Figure 1.
The target size distribution in the dataset: (a) displays the size histogram of objects in the VisDrone2019 dataset; (b) represents the object size distribution within the NWPU VHR-10 dataset.
Figure 1.
The target size distribution in the dataset: (a) displays the size histogram of objects in the VisDrone2019 dataset; (b) represents the object size distribution within the NWPU VHR-10 dataset.
Figure 2.
Network before improvement.
Figure 2.
Network before improvement.
Figure 3.
Improved network structure. In this figure, SPD Conv represents non-strided convolution, EMA represents efficient multi-scale attention, DAT represents deformable attention, and MConv represents multi-branch convolution.
Figure 3.
Improved network structure. In this figure, SPD Conv represents non-strided convolution, EMA represents efficient multi-scale attention, DAT represents deformable attention, and MConv represents multi-branch convolution.
Figure 4.
Schematic diagram of non-strided convolution module. Split is the pixel separation operation, and concatenate is the combination operation in the channel direction.
Figure 4.
Schematic diagram of non-strided convolution module. Split is the pixel separation operation, and concatenate is the combination operation in the channel direction.
Figure 5.
Schematic diagram of MConv module. Among them, Depthwise Conv represents deep convolution [
48], Common Conv represents ordinary 3 × 3 convolutions, and Pointwise Conv represents 1 × 1 Convolution.
Figure 5.
Schematic diagram of MConv module. Among them, Depthwise Conv represents deep convolution [
48], Common Conv represents ordinary 3 × 3 convolutions, and Pointwise Conv represents 1 × 1 Convolution.
Figure 6.
Schematic diagram of deformable attention module.
Figure 6.
Schematic diagram of deformable attention module.
Figure 7.
Schematic diagram of EMA.
Figure 7.
Schematic diagram of EMA.
Figure 8.
A graphical representation of the Intersection over Union (IoU) metric.
Figure 8.
A graphical representation of the Intersection over Union (IoU) metric.
Figure 9.
Schematic diagram of MPDIoU.
Figure 9.
Schematic diagram of MPDIoU.
Figure 10.
A visual representation illustrating the detection results generated by the network.
Figure 10.
A visual representation illustrating the detection results generated by the network.
Figure 11.
Schematic diagram of evaluation metrics for the model.
Figure 11.
Schematic diagram of evaluation metrics for the model.
Figure 12.
Sample images from the dataset. (a–c) show images from the VisDrone2019; images shown in (d–f) are from the NWPU VHR-10 dataset.
Figure 12.
Sample images from the dataset. (a–c) show images from the VisDrone2019; images shown in (d–f) are from the NWPU VHR-10 dataset.
Figure 13.
Schematic diagram of image data augmentation.
Figure 13.
Schematic diagram of image data augmentation.
Figure 14.
Training flowchart.
Figure 14.
Training flowchart.
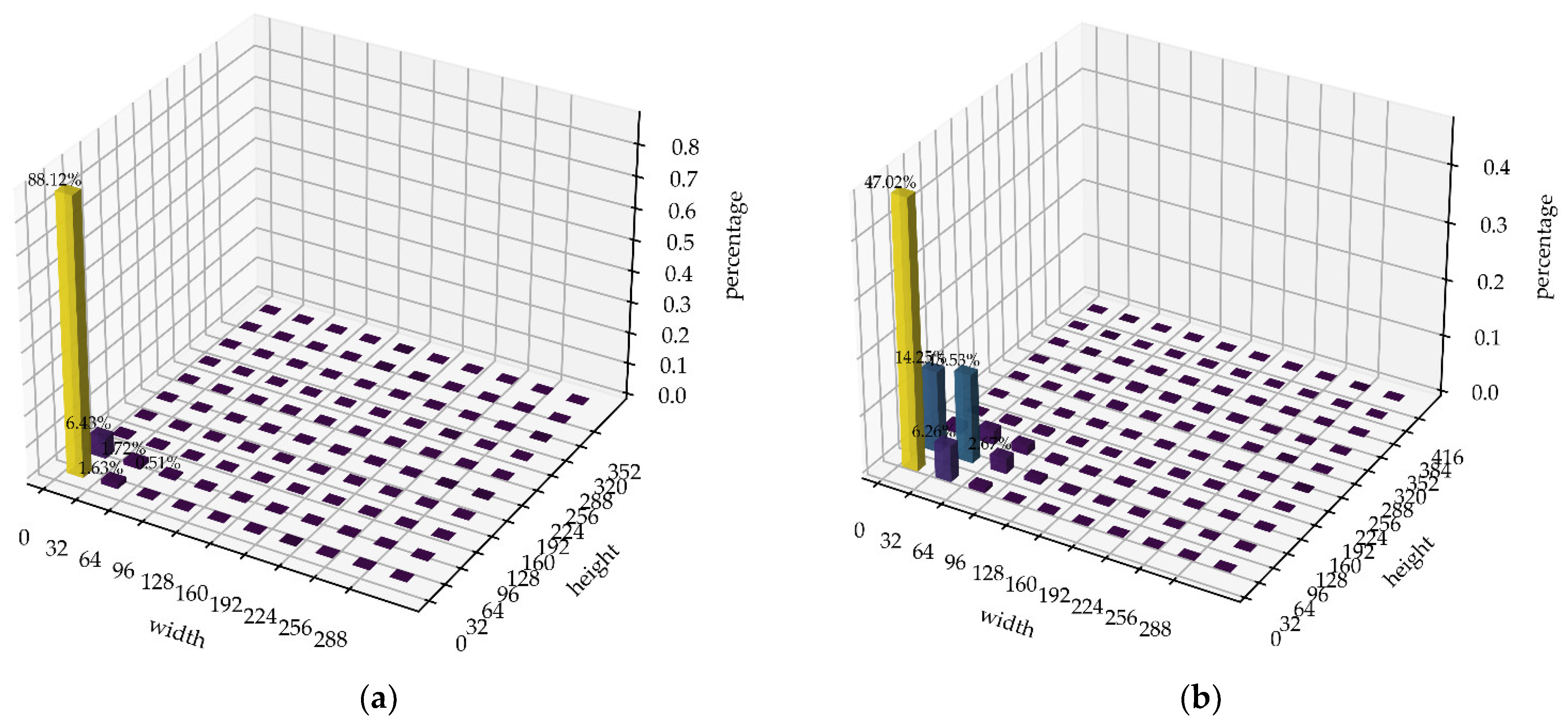
Figure 15.
Statistics on the distribution of bounding box size of the object to be detected. (a,b) depict the statistical findings of the width and height distribution of objects in the Vis-Drone2019 dataset. Similarly, (c,d) showcase the statistical results of the width and height distribution of objects in the NWPU VHR-10 dataset.
Figure 15.
Statistics on the distribution of bounding box size of the object to be detected. (a,b) depict the statistical findings of the width and height distribution of objects in the Vis-Drone2019 dataset. Similarly, (c,d) showcase the statistical results of the width and height distribution of objects in the NWPU VHR-10 dataset.
Figure 16.
Statistics of every category’s number in every database. (a) displays the statistical outcomes of different object categories in the VisDrone2019 dataset, while (b) showcases the statistical results of each object category in the NWPU VHR-10 dataset.
Figure 16.
Statistics of every category’s number in every database. (a) displays the statistical outcomes of different object categories in the VisDrone2019 dataset, while (b) showcases the statistical results of each object category in the NWPU VHR-10 dataset.
Figure 17.
The P-R curve of every category object at an IoU threshold of 0.5. (a) P-R curves on the VisDrone2019 validation dataset; (b) P-R curves on the NWPU VHR-10 validation dataset.
Figure 17.
The P-R curve of every category object at an IoU threshold of 0.5. (a) P-R curves on the VisDrone2019 validation dataset; (b) P-R curves on the NWPU VHR-10 validation dataset.
Figure 18.
Comparison of mAP50 curves before and after model improvement. (a) Comparison chart of curves for the VisDrone2019 dataset mAP50; (b) comparison chart of the curves of mAP50 in the NWPU VHR-10 dataset.
Figure 18.
Comparison of mAP50 curves before and after model improvement. (a) Comparison chart of curves for the VisDrone2019 dataset mAP50; (b) comparison chart of the curves of mAP50 in the NWPU VHR-10 dataset.
Figure 19.
Radar chart for each category of AP50, (a) Comparison chart of AP50 for each category in the VisDrone2019 dataset before and after model improvement; (b) comparison chart of AP50 for each category in the NWPU VHR-10 dataset before and after model improvement.
Figure 19.
Radar chart for each category of AP50, (a) Comparison chart of AP50 for each category in the VisDrone2019 dataset before and after model improvement; (b) comparison chart of AP50 for each category in the NWPU VHR-10 dataset before and after model improvement.
Figure 20.
Comparison of confusion matrices. (a) Confusion matrix diagram for the VisDrone2019 validation set before model improvement; (b) confusion matrix diagram for the VisDrone2019 validation set after model improvement; (c) confusion matrix diagram for NWPU VHR-10 validation set before model improvement; (d) confusion matrix diagram for the NWPU VHR-10 validation set after model improvement.
Figure 20.
Comparison of confusion matrices. (a) Confusion matrix diagram for the VisDrone2019 validation set before model improvement; (b) confusion matrix diagram for the VisDrone2019 validation set after model improvement; (c) confusion matrix diagram for NWPU VHR-10 validation set before model improvement; (d) confusion matrix diagram for the NWPU VHR-10 validation set after model improvement.
Figure 21.
Comparison experiments with the modules on VisDrone2019 for each category of AP50.
Figure 21.
Comparison experiments with the modules on VisDrone2019 for each category of AP50.
Figure 22.
Comparison experiments with the modules on NWPU VHR-10 for each category of AP50.
Figure 22.
Comparison experiments with the modules on NWPU VHR-10 for each category of AP50.
Figure 23.
The performance of different models in detecting objects was evaluated on the VisDrone2019 validation dataset.
Figure 23.
The performance of different models in detecting objects was evaluated on the VisDrone2019 validation dataset.
Figure 24.
Detection results of different models on the NWPU VHR-10 validation dataset.
Figure 24.
Detection results of different models on the NWPU VHR-10 validation dataset.
Figure 25.
Comparison of thermal maps generated using GradCAM for different model detection results.
Figure 25.
Comparison of thermal maps generated using GradCAM for different model detection results.
Figure 26.
Comparison of heat maps generated using GradCAM for different model detection results. (a,b) are the results generated from two different images, respectively.
Figure 26.
Comparison of heat maps generated using GradCAM for different model detection results. (a,b) are the results generated from two different images, respectively.
Table 1.
Experimental configuration.
Table 1.
Experimental configuration.
| Parameters | Value |
|---|
| Programming language | Python (3.8.16) |
| GPU | NVIDIA GeForce RTX 6000 Ada |
| CPU | Intel(R) Xeon(R) w9-3495X |
| RAM | 64 G |
| system | Ubuntu 20.04 |
| Neural network framework | Pytorch (torch 1.13.1 + cu116) |
Table 2.
Experimental setting.
Table 2.
Experimental setting.
| Hyperparameters | Value |
|---|
| Image | 640 × 640 |
| Batch | 16 |
| Epoch | 200 |
| Weight Decay | 0.0005 |
| Momentum | 0.937 |
| Learning Rate | 0.01 |
| Optimizer | Lion |
Table 3.
Anchor box sizes for different datasets.
Table 3.
Anchor box sizes for different datasets.
| Dataset | Value |
|---|
| Group One | Group Two | Group Three |
|---|
| VisDrone2019 | [3 4] | [4 9] | [8 7] | [8 14] | [15 9] | [14 21] | [28 15] | [31 34] | [62 46] |
| NWPU VHR-10 | [6 7] | [10 15] | [21 12] | [19 28] | [41 23] | [34 49] | [73 41] | [59 86] | [128 82] |
Table 4.
Value of AP50 for each category in the VisDrone2019 dataset before and after model improvement.
Table 4.
Value of AP50 for each category in the VisDrone2019 dataset before and after model improvement.
| Models | All | Bicycle | Pedestrian | Truck | People | Motor | Car | Bus | Van | Tricycle | Awning-Tricycle |
|---|
| Original | 48.5 | 23.8 | 56.3 | 48.2 | 45.9 | 56.3 | 85.1 | 64.9 | 48.9 | 37.1 | 18.6 |
| Improved | 56.8 | 38.3 | 69.6 | 49.7 | 57.9 | 69.8 | 89.7 | 65.1 | 57.5 | 43.1 | 26.2 |
Table 5.
The AP50 values of each category in the NWPU VHR-10 dataset before and after model improvement.
Table 5.
The AP50 values of each category in the NWPU VHR-10 dataset before and after model improvement.
| Models | All | Tennis Court | Airplane | Storage Tank | Basketball Court | Ship | Ground Track Field | Harbor | Baseball Diamond | Bridge | Vehicles |
|---|
| Original | 88.3 | 95.9 | 96.8 | 83.5 | 85.6 | 83.6 | 96.1 | 95.5 | 97.4 | 62.1 | 86.8 |
| Improved | 94.6 | 97.3 | 98.5 | 93.5 | 93.6 | 93.6 | 98.2 | 95.5 | 99.4 | 83.5 | 92.8 |
Table 6.
Ablation experiments with the modules on VisDrone2019 and NWPU VHR-10 datasets.
Table 6.
Ablation experiments with the modules on VisDrone2019 and NWPU VHR-10 datasets.
| Dataset | Models | P (%) | R (%) | mAP50 (%) | mAP50:95 (%) |
|---|
| VisDrone2019 | Baseline | 53.1 | 52.3 | 48.5 | 28.1 |
| +SPD − Conv | 60.6 | 53.2 | 53.6 | 31.4 |
| +DAT + SPD − Conv | 61.1 | 56.7 | 54.8 | 32.6 |
| +DAT + SPD – Conv + EMA | 62.3 | 57.6 | 55.3 | 33.1 |
| +DAT + SPD – Conv + EMA + MConv | 63.3 | 58.5 | 56.1 | 34.1 |
| +DAT + SPD – Conv + EMA + MConv + MPDIoU | 63.9 | 59.2 | 56.8 | 34.9 |
| NWPU VHR-10 | Baseline | 90.8 | 82.6 | 88.3 | 55.8 |
| +SPD − Conv | 91.3 | 83.4 | 89.0 | 56.1 |
| +DAT + SPD − Conv | 93.1 | 86.5 | 91.5 | 57.2 |
| +DAT + SPD – Conv + EMA | 94.6 | 89.1 | 93.6 | 57.9 |
| +DAT + SPD – Conv + EMA + MConv | 94.9 | 89.5 | 94.1 | 58.1 |
| +DAT + SPD – Conv + EMA + MConv + MPDIoU | 95.3 | 90.2 | 94.6 | 58.3 |
Table 7.
Ablation experiments on VisDrone2019 and NWPU VHR-10.
Table 7.
Ablation experiments on VisDrone2019 and NWPU VHR-10.
| Dataset | Models | P (%) | R (%) | mAP50 (%) | mAP50:95 (%) |
|---|
| VisDrone2019 | Baseline | 53.1 | 52.3 | 48.5 | 28.1 |
| +DD + PC | 53.8 | 53.1 | 49.1 | 28.9 |
| +CC + PC | 53.3 | 52.3 | 48.6 | 28.1 |
| + DD + CC + PC | 53.9 | 53.2 | 49.2 | 29.1 |
| NWPU VHR-10 | Baseline | 90.8 | 82.6 | 88.3 | 55.8 |
| +DD + PC | 91.0 | 82.9 | 88.6 | 56.0 |
| + CC + PC | 90.9 | 82.6 | 88.4 | 55.8 |
| + DD + CC + PC | 91.1 | 82.9 | 88.7 | 56.1 |
Table 8.
Comparison experiments on VisDrone2019.
Table 8.
Comparison experiments on VisDrone2019.
| Algorithm | FPS | mAP50(%) | mAP50:95(%) |
|---|
| YOLOv3-SPP [22] | 32 | 47.7 | 28.6 |
| YOLOv4 [23] | 35 | 47.3 | 26.4 |
| YOLOv5l [24] | 28 | 48.1 | 25.3 |
| YOLOv7 [5] | 53 | 48.5 | 28.1 |
| TPH-YOLOv5 [54] | 32 | 48.9 | 26.1 |
| PP-YOLOE [55] | 36 | 39.6 | 24.6 |
| YOLOv8 [56] | 59 | 46.3 | 27.8 |
| Ours | 51 | 56.8 | 34.9 |
Table 9.
Comparison experiments with the modules on VisDrone2019 for each category of AP50.
Table 9.
Comparison experiments with the modules on VisDrone2019 for each category of AP50.
| Category | YOLOv3-SPP [22] | YOLOv4 [23] | YOLOv5l [24] | TPH-YOLOv5 [5] | YOLOv7 [54] | Ours |
|---|
| All | 47.7 | 47.3 | 48.1 | 48.9 | 48.5 | 56.8 |
| Motor | 55.4 | 58.2 | 55.8 | 60.2 | 56.3 | 69.8 |
| Bus | 63.8 | 54.3 | 64.3 | 56.1 | 64.9 | 65.1 |
| Awning-tricycle | 18.3 | 21.8 | 18.4 | 22.6 | 18.6 | 26.2 |
| Tricycle | 36.5 | 35.9 | 36.7 | 37.2 | 37.1 | 43.1 |
| Truck | 47.4 | 41.4 | 47.8 | 42.9 | 48.2 | 49.7 |
| Van | 48.1 | 47.9 | 48.5 | 49.5 | 48.9 | 57.5 |
| Car | 83.6 | 74.8 | 84.3 | 77.3 | 85.1 | 89.7 |
| Bicycle | 23.4 | 31.9 | 23.6 | 33.2 | 23.8 | 38.3 |
| People | 45.1 | 48.3 | 45.5 | 49.8 | 45.9 | 57.9 |
| Pedestrian | 55.3 | 58.1 | 55.8 | 60.1 | 56.3 | 69.6 |
Table 10.
Comparison experiments on NWPU VHR-10.
Table 10.
Comparison experiments on NWPU VHR-10.
| Algorithm | FPS | mAP50(%) | mAP50:95(%) |
|---|
| YOLOv3-SPP [22] | 39 | 89.1 | 55.2 |
| YOLOv4 [23] | 42 | 86.9 | 54.3 |
| YOLOv5l [24] | 36 | 87.6 | 54.9 |
| YOLOv7 [5] | 61 | 88.3 | 55.8 |
| TPH-YOLOv5 [54] | 41 | 92.3 | 56.8 |
| PP-YOLOE [55] | 45 | 81.8 | 54.2 |
| YOLOv8 [56] | 67 | 89.9 | 56.3 |
| Ours | 58 | 94.6 | 58.3 |
Table 11.
Comparison experiments with the modules on NWPU VHR-10 for each category of AP50.
Table 11.
Comparison experiments with the modules on NWPU VHR-10 for each category of AP50.
| Category | YOLOv3-SPP [22] | YOLOv4 [23] | YOLOv5l [24] | TPH-YOLOv5 [54] | YOLOv7 [5] | Ours |
|---|
| Tennis court | 89.1 | 89.6 | 87.8 | 92.1 | 95.9 | 97.3 |
| Baseball diamond | 94.4 | 95.4 | 92.4 | 97.0 | 97.4 | 99.4 |
| Storage tank | 65.3 | 67.1 | 85.5 | 88.3 | 83.5 | 93.5 |
| Airplane | 94.6 | 96.1 | 92.5 | 96.1 | 96.8 | 98.5 |
| Ship | 90.8 | 92.0 | 84.9 | 89.2 | 83.6 | 93.6 |
| Basketball court | 87.5 | 73.0 | 85.7 | 90.8 | 85.6 | 93.6 |
| Ground track field | 92.5 | 94.1 | 89.8 | 94.9 | 96.3 | 98.2 |
| Harbor | 93.9 | 80.9 | 83.5 | 89.1 | 95.2 | 95.6 |
| Bridge | 90.4 | 86.7 | 82.6 | 89.4 | 62.1 | 83.5 |
| Vehicles | 92.3 | 93.9 | 91.2 | 95.7 | 86.8 | 92.8 |
| All | 89.1 | 86.9 | 87.6 | 92.3 | 88.3 | 94.6 |

































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}