1. Introduction
Wetlands play an important role in global climate models as both carbon stores and methane (CH
4) emitters. They represent the largest single natural source of CH
4 [
1], accounting for 20%–45% of total emissions [
2]. As CH
4 has 25-times the global warming potential of carbon dioxide (CO
2) [
1] and current models predict increased CH
4 emissions from wetland areas in response to rising CO
2 emissions [
2,
3], a better understanding of current emissions and changes in response to climate change is particularly important. In addition to their role in the global greenhouse gas cycle, wetlands are home to a number of plant and animal species and are important to the hydrological cycle [
4].
Although temperatures are increasing globally, in the Arctic, they have been increasing at a rate almost double the average, due to what is known as “Arctic amplification” [
5]. In the state of Alaska, accelerated warming has been observed between 1970 and 2000 [
6]. In subsequent years, temperatures have continued to rise in northern Alaska, although a decrease in temperature has been observed in the south [
7]. This disproportionate increase in temperatures, at high latitudes in general and in Alaska in particular, makes Alaskan wetlands especially vulnerable to climate change.
It has been estimated that wetlands cover 43% of the surface area of Alaska [
4], representing a greater total area of wetlands than in all of the conterminous United States (U.S.) [
8]. High-resolution maps are critical to understanding the response of wetlands to climate change [
9]. Maps produced decadally, in sufficient detail with respect to the Cowardin
et al. [
10] wetland classification scheme, have been recognized as being beneficial for CO
2 budgets [
8]. To generate maps meeting these requirements, it is necessary to develop a methodology that can be applied to produce maps for multiple years, as required for a monitoring system [
11]. As different types of wetlands sequester and emit at different rates [
8], it is important to discriminate between wetland types in mapping efforts. This is particularly important for monitoring changes in wetland type, with previous studies noting increases in shrub abundance [
12], a reduction in size or loss of water bodies [
13,
14] and drying of wetland areas [
15] within Alaska.
The use of spaceborne synthetic aperture radar (SAR) provides a number of advantages for mapping and monitoring the extent and type of wetlands over large areas and at a relatively high spatial resolution (20–100 m), including the ability to acquire data regardless of illumination conditions or cloud cover and a sensitivity to vegetation structure and moisture content, particularly at L-band wavelengths [
16]. Although the use of remote sensing has been established in mapping wetlands in the United States, through the National Wetlands Inventory (NWI) [
17,
18], the methodological approach has primarily been through manual interpretation of aerial photographs. Photointerpretation is a time-consuming process, making it costly to generate maps over large areas, particularly if they need to be updated regularly. Therefore, more automated techniques are required. There are a number of algorithms available that can be applied to generate thematic maps from remotely-sensed data. These include unsupervised (e.g., k-means and ISODATA), supervised (e.g., maximum likelihood), rule or knowledge-based [
19,
20] and machine learning approaches (e.g., support vector machines). Random forests [
21] is a machine learning approach capable of handling discrete (thematic) and continuous input data. Fernandez-Delgado
et al. [
22] compared a large number of classification algorithms and implementations and found random forests to produce the best accuracy across a number of datasets. Random forests has previously been used for classifying remotely-sensed data in a number of studies (e.g., [
23,
24]) and has demonstrated the capability to generate classifications with a high accuracy. A particular advantage of random forests over other machine learning algorithms, such as support vector machines (SVM), is that it only requires a small number of tuning parameters [
25] and is computationally efficient. Random forests was applied by Whitcomb
et al. [
26] to data from the Japanese Earth Resources Satellite (JERS-1) and ancillary layers to derive a map of wetlands in Alaska and was found to produce maps with a higher accuracy than applying unsupervised (ISODATA) and supervised (maximum likelihood) algorithms. Following from the successful application of random forests to map wetlands from JERS-1 data and ancillary data [
26], subsequent studies focused on applying the same method to data from the Phased-Array L-band SAR (PALSAR) carried onboard the Advanced Land Orbiting Satellite (ALOS) [
27] and expanding the technique to also include wetlands in Canada [
28].
Although the original [
26] classification in Alaska and subsequent work demonstrated that the technique was capable of providing highly accurate (
~90%) maps of wetland type and represented a significant improvement over existing mapping in the area, the approach had a number of limitations that needed to be addressed. One major problem was that the method necessitated breaking the mosaic into sixteen tiles. For each tile, a separate “random forest” was generated from training data within that tile and applied. This meant that only those classes for which training data fell within the tile were considered; any other classes were omitted. Given that a separate classification, with a different subset of classes, was applied for each tile, discontinuities became apparent when the classified tiles were combined to create the mosaicked map. These problems persisted in subsequent attempts to classify small regions of PALSAR imagery using the methodology presented in Whitcomb
et al. [
26], such that production of a complete map for Alaska with the code of [
26] would not have been possible. Whitcomb
et al. [
27] thus presented PALSAR classification results only for key areas. In Clewley
et al. [
11], the code used for pre-processing and classification was re-written to address these and other limitations, resulting in a greatly improved software suite, particularly as regards the manipulation of large datasets. The updated software was used to produce an improved map derived from JERS-1 data and ancillary data and an initial map from ALOS PALSAR data and ancillary data, both at 100-m spatial resolution.
Building on previous work [
11,
26], this study has aimed to produce an enhanced classification of vegetated wetlands in Alaska based on ALOS PALSAR data from 2007 and ancillary data at a higher spatial resolution than existing maps. The method presents a number of improvements to that of Whitcomb
et al. [
26], both to the input and training data (described in Section 3) and to the method of applying random forests to the entire state at once by using stratified sampling (described in Section 4). This classification was then used to provide an estimate of the extent of vegetated wetlands in Alaska, as of 2007, and the proportion within each wetland class.
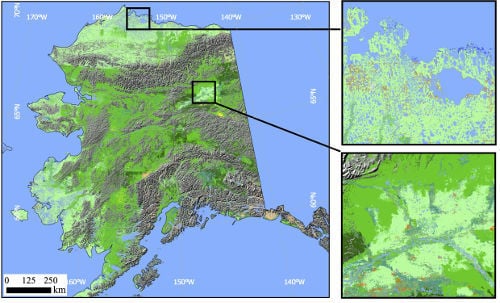
2. Study Area
Alaska, which spans latitudes from 51° to 72°N, is the largest state in the United States with a total surface area of over 1.6 million km
2 [
4] and more than 53,000 km of shoreline [
29]. The range of latitudes within Alaska leads to variations in climate spanning arctic to subarctic conditions. Permafrost is an important feature of Alaska, with continuous permafrost occurring in the north and discontinuous or sporadic permafrost further south [
29].
Alaska can be divided into seven broad physiographic units: (1) northwest Alaska, with moist and wet tundra types (
Eriophorum spp.), ericaceous shrub polygons and saline meadows; (2) arctic Alaska, which includes extensive wet tundra and wet sedge meadows (
Eriophorum angustifolium and
Carex aquatilis); (3) south-central Alaska, which ranges from the peaks of the Alaska Range to coastal marshes and includes forest cover with extensive areas of black spruce muskeg; (4) southwest Alaska, which includes wet sedge meadows, halophytic wet meadows and wet shrub tundra; (5) southeast Alaska, where forest cover includes extensive regions of black spruce muskeg with halophytic and freshwater sedge and wet meadows dominated by
C. lyngbyei on coastal deltas; (6) interior Alaska, with extensive black spruce muskeg forest cover, subarctic lowland sedge and sedge-moss bog meadows; and (7) the Aleutian Islands, where the most widespread community is
Empetrum heath [
30].
6. Discussion
6.1. Significant Improvements to Existing Mapping
Although the idea of applying random forests to a combination of L-band SAR data and ancillary layers was initially proposed in a Whitcomb
et al. [
26] study investigating the application of JERS-1 data and ancillary information for mapping wetlands in Alaska, the current study has broken new ground through the development of an entirely new software suite that addressed a host of unresolved issues that had plagued the earlier study and thereby allowed the production of a more accurate map of vegetated wetlands in Alaska.
Firstly, the current study employed higher quality input data than that used in the 2009 study. Its ALOS PALSAR data exhibited much better geometric and radiometric accuracy than did the JERS-1 data used in [
26]. The PALSAR data were also available at a higher spatial resolution than had been used in the JERS-1 mosaics of the previous study, thereby enabling us to produce a wetlands map with 2:1 better spatial resolution than our previous wetlands map. Improvements to the quality of ancillary data layers were also utilized, namely the NED DEM [
39,
40], which was a vast improvement over the previous elevation data available for Alaska. Improvements were also made to the training data through the inclusion of newly available quadrangles of NWI data and the use of the NLCD data for non-wetland areas, which was standardized across the state, rather than region-specific data from the Alaska Geospatial Data Clearinghouse.
The study also benefited from an overhaul of the classification method, as first outlined in Clewley
et al. [
11]. A major advance was the choice to generate and apply a single random forest model for the entire state using a stratified sample of training pixels rather than applying the classification to sixteen separate tiles using all available training pixels for each tile. This improvement compensated for a large disparity in the number of samples available for each class, which had caused sparse classes to be underrepresented in the [
26] classification, while also eliminating what had been quite prominent tile boundary discontinuities in the classification. Additional enhancements over previous work included improved PALSAR swath processing that nearly eliminated what had been prominent swath edge anomalies, correction of substantial errors in the slope data layer, planar-regression filtering to reduce the effects of DEM terracing on the slope data layer, addition of a longitude data layer and addition of a coniferous uplands class. As a consequence of all of these improvements, an assessment with points verified using high-resolution optical data demonstrated a greatly improved accuracy of 94%, compared to 48.6% for the map of Whitcomb
et al. [
26].
The software developed for the current study, which exploited a newly-developed compressed file format, was many times more efficient in the handling of large datasets than that used in the [
26] study. This, in combination with more direct and flexible interface processing, establishes a solid baseline from which future high-resolution wetlands maps can be quickly developed.
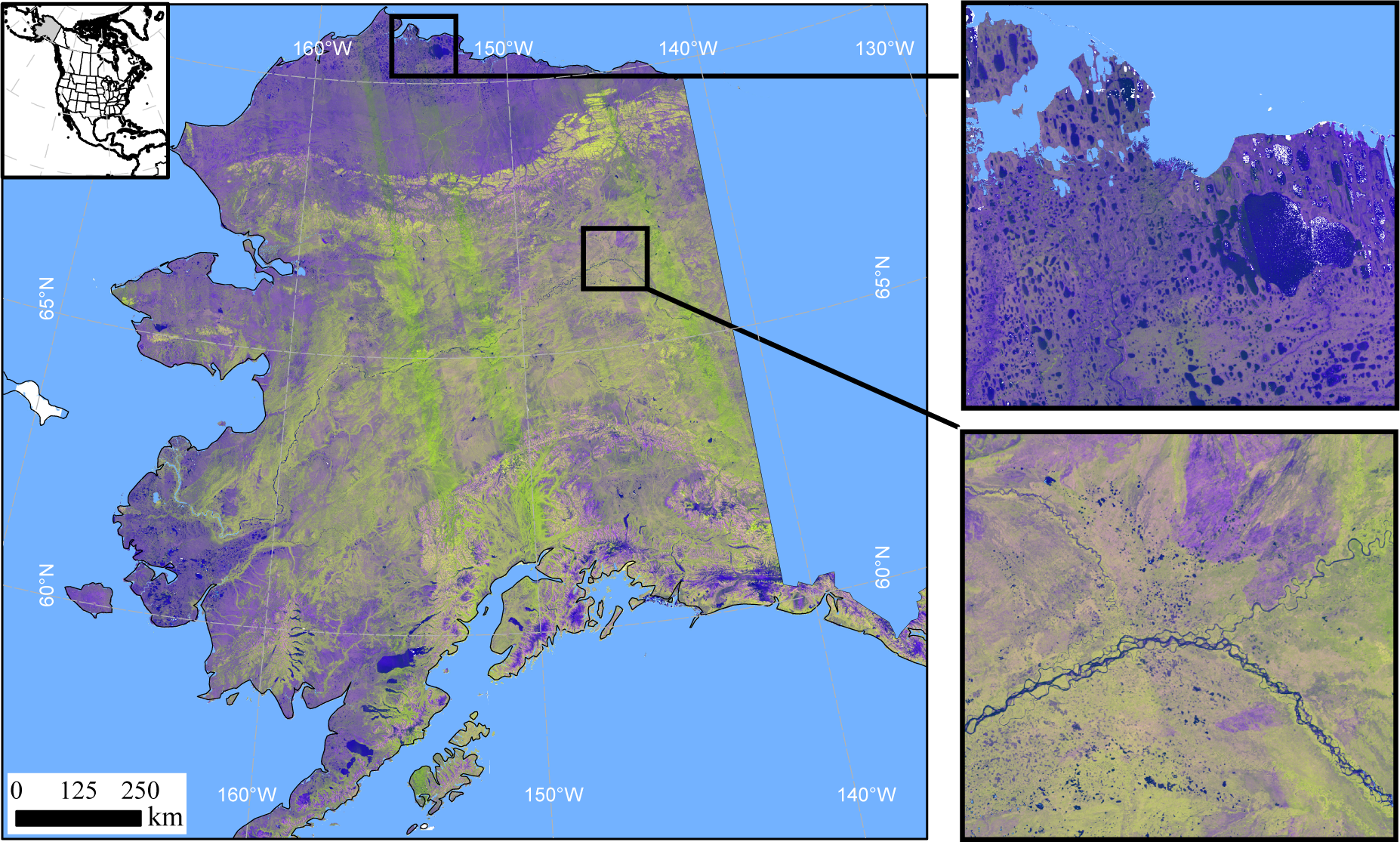
6.2. Wetlands Area
The total wetlands area of 585,400 km
2 (35.9%) is lower than the estimated 688,800 km
2 (42.2%) reported for vegetated wetlands by Hall
et al. [
4], but is much larger than the 410,000 km
2 (26.3%) provided by Whitcomb
et al. [
26]. However, the quality of the DEM and the commercial routine used for the slope calculation by Whitcomb
et al. [
26] in the earlier classification led to substantial areas of wetlands being masked out [
58]. The revised map of vegetated wetlands derived from JERS-1 data and ancillary data [
11] used an improved DEM and slope calculation method and mapped a total of 613,800 km
2 of wetlands, following correction for bias due to classification errors [
55]. This revised JERS-1-derived estimate of wetlands area represents a more accurate estimate of the extent of vegetated wetlands in Alaska in the 1990s based on comparison with other studies (e.g., [
8]).
Despite some correction for areal bias using the confusion matrix, there likely are errors in both areal estimates and the effects of different spatial resolutions used for the JERS-1 classification (100 m) and the PALSAR classification presented here (50 m), which need to be quantified before developing a baseline estimate of changes in wetland extent between the 1990s and 2000s. The development of techniques to better understand these errors will be the focus of future work and will enable changes in wetland type and extent within Alaska to be better understood.
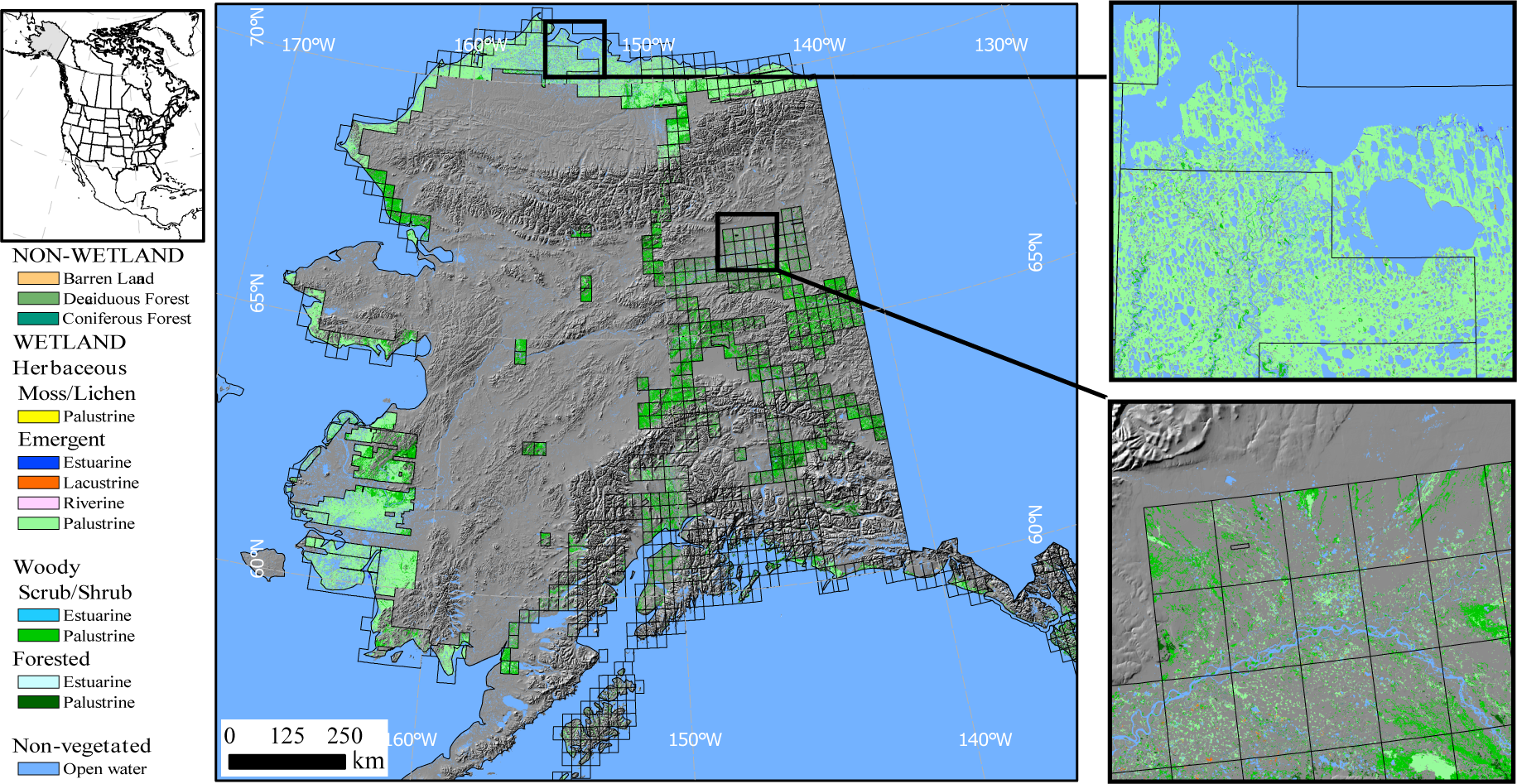
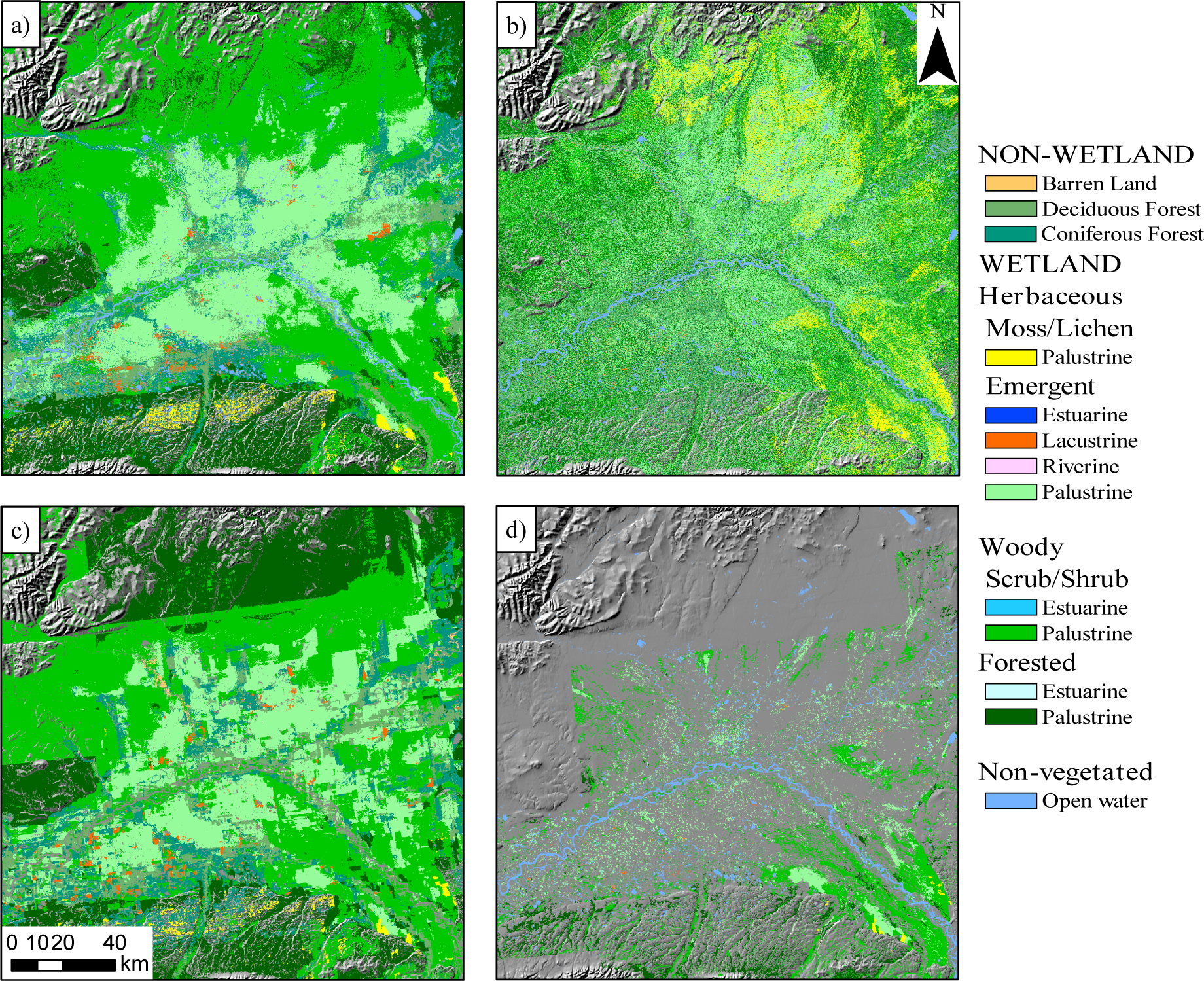
6.3. Comparison with 1990s Map
The map was visually compared with both the original map of Whitcomb
et al. [
26] and the updated version of Clewley
et al. [
11], with reference to historical optical data available through GoogleEarth, primarily from the Landsat program. A number of ponds classified in the JERS-1-derived classification [
11,
26] had either shrunk or disappeared altogether. The shrinking of ponds has also been noted in other studies (e.g., [
13,
14]), with degradation of the permafrost layer leading to lake drainage identified as a possible cause.
The percentage of wetlands in each class was compared with the JERS-1-derived classification [
11], with the largest changes being a 1.9% increase in the proportion of palustrine forested wetlands and a 1.8% decrease in the proportion of palustrine emergent wetlands between the 1998 (JERS-1) and 2007 (PALSAR) products. An increase in shrub abundance, as well as an increase in the extent and density of spruce forest, has been previously noted in Alaska [
12].
When comparing changes between the 1990s map and the current product, it is important to separate differences in classes due to inter-annual variability and long-term trends. Given that both maps present only a snapshot at a particular time with a gap of nearly ten years, additional data are required for change analysis. For example, incorporating higher temporal resolution data from the Moderate Resolution Imaging Spectroradiometer (MODIS) instrument [
59] with our wetland mapping procedures might be an option.
6.4. Importance of SAR Data
When considering the overall importance, across all classes, the positional and elevation layers were found to be more important than the PALSAR-derived layers in terms of the decrease in the Gini impurity index. By separating the importance by class, it was found the PALSAR-derived layers were most important for distinguishing the palustrine emergent class, which made up nearly 40% of the area mapped.
Despite the PALSAR-derived data layers being assigned a lower importance within the random forests classification than the topographic and position layers, the latter “static” layers provide only an approximation of where wetlands are likely to occur. It is possible to derive a map using only these static layers, but the map will contain no dynamic component and, thus, provide no way to monitor long-term wetland dynamics. The SAR data used in our classification provided information from a given time period that refined the classification. As only points where there had been no change in wetland type were used for evaluating accuracy, there was little difference in overall accuracy when all data layers were included (94%), compared to when only non-PALSAR layers were used (95.5%). If more dynamic areas were considered as part of the accuracy assessment, we would expect to see lower accuracy for classification runs where PALSAR data were excluded.
Although we encountered problems inherent in the use of SAR data, namely variations in backscatter between strips due to variations in environmental conditions, SAR data offered a number of benefits over optical Earth observation data. For example, over 85% of the PALSAR data used for the classification was acquired during a single year (2007), most of which were from a single season (summer). Data over a much longer time period would be required to produce a cloud-free mosaic of optical data at an equivalent resolution for the entire state of Alaska.
6.5. Limitations of Approach
Both the NWI and NLCD datasets used to train the classification had errors associated with them that likely influenced the accuracy of the classification. These errors include inaccuracies in the original mapping and changes that have occurred in the 30–40 years since the NWI maps were produced. Given the large areas covered by both datasets and ongoing changes in the Alaskan landscape, identifying which areas of training data were correct or incorrect is difficult. One approach would be to select a small number of training samples and to compare them manually with aerial photography or high-resolution satellite data from around the period for which the classification is being produced (2007 in our case) to confirm that they are an accurate representation of classes for the study period. This is labor intensive, and for the current study, we could check only a small number of training points using this method. An alternative is to use a large number of training samples, of which a proportion will be incorrect, and reserve points that have been verified for validation. The impact of the incorrect training samples will depend on the classification method used. Random forests is relatively robust to outliers and noise in the training data [
21], provided sufficient samples are available. Therefore, the approach adopted here was to use a large amount of training data that undoubtedly contained some errors, rather than a very small amount of well-validated training data.
A large factor determining the amount of wetlands mapped with the method proposed was the slope threshold used to mask out non-wetland areas. We followed the method used by Whitcomb
et al. [
26]; however, as was noted in Hall
et al. [
4], wetlands are also likely to occur on slopes, particularly north-facing slopes, due to the presence of permafrost. Therefore, refinement of the method used for the initial wetland/upland split is required.
Although the classification method can incorporate SAR data from multiple seasons (as in [
26], where summer and winter JERS-1 data were used), only summer data were used here, as no PALSAR data from other seasons were obtainable. If PALSAR data from other seasons, or multi-season data from another sensor, became available, the new data could easily be incorporated into the random forests classification algorithm and would be expected to increase the accuracy of the classification.
6.6. Future Work
Although an initial comparison has been made between the current map produced from ALOS PALSAR and ancillary data and the 1990s map produced using JERS-1 data and ancillary data [
11,
26], work is ongoing to further quantify the uncertainty associated with both datasets and the implications for detecting change. We continue to improve the quality of our wetland mapping, especially in relation to improving discrimination of wetland/non-wetland vegetation types.
The use of geographic object-based image analysis (GEOBIA) for classification has been increasing in popularity in recent years [
20,
60,
61]. Applying the random forests-based classification described here at the object level is one area for evaluation. The use of GEOBIA is expected to become more relevant as higher resolution data become available. One particular advantage of GEOBIA is that the polygon classification output is closer to the classification produced from air photo interpretation (e.g., the NWI dataset).
In addition to developing ways to improve the accuracy of the existing classification, future work will continue the time series using the next generation of Earth observation data. The successor to ALOS, ALOS-2, was launched in May 2014 and will provide a continued time series of L-band SAR data, allowing continued monitoring of wetland areas in Alaska.
We also hope to assess the improvement in classification accuracy achievable through the incorporation of C-band SAR data, which could be expected to enhance performance for the herbaceous vegetation classes.



 and
and 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}