

Automatic Aircraft Identification with High Precision from SAR Images Considering Multiscale Problems and Channel Information Enhancement


Abstract

1. Introductory
- (1)
- An efficient bidirectional-path multiscale fusion and attention network (EBMA-Net) is proposed. It realizes multiple cross-level feature-fusion operations, captures aircraft features more richly and comprehensively, and can effectively solve the problems of discrete aircraft, scale inhomogeneity and complex background interference.
- (2)
- The construction of an efficient multiscale channel attention fusion module (EMCA), which effectively learns multiscale spatial information and accurately captures small aircraft target features.
- (3)
- An efficient dual-channel attention module is proposed, namely, squeeze efficient channel attention (SECA), to reduce the interference of complex background and scattering noise, enhance the robustness of the model, and reduce the dependence on a specific scene, so as to reduce false alarms.
2. Methodology
2.1. The YOLOv7 Backbone Network
2.2. EBMA-Net
2.2.1. EMCA Module
UPF Module
DPF Module
ECBT Module
2.2.2. SECA High-Efficiency Dual-Channel Attention Module
2.3. Classifier
3. Experiments
3.1. Experimental Data
3.2. Environment and Parameters
3.3. Assessment of Indicators
3.4. Results
3.4.1. Analysis of Aircraft Detection Results
3.4.2. Aircraft Inspection Performance Assessment
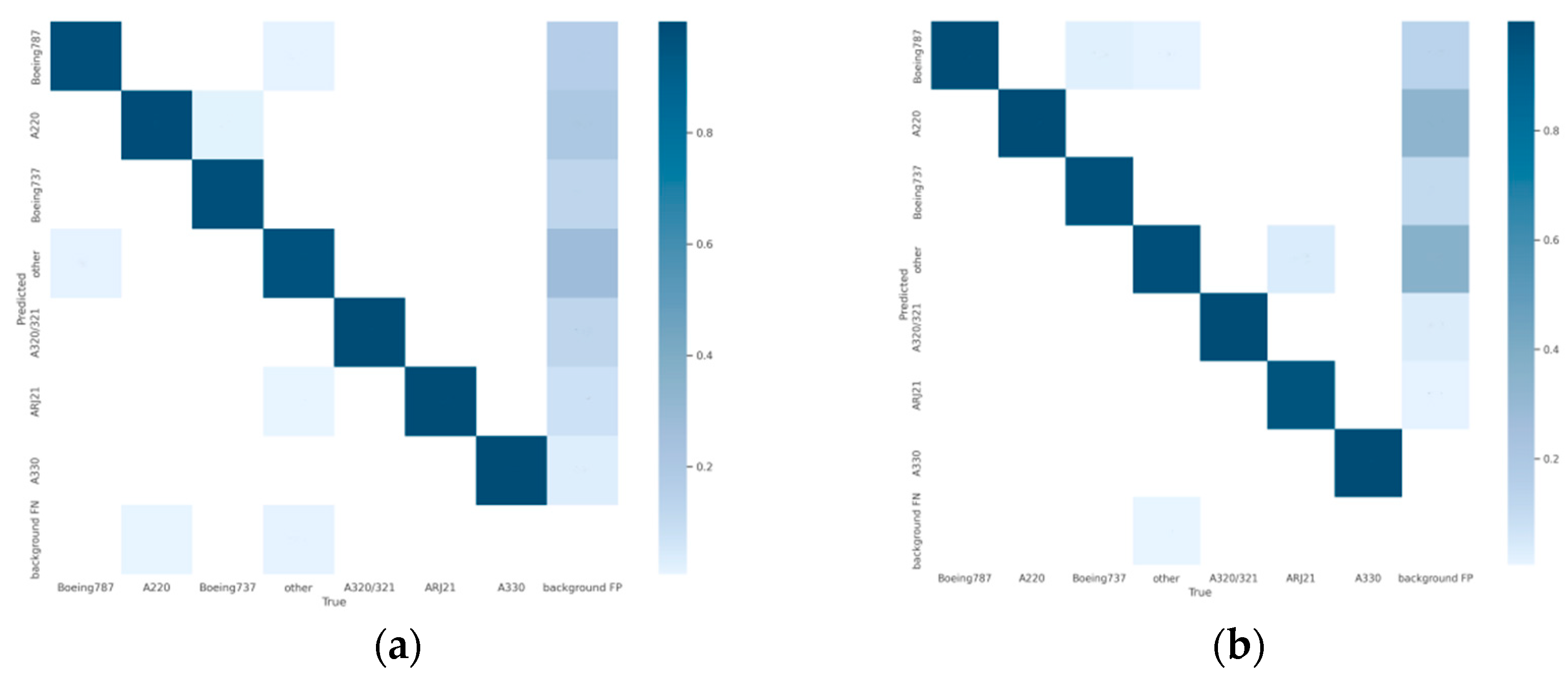
3.4.3. Analysis of Aircraft Identification Results
3.4.4. Performance Evaluation of Aircraft Identification
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, C. Principles, System Analysis and Application of Integrated Aperture Radar; Science Press: Beijing, China, 1989. [Google Scholar]
- Dong, G. Research on SAR Image Target Recognition Technology Based on Single Acting Signal. Ph.D. Thesis, National University of Defense Technology, Qinhuangdao, China, 2016. [Google Scholar]
- Yang, W.; Xu, X.; Sun, H. Discussion on the interpretation technology of synthetic aperture radar image. Space Electron. Technol. 2004, 1, 9. [Google Scholar]
- Chen, L.; Li, Z.; Song, C.; Xing, J.; Cai, X.; Fang, Z.; Luo, R.; Li, Z. Automatic detection of earthquake triggered landslides using Sentinel-1 SAR imagery based on deep learning. Int. J. Digit. Earth 2024, 17, 2393261. [Google Scholar] [CrossRef]
- Li, C. Deep Learning-Based Aircraft Target Detection and Recognition for SAR Images. Ph.D. Thesis, National University of Defense Technology, Qinhuangdao, China, 2019. [Google Scholar]
- Chen, L.; Cai, X.; Li, Z.; Xing, J.; Ai, J. Where is my attention? An explainable AI exploration in water detection from SAR imagery. Int. J. Appl. Earth Obs. Geoinf. 2024, 130, 103878. [Google Scholar] [CrossRef]
- Pan, B.; Tai, J.; Zheng, Q.; Zhao, S. Cascade convolutional neural network based on transfer-learning for aircraft detection on high-resolution remote sensing images. J. Sens. 2017, 2017, 1796728. [Google Scholar] [CrossRef]
- Chen, L.; Cai, X.; Xing, J.; Li, Z.; Zhu, W.; Yuan, Z.; Fang, Z. Towards transparent deep learning for surface water detection from SAR imagery. Int. J. Appl. Earth Obs. Geoinf. 2023, 118, 103287. [Google Scholar] [CrossRef]
- Fu, J. Research on Aircraft Target Recognition from Remote Sensing Images Based on Feature Fusion. Ph.D. Thesis, Nanchang Aviation University, Nanchang, China, 2014. [Google Scholar]
- Gagliardi, R.; Reed, I.S. Adaptive Multiple-Band CFAR (Constant-False-Alarm-Rate) Detection of an Optical Pattern with Unknown Spectral Distribution; Report; Department of Electrical Engineering, University of Southern California: Los Angeles, CA, USA, 1989. [Google Scholar]
- Pan, Z.; Liu, L.; Qiu, X.; Lei, B. Fast Vessel Detection in Gaofen-3 SAR Images with Ultrafine Strip-Map Mode. Sensors 2017, 17, 1578. [Google Scholar] [CrossRef]
- Guo, Q.; Wang, H.; Xu, F. Aircraft target detection from satellite-borne synthetic aperture radar images. Shanghai Aerosp. 2018, 35, 57–64. [Google Scholar]
- Olson, C.F.; Huttenlocher, D.P. Automatic target recognition by matching oriented edge pixels. IEEE Trans. Image Process 1997, 6, 103–113. [Google Scholar] [CrossRef] [PubMed]
- Pan, J.; Niu, Z.; Chen, Z. Aircraft Target Identification Method for SAR Images Based on Peak Matching. Mod. Electron. Technol. 2015, 38, 19–23. [Google Scholar] [CrossRef]
- Guo, Q.; Wang, H.; Xu, F. Advances in aircraft target detection and identification from SAR images. Radar J. 2020, 9, 497–513. [Google Scholar]
- Tan, Y.; Li, Q.; Li, Y.; Tian, J. Aircraft Detection in High-Resolution SAR Images Based on a Gradient Textural Saliency Map. Sensors 2015, 15, 23071–23094. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Meng, W. Research review on single-stage target detection algorithm based on deep learning. Air Armament 2020, 27, 44–53. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Li, C.; Zhao, L.; Kuang, G. A Two-stage Airport Detection Model for Large Scale SAR Images Based on Faster R-CNN. In Proceedings of the Eleventh International Conference on Digital Image Processing (ICDIP 2019), Guangzhou, China, 10–13 May 2019; pp. 515–525. [Google Scholar]
- Zhang, L.; Li, C.; Zhao, L.; Xiong, B.; Quan, S.; Kuang, G. A cascaded three-look network for aircraft detection in SAR images. Remote Sens. Lett. 2020, 11, 57–65. [Google Scholar] [CrossRef]
- Yang, Y.; Zhuang, Y.; Bi, F.; Shi, H.; Xie, Y. M-FCN: Effective fully convolutional network-based airplane detection framework. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1293–1297. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 2999–3007. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934v1. [Google Scholar]
- Wang, C.; Bochkovskiy, A.; Liao, H. Scaled-YOLOv4: Scaling Cross Stage Partial Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 13029–13038. [Google Scholar]
- Ultralytics. YOLOv5. Available online: https://github.com/ultralytics/yolov5 (accessed on 18 May 2024).
- Chen, L.; Luo, R.; Xing, J.; Li, Z.; Xing, X.; Yuan, Z.; Tan, S.; Cai, X. Geospatial transformer is what you need for aircraft detection in SAR Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5225715. [Google Scholar] [CrossRef]
- Luo, R.; Chen, L.; Xing, J.; Yuan, Z.; Tan, S.; Cai, X.; Wang, J. A Fast Aircraft Detection Method for SAR Images Based on Efficient Bidirectional Path Aggregated Attention Network. Remote Sens. 2021, 13, 2940. [Google Scholar] [CrossRef]
- Nie, Y.; Bian, C.; Li, L.; Chen, H.; Chen, S. LFC-SSD: Multiscale aircraft detection based on local feature correlation. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6510505. [Google Scholar] [CrossRef]
- Wang, C.; Bochkovskiy, A.; Liao, H. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Weng, T.; Xing, J.; Li, Z.; Yuan, Z.; Pan, Z.; Tan, S.; Luo, R. Employing deep learning for automatic river bridge detection from SAR images based on adaptively effective feature fusion. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102245. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 11531–11539. [Google Scholar] [CrossRef]
- Srinivas, A.; Lin, T.Y.; Parmar, N.; Shlens, J.; Abbeel, P.; Vaswani, A. Bottleneck transformers for visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 16519–16529. [Google Scholar]
- Wang, Z.; Kang, Y.; Zeng, X.; Wang, Y.; Zhang, T.; Sun, X. SAR-AIRcraft-1.0: A high-resolution SAR aircraft detection and identification dataset. Radar J. 2023, 12, 906–922. [Google Scholar]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Networks | P (%) | R (%) | MDR (%) | FAR (%) |
|---|---|---|---|---|
| YOLOv5s | 84.2 | 93.68 | 6.32 | 15.8 |
| YOLOv7 | 86.78 | 93.78 | 6.22 | 13.22 |
| MGCAN | 86.12 | 93.98 | 6.12 | 13.88 |
| EBPA2N | 87.31 | 93.88 | 6.22 | 12.69 |
| EBMA-Net | 91.31 | 93.88 | 6.12 | 8.69 |
| Networks | Type of Aircraft | P (%) | R (%) | MDR (%) | FAR (%) |
|---|---|---|---|---|---|
| YOLOv5s | Boeing 787 | 93.8 | 92.5 | 7.5 | 6.2 |
| A220 | 95.2 | 96 | 4 | 4.8 | |
| Boeing 737 | 91.2 | 98.3 | 1.7 | 8.8 | |
| Others | 94.3 | 93.9 | 6.1 | 5.7 | |
| A320/321 | 91.6 | 1 | 0 | 8.4 | |
| ARJ21 | 1 | 95.9 | 4.1 | 0 | |
| A330 | 98.4 | 1 | 0 | 1.6 | |
| Mean | 94.9 | 96.6 | 3.4 | 5.1 | |
| YOLOv7 | Boeing 787 | 93.4 | 96.9 | 3.1 | 6.6 |
| A220 | 91.1 | 97.9 | 2.1 | 8.9 | |
| Boeing 737 | 85.9 | 1 | 0 | 14.1 | |
| Others | 88.3 | 97.1 | 2.1 | 11.7 | |
| A320/321 | 90.7 | 1 | 0 | 9.3 | |
| ARJ21 | 95.9 | 95.9 | 4.1 | 4.1 | |
| A330 | 98.3 | 1 | 0 | 1.7 | |
| Mean | 91.9 | 98.2 | 1.8 | 8.1 | |
| MGCAN | Boeing 787 | 93.1 | 95.2 | 4.8 | 6.9 |
| A220 | 93.3 | 96.9 | 3.1 | 6.7 | |
| Boeing 737 | 91.7 | 99.5 | 0.5 | 8.3 | |
| Others | 91.8 | 95 | 5 | 8.2 | |
| A320/321 | 90.5 | 1 | 0 | 9.5 | |
| ARJ21 | 1 | 95.5 | 4.5 | 0 | |
| A330 | 98.7 | 1 | 0 | 1.3 | |
| Mean | 94.1 | 97.4 | 2.6 | 5.9 | |
| EBPA2N | Boeing 787 | 93.8 | 93.6 | 6.7 | 6.2 |
| A220 | 94.8 | 95.3 | 4.7 | 5.2 | |
| Boeing 737 | 95.4 | 97.2 | 2.3 | 4.6 | |
| Others | 93.8 | 93.9 | 6.1 | 6.2 | |
| A320/321 | 91.7 | 99.5 | 0.5 | 8.3 | |
| ARJ21 | 99.8 | 95.9 | 4.1 | 0.2 | |
| A330 | 99.2 | 1 | 0 | 0.8 | |
| Mean | 95.5 | 96.5 | 3.5 | 4.5 | |
| EBMA-Net | Boeing 787 | 93.8 | 97.4 | 2.6 | 6.2 |
| A220 | 94.8 | 97.9 | 2.1 | 5.2 | |
| Boeing 737 | 95.2 | 99.8 | 0.2 | 4.8 | |
| Others | 93.4 | 97.4 | 3.6 | 6.6 | |
| A320/321 | 93.3 | 1 | 0 | 6.7 | |
| ARJ21 | 1 | 96.5 | 3.5 | 0 | |
| A330 | 99 | 1 | 0 | 1 | |
| Mean | 95.6 | 98.4 | 1.6 | 4.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Liu, G.; Liu, J.; Dong, W.; Song, W. Automatic Aircraft Identification with High Precision from SAR Images Considering Multiscale Problems and Channel Information Enhancement. Remote Sens. 2024, 16, 3177. https://doi.org/10.3390/rs16173177
Wang J, Liu G, Liu J, Dong W, Song W. Automatic Aircraft Identification with High Precision from SAR Images Considering Multiscale Problems and Channel Information Enhancement. Remote Sensing. 2024; 16(17):3177. https://doi.org/10.3390/rs16173177
Chicago/Turabian StyleWang, Jing, Guohan Liu, Jiaxing Liu, Wenjie Dong, and Wanying Song. 2024. "Automatic Aircraft Identification with High Precision from SAR Images Considering Multiscale Problems and Channel Information Enhancement" Remote Sensing 16, no. 17: 3177. https://doi.org/10.3390/rs16173177
APA StyleWang, J., Liu, G., Liu, J., Dong, W., & Song, W. (2024). Automatic Aircraft Identification with High Precision from SAR Images Considering Multiscale Problems and Channel Information Enhancement. Remote Sensing, 16(17), 3177. https://doi.org/10.3390/rs16173177