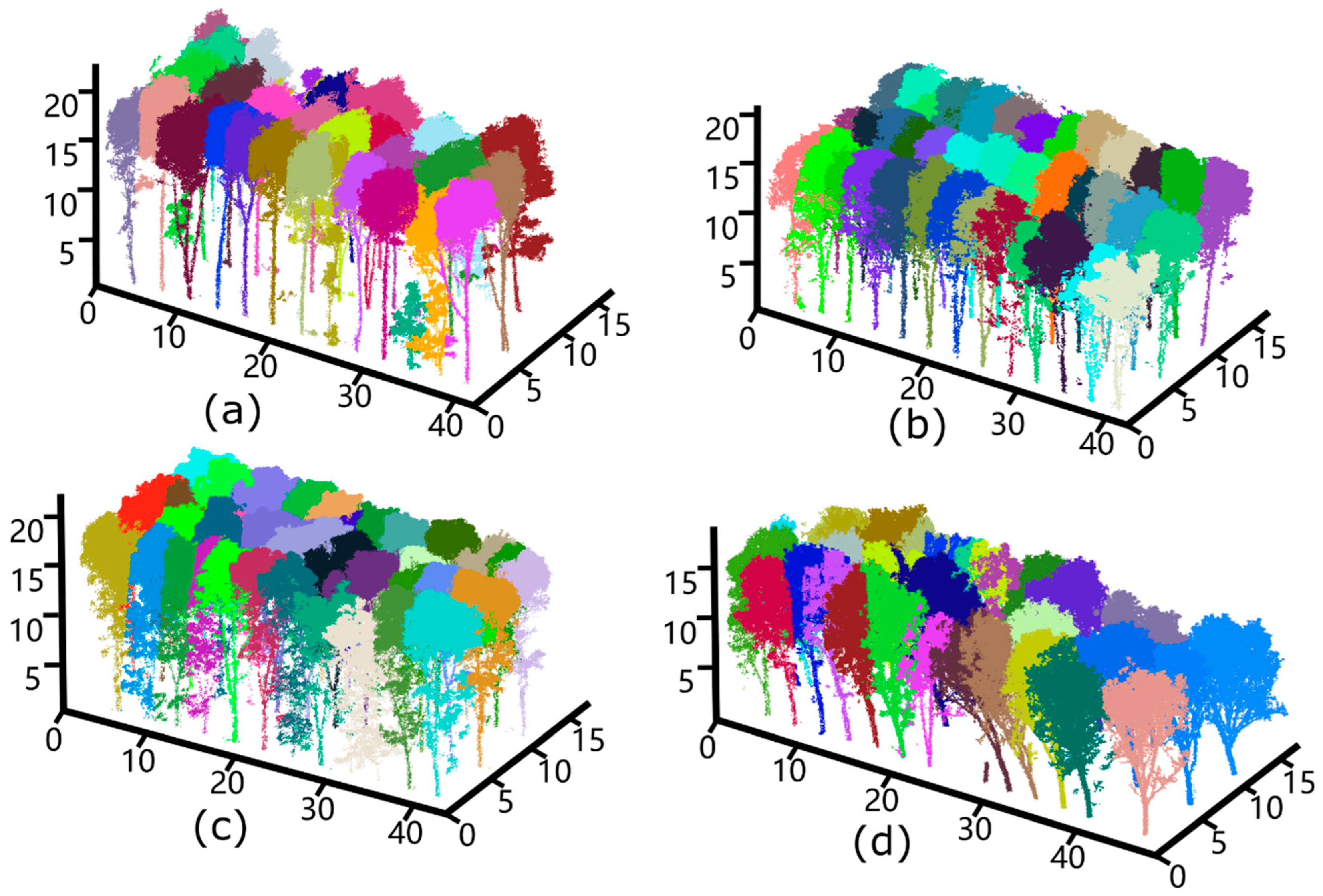
4. Results
4.1. Leaf Detection
4.2. Individual Tree Segmentation
5. Discussion
5.1. Comparison between the Two Networks
5.2. Comparison with Existing Methods
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Arias, M.; Van Dijk, P.J. What Is Natural Rubber and Why Are We Searching for New Sources? Front. Young Minds 2019, 7, 100. [Google Scholar] [CrossRef]
- Beland, M.; Parker, G.; Sparrow, B.; Harding, D.; Chasmer, L.; Phinn, S.; Antonarakis, A.; Strahler, A. On Promoting the Use of Lidar Systems in Forest Ecosystem Research. For. Ecol. Manag. 2019, 450, 117484. [Google Scholar] [CrossRef]
- Zhang, J.; Hu, X.; Dai, H.; Qu, S. DEM Extraction from ALS Point Clouds in Forest Areas via Graph Convolution Network. Remote Sens. 2020, 12, 178. [Google Scholar] [CrossRef]
- Hu, B.; Li, J.; Jing, L.; Judah, A. Improving the Efficiency and Accuracy of Individual Tree Crown Delineation from High-Density LiDAR Data. Int. J. Appl. Earth Obs. Geoinf. 2014, 26, 145–155. [Google Scholar] [CrossRef]
- Yun, T.; Jiang, K.; Li, G.; Eichhorn, M.P.; Fan, J.; Liu, F.; Chen, B.; An, F.; Cao, L. Individual Tree Crown Segmentation from Airborne LiDAR Data Using a Novel Gaussian Filter and Energy Function Minimization-Based Approach. Remote Sens. Environ. 2021, 256, 112307. [Google Scholar] [CrossRef]
- Mongus, D.; Žalik, B. An Efficient Approach to 3D Single Tree-Crown Delineation in LiDAR Data. ISPRS J. Photogramm. Remote Sens. 2015, 108, 219–233. [Google Scholar] [CrossRef]
- Dong, T.; Zhang, X.; Ding, Z.; Fan, J. Multi-Layered Tree Crown Extraction from LiDAR Data Using Graph-Based Segmentation. Comput. Electron. Agric. 2020, 170, 105213. [Google Scholar] [CrossRef]
- Reitberger, J.; Schnörr, C.; Krzystek, P.; Stilla, U. 3D Segmentation of Single Trees Exploiting Full Waveform LIDAR Data. ISPRS J. Photogramm. Remote Sens. 2009, 64, 561–574. [Google Scholar] [CrossRef]
- Yang, J.; Kang, Z.; Cheng, S.; Yang, Z.; Akwensi, P.H. An Individual Tree Segmentation Method Based on Watershed Algorithm and Three-Dimensional Spatial Distribution Analysis from Airborne LiDAR Point Clouds. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1055–1067. [Google Scholar] [CrossRef]
- Dersch, S.; Heurich, M.; Krueger, N.; Krzystek, P. Combining Graph-Cut Clustering with Object-Based Stem Detection for Tree Segmentation in Highly Dense Airborne Lidar Point Clouds. ISPRS J. Photogramm. Remote Sens. 2021, 172, 207–222. [Google Scholar] [CrossRef]
- Dutta, A.; Engels, J.; Hahn, M. Segmentation of Laser Point Clouds in Urban Areas by a Modified Normalized Cut Method. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 3034–3047. [Google Scholar] [CrossRef]
- Shi, J.; Malik, J. Normalized Cuts and Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 18. [Google Scholar] [CrossRef]
- Liu, T.; Im, J.; Quackenbush, L.J. A Novel Transferable Individual Tree Crown Delineation Model Based on Fishing Net Dragging and Boundary Classification. ISPRS J. Photogramm. Remote Sens. 2015, 110, 34–47. [Google Scholar] [CrossRef]
- Dai, W.; Yang, B.; Dong, Z.; Shaker, A. A New Method for 3D Individual Tree Extraction Using Multispectral Airborne LiDAR Point Clouds. ISPRS J. Photogramm. Remote Sens. 2018, 144, 400–411. [Google Scholar] [CrossRef]
- Xiao, W.; Zaforemska, A.; Smigaj, M.; Wang, Y.; Gaulton, R. Mean Shift Segmentation Assessment for Individual Forest Tree Delineation from Airborne Lidar Data. Remote Sens. 2019, 11, 1263. [Google Scholar] [CrossRef]
- Ramiya, A.M.; Nidamanuri, R.R.; Krishnan, R. Individual Tree Detection from Airborne Laser Scanning Data Based on Supervoxels and Local Convexity. Remote Sens. Appl. Soc. Environ. 2019, 15, 100242. [Google Scholar] [CrossRef]
- Schiefer, F.; Kattenborn, T.; Frick, A.; Frey, J.; Schall, P.; Koch, B.; Schmidtlein, S. Mapping Forest Tree Species in High Resolution UAV-Based RGB-Imagery by Means of Convolutional Neural Networks. ISPRS J. Photogramm. Remote Sens. 2020, 170, 205–215. [Google Scholar] [CrossRef]
- Ioannidou, A.; Chatzilari, E.; Nikolopoulos, S.; Kompatsiaris, I. Deep Learning Advances in Computer Vision with 3D Data: A Survey. ACM Comput. Surv. 2018, 50, 1–38. [Google Scholar] [CrossRef]
- Hao, Z.; Lin, L.; Post, C.J.; Mikhailova, E.A.; Li, M.; Chen, Y.; Yu, K.; Liu, J. Automated Tree-Crown and Height Detection in a Young Forest Plantation Using Mask Region-Based Convolutional Neural Network (Mask R-CNN). ISPRS J. Photogramm. Remote Sens. 2021, 178, 112–123. [Google Scholar] [CrossRef]
- Guan, Z.; Miao, X.; Mu, Y.; Sun, Q.; Ye, Q.; Gao, D. Forest Fire Segmentation from Aerial Imagery Data Using an Improved Instance Segmentation Model. Remote Sens. 2022, 14, 3159. [Google Scholar] [CrossRef]
- Wang, J.; Chen, X.; Cao, L.; An, F.; Chen, B.; Xue, L.; Yun, T. Individual Rubber Tree Segmentation Based on Ground-Based LiDAR Data and Faster R-CNN of Deep Learning. Forests 2019, 10, 793. [Google Scholar] [CrossRef]
- Kumar, B.; Pandey, G.; Lohani, B.; Misra, S.C. A Multi-Faceted CNN Architecture for Automatic Classification of Mobile LiDAR Data and an Algorithm to Reproduce Point Cloud Samples for Enhanced Training. ISPRS J. Photogramm. Remote Sens. 2019, 147, 80–89. [Google Scholar] [CrossRef]
- Harikumar, A.; Bovolo, F.; Bruzzone, L. A Local Projection-Based Approach to Individual Tree Detection and 3-D Crown Delineation in Multistoried Coniferous Forests Using High-Density Airborne LiDAR Data. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1168–1182. [Google Scholar] [CrossRef]
- Chen, X.; Jiang, K.; Zhu, Y.; Wang, X.; Yun, T. Individual Tree Crown Segmentation Directly from UAV-Borne LiDAR Data Using the PointNet of Deep Learning. Forests 2021, 12, 131. [Google Scholar] [CrossRef]
- Zhou, Y.; Tuzel, O. VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, IEEE; Salt Lake City, UT, USA: 18–23 June 2018; pp. 4490–4499.
- Luo, H.; Khoshelham, K.; Chen, C.; He, H. Individual Tree Extraction from Urban Mobile Laser Scanning Point Clouds Using Deep Pointwise Direction Embedding. ISPRS J. Photogramm. Remote Sens. 2021, 175, 326–339. [Google Scholar] [CrossRef]
- Wei, H.; Xu, E.; Zhang, J.; Meng, Y.; Wei, J.; Dong, Z.; Li, Z. BushNet: Effective Semantic Segmentation of Bush in Large-Scale Point Clouds. Comput. Electron. Agric. 2022, 193, 106653. [Google Scholar] [CrossRef]
- Xi, Z.; Hopkinson, C.; Rood, S.B.; Peddle, D.R. See the Forest and the Trees: Effective Machine and Deep Learning Algorithms for Wood Filtering and Tree Species Classification from Terrestrial Laser Scanning. ISPRS J. Photogramm. Remote Sens. 2020, 168, 1–16. [Google Scholar] [CrossRef]
- Yun, T.; An, F.; Li, W.; Sun, Y.; Cao, L.; Xue, L. A Novel Approach for Retrieving Tree Leaf Area from Ground-Based LiDAR. Remote Sens. 2016, 8, 942. [Google Scholar] [CrossRef]
- Kamousi, P.; Lazard, S.; Maheshwari, A.; Wuhrer, S. Analysis of Farthest Point Sampling for Approximating Geodesics in a Graph. Comput. Geom. 2016, 57, 1–7. [Google Scholar] [CrossRef]
- Chen, Q.; Wynne, R.J.; Goulding, P.; Sandoz, D. The Application of Principal Component Analysis and Kernel Density Estimation to Enhance Process Monitoring. Control Eng. Pract. 2000, 8, 531–543. [Google Scholar] [CrossRef]
- Flores-Garnica, J.G.; Macías-Muro, A. Bandwidth selection for kernel density estimation of forest fires. Rev. Chapingo Ser. Cienc. For. Y Del Ambiente 2018, 24, 313–327. [Google Scholar] [CrossRef]
- Zhang, W.; Cai, S.; Liang, X.; Shao, J.; Hu, R.; Yu, S.; Yan, G. Cloth Simulation-Based Construction of Pit-Free Canopy Height Models from Airborne LiDAR Data. For. Ecosyst. 2020, 7, 1. [Google Scholar] [CrossRef]
- Felzenszwalb, P.F.; Huttenlocher, D.P. Efficient Graph-Based Image Segmentation. Int. J. Comput. Vis. 2004, 59, 167–181. [Google Scholar] [CrossRef]
- Amiri, N.; Polewski, P.; Heurich, M.; Krzystek, P.; Skidmore, A.K. Adaptive Stopping Criterion for Top-down Segmentation of ALS Point Clouds in Temperate Coniferous Forests. ISPRS J. Photogramm. Remote Sens. 2018, 141, 265–274. [Google Scholar] [CrossRef]
- Han, T.S.; Endo, H.; Sasaki, M. Reliability and Secrecy Functions of the Wiretap Channel Under Cost Constraint. IEEE Trans. Inf. Theory 2014, 60, 6819–6843. [Google Scholar] [CrossRef]
- Wang, K.; Zhou, J.; Zhang, W.; Zhang, B. Mobile LiDAR Scanning System Combined with Canopy Morphology Extracting Methods for Tree Crown Parameters Evaluation in Orchards. Sensors 2021, 21, 339. [Google Scholar] [CrossRef]
- Jing, Z.; Guan, H.; Zhao, P.; Li, D.; Yu, Y.; Zang, Y.; Wang, H.; Li, J. Multispectral LiDAR Point Cloud Classification Using SE-PointNet++. Remote Sens. 2021, 13, 2516. [Google Scholar] [CrossRef]
- Li, D.; Shi, G.; Li, J.; Chen, Y.; Zhang, S.; Xiang, S.; Jin, S. PlantNet: A Dual-Function Point Cloud Segmentation Network for Multiple Plant Species. ISPRS J. Photogramm. Remote Sens. 2022, 184, 243–263. [Google Scholar] [CrossRef]
- Huo, L.; Lindberg, E.; Holmgren, J. Towards Low Vegetation Identification: A New Method for Tree Crown Segmentation from LiDAR Data Based on a Symmetrical Structure Detection Algorithm (SSD). Remote Sens. Environ. 2022, 270, 112857. [Google Scholar] [CrossRef]
- Li, Y.; Quan, C.; Yang, S.; Wu, S.; Shi, M.; Wang, J.; Tian, W. Functional Identification of ICE Transcription Factors in Rubber Tree. Forests 2022, 13, 52. [Google Scholar] [CrossRef]
- Peng, X.; Zhao, A.; Chen, Y.; Chen, Q.; Liu, H.; Wang, J.; Li, H. Comparison of Modeling Algorithms for Forest Canopy Structures Based on UAV-LiDAR: A Case Study in Tropical China. Forests 2020, 11, 1324. [Google Scholar] [CrossRef]
- Hao, Y.; Widagdo, F.R.A.; Liu, X.; Liu, Y.; Dong, L.; Li, F. A Hierarchical Region-Merging Algorithm for 3-D Segmentation of Individual Trees Using UAV-LiDAR Point Clouds. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Tusa, E.; Monnet, J.-M.; Barre, J.-B.; Mura, M.D.; Dalponte, M.; Chanussot, J. Individual Tree Segmentation Based on Mean Shift and Crown Shape Model for Temperate Forest. IEEE Geosci. Remote Sens. Lett. 2021, 18, 2052–2056. [Google Scholar] [CrossRef]
- Minařík, R.; Langhammer, J.; Lendzioch, T. Automatic Tree Crown Extraction from UAS Multispectral Imagery for the Detection of Bark Beetle Disturbance in Mixed Forests. Remote Sens. 2020, 12, 4081. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Equipment | Specification | Measurement |
|---|---|---|
| Velodyne HDL-32E | Dimensions (mm) (Height/Diameter) | |
| Weight (kg) | ||
| Field of View (°) (Horizontal/Vertical) | 0–360/ −30.67 ± 10.67 | |
| Accuracy (cm) | ||
| Measurement Range (m) | ||
| Velodyne HDL-32E | Wavelength (nm) | |
| Point Cloud Rate (points/second) | ||
| Operating Temperature (°C) | ||
| Storage temperature (°C) | ||
| Scan Rate (Hz) |
| ReKen 523 | ReYan 72059 | ReYan 73397 | PR 107 | ||
|---|---|---|---|---|---|
| Average tree height (m) | 21.75 ± 3.93 | 19.52 ± 1.81 | 18.47 ± 1.72 | 17.12 ± 1.21 | |
| Average Crown width (m) (N-S/E-W) | 4.76 ± 2.12/ 4.01 ± 1.25 | 6.02 ± 1.98/ 3.01 ± 1.48 | 6.53 ± 1.15/ 3.38 ± 0.66 | 5.17 ± 1.12/ 3.57 ± 0.95 | |
| Tree number | 232 | 178 | 245 | 185 | |
| Diameter at breast height (cm) | 19.38 ± 3.12 | 12.74 ± 1.85 | 12.18 ± 1.71 | 13.48 ± 2.29 | |
| Leaf area index (LAI) | 2.89 ± 0.96 | 3.32 ± 1.21 | 4.92 ± 1.35 | 4.52 ± 1.47 | |
| Tree spacing between lines and rows (m) | (N-S 7 m/E-W 3 m) | ||||
| Plots | Instance-Level | Point-Level | ||||||
|---|---|---|---|---|---|---|---|---|
| Trees-Num | R | P | F-Score | Points-Num | R | P | F-Score | |
| Plot 1 | 78 | 98.2 | 98.9 | 98.5 | 13,272,012 | 87.3 | 82.2 | 84.7 |
| Plot 2 | 69 | 94.7 | 96.2 | 95.4 | 6,169,773 | 81.4 | 75.6 | 78.4 |
| Plot 3 | 72 | 93.6 | 95.6 | 94.6 | 5,558,256 | 79.2 | 72.6 | 75.8 |
| Plot 4 | 61 | 92.0 | 94.1 | 93.0 | 2,979,118 | 74.5 | 81.7 | 77.9 |
| Plots | TN (m) | TH (m) | DBH (cm) | Precision (%) | Recall (%) | mIoU (%) | |||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 1 | 2 | 1 | 2 | ||||
| Plot 1 | 97 | 15.36–18.71 | 18.6–26.9 | 86.7 | 84.1 | 81.5 | 78.9 | 77.4 | 76.2 |
| Plot 2 | 89 | 16.72–19.92 | 20.9–28.3 | 77.0 | 74.8 | 79.1 | 73.4 | 71.1 | 67.4 |
| Plot 3 | 92 | 15.54–18.19 | 22.8–35.5 | 74.1 | 71.1 | 83.8 | 78.0 | 75.5 | 73.1 |
| Plot 4 | 110 | 12.47–17.5 | 21.5–29.8 | 80.2 | 79.6 | 73.1 | 66.8 | 76.2 | 71.6 |
| Method | Plot | Tree Num | TP | FP | FN | Recall | Precision | F-Score |
|---|---|---|---|---|---|---|---|---|
| Marker controlled Watershed algorithm | Plot 1 | 121 | 110 | 11 | 7 | 0.92 | 0.89 | 0.90 |
| Plot 2 | 97 | 78 | 19 | 12 | 0.85 | 0.78 | 0.81 | |
| Plot 3 | 103 | 91 | 12 | 16 | 0.83 | 0.86 | 0.84 | |
| Plot 4 | 89 | 74 | 15 | 8 | 0.88 | 0.81 | 0.84 | |
| Cluster-based method | Plot 1 | 121 | 107 | 14 | 9 | 0.90 | 0.86 | 0.88 |
| Plot 2 | 97 | 81 | 16 | 19 | 0.79 | 0.82 | 0.80 | |
| Plot 3 | 103 | 90 | 13 | 17 | 0.82 | 0.85 | 0.83 | |
| Plot 4 | 89 | 76 | 13 | 12 | 0.84 | 0.82 | 0.83 | |
| Our method | Plot 1 | 121 | 111 | 9 | 6 | 0.92 | 0.91 | 0.91 |
| Plot 2 | 97 | 82 | 15 | 9 | 0.88 | 0.83 | 0.85 | |
| Plot 3 | 103 | 94 | 9 | 7 | 0.91 | 0.89 | 0.90 | |
| Plot 4 | 89 | 67 | 18 | 9 | 0.86 | 0.77 | 0.81 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, Y.; Lin, Y.; Chen, B.; Yun, T.; Wang, X. Synergizing a Deep Learning and Enhanced Graph-Partitioning Algorithm for Accurate Individual Rubber Tree-Crown Segmentation from Unmanned Aerial Vehicle Light-Detection and Ranging Data. Remote Sens. 2024, 16, 2807. https://doi.org/10.3390/rs16152807
Zhu Y, Lin Y, Chen B, Yun T, Wang X. Synergizing a Deep Learning and Enhanced Graph-Partitioning Algorithm for Accurate Individual Rubber Tree-Crown Segmentation from Unmanned Aerial Vehicle Light-Detection and Ranging Data. Remote Sensing. 2024; 16(15):2807. https://doi.org/10.3390/rs16152807
Chicago/Turabian StyleZhu, Yunfeng, Yuxuan Lin, Bangqian Chen, Ting Yun, and Xiangjun Wang. 2024. "Synergizing a Deep Learning and Enhanced Graph-Partitioning Algorithm for Accurate Individual Rubber Tree-Crown Segmentation from Unmanned Aerial Vehicle Light-Detection and Ranging Data" Remote Sensing 16, no. 15: 2807. https://doi.org/10.3390/rs16152807
APA StyleZhu, Y., Lin, Y., Chen, B., Yun, T., & Wang, X. (2024). Synergizing a Deep Learning and Enhanced Graph-Partitioning Algorithm for Accurate Individual Rubber Tree-Crown Segmentation from Unmanned Aerial Vehicle Light-Detection and Ranging Data. Remote Sensing, 16(15), 2807. https://doi.org/10.3390/rs16152807