
Night-Time Vessel Detection Based on Enhanced Dense Nested Attention Network

Abstract
:1. Introduction
2. Study Area and Materials
2.1. Study Area
2.2. Datasets and Pre-Processing
2.2.1. VIIRS/DNB
2.2.2. Auxiliary Data
3. Methodology
3.1. Enhanced Dense Nested Attention Network
3.2. Loss Function
3.3. Training Parameter and Evaluation Metrics
4. Results
4.1. Night-Time Vessel-Detection Results
4.2. Comparison of Different Approaches
4.2.1. Enhanced DNA-Net versus DNA-Net
4.2.2. Ablation Study
- (1)
- Effect of CAM and SAM
- (2)
- DNIM Versus U-net
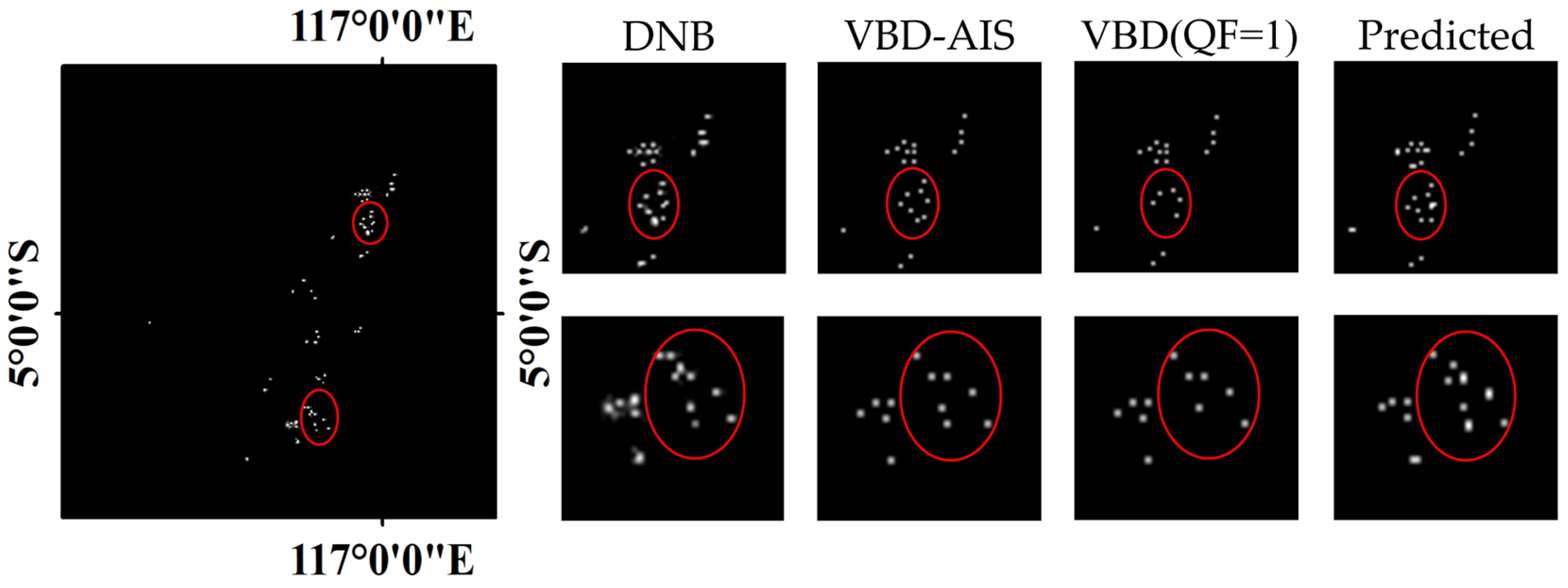
4.2.3. VBD versus Enhanced DNA-Net
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cabral, R.B.; Mayorga, J.; Clemence, M.; Lynham, J.; Koeshendrajana, S.; Muawanah, U.; Nugroho, D.; Anna, Z.; Mira; Ghofar, A.; et al. Rapid and Lasting Gains from Solving Illegal Fishing. Nat. Ecol. Evol. 2018, 2, 650–658. [Google Scholar] [CrossRef] [PubMed]
- Chuaysi, B.; Kiattisin, S. Fishing Vessels Behavior Identification for Combating IUU Fishing: Enable Traceability at Sea. Wirel. Pers Commun. 2020, 115, 2971–2993. [Google Scholar] [CrossRef]
- Deja, A.; Ulewicz, R.; Kyrychenko, Y. Analysis and Assessment of Environmental Threats in Maritime Transport. Transp. Res. Procedia 2021, 55, 1073–1080. [Google Scholar] [CrossRef]
- Li, X.; Xiao, Y.; Su, F.; Wu, W.; Zhou, L. AIS and VBD data fusion for marine fishing intensity mapping and analysis in the northern part of the South China Sea. Int. J. Geo Inf. 2021, 10, 277. [Google Scholar] [CrossRef]
- Hsu, F.-C.; Elvidge, C.D.; Baugh, K.; Zhizhin, M.; Ghosh, T.; Kroodsma, D.; Susanto, A.; Budy, W.; Riyanto, M.; Nurzeha, R.; et al. Cross-matching VIIRS boat detections with vessel monitoring system Tracks in Indonesia. Remote Sens. 2019, 11, 995. [Google Scholar] [CrossRef]
- Ophoff, T.; Puttemans, S.; Kalogirou, V.; Robin, J.-P.; Goedemé, T. Vehicle and vessel detection on satellite imagery: A comparative study on single-shot detectors. Remote Sens. 2020, 12, 1217. [Google Scholar] [CrossRef]
- He, C.; Ma, Q.; Liu, Z.; Zhang, Q. Modeling the spatiotemporal dynamics of electric power consumption in mainland China using saturation-corrected DMSP/OLS nighttime stable light data. Int. J. Digit. Earth. 2014, 7, 993–1014. [Google Scholar] [CrossRef]
- Huang, Q.; He, C.; Gao, B.; Yang, Y.; Liu, Z.; Zhao, Y.; Dou, Y. Detecting the 20 year city-size dynamics in China with a rank clock approach and DMSP/OLS nighttime data. Landsc. Urban Plan. 2015, 137, 138–148. [Google Scholar] [CrossRef]
- Levin, N.; Kyba, C.C.M.; Zhang, Q.; Sánchez de Miguel, A.; Román, M.O.; Li, X.; Portnov, B.A.; Molthan, A.L.; Jechow, A.; Miller, S.D.; et al. Remote Sensing of Night Lights: A review and an outlook for the future. Remote Sens. Environ. 2020, 237, 111443. [Google Scholar] [CrossRef]
- Elvidge, C.D.; Baugh, K.E.; Zhizhin, M.; Hsu, F.-C. Why VIIRS data are superior to DMSP for mapping nighttime lights. Proc. Asia-Pac. Adv. Netw. 2013, 35, 62. [Google Scholar] [CrossRef]
- Miller, S.D.; Straka III, W.; Mills, S.P.; Elvidge, C.D.; Lee, T.F.; Solbrig, J.; Walther, A.; Heidinger, A.K.; Weiss, S.C. Illuminating the capabilities of the suomi national polar-orbiting partnership (NPP) visible infrared imaging radiometer suite (VIIRS) day/night band. Remote Sens. 2013, 5, 6717–6766. [Google Scholar] [CrossRef]
- Tan, X.; Zhu, X.; Chen, J.; Chen, R. Modeling the direction and magnitude of angular effects in nighttime light remote sensing. Remote Sens. Environ. 2022, 269, 112834. [Google Scholar] [CrossRef]
- Elvidge, C.; Zhizhin, M.; Baugh, K.; Hsu, F.-C. Automatic boat identification system for VIIRS low light imaging data. Remote Sens. 2015, 7, 3020–3036. [Google Scholar] [CrossRef]
- Kim, E.; Kim, S.-W.; Jung, H.C.; Ryu, J.-H. Moon phase based threshold determination for VIIRS boat detection. Korean J. Remote Sens. 2021, 37, 69–84. [Google Scholar] [CrossRef]
- Xue, C.; Gao, C.; Hu, J.; Qiu, S.; Wang, Q. Automatic boat detection based on diffusion and radiation characterization of boat lights during night for VIIRS DNB imaging data. Opt. Express. 2022, 30, 13024–13038. [Google Scholar] [CrossRef] [PubMed]
- Shao, J.; Yang, Q.; Luo, C.; Li, R.; Zhou, Y.; Zhang, F. Vessel detection from nighttime remote sensing imagery based on deep learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 12536–12544. [Google Scholar] [CrossRef]
- Tsuda, M.E.; Miller, N.A.; Saito, R.; Park, J.; Oozeki, Y. Automated VIIRS boat detection based on machine learning and its application to monitoring fisheries in the East China Sea. Remote Sens. 2023, 15, 2911. [Google Scholar] [CrossRef]
- Li, B.; Xiao, C.; Wang, L.; Wang, Y.; Lin, Z.; Li, M.; An, W.; Guo, Y. Dense nested attention network for infrared small target detection. IEEE Trans. Image Process. 2022, 32, 1745–1758. [Google Scholar] [CrossRef]
- Li, Y.; Li, S.; Du, H.; Chen, L.; Zhang, D.; Li, Y. YOLO-ACN: Focusing on small target and occluded object detection. IEEE Access 2020, 8, 227288–227303. [Google Scholar] [CrossRef]
- Song, Z.; Yang, J.; Zhang, D.; Wang, S.; Li, Z. Semi-supervised dim and small infrared ship detection network based on haar wavelet. IEEE Access 2021, 9, 29686–29695. [Google Scholar] [CrossRef]
- Nie, Y.; Tao, Y.; Liu, W.; Li, J.; Guo, B. Deep learning method for ship detection in nighttime sensing images. Sens. Mater. 2022, 34, 4521–4538. [Google Scholar] [CrossRef]
- Dai, Z.; Cai, B.; Lin, Y.; Chen, J. UP-DETR: Unsupervised Pre-Training for Object Detection with Transformers. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1601–1610. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.S.; et al. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 6877–6886. [Google Scholar]
- Yoo, S.; Park, J. Why is the southwest the most productive region of the East Sea/Sea of Japan? J. Mar. Syst. 2009, 78, 301–315. [Google Scholar] [CrossRef]
- Zhao, X.; Li, D.; Li, X.; Zhao, L.; Wu, C. Spatial and seasonal patterns of night-time lights in global ocean derived from VIIRS DNB images. Int. J. Remote Sens. 2018, 39, 8151–8181. [Google Scholar] [CrossRef]
- Apriansyah; Atmadipoera, A.S.; Nugroho, D.; Jaya, I.; Akhir, M.F. Simulated seasonal oceanographic changes and their implication for the small pelagic fisheries in the Java Sea, Indonesia. Mar. Environ. Res. 2023, 188, 106012. [Google Scholar] [CrossRef] [PubMed]
- VIIRS/DNB SDR Product. Available online: https://www.avl.class.noaa.gov/saa/products/ (accessed on 12 April 2023).
- GSHHG—A Global Self-Consistent, Hierarchical, High-Resolution Geography Database (Online). Available online: http://www.ngdc.noaa.gov/mgg/shorelines/gshhs.html (accessed on 8 April 2023).
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Sarangi, R.K.; Nagendra Jaiganesh, S.N. VIIRS Boat Detection (VBD) Product-Based Night Time Fishing Vessels Observation in the Arabian Sea and Bay of Bengal Sub-Regions. Geocarto Int. 2022, 37, 3504–3519. [Google Scholar] [CrossRef]
- Motomura, K.; Nagao, T. Fishing Activity Prediction from Satellite Boat Detection Data. In Proceedings of the 2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Toronto, ON, Canada, 11–14 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 2870–2875. [Google Scholar]
- Meng, Y.; Zhou, J.; Wang, Z.; Tang, W.; Ma, J.; Zhang, T.; Long, Z. Retrieval of nighttime aerosol optical depth by simultaneous consideration of artificial and natural light sources. Sci. Total Environ. 2023, 896, 166354. [Google Scholar] [CrossRef]
- VIIRS Boat Detection (VBD) Products (Online). Available online: http://payneinstitute.mines.edu/eog/viirs-vessel-detection-vbd/ (accessed on 18 April 2023).
- Balduzzi, M.; Pasta, A.; Wilhoit, K. A security evaluation of AIS automated identification system. In Proceedings of the 30th Annual Computer Security Applications Conference, New Orleans, LA, USA, 8–12 December 2014; ACM: New Orleans, LA, USA, 2014; pp. 436–445. [Google Scholar] [CrossRef]
- Lee, E.; Mokashi, A.J.; Moon, S.Y.; Kim, G. The maturity of automatic identification systems (AIS) and its implications for innovation. J. Mar. Sci. Eng. 2019, 7, 287. [Google Scholar] [CrossRef]
- Automatic Identification System (AIS) (Online). Available online: https://globalfishingwatch.org/map (accessed on 18 April 2023).
- Sánchez, R.J.; Perrotti, D.E. Looking into the future: Big full containerships and their arrival to South American ports. Marit. Policy Manag. 2012, 39, 571–588. [Google Scholar] [CrossRef]
- Chua, L.O.; Roska, T. The CNN paradigm. IEEE Trans. Circuits Syst. I 1993, 40, 147–156. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-Cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Gallego, A.-J.; Pertusa, A.; Gil, P. Automatic ship classification from optical aerial images with convolutional neural networks. Remote Sens. 2018, 10, 511. [Google Scholar] [CrossRef]
- Zou, Z.; Shi, Z. Random Access Memories: A new paradigm for target detection in high resolution aerial remote sensing images. IEEE Trans. Image Process. 2018, 27, 1100–1111. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2016, arXiv:1409.0473. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Sudre, C.H.; Li, W.; Vercauteren, T.; Ourselin, S.; Jorge Cardoso, M. Generalised dice overlap as a deep learning loss function for highly unbalanced segmentations. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2017; Volume 10553, pp. 240–248. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Guo, G.; Fan, W.; Xue, J.; Zhang, S.; Zhang, H.; Tang, F.; Cheng, T. Identification for Operating Pelagic Light-Fishing Vessels Based on NPP/VIIRS Low Light Imaging Data. Trans. Chin. Soc. Agric. Eng. 2017, 33, 245–251. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Song, L.; Zhao, S.; Zhao, D.; Wu, Y.; You, G.; Kong, Z.; Xi, X.; Yu, Z. Nighttime fishing vessel observation in Bohai Sea based on VIIRS fishing vessel detection product (VBD). Fish Res. 2023, 258, 106539. [Google Scholar] [CrossRef]
- Yamaguchi, T.; Asanuma, I.; Park, J.G.; Mackin, K.J.; Mittleman, J. Estimation of vessel traffic density from suomi NPP VIIRS day/night band. In Proceedings of the OCEANS 2016 MTS/IEEE Monterey, Monterey, CA, USA, 19–23 September 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Zhu, X.; Tan, X.; Liao, M.; Liu, T.; Su, M.; Zhao, S.; Xu, Y.N.; Liu, X. Assessment of a new fine-resolution nighttime light imagery from the Yangwang-1 (“Look up 1”) satellite. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Zhao, Z.; Qiu, S.; Chen, F.; Chen, Y.; Qian, Y.; Cui, H.; Zhang, Y.; Khoramshahi, E.; Qiu, Y. Vessel detection with SDGSAT-1 nighttime light images. Remote Sens. 2023, 15, 4354. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | IOU (×10−2) | Pd (×10−2) | Fa (×10−6) | MPD (px) |
|---|---|---|---|---|
| Enhanced DNA-net | 87.81 | 96.72 | 5.42 | 0.36 |
| DNA-net (sDNB) | 86.37 | 92.06 | 5.11 | 1.56 |
| DNA-net (SMI) | 83.64 | 93.52 | 7.64 | 0.97 |
| DNA-net (SHI) | 80.84 | 89.33 | 9.28 | 2.38 |
| Method | IOU (×10−2) | Pd (×10−2) | Fa (×10−6) | MPD (px) |
|---|---|---|---|---|
| Enhanced DNA-net w/o CSAM | 86.09 | 94.49 | 7.04 | 0.68 |
| Enhanced DNA-net w/o CAM | 86.78 | 94.75 | 6.78 | 0.50 |
| Enhanced DNA-net w/o SAM | 86.94 | 95.07 | 6.05 | 0.43 |
| Module | IOU (×10−2) | Pd (×10−2) | Fa (×10−6) | MPD (px) |
|---|---|---|---|---|
| Enhanced DNA-net | 87.81 | 96.72 | 5.42 | 0.36 |
| w/o DNIM (U-Net) | 73.25 | 89.64 | 9.57 | 2.05 |
| Module | Identification Numbers | Extraction Number of VBD-AIS | Identification Accuracy |
|---|---|---|---|
| VBD (QF = 1) | 3081 | 3263 | 0.94 |
| Enhanced DNA-net | 3114 | 3263 | 0.95 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zuo, G.; Zhou, J.; Meng, Y.; Zhang, T.; Long, Z. Night-Time Vessel Detection Based on Enhanced Dense Nested Attention Network. Remote Sens. 2024, 16, 1038. https://doi.org/10.3390/rs16061038
Zuo G, Zhou J, Meng Y, Zhang T, Long Z. Night-Time Vessel Detection Based on Enhanced Dense Nested Attention Network. Remote Sensing. 2024; 16(6):1038. https://doi.org/10.3390/rs16061038
Chicago/Turabian StyleZuo, Gao, Ji Zhou, Yizhen Meng, Tao Zhang, and Zhiyong Long. 2024. "Night-Time Vessel Detection Based on Enhanced Dense Nested Attention Network" Remote Sensing 16, no. 6: 1038. https://doi.org/10.3390/rs16061038