
A Lightweight Machine-Learning Method for Cloud Removal in Remote Sensing Images Constrained by Conditional Information


Abstract
:1. Introduction
2. Related Work
2.1. Spatial-Based Methods
2.2. Spectral-Based Methods
2.3. Temporal-Based Methods
2.4. Hybrid-Based Methods
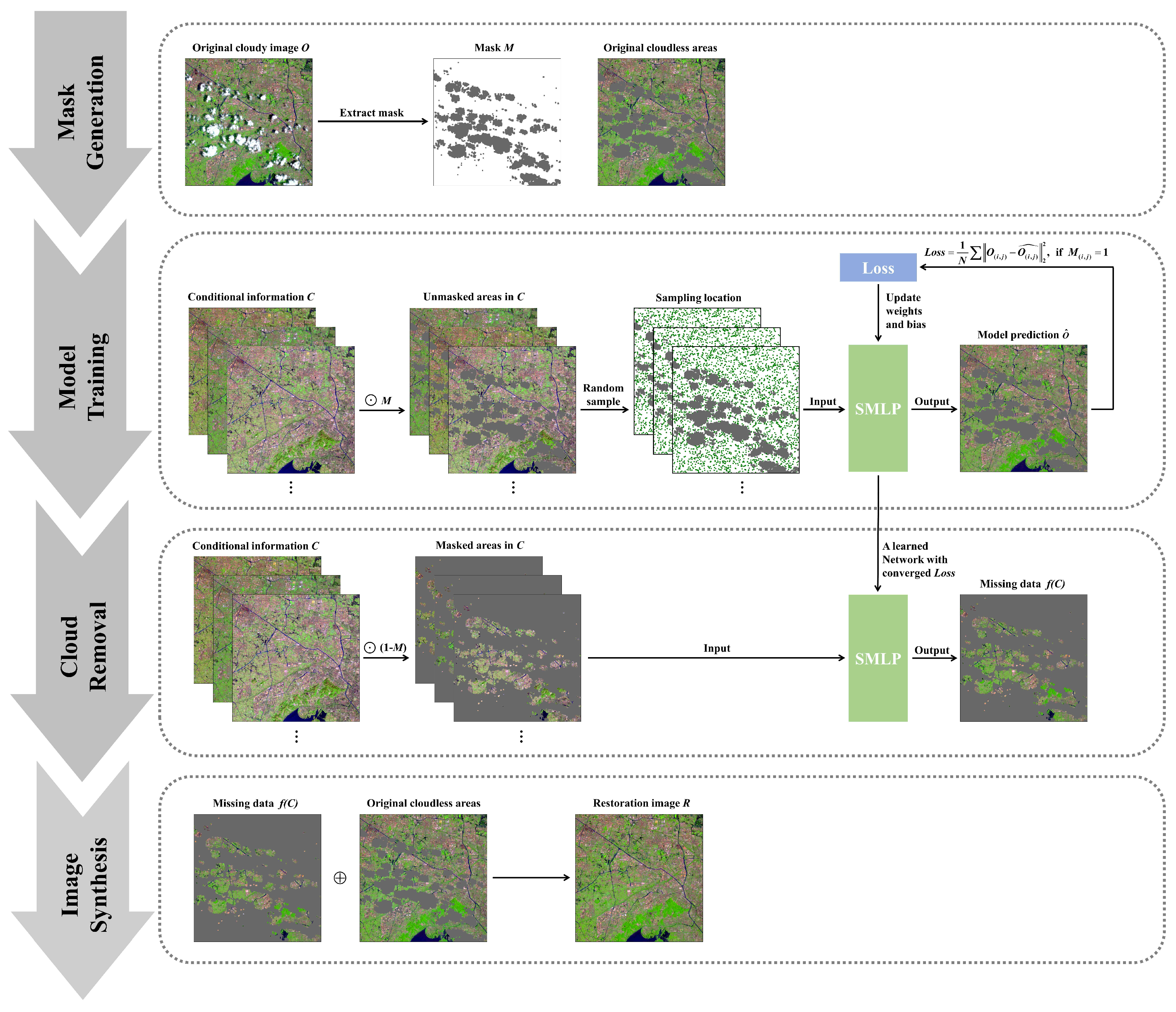
3. Methodology
3.1. A Multilayer Perceptron with a Presingle-Connection Layer (SMLP)
3.2. Conditional Information
3.2.1. Temporal and Spectral Information
3.2.2. Spatial Information
3.2.3. Pixel Similarity
3.3. Cloud Removal Method Constrained by Conditional Information (SMLP-CR)
3.3.1. Mask Generation
3.3.2. Model Training
3.3.3. Cloud Removal
3.3.4. Image Synthesis
4. Experiments
4.1. Datasets
4.1.1. Data Sources
4.1.2. Data Preprocessing
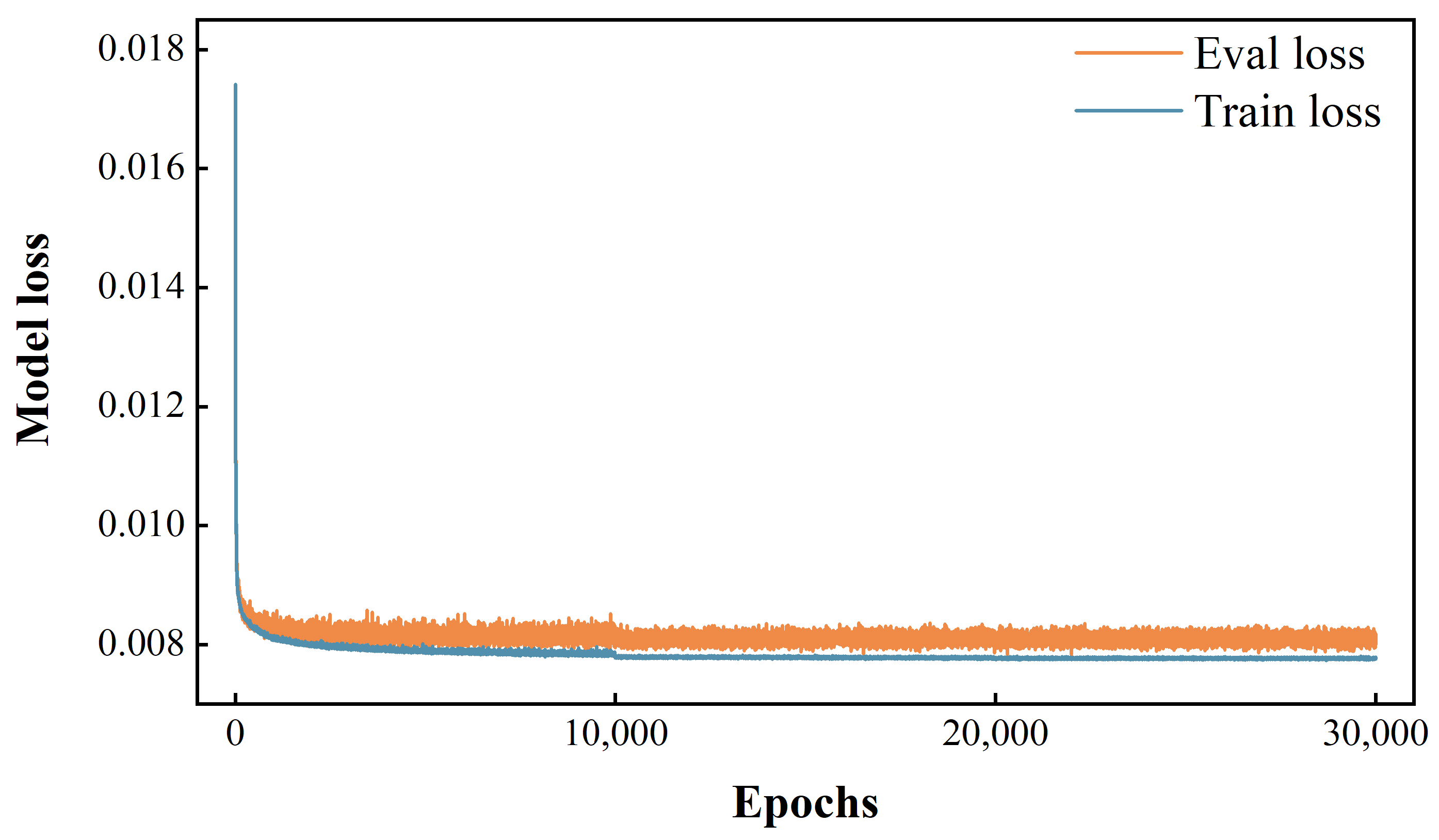
4.2. Evaluation Metrics and Implementation Details
4.3. Simulated Experiments using Various Temporal RS Images
4.4. Comparison Experiments and Discussions
4.4.1. Comparison Methods and Hyperparameters
4.4.2. Simulated Comparison Experiments
4.4.3. Real-World Comparison Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Guo, H.; Shi, Q.; Marinoni, A.; Du, B.; Zhang, L. Deep Building Footprint Update Network: A Semi-Supervised Method for Updating Existing Building Footprint from Bi-Temporal Remote Sensing Images. Remote Sens. Environ. 2021, 264, 112589. [Google Scholar] [CrossRef]
- He, D.; Shi, Q.; Liu, X.; Zhong, Y.; Zhang, X. Deep Subpixel Mapping Based on Semantic Information Modulated Network for Urban Land Use Mapping. IEEE Trans. Geosci. Remote Sens. 2021, 59, 10628–10646. [Google Scholar] [CrossRef]
- He, L.; Qi, S.L.; Duan, L.Z.; Guo, T.C.; Feng, W.; He, D.X. Monitoring of Wheat Powdery Mildew Disease Severity Using Multiangle Hyperspectral Remote Sensing. IEEE Trans. Geosci. Remote Sens. 2021, 59, 979–990. [Google Scholar] [CrossRef]
- Weiss, M.; Jacob, F.; Duveiller, G. Remote Sensing for Agricultural Applications: A Meta-Review. Remote Sens. Environ. 2020, 236, 111402. [Google Scholar] [CrossRef]
- Maheswaran, G.; Selvarani, A.G.; Elangovan, K. Groundwater Resource Exploration in Salem District, Tamil Nadu Using GIS and Remote Sensing. J. Earth Syst. Sci. 2016, 125, 311–328. [Google Scholar] [CrossRef]
- Shirmard, H.; Farahbakhsh, E.; Müller, R.D.; Chandra, R. A Review of Machine Learning in Processing Remote Sensing Data for Mineral Exploration. Remote Sens. Environ. 2022, 268, 112750. [Google Scholar] [CrossRef]
- Mao, K.; Yuan, Z.; Zuo, Z.; Xu, T.; Shen, X.; Gao, C. Changes in Global Cloud Cover Based on Remote Sensing Data from 2003 to 2012. Chin. Geogr. Sci. 2019, 29, 306–315. [Google Scholar] [CrossRef]
- Zou, X.; Li, K.; Xing, J.; Zhang, Y.; Wang, S.; Jin, L.; Tao, P. DiffCR: A Fast Conditional Diffusion Framework for Cloud Removal from Optical Satellite Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–14. [Google Scholar] [CrossRef]
- Jiang, B.; Li, X.; Chong, H.; Wu, Y.; Li, Y.; Jia, J.; Wang, S.; Wang, J.; Chen, X. A Deep-Learning Reconstruction Method for Remote Sensing Images with Large Thick Cloud Cover. Int. J. Appl. Earth Obs. Geoinf. 2022, 115, 103079. [Google Scholar] [CrossRef]
- Li, W.; Li, Y.; Chen, D.; Chan, J.C.W. Thin Cloud Removal with Residual Symmetrical Concatenation Network. ISPRS J. Photogramm. Remote Sens. 2019, 153, 137–150. [Google Scholar] [CrossRef]
- Zhang, Q.; Yuan, Q.; Li, J.; Li, Z.; Shen, H.; Zhang, L. Thick Cloud and Cloud Shadow Removal in Multitemporal Imagery Using Progressively Spatio-Temporal Patch Group Deep Learning. ISPRS J. Photogramm. Remote Sens. 2020, 162, 148–160. [Google Scholar] [CrossRef]
- Sarukkai, V.; Jain, A.; Uzkent, B.; Ermon, S. Cloud Removal in Satellite Images Using Spatiotemporal Generative Networks. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020; pp. 1785–1794. [Google Scholar] [CrossRef]
- Long, C.; Yang, J.; Guan, X.; Li, X. Thick Cloud Removal from Remote Sensing Images Using Double Shift Networks. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 2687–2690. [Google Scholar] [CrossRef]
- Huang, G.L.; Wu, P.Y. CTGAN: Cloud Transformer Generative Adversarial Network. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 511–515. [Google Scholar] [CrossRef]
- Ebel, P.; Xu, Y.; Schmitt, M.; Zhu, X.X. SEN12MS-CR-TS: A Remote-Sensing Data Set for Multimodal Multitemporal Cloud Removal. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Gao, J.; Yuan, Q.; Li, J.; Su, X. Unsupervised Missing Information Reconstruction for Single Remote Sensing Image with Deep Code Regression. Int. J. Appl. Earth Obs. Geoinf. 2021, 105, 102599. [Google Scholar] [CrossRef]
- Liu, W.; Jiang, Y.; Li, F.; Zhang, G.; Song, H.; Wang, C.; Li, X. Collaborative Dual-Harmonization Reconstruction Network for Large-Ratio Cloud Occlusion Missing Information in High-Resolution Remote Sensing Images. Eng. Appl. Artif. Intell. 2024, 136, 108861. [Google Scholar] [CrossRef]
- Li, J.; Hassani, A.; Walton, S.; Shi, H. ConvMLP: Hierarchical Convolutional MLPs for Vision. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Vancouver, BC, Canada, 17–24 June 2023; pp. 6307–6316. [Google Scholar] [CrossRef]
- Tolstikhin, I.; Houlsby, N.; Kolesnikov, A.; Beyer, L.; Zhai, X.; Unterthiner, T.; Yung, J.; Steiner, A.; Keysers, D.; Uszkoreit, J.; et al. MLP-Mixer: An All-MLP Architecture for Vision. arXiv 2021, arXiv:2105.01601. [Google Scholar]
- Wang, Y.; Tang, S.; Zhu, F.; Bai, L.; Zhao, R.; Qi, D.; Ouyang, W. Revisiting the Transferability of Supervised Pretraining: An MLP Perspective. arXiv 2022, arXiv:2112.00496. [Google Scholar] [CrossRef]
- Bozic, V.; Dordevic, D.; Coppola, D.; Thommes, J.; Singh, S.P. Rethinking Attention: Exploring Shallow Feed-Forward Neural Networks as an Alternative to Attention Layers in Transformers. arXiv 2024, arXiv:2311.10642. [Google Scholar] [CrossRef]
- Tobler, W.R. A Computer Movie Simulating Urban Growth in the Detroit Region. Econ. Geogr. 1970, 46, 234–240. [Google Scholar] [CrossRef]
- Zhang, Q.; Yuan, Q.; Zeng, C.; Li, X.; Wei, Y. Missing Data Reconstruction in Remote Sensing Image with a Unified Spatial–Temporal–Spectral Deep Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4274–4288. [Google Scholar] [CrossRef]
- Chen, Y.; Nan, Z.; Cao, Z.; Ou, M.; Feng, K. A Stepwise Framework for Interpolating Land Surface Temperature under Cloudy Conditions Based on the Solar-Cloud-Satellite Geometry. ISPRS J. Photogramm. Remote Sens. 2023, 197, 292–308. [Google Scholar] [CrossRef]
- Shi, C.; Wang, T.; Wang, S.; Jia, A.; Zheng, X.; Leng, W.; Du, Y. MDINEOF: A Scheme to Recover Land Surface Temperatures under Cloudy-Sky Conditions by Incorporating Radiation Fluxes. Remote Sens. Environ. 2024, 309, 114208. [Google Scholar] [CrossRef]
- Jing, R.; Duan, F.; Lu, F.; Zhang, M.; Zhao, W. Denoising Diffusion Probabilistic Feature-Based Network for Cloud Removal in Sentinel-2 Imagery. Remote Sens. 2023, 15, 2217. [Google Scholar] [CrossRef]
- Chen, Y.; He, W.; Yokoya, N.; Huang, T.Z. Blind Cloud and Cloud Shadow Removal of Multitemporal Images Based on Total Variation Regularized Low-Rank Sparsity Decomposition. ISPRS J. Photogramm. Remote Sens. 2019, 157, 93–107. [Google Scholar] [CrossRef]
- Zheng, J.; Liu, X.Y.; Wang, X. Single Image Cloud Removal Using U-Net and Generative Adversarial Networks. IEEE Trans. Geosci. Remote Sens. 2021, 59, 6371–6385. [Google Scholar] [CrossRef]
- Pan, H. Cloud Removal for Remote Sensing Imagery via Spatial Attention Generative Adversarial Network. arXiv 2020, arXiv:2009.13015. [Google Scholar] [CrossRef]
- Sui, J.; Ma, Y.; Yang, W.; Zhang, X.; Pun, M.O.; Liu, J. Diffusion Enhancement for Cloud Removal in Ultra-Resolution Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–14. [Google Scholar] [CrossRef]
- Wang, L.; Qu, J.; Xiong, X.; Hao, X.; Xie, Y.; Che, N. A New Method for Retrieving Band 6 of Aqua MODIS. IEEE Geosci. Remote Sens. Lett. 2006, 3, 267–270. [Google Scholar] [CrossRef]
- Rakwatin, P.; Takeuchi, W.; Yasuoka, Y. Restoration of Aqua MODIS Band 6 Using Histogram Matching and Local Least Squares Fitting. IEEE Trans. Geosci. Remote Sens. 2009, 47, 613–627. [Google Scholar] [CrossRef]
- Storey, J.; Scaramuzza, P.; Schmidt, G.; Barsi, J. Landsat 7 Scan Line Corrector-off Gap-Filled Product Development. In Proceedings of the Pecora 16 “Global Priorities in Land Remote Sensing”, Sioux Falls, South Dakota, 23–27 October 2005. [Google Scholar]
- Zeng, C.; Shen, H.; Zhang, L. Recovering Missing Pixels for Landsat ETM+ SLC-off Imagery Using Multi-Temporal Regression Analysis and a Regularization Method. Remote Sens. Environ. 2013, 131, 182–194. [Google Scholar] [CrossRef]
- Li, X.; Shen, H.; Li, H.; Zhang, L. Patch Matching-Based Multitemporal Group Sparse Representation for the Missing Information Reconstruction of Remote-Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 3629–3641. [Google Scholar] [CrossRef]
- Ng, M.K.P.; Yuan, Q.; Yan, L.; Sun, J. An Adaptive Weighted Tensor Completion Method for the Recovery of Remote Sensing Images with Missing Data. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3367–3381. [Google Scholar] [CrossRef]
- Sun, D.L.; Ji, T.Y.; Ding, M. A New Sparse Collaborative Low-Rank Prior Knowledge Representation for Thick Cloud Removal in Remote Sensing Images. Remote Sens. 2024, 16, 1518. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. arXiv 2018, arXiv:1611.07004. [Google Scholar] [CrossRef]
- Liu, H.; Huang, B.; Cai, J. Thick Cloud Removal Under Land Cover Changes Using Multisource Satellite Imagery and a Spatiotemporal Attention Network. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–18. [Google Scholar] [CrossRef]
- Garnot, V.S.F.; Landrieu, L. Lightweight Temporal Self-Attention for Classifying Satellite Image Time Series. arXiv 2020, arXiv:2007.00586. [Google Scholar] [CrossRef]
- Ebel, P.; Garnot, V.S.F.; Schmitt, M.; Wegner, J.D.; Zhu, X.X. UnCRtainTS: Uncertainty Quantification for Cloud Removal in Optical Satellite Time Series. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 2086–2096. [Google Scholar]
- Zou, X.; Li, K.; Xing, J.; Tao, P.; Cui, Y. PMAA: A Progressive Multi-scale Attention Autoencoder Model for High-performance Cloud Removal from Multi-temporal Satellite Imagery. arXiv 2023, arXiv:2303.16565. [Google Scholar] [CrossRef]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein GAN. arXiv 2017, arXiv:1701.07875. [Google Scholar] [CrossRef]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved Training of Wasserstein GANs. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Elfeki, M.; Couprie, C.; Riviere, M.; Elhoseiny, M. GDPP: Learning Diverse Generations Using Determinantal Point Processes. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 1774–1783. [Google Scholar]
- Zhang, W.; Shen, X.; Zhang, H.; Yin, Z.; Sun, J.; Zhang, X.; Zou, L. Feature Importance Measure of a Multilayer Perceptron Based on the Presingle-Connection Layer. Knowl. Inf. Syst. 2024, 66, 511–533. [Google Scholar] [CrossRef]
- Stollfuss, B.; Bacher, M. MLP-Supported Mathematical Optimization of Simulation Models: Investigation into the Approximation of Black Box Functions of Any Simulation Model with MLPs with the Aim of Functional Analysis. In Proceedings of the 3rd International Conference on Innovative Intelligent Industrial Production and Logistics, Valletta, Malta, 24–26 October 2022; pp. 107–114. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Chen, T.J. A Novel Image Blurring Detection Scheme Using Spatial Autocorrelation. In Proceedings of the 2023 34th Irish Signals and Systems Conference (ISSC), Dublin, Ireland, 13–14 June 2023; pp. 1–4. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.; Sheikh, H.; Simoncelli, E. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Data Source | Path/Row | Date of Restoration Images | Date of Conditional Images | Cloud-Covered Percentage of Applications/Simulations |
|---|---|---|---|---|---|
| Suzhou | Landsat 8-9 OLI-TIRS | 119/038 | 18 June 2022 | 9 November 2021, 26 February 2022, 28 May 2023 | 43.2%/48.8% |
| Kuqa | Landsat 8-9 OLI-TIRS | 145/031 | 1 October 2023 | 4 February 2022, 17 December 2022, 2 January 2023 | 33.5%/34.4% |
| Guangzhou | Sentinel-2 MSI | N0400/R089/T51STR | 23 February 2023 | 16 October 2023, 20 November 2023, 25 December 2023 | 27.7%/22.0% |
| Conditional Information | SSIM↑ | PSNR↓ | ||||
|---|---|---|---|---|---|---|
| SWIR | NIR | RED | SWIR | NIR | RED | |
| OLI-20211109 | 0.9147 | 0.9196 | 0.9650 | 39.11 | 38.91 | 44.31 |
| OLI-20220226 | 0.9178 | 0.9038 | 0.9687 | 39.58 | 38.66 | 44.81 |
| OLI-20230528 | 0.9271 | 0.9302 | 0.9713 | 40.17 | 39.84 | 45.25 |
| MSI-20220227 | 0.8942 | 0.8812 | 0.9611 | 38.31 | 37.91 | 43.98 |
| Multi-Temporal | 0.9380 | 0.9458 | 0.9765 | 40.79 | 40.67 | 46.05 |
| Conditional Information | OLI-20211109 | OLI-20220226 | OLI-20230528 | MSI-20220227 |
|---|---|---|---|---|
| Feature Importance | 0.25 | 0.28 | 0.30 | 0.17 |
| Method | Dataset | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Suzhou | Kuqa | Guangzhou | ||||||||||||||||
| SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | |||||||||||||
| SWIR | NIR | RED | SWIR | NIR | RED | SWIR | NIR | RED | SWIR | NIR | RED | SWIR | NIR | RED | SWIR | NIR | RED | |
| GAN (TGRS, 2021) [28] | 0.7442 | 0.7237 | 0.8948 | 34.51 | 34.19 | 38.85 | 0.8751 | 0.8825 | 0.9079 | 46.06 | 46.04 | 46.97 | 0.8440 | 0.8506 | 0.8696 | 45.60 | 45.59 | 45.60 |
| LLHM (USGS, 2005) [33] | 0.8871 | 0.8582 | 0.9546 | 36.97 | 36.03 | 40.67 | 0.9642 | 0.9620 | 0.9681 | 50.01 | 49.85 | 50.74 | 0.9558 | 0.9498 | 0.9562 | 47.75 | 47.78 | 49.33 |
| STS-CNN (TGRS, 2018) [23] | 0.9207 | 0.9233 | 0.9665 | 38.38 | 37.99 | 43.36 | 0.9754 | 0.9742 | 0.9811 | 50.88 | 51.07 | 52.17 | 0.9681 | 0.9601 | 0.9628 | 49.37 | 48.80 | 49.96 |
| STGAN (WACV, 2020) [12] | 0.8596 | 0.8474 | 0.9369 | 35.91 | 35.19 | 40.35 | 0.9598 | 0.9571 | 0.9671 | 47.89 | 47.35 | 48.68 | 0.9560 | 0.9438 | 0.9446 | 47.69 | 47.32 | 48.13 |
| SEN12MS-CR (TGRS, 2022) [15] | 0.8953 | 0.8935 | 0.9512 | 37.18 | 36.64 | 41.18 | 0.9700 | 0.9669 | 0.9751 | 49.93 | 49.58 | 50.95 | 0.9623 | 0.9477 | 0.9496 | 48.47 | 47.70 | 48.61 |
| CTGAN (ICIP, 2022) [14] | 0.8747 | 0.8868 | 0.9443 | 36.65 | 35.98 | 41.83 | 0.9710 | 0.9693 | 0.9760 | 49.66 | 49.58 | 50.59 | 0.9663 | 0.9535 | 0.9562 | 48.62 | 48.03 | 48.79 |
| PMAA (ECAI, 2023) [42] | 0.8981 | 0.9036 | 0.9580 | 37.11 | 36.65 | 42.60 | 0.9752 | 0.9710 | 0.9790 | 50.13 | 48.62 | 50.82 | 0.9660 | 0.9507 | 0.9564 | 48.82 | 47.95 | 49.30 |
| DiffCR (TGRS, 2024) [8] | 0.9109 | 0.9153 | 0.9549 | 38.22 | 37.75 | 42.04 | 0.9731 | 0.9703 | 0.9758 | 50.53 | 49.86 | 51.01 | 0.9658 | 0.9542 | 0.9539 | 48.68 | 48.05 | 48.55 |
| SMLP-CR | 0.9266 | 0.9307 | 0.9710 | 40.19 | 39.88 | 45.18 | 0.9804 | 0.9786 | 0.9843 | 53.00 | 52.90 | 54.45 | 0.9694 | 0.9614 | 0.9653 | 49.23 | 48.82 | 50.11 |
| Method | Dataset | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Suzhou | Kuqa | Guangzhou | ||||||||||||||||
| SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | |||||||||||||
| SWIR | NIR | RED | SWIR | NIR | RED | SWIR | NIR | RED | SWIR | NIR | RED | SWIR | NIR | RED | SWIR | NIR | RED | |
| STS-CNN (TGRS, 2018) | 0.9289 | 0.9306 | 0.9718 | 38.91 | 37.98 | 43.80 | 0.9809 | 0.9800 | 0.9852 | 51.98 | 52.66 | 53.44 | 0.9737 | 0.9695 | 0.9701 | 50.18 | 49.84 | 50.93 |
| STGAN (WACV, 2020) | 0.9023 | 0.9043 | 0.9596 | 37.01 | 36.40 | 41.64 | 0.9687 | 0.9647 | 0.9744 | 49.04 | 48.17 | 49.94 | 0.9660 | 0.9611 | 0.9610 | 48.25 | 48.18 | 49.21 |
| SEN12MS-CR (TGRS, 2022) | 0.9157 | 0.9242 | 0.9664 | 38.23 | 37.79 | 42.58 | 0.9756 | 0.9734 | 0.9797 | 51.79 | 51.51 | 52.56 | 0.9756 | 0.9648 | 0.9695 | 50.01 | 49.00 | 50.45 |
| CTGAN (ICIP, 2022) | 0.9040 | 0.9120 | 0.9586 | 37.51 | 37.04 | 42.24 | 0.9751 | 0.9730 | 0.9797 | 50.88 | 50.54 | 51.69 | 0.9722 | 0.9672 | 0.9690 | 49.12 | 48.86 | 50.14 |
| PMAA (ECAI, 2023) | 0.9188 | 0.9315 | 0.9651 | 39.22 | 38.82 | 42.44 | 0.9792 | 0.9781 | 0.9834 | 51.66 | 51.96 | 52.13 | 0.9726 | 0.9695 | 0.9729 | 49.76 | 49.50 | 51.13 |
| DiffCR (TGRS, 2024) | 0.9180 | 0.9288 | 0.9608 | 38.64 | 38.45 | 42.62 | 0.9765 | 0.9737 | 0.9790 | 51.95 | 51.03 | 51.77 | 0.9753 | 0.9686 | 0.9706 | 50.08 | 49.53 | 50.65 |
| SMLP-CR | 0.9363 | 0.9449 | 0.9753 | 40.76 | 40.74 | 45.98 | 0.9848 | 0.9834 | 0.9882 | 55.16 | 55.06 | 56.59 | 0.9779 | 0.9745 | 0.9773 | 50.85 | 50.54 | 52.11 |
| Method | Model Complexity | |
|---|---|---|
| Floating Point Operations (FLOPs) | Parameters | |
| STS-CNN (TGRS, 2018) | ||
| STGAN (WACV, 2020) | ||
| SEN12MS-CR (TGRS, 2022) | ||
| CTGAN (ICIP, 2022) | ||
| PMAA (ECAI, 2023) | ||
| DiffCR (TGRS, 2024) | ||
| SMLP-CR | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, W.; Zhang, H.; Zhang, X.; Shen, X.; Zou, L. A Lightweight Machine-Learning Method for Cloud Removal in Remote Sensing Images Constrained by Conditional Information. Remote Sens. 2024, 16, 3134. https://doi.org/10.3390/rs16173134
Zhang W, Zhang H, Zhang X, Shen X, Zou L. A Lightweight Machine-Learning Method for Cloud Removal in Remote Sensing Images Constrained by Conditional Information. Remote Sensing. 2024; 16(17):3134. https://doi.org/10.3390/rs16173134
Chicago/Turabian StyleZhang, Wenyi, Haoran Zhang, Xisheng Zhang, Xiaohua Shen, and Lejun Zou. 2024. "A Lightweight Machine-Learning Method for Cloud Removal in Remote Sensing Images Constrained by Conditional Information" Remote Sensing 16, no. 17: 3134. https://doi.org/10.3390/rs16173134
APA StyleZhang, W., Zhang, H., Zhang, X., Shen, X., & Zou, L. (2024). A Lightweight Machine-Learning Method for Cloud Removal in Remote Sensing Images Constrained by Conditional Information. Remote Sensing, 16(17), 3134. https://doi.org/10.3390/rs16173134