
Detection of Military Targets on Ground and Sea by UAVs with Low-Altitude Oblique Perspective


Abstract
:1. Introduction
- The dataset is supposed to encompass a wide range of terrain and weather conditions, including both ground and water domains;
- The UAV’s viewpoint has a large oblique perspective and altitude variations to match real scouting mission scenarios.
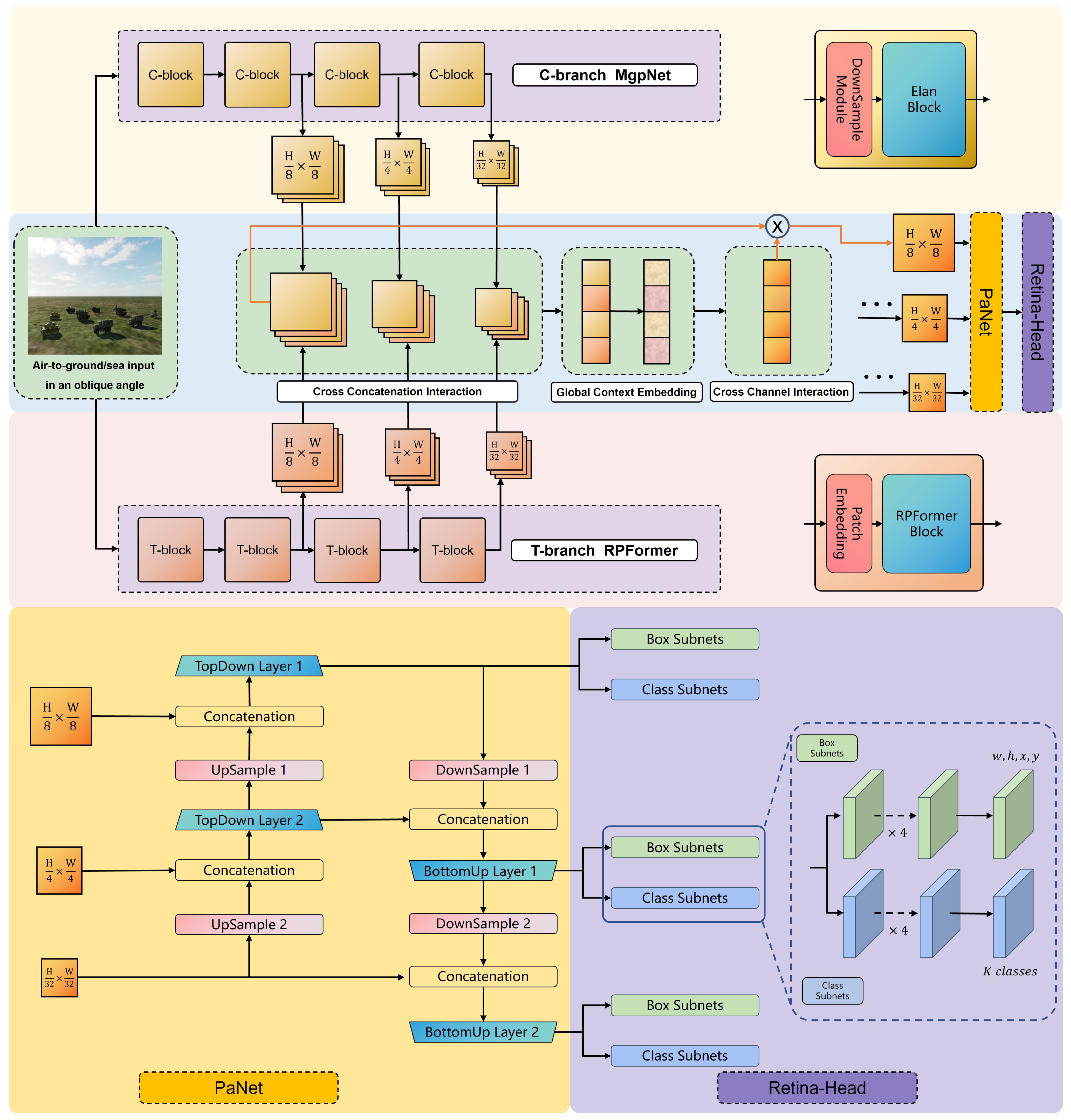
- A hybrid detection model that combines CNN and Transformer architectures is proposed for detecting military targets on ground and at sea. The detector incorporates T-branch Region–Pixel two-stage Transformer (RPFormer) and C-branch Multi-gradient Path Network (MgpNet) in a decoupled manner.
- RPFormer, an efficient Transformer architecture consisting of Region-stage and Pixel-stage attention mechanisms, is proposed to gather the global information of an entire image. Additionally, MgpNet, based on Elan [21] block and inspired by the multi-gradient flow strategy [31], is introduced using local feature extraction.
- A feature fusion strategy for hybrid models in channel dimensions is proposed. It fuses feature maps through three steps: Cross-Concatenation Interaction, Global Context Embedding, and Cross-Channel Interaction.
- An object detection dataset regarding military background is constructed. The dataset consists of air-to-ground and air-to-sea scenarios and includes common combat units in a real scenario. All the images are captured from a large oblique perspective from 10 to 45 degrees at low altitude.
2. Related Work
2.1. CNN-Based Detectors
2.2. Transformer-Based Detectors
2.3. Hybrid Detectors
3. Method
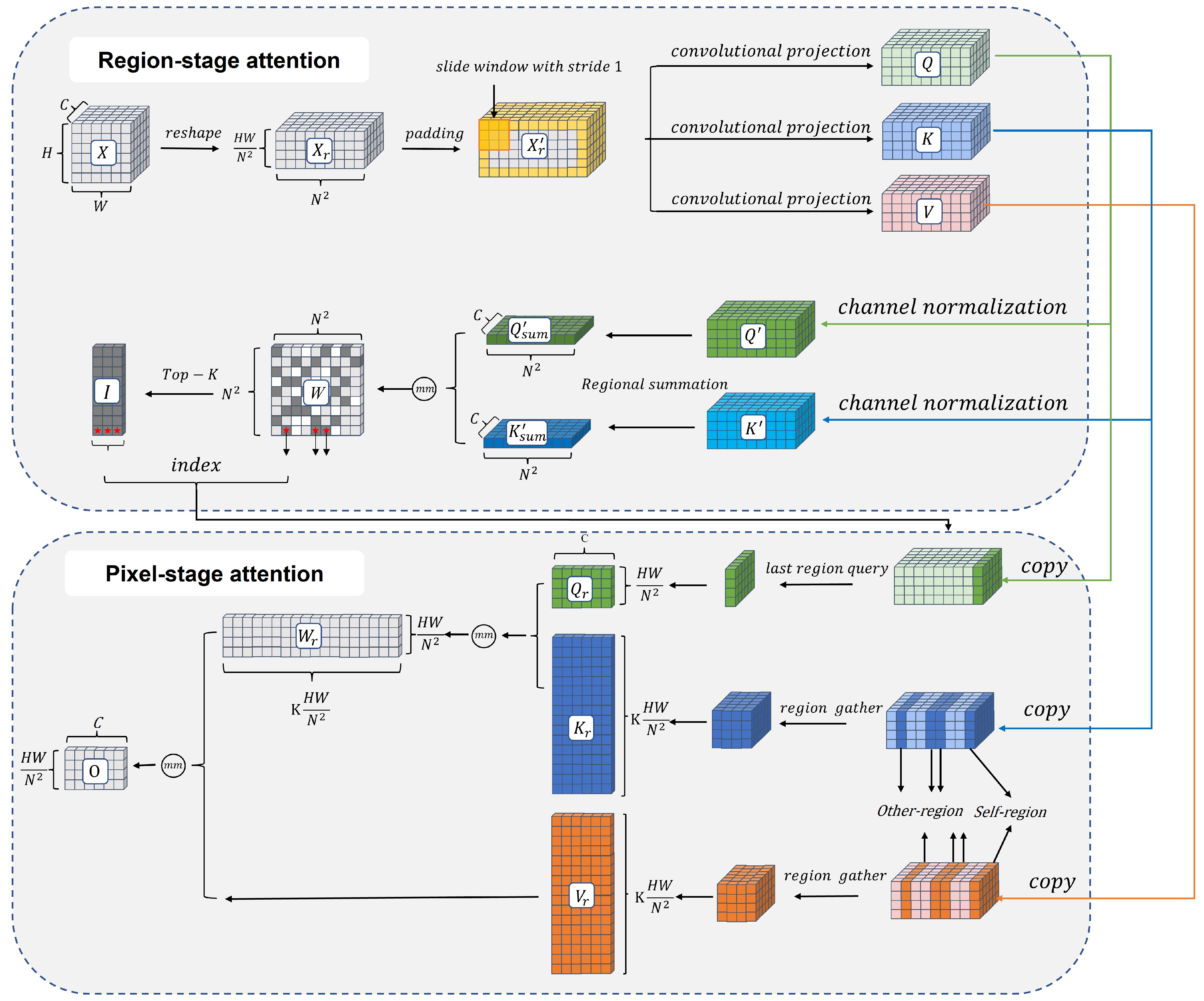
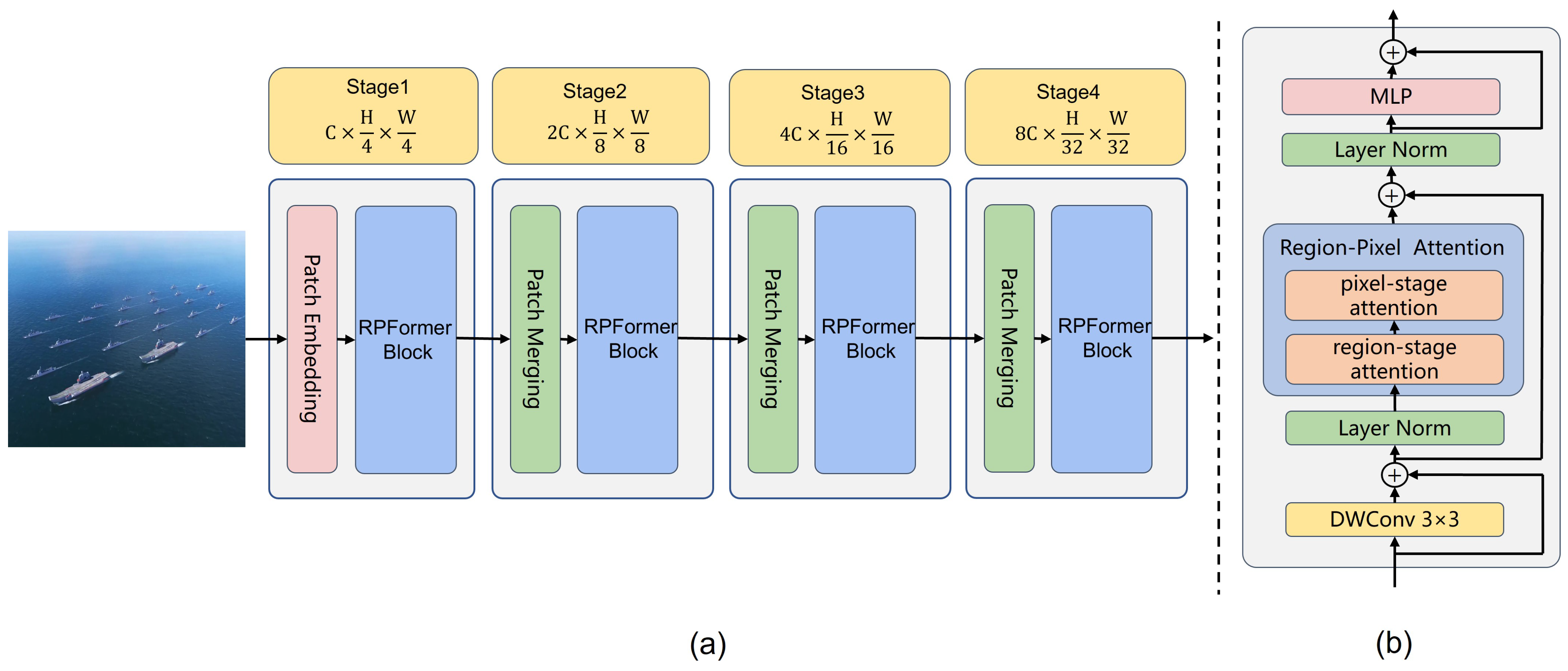
- In Section 3.1, the core block Region-Pixel two-stage attention mechanism in RPformer is illustrated in Figure 2. RPformer, an efficient Transformer Network as depicted in Figure 3, is proposed as T-branch to gather information in global scope;
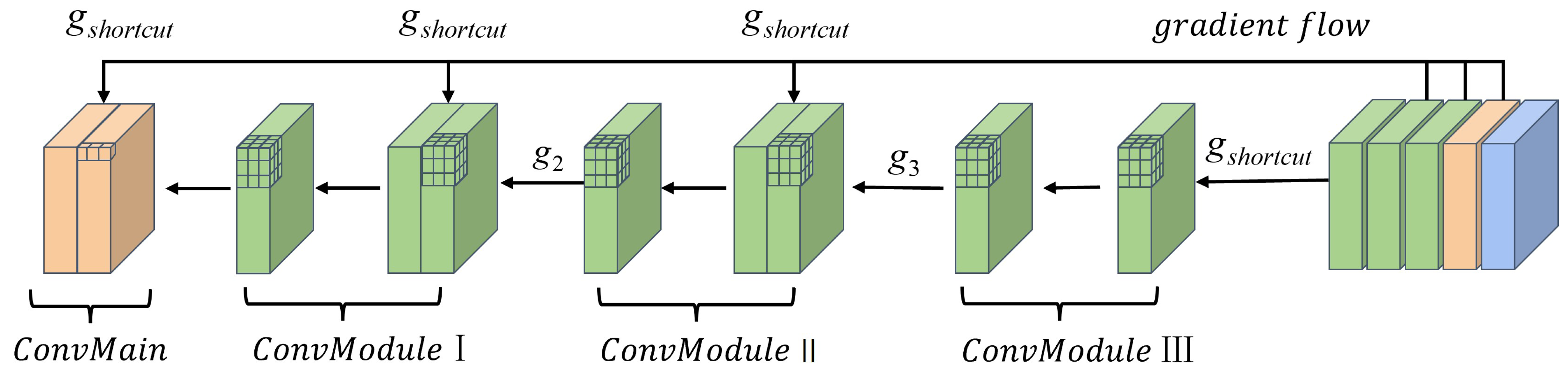
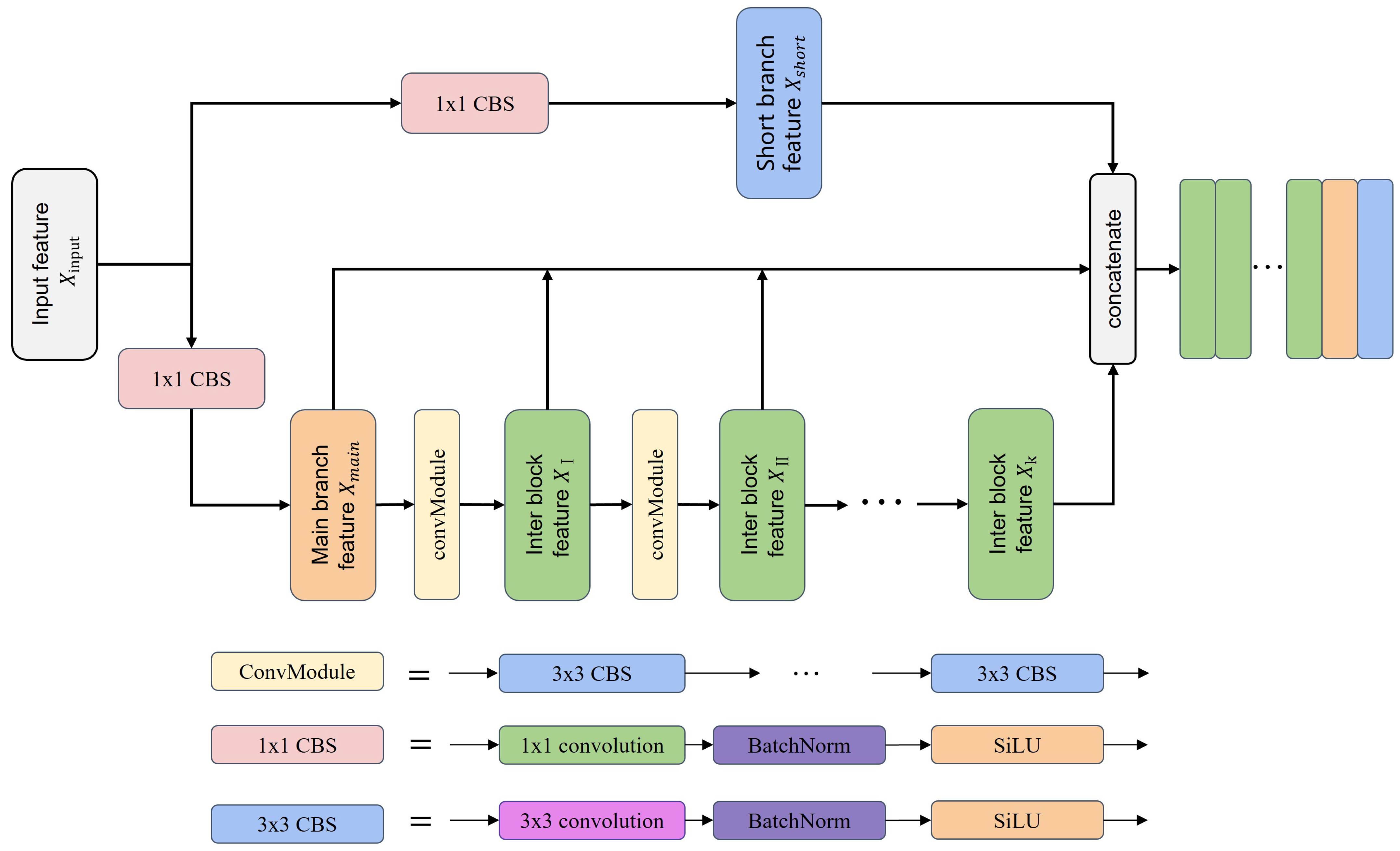
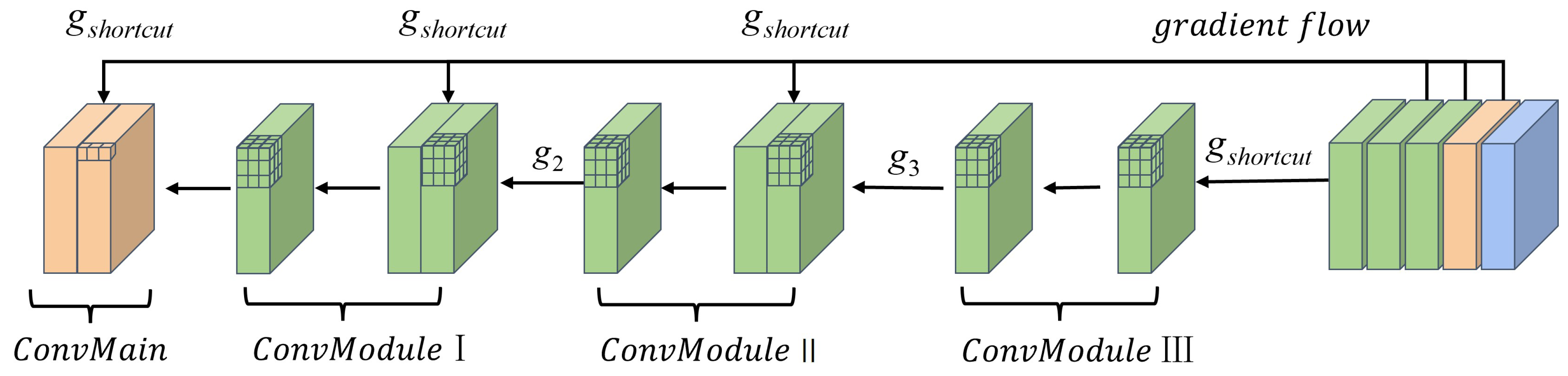
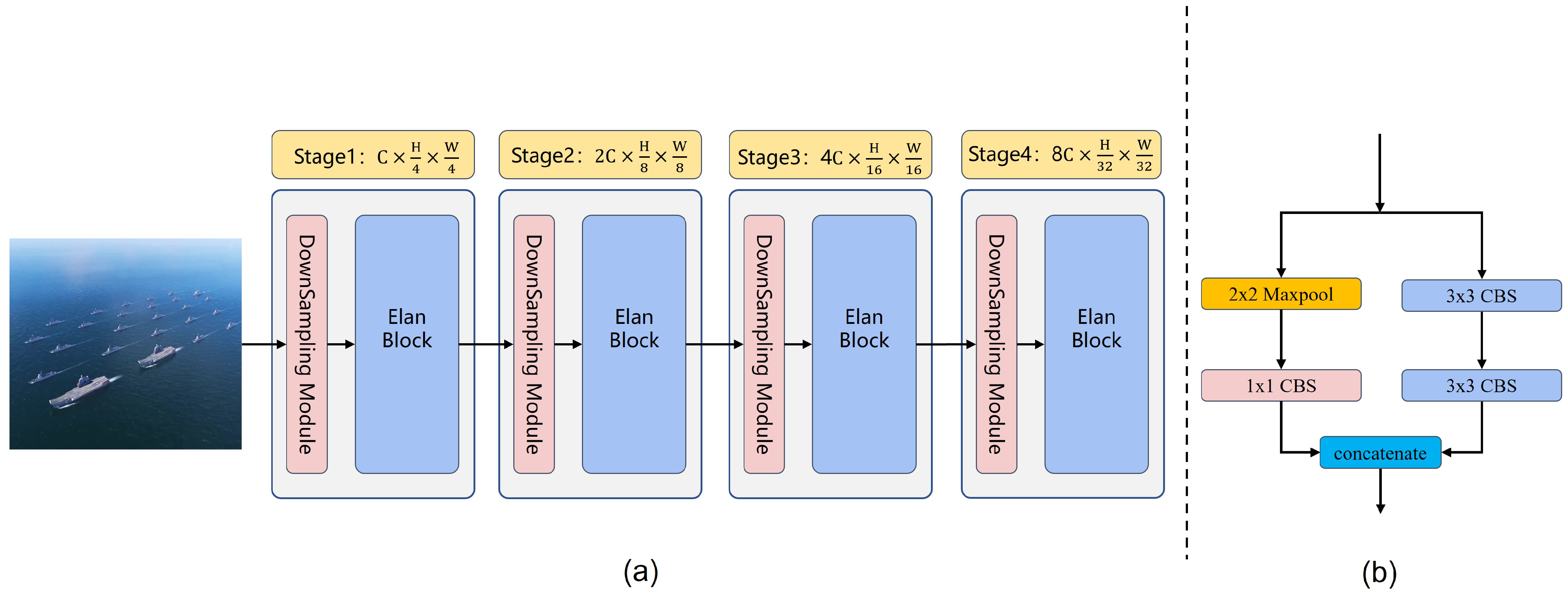
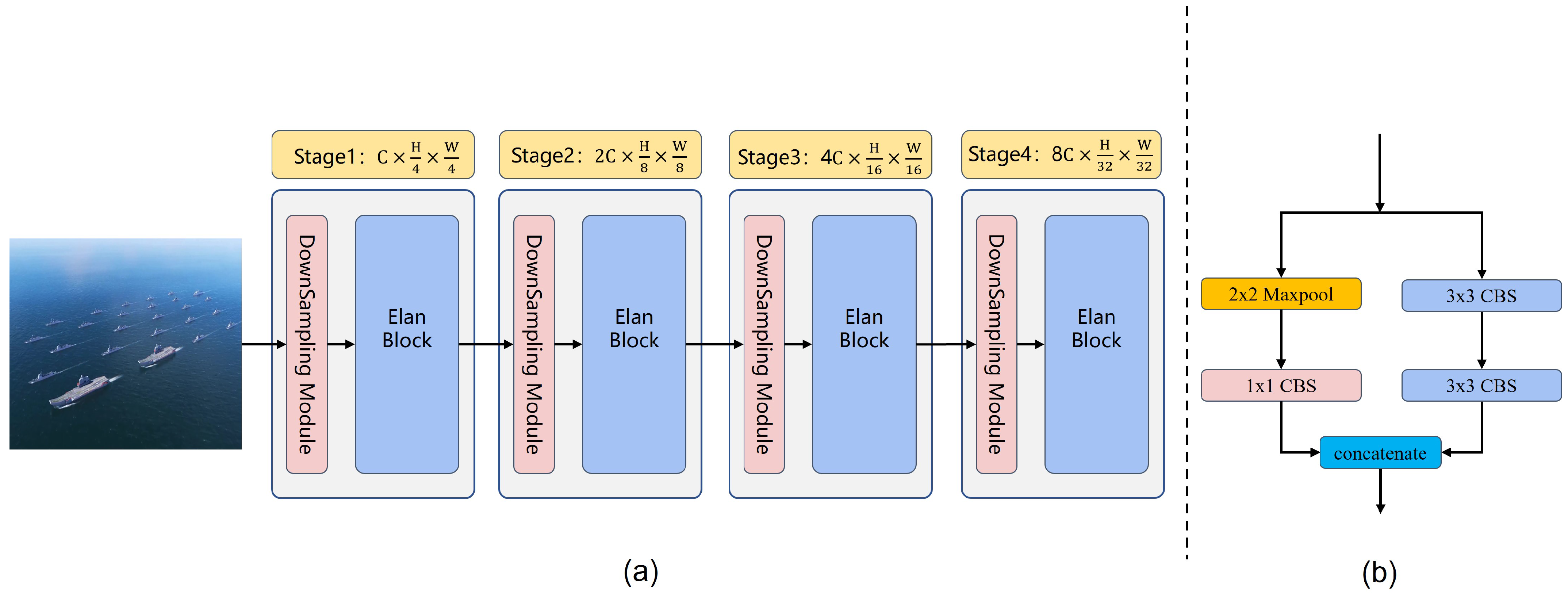
- In Section 3.2, the core block of MgpNet, efficient layer aggregation network’s (Elan) block details, is illustrated in Figure 4. Inspired by multi-gradient flow strategy [31], as shown in Figure 5, a Multi-gradient Path Network (MgpNet), as depicted in Figure 6, is introduced as C-branch for extracting local information;
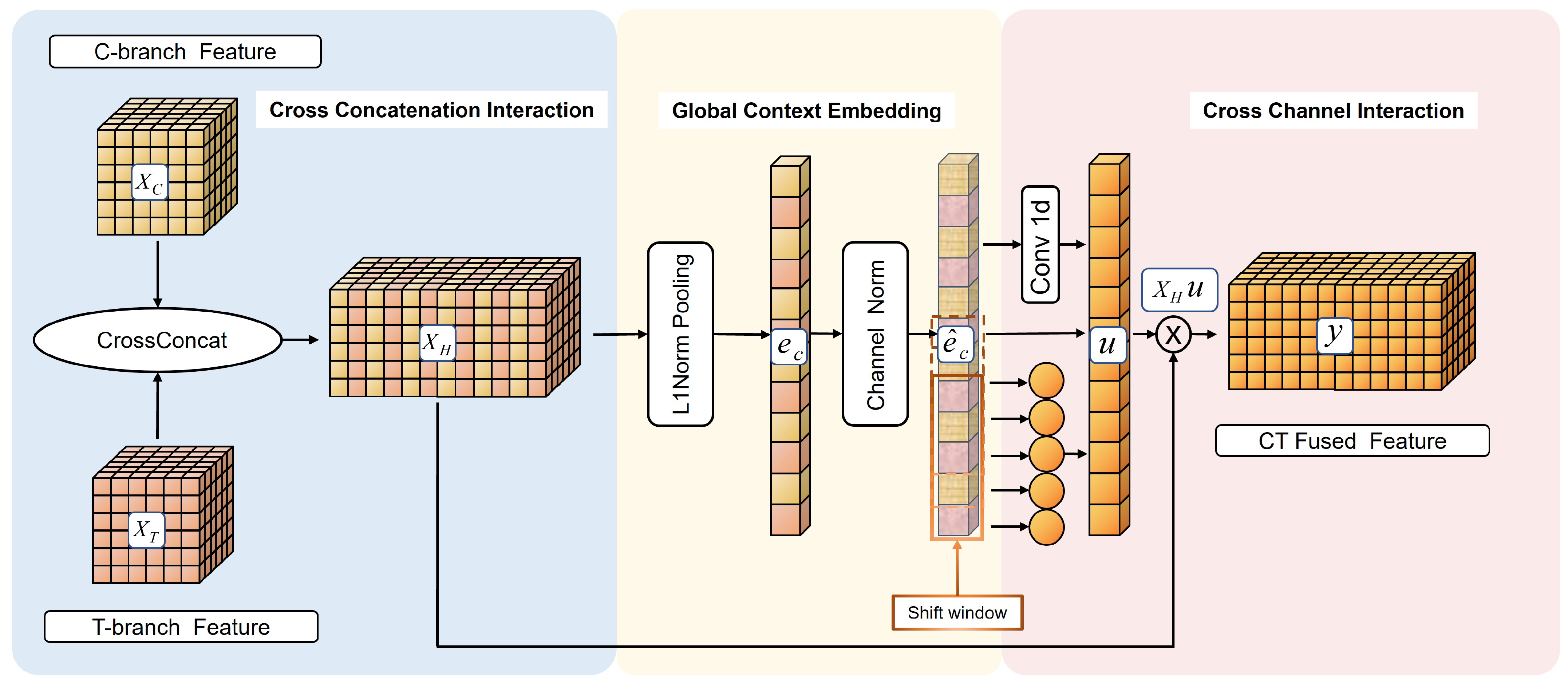
- In Section 3.3, a feature fusion strategy for the hybrid model is designed as depicted in Figure 7. The fusion module combines feature maps of the same scale through three steps in turn: Cross-Concatenation Interaction, Global Context Embedding, and Cross-Channel Interaction.

3.1. Region–Pixel Two-Stage Attention Mechanism
3.1.1. Region–Pixel Transformer Block
- Region-stage attention
- Pixel-stage attention

3.1.2. Structure

3.2. Multi-Gradient Path Network
3.2.1. Elan Block


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ConvLayer | Layer1 | Layer2 | Layer3 | Layer4 | Layer5 | Layer6 | Layer7 | |||
| Shortcut | ✓ | / | / | ✓ | / | / | ✓ | / | / | / |
| moment·1 | G1 | / | / | G1 | / | / | G1 | / | / | G1 |
| moment·2 | / | / | G2 | / | / | G2 | / | / | G2 | / |
| moment·3 | / | G3 | / | / | G3 | / | / | G3 | / | / |
| moment·4 | / | / | G4 | / | / | G4 | / | / | / | / |
| moment·5 | / | G5 | / | / | G5 | / | / | / | / | / |
| moment·6 | / | G6 | / | / | / | / | / | / | / | |
| moment·7 | / | G7 | / | / | / | / | / | / | / | / |
3.2.2. Structure
3.3. Channel-Attention-Based Feature Fusion Module

3.3.1. Cross-Concatenation Interaction
3.3.2. Global Context Embedding
3.3.3. Cross-Channel Interaction
4. Datasets
4.1. Simulation Environments
4.2. Details of Dataset
5. Experiments and Discussion
5.1. Experimental Setup
5.2. Comparison with State of the Art

5.3. Ablation Experiments
| Scenario | Branch | ||||||
|---|---|---|---|---|---|---|---|
| Air-to-sea | C | 55.4 | 92.2 | 56.5 | 14.1 | 47.9 | 69.5 |
| T | 56.5 | 93.6 | 58.6 | 15.1 | 49.2 | 69.9 | |
| ours | 57.9 | 95.1 | 60.2 | 17.1 | 50.3 | 70.6 | |
| Air-to-ground | C | 64.3 | 88.7 | 72.2 | 11.4 | 62.7 | 85.8 |
| T | 67.4 | 90.8 | 75.3 | 15.8 | 65.9 | 86.3 | |
| ours | 68.9 | 92.5 | 76.9 | 18.1 | 67.6 | 87.4 |
| Scenario | Method | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Add | Concat | CCI 1 | GCE 1 | CCHI 1 | Conv2d | |||||||
| Air-to-sea | ✓ | / | / | / | / | / | 56.8 | 94.0 | 58.9 | 15.6 | 49.8 | 70.6 |
| / | ✓ | / | / | / | / | 57.0 | 94.3 | 59.3 | 16.0 | 49.4 | 70.7 | |
| / | / | ✓ | / | / | / | 55.5 | 92.7 | 57.3 | 14.3 | 48.3 | 69.3 | |
| / | / | ✓ | ✓ | / | / | 58.9 | 96.1 | 60.6 | 17.9 | 49.9 | 71.2 | |
| / | / | ✓ | ✓ | ✓ | ✓ | 57.2 | 94.5 | 59.5 | 16.4 | 49.9 | 70.5 | |
| / | / | ✓ | ✓ | ✓ | / | 57.9 | 95.1 | 60.2 | 17.1 | 50.3 | 70.6 | |
| Air-to-ground | ✓ | / | / | / | / | / | 67.8 | 91.1 | 75.6 | 16.7 | 66.5 | 87.7 |
| / | ✓ | / | / | / | / | 68.1 | 91.5 | 76.0 | 17.0 | 66.8 | 87.7 | |
| / | / | ✓ | / | / | / | 67.1 | 89.9 | 75.2 | 14.4 | 67.1 | 87.4 | |
| / | / | ✓ | ✓ | / | / | 68.3 | 91.9 | 76.3 | 17.7 | 67.0 | 87.2 | |
| / | / | ✓ | ✓ | ✓ | ✓ | 51.3 | 79.6 | 57.7 | 10.6 | 43.1 | 75.2 | |
| / | / | ✓ | ✓ | ✓ | / | 68.9 | 92.5 | 76.9 | 18.1 | 67.6 | 87.4 | |
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Peng, H.; Zhang, Y.; Yang, S.; Song, B. Battlefield image situational awareness application based on deep learning. IEEE Intell. Syst. 2019, 35, 36–43. [Google Scholar] [CrossRef]
- Yang, K.; Pan, A.; Yang, Y.; Zhang, S.; Ong, S.H.; Tang, H. Remote sensing image registration using multiple image features. Remote Sens. 2017, 9, 581. [Google Scholar] [CrossRef]
- Zhou, L.; Leng, S.; Liu, Q.; Wang, Q. Intelligent UAV swarm cooperation for multiple targets tracking. IEEE Internet Things J. 2021, 9, 743–754. [Google Scholar] [CrossRef]
- Mei, C.; Fan, Z.; Zhu, Q.; Yang, P.; Hou, Z.; Jin, H. A Novel scene matching navigation system for UAVs based on vision/inertial fusion. IEEE Sens. J. 2023, 23, 6192–6203. [Google Scholar] [CrossRef]
- Fang, W.; Love, P.E.; Luo, H.; Ding, L. Computer vision for behaviour-based safety in construction: A review and future directions. Adv. Eng. Inform. 2020, 43, 100980. [Google Scholar] [CrossRef]
- Stodola, P.; Kozůbek, J.; Drozd, J. Using unmanned aerial systems in military operations for autonomous reconnaissance. In Proceedings of the Modelling and Simulation for Autonomous Systems: 5th International Conference, MESAS 2018, Prague, Czech Republic, 17–19 October 2018; Revised Selected Papers 5. Springer: Cham, Switzerland, 2019; pp. 514–529. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1627–1645. [Google Scholar] [CrossRef]
- Sumari, A.D.W.; Pranata, A.S.; Mashudi, I.A.; Syamsiana, I.N.; Sereati, C.O. Automatic target recognition and identification for military ground-to-air observation tasks using support vector machine and information fusion. In Proceedings of the 2022 International Conference on ICT for Smart Society (ICISS), Bandung, Indonesia, 10–11 August 2022; pp. 1–8. [Google Scholar]
- Du, X.; Song, L.; Lv, Y.; Qiu, S. A lightweight military target detection algorithm based on improved YOLOv5. Electronics 2022, 11, 3263. [Google Scholar] [CrossRef]
- Jafarzadeh, P.; Zelioli, L.; Farahnakian, F.; Nevalainen, P.; Heikkonen, J.; Hemminki, P.; Andersson, C. Real-Time Military Tank Detection Using YOLOv5 Implemented on Raspberry Pi. In Proceedings of the 2023 4th International Conference on Artificial Intelligence, Robotics and Control (AIRC), Cairo, Egypt, 9–11 May 2023; pp. 20–26. [Google Scholar]
- Jacob, S.; Wall, J.; Sharif, M.S. Analysis of Deep Neural Networks for Military Target Classification using Synthetic Aperture Radar Images. In Proceedings of the 2023 International Conference on Innovation and Intelligence for Informatics, Computing, and Technologies (3ICT), Sakheer, Bahrain, 20–21 November 2023; pp. 227–233. [Google Scholar]
- Yu, B.; Lv, M. Improved YOLOv3 algorithm and its application in military target detection. Acta Armamentarii 2022, 43, 345. [Google Scholar]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. Cvt: Introducing convolutions to vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 22–31. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov2:yolo9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Dong, X.; Bao, J.; Chen, D.; Zhang, W.; Yu, N.; Yuan, L.; Chen, D.; Guo, B. Cswin transformer: A general vision transformer backbone with cross-shaped windows. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12124–12134. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 568–578. [Google Scholar]
- Srinivas, A.; Lin, T.Y.; Parmar, N.; Shlens, J.; Abbeel, P.; Vaswani, A. Bottleneck transformers for visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 16519–16529. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Yeh, I.H. Designing network design strategies through gradient path analysis. arXiv 2022, arXiv:2211.04800. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Wang, Y.; Ning, X.; Leng, B.; Fu, H. Ship detection based on deep learning. In Proceedings of the 2019 IEEE International Conference on Mechatronics and Automation (ICMA), Tianjin, China, 4–7 August 2019; pp. 275–279. [Google Scholar]
- Xiong, Z.; Wang, L.; Zhao, Y.; Lan, Y. Precision Detection of Dense Litchi Fruit in UAV Images Based on Improved YOLOv5 Model. Remote Sens. 2023, 15, 4017. [Google Scholar] [CrossRef]
- Hou, H.; Chen, M.; Tie, Y.; Li, W. A universal landslide detection method in optical remote sensing images based on improved YOLOX. Remote Sens. 2022, 14, 4939. [Google Scholar] [CrossRef]
- Dai, Z.; Cai, B.; Lin, Y.; Chen, J. Up-detr: Unsupervised pre-training for object detection with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 1601–1610. [Google Scholar]
- Liu, S.; Li, F.; Zhang, H.; Yang, X.; Qi, X.; Su, H.; Zhu, J.; Zhang, L. Dab-detr: Dynamic anchor boxes are better queries for detr. arXiv 2022, arXiv:2201.12329. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Wang, W.; Chen, W.; Qiu, Q.; Chen, L.; Wu, B.; Lin, B.; He, X.; Liu, W. Crossformer++: A versatile vision transformer hinging on cross-scale attention. arXiv 2023, arXiv:2303.06908. [Google Scholar] [CrossRef]
- Zhao, T.; Cao, J.; Hao, Q.; Bao, C.; Shi, M. Res-SwinTransformer with Local Contrast Attention for Infrared Small Target Detection. Remote Sens. 2023, 15, 4387. [Google Scholar] [CrossRef]
- Xu, Y.; Wu, Z.; Wei, Z. Spectral-Spatial Classification of Hyperspectral Image Based on Low-Rank Decomposition. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2370–2380. [Google Scholar] [CrossRef]
- Lu, W.; Lan, C.; Niu, C.; Liu, W.; Lyu, L.; Shi, Q.; Wang, S. A CNN-Transformer Hybrid Model Based on CSWin Transformer for UAV Image Object Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 1211–1231. [Google Scholar] [CrossRef]
- Zhao, X.; Xia, Y.; Zhang, W.; Zheng, C.; Zhang, Z. YOLO-ViT-Based Method for Unmanned Aerial Vehicle Infrared Vehicle Target Detection. Remote Sens. 2023, 15, 3778. [Google Scholar] [CrossRef]
- Ren, K.; Chen, X.; Wang, Z.; Liang, X.; Chen, Z.; Miao, X. HAM-Transformer: A Hybrid Adaptive Multi-Scaled Transformer Net for Remote Sensing in Complex Scenes. Remote Sens. 2023, 15, 4817. [Google Scholar] [CrossRef]
- Ye, T.; Zhang, J.; Li, Y.; Zhang, X.; Zhao, Z.; Li, Z. CT-Net: An efficient network for low-altitude object detection based on convolution and transformer. IEEE Trans. Instrum. Meas. 2022, 71, 1–12. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8697–8710. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Yang, Z.; Zhu, L.; Wu, Y.; Yang, Y. Gated channel transformation for visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11794–11803. [Google Scholar]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Su, H.; Wei, S.; Yan, M.; Wang, C.; Shi, J.; Zhang, X. Object detection and instance segmentation in remote sensing imagery based on precise mask R-CNN. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 1454–1457. [Google Scholar]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Lin, H.; Zhang, Z.; Sun, Y.; He, T.; Mueller, J.; Manmatha, R.; et al. Resnest: Split-attention networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 2736–2746. [Google Scholar]
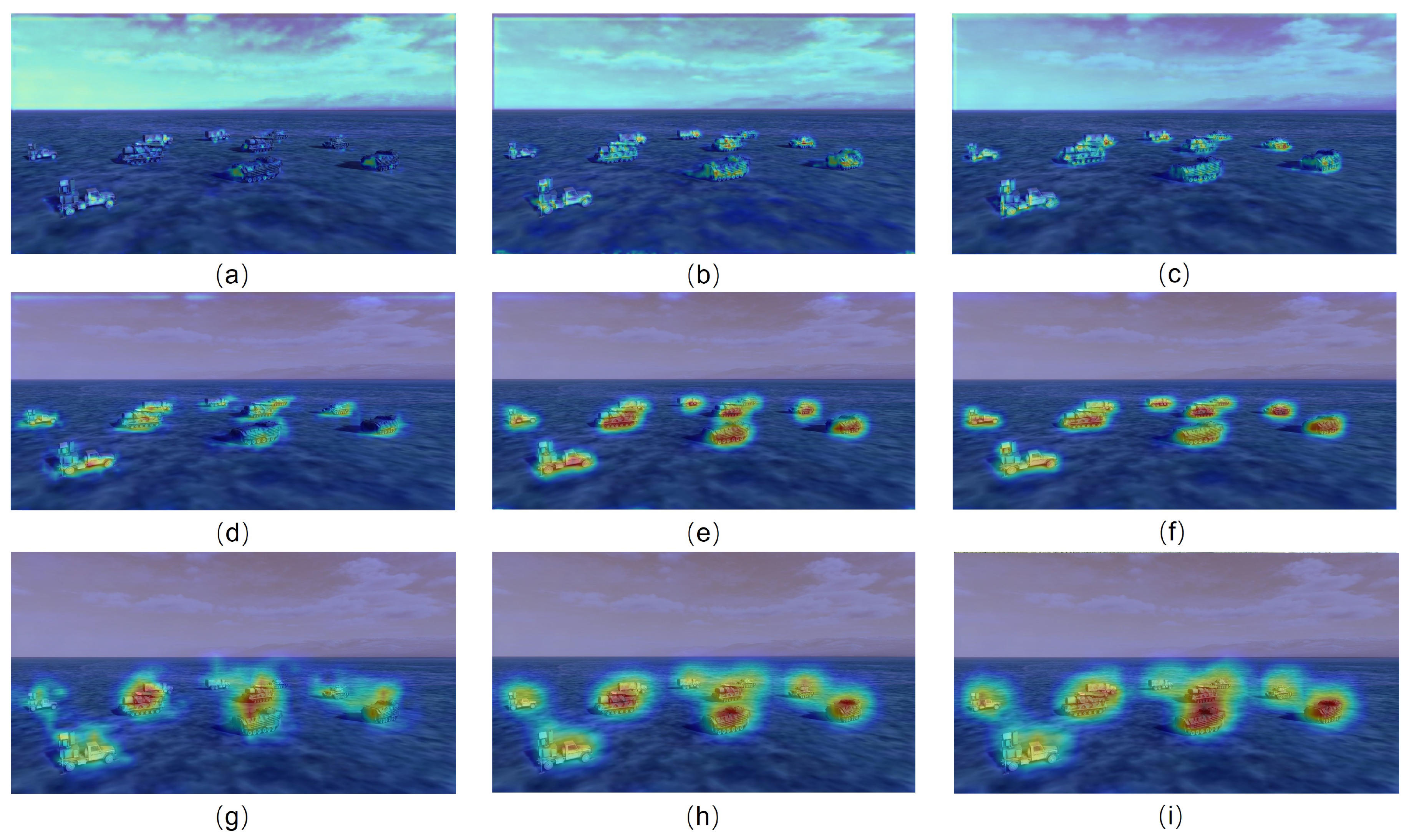
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]





| Scenario | Target Category | Box Number | Height Range | Image Size | Angle Range |
|---|---|---|---|---|---|
| Air-to-ground | tank | 6598 | 25–200 m | 1080 × 1920 pixels | 10–45 degrees |
| radar vehicle | 4186 | ||||
| transport vehicle | 6850 | ||||
| rocket launcher | 7216 | ||||
| armored vehicle | 6756 | ||||
| Air-to-sea | large warship | 11,128 | 200–2000 m | ||
| medium warship | 8440 | ||||
| small warship | 19,134 |
| Scenario | Method | Flops (G) | Params (M) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Air-to-sea | EfficientNet-b0 | 29.8 | 5.3 | 50.0 | 87.3 | 49.5 | 6.6 | 41.5 | 66.1 |
| ResNet-50 | 47.6 | 25.6 | 52.0 | 89.0 | 51.0 | 7.6 | 43.1 | 66.6 | |
| ResNest-50 | 50.9 | 27.5 | 53.6 | 91.1 | 55.0 | 11.0 | 46.1 | 68.2 | |
| CSPDarkNet-53 | 66.9 | 43.2 | 54.5 | 91.5 | 56.1 | 13.7 | 47.2 | 69.2 | |
| PVT-s | 51.3 | 24.5 | 54.8 | 92.1 | 55.0 | 13.8 | 47.1 | 69.0 | |
| Swin-s | 49.4 | 49.6 | 55.7 | 92.8 | 57.8 | 14.2 | 48.6 | 69.4 | |
| CSWin-s | 42.7 | 35.3 | 56.0 | 93.1 | 58.4 | 14.6 | 49.1 | 69.6 | |
| Ours | 61.7 | 37.5 | 57.9 | 95.1 | 60.2 | 17.1 | 50.3 | 70.6 | |
| Air-to-ground | EfficientNet-b0 | 29.8 | 5.3 | 58.7 | 83.1 | 65.9 | 6.8 | 57.2 | 83.9 |
| ResNet-50 | 47.6 | 25.6 | 61.1 | 85.4 | 68.3 | 8.4 | 60.1 | 84.6 | |
| ResNest-50 | 50.9 | 27.5 | 62.9 | 87.3 | 70.2 | 9.9 | 61.2 | 84.9 | |
| CSPDarkNet-53 | 66.9 | 43.2 | 63.7 | 88.2 | 71.1 | 10.7 | 61.9 | 85.7 | |
| PVT-s | 51.3 | 24.5 | 64.6 | 89.1 | 72.7 | 12.2 | 63.4 | 85.8 | |
| Swin-s | 49.4 | 49.6 | 65.2 | 89.6 | 73.3 | 14.4 | 64.7 | 86.1 | |
| CSWin-s | 42.7 | 35.3 | 66.5 | 90.4 | 74.5 | 14.9 | 65.2 | 86.4 | |
| Ours | 61.7 | 37.5 | 68.9 | 92.5 | 76.9 | 18.1 | 67.6 | 87.4 |
| Method | Scenario | |||||||
|---|---|---|---|---|---|---|---|---|
| Air-to-Sea | Air-to-Ground | |||||||
| Large Warship | Medium Warship | Small Warship | Transport Vehicle | Tank | Rocket Launcher | Armored Vehicle | Radar Vehicle | |
| EfficientNet-b0 | 69.0 | 50.9 | 31.1 | 55.3 | 59.8 | 62.6 | 50.4 | 65.4 |
| ResNest-50 | 69.3 | 53.9 | 32.9 | 58.3 | 61.5 | 64.4 | 53.5 | 67.7 |
| CSPDarkNet-53 | 71.1 | 55.8 | 33.8 | 61.9 | 62.1 | 66.8 | 55.6 | 68.1 |
| ResNet-50 | 71.7 | 57.5 | 34.2 | 62.8 | 63.2 | 67.9 | 55.9 | 68.7 |
| PVT-s | 72.2 | 57.9 | 34.2 | 64.8 | 62.6 | 68.2 | 57.0 | 70.4 |
| Swin-s | 73.4 | 59.3 | 34.5 | 66.1 | 63.0 | 68.8 | 57.7 | 70.6 |
| CSWin-s | 73.3 | 60.1 | 34.6 | 67.2 | 65.8 | 69.3 | 58.6 | 71.5 |
| Ours | 74.6 | 62.9 | 36.1 | 68.7 | 67.8 | 73.7 | 60.8 | 73.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeng, B.; Gao, S.; Xu, Y.; Zhang, Z.; Li, F.; Wang, C. Detection of Military Targets on Ground and Sea by UAVs with Low-Altitude Oblique Perspective. Remote Sens. 2024, 16, 1288. https://doi.org/10.3390/rs16071288
Zeng B, Gao S, Xu Y, Zhang Z, Li F, Wang C. Detection of Military Targets on Ground and Sea by UAVs with Low-Altitude Oblique Perspective. Remote Sensing. 2024; 16(7):1288. https://doi.org/10.3390/rs16071288
Chicago/Turabian StyleZeng, Bohan, Shan Gao, Yuelei Xu, Zhaoxiang Zhang, Fan Li, and Chenghang Wang. 2024. "Detection of Military Targets on Ground and Sea by UAVs with Low-Altitude Oblique Perspective" Remote Sensing 16, no. 7: 1288. https://doi.org/10.3390/rs16071288
APA StyleZeng, B., Gao, S., Xu, Y., Zhang, Z., Li, F., & Wang, C. (2024). Detection of Military Targets on Ground and Sea by UAVs with Low-Altitude Oblique Perspective. Remote Sensing, 16(7), 1288. https://doi.org/10.3390/rs16071288