As illustrated in
Figure 2, a hybrid Transformer–convolutional structure is designed as the noise predictor, which is conditioned on CD features extracted from MCD, as expressed by
where
and
represent the high- and low-dimensional CD conditions from MCD, respectively. Both conditions are extracted from the RS images
and
. The function
is a convolutional layer designed to encode the noise
, thereby generating a CD noise feature. The CD noise feature is represented as
within the space
. Initially, the feature
undergoes a conditioning process by
, after which it is encoded by the
DDPM-Encoder denoted as
E. This encoded feature is subsequently integrated with the high-dimensional CD condition
through the GHAT mechanism. The attention mechanism refines the integration process and outputs an Attention Change feature map, referred to as
, which is then relayed to the
DDPM-Decoder, symbolized as
D, to obtain the CD-related noise.
Specifically, given RGB pre- and post-change images
and
, a
Mamba-Encoder within MCD extracts multi-level features from each image. The downsampled conditional feature maps
and
produced by the
i-th
SME layer are of size
, where
i is the layer index with
, and
. These semantic features
of
and
are conveyed into
VSS-CD to compute informative change features
,
, where
denotes the highest-dimension change feature map
, which will be integrated into the GHAT as the high-dimensional CD condition. Extracted change features are fused and upscaled by a
CD-yolo module in MCD to obtain the lowest-dimension change feature map with precise edge details, denoted as
. Element-wise addition is employed to fuse the
and
. The details of the SME is shown in
Table 1.
The estimated noise is then leveraged to facilitate the sampling process each step iteratively, based on the equations, obtaining
where
. Through 1000 iterations of sampling [
50], the single-channel CD map is ultimately generated and sampled from a 2D Gaussian noise distribution.
3.2.1. Mamba-CD Feature Extractor Module
To extract global semantic information from images while maintaining linear complexity, we introduce the
Mamba-based module, termed MCD, effectively improving the change-detection accuracy. This module processes pre- and post-change images, represented as
and
, respectively. Specifically, MCD employs the SME, with five stages for extracting multi-scale features, to obtain multi-scale features from image sets. The extracted feature maps at various levels are denoted as
for
and
for
, where the
i-th level is for
. Specifically, the first stage involves a convolution layer that performs 2× downsampling, reducing the spatial dimensions of the input images
and
, formulated as
where
denotes a convolution operation with a 7 × 7 kernel, stride
s of 2, and padding
p of 3. This operation effectively halves the resolution of the input images.
Moreover, from stages two to five, the downsampling is primarily conducted through a patch-merging layer, which consistently reduces the spatial resolution by a factor of 2× at each stage. The specific transformation at each stage
i (for
) for both pre- and post-change images can be mathematically detailed as follows:
where PatchMerge represents the patch-merging operation that combines adjacent patches (each patch representing a specific feature vector) into a single, larger patch. This operation not only reduces the dimensionality but also helps in aggregating local features into more global representations, crucial for detecting changes across images. The output at each stage further undergoes processing through VSS blocks for enhanced feature extraction.
Sequentially, we further innovate the SSM to make it more suitable for the CD task, which focuses on emphasizing the differences between sequential images. We propose the
SS-CD (State Space Change Detection) module, which focuses on the difference values between pre-change and post-change images. Specifically, the
SS-CD is a linear time-invariant system function to map the difference between the pre-change and post-change images through a hidden state
given
as the evolution parameter,
as the projection parameters for a state size
N, and skip connection
. The model can be formulated as a linear ordinary differential equation as
The discrete version of this linear model can be transformed by the zero-order hold given a timescale parameter
, represented by
The approximation of B is refined using the first-order Taylor series .
As shown in
Figure 3, the VSS-CD block processes the input feature through a linear embedding layer before bifurcating into dual pathways. One pathway proceeds through depth-wise convolution [
60] and SiLU activation [
61], leading to the
SS-CD module as a bridge, linking the pre-change and post-change CD images. Subsequently, post-layer normalization is applied, followed by integration with the alternate pathway post-SiLU activation for the other portion of the difference information. The SS-CD module functions as a sophisticated mechanism to distill the essence of change within a data stream, particularly focusing on capturing subtle and nuanced alterations over extended periods. Consequently, it ensures that the CD process is both accurate and comprehensive in its assessment of the evolving data landscape. After processing by the SS-CD module, the differences are then fed into the DDPM, enhancing the overall analysis.
The number of channels in each subsequent stage of the encoder is increased as the spatial dimensions are reduced.
Inspired by [
55], we propose the
SME to tackle the problem of precisely detecting and outlining changes in intricate, high-dimensional image data. The input image, denoted by
, is initially processed through a convolution layer, effectively halving both the height and width (resulting in
), where
C represents the channel dimension at this initial stage. This convolution is followed by a linear embedding process paired with Vision Swin Sequence (VSS) blocks, which further condense the spatial dimensions to
. Subsequent stages in the encoder involve a series of patch-merging operations coupled with additional VSS blocks that continuously compress the spatial dimensions while increasing the number of channels. The strategy of channel increasing effectively compensates for the loss of spatial information and improves the network’s capacity to represent features more comprehensively. By capturing more complex patterns and details in the data, the network is better equipped to represent high-level semantic information, which is crucial for accurate and detailed image analysis. The third stage results in an output of
, the fourth stage produces
, and the fifth stage culminates in a resolution of
. Each of these stages incorporates two instances of VSS blocks to enrich the feature-extraction process, ensuring a deep and complex representation suitable for high-precision change detection.
Moreover, we employ the CD-yolo module as the decoder of the model. Inspired by the head and neck parts of YOLOv8, the CD-yolo module incorporates advanced techniques to enhance feature integration for CD. The design includes a series of upsampling, concatenation, C2f, and convolution operations, which work together to effectively integrate CD features from SS-CD at different scales. By leveraging these operations, the CD-yolo module improves the model’s ability to capture and combine multi-scale features, thereby enhancing the Overall Accuracy and performance of the CD process.
The CD-yolo module, serving as the decoder part of the model, integrates features from different layers through upsampling and concatenation, ensuring a comprehensive analysis at various scales. Its core component, the C2f module, utilizes convolutional kernels within Bottleneck layers to extract and refine feature information. As these features progress through interconnected Bottleneck layers, they evolve from basic to complex feature maps, balancing intricate details and contextual information. Residual connections within the C2f module enable the leveraging of both fine-grained details and the broader context, enhancing the accuracy and robustness of feature integration.
By integrating these components, the CD-yolo module optimally fulfills its role as a decoder, ensuring that the CD process leverages both detailed and contextual features to yield more precise and reliable outcomes.
3.2.2. NEUNet Architecture and Functionality
The NEUNet consists of the DDPM-Encoder, the GHAT module, and the DDPM-Decoder. This setup effectively combines low- and high-dimensional CD conditions to produce refined CD-related noise. The - is tasked with enriching the conditioned CD noise features, denoted as , through four Residual blocks at levels . Each block uses downsample layers for reducing dimensions, employing a convolutional layer with stride 2, preceded by layer normalization. Starting with a dimension of after the initial layer, the encoder applies successive downsampling, resulting in feature dimensions of , , and at each subsequent stage. The final stage outputs , a feature map with a dimension of after processing through the ResNet-inspired encoder.
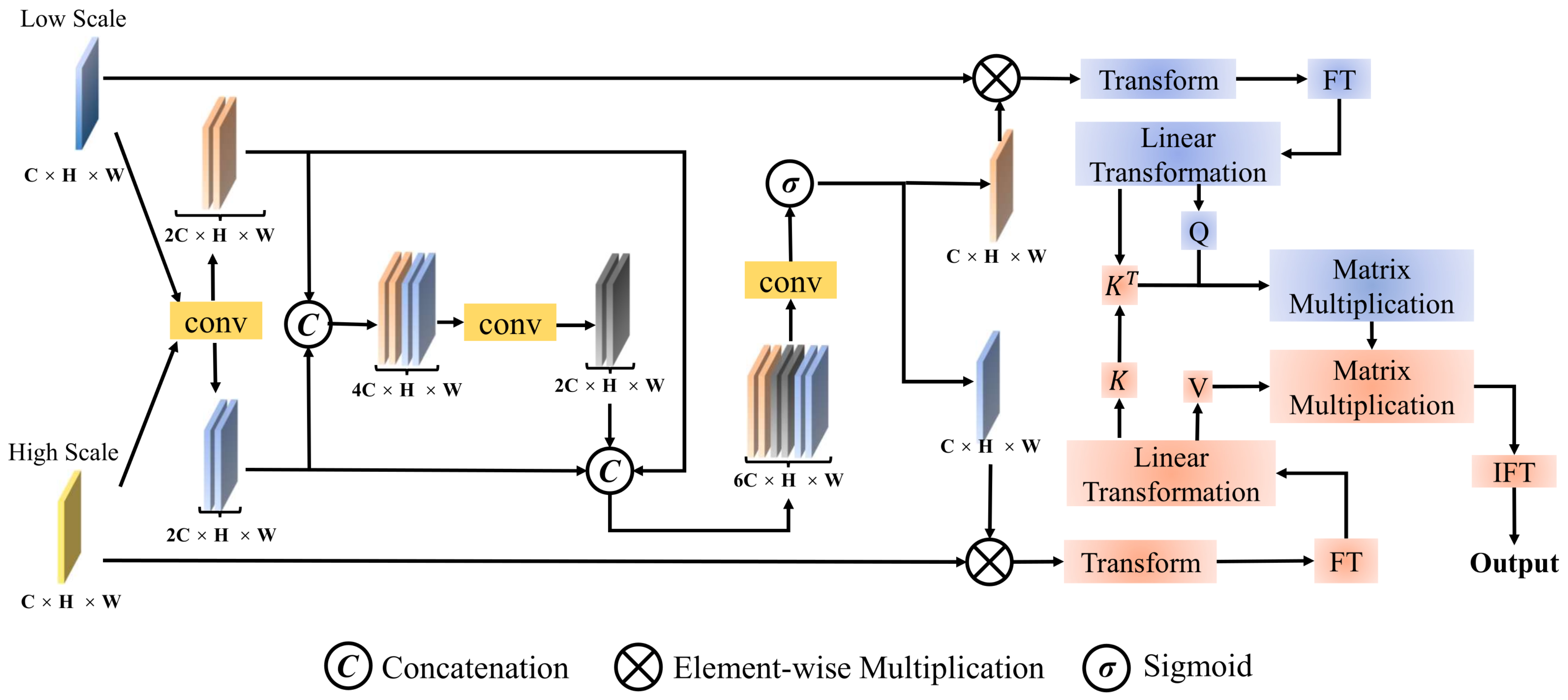
Furthermore, to overcome the challenge of merging high-level CD conditions with noise features effectively, we introduce the GHAT. As illustrated in
Figure 4, this component is carefully designed to ensure a seamless and coherent union of the high-dimensional CD condition
with the encoded conditioned CD noise feature
. Specifically, we double the number of channels on both inputs through a 1 × 1 convolution operation, which can be defined as
while
and
represent the refined feature map after extending the channel. Subsequently, we concatenate the two feature maps, effectively combining their respective information, which can be represented as
where
represents the concatenation and
represents the first intermediate feature map. Following this, we average the two refined feature maps simultaneously to obtain the aligned global features and then splice the aforementioned three feature maps together as follows:
where
represents the operation of calculating the mean value of a feature map and expanding it over the entire pixel space. This operation aims to obtain global features that capture the overall properties of the input features.
represents the second intermediate feature map. After concatenating the three feature maps, we apply a
convolution operation followed by a sigmoid function. This process yields two different global attention feature maps with enhanced global semantic information, one at a low scale and the other at a high scale:
where
and
represent the global attention feature maps of low and high scales, respectively. Then, we multiply the two attentional feature maps element-wise with the original input feature map as
Subsequently,
and
are transformed into token representations
and
, respectively. These tokens undergo Fourier Transform (FT), which converts the spatial domain features into their frequency domain representations. This strategy enables the model to efficiently capture both global and local features from the image data. The tokens are then processed with query, key, and value weight matrices
,
, and
, resulting in
Q,
K, and
V as shown below:
Subsequently, a cross-attention mechanism computes the interaction between
H and
L, with the attention weights captured by
where
denotes the Inverse Fourier Transform (IFT), ensuring that the learned global and local patterns can be reapplied to the original image structure.
is the SoftMax function. The transposed matrix of
K is given by
, with
representing the dimensionality of the keys. The symbol
S indicates the weighting parameters across all channels, and the resulting Attention Change Token
incorporates channel-specific weightings.
Finally, the Attention Change Token is transformed by the reconstruction module into an Attention Change feature map , which has the dimensions . In essence, the fusion process within the GHAT yields the feature map . Starting with —the output from the encoder’s final stage—the decoder utilizes upsampling layers that feature transposed convolution operations with a kernel and stride of 2. This convolution process within the DDPM-Encoder expands the dimensions to . The NEUNet’s robust architecture facilitates a streamlined progression from encoding through fusion to decoding. This seamless operational flow is what renders NEUNet an essential tool for precise noise estimation in sophisticated CD tasks. By intricately modeling and adjusting the noise, NEUNet significantly enhances the accuracy and dependability of the resulting CD map.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}