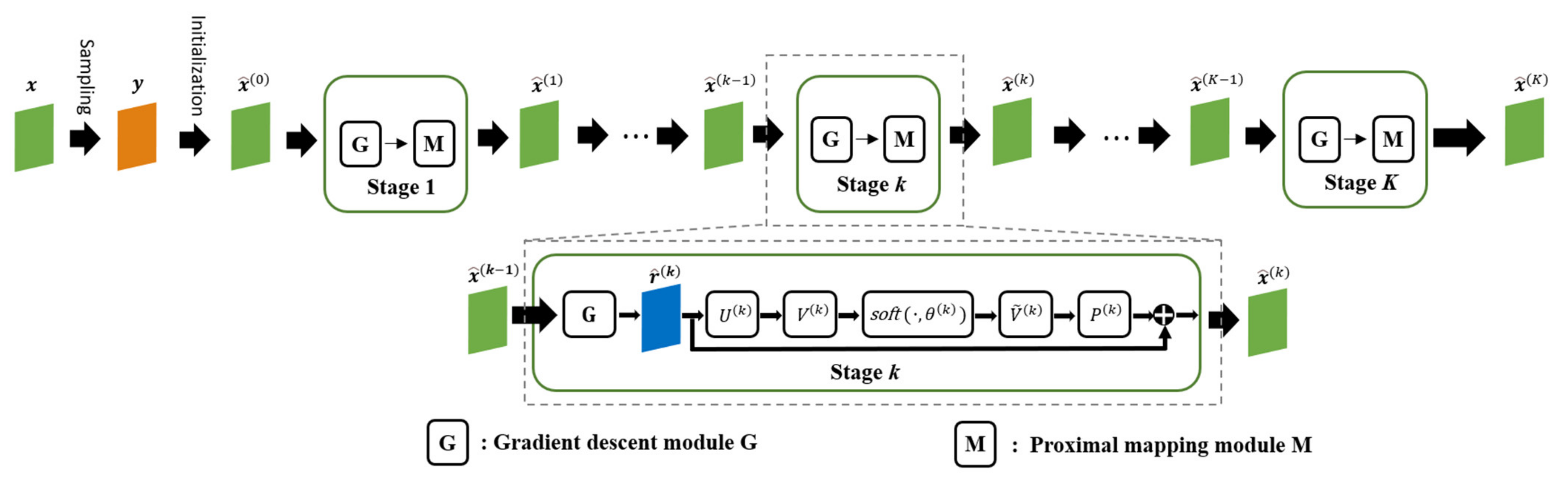
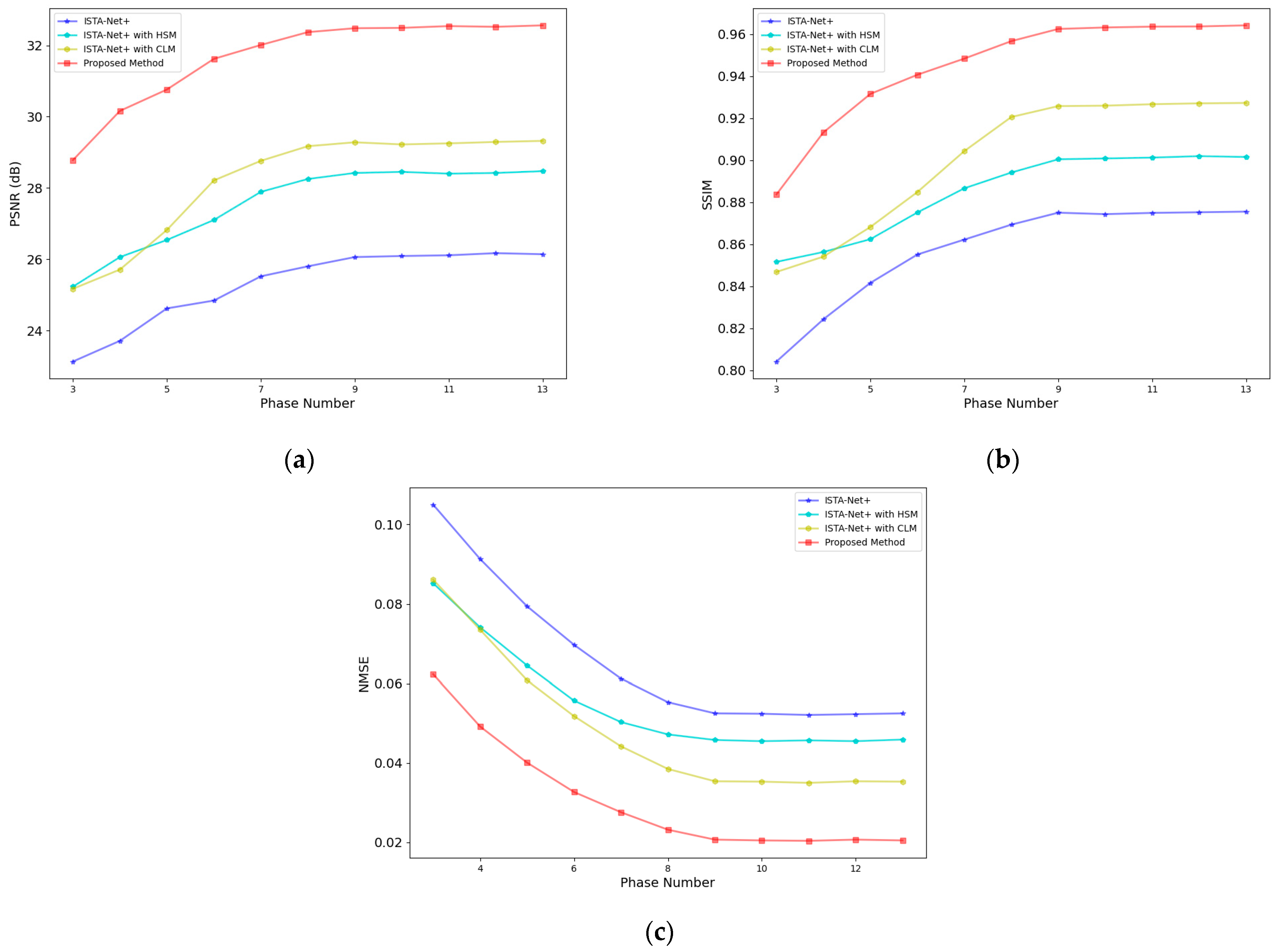
The deep unfolding network inspired by ISTA exhibits a sequential, stage-by-stage architecture. However, this design, characterized by single-channel information flow between stages, inadvertently leads to the omission of critical information, mirroring a shortfall in short-term memory capabilities. Moreover, the linear, cascaded structure that links the output of one stage directly to the input of the next can cause a progressive attenuation of information transfer. This effect hampers the effective transmission of vital features identified in earlier stages to later ones, indicative of a lack of a robust long-term memory mechanism. To address these limitations and bolster the network’s capacity for information retention across stages, the introduction of a memory enhancement mechanism is imperative. Such a mechanism is designed to amplify the network’s ability to leverage data correlations, thereby elevating the quality of SAR imaging outcomes.
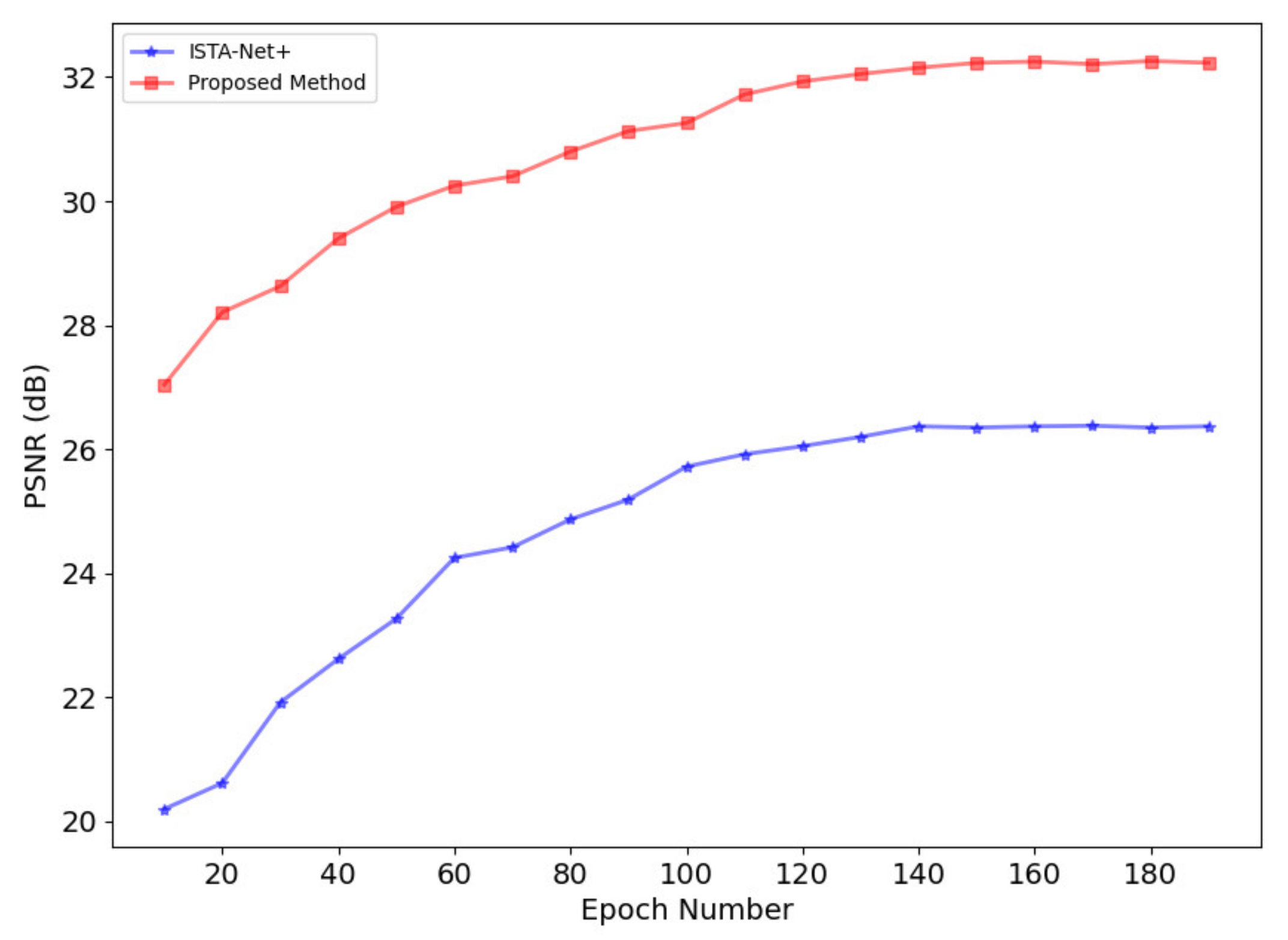
In response to this need, we introduce an innovative sparse SAR imaging algorithm embodied in a MADUN. Rooted in the ISTA-based deep unfolding framework, MADUN incorporates a novel memory enhancement feature. This algorithm enhances the traditional ISTA algorithm’s performance by integrating a deep learning framework and incorporating a memory augmentation mechanism. It represents an advanced hybrid method that synergizes convex optimization theory with deep learning techniques [
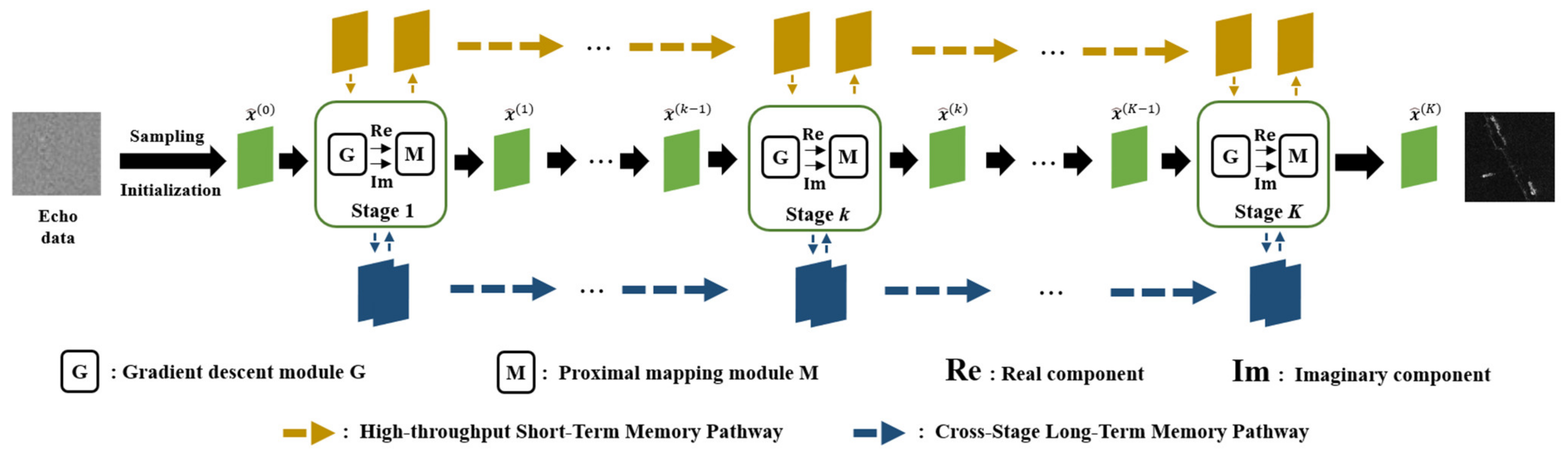
18]. As depicted in
Figure 2, the architecture of MADUN is composed of two core components: a gradient descent module and a proximal mapping module. The gradient descent module is tasked with independently processing the real and imaginary components of the radar signal. Concurrently, the proximal mapping module is designed to fortify both short-term and long-term memory through dual pathways. These pathways are intricately woven into the primary information flow, ensuring dynamic interaction at each stage. The short-term memory pathway aims to mitigate the loss of information during the transition between adjacent stages, whereas the long-term memory pathway is devoted to overcoming the absence of inter-stage connectivity. This approach, integrating dual memory enhancement mechanisms, not only preserves the integrity of information through successive stages, but also enhances the algorithm’s capacity to reconstruct high-fidelity SAR images by effectively utilizing the inherent correlations within the data.
2.3.2. Proximal Mapping Module Combined with Memory Enhancement Mechanisms
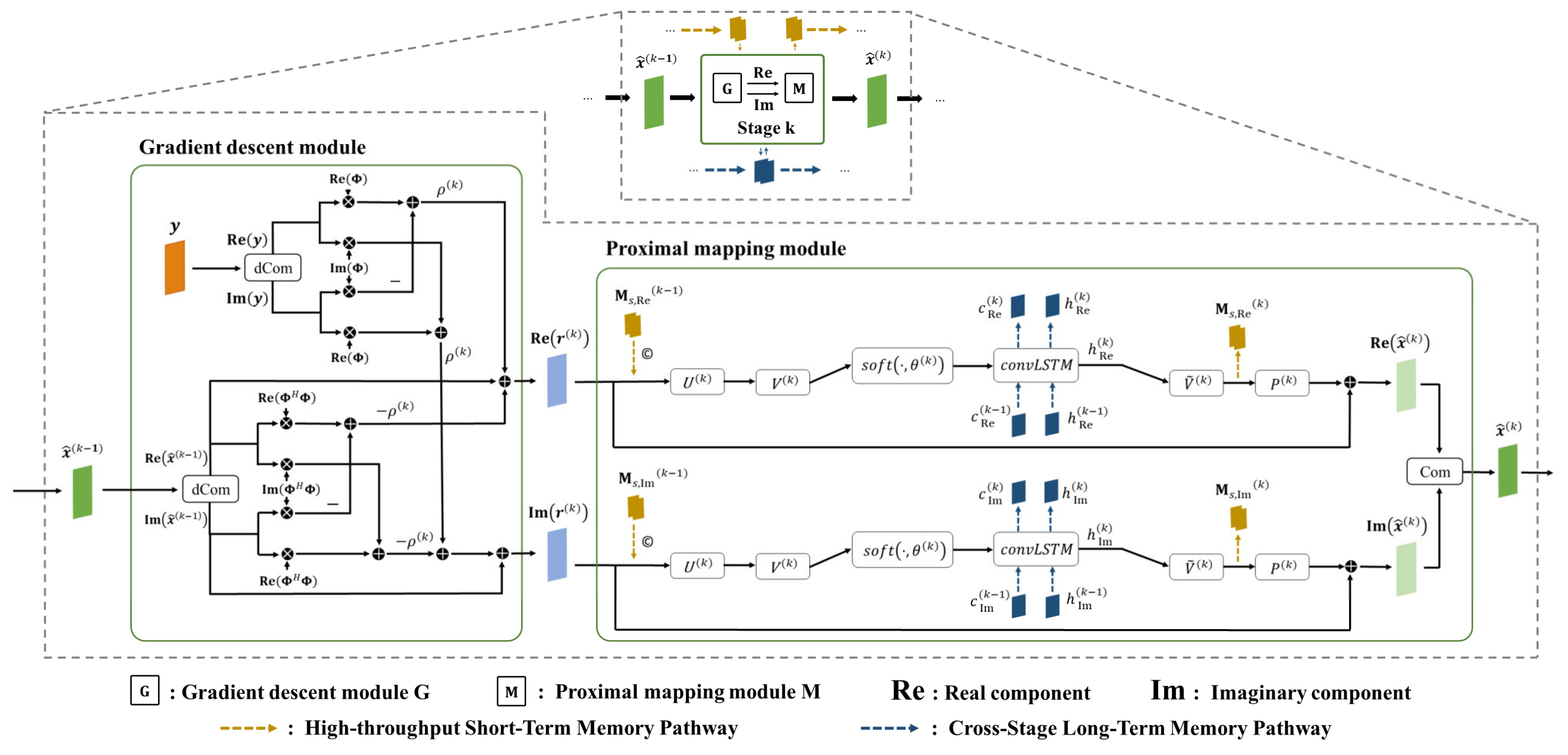
Considering the gradient mapping module’s role in bifurcating radar signals into their real and imaginary components, it is imperative for the subsequent proximal mapping module to individually process these constituents. The architecture of the proximal mapping module, endowed with dual memory augment strategies, is depicted in
Figure 3. The nonlinear transformation
is conceptualized as the synergy of two linear convolution operations and a ReLU function, specifically
, where both linear convolution operators
and
can be implemented by filter banks. Analogously,
is represented as
. The operators
and
denote a series of
filters, each with dimensions
.
is facilitated by a filter sized
, and
pertains to a collection of
filters, each measuring
. Short-term memory is integrated prior to
, being captured and stored before engagement with
. Long-term memory leverages a ConvLSTM [
19] mechanism, necessitating the inclusion of a ConvLSTM unit subsequent to the
. The default setting for
is 32.
A. High Throughput Short-term Memory
The short-term memory enhancement mechanism introduced, denoted as
, features dimensions
. This facilitates the storage of multi-channel information, where
and
denote the image’s height and width, respectively. Initially, the short-term memory mechanism generates feature maps from SAR echo data. Specifically, the echo data
, after being processed through the measurement matrix
, are passed through a single convolution layer to produce a
-channel feature map,
, as follows:
where
is a single convolution layer with a filter kernel size of
.
The HSM facilitates multi-channel information transmission across nearly every stage of the proximal mapping module. Its primary function at the current stage is to capture and preserve multi-channel feature information. Though information transmission between two adjacent stages remains single-channel, the feature information saved earlier is reintroduced at the next stage. This process ensures continuous high-throughput information transmission and significantly enhances the network’s short-term memory capabilities. As shown in
Figure 3, for stage k as an example,
can be represented as
where “
” denotes feature concatenation.
transmits high-throughput information from the previous level to the current one, where short-term memory
is concatenated with
along the channel dimension. After memory integration is completed, it passes through the deep unfolding network’s hierarchy in coordination with
and, after passing through the nonlinear transformation
, generates high-throughput information for stage
k, used in memory integration for stage
k + 1.
B. Cross-stage Long-term Memory
Since the ConvLSTM model can maintain continuity of information across cascaded stages, balancing past stored information with the current state, it establishes long-range cross-stage connections through ConvLSTM within CLM. Specifically, as depicted in
Figure 3, a ConvLSTM layer is interposed between the soft thresholding operation
and the nonlinear transformation
. Here, the output from the soft thresholding operation feeds into the ConvLSTM network, generating a combination of hidden states and memory cells,
:
We employed the architecture, where denotes convolution and represents the Hadamard product, with , ,…, as filter weights, , ,…, as biases, and and representing the sigmoid and tanh functions, respectively.
The input gate
is regulated by the current input
, the output from the preceding ConvLSTM module
, the module state
, and bias
:
The forget gate
decides which parts of the previous cell state
to forget:
The cell state
, acting as a state information accumulator, updates as follows:
The output gate
is described by:
The module output
, determined by the latest cell state
and output gate
, is:
This cross-stage long-term memory utilization is aimed at establishing dependencies from the initial stage through all subsequent stages of information flow, without the necessity of introducing additional memory information at the commencement of this path, allowing for to be initialized to zero. The dimensions of and are both . The output of the cross-stage long-term memory module for a given stage, , serves as the input to the nonlinear transformation on the main information flow path, and both and the latest cell state progress to stage k + 1 through the long-term memory mechanism, transmitting high-level features across different stages to bolster deep information association.
Consequently, the proximal mapping module, augmented with dual memory enhancement mechanisms, is articulated as:
where “||” denotes feature concatenation. At the end of the proximal mapping module, the results from both the real and imaginary components are combined,
, to obtain the reconstructed result for that stage.


 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}