

Remote Sensing Image Dehazing via a Local Context-Enriched Transformer



Abstract
1. Introduction
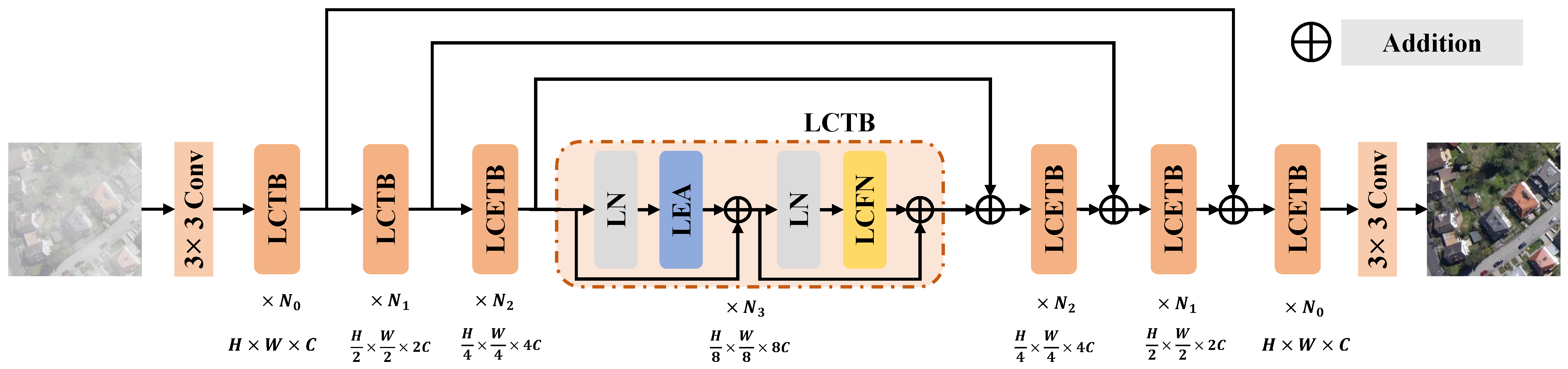
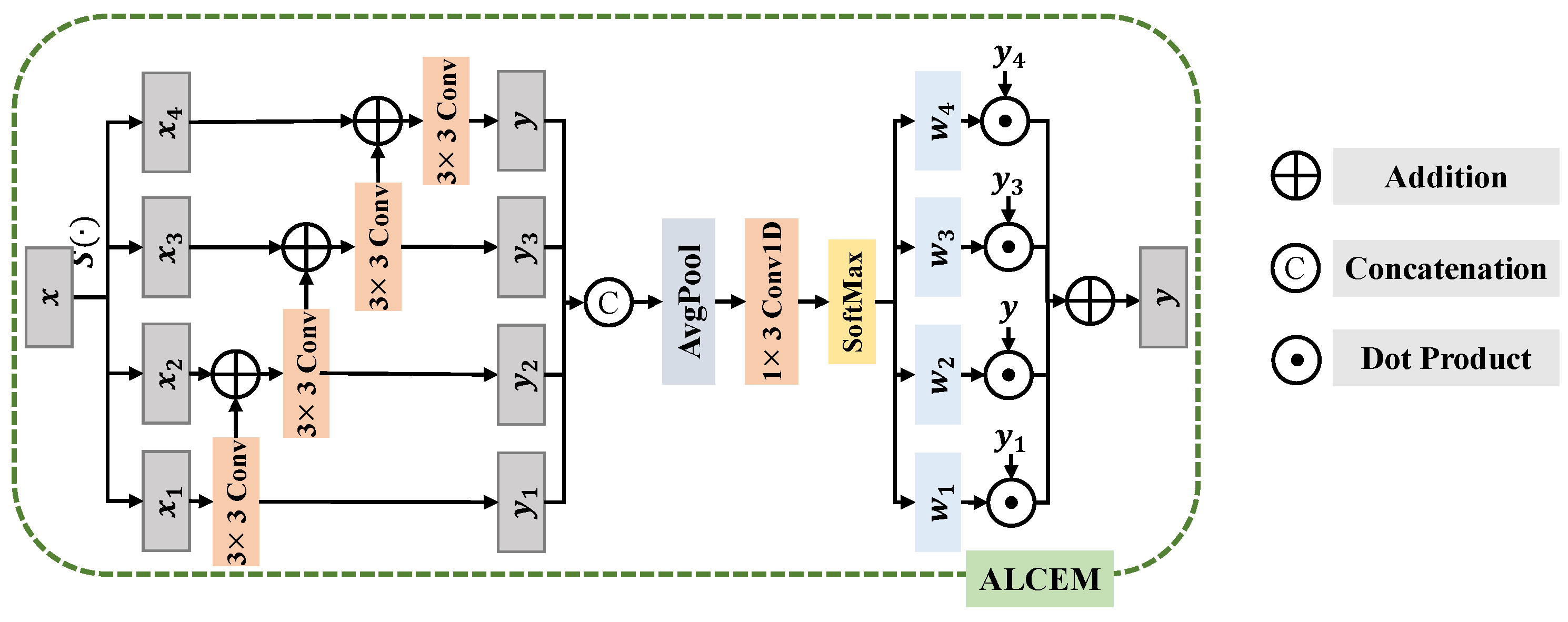
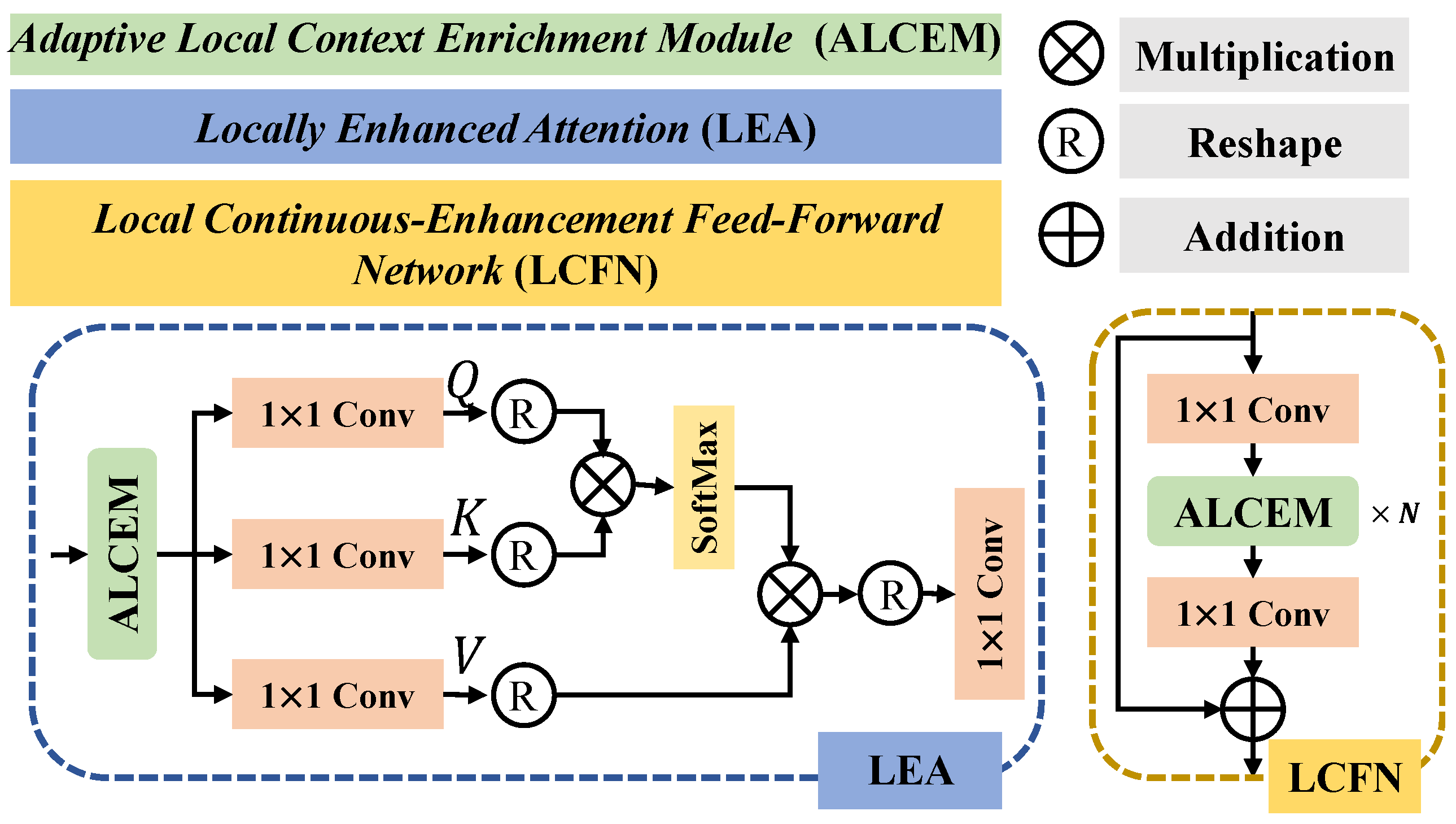
- We propose a novel transformer-based U-shape remote sensing dehazing network, namely Local Context-Enriched Transformer (LCEFormer). LCEFormer stacks local context-enriched transformer blocks (LCTBs), each comprising a locally enhanced attention (LEA) and a local continuous enhancement feed-forward network (LCFN). Both LEA and LCFN are equipped with an adaptive local context enrichment module (ALCEM) that extracts multi-scale local contextually enriched features and fuses them selectively.
- Different from the common self-attention module, the LEA module employs the ALCEM to extract more informative local context, thus enhancing the discriminative power of the query, key, and value vectors used for computing multi-head attention, which helps in effectively removing haze from the input image, resulting in cleaner results. In contrast to regular feed-forward networks that only perform position-specific information flow, our LCFN enriches multi-scale local context. This enhancement proves beneficial in refining regions by leveraging neighborhood information inference, resulting in cleaner outputs.
- We validate the effectiveness of the proposed LCEFormer by conducting comprehensive experiments on three remote image dehazing benchmarks: DHID [36], ERICE [37], and RSID [38]. Our LCEFormer outperforms existing image dehazing methods on both benchmarks. Additionally, to demonstrate the scalability of the proposed LCEFormer, experiments on the UCMERCED dataset [39] demonstrate that our LCEFormer achieves the state-of-the-art performance in the remote sensing image super-resolution task.
2. Related Work
2.1. Image Dehazing Methods
2.2. Vision Transformer
3. Method
3.1. Overall Pipeline
3.2. Local Context-Enriched Transformer Block
3.3. Loss Function
4. Experiments
4.1. Datasets and Evaluation Metrics
4.2. Training Details
4.3. Experimental Results
4.3.1. Results on the DHID Dataset
4.3.2. Results on the ERICE Dataset
4.3.3. Results on the RSID Dataset
4.3.4. Experimental Results on the Remote Sensing Image Super-Resolution
4.3.5. Qualitative Comparison
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wei, J.; Cao, Y.; Yang, K.; Chen, L.; Wu, Y. Self-Supervised Remote Sensing Image Dehazing Network Based on Zero-Shot Learning. Remote Sens. 2023, 15, 2732. [Google Scholar] [CrossRef]
- Yu, J.; Liang, D.; Hang, B.; Gao, H. Aerial image dehazing using reinforcement learning. Remote Sens. 2022, 14, 5998. [Google Scholar] [CrossRef]
- Jia, J.; Pan, M.; Li, Y.; Yin, Y.; Chen, S.; Qu, H.; Chen, X.; Jiang, B. GLTF-Net: Deep-Learning Network for Thick Cloud Removal of Remote Sensing Images via Global–Local Temporality and Features. Remote Sens. 2023, 15, 5145. [Google Scholar] [CrossRef]
- Saleem, A.; Paheding, S.; Rawashdeh, N.; Awad, A.; Kaur, N. A Non-Reference Evaluation of Underwater Image Enhancement Methods Using a New Underwater Image Dataset. IEEE Access 2023, 11, 10412–10428. [Google Scholar] [CrossRef]
- Paheding, S.; Reyes, A.A.; Kasaragod, A.; Oommen, T. GAF-NAU: Gramian Angular Field Encoded Neighborhood Attention U-Net for Pixel-Wise Hyperspectral Image Classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, New Orleans, LA, USA, 18–24 June 2022; pp. 409–417. [Google Scholar]
- Bazi, Y.; Bashmal, L.; Rahhal, M.M.A.; Dayil, R.A.; Ajlan, N.A. Vision transformers for remote sensing image classification. Remote Sens. 2021, 13, 516. [Google Scholar] [CrossRef]
- Zheng, X.; Sun, H.; Lu, X.; Xie, W. Rotation-invariant attention network for hyperspectral image classification. IEEE Trans. Image Process. 2022, 31, 4251–4265. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Jiang, W. OII: An Orientation Information Integrating Network for Oriented Object Detection in Remote Sensing Images. Remote Sens. 2024, 16, 731. [Google Scholar] [CrossRef]
- Xu, C.; Zheng, X.; Lu, X. Multi-level alignment network for cross-domain ship detection. Remote Sens. 2022, 14, 2389. [Google Scholar] [CrossRef]
- Xie, J.; Nie, J.; Ding, B.; Yu, M.; Cao, J. Cross-Modal Local Calibration and Global Context Modeling Network for RGB–Infrared Remote-Sensing Object Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 8933–8942. [Google Scholar] [CrossRef]
- Asokan, A.; Anitha, J. Change detection techniques for remote sensing applications: A survey. Earth Sci. Inform. 2019, 12, 143–160. [Google Scholar] [CrossRef]
- Zheng, X.; Chen, X.; Lu, X.; Sun, B. Unsupervised change detection by cross-resolution difference learning. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–16. [Google Scholar] [CrossRef]
- Ma, J.; Liu, D.; Qin, S.; Jia, G.; Zhang, J.; Xu, Z. An Asymmetric Feature Enhancement Network for Multiple Object Tracking of Unmanned Aerial Vehicle. Remote Sens. 2023, 16, 70. [Google Scholar] [CrossRef]
- Zheng, X.; Cui, H.; Lu, X. Multiple Source Domain Adaptation for Multiple Object Tracking in Satellite Video. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4702914. [Google Scholar] [CrossRef]
- Qi, L.; Zuo, D.; Wang, Y.; Tao, Y.; Tang, R.; Shi, J.; Gong, J.; Li, B. Convolutional Neural Network-Based Method for Agriculture Plot Segmentation in Remote Sensing Images. Remote Sens. 2024, 16, 346. [Google Scholar] [CrossRef]
- Paheding, S.; Reyes, A.A.; Rajaneesh, A.; Sajinkumar, K.; Oommen, T. MarsLS-Net: Martian Landslides Segmentation Network and Benchmark Dataset. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 4–8 January 2024; pp. 8236–8245. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2341–2353. [Google Scholar]
- Berman, D.; Avidan, S. Non-local image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1674–1682. [Google Scholar]
- Tan, R.T. Visibility in bad weather from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Fattal, R. Dehazing using color-lines. ACM Trans. Graph. 2014, 34, 13–31. [Google Scholar] [CrossRef]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. Dehazenet: An end-to-end system for single image haze removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef] [PubMed]
- Pang, Y.; Xie, J.; Li, X. Visual Haze Removal by a Unified Generative Adversarial Network. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 3211–3221. [Google Scholar] [CrossRef]
- Liu, X.; Ma, Y.; Shi, Z.; Chen, J. GridDehazeNet: Attention-Based Multi-Scale Network for Image Dehazing. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7313–7322. [Google Scholar]
- Hang, D.; Jinshan, P.; Zhe, H.; Xiang, L.; Fei, W.; Ming-Hsuan, Y. Multi-Scale Boosted Dehazing Network with Dense Feature Fusion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2157–2167. [Google Scholar]
- McCartney, E.J. Optics of the Atmosphere: Scattering by Molecules and Particles; John Wiley and Sons, Inc.: New York, NY, USA, 1976. [Google Scholar]
- Zhang, H.; Patel, V.M. Densely Connected Pyramid Dehazing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, X.; Jia, H. FFA-Net: Feature Fusion Attention Network for Single Image Dehazing. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; AAAI Press: Washington, DC, USA, 2020; pp. 11908–11915. [Google Scholar]
- Pang, Y.; Nie, J.; Xie, J.; Han, J.; Li, X. BidNet: Binocular image dehazing without explicit disparity estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020; pp. 5931–5940. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Wang, Z.; Cun, X.; Bao, J.; Liu, J. Uformer: A General U-Shaped Transformer for Image Restoration. arXiv 2021, arXiv:2106.03106. [Google Scholar]
- Song, Y.; He, Z.; Qian, H.; Du, X. Vision transformers for single image dehazing. IEEE Trans. Image Process. 2023, 32, 1927–1941. [Google Scholar] [CrossRef] [PubMed]
- Wu, P.; Pan, Z.; Tang, H.; Hu, Y. Cloudformer: A Cloud-Removal Network Combining Self-Attention Mechanism and Convolution. Remote Sens. 2022, 14, 6132. [Google Scholar] [CrossRef]
- Guo, C.; Yan, Q.; Anwar, S.; Cong, R.; Ren, W.; Li, C. Image Dehazing Transformer with Transmission-Aware 3D Position Embeddingn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5802–5810. [Google Scholar]
- Zhang, L.; Wang, S. Dense Haze Removal Based on Dynamic Collaborative Inference Learning for Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5631016. [Google Scholar] [CrossRef]
- Lin, D.; Xu, G.; Wang, X.; Wang, Y.; Sun, X.; Fu, K. A remote sensing image dataset for cloud removal. arXiv 2019, arXiv:1901.00600. [Google Scholar]
- Chi, K.; Yuan, Y.; Wang, Q. Trinity-Net: Gradient-Guided Swin Transformer-Based Remote Sensing Image Dehazing and Beyond. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4702914. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Li, B.; Peng, X.; Wang, Z.; Xu, J.; Feng, D. Aod-net: All-in-one dehazing network. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4770–4778. [Google Scholar]
- Wang, Z.; Cun, X.; Bao, J.; Zhou, W.; Liu, J.; Li, H. Uformer: A general u-shaped transformer for image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17683–17693. [Google Scholar]
- Dong, J.; Pan, J. Physics-based feature dehazing networks. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 188–204. [Google Scholar]
- Wang, J.; Wu, S.; Xu, K.; Yuan, Z. Frequency Compensated Diffusion Model for Real-scene Dehazing. arXiv 2023, arXiv:2308.10510. [Google Scholar] [CrossRef]
- Xu, M.; Deng, F.; Jia, S.; Jia, X.; Plaza, A.J. Attention mechanism-based generative adversarial networks for cloud removal in Landsat images. Remote. Sens. Environ. 2022, 271, 112902. [Google Scholar] [CrossRef]
- Enomoto, K.; Sakurada, K.; Wang, W.; Fukui, H.; Matsuoka, M.; Nakamura, R.; Kawaguchi, N. Filmy cloud removal on satellite imagery with multispectral conditional generative adversarial nets. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 48–56. [Google Scholar]
- Tao, C.; Fu, S.; Qi, J.; Li, H. Thick Cloud Removal in Optical Remote Sensing Images Using a Texture Complexity Guided Self-Paced Learning Method. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5619612. [Google Scholar] [CrossRef]
- Wang, W.; Xie, E.; Li, X.; Fan, D.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 548–558. [Google Scholar]
- Zhang, Q.; Yang, Y.B. ResT: An Efficient Transformer for Visual Recognition. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 7–10 December 2021. [Google Scholar]
- Liu, J.; Yuan, H.; Yuan, Z.; Liu, L.; Lu, B.; Yu, M. Visual transformer with stable prior and patch-level attention for single image dehazing. Neurocomputing 2023, 551, 126535. [Google Scholar] [CrossRef]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient Transformer for High-Resolution Image Restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Charbonnier, P.; Blanc-Feraud, L.; Aubert, G.; Barlaud, M. Two deterministic half-quadratic regularization algorithms for computed imaging. In Proceedings of the 1st International Conference on Image Processing, Austin, TX, USA, 13–16 November 1994; Volume 2, pp. 168–172. [Google Scholar]
- Huang, B.; Li, Z.; Yang, C.; Sun, F.; Song, Y. Single Satellite Optical Imagery Dehazing using SAR Image Prior Based on conditional Generative Adversarial Networks. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020; pp. 1795–1802. [Google Scholar]
- MMagic Contributors. MMagic: OpenMMLab Multimodal Advanced, Generative, and Intelligent Creation Toolbox. 2023. Available online: https://github.com/open-mmlab/mmagic (accessed on 24 February 2024).
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in PyTorch. In Proceedings of the NIPS workshop, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic gradient descent with warm restarts. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Yang, H.H.; Yang, C.H.H.; James Tsai, Y.C. Y-Net: Multi-Scale Feature Aggregation Network With Wavelet Structure Similarity Loss Function For Single Image Dehazing. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtual, 4–9 May 2020; pp. 2628–2632. [Google Scholar]
- Li, Y.; Chen, X. A Coarse-to-Fine Two-Stage Attentive Network for Haze Removal of Remote Sensing Images. IEEE Geosci. Remote. Sens. Lett. 2021, 18, 1751–1755. [Google Scholar] [CrossRef]
- Wang, S.; Wu, H.; Zhang, L. Afdn: Attention-Based Feedback Dehazing Network For Uav Remote Sensing Image Haze Removal. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 3822–3826. [Google Scholar]
- Zheng, Z.; Ren, W.; Cao, X.; Hu, X.; Wang, T.; Song, F.; Jia, X. Ultra-high-definition image dehazing via multi-guided bilateral learning. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 16180–16189. [Google Scholar]
- Lei, S.; Shi, Z. Hybrid-scale self-similarity exploitation for remote sensing image super-resolution. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5401410. [Google Scholar] [CrossRef]
- Yang, J.; Wright, J.; Huang, T.S.; Ma, Y. Image super-resolution via sparse representation. IEEE Trans. Image Process. 2010, 19, 2861–2873. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 391–407. [Google Scholar]
- Lei, S.; Shi, Z.; Zou, Z. Super-resolution for remote sensing images via local–global combined network. IEEE Geosci. Remote. Sens. Lett. 2017, 14, 1243–1247. [Google Scholar] [CrossRef]
- Haut, J.M.; Paoletti, M.E.; Fernández-Beltran, R.; Plaza, J.; Plaza, A.; Li, J. Remote sensing single-image superresolution based on a deep compendium model. IEEE Geosci. Remote. Sens. Lett. 2019, 16, 1432–1436. [Google Scholar] [CrossRef]
- Qin, M.; Mavromatis, S.; Hu, L.; Zhang, F.; Liu, R.; Sequeira, J.; Du, Z. Remote sensing single-image resolution improvement using a deep gradient-aware network with image-specific enhancement. Remote Sens. 2020, 12, 758. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | # of Train | # of Test | Resolution |
|---|---|---|---|
| DHID [36] | 14,490 | 500 | |
| ERICE [37] | 1600 | 400 | |
| RSID [38] | 1760 | 100 | , |
| Type | Method | PSNR | SSIM |
|---|---|---|---|
| CNN-based | Y-Net [57] | 18.31 | 0.783 |
| FCTF-Net [58] | 18.77 | 0.794 | |
| AFDN [59] | 20.03 | 0.803 | |
| DCIL [36] | 28.18 | 0.892 | |
| Transformer | DehazeFormer [33] | 26.29 | 0.889 |
| CNN + Transformer | Dehamer [35] | 26.19 | 0.886 |
| LCEFormer | 28.96 | 0.910 |
| Methods | PSNR | SSIM |
|---|---|---|
| SRA [47] | 28.39 | 0.907 |
| MDTA [50] | 28.75 | 0.910 |
| LEA | 28.96 | 0.910 |
| Methods | PSNR | SSIM |
|---|---|---|
| FN [31] | 26.86 | 0.898 |
| LeFF [32] | 28.01 | 0.905 |
| GDFN [50] | 28.17 | 0.906 |
| LCFN | 28.96 | 0.910 |
| Type | Method | PSNR | SSIM |
|---|---|---|---|
| CNN | GridDehaze [23] | 35.03 | 0.954 |
| Transformer | Uformer [41] | 34.14 | 0.954 |
| DehazeFormer [33] | 36.49 | 0.958 | |
| CNN + Transformer | Dehamer [35] | 33.43 | 0.953 |
| LCEFormer | 37.23 | 0.965 |
| Type | Method | PSNR | SSIM |
|---|---|---|---|
| CNN | FCTF-Net [58] | 19.31 | 0.856 |
| FFANet [27] | 24.05 | 0.899 | |
| UHD [60] | 26.66 | 0.923 | |
| CNN + Transformer | Dehamer [35] | 23.75 | 0.899 |
| Trinity-Net [38] | 27.24 | 0.934 | |
| LCEFormer | 27.55 | 0.960 |
| Method | PSNR | SSIM |
|---|---|---|
| Bicubic | 25.65 | 0.673 |
| SC [62] | 25.51 | 0.715 |
| SRCNN [63] | 26.78 | 0.722 |
| FSRCNN [64] | 26.93 | 0.727 |
| LGCNet [65] | 27.02 | 0.733 |
| DCM [66] | 27.22 | 0.753 |
| DGANet-ISE [67] | 27.31 | 0.767 |
| HSENet [61] | 27.73 | 0.762 |
| LCEFormer | 27.80 | 0.774 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nie, J.; Xie, J.; Sun, H. Remote Sensing Image Dehazing via a Local Context-Enriched Transformer. Remote Sens. 2024, 16, 1422. https://doi.org/10.3390/rs16081422
Nie J, Xie J, Sun H. Remote Sensing Image Dehazing via a Local Context-Enriched Transformer. Remote Sensing. 2024; 16(8):1422. https://doi.org/10.3390/rs16081422
Chicago/Turabian StyleNie, Jing, Jin Xie, and Hanqing Sun. 2024. "Remote Sensing Image Dehazing via a Local Context-Enriched Transformer" Remote Sensing 16, no. 8: 1422. https://doi.org/10.3390/rs16081422
APA StyleNie, J., Xie, J., & Sun, H. (2024). Remote Sensing Image Dehazing via a Local Context-Enriched Transformer. Remote Sensing, 16(8), 1422. https://doi.org/10.3390/rs16081422