1. Introduction
In recent years, the central role of hyperspectral imaging in remote sensing technology has sparked widespread research interest [
1]. The accuracy of object recognition is directly contingent on the processing and analysis of HSI data. Within this realm, hyperspectral image (HSI) classification, recognized as a crucial step, necessitates pixel-wise labeling of object categories [
2,
3,
4,
5,
6,
7]. Due to the high-dimensional and nonlinear characteristics of HSI data [
8,
9,
10,
11], the primary focus in HSI classification becomes feature extraction [
12]. Deep learning, renowned for itss outstanding adaptive feature extraction ability, enables data-driven HSI classification methods to extract inherent features crucial for automatic recognition [
13]. With the continuous optimization of network architectures and learning patterns, there has been a notable enhancement in the classification accuracy of models when applied to standard HSI datasets.
However, HSI classification requires a substantial amount of labeled data, posing a significant challenge. To address this issue, classification methods based on few-shot learning (FSL) have been proposed and applied to HSI classification based on machine learning and deep learning. Yet, the closed-set training models presume that the training data encompass all categories that may arise in the future. In reality, deep learning models may encounter new categories that were not encountered during training. Consequently, to address these challenges, few-shot open-set recognition (FSOSR) [
14,
15,
16,
17,
18] methods for HSI classification are garnering increasing attention.
When comparing traditional hyperspectral image (HSI) open-set recognition (OSR) [
19,
20,
21,
22,
23] with few-shot open-set recognition (FSOSR) for HSI [
24,
25,
26,
27], a significant challenge arises in addressing the coexistence of spectrally fine-grained known categories and anomalies. Current FSOSR methods, which employ reconstruction-based strategies for open-set HSI classification, exhibit limitations in practical applications. Specifically, generative models underperform in capturing information about unknown categories and fail to effectively utilize known category information to model the space of unknown categories, leading to instability in addressing open-set challenges. Additionally, the process of threshold determination is complex and lacks flexibility, making it difficult to set an efficient and learnable threshold, further limiting the adaptability of these methods. On the other hand, existing generative adversarial networks (GANs) primarily adopt a fully supervised approach for generating within-distribution data. However, in few-shot scenarios, estimating data density from limited samples presents significant challenges, impeding the optimal training of these methods. More critically, these methods continue to use closed-set models, rendering them ineffective in generating data for open spaces. These limitations undoubtedly weaken the performance of HSI in open-set classification.
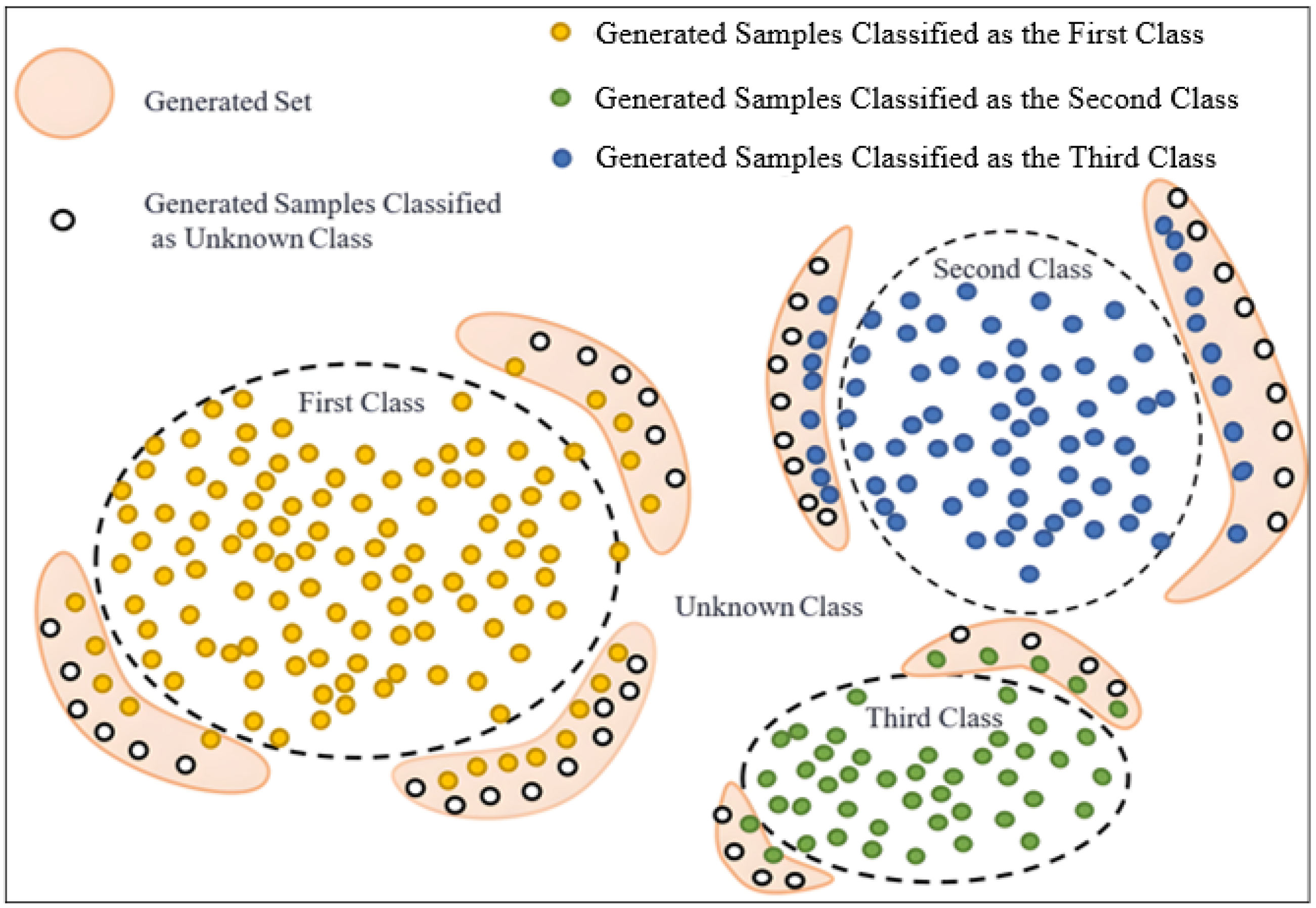
To tackle the aforementioned challenges, this research proposes an open-set HSI classification algorithm based on reciprocal point learning (RPL) and data wandering (DW) (RPLDW). Firstly, a K-class classifier suitable for closed-set problems is trained, with its internal encoder used for extracting image classification features to estimate the feature distribution of known classes. Subsequently, these feature distributions are utilized to optimize the classifier and fine-tune its training. Next, synthetic samples near the decision boundary are generated using a GAN with sample density constraints to solve the few-shot problem, as illustrated in
Figure 1.
Concurrently, a framework of RPL is introduced to classify the open-set HSI. The risk of open space is reduced by simulating the out-of-category space to increase the distance between known and unknown categories. In addition, a dynamic threshold method based on DW is devised to build a separate space for each category, thereby enhancing the model’s open-set performance. Employing a DW method, the drifting synthetic samples are categorized into known and unknown categories and inputted together with known samples into the classifier for a new round of training. At this stage, both the closed-set classifier and also a (K+1) class classifier suitable for open-set scenarios are trained in this research, sharing parameters of the early network layers. This approach enhances the data reliability and richness by including generated synthetic samples, ultimately improving the performance of the classification algorithm. The primary contributions of this research can be summarized as follows:
- (1)
A method that generates boundaries is proposed based on sample density constraints to calculate sample density. Leveraging information entropy, this approach confines generated samples outside the edge regions of known classes, ensuring proximity to the known classes. Consequently, the classifier can more accurately demarcate the range of known classes.
- (2)
The RPL method is adopted to address the open-set HSI classification challenge. It distinguishes the space of unknown categories by constructing inverse prototypes and enlarging the distance between known and unknown categories, thereby reducing the risk of open space. Meanwhile, it reinforces the boundaries of known categories and utilizes dynamic thresholds to remove unknown categories, avoiding manual determination of thresholds and enhancing the robustness of the algorithm.
- (3)
A novel sample distribution analysis method is built to screen out edge samples based on DW, enhancing the sample boundaries and improving the classification accuracy.
- (4)
Extensive experiments on three benchmark HSIs demonstrate the outstanding performance of the proposed RPLDW in FSOSR tasks, effectively fulfilling the open-set few-shot recognition. Therefore, in the real-world scenario of open-set HSI, RPLDW proves to be more robust and effective in minimizing open risks.
3. Methodology
3.1. Subsection
Herein, a dataset containing K-known classes is given (where is a set of known classes, with samples in each, and refers to a set with the same one-hot vectors, representing labels corresponding to the set ). Under this given condition, it should correctly classify the K-known classes while recognizing and classifying new classes as the (K + 1) class.
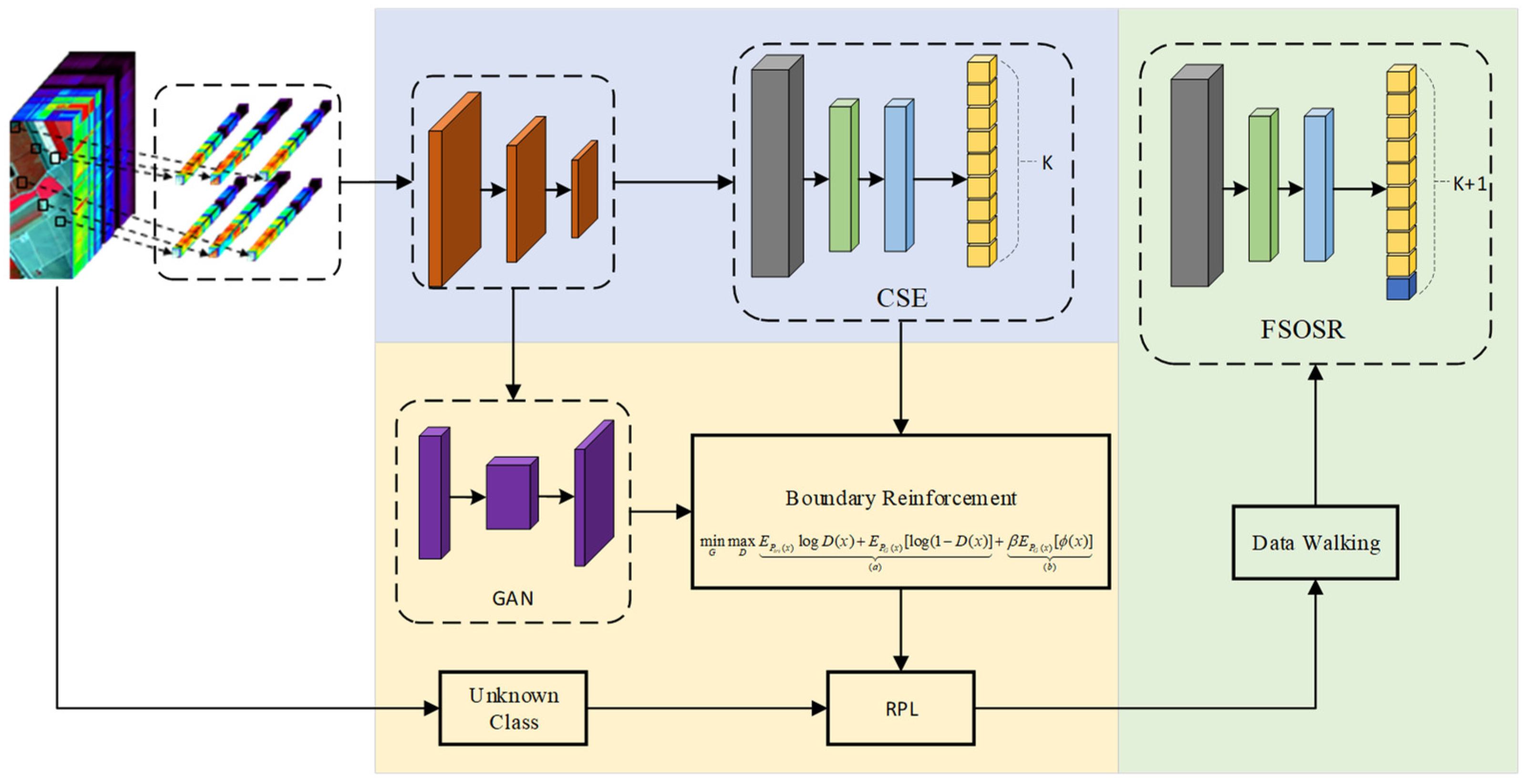
Firstly, a K-class classifier suitable for a closed set is trained in this research, with its encoder being employed to extract image classification features and estimate the feature distribution of all known classes. Meanwhile, the training of the classifier is adjusted based on it. Subsequently, a GAN constrained by sample density is employed to generate synthetic samples near the decision boundaries. Leveraging RPL, this research models the unknown class space to augment the feature distance between the known data after boundary expansion and the unknown data in the open-set space. Then, employing the data walk method, the unclassified synthetic samples are categorized into known and unknown classes and sent to the classifier with the known samples for a new round of training. At this stage, the closed-set classifier and, concurrently, a (K + 1) class classifier suitable for the open set are trained. The training of these two classifiers shares the parameters of the previous layers of the network. The overall network architecture is illustrated in
Figure 2.
The multitask network employed in this research requires an input of dimensions 9 × 9 × Channel. The first part of the network is an encoder/feature extractor equipped with two residual units and a global average pooling layer. After extracting latent features, a fully connected layer with a softmax function is set, serving as a classifier to output probabilities to the known classes. The reconstruction task of this research involves gradually increasing the spatial dimension of the latent features through a deconvolution layer. The output of the reconstruction task is a 9 × 9 × Channel instance, w intended to closely resemble the input data by minimizing the loss. Extreme value theory (EVT) is adopted to model the reconstruction loss, thus separating known and unknown classes.
The overall algorithm is outlined in Algorithm 1 below.
refers to the synthetics generated by a GAN constrained by sample density, which is composed of
and
based on DW:
is categorized as known classes as edge samples to reinforce the sample boundaries, thus improving the performance of the closed-set classification while
simulates the unknown classes and serves as the
class to train the open-set classifier
.
| Algorithm 1 Open-set recognition algorithm for generating decision boundaries based on sample density |
| Input: | |
| | : Dataset of known classes |
| | : Partition Threshold |
| | : Density Representative Parameter |
| Output: | |
| | : Open-Set Classifier |
| 1: | Calculate the sample distribution to establish an information entropy field |
| 2: | GAN generates decision boundary samples based on sample information entropy constraints. |
| 3: | translates to “Train closed set classifier |
| 4: | RPL |
| 5: | FOR
DO |
| 6: | | Calculate the score of the newly generated fake samples. |
| 7: | | Divide into and |
| 8: | END FOR |
| 9: | On the basis of , train the open-set classifier with newly generated samples. |
3.2. Generation of Known Class Sample Boundaries Based on Sample Density
This first step is to train a closed-set classifier through metric learning. Subsequently, the values in the pre-logit layer of the classifier are taken as sample points, and all sample points are collected as the sample space to calculate the sample density at any position in the sample feature space based on sample features. Next, the distribution of known classes is analyzed, and the objective function of GAN is constrained to facilitate the generation of samples within the boundary area of known classes and their periphery. In this way, it strengthens the boundary of known samples while increasing the reality and richness of simulated unknown class samples. This section details how to constrain GAN to generate sample boundaries, which is realized by calculating the sample density and training the classifier and GAN.
3.2.1. Training of the Closed-Set Classifier
In this research, a closed-set classifier is trained firstly through metric learning, with the following loss function:
where
This facilitates the classifier in accurate classification while gathering samples with the same label as much as possible, resulting in distinct classes in the sample space as separate clusters. Following this, the parameters of the feature extractor in the classifier are frozen, the distance between each sample point and the center sample is computed, and the classifier is trained.
where
is a balancing parameter. Sample points that are close to the center sample have a high-density score. The classifier’s score and the sample density score are bundled together. When the sample is at the sample boundary or floating outside the cluster, the sample density is low, the classifier score is low, and the corresponding predicted label information entropy value is large, increasing the difficulty of being classified into a known class. With such a classifier, training a GAN to generate boundary samples becomes feasible, further refining the constraints on the classifier’s ability to recognize the boundaries of known class samples.
3.2.2. Calculation of Sample Density
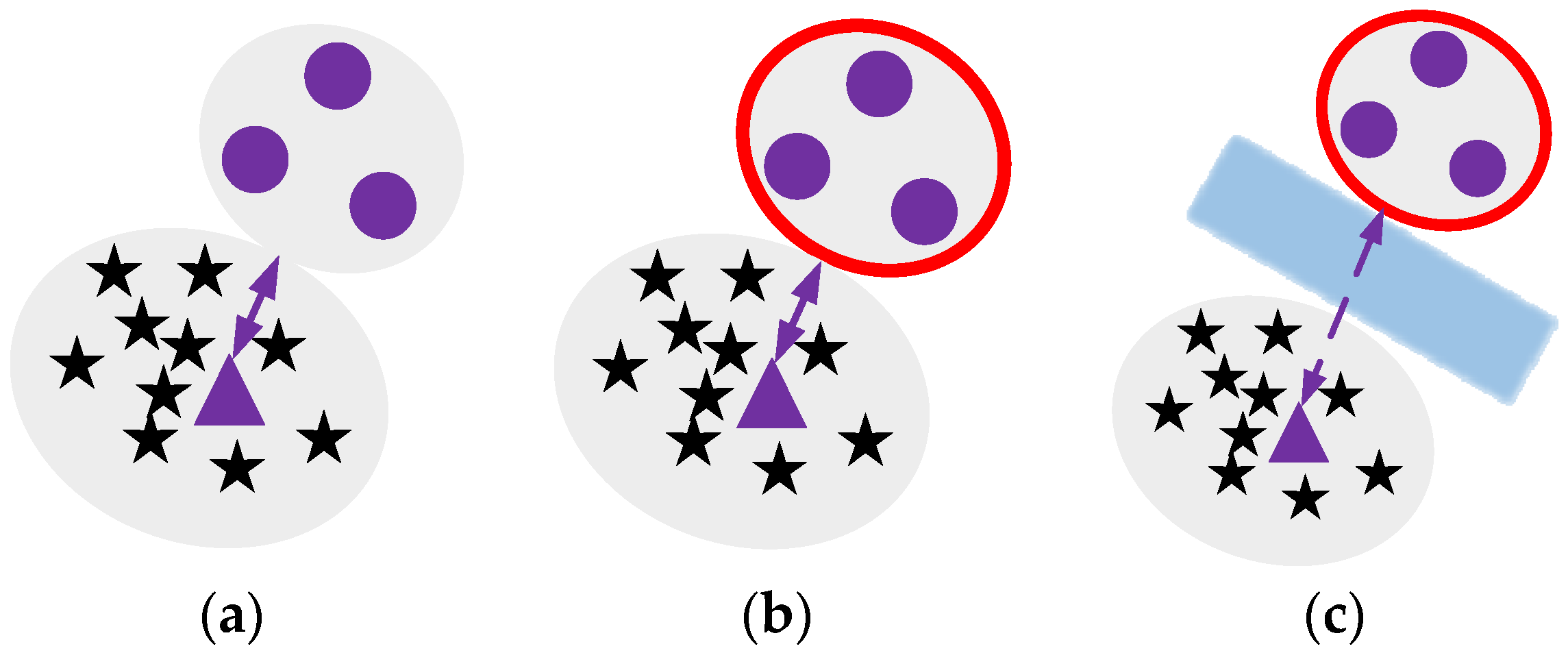
There are two challenges when calculating the sample density. Firstly, due to the different aggregation degrees in each cluster, some clusters exhibit a relatively dense distribution of central feature points, while others have spare edges. Consequently, the density estimation of different regions needs to consider the relative positions of distinct clusters. Secondly, a small cluster of sample points is found to be gathered, forming a pseudo-sample center, as described in
Figure 3.
The density peak clustering algorithm (DPC) is employed to calculate the maximum diameter
of the entire sample space.
points are selected on average contained in each neighborhood, and
serves as the neighborhood radius of a sample point
. Meanwhile, the number of sample points neighboring the point is counted as the local density
of the point. Finally, the entropy of the region is calculated using the following equation:
where
Each data point
can be sorted in ascending order, and the minimum distance
between this sample point and other points with higher density is calculated. The density peak score for this point is calculated as:
Afterward, the top K points with the highest scores are selected as the center samples of the known class. The distance
between each sample point and the center sample of its class is calculated. Meanwhile, the maximum radius
in the
i-th class is selected and
refers to the neighborhood radius of each sample point. After that, the number of sample points
contained in the neighborhood of the
j-th sample is calculated. The aggregation score of the neighborhood where each point is located is calculated as follows:
Subsequently, the distribution of the known class is estimated through Gaussian kernel density. All sample points are assigned a Gaussian function
with a mean of itself and a variance of
. The sum of the Gaussian functions of all sample points forms the energy field, which can be expressed as follows:
In the above equation, signifies the number of all sample points in the sample space, based on which the density representation of each position within the sample space can be acquired.
3.2.3. Training of GAN
GAN, typically used to generate pixel images that are as similar as possible to the original images, primarily encompasses discriminators (
D) and generators (
G). The generator maps the latent variables
z to the output space through the prior distribution
and outputs
. The discriminator
represents the probability that the sample comes from the real target distribution. Through the showdown between the generator and the discriminator, the distribution
of the samples generated by the generator gradually approaches the target distribution
. Its objective function is described as follows:
This research aims to produce samples on the periphery of the known classes for the generator. For this purpose, the original GAN objective function is modified accordingly, as given in Equation (10) below.
In the above expression, is the balance parameter, which means that the trained classifier becomes a class one at . This objective function can be delineated into two components. The first term (a) corresponds to the loss of the original GAN, making the samples generated by the generator as similar as possible to the real samples. The second term (b) calculates the sample density. Throughout the training, the generator and the discriminator undergo multiple training iterations under the constraint of sample density. This iterative process eventually guides the generator in producing samples on the low-density boundary and discrete samples.
Equation (10) emphasizes generating authentic images to augment the closed-set training data. To ensure that the generated and the real images are ultimately projected into the same feature space, the conditional generative network should be trained on the basis of the well-trained autoencoder. However, this research deviates from relying on autoencoder training and instead opts to generate synthetic samples by referencing the latent feature layer of the known class. The
chosen refers to the feature value corresponding to the pre-logit layer of the closed-set classifier. The final equation is as follows:
This approach enables the generator to produce synthetic samples in areas with low sample density, effectively balancing the distribution of internal samples within the known classes and consequently enhancing the accuracy of the classifier. Additionally, generating samples in the low-density regions outside the known classes can train the classifier to recognize unknown class samples by categorizing them as unknown classes. This process provides negative feedback, allowing the model to perceive the boundary area of the known classes.
3.3. Reciprocal Point Learning
Reciprocal points [
30] represent the inverse prototypes of each known category, and their utilization enables the constraints of the space outside the category while maintaining the accuracy of the known category. During the training, RPL [
49], based on reciprocal points, pushes all known categories towards the edge of the space. As a result, this strategy ensures that the unknown category and reciprocal points collectively define the space outside the category, minimizing the overlap between known and unknown distributions. Consequently, this enhances the distinguishability of the unknown category. In this research, RPL is adopted to model the space of unknown categories to classify the open-set HSI.
Specifically, given there are n labeled samples and N known categories in the training dataset , is the corresponding label of . For trail data , the labels of belong to for closed-set HSI classification and to for open-set HSI classification, where U denotes the number of unknown categories in a realistic HSI scenario. Thus, the potential unknown data can be denoted as . For each known category , is the embedding space in the space , and the corresponding open space can be denoted as .
Therefore, as an inverse prototype of the known category
, the reciprocal point
can be regarded as a potential representation of the sub-dataset
[
14]. As demonstrated in
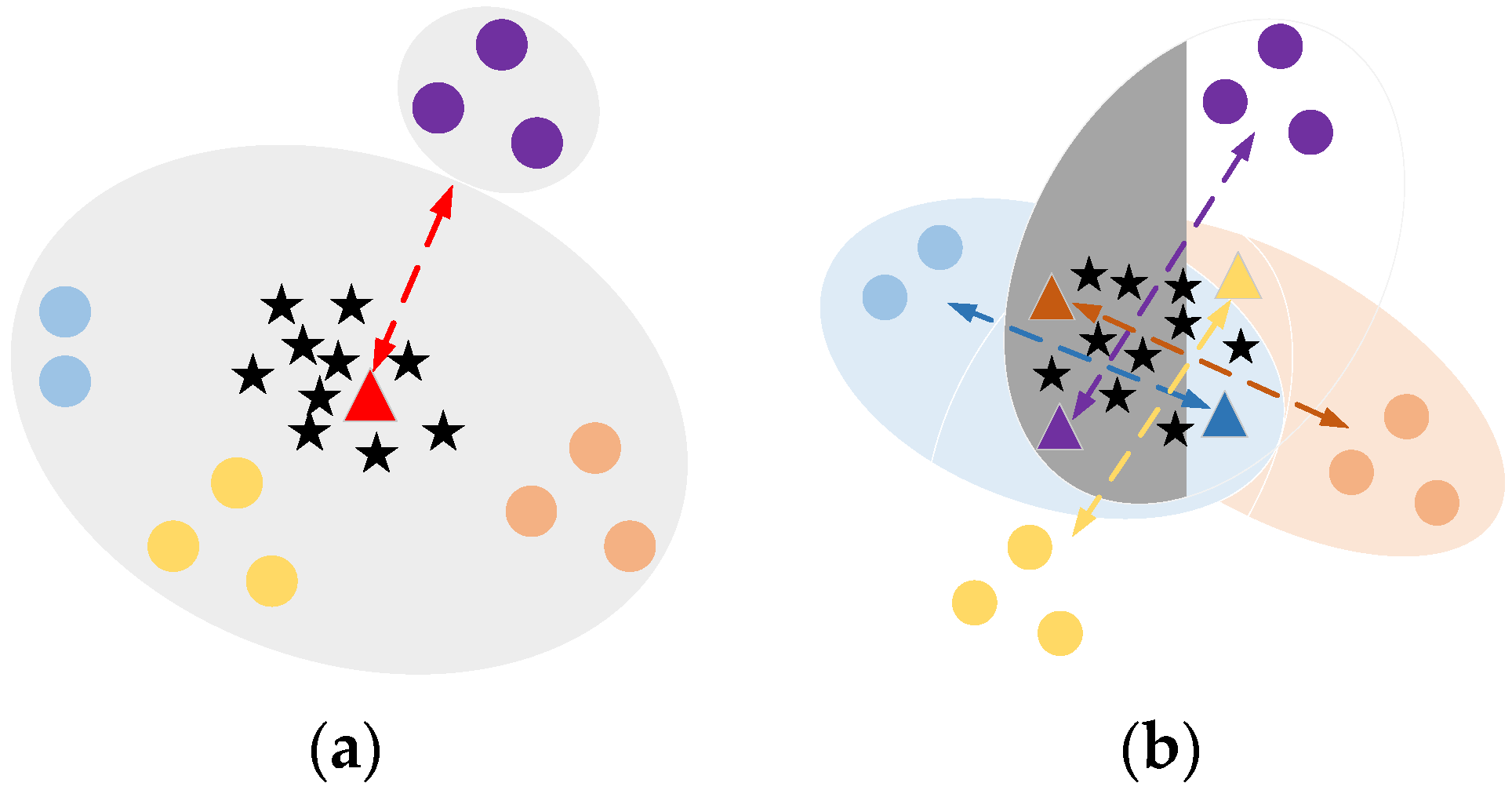
Figure 4a, the reciprocal point
should be closer to the empty space
and far away from
, as follows.
where
denotes a set of distances such that the known category
is maximally distant from
.
Therefore, a pivotal objective of RPL is to expand the distance between known categories and their corresponding reciprocal points. To achieve this, the cosine distance
is employed to compute the spatial position and angular orientation between instance
and the corresponding reciprocal point
.
where
denotes a feature representation network with a learnable parameter set
, and
refers to a network feature of sample
.
After describing the distance metric, it is noteworthy that as the distance
increases, the probability of labeling
is calculated as the category
. The category probability can be calculated using the softmax function, considering the nature of the reciprocal points and the instance-related weights in the expression below.
Therefore, the supervised loss function can be defined as the negative logistic loss of the labels:
The learnable parameter set of the feature representation network
is updated by minimizing
. Therefore,
can classify the known categories through supervised learning with multi-class samples and their corresponding true labels. More importantly, as illustrated in
Figure 4b, all known categories are pushed to the periphery of the space by their respective reciprocal points throughout the training. In addition, reciprocal points in the space outside the category are also pushed into the known space.
3.4. Sample Distribution Using Data Wandering
Since the potential unknown categories are in the space outside the categories, the risk of encountering open space persists. In response, a learnable dynamic threshold strategy is further proposed in this research. By constructing a separation space, the open-set HSI classification approach is optimized to lower the risk of the open space and facilitate the recognition of unknown categories. Different from the past approaches that relied on multi-class classifier prediction results for in-class splitting, DW is introduced for sample distribution analysis and further constrains the open space, as explicated in
Figure 5.
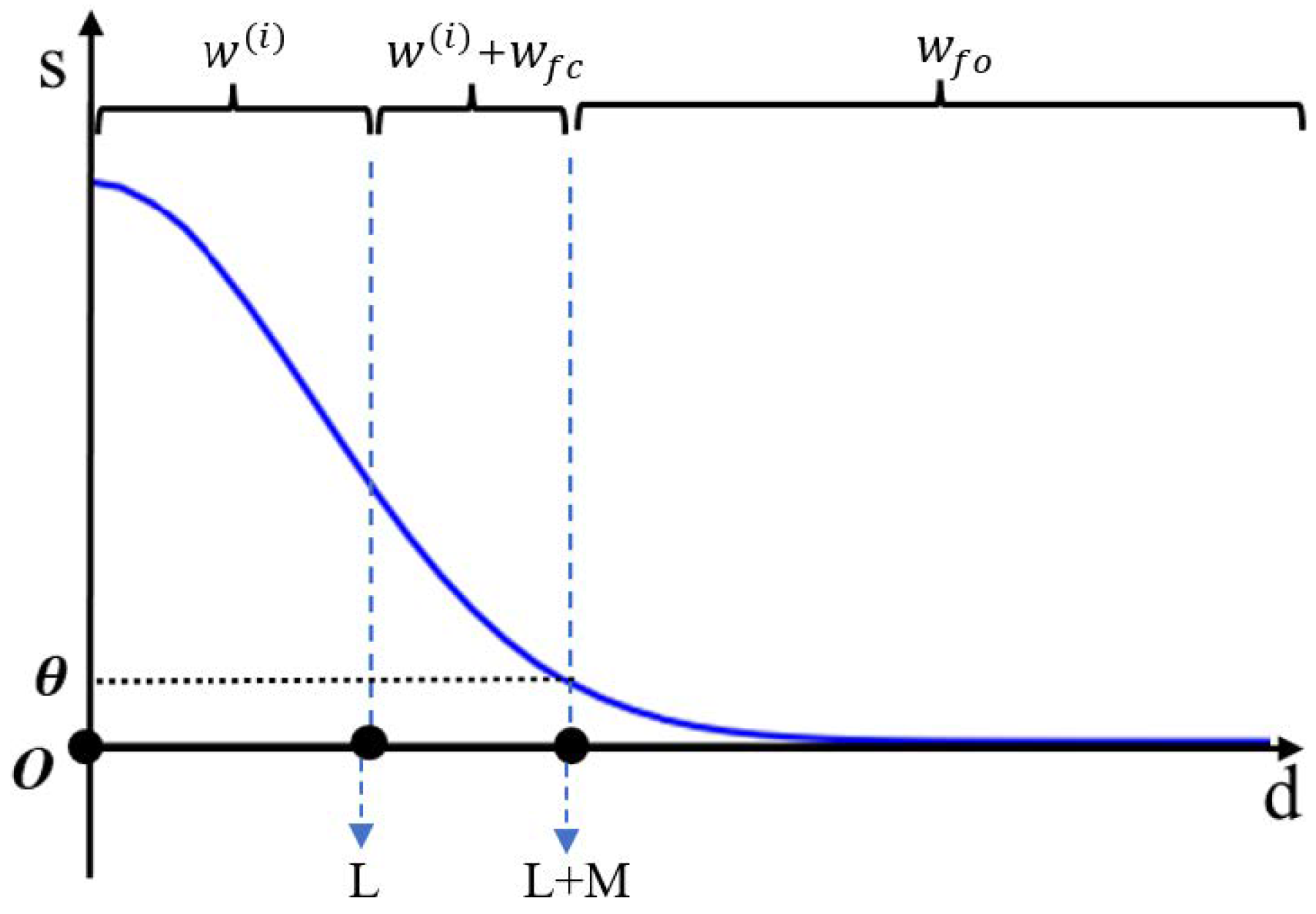
By constructing an information energy field and setting a threshold
, the sample space is divided into within-class and outside-class after incorporating the synthetic samples. The basic concept is depicted in
Figure 6.
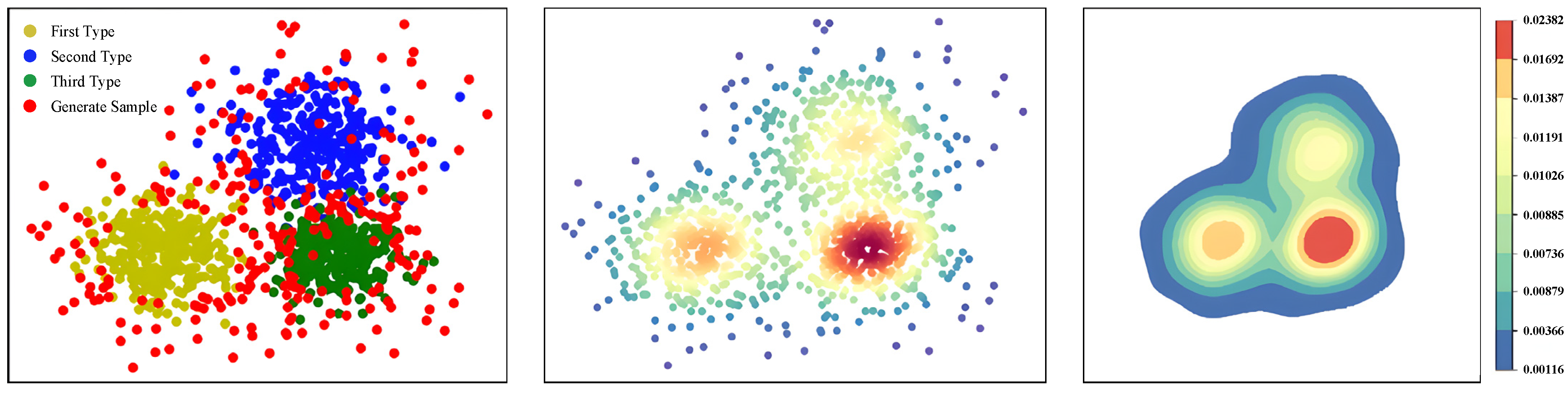
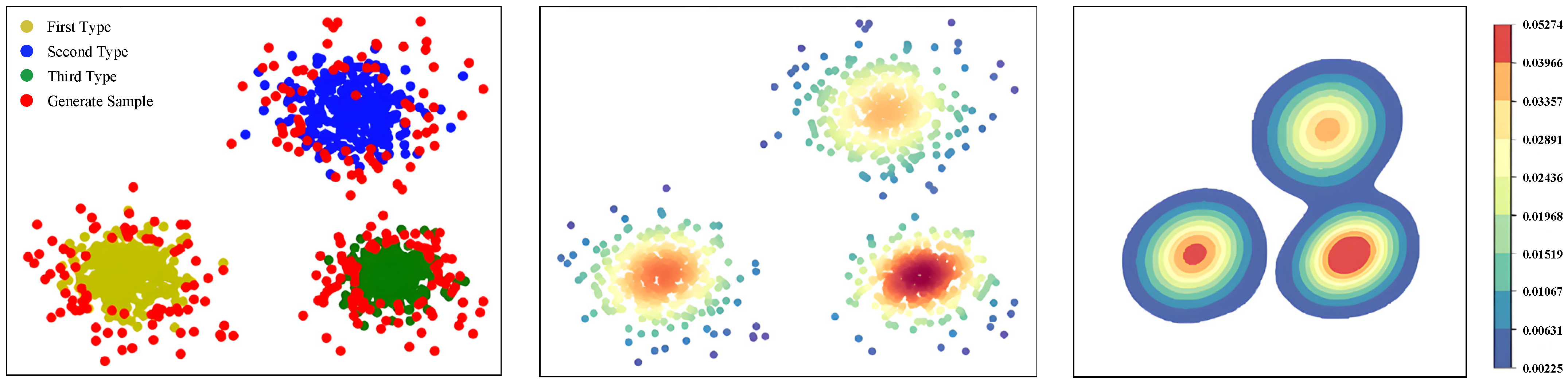
In the figure above, the horizontal axis represents the distance from the sample to the relative sample center, while the vertical axis shows the magnitude of the energy value. The interval refers to the central sample of the known class, the interval contains the known class edge samples and some generated samples (), and the interval is composed of generated samples only. Existing methods can be employed to directly classify the interval as an unknown class, so samples from the known class that are close to the edge are classified as unknown. In this research, some generated samples from the known class are selected to enhance the accuracy of recognition.
Although RPL can classify synthetic samples in the open-set space into unknown class and known class . Due to the existence of fuzzy sample boundaries, the boundary samples are categorized as comprehensively as possible, and a data walking method is adopted to iterate. Each sample point is moved in the direction of high energy at a specific step length. Following this, a new data distribution is formed, and the energy field is recalculated. These steps are iteratively repeated several times. After multiple iterations, based on the data redistribution in the open-set space, synthetic samples within the known range are identified as boundary samples through RPL, while the remaining samples are considered new classes.
The data wandering algorithm, as an optimization technique based on energy fields, demonstrates its unique value and efficiency. According to the hypothesis proposed by the decision algorithm, clustering clusters should be centered around high-density data, with low-density data surrounding the high-density ones. In the information energy field, a cluster’s region should exhibit a distribution state where the central energy field strength is high, and the edge energy field strength is low. This paper utilizes to construct the information energy field. After forming the sample information energy field values, it is assumed that each sample point can move in the numerical space. By comparing the energy field strength of the sample point with its surrounding eight neighborhoods, the sample point is made to wander toward the direction of higher field strength. After several wanderings, all sample points will move towards regions of higher data energy at a certain step length, forming the final data distribution shape, and the final clustering results are obtained by dividing the regions. Calculating the average energy of samples and setting a threshold can be defined: if the average energy of a clustering cluster is higher than 1.5 times the total average entropy, it is defined as a high-energy cluster; otherwise, it is a low-energy cluster. After the data wandering, due to the energy distribution deviation, i.e., the average energy of the high-energy cluster is far higher than that of the low-energy cluster, new samples in the process of data wandering will tend to move towards high-energy fields. This will result in the following: (1) Data wandering can effectively solve the clustering affiliation of discrete points, making it easier to form clustering clusters after data wandering. (2) In the process of data wandering, high-energy clustering clusters will influence low-energy clustering clusters, causing the clustering results of low-energy clusters to become more dispersed.
Therefore, the RPL constraints for the separation space based on DW can be represented as follows:
4. Experimental Results and Corresponding Analysis
4.1. Dataset
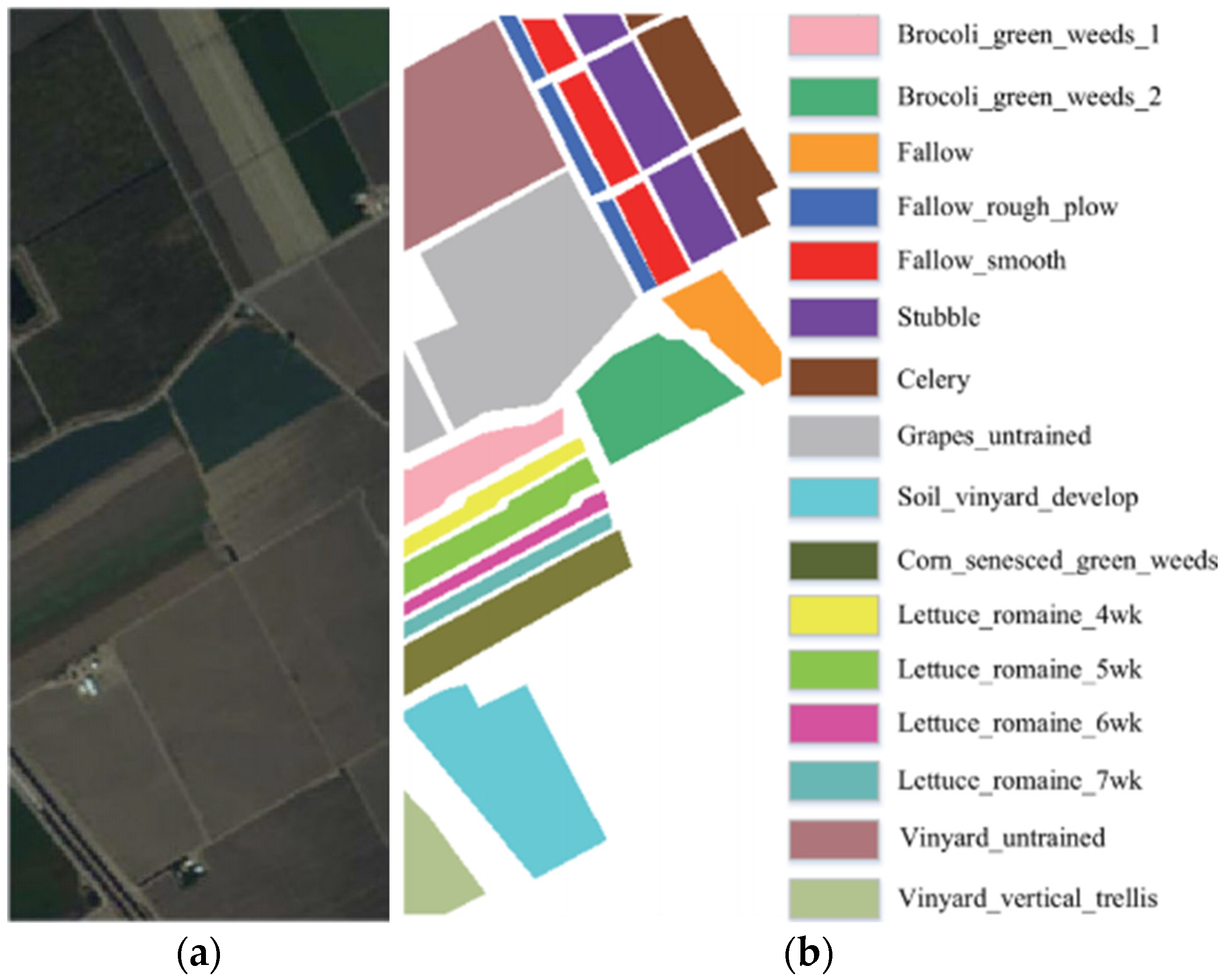
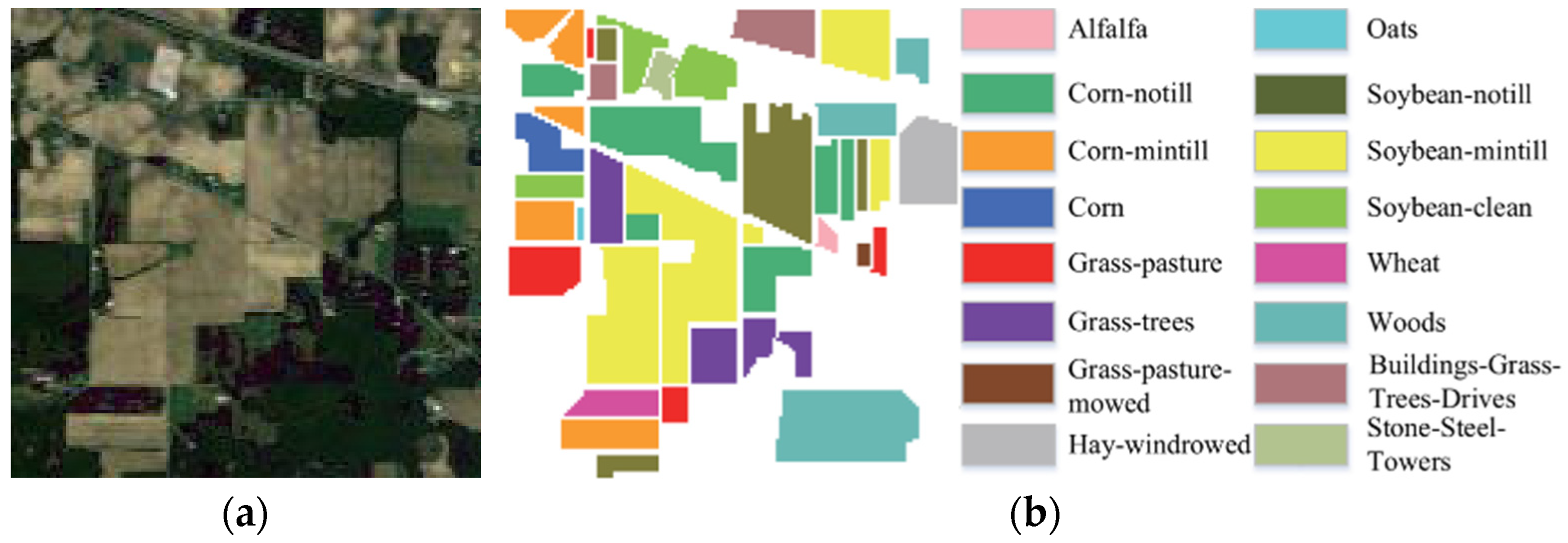
To carry out the open-set HSI multiclassification experiments proposed and to thoroughly validate our methodology, three HSI datasets, Pavia University (PU), Salinas (SA), and Indian Pines (IP) are selected in this research.
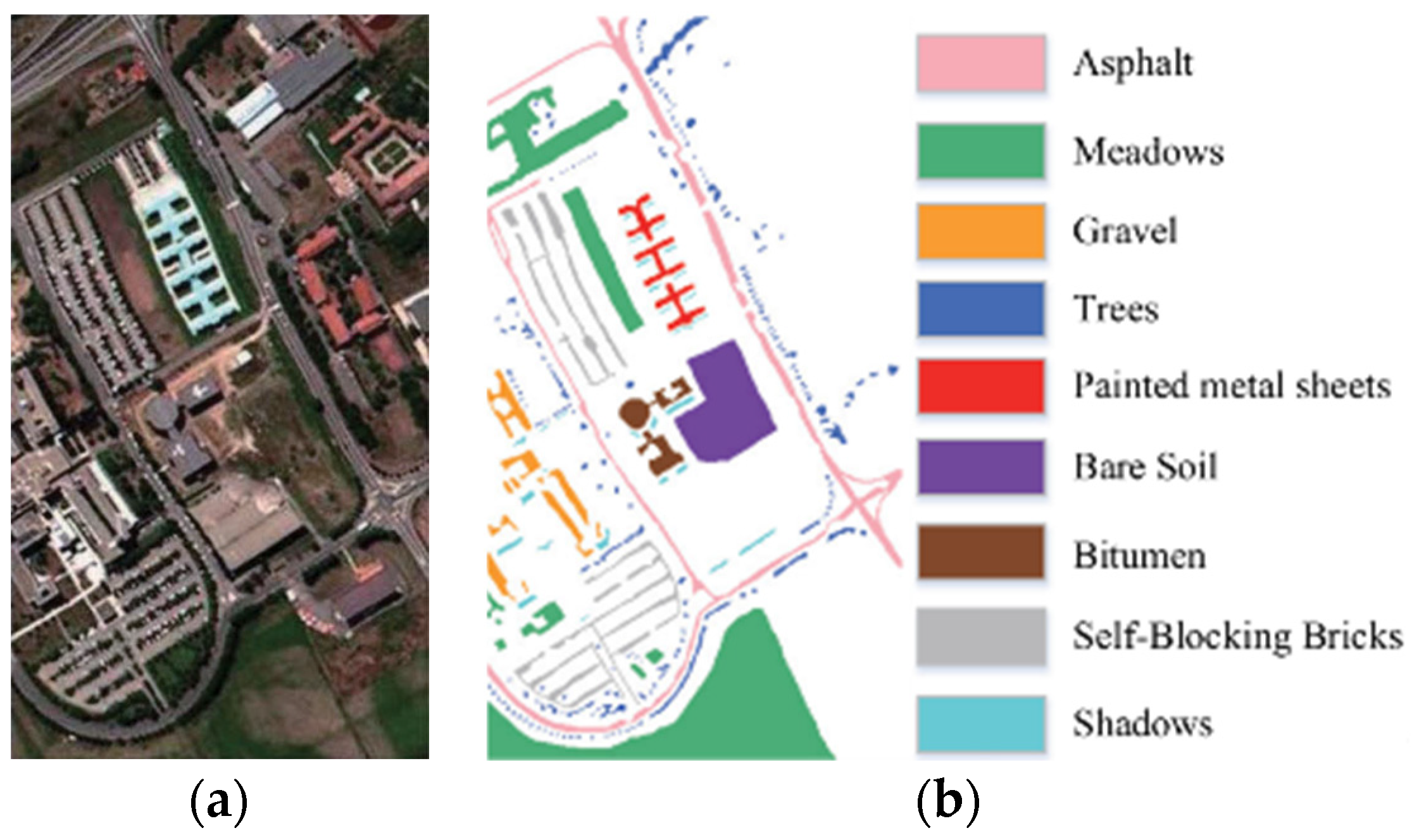
The PU dataset, captured by the reflective optical system imaging spectrometer (ROSIS) near the university, exhibits spatial dimensions of 610 × 340 with a spatial resolution of 1.3 m. It consists of 115 channels covering a wavelength range of 0.43~0.86 μm. Before classification experiments, 12 bands affected by noise and water absorption are eliminated first. Buildings without previous labels are annotated as unknown due to their distinct spectral profiles from known land cover.
The SA dataset is acquired by the Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) over the Salinas Valley in California, USA. The image possesses spatial dimensions of 512 × 217 with a spatial resolution of 3.7 m, and it includes 224 bands spanning a wavelength range of 0.4~2.5 μm. Similarly, 20 bands are removed prior to experiments due to water absorption. Man-made materials without previous annotations are labeled as unknown samples.
The IP dataset, obtained via AVIRIS at the Indian Pines test site in Tippecanoe County, Northwest Indiana, USA, has spatial dimensions of 145 × 145 with a spatial resolution of 20 m. It comprises 220 bands spanning a wavelength range of 0.43~0.86 μm. Before classification experiments, 20 bands are eliminated due to water absorption. Classes with fewer than 10 instances were discarded as tail classes and considered unknown, resulting in 8 known classes. Roads that are not previously labeled are identified as unknown.
Table 1 and
Table 2 provides the class distribution for each dataset, while
Figure 9a,
Figure 10a and
Figure 11a are their false color images.
Figure 9b,
Figure 10b and
Figure 11b display the standard true values of the closed-set constant index classification, along with the respective class representations denoted by the true values.
4.2. Evaluation Metrics
To evaluate the performance of RPLDW, the standard OSR indicators are adopted herein, namely closed-set overall accuracy (ClosedOA), open-set overall accuracy (OpenOA), and Kappa. ClosedOA and OpenOA represent the percentage of known category samples and that of open-set samples that are correctly classified, respectively.
where
,
,
, and
signify the true positive, true negative, false positive, and false negative of the
th known class, respectively. All the outliers are combinedly considered as the (
)th class in OpenOA.
4.3. Experiments
The ADAM (Adaptive Moment Estimation) optimizer is utilized for back-propagation, with a maximum training round of 100 times. The learning rate is set at 0.0001 for 1-shot and 0.003 for 5-shot. During the training, all experiments are composed in a random manner from the training samples and repeated 10 times to reduce experimental errors. Subsequently, the average results are calculated for analysis and comparison.
To simulate the conditions for open-set HSI classification, the last category of features is designated as unknown, based on generally accepted standard true values of features, to ensure experiment fairness. In addition, setting a single unknown category aids in maintaining the overall effectiveness of the open-set classification image and facilitates in-depth analysis.
To fully assess the performance of our method in open-set HSI classification, several important comparison methods are employed in this work, involving two categories:
- (1)
Comparison with traditional closed-set HSI classification methods: the three-dimensional octave convolutional space-spectral attention networks (3DOC-SSAN) [
50] and the spectral–spatial transformer network (SSTN) based on transformer backbone [
51] are adopted to emphasize the superiority of open-set classification methods in dealing with unknown categories. In this research, a fully connected (FC) layer is introduced at the end of the network for score prediction, where the maximum score serves as the final label. According to the general solution for open-set issues [
52], an extra softmax function is added to these networks, and the maximum probability value in the probability vector functions as the prediction label. Referring to [
52], the threshold of the softmax function is set to 0.5 to recognize outputs considered as unknown categories (i.e., when the maximum probability is less than 0.5);
- (2)
Comparison with open-set HSI classification methods: OpenMax [
22], SSLR, and MDL4OW [
29] are originally developed for large-scale OSR by fitting the Weibull distribution in the prototype network, making them suitable for FSOSR. RDOSR [
25] performs OSR on HSI datasets in the latent space using a limited number of supervised samples. PEELER [
26], SnaTCHer [
25], and OCN [
53] are developed in the context of FSOSR and can be easily evaluated on HSI datasets.
The above comparisons are conducted by adhering to the optimal settings outlined in each original piece of literature. Consistency in the combinations of randomly selected training samples for each method is maintained across 10 experiments to ensure fairness. Notably, each method’s closed-set and open-set performance is validated by recording the closed-set and open-set metrics, respectively. The experimental results are summarized in
Table 3,
Table 4,
Table 5,
Table 6,
Table 7 and
Table 8.
4.4. Experimental Results
The RPLDW is compared with the most advanced 1-shot and 5-shot FSOSR methods in
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7, respectively. The HSI datasets demonstrate superior performance compared to other OSR methods. The following valuable conclusions can be drawn from the observed results.
- (1)
Limitations of Closed-Set Methods and the Impact of Sample Size on Accuracy: While the use of the softmax function at the end of networks enhances the ability of other closed-set methods to recognize unknown categories, these methods exhibit significant fluctuations when confronted with potential unknown categories. This is especially pronounced in the FSOSR context with limited samples. Methods like 3DOC-SSAN and SSTN perform well with ample samples but become unstable with fewer samples, leading to decreased performance in open-set environments. This highlights the inherent limitations of closed-set classifiers in FSOSR contexts.
- (2)
Performance Comparison of Open-Set Methods and Traditional Classification Methods: Both traditional classification methods and those designed for open sets generally do not perform as well in open-set environments as they do in closed-set ones. This phenomenon is more evident in the context of FSOSR. Dedicated open-set methods, such as RPLDW, demonstrate greater resilience and stability, especially under limited sample conditions, by considering the capability to process unknown categories during the design phase.
- (3)
Correlation Between Open-Set and Closed-Set Performance: Both conventional classification methods and specialized open-set classification methods reveal a close relationship between open-set and closed-set performance. In FSOSR contexts, if a method excels in open-set performance, it often also performs well in closed-set scenarios, but the reverse is not necessarily true.
- (4)
Superiority of Open-Set Methods: Open-set methods exhibit stable accuracy in handling both open and closed-set classifications, which is particularly crucial in FSOSR environments. Compared to closed-set methods, specialized open-set methods effectively exclude unknown categories while maintaining high accuracy in recognizing known categories.
- (5)
Advantages of the RPLDW Method: In the FSOSR environment, the RPLDW method outperforms all other studied methods. It scores highest in closed and open-set metrics and achieves the highest accuracy in identifying unknown categories. RPLDW enhances the boundaries of known categories, eliminating the need to manually set specific thresholds. It constructs an independent space in limited sample situations and employs RPL to calculate reciprocal point distances. This approach significantly improves accuracy by determining labels within the known range in open-set scenarios.
Therefore, it can be concluded that RPLDW performs more robustly and effectively when dealing with open risks in the real open world.
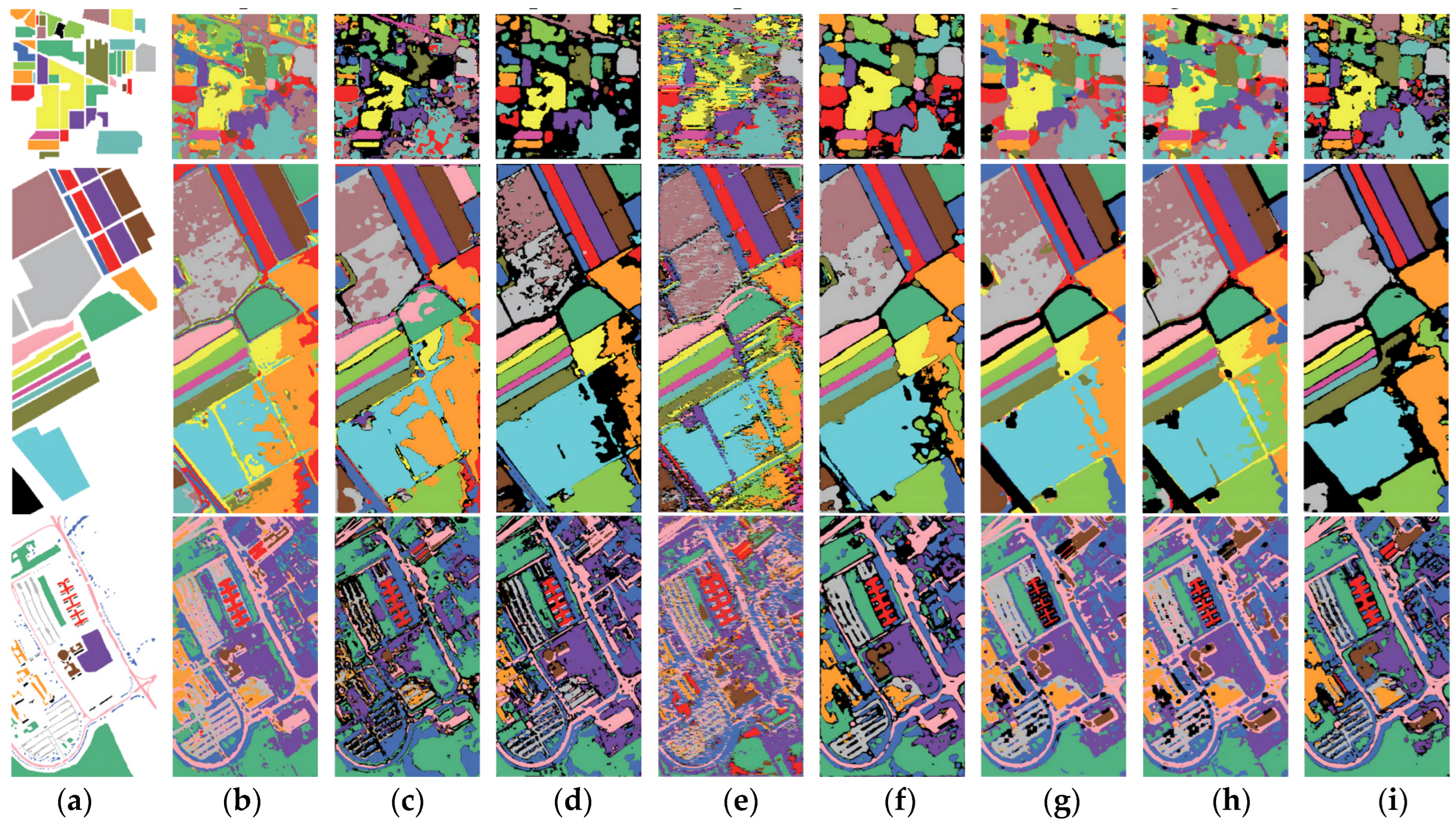
To compare the effects of different methods more intuitively, the classification maps depicting the performance of the better-performing open-set classification methods in the experiment are generated, as explicated in
Figure 12. This visual approach provides a better comprehension and comparison of the performance differences among various methods.
Figure 12 reveals that high closure metrics usually align with high-quality closed-set classification maps, whereas low closure metrics may result in subpar outcomes. Despite SSTN demonstrating superior open performance compared to other closed-set methods, it still struggles to effectively exclude unknown categories.
Improved closed-set methods can identify potential unknown categories, as evidenced by the black areas in the open-set classification maps. However, the overall open-set performance of closed-set methods falls short of ideal. The primary issue lies in misclassifying a considerable number of known categories as unknown, causing inconsistencies between the black areas of the open-set classification maps and the actual situation.
The negative impact of the OSE slightly influences the performance of the open-set methods. The classification maps of open-set methods achieve superior visual effects in both the ideal closed-set assumption and the realistic open HSI world. They usually correspond with the actual distribution of ground objects and exhibit less noise.
RPLDW demonstrates excellent visual effects on both closed-set and open-set classification maps, providing further evidence of its robustness and superior performance in the realistic open HSI world. Notably, MDL4OW and SSLR, with fixed thresholds, tend to overlook certain potential areas of unknown categories. In contrast, our proposed RPLDW incorporates a dynamic, learnable threshold, enabling it to discover more potential areas of unknown categories. This adaptive approach proves effective in navigating the complex open world with new ground object categories.
4.5. Open-Set Multiclassification and Visualization Analysis
Herein, categories 11, 12, 13, and 14 of the SA datasets are identified as unknown for open-set multiclassification experimental analysis. The experiments are compared with the latest open-set recognition algorithms, including FCPN [
15], DLRSPs-DAEs [
54], POSM [
15], and SSMLP-RPL [
14]. The other detailed settings are consistent with the above-mentioned experiments, and the results are outlined in
Table 9.
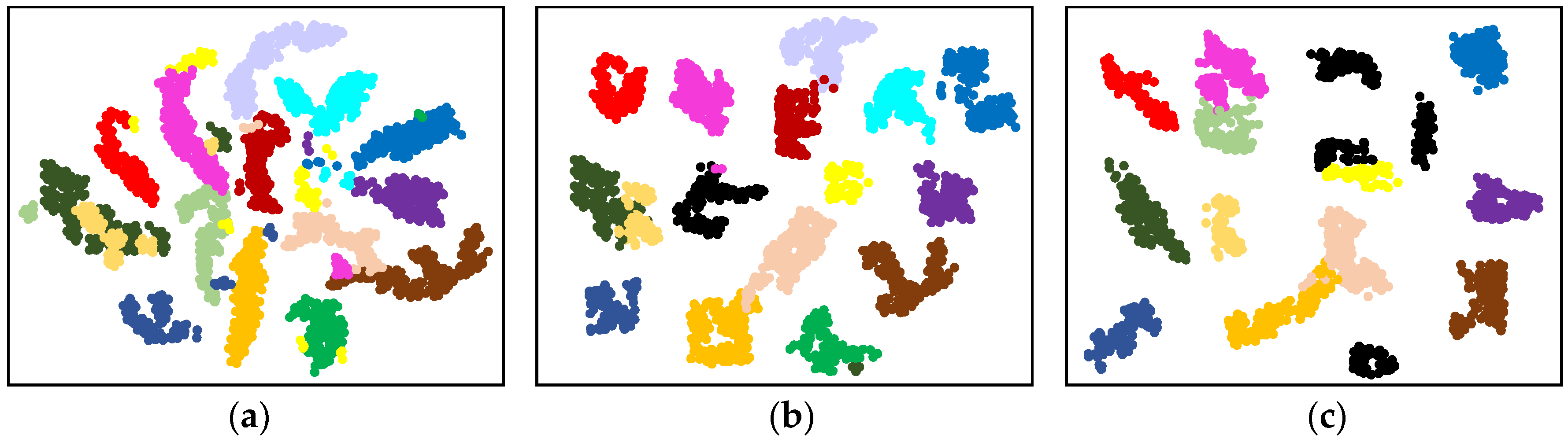
To further intuitively demonstrate the discriminative feature space constructed by RPLDW, the t-SNE dimensionality reduction visualization method is utilized to further highlight its advantages in identifying known and unknown categories. This is implemented by taking SA data as an example, and the results are visualized in
Figure 13.
Examining the original SA data reveals suboptimal discriminability in its feature space, primarily presenting as overlap and too much closeness among different categories. However, using the RPL training and DW strategy, the data samples are successfully projected into a more distinctive high-dimensional feature space, enabling the open-set HSI classification. More specifically, the distance between known categories and their corresponding antipodes is broadened, pushing known categories towards the fringe of the space. In addition, the distance between unknown categories and antipodes is confined within a limited boundary. Therefore, the feature space created by RPLDW enhances the distance between known categories and unknown categories, facilitating the identification of unknown categories.
This optimized feature space ensures the correct classification of known categories while effectively excluding unknown categories. More importantly, the label assignment for the instance to be classified is determined by its distance to the antipode. Setting a reasonable threshold can effectively reject unknown categories, thereby mitigating the risk of open space. However, a single and fixed threshold could potentially lead to overlooking potential unknown categories due to variations in the distance between known categories and their antipodes. A learnable dynamic threshold strategy is proposed in this research to address this issue. It can reject unknown categories to the maximum extent without affecting the recognition of known categories.
4.6. Small Sample Analysis
For experiments on HSI data, the samples in each category are randomly disrupted, and the number of samples from each category is set as 20, 50, 150, and 200 labeled with the real class label, forming the training dataset. Importantly, the training dataset does not include samples labeled as “Unknown”. To create the test dataset, the remaining labeled data are combined with the samples labeled as “Unknown”. Furthermore, five repeated tests are conducted following the aforementioned steps to mitigate the potential impact of random factors and ensure the robustness of the experimental outcomes. The algorithm’s performance is assessed using the average classification results. To assess the efficacy of the algorithm proposed in this research, its experimental results are compared with those of several algorithms mentioned in the previous section, employing three experimental datasets. The specific comparisons are detailed in
Table 10,
Table 11 and
Table 12.
The experimental results further reinforce the efficacy of the proposed RPLDW algorithm, showing its pronounced advantage over other methods at a consistent training rate. Notably, as the training dataset increases from 150 to 200, the RPLDW algorithm maintains stable classification results, underscoring its robust performance even with relatively small training datasets. This stability is a significant strength of our algorithm, opening up possibilities for practical applications in scenarios with limited data and quick decision-making requirements or situations characterized by continuous data growth and continuous learning needs.
The success of the proposed method in achieving high accuracy can be attributed to the effectiveness of the reciprocal points and reinforced boundary algorithms proposed. The reciprocal point algorithm can effectively project data instances into a high-dimensional feature space, enlarging the separation between known and unknown categories. This clear distance difference provides a clearer foundation for classification decisions, thereby enhancing overall accuracy. Simultaneously, the reinforced boundary algorithm contributes to the stability of classification by optimizing decision boundaries and maintaining high classification accuracy even with limited training samples. This approach fortifies more robust classification decisions in environments with scarce data, solidifying the strong performance of our method under these circumstances.
In summary, the harmonious integration of reciprocal points and reinforced boundary algorithms empowers the proposed method to demonstrate exceptional performance, particularly in scenarios with limited data. This success is a testament to algorithmic design and our ability to deeply understand the dynamics of data and the needs of classification.
4.7. RPLDW Model Ablation Analysis
The RPLDW method introduced herein incorporates GAN and RPL, which significantly enhances its performance in HSI data classification in the OSE. Ablation experiments were conducted on these two modules by systematically excluding them from the RPLDW framework. Subsequently, open-set classification on the “Unknown” labeled data across three datasets was conducted, using the accuracy of open-set classification as the evaluation metric. The experimental results are summarized in
Table 13, revealing the substantial contributions of both GAN and RPL to the classification capability of RPLDW in the OSE. The removal of either the GAN or the RPL module from RPLDW leads to a marked decrease in the model’s accuracy for classification in the OSE.
After the removal of the GAN module, the model exhibited a notable decrease in the average accuracy for classification in the OSE across various training data sizes. Specifically, for training data sizes of 20, 50, 100, 150, and 200, the declines in accuracy were 22.32%, 23.78%, 22.97%, 22.57%, and 20.7%, respectively. Similarly, excluding the RPL module resulted in accuracy reductions of 27.11%, 26.89%, 25.62%, 24.23%, and 22.95% for the same training data sizes, respectively. RPL differentiates the unknown category space by constructing inverse prototypes and widening the distance between known and unknown categories, thereby mitigating risks in open spaces. Conversely, GAN assesses the similarity of test data from a metric domain perspective, facilitating the detection and classification of unknown label data.
In summary, the RPLDW model proposed herein leveraged RPL to construct a separation space and incorporated GAN for outstanding performance in HSI open-set classification. RPLDW demonstrates superior performance in unknown class identification, model stability, classification efficacy, and convergence speed compared to other algorithms. Despite its effectiveness in identifying known and unknown categories in HSI data with enhanced boundaries, some stray data points in the sample space remain inadequately classified. Additionally, applying a threshold method for open-set recognition in RPLDW can impact the accuracy. These limitations provide opportunities for future enhancement and refinement.
5. Conclusions
In the field of HSI classification, despite the significant strides made by deep learning methods, they still heavily rely on the ideal CSE and demand a substantial volume of labeled data. In response to these challenges, this research proposes the RPLDW method. Firstly, a K-class classifier tailored for the closed set is trained, leveraging its internal encoder to extract features. These features, indicative of known class distributions, are then employed to fine-tune the training of the classifier. Secondly, synthetic samples close to the decision boundary are generated using the GAN based on sample density constraints. These synthetic samples are processed to augment the training data. This addresses the scarcity of samples and enhances the training data. Concurrently, an RPL framework is introduced to lower the risk of open space by simulating category external space, thereby enlarging the distance between known and unknown categories. Finally, a dynamic threshold method is designed based on data roaming by dividing the synthetic samples into known and unknown categories and inputting them together with known samples into the classifier for a new round of training.
The experimental results reveal the strong competitiveness of RPLDW in both the CSE and OSE, even surpassing the current state-of-the-art HSI classification methods. This proves the effectiveness and robustness of the proposed RPLDW in lowering risks in the real open world and improving classification accuracy. However, it should be noted that RPLDW may erroneously label distinct land objects as unknown categories at their boundaries, highlighting an area that warrants further research and improvement.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}