
An Instrument Error Correlation Model for Global Navigation Satellite System Reflectometry


Abstract
1. Introduction
2. Materials and Methods
2.1. The CYGNSS Observatory
2.2. The Bottoms-Up Correlated Error Model
2.2.1. Model Assumptions
2.2.2. The Full Correlated Error Model
2.3. Verification Techniques
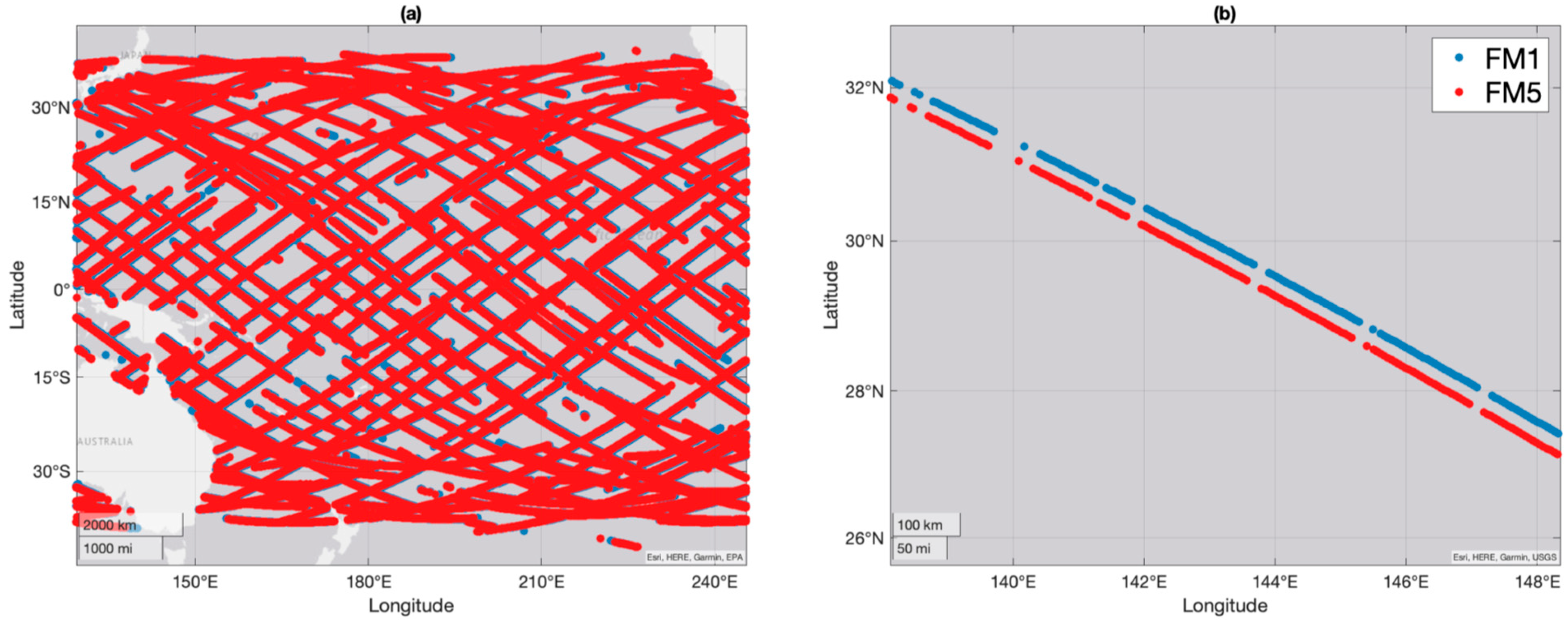
2.3.1. Curating Matchup Observations
- Matched tracks must both contain more than 300 samples;
- Individual sample matchups are valid if samples are within 0.5 degrees (great circle distance);
- Individual samples are screened to ensure no quality control flags apply; and
- The matched track is only valid if 60% of the data remains after all other matchup criteria apply.
2.3.2. Generating Model NBRCS
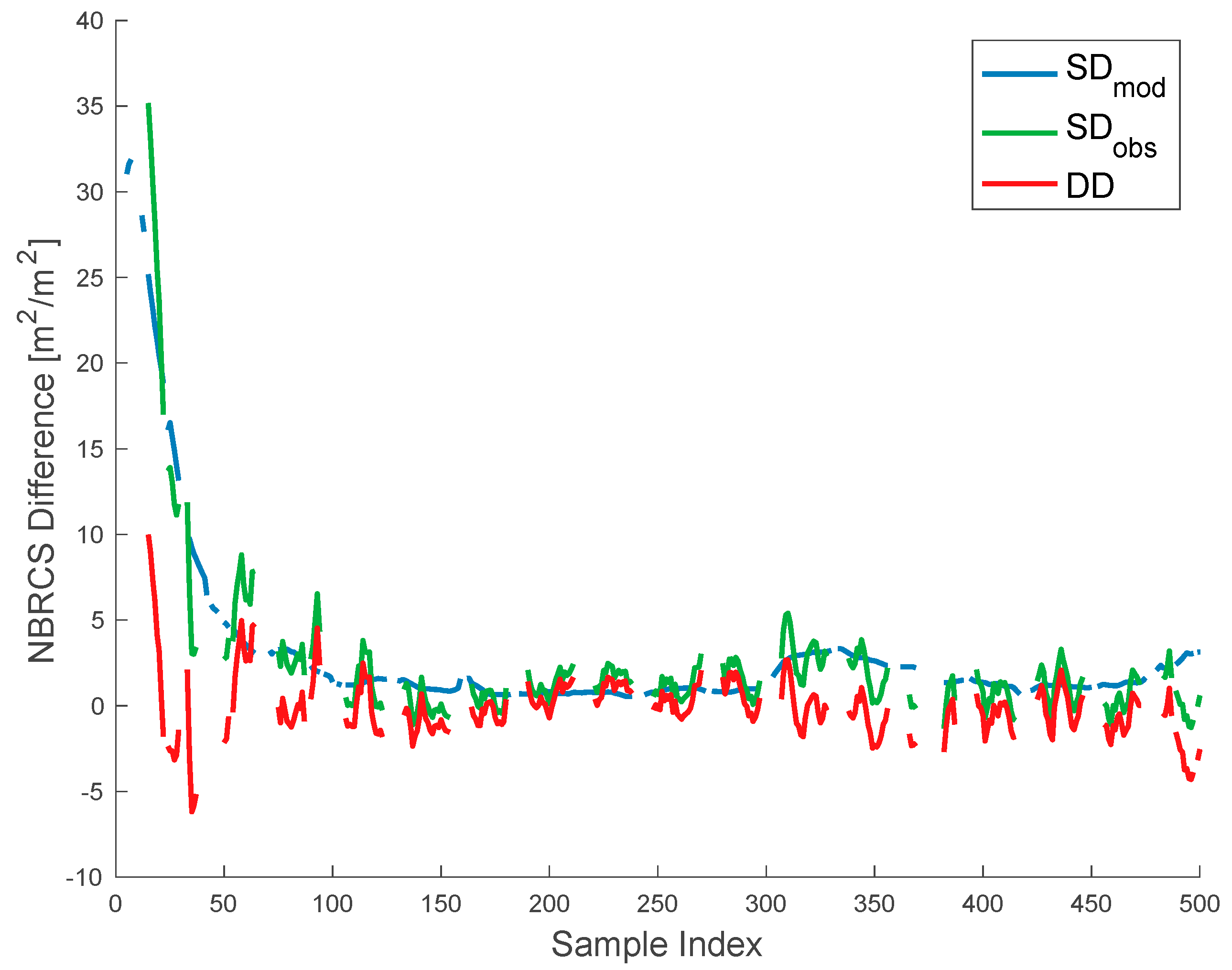
2.3.3. Estimating Total Correlated Error
2.3.4. Model Tuning
- α represents the relative magnitude of the white noise component of the error, which decorrelates at τ = 1;
- β represents the relative magnitude long-decay pedestal or any residual correlated errors at the edge of our timescales of interest;
- γ represents the relative magnitude of the correlated error caused by the terms and , which exhibit smooth decay as samples spread apart when projected through the nadir and zenith antenna coordinates, respectively [see Appendix D for an in-depth discussion]; and
- δ represents the relative decorrelation roll-off in terms and .
3. Results
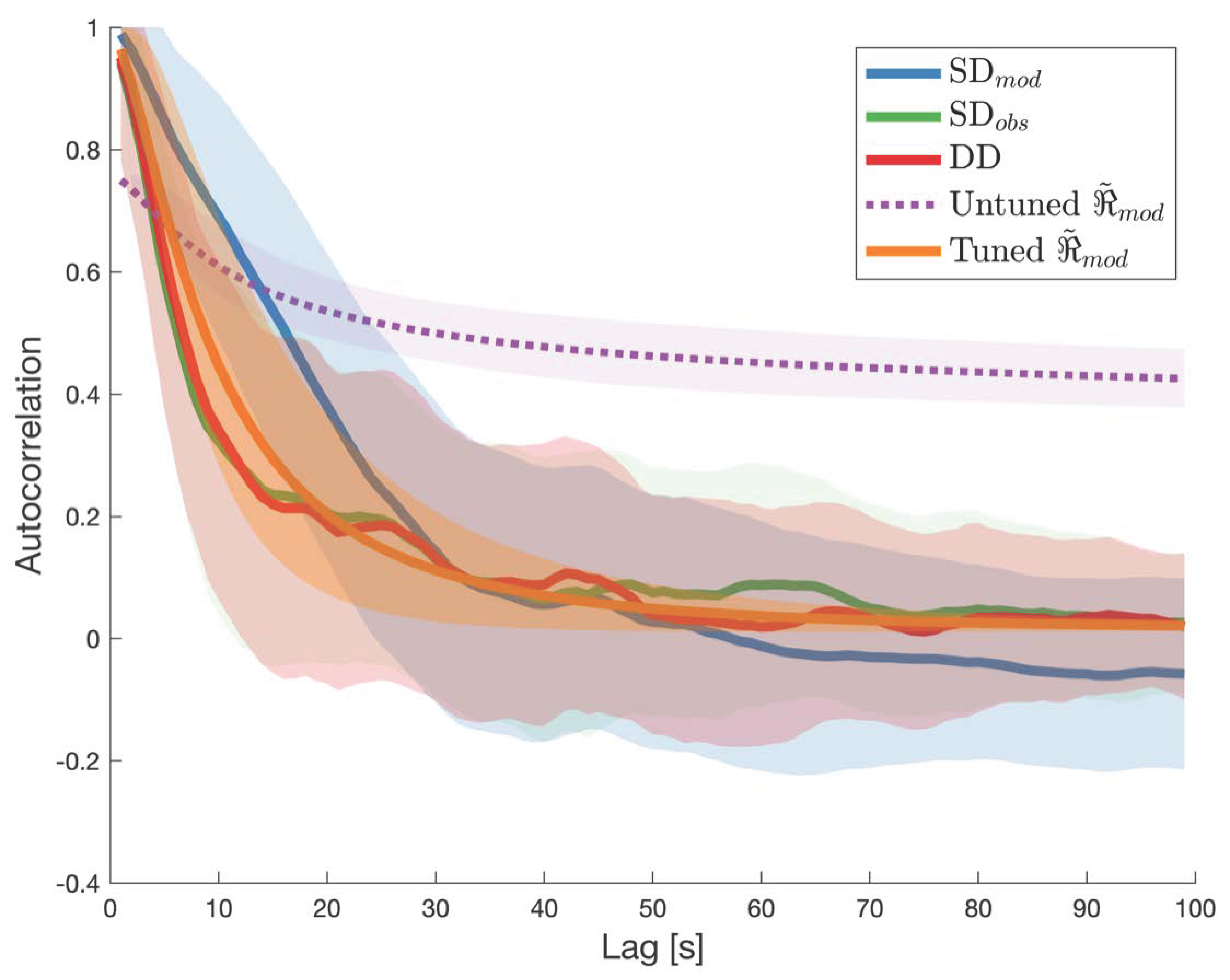
3.1. Bulk Behavior
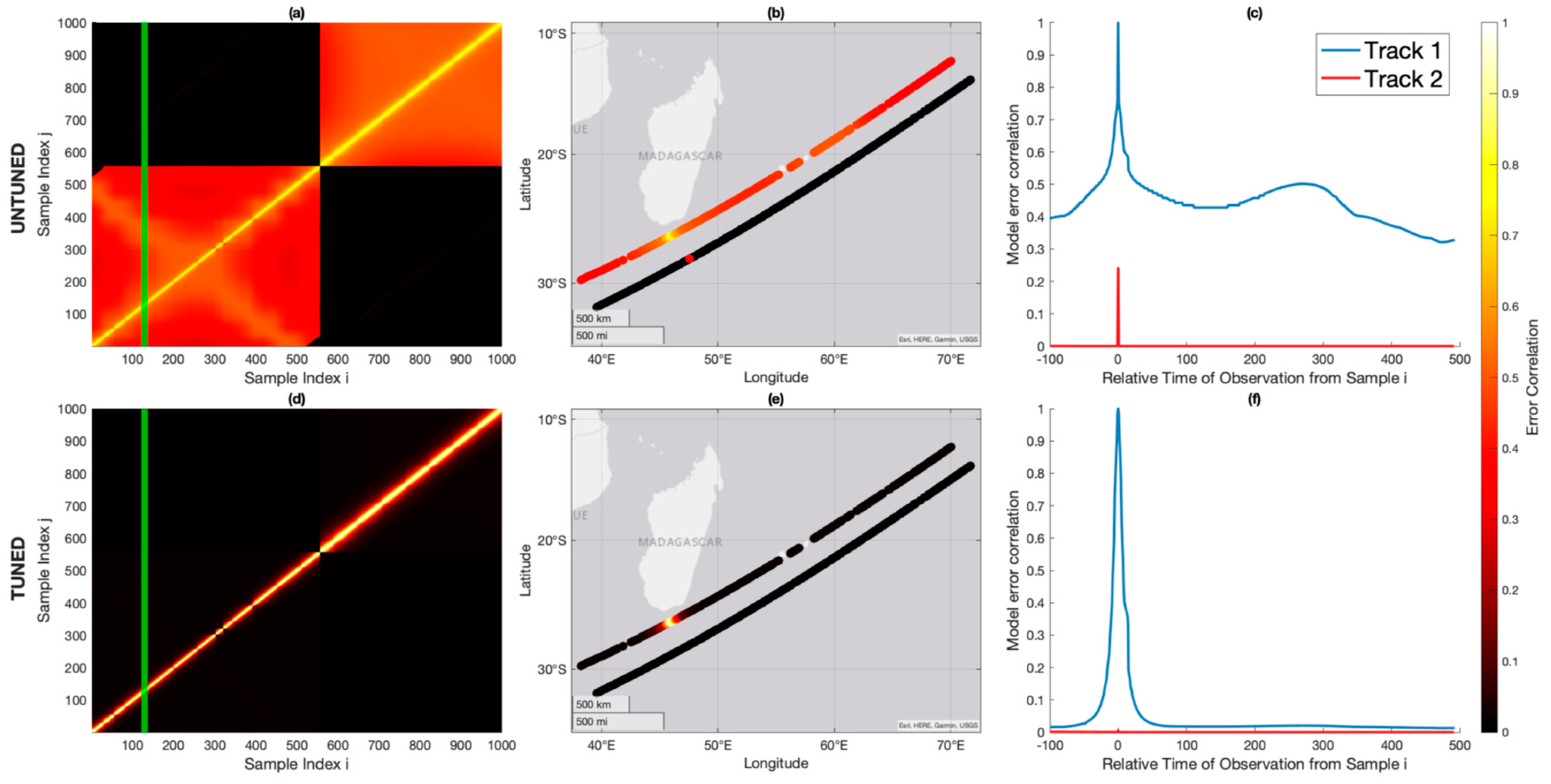
3.2. Single-Track Comparisons
3.3. Dynamic Correlated Error Estimation and Impact of Tuning
4. Discussion
4.1. Limitations
4.2. Impact of Tuning Parameters
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
- The terms Kn, as described in Appendix B, Appendix C, Appendix D and Appendix E, are not constructed from random variables but rather through analytic specification to emulate the expected correlated behavior. We generally have insufficient knowledge to measure or estimate the cross-correlation between error components. Instead, this model simply estimates the cross-correlation of error within individual components, which are then added independently.
- Any residual cross-correlation between error components can be tuned per our tuning parameters.
Appendix B

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Error Term | Error Magnitude [dB] |
|---|---|
| 0.14 [36] | |
| 0.14 [36] | |
| 0.10 [36] | |
| 0.07 [35] | |
| ~0.04 [36] |
Appendix C
Appendix D
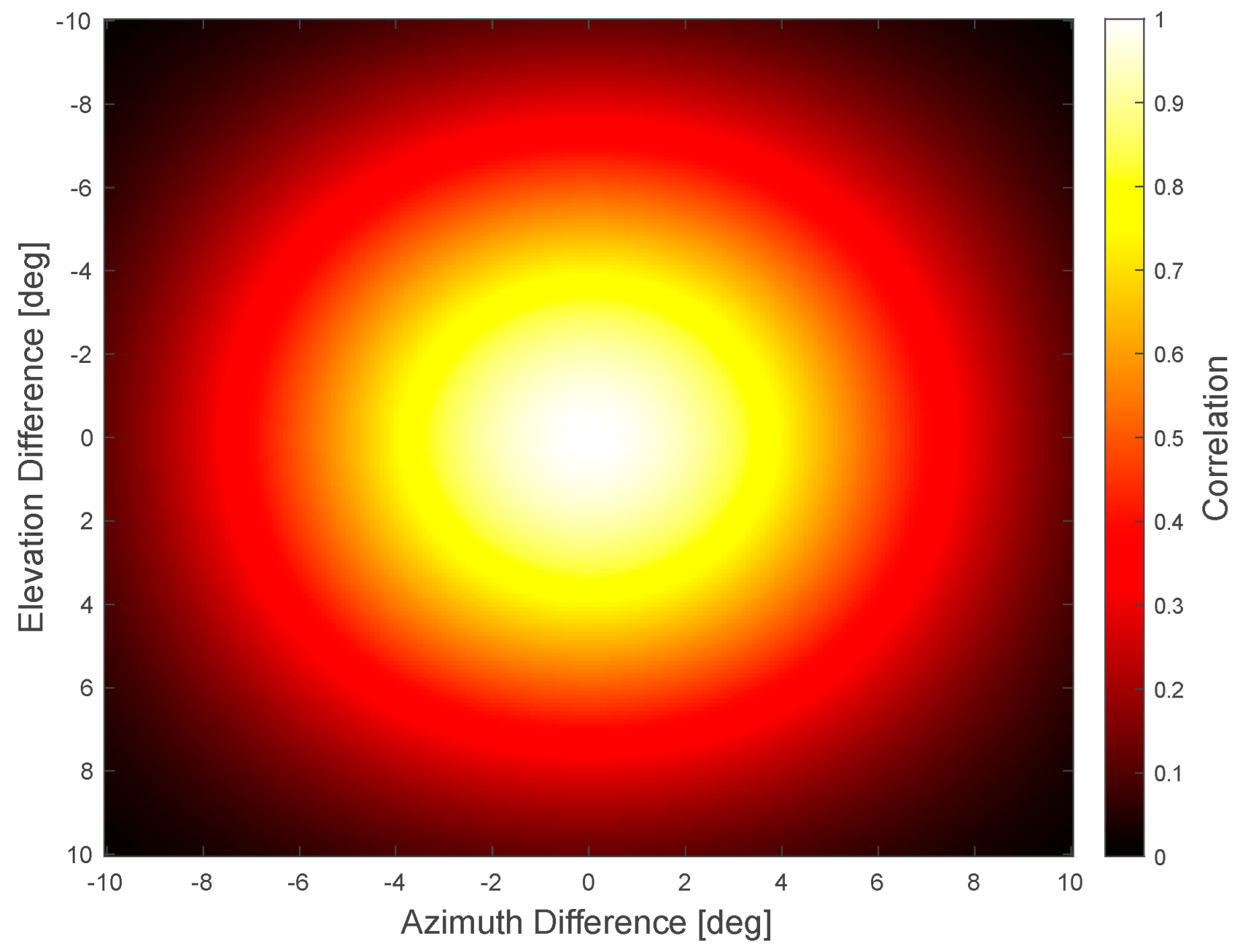
Appendix E
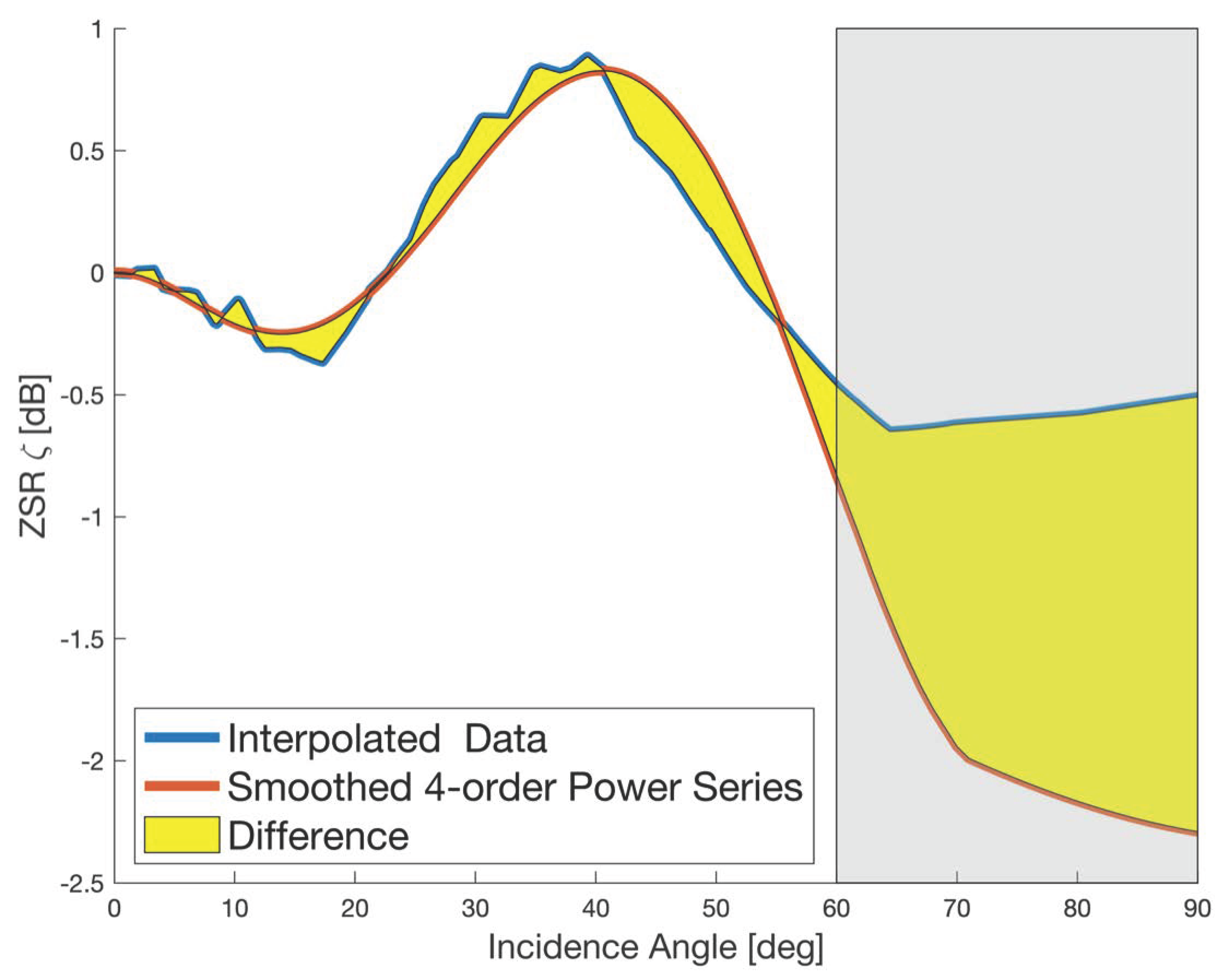

References
- Ruf, C.S.; Chew, C.; Lang, T.; Morris, M.G.; Nave, K.; Ridley, A.; Balasubramaniam, R. A New Paradigm in Earth Environmental Monitoring with the CYGNSS Small Satellite Constellation. Sci. Rep. 2018, 8, 8782. [Google Scholar] [CrossRef] [PubMed]
- Lorenc, A.C.; Ballard, S.P.; Bell, R.S.; Ingleby, N.B.; Andrews, P.L.F.; Barker, D.M.; Bray, J.R.; Clayton, A.M.; Dalby, T.; Li, D.; et al. The Met. Office global three-dimensional variational data assimilation scheme. Q. J. R. Meteorol. Soc. 2000, 126, 2991–3012. [Google Scholar] [CrossRef]
- Bannister, R.N. A review of forecast error covariance statistics in atmospheric variational data assimilation. I: Characteristics and measurements of forecast error covariances. Q. J. R. Meteorol. Soc. 2008, 134, 1951–1970. [Google Scholar] [CrossRef]
- Bannister, R.N. A review of forecast error covariance statistics in atmospheric variational data assimilation. II: Modelling the forecast error covariance statistics. Q. J. R. Meteorol. Soc. 2008, 134, 1971–1996. [Google Scholar] [CrossRef]
- Morss, R.E.; Emanuel, K.A. Influence of added observations on analysis and forecast errors: Results from idealized systems. Q. J. R. Meteorol. Soc. 2002, 128, 285–321. [Google Scholar] [CrossRef]
- Stewart, L.M.; Dance, S.L.; Nichols, N.K. Data assimilation with correlated observation errors: Experiments with a 1-D shallow water model. Tellus A Dyn. Meteorol. Oceanogr. 2013, 65, 19546. [Google Scholar] [CrossRef]
- Fowler, A.M.; Dance, S.L.; Waller, J.A. On the interaction of observation and prior error correlations in data assimilation. Q. J. R. Meteorol. Soc. 2018, 144, 48–62. [Google Scholar] [CrossRef]
- Liu, Z.Q.; Rabier, F. The interaction between model resolution, observation resolution and observation density in data assimilation: A one-dimensional study. Q. J. R. Meteorol. Soc. 2002, 128, 1367–1386. [Google Scholar] [CrossRef]
- Stewart, L.M.; Dance, S.L.; Nichols, N.K.; Eyre, J.R.; Cameron, J. Estimating interchannel observation-error correlations for IASI radiance data in the Met Office system. Q. J. R. Meteorol. Soc. 2014, 140, 1236–1244. [Google Scholar] [CrossRef]
- Bormann, N.; Bonavita, M.; Dragani, R.; Eresmaa, R.; Matricardi, M.; McNally, A. Enhancing the impact of IASI observations through an updated observation-error covariance matrix. Q. J. R. Meteorol. Soc. 2016, 142, 1767–1780. [Google Scholar] [CrossRef]
- Bormann, N.; Bauer, P. Estimates of spatial and interchannel observation-error characteristics for current sounder radiances for numerical weather prediction. I: Methods and application to ATOVS data. Q. J. R. Meteorol. Soc. 2010, 136, 1036–1050. [Google Scholar] [CrossRef]
- Smith, D.; Hunt, S.E.; Etxaluze, M.; Peters, D.; Nightingale, T.; Mittaz, J.; Woolliams, E.R.; Polehampton, E. Traceability of the Sentinel-3 SLSTR Level-1 Infrared Radiometric Processing. Remote Sens. 2021, 13, 374. [Google Scholar] [CrossRef]
- Yang, J.X.; You, Y.; Blackwell, W.; Da, C.; Kalnay, E.; Grassotti, C.; Liu, Q.; Ferraro, R.; Meng, H.; Zou, C.-Z.; et al. SatERR: A Community Error Inventory for Satellite Microwave Observation Error Representation and Uncertainty Quantification. Bull. Am. Meteorol. Soc. 2023, 105, E1–E20. [Google Scholar] [CrossRef]
- Simonin, D.; Waller, J.A.; Ballard, S.P.; Dance, S.L.; Nichols, N.K. A pragmatic strategy for implementing spatially correlated observation errors in an operational system: An application to Doppler radial winds. Q. J. R. Meteorol. Soc. 2019, 145, 2772–2790. [Google Scholar] [CrossRef]
- Waller, J.A.; Dance, S.L.; Nichols, N.K. On diagnosing observation-error statistics with local ensemble data assimilation. Q. J. R. Meteorol. Soc. 2017, 143, 2677–2686. [Google Scholar] [CrossRef]
- Bauer, P.; Buizza, R.; Cardinali, C.; Noël Thépaut, J. Impact of singular-vector-based satellite data thinning on NWP. Q. J. R. Meteorol. Soc. 2011, 137, 286–302. [Google Scholar] [CrossRef]
- Gao, Y.; Xiao, H.; Jiang, D.; Wan, Q.; Chan, P.W.; Hon, K.K.; Deng, G. Impacts of thinning aircraft observations on data assimilation and its prediction during typhoon nida (2016). Atmosphere 2019, 10, 754. [Google Scholar] [CrossRef]
- Hoffman, R.N. The Effect of Thinning and Superobservations in a Simple One-Dimensional Data Analysis with Mischaracterized Error. Mon. Weather Rev. 2018, 146, 1181–1195. [Google Scholar] [CrossRef]
- Rainwater, S.; Bishop, C.H.; Campbell, W.F. The benefits of correlated observation errors for small scales. Q. J. R. Meteorol. Soc. 2015, 141, 3439–3445. [Google Scholar] [CrossRef]
- Stewart, L.M.; Dance, S.L.; Nichols, N.K. Correlated observation errors in data assimilation. Numer. Methods Fluids 2008, 56, 1521–1527. [Google Scholar] [CrossRef]
- Daley, R. The Effect of Serially Correlated Observation and Model Error on Atmospheric Data Assimilation. Mon. Weather Rev. 1992, 120, 164–177. [Google Scholar] [CrossRef]
- Waller, J.A.; Dance, S.L.; Nichols, N.K. Theoretical insight into diagnosing observation error correlations using observation-minus-background and observation-minus-analysis statistics. Quart. J. R. Meteoro. Soc. 2016, 142, 418–431. [Google Scholar] [CrossRef]
- Dee, D.P.; Da Silva, A.M. Maximum-Likelihood Estimation of Forecast and Observation Error Covariance Parameters. Part I: Methodology. Mon. Weather Rev. 1999, 127, 1822–1834. [Google Scholar] [CrossRef]
- Desroziers, G.; Berre, L.; Chapnik, B.; Poli, P. Diagnosis of observation, background and analysis-error statistics in observation space. Q. J. R. Meteorol. Soc. 2005, 131, 3385–3396. [Google Scholar] [CrossRef]
- Ruf, C.; McKague, D.; Posselt, D.J.; Gleason, S.; Clarizia, M.P.; Zavorotny, V.U.; Butler, T.; Redfern, J.; Wells, W.; Morris, M.; et al. CYGNSS Handbook, 2nd ed.; Michigan Publishing Services: Ann Arbor, MI, USA, 2022; ISBN 978-1-60785-787-7. [Google Scholar]
- Clarizia, M.P.; Ruf, C.S. Wind Speed Retrieval Algorithm for the Cyclone Global Navigation Satellite System (CYGNSS) Mission. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4419–4432. [Google Scholar] [CrossRef]
- Ruf, C.S.; Balasubramaniam, R. Development of the CYGNSS Geophysical Model Function for Wind Speed. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 66–77. [Google Scholar] [CrossRef]
- Gleason, S.; Ruf, C.S.; Orbrien, A.J.; McKague, D.S. The CYGNSS Level 1 Calibration Algorithm and Error Analysis Based on On-Orbit Measurements. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 37–49. [Google Scholar] [CrossRef]
- Wang, T.; Ruf, C.; McKague, D.; Russel, A.; O’Brien, A.; Gleason, S. The Important Role of Antenna Pattern Characterization in the Absolute Calibration of GNSS-R Measurements. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 144–146. [Google Scholar]
- Wang, T.; Ruf, C.; Gleason, S.; McKague, D.; O’Brien, A.; Block, B. Monitoring GPS Eirp for Cygnss Level 1 Calibration. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 17 February 2020; pp. 6293–6296. [Google Scholar]
- Steigenberger, P.; Thölert, S.; Montenbruck, O. Flex power on GPS Block IIR-M and IIF. GPS Solut. 2019, 23, 8. [Google Scholar] [CrossRef]
- Marquis, W.A.; Reigh, D.L. The GPS Block IIR and IIR-M Broadcast L-band Antenna Panel: Its Pattern and Performance: GPS Block IIR and IIR-M L-band Antenna Panel Pattern. J. Inst. Navig. 2015, 62, 329–347. [Google Scholar] [CrossRef]
- Wang, T.; Ruf, C.S.; Gleason, S.; O’Brien, A.J.; McKague, D.S.; Block, B.P.; Russel, A. Dynamic Calibration of GPS Effective Isotropic Radiated Power for GNSS-Reflectometry Earth Remote Sensing. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–12. [Google Scholar] [CrossRef]
- Gleason, S. Level 1B DDM Calibration Algorithm Theoritical Basis Document (Rev. 3); University of Michigan: Ann Arbor, MI, USA, 2020. [Google Scholar]
- Powell, C.E.; Ruf, C.S.; Russel, A. An Improved Blackbody Calibration Cadence for CYGNSS. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–7. [Google Scholar] [CrossRef]
- Gleason, S. Level 1A DDM Calibration Algorithm Theoretical Basis Document (Rev. 2); University of Michigan: Ann Arbor, MI, USA, 2018. [Google Scholar]
- Hersbach, H.; Bell, B.; Berrisford, P.; Hirahara, S.; Horányi, A.; Muñoz-Sabater, J.; Nicolas, J.; Peubey, C.; Radu, R.; Schepers, D.; et al. The ERA5 global reanalysis. Q. J. R. Meteorol. Soc. 2020, 146, 1999–2049. [Google Scholar] [CrossRef]
- Wang, T.; Zavorotny, V.U.; Johnson, J.; Yi, Y.; Ruf, C. Integration of Cygnss Wind and Wave Observations with the Wavewatch III Numerical Model. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 8350–8353. [Google Scholar]
- Berg, W.; Brown, S.T.; Lim, B.H.; Reising, S.C.; Goncharenko, Y.; Kummerow, C.D.; Gaier, T.C.; Padmanabhan, S. Calibration and Validation of the TEMPEST-D CubeSat Radiometer. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4904–4914. [Google Scholar] [CrossRef]
- Kroodsma, R.A.; McKague, D.S.; Ruf, C.S. Inter-Calibration of Microwave Radiometers Using the Vicarious Cold Calibration Double Difference Method. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 1006–1013. [Google Scholar] [CrossRef]
- Zec, J.; Jones, W.; Alsabah, R.; Al-Sabbagh, A. RapidScat Cross-Calibration Using the Double Difference Technique. Remote Sens. 2017, 9, 1160. [Google Scholar] [CrossRef]
- Powell, C.E.; Ruf, C.S.; Gleason, S.; Rafkin, S.C.R. Sampled Together: Assessing the Value of Simultaneous Collocated Measurements for Optimal Satellite Configurations. Bull. Am. Meteorol. Soc. 2024, 105, E285–E296. [Google Scholar] [CrossRef]
- CYGNSS CYGNSS Level 1 Science Data Record Version 3.1; NASA: Washington, DC, USA, 2021. [CrossRef]
- Hersbach, H.; Bell, B.; Berrisford, P.; Biavati, G.; Horányi, A.; Muñoz Sabater, J.; Nicolas, J.; Peubey, C.; Radu, R.; Razum, I.; et al. ERA5 Hourly Data on Single Levels from 1940 to Present. Copernicus Climate Change Service (C3S) Climate Data Store (CDS). Available online: https://cds.climate.copernicus.eu/cdsapp#!/dataset/reanalysis-era5-single-levels?tab=overview (accessed on 12 March 2022).
- Taylor, J.R. An Introduction to Error Analysis: The Study of Uncertainties in Physical Measurements, 2nd ed.; University Science Books: Sausalito, CA, USA, 1997; ISBN 978-0-935702-42-2. [Google Scholar]


| Error Term | Error Magnitude [dB] |
|---|---|
| 0.43 [25] | |
| 0.23 [35] | |
| 0.20 [33] | |
| 0.18 [33] | |
| 0.15 [33] | |
| 0.05 [34] | |
| 0.04 [34] | |
| <0.01 [34] | |
| <0.01 ) |
| Tuning Parameter | Magnitude | Function |
|---|---|---|
| 0.005 | Relative magnitude of uncorrelated error | |
| 0.01 | Relative magnitude of endpoint correlated error | |
| 1 | Relative magnitude of nearby roll-off | |
| 1 | Steepness of roll-off component |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Powell, C.E.; Ruf, C.S.; McKague, D.S.; Wang, T.; Russel, A. An Instrument Error Correlation Model for Global Navigation Satellite System Reflectometry. Remote Sens. 2024, 16, 742. https://doi.org/10.3390/rs16050742
Powell CE, Ruf CS, McKague DS, Wang T, Russel A. An Instrument Error Correlation Model for Global Navigation Satellite System Reflectometry. Remote Sensing. 2024; 16(5):742. https://doi.org/10.3390/rs16050742
Chicago/Turabian StylePowell, C. E., Christopher S. Ruf, Darren S. McKague, Tianlin Wang, and Anthony Russel. 2024. "An Instrument Error Correlation Model for Global Navigation Satellite System Reflectometry" Remote Sensing 16, no. 5: 742. https://doi.org/10.3390/rs16050742
APA StylePowell, C. E., Ruf, C. S., McKague, D. S., Wang, T., & Russel, A. (2024). An Instrument Error Correlation Model for Global Navigation Satellite System Reflectometry. Remote Sensing, 16(5), 742. https://doi.org/10.3390/rs16050742