1. Introduction
Increasing the availability of digital pathology opens new possibilities. Digital whole slide images (WSIs) stored on servers are easily retrieved for review by pathologists. Viewing serial WSIs from the same patient side-by-side enables the pathologist to assess the morphology and protein expression at the same time, as opposed to swapping the slides back-and-forth when viewing with a microscope. As a bonus, the field of view is vastly increased compared to the ~1000-μm circle offered at 400× in a microscope. Further, residents in pathology may demark areas of interest and pass these to consultant pathologists for feedback and learning.
Although digital pathology will optimize the current work flows, computational pathology is by many believed to be one of its most significant advantages. A standard three-channel WSI is approximately 100,000 × 100,000 pixels. This represents an enormous amount of information that may be used to identify, and subsequently quantify, macro- (patches of cartilage and bone, islets of cancer or vessels); intermediate- (different types of cells) and micro-structures (different cellular components). Whilst some of this information is utilized in classical light microscopy, important information is likely discarded. Moreover, image features, abstract to the human mind, may be extracted and incorporated as biomarkers into existing diagnostic pipelines, expanding the prognostic and predictive toolkit. An additional benefit may be a reduction of intra- and interobserver variations [
1]—a known diagnostic challenge that is especially pronounced if the problem is complex and/or open for personal opinions.
A hematoxylin & eosin (H&E)-stained tissue slide is the principal method used to evaluate tissue morphology, while immunohistochemistry (IHC), with chromogens or fluorophores bound to an antibody, is used to visualize specific protein expressions. Classically, the focus has been on the morphology and protein expression of cancer cells. However, numerous studies have highlighted the interactions between cancer cells and their surroundings. This interplay, popularly termed the tumor microenvironment, impacts patients’ prognoses and is likely important when deciding treatment strategies. Immune cells and, especially, tumor-infiltrating lymphocytes (TILs) are among the most important cells in the tumor microenvironment and will, in many cases, directly influence cancer development. As a result, different variations of TILs have been suggested as prognostic and/or predictive biomarkers in various types of cancers, including colorectal cancer, breast cancer, melanoma and non-small cell lung cancer (NSCLC) [
2,
3,
4,
5]. Interestingly, the strategies for TIL identification vary between cancer types. In colorectal cancer (CRC), IHC is used to visualize CD3+ and CD8+ TILs [
4], while conventional H&E is used for TIL identification in breast cancer and melanoma [
2,
3]. Moreover, TIL quantification ranges from fully discrete grouping via semi-quantitative to absolute count-based methods. For other cancers, such as NSCLC, the preferred method of TIL identification and quantification is yet to be determined [
2,
5,
6]. While IHC-based methods provide information about the cell type and function, they add complexity, time spent and cost. Hence, using conventional H&E for TIL identification is tempting, especially if identification can be conducted without time-consuming manual counting.
Computational pathology presents an opportunity for automatic TIL identification in H&E WSIs. The methods range from simple rule-based systems, which rely on easily understandable hand-crafted features such as shape, size and color, to deep learning (DL) approaches, which calculate and combine image features nonlinearly. Given proper implementation, DL will usually outperform the sensitivity/specificity of simpler approaches at the cost of increased complexity, calculation time and loss of interpretability. Unfortunately, DL requires thousands of annotated images to reach its full potential, and the procurement of annotated training datasets may be challenging due to the required pathologist effort. Fortunately, several recent projects provided datasets and introduced highly accurate DL models for cell segmentation and classification in H&E images [
7,
8,
9,
10,
11,
12,
13]. However, to our knowledge, none of these approaches have been adapted to TIL quantification in a clinical setting.
Herein, we present our approach and cloud-based system for the quick evaluation and deployment of machine learning models in a clinical pathology setting using our real-world dataset from patients with NSCLC. To investigate the clinical usefulness of DL for TIL quantification, we:
Implemented the HoVer-Net [
7] algorithm and compared our results to the original paper and the work of Gamper et al. [
10].
Tested how HoVer-Net performs on unseen data, which will be the case in a clinical setting.
Evaluated an additional augmentation approach with the aim of improving the performance on unseen data [
14].
Compared the prognostic performance of TILs identified by HoVer-Net to the standard state-of-the-art approach (CD8 staining).
Assessed the immune cell annotations produced by six HoVer-Net models trained on three datasets for our unlabeled dataset comprising H&E-stained images of NSCLC.
Created a system for deploying machine learning models in a cloud to support the implementation of computational pathology and to quickly evaluate promising methods in a clinical setting.
3. Datasets
3.1. Public Datasets to Train and Test a Machine Learning Model
In the past decade, several excellent annotated datasets for cell segmentation and classification were made publicly available, as summarized in
Table 1. The CoNSeP, PanNuke and MoNuSAC datasets were, at the time of submission, the only publicly available datasets comprising both the segmentation masks and class labels necessary to train DL models for simultaneous cell segmentation and classification. The dataset characteristics are summarized in
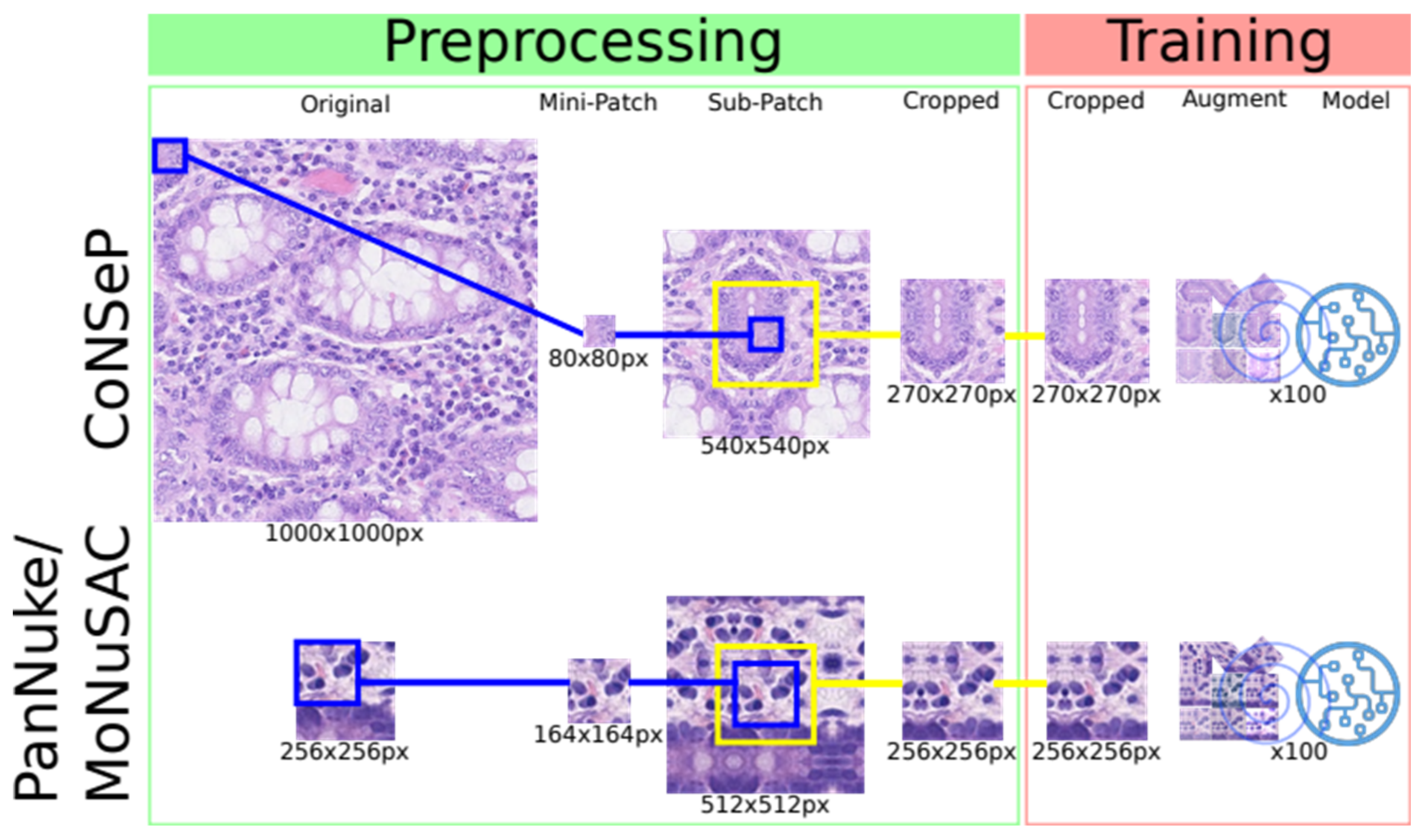
Table 1, and a simplified version of how patches are generated and processed during the training procedure is illustrated in
Figure 1.
3.2. UiT-TILs Dataset Used to Clinically Validate TIL Classifications
To validate the clinical relevance of TIL detection, we compiled the UiT-TILs dataset comprising 1189 image patches from 87 NSCLC patients with matched clinical data. The UiT-TILs dataset is a subset of the cohort presented by Rakaee et al. in 2018 [
15]. The patches were generated in QuPath [
16] using thresholding to detect the tissue area, followed by the generation of 4019 × 4019 px (1000 × 1000-μm) patches and the manual selection of up to 15 consecutive patches from the tumor border. Due to differences in the tumor size, tissue quality and the absolute length of the tumor border present in each WSI, the target number of 15 patches from each patient could not be met in all instances (median number = 15, range 3–16). The patient’s clinical data are summarized in
Table S1.
3.3. Augmentation
Our augmentation strategy includes the use of a heuristic data augmentation scheme thought to boost the classification performance [
17]. First, we augment the two training datasets using the augmentation policies provided in the HoVer-Net source code [
7]. These include affine transformations (flip, rotation and scaling), Gaussian noise, Gaussian blur, median blur and color augmentations (brightness, saturation and contrast). Second, we introduce a linear augmentation policy proposed by Balkenhol et al. [
14] for better generalizability and overall improvement of the trained models. The image is (1) converted from the RGB to the HED color space using the scikit image implementation of color deconvolution, according to the Ruifrok and Johnston algorithm [
18]; (2) each channel is transformed using a linear function that stochastically picks coefficients from a predefined range, and (3) transformed channels are combined and converted back into the RGB space.
3.4. Replicated Training Algorithm
We repurpose the training pipeline from the HoVer-Net source code. In brief, we preprocess the data and extract sub-patches from the training dataset. For the CoNSeP, MoNuSAC and PanNuke datasets, the input patch sizes are 270 × 270 px, 256 × 256 px and 256 × 256 px, respectively. For each input patch, the RGB channels are normalized between 0 and 1. The datasets are augmented via predefined policies and handled by the generator during training.
Figure 1 is a simplistic depiction of preprocessing and training. The training procedure is performed in two phases—training decoders and freezing encoders and fine-tuning of the full model. The training is initialized on weights pretrained on ResNet50 and optimized using Adam optimization while decreasing the learning rate after 25 epochs for each phase. The models are trained for a total of 100 epochs. The ConSeP dataset used by Graham et al. is split into training and test subsets with 27 and 14 image patches, respectively. Since no validation set is provided for the CoNSeP dataset, we use the training and test sets to train and validate the CoNSeP models, and the test set is used again to evaluate the model performance. The MoNuSAC dataset provides training and test sets, and when training our models, we split the training set 80/20 into training and validation sets, respectively. The PanNuke dataset provides separate sets for the training, validation and testing models. For additional details about the training parameters, we refer to the original paper and their open-source code [
7,
10,
11].
3.5. A System for Training, Tuning and Deploying Machine Learning Models
To easily tune and evaluate machine learning models, we need an environment that has the computing resource to keep the training time short, provide easy deployment, keep track of the experimental configuration and ensure that our experiments are reproducible. In addition, we want to make the code portable. This will enable us to deploy the containers on a commercial cloud with GPU support to gain access to the needed computing resources for fast training or on a secure platform to train on sensitive data that cannot be moved to a commercial cloud.
To solve the above challenges, we containerize the code so that we can easily deploy it on a cloud platform or our in-house infrastructure. We use Docker [
19] containers and a Conda [
20] environment for dependency handling. We use Kubernetes [
21] for container management. To ensure the experiment reproducibility and to keep track of the tuning parameters, we use Pachyderm [
22], since it enables data and model provenance and parallelized batch processing.
We deploy our customized HoVer-Net model using our approach summarized in
Figure 2. To make it easier to test different training data, augmentation and parameters, we use configuration profiles implemented as YAML files generated in the process and stored in the code repository. We split data wrangling and training from inferences to make it easier to deploy these on a new platform. To reduce the execution time, we use Tensorpack with Tensorflow 1.12 to infer and post process patches in parallel.
We use a docker container on a local server with a RTX Titan GPU for development and debugging. We train and tune the models on the Azure cloud, using AKS (Azure Kubernetes Service) with GPU nodes with the Pachyderm framework. As a node pool, we use 1 Standard NC6 (6 cores, 56 GB RAM) node with 1× K80 GPU accelerator.
3.6. Interactive Annotation of WSIs
To demonstrate and visually evaluate the TIL classifications and quantification, we developed the hdl-histology system (
Figure 3). It is an interactive web application for exploring and annotating gigabyte-sized WSIs. Our web server implements the URL endpoints required to request and transfer WSI tiles with interactive response times. It uses the Flask framework to implement a RESTful API. We use Gunicorn (Green Unicorn) [
23] to handle concurrent requests. We use OpenSeadragon (OSD) to implement a tiled map service [
24]. To achieve an interactive performance for high-resolution WSIs, we export the slides from their native format (.vms, .mrxs and .tiff, etc.) using
vips dzsave and generate Microsoft’s DeepZoom Image (.dzi) tiles as a pyramidal folder hierarchy of .jpegs on a disk. We provide classification as a service for interactive patch annotation. We use Tensorflow Serving as a containerized server for the trained models. This service exports a REST API. The input is the patch to process and the name of the model to use. The service returns a class probability map that can be used to create a visual mask for the cells in the patch. The REST API is used by the webserver that overlays the returned pixel matrix of the annotated regions.
The web server runs in a docker container on the Azure App Service. The app service pulls the docker image from our Azure Container Registry. The images are stored in a blob container, which is path mapped to our app service. To deploy updates to the system, we use continuous integration with azure pipelines. The deployment pipeline triggers push events of an azure branch in the git repository using GitHub Webhooks (
https://docs.github.com/en/developers/webhooks-and-events/about-webhooks, accessed on 1 August 2019). The build pipeline pulls the latest change from the branch and builds a docker container from the repos Dockerfile and pushes the container image into our Azure Container Registry (
Figure 2).
3.7. Validation of TIL Quantification on Unlabeled Data
To pragmatically evaluate the quantification of TILs without the large effort required for manual labeling, we apply three methods.
First, to verify that our modifications to HoVer-Net do not change the results, we reproduce the results described in the original HoVer-Net and PanNuke papers using the CoNSeP and PanNuke datasets (
Table S2) [
7,
10]. Further, to investigate whether an additional augmentation leads to more robust and generalizable models, we use the CoNSeP, MoNuSAC and PanNuke datasets to train separate models with and without additional augmentations.
For comparison to the original HoVer-Net paper, we evaluate the segmentation and classification tasks using the metrics provided in the HoVer-Net source code [
7]. The full description of the metrics used in the replication study is available in the
Supplementary Materials.
For all other comparisons, we use the conventional and well-established metrics to compare and benchmark our models. Since the models encompass both segmentation and classification, we compare the segmentation and classification separately and combined. The definitions of the metrics we used to evaluate the segmentation and classification separately are available in the
Supplementary Materials. The integrated segmentation/classification metrics include:
where
- detected cells with the GT label
t, classified as
t,
- detected or falsely detected cells with a GT label other than
t, classified as other than
t,
- detected or falsely detected cells with a GT label other than
t, classified as
t, and
- detected cells with the GT label
t, classified as other than
t and all cells with the GT label
t not detected for each class
t.
As , we use inflammatory and cancer cells. To compare our augmentation approach with the original approach we applied the trained models to their respective test datasets and used cross-inference with the test data from the other dataset. For an evaluation of the cross-inference results, we had to count both normal epithelial and neoplastic cells as cancer cells, due to the fact that the CoNSeP and MoNuSAC datasets do not differentiate between normal and neoplastic epithelial cells.
Second, to demonstrate that our methods may be adapted for use in a clinical setting, we apply our models on all patches in the UiT-TILs dataset and calculate the median number of cells classified as inflammatory/TILs for each patient. The median number of identified immune cells will then be correlated to the number of immune cells identified using digital pathology and specific immunohistochemistry on tissue microarrays and semi-quantitatively scored TILs previously evaluated in the same patient cohort [
15,
25]. To assess the impact of TILs identified using our deep learning approach, the patients are stratified into high- and low-TIL groups, and their outcomes are compared using the Kaplan–Meier method and the log–rank test with disease-specific survival as the endpoint.
Third, to demonstrate that our methods are meaningful in a clinical pathology setting, two experienced pathologists (LTRB and RS) visually inspected the segmentation and classification results for the TILs and cancer cells in 20 randomly sampled patches from the provided dataset. During the inspection, they estimated the precision and recall for the TILs and cancer cells using 10% increments for each measurement. We calculate the F1 scores based on the estimated precision and recall for each patch.
5. Discussion
5.1. Summary of the Results
In this paper, we presented our adaptation of HoVer-Net. Specifically, we implemented the original approach as presented by Graham et al. and retrained the model on an expanded dataset published by Gamper et al. [
7,
10]. To increase the model accuracy and prevent overfitting, we introduced additional augmentations and compared models trained with and without these. Interestingly, our additional augmentations did not lead to a measurable increase in the model performance (
Table 2 and
Table S3). Moreover, we published UiT-TILs, a novel retrospective dataset consisting of patient information and tumor images sampled from 87 patients with NSCLC. We used this dataset to explore the possible clinical impact of our approach and compared it with the current state-of-the-art methods for TIL evaluation in NSCLC patients. Our results suggest that the prognostic impact of TIL identification in H&E-stained sections with the current DL approach is comparable, and possibly superior to, the chromogenic assays (standard IHC-stained CD8 cells in TMAs HR 0.34, 95% CI 0.17–0.68 vs. TILs in HE WSIs: HoVer-Net PanNuke Aug Model HR 0.30, 95% CI 0.15–0.60, and HoVer-Net MoNuSAC Aug model HR 0.27, 95% CI 0.14–0.53,
Figure 4 and
Table S5). Finally, to provide an environment for easy and fast prototyping and deployment for experiments and production, we built a cloud-based WSI viewer to support our back end. Our system is scalable, and both the front end and back end can function separately.
5.2. Related Works and Lessons Learned
The number of potential use cases for digital pathology is increasing. However, while the basic research is making strong headway, the use of digital pathology in routine clinical pathology is currently not aligned with the expectations for most laboratories. In a recent paper, Hanna et al. reviewed the process of adopting digital pathology in a clinical setting and shared from their process at the Department of Pathology, Memorial Sloan Kettering Cancer Center [
26]. They concluded that, to increase the number of pathologists willing to adopt digital pathology, the technology has to offer benefits that impact the pathologist’s daily work. While conventional image analyses have proven suitable for some tasks, such as counting the number of cancer cells staining positive for Ki67 in breast cancer [
27], they are prone to failure, given the increasing complexity. We, among many others, believe that DL will deliver the tools necessary to irreversibly pave the way for digital pathology. Despite this optimism, one of the main arguments against DL in medicine in general, and in cancer care in particular, is its inherent black box nature. As an example, Skrede et al. published DoMore-v1-CRC, a prognostic model in colorectal cancer that outperformed the prognostic impact of the TNM staging system for CRC patients in retrospective data [
28]. Moreover, their model may help select patients that will benefit from adjuvant chemotherapy. However, whether their lack of explanation will impede its implementation remains to be seen. We chose to focus on cell segmentation and classification in general and on TILs in particular. Distinct from models that derive patients’ prognoses from abstract features from imaging data alone, the success of our model can be evaluated directly based on its output (
Figure 5). Interestingly, the prognostic impact derived from TILs identified on NSCLC H&E WSIs by the current state-of-the-art segmentation and classification models are equal or superior to the IHC-based methods. This latter finding was corroborated by our manual validation, where the segmentation and classification of the TILs were consistent through the majority of the images. However, we observed a significant difference in the model performances for an image with a darker background and overall worse performances in images where TILs were scarce. These latter points suggest that our models are overfitting on the dataset. To summarize, our present effort illustrates that it is possible to repurpose existing DL algorithms for use on real patient samples with understandable output translating into clinical information that may be used to make informed treatment-related decisions for patients.
In an attempt to further generalize our models, we adapted a linear augmentation policy proposed by Balkehol et al. to the HoVer-Net training pipeline [
14]. For models trained on the PanNuke and MoNuSAC datasets, we did not observe the expected benefits of the additional augmentations (
Tables S2 and S3). For models trained on the CoNSeP dataset, there was a tendency towards better performances when additional augmentations were used. Currently, there is no reference augmentation policy for use on histopathology datasets. Our experience suggests that smaller datasets may benefit the most from additional augmentation. However, there are several steps, including, but not limited to, tissue handling, staining, scanning, normalization and additional augmentations fitted before or during training, that may impact the model performance. Exploring these is beyond the scope of the current paper, but our use of MLOps best practices should make it easy to evaluate different normalization techniques and augmentation policies. Based on the reasonable performances of the CoNSeP models on CRC tissues and on the CoNSeP dataset, another feasible approach is to generate specific datasets for each problem. This latter strategy may make models less complex, because the variability will be reduced. However, we do not believe that task-specific datasets will contribute to more accurate TIL detection, as TILs, contrary to cancer cells, are morphologically equal across all cancers.
5.3. Future Work
As a general direction for future works, we can outline the following points: prune and optimize models to run faster with less computational power; improve web server applications to reduce response times; integrate with widely used tools such as ImageJ/Fiji, Cell Profiler, QuPath and others; add additional features useful as decision support for pathologists and test acquired models on new datasets to validate the model performance on other tissue types. It is also pertinent to explore new methods for dataset generation that incorporate all the steps from tissue handling to staining to segmentation, auto-labeling and manual and/or automatic feedback.
For the specific use case of TIL segmentation and classification, future studies should address localization and the possible varying distributions of TILs in a tumor. Further, tile sampling may reduce the amount of tissue needed to be assessed and thereby compute resources. In addition, incorporating additional elements, such as the class of surrounding cells and information of the tissue structure, may further improve the performance of the classification step.
5.4. Limitations
In our composed dataset, we manually extracted patches to test our models and hypotheses. In future works, we plan to eliminate that flaw and automatically extract the region of interest in the WSI.
In this work, our aim was to provide an interactive graphical user interface for pathologists able to test and evaluate different machine learning models for a WSI analysis. The response time is minutes for average size patches and hours for WSIs. It can be improved by using a more powerful GPU or multiple GPUs. However, we also want to make the service accessible to pathologists by using cloud services. The cloud service cost may be significant, especially if the service is running continuously. Model optimization may reduce the cost and improve the response times by using, for example, hardware accelerators or pruning techniques. It may also be more cost-efficient to deploy the systems on an on-premise server with GPUs. Currently, our tool is designed for hypothesis generation, testing and education. In a clinical implementation, we need to improve the response times, reduce the costs, make it easier and more convenient to use, integrate it with the existing clinical ecosystems, test it in clinical scenarios and obtain permission from regulatory bodies for its use as a medical device.
6. Conclusions
In conclusion, we used already published state-of-the-art DL models for the segmentation and classification of cells and adapted and retrained these for use on new data. We showed that TIL identification using DL models on H&E WSIs is possible and, further, that the clinical results obtained are comparable to, and possibly supersede, the prognostic impact of conventional IHC-based methods for TIL identification in tissues from lung cancer patients. Moreover, our approach, utilizing published datasets, significantly limits the need for creating additional costly labeled datasets. Distributed deployment and deployment as a service allow for easier and faster model deployment, potentially facilitating the use of DL models in digital pathology. However, before clinical implementation, the efficacy of our methods needs to be further validated in independent datasets, and the system must be tightly integrated into the clinical work flow to ensure adaptation to the daily diagnostics.

 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}